Blog
本記事は、2023年度PFN夏季インターンシップで勤務された稲葉達郎さんによる寄稿です。
こんにちは,2023年の PFN 夏季インターンシップに参加した京都大学修士1年の稲葉達郎です.大学では自動音楽生成や自然言語処理に関する研究をしています.
今回のインターンシップでは「中間表現を利用した段階的推論能力の知識蒸留」というテーマで研究を行いました.大規模な言語モデルが持つ段階的な思考能力(Chain-of-Thought)を知識蒸留により小さな言語モデルに引き継ぐことを目的としています.二種類の既存手法を再現し,それらを組み合わせることで性能向上を目指しました.
はじめに
昨今,大規模言語モデル(LLM)がその高い性能や汎用性により注目を集めています.また,高い能力を持つ LLM が,段階的な思考をテキスト生成を通して擬似的に行えることがあります.この手法は Chain-of-Thought (CoT) プロンプティング [1] と呼ばれ,様々な推論タスクにおいてその有効性が確認されています.以下に例を示します(図1).
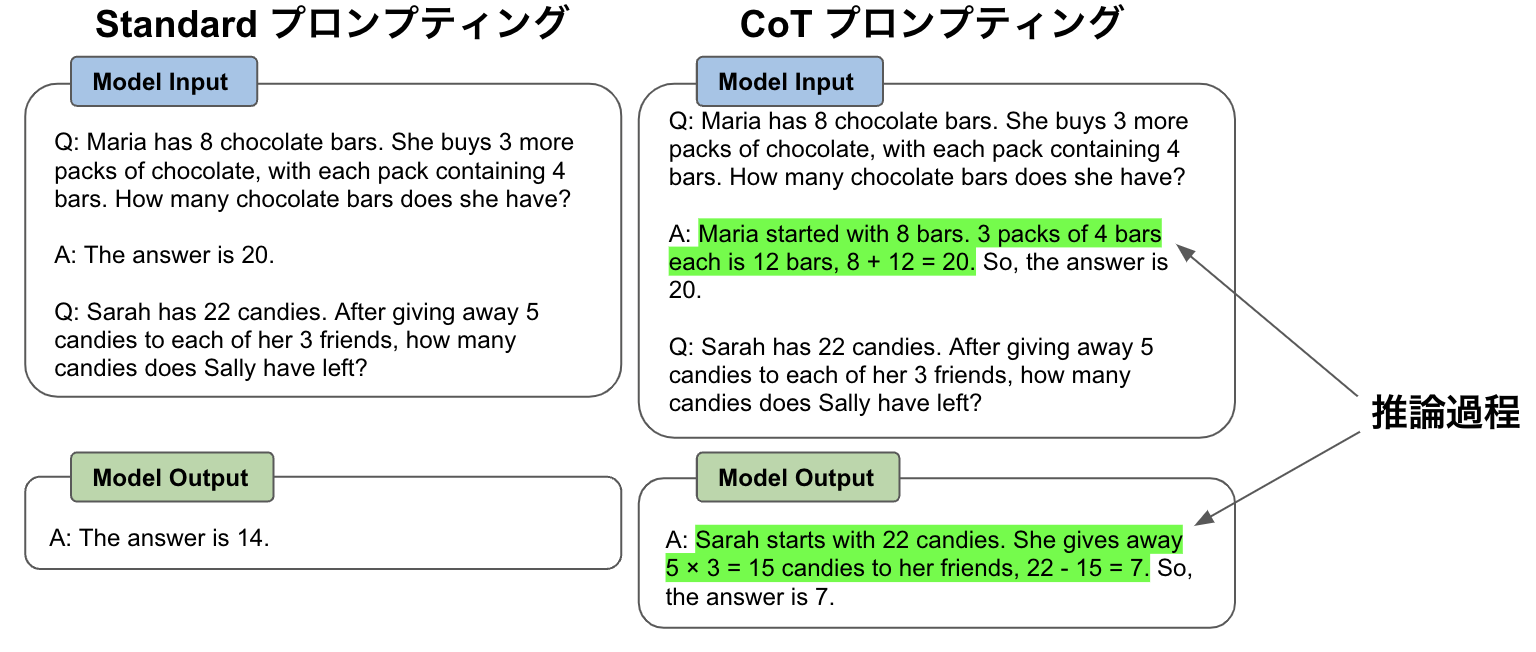 図1: Chain-of-Thought プロンプティング の例
図1: Chain-of-Thought プロンプティング の例
左では例題として問題文と回答のみを言語モデルに与えているため,実際に解きたい問題についても回答のみが生成されます.それに対し右の CoT プロンプティングでは,例題として問題文と段階的な推論の過程(推論過程)付きの回答を与えているため,実際に解きたい問題についても推論過程付きで回答が生成されます.この推論過程が最終的な回答に辿り着くまでの段階的な思考の役割を果たし,正しい回答を導くことに成功しています.
