Blog
This post is contributed by Naoki Matsumoto, who was an intern at PFN and is currently working as a part-time engineer.
The Distributed Cache System in PFN
PFN provides a unique distributed cache system called Simple Cache Service (SCS) to accelerate dataset loading and container image distribution in deep learning.(Distributed Cache Empowers AI/ML Workloads on Kubernetes Cluster) SCS has a simple HTTP API with GET and PUT methods. It makes easy to use from various applications, including Python, deployed on Pods within a Kubernetes cluster. Since its deployment in 2023, we have addressed various issues that arose during two years of operation (for details, please refer to the presentation above), and it is now capable of handling requests at peak rates of 37k req/s and data volumes of 75.1 GiB/s.
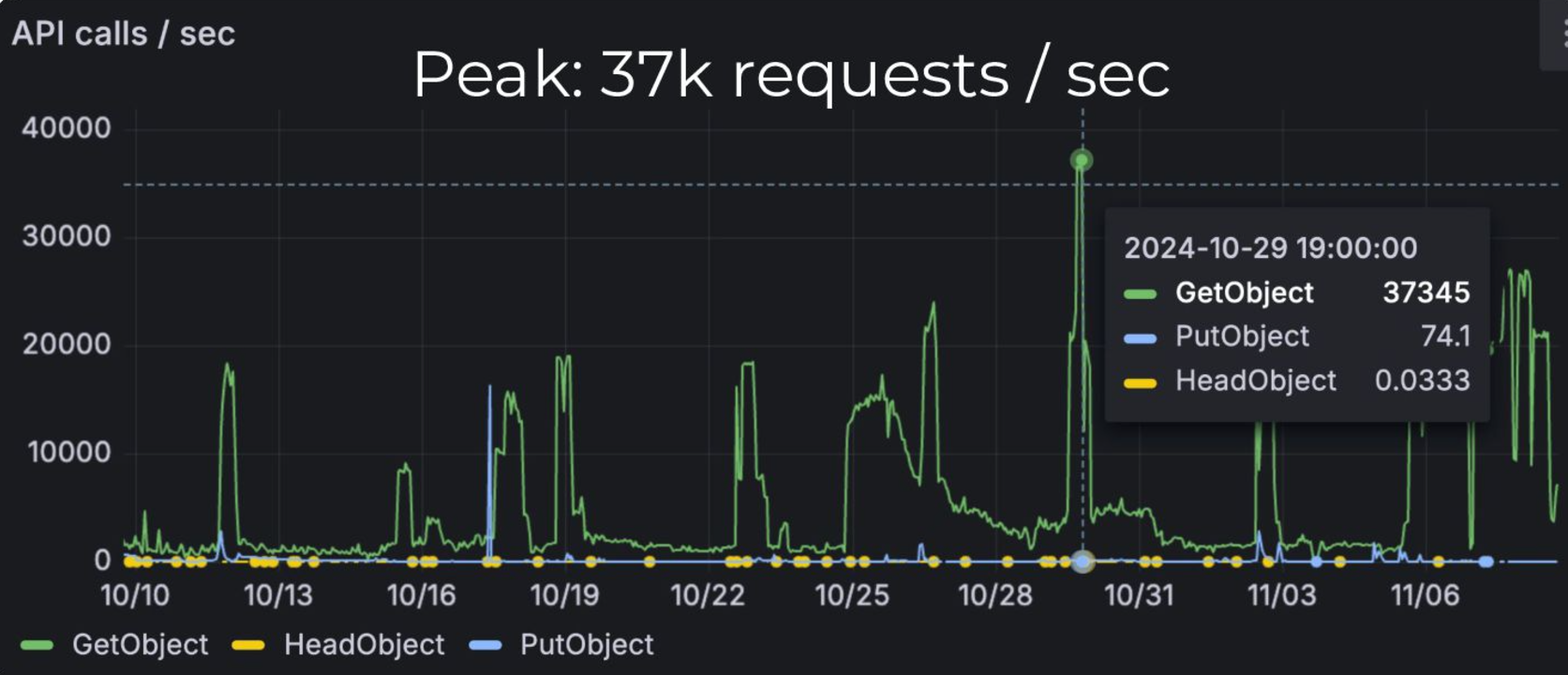
(cited from Distributed Cache Empowers AI/ML Workloads on Kubernetes Cluster / KubeCon + CloudNativeCon North America 2024 – Speaker Deck )
SCS is designed with a “shared nothing architecture” to gain scalability and eliminate performance bottlenecks. With simple implementation and tuning through profiling, SCS allows for cache data delivery in the range of hundreds of microseconds to several milliseconds. The overall architecture also utilizes load balancing at L4 and L7 through Kubernetes Services and Envoy Proxy, ensuring that there are no single points of failure and providing scalability that easily accommodates the addition of nodes.
