Blog
本記事は、2023年夏季インターンシッププログラムで勤務された大嶽匡俊さんによる寄稿です。
はじめに
2023年度夏季インターンに参加させていただいた、大嶽匡俊です。
大学では東京大学情報理工コンピュータ科学専攻の宮尾研究室に所属し自然言語について研究をしています。
今回のインターンでは、Large Language Models for Code (Code LLMs)と自然言語推論の関係や、LLMとソースコードの関係について調査しました。
背景
Code LLMとは
Code LLMとは、プログラムコードの生成や理解を目的とした言語モデルです。ここ数年盛んに開発されており、2021年にOpenAIからCodex[^1]、DeepMindからAlphaCode[^2]などが発表され、2022,3年にはCodeGen[^3]やStarCoder[^4]などの重みが公開されているモデルもいくつか出てきました。
モデルの構築方法は今のところ自然言語のLLMと殆ど同じで、コードのデータからどの程度学習しているかや、コードのデータでチューニングされたかどうかなど、何を目的として構成されたかで呼び方が決まっています。
コードのデータは量的には非常に豊富にあるため、簡単に構築を始められます。
The Stack[^5]やCodeSearchNet corpus[^6]等、GitHubにあるデータを収集する形で沢山のデータセットが公開されています。中でもThe Stackは6.4 TBほどであり、自然言語データと同量程度あると言っていいでしょう。こういった潤沢なデータのおかげで、Code LLMは自然言語以外のデータを扱う言語モデルとして先駆的な存在となっています。
LLMとCode LLM
Code LLMと一般的なLLMの境界線は曖昧です。CodeGen[^3]は訓練に使われたデータのうち半分以上が自然言語であり、StarCoder[^4]も11%の自然言語を含んでいます。一方、LLM側もソースコードからも学習しており、Llama(1) [^7]は4%程、rinnaの日英モデルも11%がソースコードです[^8]。
構築されている多くのLLMがコードからも学習している一方、LLMにコードのデータを入れる方がよいのかについて様々な議論があります。
Muennighoffら “Scaling Data-Constrained Language Models.”[^9]では、データの50%までをコードで埋めても全体的な自然言語処理性能はほとんど上昇も低下もしなかったが、50%を超えると自然言語タスクでは性能が急速に低下したことを報告しています。また、タスクごとで見ていくとWebNLG[^10]やbAbI[^11]で性能が向上したことから、コードで学習すると長距離の依存性(Long Term Dependencies)があるタスクでの性能向上を報告しています。
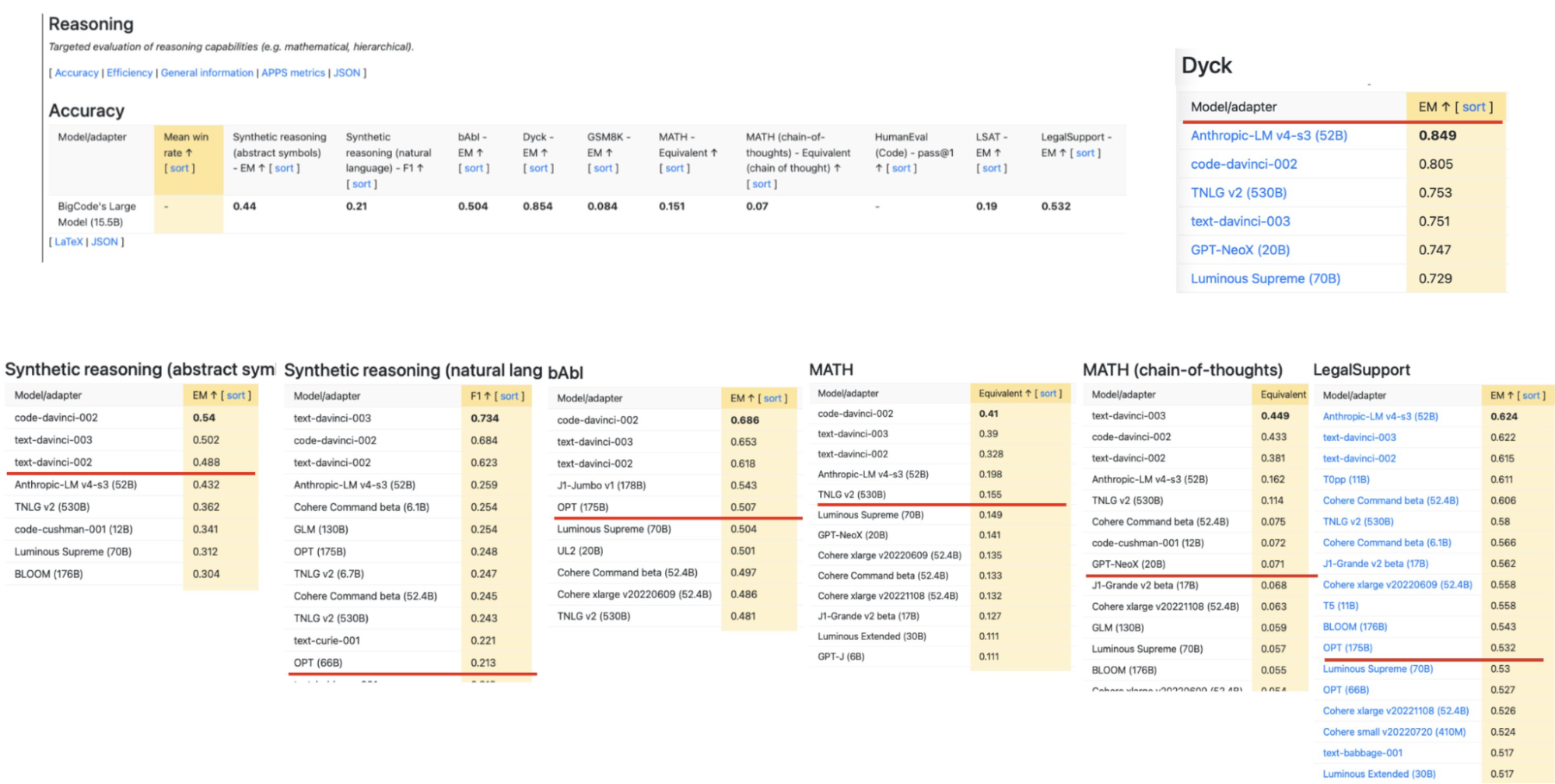
また、オープンソースのコードモデルであるStarCoder[^4]では、推論タスクでスコアが高かったことが報告されています。以下は、 [^12]推論タスクのStarCoderの評価値です[Holistic Evaluation of Language Models (HELM)](https://crfm.stanford.edu/helm/)が、他の大規模なモデルとcomparableであるとされています。(引用元) これは、プログラムに長距離依存性という性質があるからだと考えられます。