ただし,段階的な思考を模倣するための CoT プロンプティングは流暢なテキストを生成する必要があり,現在のところ十分大きいモデルでのみ性能向上が確認されています.また,LLM はその膨大なパラメータ数により推論コストがとても高く,リソースが限られる状況では利用することが困難です.
そこで,今回のインターンでは知識蒸留を利用して,LLM の段階的思考能力を小さい言語モデルに引き継ぐことを目的とした研究を行いました.
既存手法
ここでは,知識蒸留について簡単に説明し,その後,知識蒸留に関連する2つの関連研究について紹介します.
前提知識:知識蒸留
知識蒸留とは教師モデル(一般には大きいモデル)が持つ知識を生徒モデル(一般にはより小さいモデル)へ引き継がせる手法です.深層学習における知識蒸留には大きく分けて出力を利用した知識蒸留 [2] と中間表現を利用した知識蒸留 [3,4] の二種類が存在します.図2にそれぞれの例を示します.

図2: (左)出力を利用した知識蒸留,(右)中間表現を利用した知識蒸留
左の出力を利用した知識蒸留では,教師モデルが出力するソフトラベル(確率分布)を生徒モデルが出力するように学習を行います.ワンホットな正解ラベルの代わりに教師モデルのソフトラベルで学習することで,正解だけでなく,惜しい間違い方についても一緒に学習することができます.[2]では確率分布を利用した蒸留について書かれていますが,言語モデルを用いた蒸留の際には,教師モデルが出力するテキスト自体を利用することもあります.
右の中間表現を利用した知識蒸留では教師モデルの中間表現で生徒モデルの中間表現を学習します.ロスの取り方には L2 ロス[4]や対照ロス[3]などがあります.
関連研究①:正解と推論過程のマルチタスク学習による知識蒸留 [5]
この研究では教師となる LLM に回答へ至るまでの推論過程を生成させ,そのテキストデータを用いて知識蒸留を行っています.図3に推論過程の生成から生徒モデルの fine-tuning までの全体図を示します.
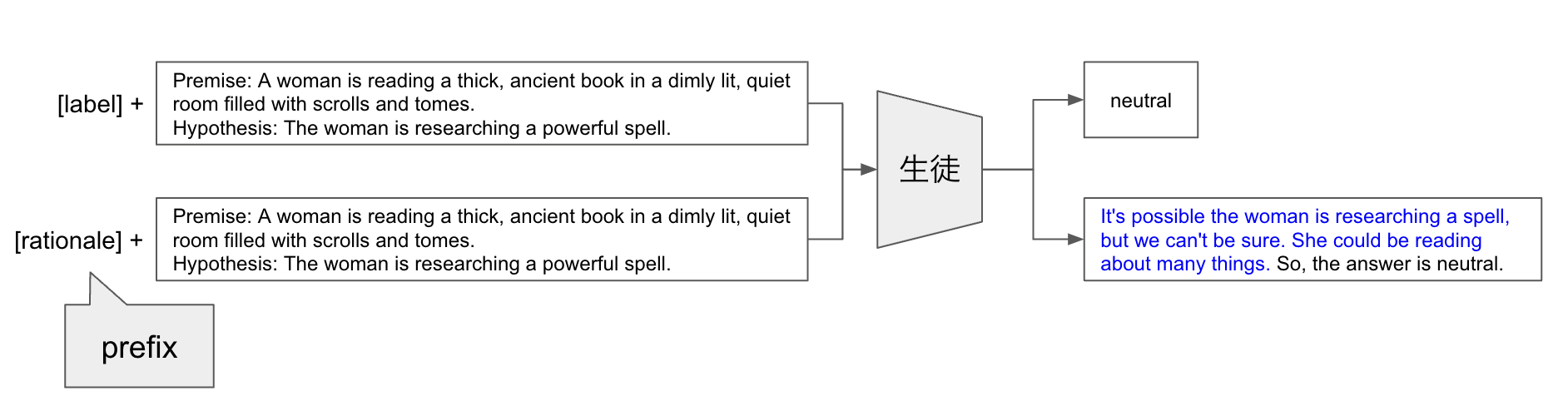 図3: Distilling step-by-step 全体図
図3: Distilling step-by-step 全体図
まずはじめに教師モデルに CoT プロンプティングを適用し,質問応答タスクの推論過程(図3の青文字)を生成します.生徒モデルを fine-tuning する際には prefix を利用した学習 (*1) [6] を採用しています.これは”prefix” と呼ばれる特別な先頭の入力トークンを与えてマルチタスクを解く方法です.prefix が “label” というトークンの時にはモデルが正解ラベル(ここでは”neutral”)を生成するように学習し,prefix が “rationale” (*2) の時にはモデルが推論過程を生成するように学習します.推論の際には prefix に正解ラベルを選択し推論過程を生成することなく正解のラベルを直接生成します.論文では,推論過程の生成をする学習がラベル予測精度の向上に繋がることが実験的に示されています.
