Blog

はじめに
ブラックボックス最適化フレームワークOptunaの最新バージョンであるv3.6をリリースしました。今回のリリースには、様々な新機能やリファクタリング、バグ修正が含まれています。このブログではv3.6のハイライトと多くの機能改善についてお伝えします。
TL;DR
- Wilcoxon Pruner、軽量なガウス過程ベースのSampler、 PED-ANOVA重要度評価器等の様々な新しいアルゴリズムのサポート
- FrozenTrialの検証ロジックの厳密化、 Dashboardのリファクタリング、 Integrationの移行などOptunaの品質に関わる様々な改善を実施
Wilcoxon Pruner
Optuna v3.5以前では、Prunerは典型的な機械学習のハイパーパラメータ最適化を想定して作られていました。そのような問題では、学習曲線を見て悪いパラメータを早期終了することができますが、学習の始めが遅くても最終的に良いものになるという可能性が常にあり、それを考慮して慎重に枝刈りする必要がありました。
Optuna v3.6では、WilcoxonPrunerという上記の典型的な利用シーンとは異なる応用を想定したPrunerが追加されます。WilcoxonPrunerは、多数の入力に対する評価指標の平均・中央値などを最適化するような場面で、悪いtrialについて評価を途中で中止したい場合に使えます。
例えば、ヒューリスティックなアルゴリズム(焼きなまし法やSATソルバーなど)の平均性能、機械学習モデルのk-分割交差検証スコア、さらには大規模言語モデルに与えるプロンプトの平均性能、といった目的関数を最適化したい場合が挙げられます。
このような場合、それぞれの入力に対する評価は独立であり、Wilcoxonの符号順位検定に基づくWilcoxonPrunerを用いてよりアグレッシブに枝刈りを行うことができます。
以下のコードは、WilcoxonPrunerを簡単な関数に使った例です。
import optuna
import numpy as np
# input_の集合に対するeval_funcの平均を最小化するparamを見つける
def eval_func(param, input_):
return (param - input_) ** 2
input_data = np.linspace(-1, 1, 100)
def objective(trial):
param = trial.suggest_float("param", -1, 1)
loss_vals = []
# それぞれのtrialで評価する順番をシャッフルすると順番の影響を受けにくい
for input_id in np.random.permutation(range(len(input_data))):
loss = eval_func(param, input_data[input_id])
# 入力のidとその入力に対する評価スコアをreportする
# 注意: WilcoxonPrunerでは、同じ入力に対してスコアを同じidでreportする必要があります。
trial.report(loss, input_id)
loss_vals.append(loss)
if trial.should_prune():
# 枝刈りされたら目的関数の予測値を返す
# (Optunaに枝刈りされたtrialの目的関数の予測値を渡す暫定的な対処)
return sum(loss_vals) / len(loss_vals)
return sum(loss_vals) / len(loss_vals)
study = optuna.study.create_study(
# p_thresholdが高いほどアグレッシブに枝刈りを行います。
pruner=optuna.pruners.WilcoxonPruner(p_threshold=0.1)
)
study.optimize(objective, n_trials=100)
より現実的な例については、焼きなまし法のパラメータ調整に使ったチュートリアルをご覧ください。詳細は後日、別のブログ記事にて紹介します。
軽量なガウス過程ベースのSampler
Optuna v3.6では、optuna.samplers.GPSamplerが追加され、ガウス過程によるベイズ最適化(GP-BO)がネイティブでサポートされます。v3.5以前でもoptuna.integration.BoTorchSamplerでGP-BOを使うことができましたが、主にBoTorchに大きく依存することに由来する制約がありました。新しいGPSamplerはBoTorchSamplerよりも次の点で優れています。
