Blog
2022.04.27
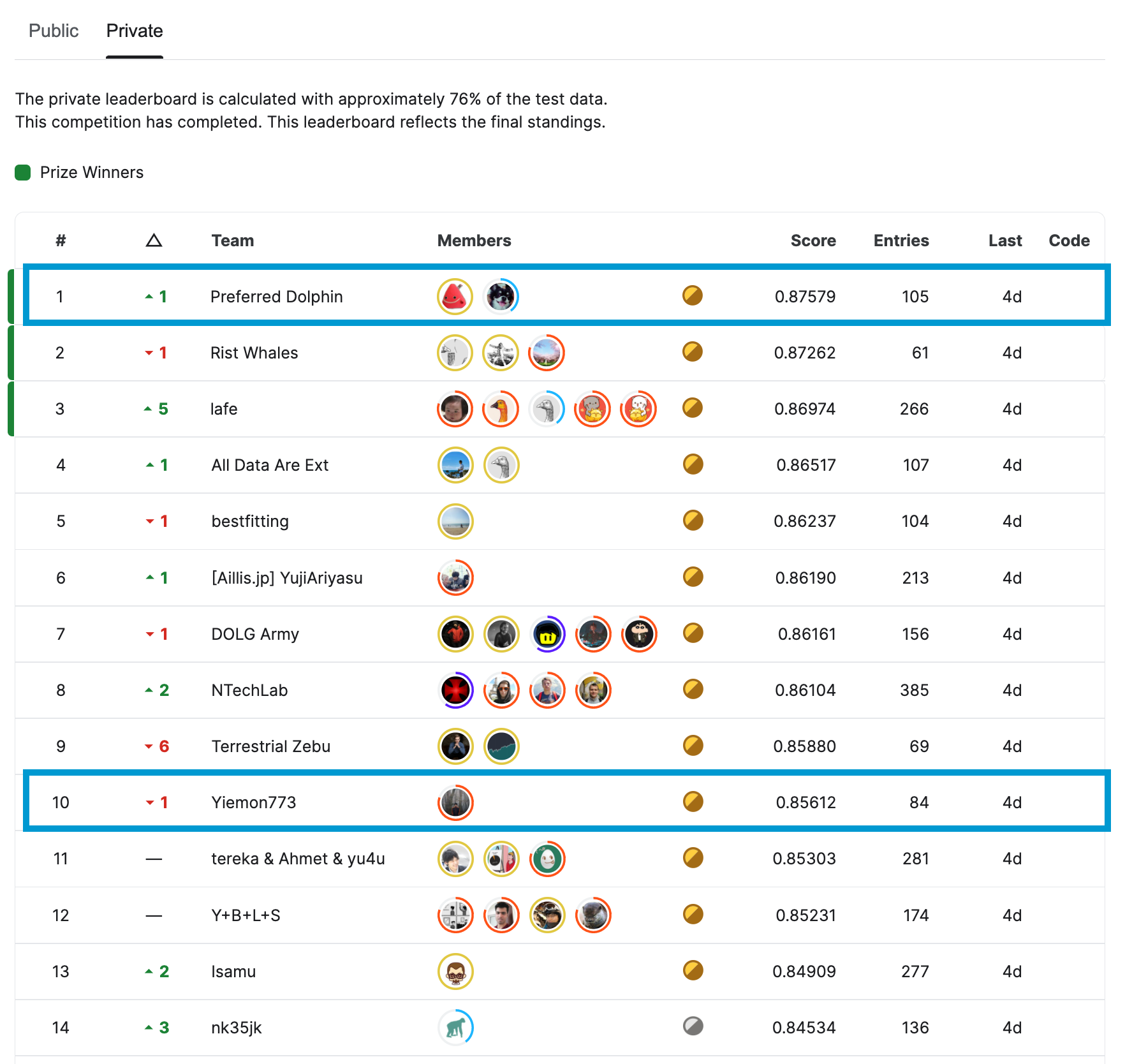
Kaggle Happywhale – Whale and Dolphin Identificationで優勝&10位でソロ金メダルを獲得しました
Taiki Yamaguchi
2022年2月から4月にかけてkaggle competition Happywhale – Whale and Dolphin Identification が開催され、Preferred Networksのメンバー2名:山口(@charmq)、阿部( @knshnb)からなるチーム Preferred Dolphinが優勝しました。また、山川(@Yiemon773)が10位でソロ金メダルを獲得しました。
今回のコンペは1,588チームが参加し、kaggle世界ランクtop10のうち過半数が参加しているなど、非常に競争が激しいものとなりました。
本記事ではこのコンペの概要と我々のソリューションについて紹介します。
コンペの概要について
本コンペでは、クジラやイルカの写真から各個体を識別するモデルの精度を競いました。
従来人手で莫大な時間をかけて行われていた個体識別を自動化することにより、海洋生物研究の大幅な効率化・発展、ひいては環境保全への大きな貢献が期待されます。
データの内容
今回与えられたデータは下記です。
- 画像・生物種名・個体IDを紐付けた表
- 各個体IDごとの画像
- 個体ごとにそれぞれ1枚 ~ 数百枚存在
これらのデータを用いて、ある画像が与えられた際、それがどの個体IDの画像なのかを予測することが今回のコンペのタスクでした。
加えて、コンペの評価で使用されるtest setには、train setに含まれない未知の個体も一定割合で存在し、そのような画像に対しては「未知個体の画像である」と予測する必要がありました。
評価指標
本コンペでは、各画像に対して最大5つの個体IDを自信度が高いもの順に並べ、それぞれの予測のPrecisionの平均値(MAP@5)で評価されました。
具体的には下記の式で表されます。
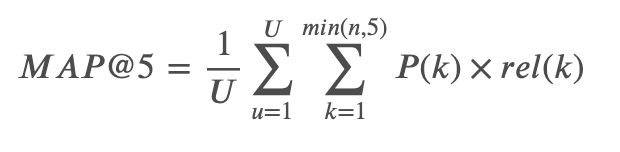
ここで、
- 𝑈: test 画像枚数
- 𝑛: 画像ごとの予測数
- 𝑃(𝑘): 上位𝑘番目までの予測に対するprecision
- 𝑟𝑒𝑙(𝑘): 指示関数。𝑘番目の予測が正解だった場合のみ1となり、それ以外は0
より詳細には、kaggleの評価指標定義をご覧ください。
すべての画像に対し5つの個体の予測を出力した場合、1番目で正解したときのスコアを1, 2番目で正解したときのスコアを1/2, …, 5番目で正解したときのスコアを1/5, 5つの中に正解がなかったときのスコアを0としたときの全画像に対する平均スコアで評価されます。
また、未知だと思われる個体に対しては`new_individual`と予測する必要があるため、これをどのように予測するかもスコアを上げる上で重要なポイントでした。全ての予測が的中すればMAP@5は1となります。最終的なprivate scoreとしては金メダルボーダーが0.85近くになり、優勝スコアは0.875でした。クラス数(個体IDの種類)が非常に多く、かなりimbalancedなデータであった一方で精度良く予測が可能になりました。