また,LLM の出力を真似るのであれば,上記のようにマルチタスクに分割せず,[推論過程+ラベル]を連続して生成するシングルタスクの形で学習する方法が直感的です(図4)[7,8].
 図4: 推論過程とラベルをまとめて生成するシングルタスク
図4: 推論過程とラベルをまとめて生成するシングルタスク
[5]ではこれらの手法との比較も実験的に行っています.結果としては,シングルタスク学習では一般的な fine-tuning よりも性能が劣化することがあり,マルチタスク学習の方が有効であると示しています(詳しくは論文のTable2等を参照).
*1 prefix を用いた学習: 問題文の前にタスクごとに特定のトークンを追加することでマルチタスク学習を行う
*2 rationale: 論理的根拠≒推論過程
関連研究②: 対照学習による言語モデルの知識蒸留 [9]
この研究では,言語モデルの知識蒸留を行う際に中間表現の対照学習(Contrastive Learning)を使用しています.この論文までは言語モデルの中間表現を蒸留する際には L2 ロスが一般に使用されていました[10,11].また,L2 ロスでは次元ごとに2乗誤差を計算しているため,次元間の相関を考慮することはできません.
しかし,Transformer の中間表現は各次元が独立に意味を持つのではなく,複数次元にわたる構造的な情報が含まれています.そこで,著者らは対照ロスとして次元間の構造も考慮できる InfoNCE ロス [12] を用いて対照学習による知識蒸留を行いました.その結果,往来の L2 ロスを使用する手法よりも性能が向上が確認され,言語モデルの中間表現を用いた蒸留を行う際には InfoNCE ロスを用いた対照学習がより有効であることが示されています.
提案手法の前に
関連研究①を読んだ時にとても面白いと思った一方で,推論過程を生成するように学習する方法は生徒モデルにとって難しすぎる設定ではないかとも思いました.そもそも CoT を行うことで性能が上がるのは十分にサイズの大きいモデルのみであり,小さなモデルにそれを無理やり模倣させても得られるゲインはあまりないように感じます.
そこで,ここに関連研究②の話を組み合わせ,推論過程に相当する中間表現で対照学習を行うことを試しました.対照学習では正しい表現(正例)を近づけて間違っている表現(負例)を遠ざけます.すなわち,正しい表現に完全に一致させる必要はなく,流暢なテキストを長々と出力する必要もありません.これは,推論過程を出力する学習に比較して容易な設定であり,より蒸留がうまくいくのではないか,と考えました.そこで,この直感を確かめるために以下の実装・実験を行いました.
試した手法: 関連研究① + 関連研究②
本手法では,生徒モデルの学習方法として,関連研究①の prefix によるマルチタスク学習を踏襲します.そして,prefix が rationale の時には推論過程を出力するのではなく,推論過程相当の中間表現で関連研究②を参考にした対照学習を行います.
まず,CoT プロンプティング を利用して教師モデルにより推論過程を生成します(図5).