- 離散空間・連続離散混合空間の探索において優れた性能: BoTorchSamplerは基本的に全ての変数が連続の時にしかうまく動作しなかったのですが、GPSamplerではその問題が解決されました。
- 高速な動作: BoTorchSamplerは内部の実装で高度な抽象化がされていて、動作が比較的低速でした。GPSamplerでは、内部の設計をシンプルに保つことによって、条件によっては5倍程度高速に動作します。
- 軽量な依存関係: BoTorchSamplerはBoTorch、 GPyTorch、 Pyroなど、孫依存を含めると多くの依存関係を抱えていて、特に制限の多い環境ではインストール上の問題が起こることが少なからずありました。GPSamplerは依存がPyTorchとSciPyのみのため、より多くの環境で動作することが期待されます。
- 目的関数が決定的であると明示的に指定できること: 他のOptunaのsamplerは全ての変数が離散の時、同じパラメータを複数回提案することがあり、問題となっていました。新たなGPSamplerはdeterministic_objectiveというオプションにTrueを指定すると、目的関数が決定的であることを考慮してガウス過程回帰を行います。これにより、同じパラメータが複数回提案される可能性が大きく減少します。
GPSamplerの基本的な使い方は単純で、create_studyを呼ぶときにsampler引数に指定するだけです。
study = optuna.create_study(sampler=optuna.samplers.GPSampler())
BoTorchSamplerも引き続きoptuna_integrationモジュールでサポートされます。実際BoTorchSamplerには現状GPSamplerにないいくつかの機能(多目的最適化、consider_running_trialsオプション、制約付き最適化)があり、それらを利用されたい方は$ pip install optuna-integration botorchのようにインストールすることでこれまで通りBoTorchSamplerを使うことができます。詳細は後日、別のブログ記事にて紹介します。
PED-ANOVAによる重要度評価の高速化
Optunaでは従来f-ANOVAと呼ばれる手法を利用して重要度を評価していましたが、パラメータの数やtrialの数が増えるに従って計算時間が非常に長くなることが問題となっていました。それを背景としてOptuna Dashboardではf-ANOVAのCython実装を利用していました。
2023年にf-ANOVAと比較してより高速なアルゴリズムであるPED-ANOVAがAI分野の国際会議であるIJCAIで発表されました*1。今回のリリースではtrialの数が増えると重要度評価が低速になる問題を解決する1つの手段としてPED-ANOVAをOptunaに導入しました。
以下の通りにインスタンス化したoptuna.importance.PedAnovaImportanceEvaluatorをoptuna.visualization.plot_param_importancesに渡すことで利用可能です。
import optuna
def objective(trial):
x1 = trial.suggest_float("x1", -5, 5)
x2 = trial.suggest_float("x2", -5, 5)
return x1 ** 2 + x2 ** 2 / 1000
study = optuna.create_study()
study.optimize(objective, n_trials=30)
evaluator = optuna.importance.PedAnovaImportanceEvaluator()
optuna.visualization.plot_param_importances(
study, evaluator=evaluator
)