Method
本コンペでは、画像数が極端に少ない画像が大量にある・未知個体であることを検出する必要があるといった問題の性質から、metric learningという手法が主に使われていました。これは、データが似ているかどうかを表す距離を学習する手法で、今回のように各クラスのサンプルが少ない場合や未知であることを認識する必要がある顔認識などのタスクで広く用いられています。
metric learningの手法には様々なものがありますが、通常のクラス分類の手法に、異なるクラス間の距離を遠ざけるペナルティとしてmarginを導入した手法が近年注目を集めています。その中でもArcFaceはよく使われている手法であり、今回のコンペではベースラインとして公開されているnotebook・上位解法どちらを見てもほとんどのチームがArcFaceを使用し高精度を達成していました。単純なArcFaceではmarginとして一種類の値を設定し、全てのクラスに対して同一のmarginを使用します。しかし、タスクによっては各クラスのデータの個数に大きく偏りがあり、クラスに依らない同一のmarginでは不適切になることがあります。こういったクラス間のサンプル数の偏りを考慮し、クラスによって異なるmarginを使用するようにArcFaceを拡張した手法として、dynamic margin ArcFaceがあります。dynamic margin ArcFaceはGoogle Landmark Recognition 2020 Competition Third Place Solutionで考案され、Google Landmark Recgnition/Retrieval 2021の優勝解法でも使われているなどkaggleのmetric learning系のコンペでは度々使われています。実際、今回のコンペでも上位解法を見るといくつかのチームがこのdynamic margin ArcFaceを使用しており、これを上手く使いこなすことが高精度を達成するための重要なポイントの1つになりました。
1st Place Solution
チームPreferred Dolphinの優勝解法のうち、高いスコアを達成するのに重要であった工夫は主に以下であると考えています。
- Optunaによるdynamic marginのハイパーパラメータの調整
- BackboneとArcFace headで異なる学習率を使用する
- Bounding box mix augmentation
- k近傍法とlogitのアンサンブル
- Pseudo labeling
この節ではそのうち、1つ目と3つ目の項目について説明します。他の項目やその他の細かいテクニックなどは、KaggleのDiscussionにSolutionを公開しているのでぜひそちらもご覧ください。
Optunaによるdynamic marginのハイパーパラメータの調整