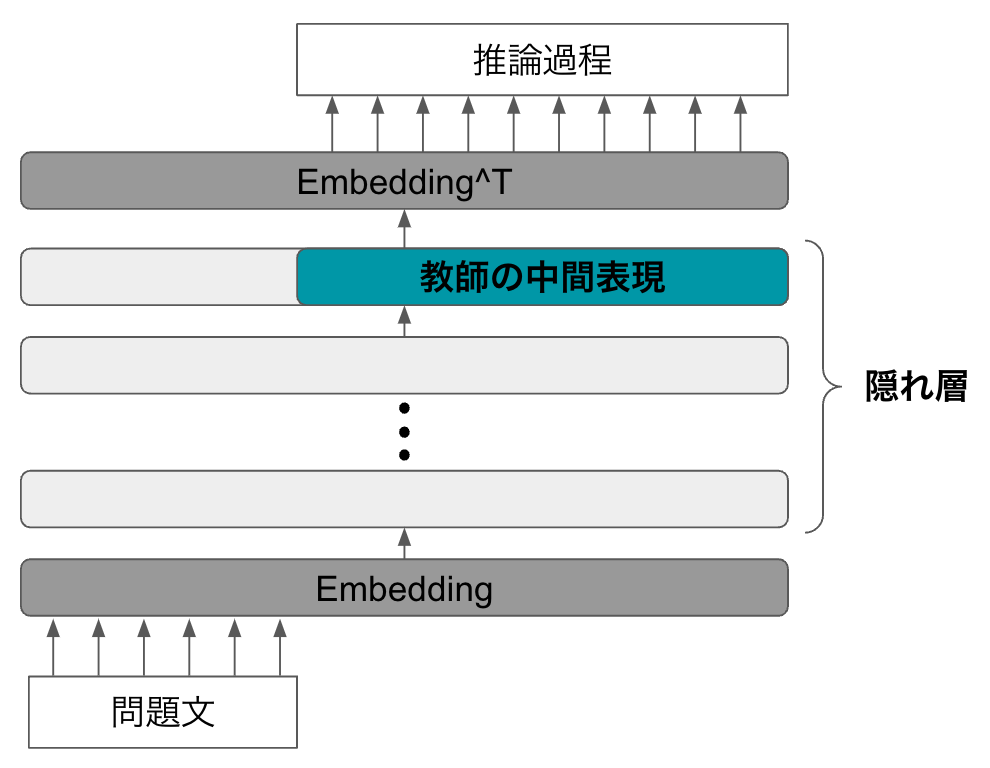 図5: 教師モデルによる推論過程相当の中間表現の生成
図5: 教師モデルによる推論過程相当の中間表現の生成
この時の最終層のベクトル表現(図5の青緑色部分)を教師モデルの中間表現として保存します.この中間表現が推論過程相当の情報を含んでいることを期待しています.中間表現の保存が終わったら,次に生徒モデルの学習を行います(図6).
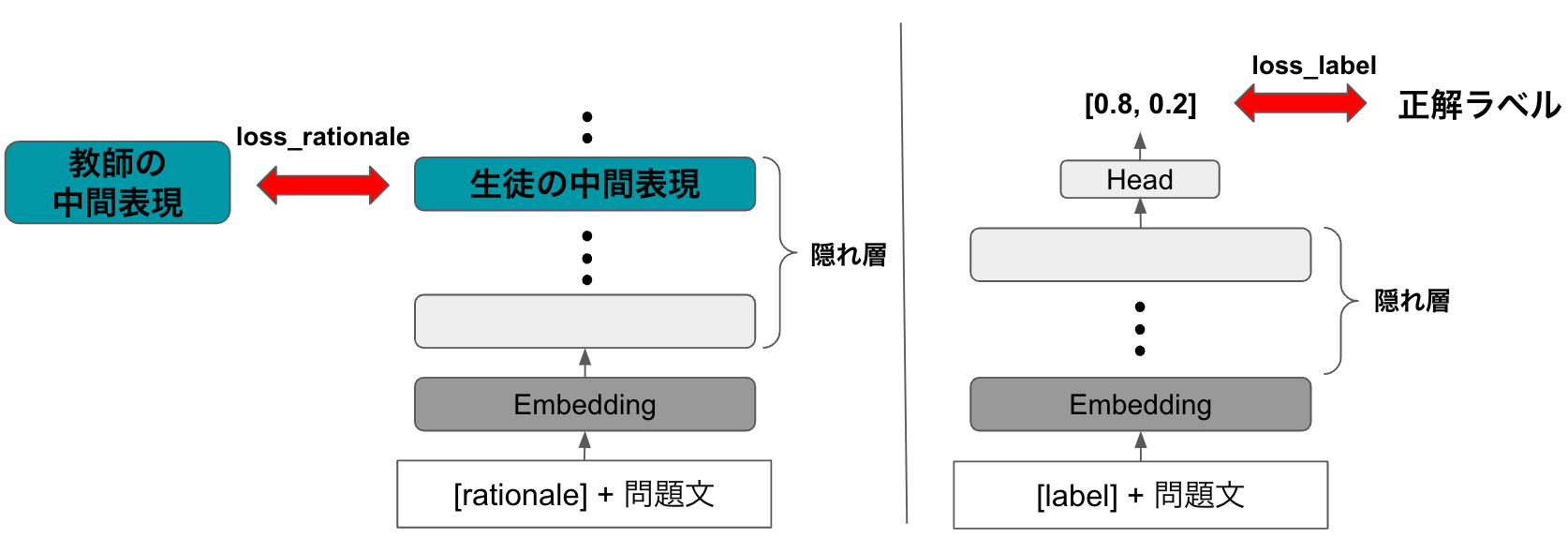 図6: 生徒モデルの学習
図6: 生徒モデルの学習
prefixがlabelの時には関連研究①と同様に正解ラベルを生成するように学習します.一方で prefix が rationale の時には,生徒モデルの中間表現が先ほど保存した教師モデルの中間表現に近づくように対照学習を行います.また,調整可能なハイパーパラメータとして以下の4つを用意しました.
- crd_weight: ロスの比率(全体のロス \( = \text{loss_label} \times (1 – \text{crd_weight } ) + \text{loss_rationale } \times {\text crd\_weight } \) )
- crd_layer: 生徒モデルのどの中間表現に対照学習を行うか(例: 2なら後ろから2層目)
- nce_k: 対照学習時の負例の数
- learning rate: 学習率
対照学習をする際に毎回負例の中間表現を計算すると計算コストがだいたい (\(1 + \text{nce_k}\)) 倍かかってしまいます.そこで,関連研究②でも使用されていた Memory Bank [13]を利用しました. Memory Bank には全ての学習データ分の中間表現を保存しておき,各データが正例として選ばれた時にのみ Memory Bank 内の中間表現が更新されます.これにより,計算コストを通常の学習とほとんど同じにまで削減することができました.
実験
本手法を用いて二種類の実験を行いました.まず,実装がより簡単な Encoder 型モデルを生徒モデルとして実験し,その後,関連研究①に合わせて生徒モデルを Encoder-Decoder 型モデルとして実験を行いました.