次の単語を予測するというタスクと違い、実際の世の中で解きたい問題は長距離依存性がある問題が多い様に感じます。その中で、プログラミング言語での学習はその能力を言語モデルに簡単な形で埋め込める可能性がある様に思います。
Code LLMの評価
Code LLMモデルは一般的に、関数名、関数の説明文、テストなどを与えられた上でモデルがコードの出力を吐き、そのコードが評価用のテストを通るかどうかで評価されています。データセットとしては一般的に、HumanEval [^13]が最も用いられており(引用数 991)、続いてMBPP [^14] (引用数 327)などが用いられています。以下、この記事では、HumanEvalを対象として、どのように評価が行われているか説明します。
HumanEvalでは、以下の様に入力として「関数名、引数、(型)、関数の説明、(入力の)テスト」を与えられます。以下は私が自作した例です。
“`
def odd_max(numbers: List[int]) -> int:
“”” Find the maximum odd number from the list
>>> odd_max([1,1,1,2,6,5])
5
>>> odd_max([6,6,6,3,6,6])
3
“””
“`
この入力を与えられたコードモデルがコードの出力を吐きます。初めの6行はモデルに与えられる入力です。
“`
def odd_max(numbers: List[int]) -> int:
“”” Find the maximum odd number from the list
>>> odd_max([1,1,1,2,6,5])
5
>>> odd_max([6,6,6,3,6,6])
3
“””
return max(filter(lambda x: x % 2!= 0, numbers))
“`
このコードが、以下のような3~10個程度の「評価用の」テストを全て通せるかどうかで評価されています。
“`
assert candidate([2, 4, 3]) == 3
assert candidate([1, 2]) == 1
assert candidate([1, 2, 4, 5, 6]) == 5
assert candidate([1, 2, 5, 5, 4, 4]) == 5
“`
CodeLLMの現状
HumanEval[^13]の正答率で今あるモデルを比べると、以下のようになります。(Code Llamaの*はUnnnatural Instruction[^15]で指示チューニングされた非公開モデル)
| Model | HumanEval | |
| GPT-4 | 67.0 | |
| GPT-3.5 | 48.1 | |
| チューニングモデル | Wizard Coder(34B) | 73.2 |
| チューニングモデル | Code Llama(34B) | 48.8(*62.2) |
| コードモデル | StarCoder(15B) | 33.6 |
| コードモデル | CodeGen-Mono(16B) | 29.3 |
| 言語モデル | Llama 2(70B) | 30.5 |
| 言語モデル | Llama 2(34B) | 22.6 |
