Blog
Preferred Networks’ subsidiary Preferred Elements has developed PLaMo-100B, a 100-billion parameter Japanese LLM trained from scratch, and released a trial version of PLaMo as a beta version in August.
Today, PLaMo Prime, the flagship model, has been released.
The alignment team in charge of post-training of PLaMo worked on improving the performance of the following items, which were determined to be in particularly high demand for commercial release.
- Extending context length
- RAG use case performance improvement
- Translation Usability Improvement
Extending context length
The most clear improvement of PLaMo Prime is supporting four times longer context length 16k than the previous PLaMo β supporting 4k. With this context length, we can feed the main text of PLaMo-100B arXiv paper or Ten Nights of Dreams by Natsume Sōseki as a single prompt. Thanks to this new feature, PLaMo Prime can be used in more diverse situations, for example,
- Long context translation: Translate some manual, research paper, or novel written in English into a Japanese summary or translation.
- Question answering over multiple documents: We can ask PLaMo Prime to answer a question regarding multiple documents simultaneously.
- Multi-turn role-play: more memorably generate responses referring to the past chat history.
We also share the benchmark on context length compared with the previous PLaMo β. Needle In A Haystack is a common retrieval benchmark to find some target text, “needle”, in a long input token sequence, “haystack”. PLaMo β cannot find needles accurately if the context length is longer than 4k (the top of Figure 1). On the other hand, PLaMo Prime can find needles in four times longer inputs (the bottom of Figure 1). Note that the white cells in the figure represent that our evaluation LLM, GPT-3.5-Turbo, did not generate an appropriate response.
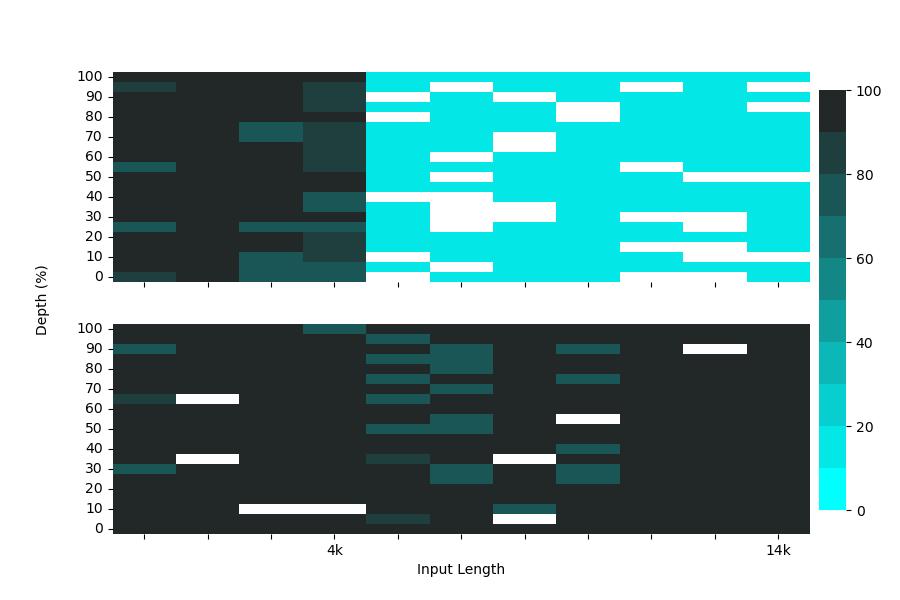
Figure1. Evaluation results of Needle In A Haystack. Top: PLaMo β. Bottom: PLaMo Prime. The x-axis represents the input token length the y-axis represents the needle’s depth, and each cell represents the accuracy of finding needles. The darker color indicates better accuracy.
For more natural language experiments, we also conduct sub-tasks in LongBench covering single-long document question answering, multiple documents question answering, and summarization of long texts. The evaluation results are as follows:
| Dataset | PLaMo β | PLaMo Prime |
| narrativeqa | 18.96 | 29.48 |
| qasper | 31.35 | 38.65 |
| multifieldqa | 39.19 | 49.47 |
| hotpotqa | 43.07 | 57.98 |
| 2wikimqa | 37.30 | 51.41 |
| musique | 17.20 | 40.04 |
| qmsum | 21.36 | 23.13 |
| triviaqa | 87.27 | 88.43 |
| passage count | 4.50 | 5.00 |
| passage retrieval | 16.50 | 29.50 |
As we can see, PLaMo Prime outperform PLaMo β for all tasks. More technical details are explained in another tech blog written in Japanese.