実験①: Encoder 型モデルへの蒸留
本手法は関連研究①のように推論過程をテキストとして扱う必要がないため,テキストを生成できない Encoder 型モデルに対しても推論過程相当の中間表現を蒸留をすることができます.そこで教師モデルとして GPT-NeoX-20B [14] を,生徒モデルを Encoder 型モデルの RoBERTa-base (125M) を使用しました.
推論過程相当の中間表現を蒸留することが効果的であるかを示すためには GPT-NeoX-20B と同じサイズの Encoder 型モデルを教師とした場合と比較するべきです.しかし,公開されている 20B の Encoder 型モデルを見つけることができず,事前学習からやる余裕はありませんでした.なので,この実験では RoBERTa-base を正解ラベルのみで Fine-tuning したものをベースラインとして比較を行いました.
データセットには GLUE に含まれる SST-2 [15] という映画レビューの感情分類タスクを使用しました.例1に SST-2 の問題例を,例2にGPT-NeoX-20B で作成した推論過程の例を示します.
例1: “contains no wit, only labored gags” 例2: “contains no wit emphasizes the absence of a desirable quality. So the answer is Negative.”
また,GPT-NeoX-20B で生成推論過程が間違った答えを導くことも多々ありました(例3).
例3: “Q: Explain as finally made a movie that is n't just offensive is Positive or Negative. A: . is offensive means offensive. So the answer is Negative.”
そのため,生成した推論過程が正しい文章かどうかでフィルタリングを行った上で中間表現の知識蒸留を行いました.その結果を表1に示します.