以下に速度ベンチマークを行った結果を示します。実装したPED-ANOVA、Optunaのf-ANOVA、Cython実装のf-ANOVAを様々なパラメータ数とtrial数で比較しました。Cython実装のf-ANOVAはOptunaのf-ANOVAと比較して高速ですが、パラメータ数やtrial数が大きい場合に1分以上の時間がかかってしまいます。一方でPED-ANOVAは全ての設定において1秒以内に動作しており、高速であることがわかります。
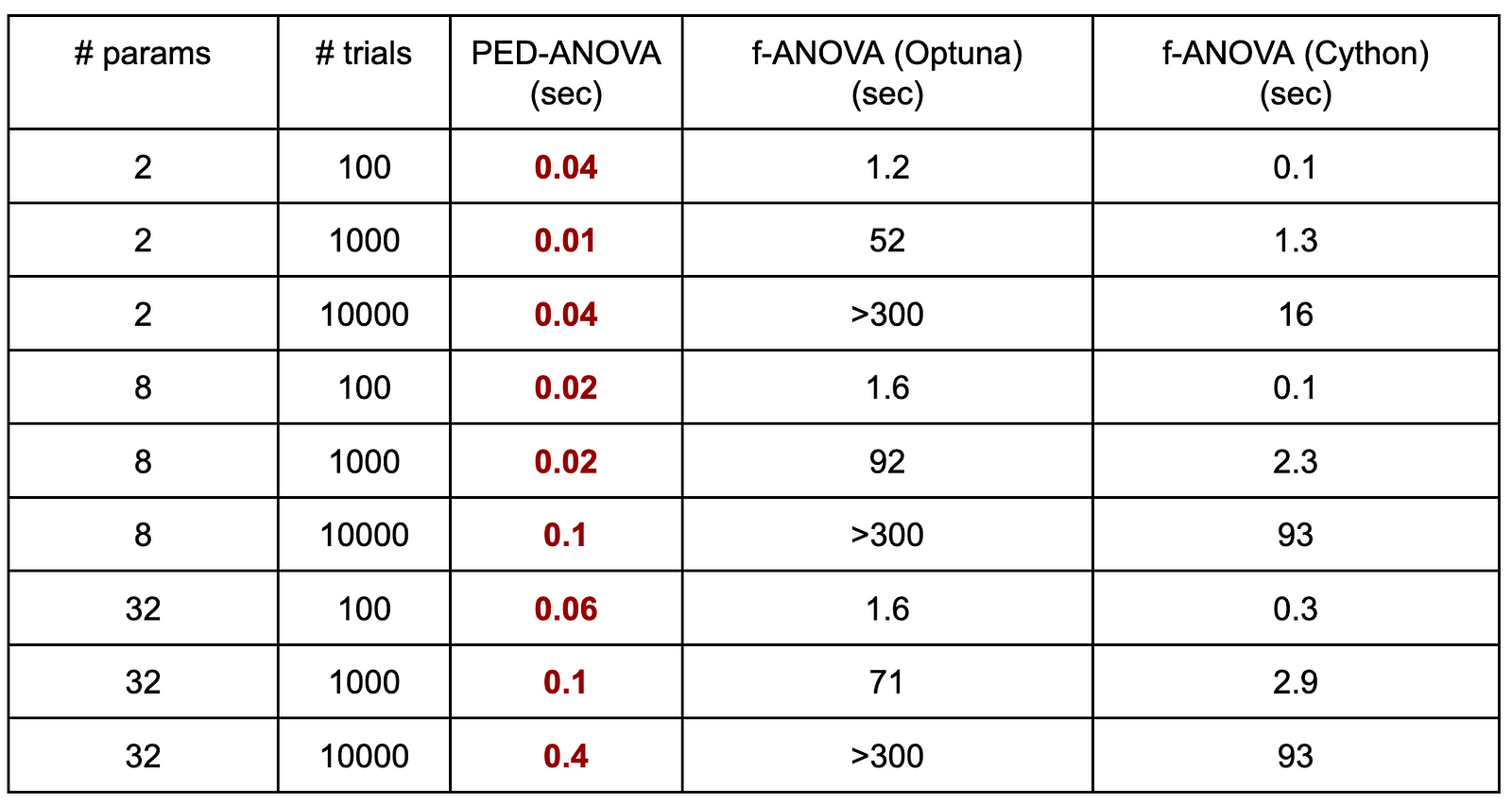
また、我々が提供するWebダッシュボードであるOptuna Dashboadでは、重要度の描画をリアルタイムに更新しています。大きなパラメータ数とtrial数では、これまで描画の更新に数分以上の時間がかかっていましたが、PED-ANOVAを用いることでその更新がたった数秒で実現されるようになりました。
*1: Watanabe et al., PED-ANOVA: Efficiently Quantifying Hyperparameter Importance in Arbitrary Subspaces. Proceedings of International Joint Conference on Artificial Intelligence 2023 (IJCAI’23). URL: https://www.ijcai.org/proceedings/2023/488
FrozenTrialの検証ロジックの厳密化
Optunaには以前からFrozenTrialというクラスが存在しています。このクラスは最適化の一試行を表すTrialクラスの一種で、主に目的関数の外でユーザに利用されます。一連の最適化処理全体はStudyクラスで管理されますが、FrozenTrialはStudyに紐づかない単一のtrialを表しています。
FrozenTrialはoptuna.create_trial関数で自由に作ることができ、それをStudy.add_trialメソッドでStudyに入れることができます。この機能を使うことで、必要なtrialのみを可視化したり、既知の優れたパラメータとその評価値をStudyにあらかじめ差し込んでアルゴリズムにヒントを提示したりできます(下記のコード例のように行います)。
しかし、以前のcreate_trial関数はOptuna内部の実装で前提とされているルールに沿わないような、異常なFrozenTrialを作ることも可能でした。そのようなケースをより早期に検出するため、今回のアップデートでFrozenTrialの検証をより詳しく行うことにしました。これによりランタイムエラーや意図しない最適化性能の低下などの厄介なトラブルの減少が期待されます。
import optuna
def objective(trial):
x = trial.suggest_float("x", -1.0, 1.0)
return x**2.0
study = optuna.create_study()
trial = optuna.trial.create_trial(
params={"x": -0.2},
distributions={
"x": optuna.distributions.FloatDistribution(-1.0, 1.0),
value=0.04,
)
study.add_trial(trial)
study.enqueue_trial({"x": 0.1})
study.optimize(objective, n_trials=20)
print(f"Best value: {study.best_value} (params: {study.best_params})")
Optuna Dashboardのリファクタリング
我々が提供するWebダッシュボードOptuna Dashboardでは、PlotlyのJavaScriptライブラリを使ってフロントエンドで可視化機能を実装していました。これはOptunaの提供するPythonでの可視化機能の再実装になっており、高いインタラクティブ性を可能にする一方で、提供するコンポーネントが増えてきた中、メンテナンス性・一貫性といった面での懸念が生じてきています。
この問題を緩和するため、Optuna DashboardからバックエンドでOptunaの可視化機能を利用するオプションを試験的に追加しました。Dashboardの左下の設定ボタンから”Use Plotlypy”というトグルを有効化することで使うことができ、これによりユーザーはOptunaの可視化関数と一貫した出力を得ることができます。また、グラフの描画のために必要な計算はバックエンドで行われるため、Optuna Dashboardをサーバーを立てて実行するようなケースではクライアントサイドでの計算の軽量化といった恩恵を受けることもできます。