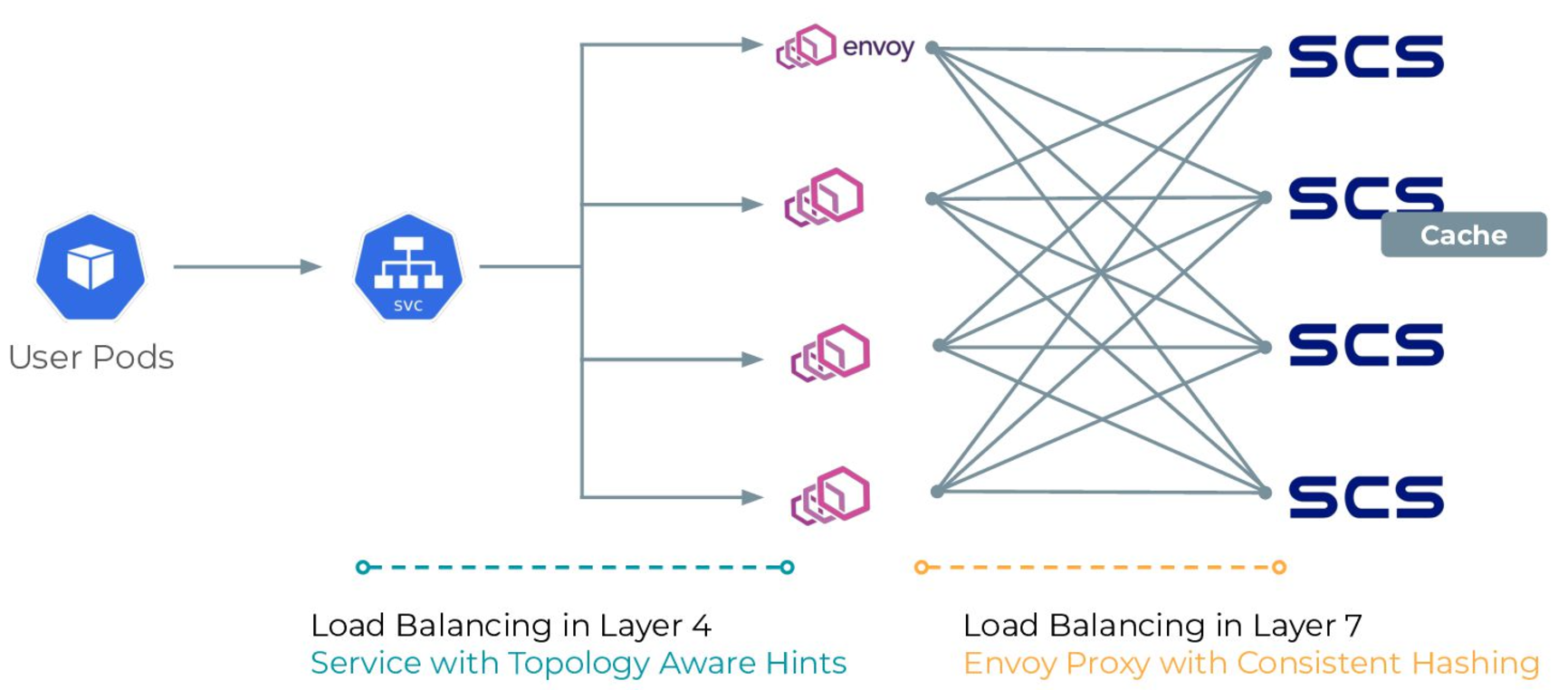
(cited from Distributed Cache Empowers AI/ML Workloads on Kubernetes Cluster / KubeCon + CloudNativeCon North America 2024 – Speaker Deck )
In actual workloads, including deep learning, combining PFIO which is an I/O abstraction library for Python developed by PFN, with SCS can accelerate dataset loading. In benchmarks using the ImageNet-1K dataset, we achieved approximately a fourfold increase in data loading speed, allowing for more efficient utilization of limited GPU resources.
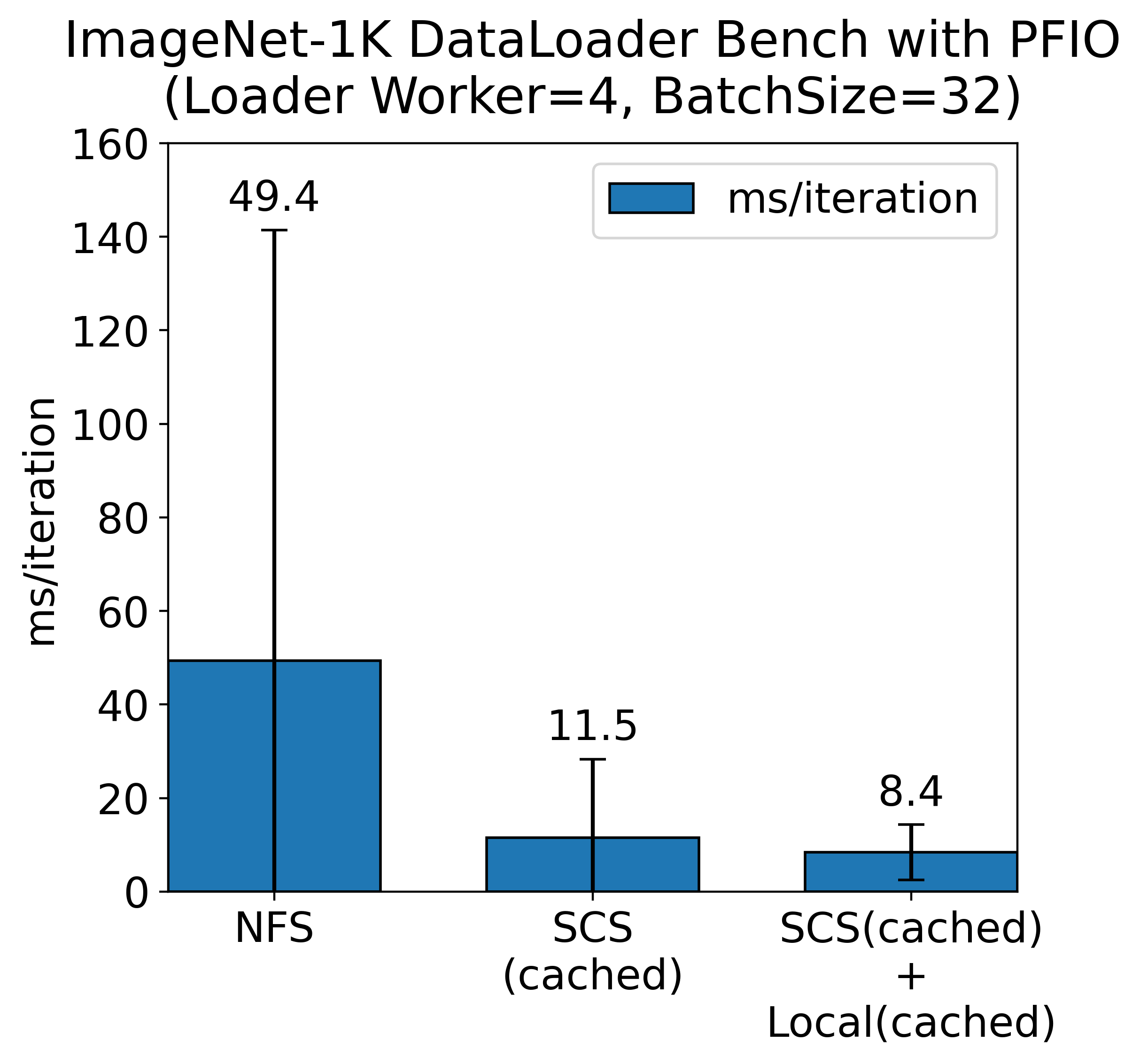
(2026/04/13 Corrected units)
While SCS is already being utilized for a variety of applications, there is still room for performance improvement. This article will introduce examples of enhancements made to the SCS server.