表1: SST-2 の結果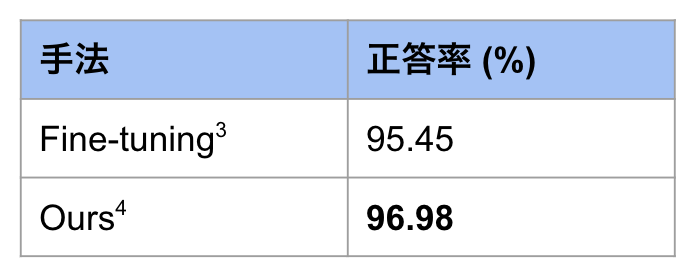 *3 fine-tuning の結果は学習率のみハイパーパラメータ調整した際に一番よかった結果を記しています
*3 fine-tuning の結果は学習率のみハイパーパラメータ調整した際に一番よかった結果を記しています
*4 Ours の結果は4つのハイパーパラメータを調整した際に一番よかった結果を表記しています(表3参照)
Fine-tuning と比較して約1.5%の精度向上を達成しています.また,ハイパーパラメータを変更する ablation study も行いました.表2にその結果を示します.
表2: SST-2 でのハイパーパラメータ調整結果(オレンジは他設定と異なる値)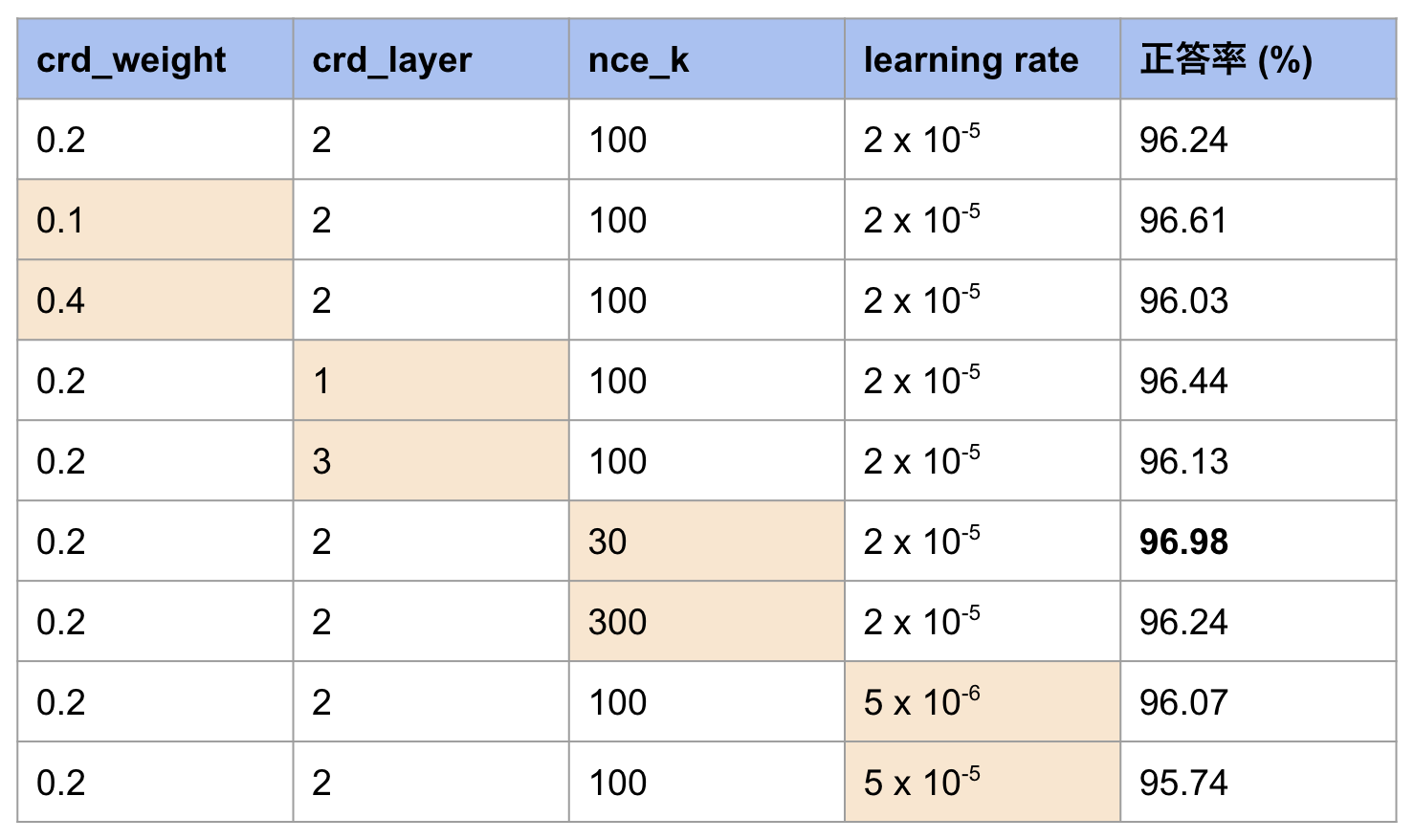
表1と表2を見て分かるようにどのハイパーパラメータを使用した場合でも fine-tuning より性能が向上しています.しかし,この実験における生徒モデルは Encoder 型なので,関連研究①の推論過程を生成する形で学習する場合との比較ができません.そこで関連研究①との比較をすることを目的に,以下の実験②を行いました.