RAG use case performance improvement
Large Language Models (LLMs) demonstrate remarkable capabilities in knowledge-intensive tasks, but face critical limitations: their knowledge is frozen at training time, and they tend to hallucinate when relying solely on their training data. Retrieval-Augmented Generation (RAG) has emerged as a promising solution to bridge this gap between static model knowledge and up-to-date, reliable information by dynamically incorporating knowledge retrieved from external sources at inference time. This approach allows for the generation of grounded answers using up-to-date data, while also enabling the use of private or sensitive information that cannot be included in public training datasets.
RAG pipelines consist of two key components: a “Retriever” that identifies relevant information from knowledge bases, and a “Generator” (the LLM) that synthesizes responses from this information. Unlike traditional Q&A systems, RAG operates in a setting where retrieved contexts are often imperfect and may be fragmented, partially relevant to the query (if at all), or missing crucial details. This imperfection stems from RAG’s reliance on approximate search methods (keyword-based, semantic, or hybrid) to fetch top-k matches, which are then prioritized and reordered through ranking heuristics. Consequently, the LLM must skillfully navigate unstructured text fragments, separating signal from noise to construct accurate and coherent responses.
To compare the RAG performance of PLaMo, we select a subset of datasets from the ChatRAG-Bench and RAGBench that cover a range of Technical QA tasks with varying answer sizes, context lengths and sources.
| Dataset | PLaMo β | PLaMo Prime | % Improvement |
| DoQA | 20.41 | 25.49 | 24.89 |
| SQA | 40.07 | 58.57 | 46.17 |
| CovidQA-RAG | 27.60 | 33.35 | 20.83 |
| DelucionQA | 40.61 | 46.47 | 14.43 |
| EManual | 39.44 | 44.62 | 13.13 |
| TechQA | 8.97 | 38.22 | 326.09 |
| Mean | 29.52 | 41.12 | 39.30 |
PLaMo Prime consistently improves over PLaMo β across all tested datasets, with particularly notable gains in SQA and TechQA. The TechQA dataset, which comprises specific technical questions answered using extensive technical manuals, presents unique challenges due to its lengthy queries and responses. Notably, over 75% of TechQA queries exceed the 4k context length limit that constrained PLaMo β. Through the enhanced long-context capabilities detailed in “Extending context length”, the new model successfully handles these extended contexts, enabling comprehensive responses to complex technical queries.
Translation Usability Improvement
One of the characteristics of PLaMo is that it has a large amount of Japanese and English text data in its training data, and translating between English and Japanese is one of its strong tasks.
In order to improve the usability of PLaMo for translation purposes, we worked on improving the instruction-following performance so that it works as intended even in the following use cases by adding training data. (Technical details are introduced in the dataset section of the context length extension blog.)
- To enable translation with a long context input.
- To enable the translation to continue appropriately without inputting instructions each time for multi-turn translation.
Thanks to the first improvement, you can input a long paragraph of text. For instance, the amount of text found in the context length extension blog posts can be translated all at once.
{{Paste all the blog contents here}}
-----
Translate the previous Japanese sentences into English, without using extra words in your response.
Regarding the second improvement, you can interactively ask the PLaMo to translate a text in the following way:
[User]
Please translate all the sentences that I will input into Japanese, without using any extra words in your response.
{{English sentence 1}}
[PLaMo]
{{Japanese sentence 1}}
[User]
{{English sentence 2}}
[PLaMo]
{{Japanese sentence 2}}
…
The example below shows the actual translation of PFN’s Products page, where even after the User’s second turn, the translation continues appropriately even though you only paste in English without inputting translation instructions.

Conclusion
In this blog post, we introduced performance improvements of long context, RAG, and translation for releasing the commercial version, PLaMo Prime. We plan to continue improving PLaMo’s performance in the future.
Of course, PLaMo Prime can be used for various purposes besides the above. We introduce and add usage examples regularly on the PLaMo LLM X account and the pfnet-research/plamo-examples repository on github.
Follow the link below to use PLaMo!
Related links
- PLaMo-100B paper
- PLaMo-100B development blog
- PLaMo-100B base model on huggingface
Area
Tag