Overview of SCS Node
In SCS, Envoy distributes requests to the SCS Node servers. Each SCS Node contains components such as sqlite3 for managing objects and an LRU (Least Recently Used) module to maintain a consistent storage usage.
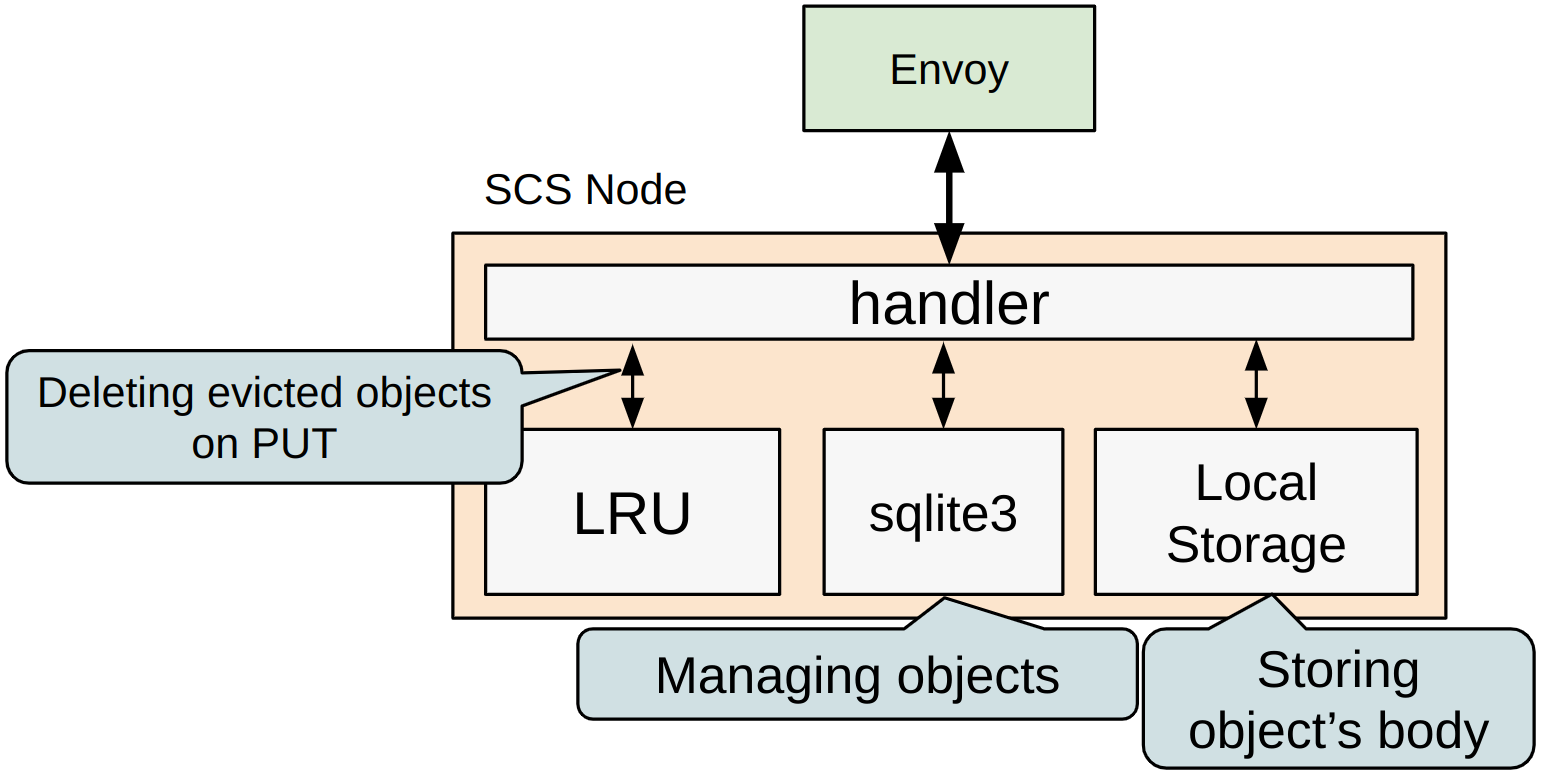
sqlite3 manages and persistently stores all objects held by the SCS Node. The actual objects are kept in node-local high-speed storage. The LRU module provides the core functionality of “removing old objects to ensure that the capacity limit is not exceeded,” and it is designed to remove older objects that exceed this limit during the PUT operation.
The SCS Node creates and adds management information for objects to the LRU and sqlite3 each time an object is PUT. Due to the limitation of sqlite3, which locks the entire database file during modification operations, INSERT and UPDATE processes cannot be performed in parallel, leading to performance bottlenecks during PUT operations and preventing full utilization of CPU cores. Additionally, the in-memory caching within the SCS Node also requires acquiring large locks, which presents similar issues. This time, we addressed these problems with improvements.
Performance Improvement with Sharding
While the SCS Node is designed with the assumption of a single node-local storage, we have considered the future use of multiple node-local storages and even faster storage solutions. This time, we implemented improvements by separating and parallelizing the processing logic through sharding. As a result, we expect that bottlenecks related to object management will be alleviated, leading to enhanced performance.