実験②: Encoder-Decoder 型モデルへの蒸留
教師モデルとして GPT-NeoX-20B を,そして生徒モデルとしてテキスト生成が可能な T5-base (200M) [6]を使用しました.また,データセットは CommonsenseQA [16] という質問応答タスクを使用しました.例4に Commonsense QA の問題例を,例5に GPT-NeoX-20B で作成した推論過程の例を示します.
例4: “What do people use to absorb extra ink from a fountain pen? Answer Choices: (a) shirt pocket (b) calligrapher's hand (c) inkwell (d) desk drawer (e) blotter”
例5: “Blotters are specially designed to absorb excess ink and prevent smudging, especially when using fountain pens. So the answer is blotter.”
また,実験1と同様に生成した推論過程・中間表現のフィルタリングを行っています.ハイパーパラメータは,crd_weight=0.2, crd_layer=1, nce_k=30, lr=5e-5 を使用しました.また,T5 は Encoder-Decoder 型なので,Encoder へ蒸留する場合(Ours-enc)と Decoder へ蒸留する場合(Ours-dec)に分けて実験しました.表3に結果を示します.
表3: cqa の結果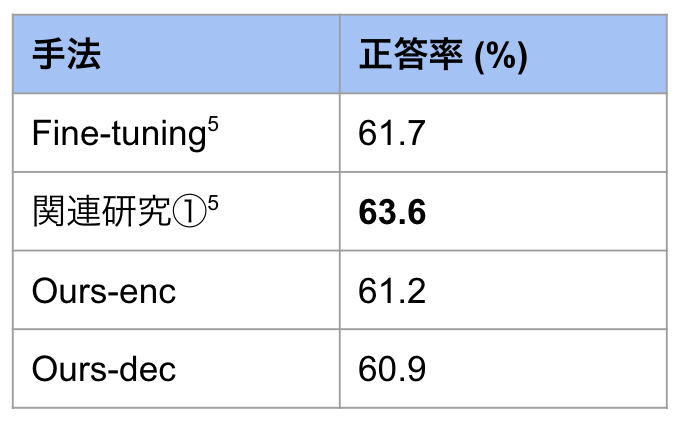 *5 fine-tuning と関連研究①の結果は論文中の数値ではなく,今回自分で再現した結果を表記しています.
*5 fine-tuning と関連研究①の結果は論文中の数値ではなく,今回自分で再現した結果を表記しています.
蒸留先が Encoder でも Decoder でも関連研究①どころか fine-tuning よりも低い結果になってしまいました.実験①と異なる結果になってしまった原因としては,CommonsenseQA は SST-2 に比較するとタスクの難化しており,GPT-NeoX-20B では十分に妥当な推論過程やその中間表現を作成できなかったことが一つ大きな原因だと思います.また,生徒モデルのアーキテクチャを変えたことに原因があった可能性もあります.
試したかった実験等
今回のインターンシップで時間があればもう少し試してみたかったことをまとめます.
他のデータセット・生徒モデル
SST-2 と CommonsenseQA 以外のタスクを使ったり,同一タスクで生徒モデルのアーキテクチャを変化させる実験も行いたかったです.様々な設定で比較することで実験①と②で相反する結果が出てしまった理由をもっと深く分析したかったです.