ArcFaceは過去コンペの上位解法にも多く使われている優秀な手法ですが、scaleとmarginという2つのハイパーパラメータに敏感であることが過去コンペのディスカッションや後続研究で報告されていました。さらに今回はmarginをクラス数に応じて変化させるdynamic marginの手法を採用したため、ハイパーパラメータの数が更に増え、その調整の良否が結果を大きく左右すると考えました。そこで、コンペの前半の段階でこのハイパーパラメータの調整に取り組むという選択を取りました。
ハイパーパラメータの調整には、弊社が中心となって開発しているOptunaというフレームワークを用いました。最適化する目的関数としては、single GPUで計算が高速に終わるように、efficientnet_b0・256という小さいモデル・画像サイズを用いたsingle foldでのvalidationスコアを設定しました。探索の際は複数の学習を並列で行いましたが、同じプロセスを複数立てるだけで自動で分散最適化を行ってくれるため便利でした。
下のグラフが、optuna-dashboardを用いて可視化した各Trialの学習の様子・目的関数の履歴になっています。最終的には0.001の精度の差を競うコンペになったため、少なくともこの設定においてはハイパーパラメータの選択が非常に重要であったことがわかると思います。
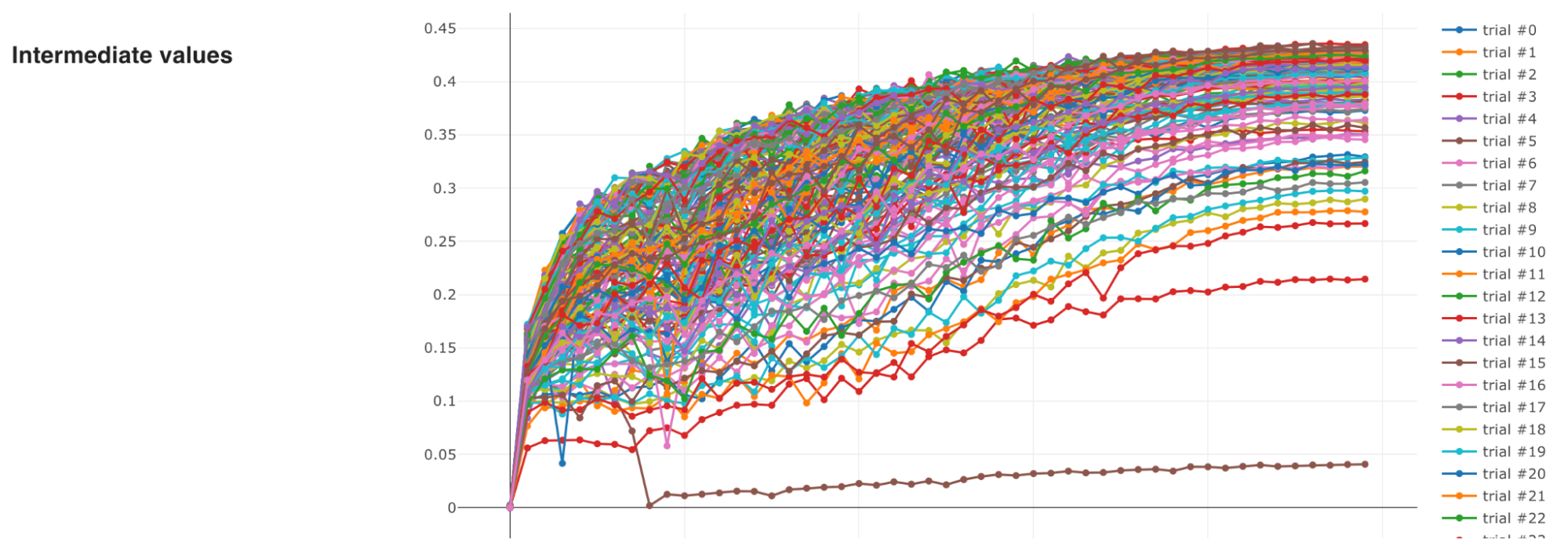
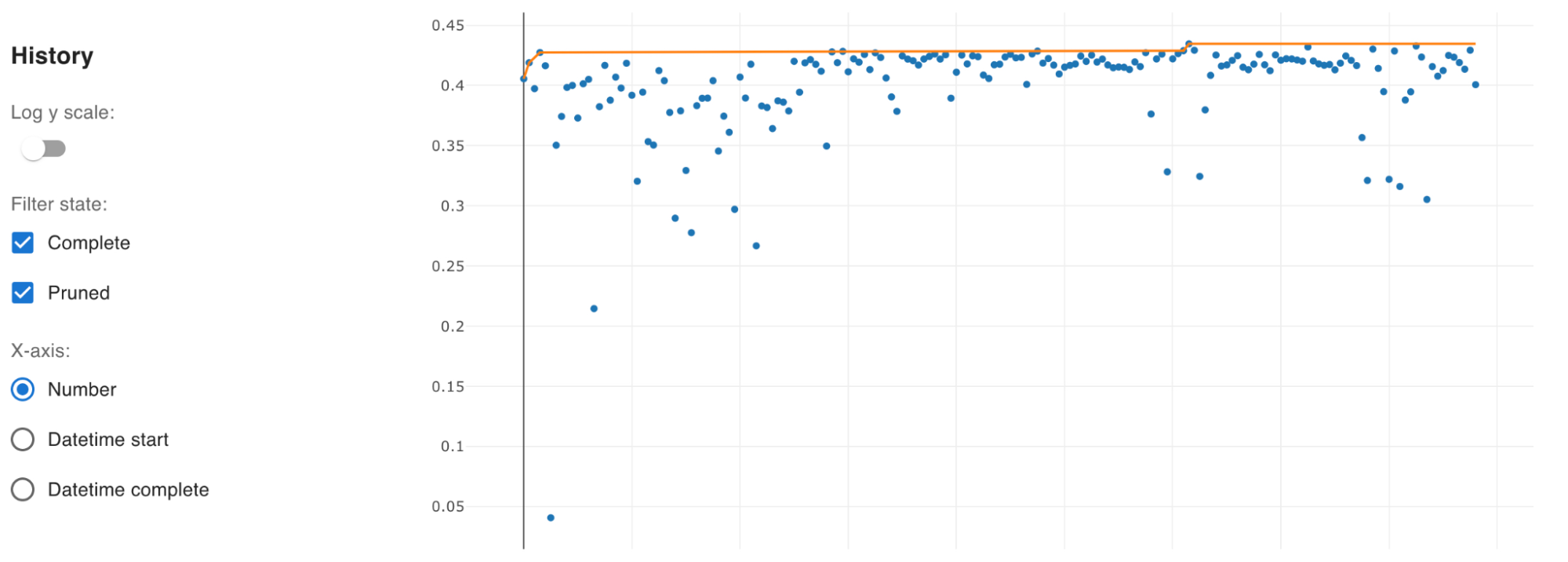
選択されたハイパーパラメータを用いて、画像サイズやモデルを大きくしたりパイプラインの他の部分を改善したりしても学習が安定して進んでいたため、最終的な提出にもこのハイパーパラメータを用いました。このハイパーパラメータ自体が他チームのスコアとの直接的な差別化要因になっていたかは未検証ですが、繊細なハイパーパラメータを自動で探索して他の検証に多くの時間を割くことができたのは、勝利につながった大きな要因であったと考えています。
Bounding box mix augmentation
この節では、学習時にランダムに異なる種類のbounding boxを選んで入力画像とするbouding box mix augmentationについて説明します。この手法を考案することにより、我々のチームは大きく精度を改善することができました。
このコンペの参加者の多くは、与えられた画像をmodelにそのまま入力するのではなく、画像のうち個体の体全体(fullbody)や背びれ(dorsal-fin, backfin)の部分を物体検出のモデルで検出したものを使用していました。
Jan Bre氏によってコンペのフォーラムにfullbody、 backfinのannotationおよび学習済み物体検出モデルによる予測bounding boxが公開されていました。この他、phalanx氏によってdeticによるbounding boxが公開されていました。我々のチームを含め、多くのチームがこれらのdatasetを使用しており、下図のbounding boxの部分を入力画像としていました。

このコンペではこのような複数種類のbounding boxをどのように学習に使用していくかが重要なポイントの一つでした。Jan Bre氏のdatasetをそのまま活用しているチームの他にも、annotationを使って自前の物体検出モデルを作っているチームも多くありました。我々のチームもその一つで、我々は用意されたannotationデータをyolov5で学習しました。