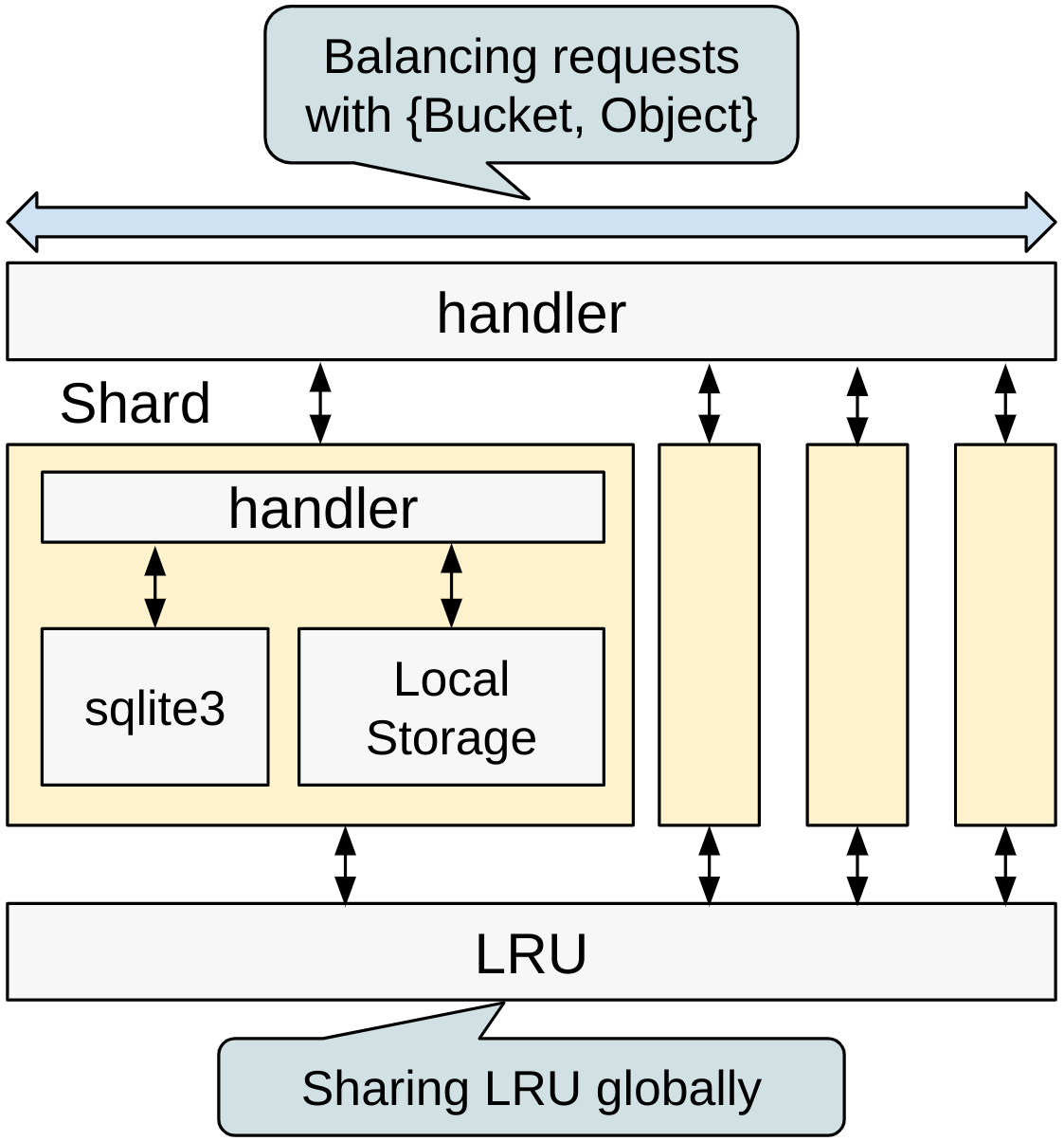
In the improved SCS Node, multiple instances (shards) are used to manage objects. Each instance has its own independent sqlite3 database, eliminating the possibility of contention between instances. Additionally, since each local storage is managed in a separate directory, it is easy to accommodate scenarios where multiple storages are utilized.
Object management occurs on a per-instance basis; however, to manage the LRU capacity globally across the node, we decided to share it globally. Because operations on the LRU can occur simultaneously from each instance, internal control is implemented using locks. While there is a potential for performance bottlenecks due to the LRU, it currently operates at sufficiently high speeds to not be an issue. The detail is described in the performance evaluation.
In cases where multiple storages are used and capacity can be managed on a storage basis, it may be beneficial to handle the LRU locally instead of sharing it globally.
Performance Evaluation
We evaluated the performance improvements brought about by sharding.