GPT-4が67%という突出したスコアを出しています。Codegen[^3]やStarcoder[^4]などの重みが公開されているモデルは2割から4割程で大きく後れを取っていたのですが、2023年の8月にLlama2[^16]やStarcoder[^4]をチューニングして作成されたWizard[^17], Code Llama[^18]が50%,60%台のスコアを出し、CodeLLMにおいてはチューニングが注目されています。特に、WizardやCode Llamaによってチューニングの中でも指示チューニングがHumanEvalのスコアを伸ばす事が確認されており、指示チューニングとCode LLMの関係が気になるところです。
Code LLMの自然言語指示チューニング
CodeLLMが指示チューニングによってなぜスコアを大きく伸ばせるかが気になりました。我々はCodeLLMモデル自体に自然言語を通した受け答えが苦手であるという特徴があるのではないかと考え、自然言語でチューニングし自然言語で評価した場合どのような結果が出るのか確かめました。
先行研究
CodeLLMをコードデータで指示チューニングした論文で面白いものをいくつか紹介します。
WizardCoder[^17]
WizardCoderでは、Evol[^19]と呼ばれる指示チューニングのデータ拡張手法を用いて作成したデータでStarcoderやLlama2ベースのモデルを指示チューニングし、HumanEvalでのスコアを10ポイント以上上げGPT-4に匹敵するモデルを作成しました。
Evolでは、元となる指示データセットをGPT-4を用いて拡張します。元になるデータと「制約を加えて問題を難しくしろ」というようなプロンプトをGPT-4に与え、新しいデータを作成しています。WizardCoderではCode Alpacaデータセット(20k)[^20] [^21]を元になる指示データとし、78k程の新しく作成したデータができています。
CodeM[^22]
この論文では、Starcoderをある言語で指示チューニングした時他の言語の性能がどのように変わるかを明らかにしています。Python, JavaScript, TypeScript, C, C++, Java, Goの7つの言語でチューニングし、7つの言語のHumanEvalスコアを計測した結果、7(チューニング言語) * 7(評価言語)の組み合わせ全てのケースでスコアが向上しました。
以下はPythonでチューニングした時の結果です(CODEM-Python)。赤文字はスコアの増分を表しています。指示チューニングには9.6Kのデータセットが用いられました。。

実験
Starcoderを自然言語の指示データセットであるP3[^23]の一部を行いて指示チューニングし、HELMのbAbIデータを用いて論理推論の能力が上がっているか確認しました。
bAbI[^11]
HELMで用いられているbAbIデータは以下のような入力を与えられ、最後に「johnはどこにいるか?」と尋ねるタスクです。
“`
Daniel went back to the bathroom. Mary journeyed to the office. Sandra went back to the garden. Daniel moved to the garden. Daniel journeyed to the hallway. John moved to the garden. Sandra went back to the hallway. Mary went back to the bedroom. John journeyed to the office. John went to the bathroom.