我々のチームが使用したbounding boxはJan Bre氏のfullbody、 backfinに加えてyolov5で独自に学習したfullbody_charm、backfin_charmとdetic(phalanx)の5種類です。また、bounding boxでcropせずに生の画像を一定の割合で学習に使うことでも精度の改善をすることができました。
各データに対して各bounding boxが割り当てられる確率はメンバーそれぞれのパイプラインで異なるものを使っており、以下のようなものでした
- パイプライン1(阿部)fullbody:fullbody_charm:backfin:backfin_charm:detic:none=0.60:0.15:0.15:0:0.05:0.05
- パイプライン2(山口)fullbody:fullbody_charm:backfin:backfin_charm:detic:none=0.60:0.20:0.05:0.05:0.05:0.05
単一の種類のbboxを使う場合にはfullbody_charmを使うよりもJan Bre氏のfullbodyを使った方がスコアが高くなることが実験によって確かめられていたので、fullbodyの割合を高めに設定してあります。どちらのパイプラインでもこのbounding box mix augmentationにより、手元で計算したvalidation scoreで0.01程度の改善を確認できました。これはprivate LBの1位と4位のスコア差に相当するため、大きな勝因の1つになったと考えられます。
また、推論時にはbackfin等は用いず、fullbodyで推論した結果とfullbody_charmで推論した結果を平均するTTA(test time augmentation)を行いました。このTTAにより各シングルモデルでは0.001程度のスコアの改善がありました。
感想(阿部)
チームを組んでいただいた山口さんはコンペ経験が豊富で、モデル作成能力などはもちろんですが特に終盤に方針を迷った際なども非常に頼りになりました。最後まで一緒に戦っていただきありがとうございました。
Kaggle初参加でしたが、このような厳しいコンペで優勝という成績を収めることができて非常に驚いたとともに光栄に思います。Kaggleに参加する前は、上位のプレイヤーたちは自分が知らないようなテクニックや思いつきもしないような発想で好成績を収めているのだと思っていました。もちろんこれまでのコンペ参加による知見や経験がショートカットにつながる場面も多いとは思いますが、地道なアイディアと検証の積み重ねで今回のような好成績を取れることが分かったことが一番の収穫でした。また、過去のコンペでの上位解法がオープンに公開されており、論文では強調されないような精度を出すためのテクニックをたくさん学ぶことができました。本ブログもそういった意味で今後、誰かの助けになれば嬉しいです。
また、計算機環境の使用を許可し今回のような経験を積ませていただいた会社にも感謝いたします。
感想(山口)