Performance Variation by the Number of Shards
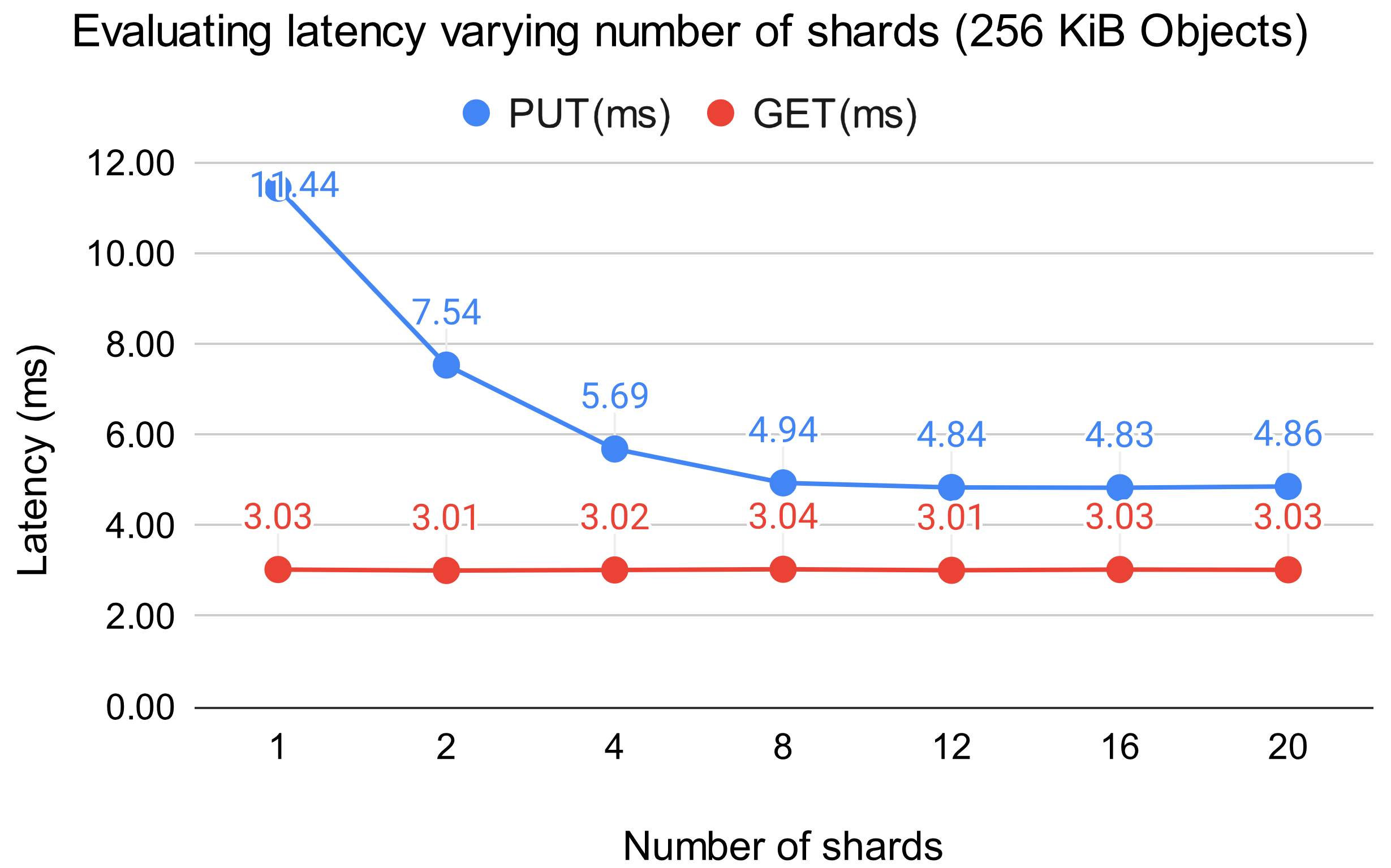
First, we measured the performance changes by varying the number of shards. The SCS Node used for benchmarking had 8 CPU cores allocated. For the benchmarking, we utilized a program where 20 clients parallelly processed 256 KiB objects according to the specified methods (either PUT or GET).
The results are shown in the figure below. It shows that the performance of PUT operations significantly improves as the number of shards increases up to 8. This is likely because the anticipated sqlite3 lock contention and write lock conflicts in the in-memory data management have become less likely. On the other hand, once the number of shards exceeds the number of cores, the reduction in latency plateaus. This suggests that we are effectively utilizing the available level of parallelism. For GET operations, there was almost no impact on performance, as sqlite3 does not acquire locks during these operations, and the design of in-memory data management does not involve acquiring write locks.
Synthetic Benchmark Simulating Clients
To conduct a more practical benchmark, we performed tests with multiple object sizes and simultaneous PUT and GET operations. In actual clients, when a 404 Not Found response is received during a GET operation, the client will perform a PUT for the cached object. In our synthetic benchmark, we incorporated this behavior into the benchmarking tool. The candidate object sizes were 256KiB, 1MiB, 4MiB, 16MiB, and 128MiB. The LRU limit was set to 40GiB, and the typical PUT and GET ratio was configured as PUT:GET = 1:99. We deployed a total of 25 clients, with 5 clients corresponding to each object size, to send requests in parallel and measure the results.
For the measurements, we evaluated both scenarios: when there is no overflow in the LRU and when overflow occurs. In the case of overflow, each client attempts to GET an object, but if it has been evicted from the cache due to the LRU policy, they will perform a PUT operation again. The LRU’s maximum capacity is set to 40GiB, while the total data amount being PUT is approximately 43GiB (300 objects for each size).
The comparison of latencies between the pre-improvement SCS (SCS-cur) Node and the post-improvement SCS (SCS-shard) Node is illustrated in the figure below.