“`
結果
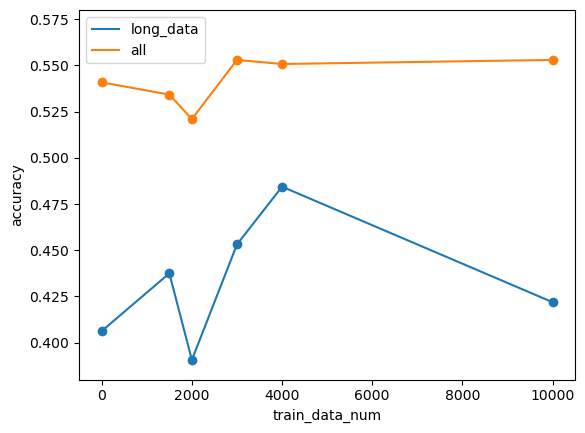
結果を以下の図に示します。long_textとは、入力の文章の長さが上位1/8のデータを用いた時の正答率です。x軸が0の時点が指示チューニングをしていない状態を表します。
指示チューニングによってスコアは上がりましたが、大きな変化はありませんでした。
先行研究
PAL: Program-aided Language Models[^23]
この研究では、few-shotの回答をコードと自然言語が混ざったものに変え、出力として出されたコードを実行する方が、自然言語で回答するよりも正答率が上がるということを確認しています。
例にあるような算数的な問題(GSM8k)だけでなく、Penguins[^24]のような表を読んで答える推論タスクにも適用され、スコアが上がりました。
LLMがコードと自然言語が混ざった文章を扱うことができるという点や、特定のモデル、タスクでは自然言語のみで行うよりコードを用いる方が有用であるという点は興味深いです。モデルとしてはtext-davinciやPALM等が使われており、コード特化モデルでこの現象が現れたというわけではなく、汎用なモデルで一般的に成り立つ性質だと言えます。

Code Prompting: a Neural Symbolic Method for Complex Reasoning in Large Language Models[^ 25]
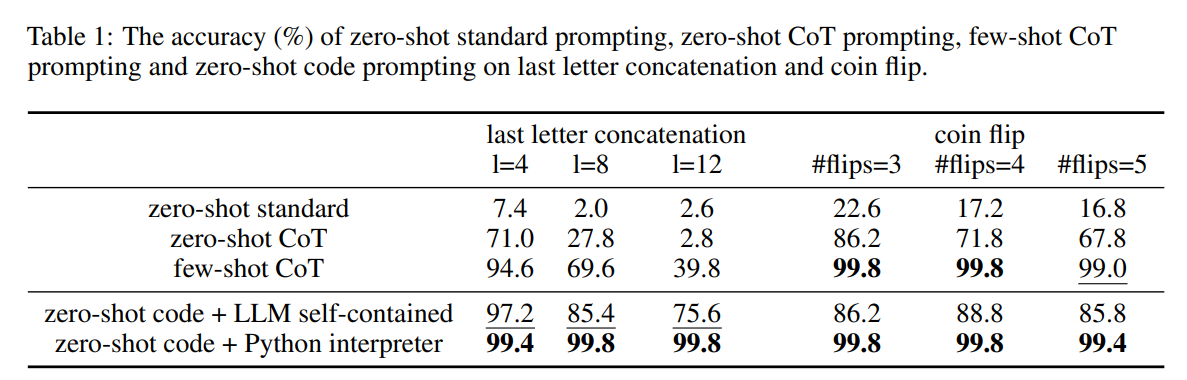
この研究では、問題に対してコードを生成しコードに問題を解かせる手法(Code Prompting + Python Interpreter.)と、問題に対してコードを生成した後、それを参照して答えさせる手法(Code Prompting + LLM Self-contained.)を提案し、chain-of-thoughtで解かせたときの結果等と比較しています。コードはコンパイルに通るかをチェックすることができるので、コンパイルに通るまで生成をやり直すことができる(self-debugging)というのが面白いです。
彼らが行った実験行ったタスクの一部を紹介します。
これらの手法ではいくつかのタスクでchain-of-thoughtを上回った他、参照させるよりもそのままコードに解かせた方が良いという結果がでています。
実験
先行研究の実験では、問題に対し、それを直接的に解くことができるコードを与えています。我々は、モデルにコードの「ヒント」を与えてそれを活用できる例があるか探しました。
Code Promptingは非常にコードに有利な問題設定だと考えられます。我々は、モデルに「コードのヒント」を与えてそれを元にモデルが答えることができるかいくつかの実験を行いました。
数列
数列の問題に対し、数列の規則を教える関数を与えて、数列仕組みの理解に変化が生じるかテストしました。openaiのAPIが叩けるモデルに対して、以下の等比数列の問題に対して関数のヒントを与える場合と与えない場合をそれぞれテストしました。
結果、関数を与える場合と与えない場合で結果が変化するモデルはありませんでした。
以下は等比数列の例です。一通りの実験はしていませんが、GPT-3.5等ではフィボナッチ数列を対象にした問題を試しました。
“`
def div(x, y):
return y //x
Find the value of the first term in the geometric sequence a,b,c,32,64
“`
推論