対照学習に関して
対照ロスを計算する際の負例を取り方をもう少し工夫できたのかなと思っています.今回の実験では,「同一問題に対する推論過程を生成しているときの教師の中間表現を正例とし,異なる問題に対する生徒の中間表現を負例とする」というとてもシンプルな手法を採用しました.しかし,もっと様々な負例の選択方法が可能だったなぁと思っています.例えば,異なる問題に対する推論過程を生成している時の教師の中間表現や,同一問題に対して間違った推論過程を生成している時の教師の中間表現などを負例とする方法等です.また,ソフトに遠ざける負例とハードに遠ざける負例を設定し,遠ざけ方にバリエーションを持たせる手法などを試してみたかったです.
対照学習をどこの中間表現で行うか
今回の実験では教師モデルの中間表現として最終層のベクトル表現を使用しました.Transformer では深い層が文の構造的な情報よりも意味的な情報を多く含んでいるという話 [17] を踏まえ,このような手法をとりましたが他の手法の方がうまくいった可能性も大いにあると思います.例えば,推論過程に含まれる段階的な思考の文構造を捉えるためには,最終層だけでは無く複数層利用した対照学習の方が適切だったかもしれません.これらの比較実験等を時間があればやってみたかったです.
教師モデルに関して
今回の実験では推論過程を生成する教師モデルとして GPT-NeoX-20B を使用しました.フィルタリングを施すことであまりにひどい推論過程を除外しましたが,それでも残った推論過程が全て完璧とは言えませんでした(例6).
例6: “Q: Explain we never feel anything for these characters is Positive or Negative. A: we never feel anything for these characters means we never feel anything for the characters. So the answer is Negative.”
フィルタリングを強めにかけてしまうとほとんどデータが残らなかったため弱めのフィルタリングで妥協しました.ですが,もっと大きく性能の高い言語モデルを使うことができれば,強めのフィルタリングをかけることで綺麗なデータを大量に生成出来たはずです.ちなみに,計算コスト的に出来なかった訳ではなく,20B より大きく蒸留に使用しても良いオープンソースの言語モデルが当初は無かったのが原因です.今であれば Falcon-180B [18] (2023/9/6 公開) などを使ってみたいなぁと思います.
まとめ
今回のインターンでは二つの関連研究の再現実装を行い,それらを組み合わせた知識蒸留を試しました.データセットに SST-2 を,生徒モデルに RoBERTa を用いた実験では単に fine-tuning するよりも性能を向上させることができました.その一方で,データセットに CommonsenseQA を,生徒モデルに T5 を用いた実験では単に fine-tuning するよりも性能が低下してしまいました.今後の課題としてはこの差が生まれてしまった原因を異なるタスクや生徒モデルのアーキテクチャで確かめることが挙げられます.また,教師モデルにより高性能なモデルを使って試してみたいです.
感想
当初思っていたより何倍も面白く楽しいインターンでした.研究を進めるにあたり,適宜相談に乗っていただき楽しく議論を深めることができました.メンターの小松さん,岡田さん,林さん,岡野原さん,手厚いサポートをありがとうございました.これからも頑張っていきます.
参考文献
[1] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models [Wei+, 22/1]
[2] Distilling the Knowledge in a Neural Network [Hinton+, 15]
[3] Contrastive Representation Distillation [Tian+, 19]
[4] FitNets: Hints for Thin Deep Nets [Romero+, 14]
[5] Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes [Hsieh+, 23/5]
[6] Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer [Raffel+, 19]
[7] Teaching Small Language Models to Reason [Magister+, 22]
[8] Large Language Models Are Reasoning Teachers [Ho+, 22]
[9] Contrastive Distillation on Intermediate Representations for Language Model Compression [Sun+, 20]
[10] Patient Knowledge Distillation for BERT Model Compression [Sun+, 19]
[11] TinyBERT: Distilling BERT for Natural Language Understanding [Jiao+, 20]
[12] Representation learning with contrastive predictive coding [Oord+, 18]
[13] Unsupervised Feature Learning via Nonparametric Instance-level Discrimination [Wu+, 18]
[14] GPT-NeoX-20B: An Open-Source Autoregressive Language Model [Black+, 22]
[15] Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank [Socher+, 13]
[16] CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge [Talmor+, 19]
[17] What Does BERT Learn about the Structure of Language? [Jawahar+, 19]
[18] Spread Your Wings: Falcon 180B is here [TII, 23]