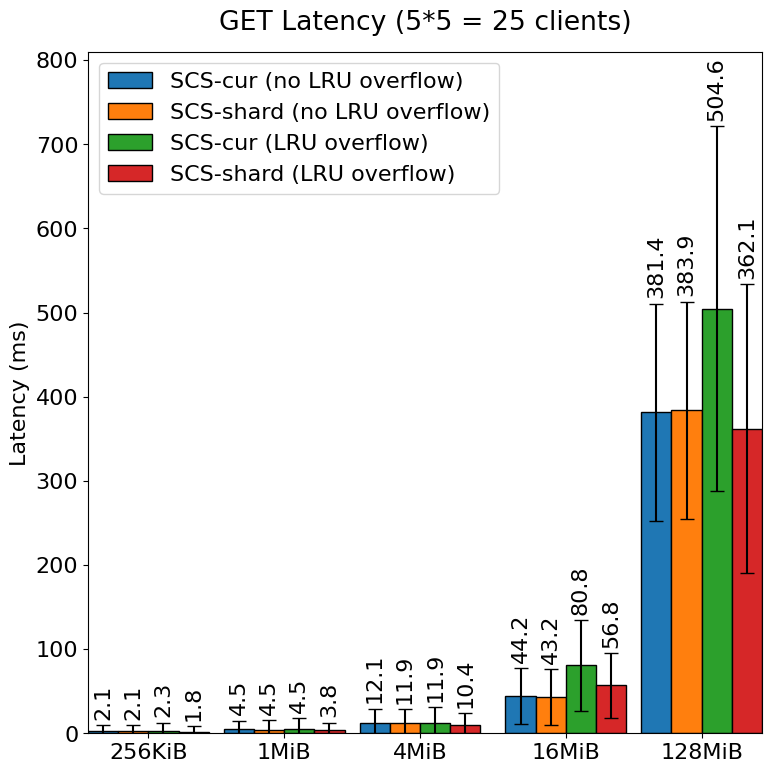
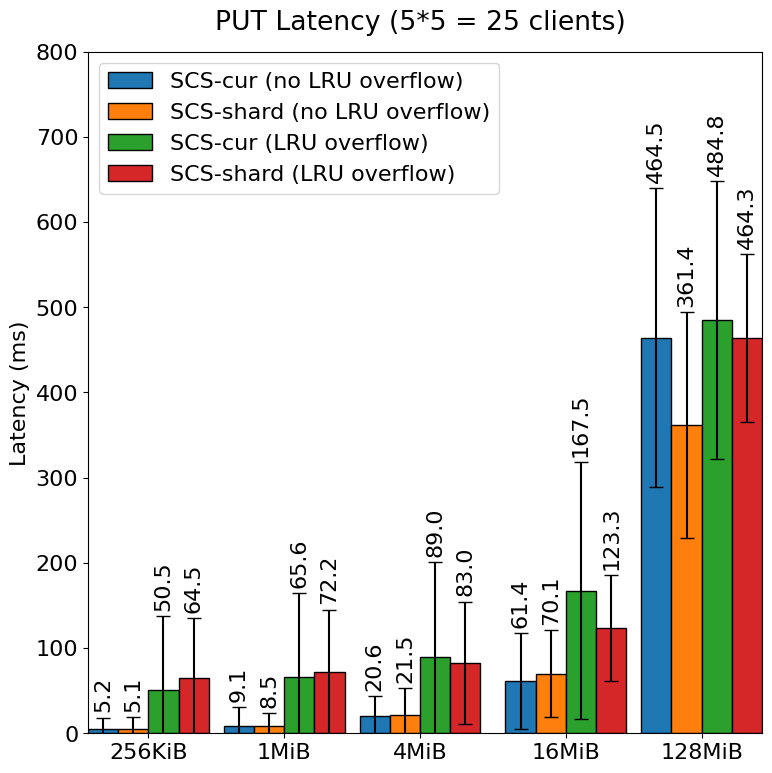
In cases where overflow occurs in the LRU, the overall performance degraded for both the SCS-cur Node and the SCS-shard Node. However, with SCS-shard Node, there is virtually no degradation in performance for overall GET operations or PUT operations related to larger objects compared to the SCS-cur Node. It is evident that the average latency and variance have been effectively minimized in the post-improvement version. The need to acquire write locks internally when processing LRU overflow had an impact on other GET and PUT operations. By implementing sharding, we were able to mitigate this influence.
The significant performance degradation observed for particularly small objects during PUT operations can be attributed to several factors, including the synchronous deletion of objects that have overflowed from the LRU during the PUT, as well as potential throttling due to a decrease in throughput that hits the disk performance limits. In the SCS-cur Node (with LRU overflow) benchmarks, the speed of object updates (including saving and deleting objects) reached 2 GiB/s. This indicates that, depending on the object size, performance may be approaching the limits typically achievable with standard NVMe SSDs.
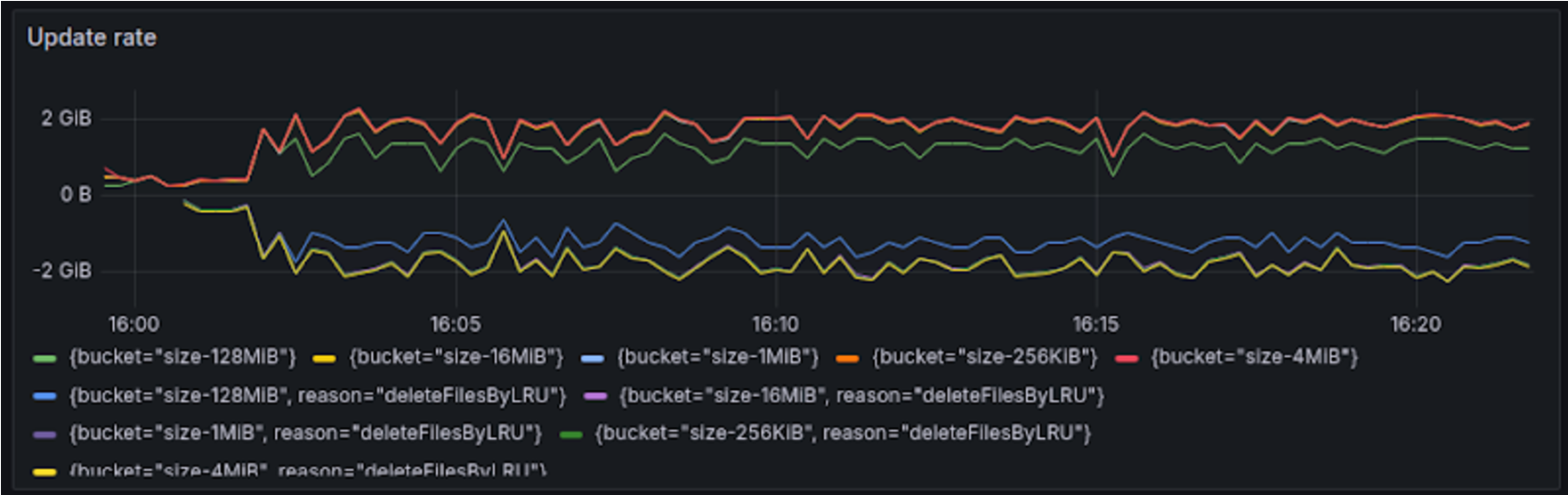
While sharding has provided some performance improvements, it still has a nearly tenfold difference in performance for smaller objects (256KiB, 1MiB) during PUT operations with LRU overflow. In a system like SCS that caches all types of objects, this results in congestion on the client side, leading to performance degradation issues. We will continue to work on improvements moving forward.