いくつかのif文を組み合わせた自然言語の文章題を作成し、それに対する応答についてヒントとなるif文の関数を与える場合と与えない場合を比較しました。
以下は、入力例です。
“`
This function is an example to think next problem.
def func (x,y):
if x and y:
return True
….
When it is raining and weekend, I don’t go to college today. When it is not raining but the weekend, I don’t go to college today. When it is not raining and not weekend, I don’t go to college today. In other case, I go to college today. Today, it is raining but not weekend. Do I go to college?
“`
時間が足りなくてできなかったのですが、自動的にこのような問題を作って、それを用いて関数のプロンプトを加える意味を評価してみると面白いかもしれません。
その他、GSM8k[^26](四則演算のデータ)に対して四則演算のプロンプトを入れたり、Reclor[^27](論理推論のデータセット)にif文のプロンプトを入れたりなどしましたが、スコアにあまり変化がなかったです。
終わりに
Future Work
コードと自然言語の間の関係性を解き明かすという点でいうと、指示チューニングやプロンプトでの実験のような入力と出力から考察を行う実験だけでなく、内部表現などモデルの中身やその表現を見る実験を行っていくと面白いかもしれません。例えば、コードとそれを表す自然言語文について、それぞれを表現するベクトルを用意し一体どのような空間に広がっているか調べることなどです。
謝辞
今回のインターンでは、大規模言語モデルについてほぼ何も知らない中押しかけてきた私を、メンターの石黒さん、前田さんが丁寧に指導してくださいました。心から感謝致します。VPの岡野原さんには研究について鋭い指摘を沢山頂きました。ありがとうございます。また、社員の方やインターンの同期達と起こった議論はどれも刺激的で楽しかったです。
今回の経験を忘れず、より一層の成長を目指したいと思います。大変お世話になりました。
[^1]: Chen, Mark, et al. “Evaluating large language models trained on code.” *arXiv preprint arXiv:2107.03374* (2021).
[^2]: Li, Yujia, et al. “Competition-level code generation with alphacode.” *Science* 378.6624 (2022): 1092-1097
[^3]: Nijkamp, Erik, et al. “Codegen: An open large language model for code with multi-turn program synthesis.” *arXiv preprint arXiv:2203.13474* (2022).
[^4]: Li, Raymond, et al. “StarCoder: may the source be with you!.” *arXiv preprint arXiv:2305.06161* (2023).