kaggleのコンペ初参加の阿部さんとの参加でしたが、それなりにコンペ参加経験のある自分と初参加ならではの発想力を持つ阿部さんとお互いに足りない部分を上手く補い合うことができ、非常に良いチームワークを発揮できました。今回のコンペはタスクがmetric learningであることもあり、他のコンペに比べてもハイパーパラメータやパイプラインのチューニングがかなりシビアだったように感じます。実際上位解法では十人十色のbackboneを使用しており、経験だけで最適なセットアップをすぐに引き当てることは難しいものでした。そのような条件下でも上手く分担することで効率的に実験を回すことができたことが優勝という結果に繋がりました。また、タスクの難しさに加えて、今回のコンペはkaggle世界ランクtop10のうち過半数が参加しているなど、非常に参加者のレベルが高いコンペでした。そのせいかコンペ終了一週間を切ってからは上位チームが凄まじいスピードでスコアを上げ、金メダルボーダーが毎日大きく上がっていく激しいものでした。終了間際には激しく順位が変動するリーダーボードを眺めて胃を痛める日々でしたが、最終的にはこのような結果に終わることができて本当に嬉しく思います。自分にとってはkaggleでは初めての優勝でしたが、勝ったことで改めて感じたことは「魔法はない」ということです。kaggleで良い成績を収めるためには何か誰も知らないようなすごいアイデアを思いつく必要があるのではないかと思ってしまいがちですが(そういうコンペもあるとは思いますが)、やはり重要なのは単純で誰でも思いつきそうなことを地道に正確に積み重ねていくことなんだと実感しました。とはいえ、このコンペでも自分が思いついたこと、やりたかったことを全てやり切れたわけではありません。実際、pseudo labelingをさらに繰り返せばさらにスコアを上げることができたのではないかと思います。今後はやりたかったことは全て試せた、という状況に終われることを目指してさらに色々なコンペに出ていこうと考えています。
また、会社のスパコン(MN-2)を利用することで多くの実験をこなすことができ、結果的に勝利に繋がりました。ありがとうございました。
10th Place Solution
この節では、10位に入賞した@Yiemon773による解法を説明します。
特に、上述の1st place solutionはじめ他の参加者の解法と差異がありそうな部分について記述します。
Model
まず、
- 1. 各個体の体全体をcropしたdataset
- 2. 各個体の背びれ付近をcropしたdataset
- 一部の生物種には存在しない
をYOLOV5 / DeticなどのDetectorを用いて作成しました。
その際、Jan Bre氏のfullbody, backfinのアノテーションを活用させていただきました。
それぞれのdatasetについて学習させたあと、
- 背びれが存在する生物種については、1, 2 のembeddingをconcatしてkNN
- 背びれが存在しない、見つけられない生物種については、1のembeddingのみを用いてkNN
を行いました。この際kNNにはFaissを利用し、近傍探索の時間効率化を図りました。
モデルのアーキテクチャ部分の工夫としては、backboneのconv-block群で出力されるfeature mapをそれぞれ抜き出して、様々なscaleの特徴を活用することにしました。実際これによっても精度は向上しました。