Scalability of LRU
Since the LRU is shared globally across shards, there are concerns about its impact on performance as the number of shards, and consequently the level of parallelism, increases. We also conducted evaluations to address this concern. In this benchmark, PUT operations corresponded to Inserts, and GET operations corresponded to Accesses, with a PUT:GET ratio of 1:9. Additionally, the LRU limit was set to 10 million entries, and the benchmark was conducted in a state where 10 million object entries had already been added, meaning that overflow from the cache occurred on the initial insert.
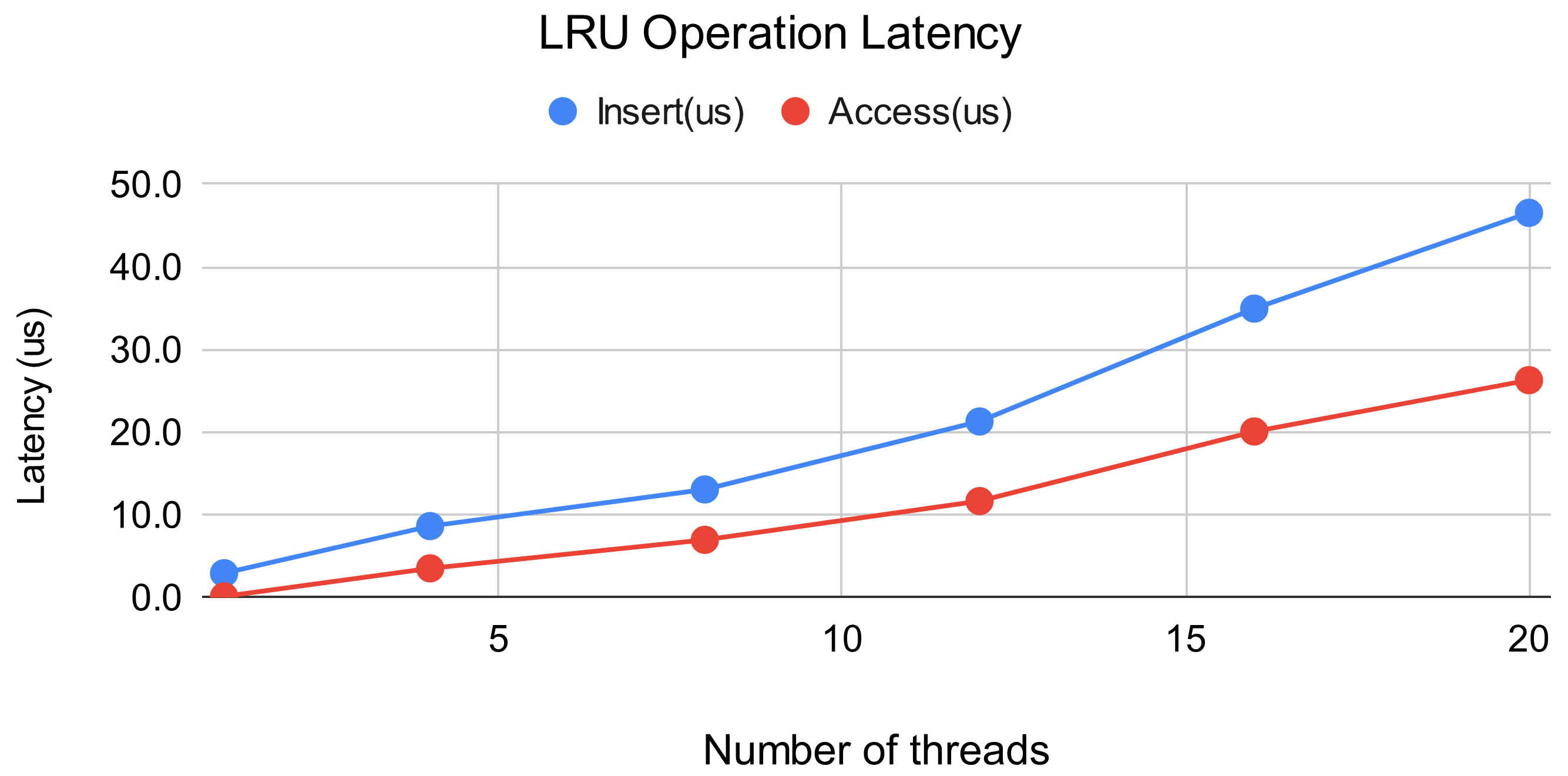
The results indicate that as the level of parallelism increases, both Insert and Access latency also increase almost proportionally. While the increase in parallelism may affect the performance of PUT and GET operations, it is important to note that the overall latency for PUT and GET is in the range of several milliseconds, whereas the latency for the LRU is in the tens of microseconds. Therefore, the impact on overall performance is considered negligible.
Benchmark with Real Workloads: Deep Learning Using PFIO.
PFIO is an I/O abstraction library developed by PFN. It not only handles datasets compressed with Zip but also provides the functionality to cache datasets on local storage and via HTTP APIs (i.e., distributed cache systems). In this comparison, we measured the time required to load approximately 1.28 million training images contained in the ImageNet-1K dataset using PFIO. The entire dataset is maintained as a Zip file, with each image being approximately 120 KiB in size.
The origin of the dataset was placed on an NFS server configured with NVMe SSDs, and we compared the time taken for one iteration with and without caching using SCS. For dataset loading, we implemented the Dataset using PyTorch DataLoader with 4 data loading workers and a batch size of 32. It is important to note that we only compared the time required for data retrieval, without conducting any model training.