[^5]: Kocetkov, Denis, et al. “The stack: 3 tb of permissively licensed source code.” *arXiv preprint arXiv:2211.15533* (2022).
[^6]: Husain, Hamel, et al. “Codesearchnet challenge: Evaluating the state of semantic code search.” *arXiv preprint arXiv:1909.09436* (2019).
[^7]: Touvron, Hugo, et al. “Llama: Open and efficient foundation language models.” *arXiv preprint arXiv:2302.13971* (2023).
[^8]: https://rinna.co.jp/news/2023/07/20230731.html#:~:text=%E2%96%A0%20rinna%E3%81%AE%E6%97%A5%E8%8B%B1,%E6%80%A7%E3%81%8C%E9%AB%98%E3%81%84%E3%83%A2%E3%83%87%E3%83%AB%E3%81%A7%E3%81%99%E3%80%82
[^9]: Muennighoff, Niklas, et al. “Scaling Data-Constrained Language Models.” *arXiv preprint arXiv:2305.16264* (2023).
[^10]: Moryossef, Amit, Yoav Goldberg, and Ido Dagan. “Step-by-step: Separating planning from realization in neural data-to-text generation.” *arXiv preprint arXiv:1904.03396* (2019).
[^11 ]:Weston, Jason, et al. “Towards ai-complete question answering: A set of prerequisite toy tasks.” *arXiv preprint arXiv:1502.05698* (2015).
[^12]:Liang, Percy, et al. “Holistic evaluation of language models.” *arXiv preprint arXiv:2211.09110* (2022).
[^13]:Chen, Mark, et al. “Evaluating large language models trained on code.” *arXiv preprint arXiv:2107.03374* (2021).
[^14]:Austin, Jacob, et al. “Program synthesis with large language models.” *arXiv preprint arXiv:2108.07732* (2021).
[^15]:Honovich, Or, et al. “Unnatural instructions: Tuning language models with (almost) no human labor.” arXiv preprint arXiv:2212.09689 (2022).
[^16]:Touvron, Hugo, et al. “Llama 2: Open foundation and fine-tuned chat models.” *arXiv preprint arXiv:2307.09288* (2023).
[^17]:Luo, Ziyang, et al. “WizardCoder: Empowering Code Large Language Models with Evol-Instruct.” *arXiv preprint arXiv:2306.08568* (2023).
[^18]:Roziere, Baptiste, et al. “Code llama: Open foundation models for code.” *arXiv preprint arXiv:2308.12950* (2023).
[^19]:Xu, Can, et al. “Wizardlm: Empowering large language models to follow complex instructions.” *arXiv preprint arXiv:2304.12244* (2023).
[^20]:https://github.com/sahil280114/codealpaca
[^21]:Wang, Yizhong, et al. “Self-instruct: Aligning language model with self generated instructions.” *arXiv preprint arXiv:2212.10560* (2022).
[^22]:Zan, Daoguang, et al. “Can Programming Languages Boost Each Other via Instruction Tuning?.” *arXiv preprint arXiv:2308.16824* (2023).
[^23]:Victor, Sanh, et al. “Multitask prompted training enables zero-shot task generalization.” *International Conference on Learning Representations*. 2022.
[^23]:Gao, Luyu, et al. “Pal: Program-aided language models.” International Conference on Machine Learning. PMLR, 2023.
[^24]:https://github.com/suzgunmirac/BIG-Bench-Hard/tree/9ee07bd481feebf959a6b59d61ea57bdcf30964d/bbh
[^25]:Hu, Yi, et al. “Code Prompting: a Neural Symbolic Method for Complex Reasoning in Large Language Models.” arXiv preprint arXiv:2305.18507 (2023).
[^26]:Cobbe, Karl, et al. “Training verifiers to solve math word problems.” arXiv preprint arXiv:2110.14168 (2021).
[^27]:Yu, Weihao, et al. “Reclor: A reading comprehension dataset requiring logical reasoning.” arXiv preprint arXiv:2002.04326 (2020).