最終的に、backboneとして
- efficientnetv2_m
- efficientnetv2_l
- convnext_base
- convnext_large
を使用したモデル群をensembleしました。
今回私のパイプラインにおいて単体で最も精度が高かったのはEfficientnetV2ベースのモデルでしたが、どのbackboneが最善だったかは上位参加者の中でも異なっていたようで、学習パラメータ等の細かい調整による部分が大きかったのかもしれません。
Augmentation(Manifold Mixup)
画像コンペにおいては、mixupやcutmixなどを用いたaugmentationが有効である場合が多いですが、今回は直接入力画像同士でmixupするとうまく精度が上がりませんでした。
ArcFaceを用いて学習させることで、同一個体内ではembeddingの分散が小さくなるように学習が進むことが期待されていたので、個体間のembeddingを滑らかにつなぐような学習データをaugmentationによって作ることができれば、精度向上に寄与するのではないかと考えました。
そこで、embedding空間におけるmixup(Manifold Mixup: http://proceedings.mlr.press/v97/verma19a/verma19a.pdf)を実装したところ、うまく精度向上させることが出来ました。
Mixupした際はラベルもmixされsoft labelとなりますが、それにも対応できるようArcFaceの実装も修正しました。
Loss
個体を予測するHeadに加えて生物種も予測させるようにHeadを追加し、multi-taskなLossを設計し学習させることで精度が向上しました。
具体的には、下記の3種類のLoss関数を導入しています。
- ArcFace Loss:個体IDを学習するためのloss関数
- Focal Loss:個体IDを学習するための別のloss関数
- Cross Entropy Loss:Species を学習するためのloss関数
Progressive Dynamic Margins
他の参加者同様、私の解法でもDynamic Margin ArcFaceを用いましたが、マージンを大きく設定すると学習がうまく進まないケースがあったため、学習序盤はエポックに応じた係数(< 1)をマージンに掛け、その後全体的にマージンを徐々に大きくしていく学習戦略をとることで、精度向上させることが出来ました。
感想(山川)
本コンペは、データセット・モデル・損失関数など、多岐に渡って工夫のしどころが多く、各項目についてきちんと取り組めば精度を向上させることができたので、取り組んでいて非常に勉強になり面白かったです。
また、kaggle ranking上位のユーザーも多く参加しており、Leaderboardの競争が苛烈で終盤のプレッシャーも大きかったですが、同時に非常に良い刺激をもらうことができました。
終了後公開された上位参加者の解法から学ぶところも多かったため、今後の研究開発にうまく活かしていきたいと考えています。