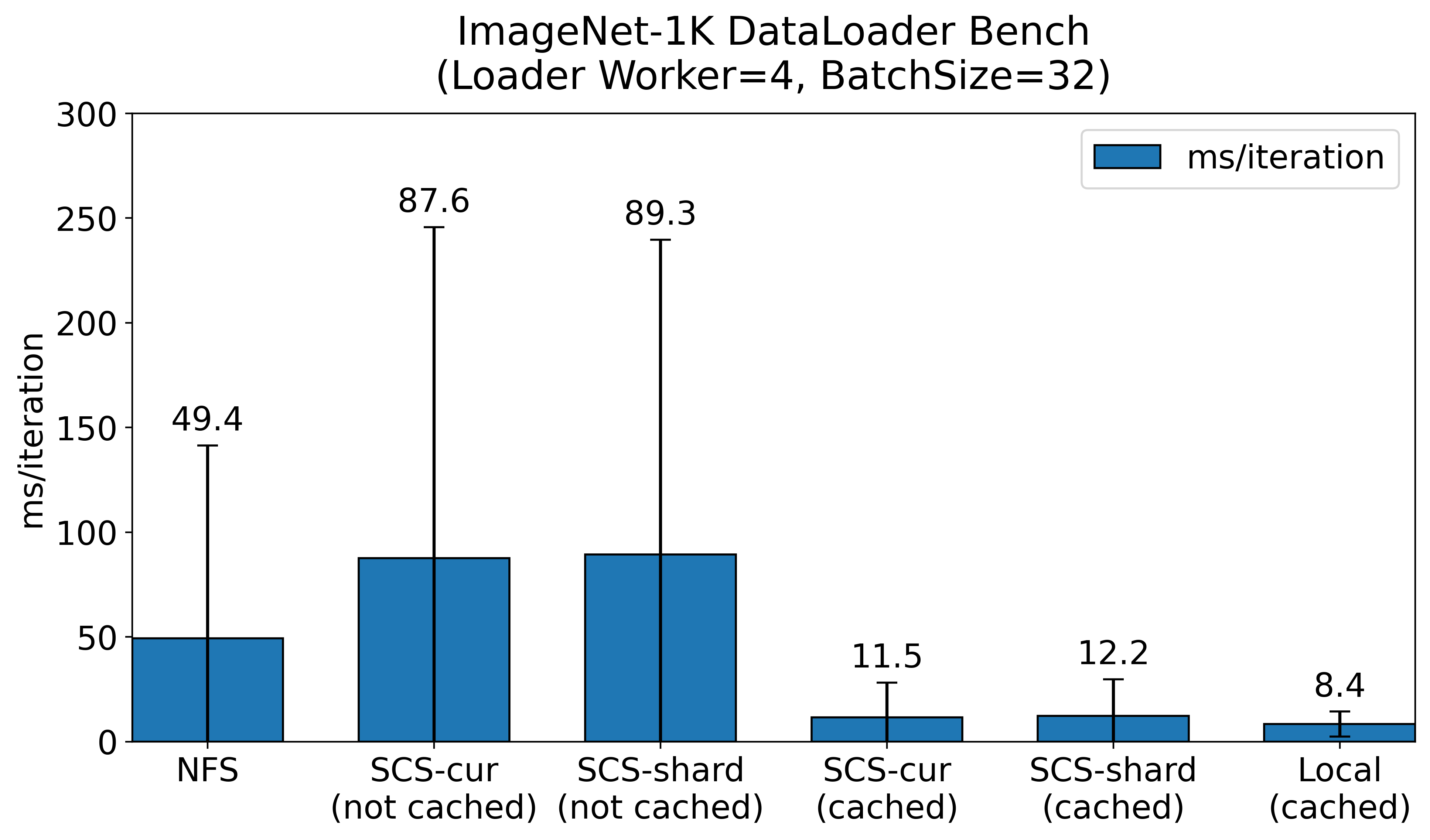
(2026/04/13 Corrected units)
The NFS server alone took an average of nearly 50 ms, and during the benchmark, the NFS server experienced traffic of around 1 GiB/s.
In cases using SCS, when the data is not cached, it takes approximately 90 ms. It is nearly double the time. This is because when a GET request to SCS returns a 404 Not Found, it has to retrieve the corresponding data from the NFS server and subsequently perform a PUT to SCS, resulting in longer retrieval times compared to just accessing the NFS.After running a complete epoch of the dataset and caching everything in SCS, we found that when hitting the SCS cache, data retrieval speeds improved to about 12 ms, which is roughly four times faster compared to the NFS server. When training ResNet-50 using 32 images on an NVIDIA V100, it takes several tens of milliseconds. Considering the overlap between I/O and computation, if I/O exceeds several tens of milliseconds, it can lead to GPU waiting times due to I/O delays. However, when caching is hit in SCS, such waiting is eliminated.
From the results above, the most ideal scenario is when a local cache is present. However, there are many situations where local cache cannot be utilized, such as in distributed learning or when training pods are rescheduled to different nodes. By using SCS, it is possible to leverage a shared cache across the entire cluster without significant performance degradation compared to local caching. This facilitates faster data loading and reduces the burden on storage systems such as NFS servers or object storage that hold datasets. As mentioned earlier, SCS has an architecture that avoids single points of bottleneck, which is expected to deliver high performance even in large-scale distributed learning scenarios.
There were no significant improvements observed between the pre-improvement and post-improvement evaluations. In fact, there was a slight decrease in performance, which may be resulted from the shared nature of the measurement environment, potentially introducing variability in the benchmark results. Additionally, the improvements made are focused on accelerating PUT operations to SCS. It is important to note that not cached latency includes both the PUT time to SCS and the reading time from NFS, making it harder to see the improvements reflected in the benchmark results. Deploying the improved SCS Node in an environment with actual workloads and measuring its effectiveness will be an important task for the future.
Conclusion
As a mechanism to accelerate dataset loading and container image distribution in deep learning, PFN offers the Simple Cache Service (SCS). The performance of SCS significantly impacts the efficiency of processing various data types, including those used in deep learning; therefore, it is essential to handle a large volume of requests with minimal latency.
In this article, we highlighted the implementation of sharding in the nodes that comprise SCS as part of our efforts to improve performance, demonstrating a significant enhancement in PUT performance. We also presented a specific use case of SCS using PFIO and discussed the performance impacts of the improvements made. Moving forward, we will continue to work on enhancing SCS, which serves as a caching service to accelerate deep learning workloads and various services within the cluster.
Area