現状このオプションではシンプルな機能のみ提供しインタラクティブ性を最小限に留めています。使ってみてフィードバックなどありましたらissueやPRをいただけると嬉しいです。
Migration to Optuna Integration
Optunaでは、Optunaとサードパーティのライブラリを組み合わせて便利に使うためのモジュール群を提供しています。このモジュール群は当初Optuna本体にoptuna.integrationとして導入されましたが、本体の動作に必須の機能ではないため、v3.2から本体のコードベース肥大化やCIにおける負担を軽減するためにoptuna-integrationという別パッケージへの移行が部分的に開始されました。そして、今回のv3.6リリースで晴れて全てのモジュールのoptuna-integrationへの移行が完了しました。
このため、v3.6で移行されたモジュールを用いるには次のようにoptuna-integrationのインストールが必要となります。
pip install optuna-integration
一方で、今回の移行における既存のユーザーコードへの影響を最小限に留めるため、optuna.integration.XXX(XXXは任意のモジュール)はoptuna_integration.XXXを参照する薄いラッパーとして残されており、optuna-integrationさえ環境にインストールされていれば、optuna.integrationを用いる従来のコードもエラーなく適切に動作するようになっています。以下に例を示します。
# optuna_integrationからimportすることも可能 from optuna_integration import OptunaSearchCV # 従来通りの以下でもOK、ただしoptuna-integrationがない環境ではエラーとなる from optuna.integration import OptunaSearchCV
おわりに
我々コミッターはOptunaを世界で最高のブラックボックス最適化フレームワークとするべく日々開発に勤しんでいます。既存の機能を改善し、様々な新機能を公開し、そして最近ではRustによる実装といった野心的なプロジェクトも走っています。Optunaは絶えず進化し続けているので、常に新しいコントリビュータを募集しています。興味のある方はぜひGitHubで我々コミッターに声をかけたり、開発イベントに参加してみてください。
また、これから数週間にわたってコミッター内部で行った試験的な取り組み、新機能の紹介、応用事例の紹介を行うブログを公開していきます。以下のようなコンテンツを用意しているのでお楽しみに!
- Wilcoxon Prunerのアイデア、アルゴリズム、使い所
- 軽量なガウス過程ベースのSampler
- Wilcoxon Prunerのヒューリスティックコンテストへの適用例
- Rustによる高速かつ依存関係の少ないOptunaの試作
Optuna開発チームでは、より多くのユーザーにより便利にOptunaをお使いいただけるよう、様々な可能性を模索し日々改善を続けています。一緒にOptunaを開発するパートタイムエンジニアを随時募集しています。本記事を通して、ご興味を持っていただけたという方はぜひ下記ページをご確認ください。
Software engineer (Optuna) / ソフトウェアエンジニア(Optuna) / 株式会社Preferred Networks
Contributors
v3.6のリリースには以下のコントリビュータの方々の貢献が含まれます。ありがとうございました!
@Alnusjaponica, @DanielAvdar, @HarshitNagpal29, @HideakiImamura, @SimonPop, @adjeiv, @buruzaemon, @c-bata, @contramundum53, @dheemantha-bhat, @eukaryo, @gen740, @hrntsm, @knshnb, @nabenabe0928, @not522, @nzw0301, @porink0424, @ryota717, @shahpratham, @toshihikoyanase, @y0z