Blog
2024.10.17
CuPyにおけるCUDA Graph Conditional Nodesのサポート
Kenichi Maehashi
Engineering Manager (Deep Learning Ecosystem Team)
本記事は、2024年夏季インターンシッププログラムで勤務された細川颯介さんによる寄稿です。
こんにちは、2024年度のPFN夏季インターンシップに参加していた、東京大学大学院修士1年の細川颯介と申します。今回のインターンシップでは、「CuPyへのCUDA Graph Conditional Nodesサポートの追加」というテーマに取り組みました。
CuPy はPFNが中心となりOSSで開発されている、GPUを利用して高速に配列計算を行うことができるライブラリです。CuPyはCPU向けの配列計算ライブラリとして広く普及している NumPy や、科学計算のためのSciPyなどのライブラリと高い互換性を持つAPIで、簡単にGPUを利用した高速化が行えるようにすることを目指して開発が行われています。
本プロジェクトでは、CuPyに対してCUDA 12.3で追加されたCUDA Graph Conditional Nodeのサポートを追加し、一般ユーザーが利用しやすいCUDA GraphのAPIの実装を行いました。CuPy本体へのPull Requestはこちらになります。
背景
CUDAカーネルの起動オーバヘッドとCUDA Graph
CUDAにおいて、GPU上で並列実行される関数をCUDAカーネルと呼びます。CUDAプログラムは、複数のCUDAカーネルにより構成されていることが一般的であり、例えば、特に工夫をせずにCuPyのプログラムを記述した際には、ndarrayに対するそれぞれの演算(加算や乗算、行列演算など) に対して個別にCUDAカーネルが呼び出され、実行されます。
ところで、CUDAカーネルの呼び出しには1回あたり10us程度の時間がかかります (図1)。一方で、プログラムの特性にもよりますが、近年のGPUの性能向上なども相まって、一つのカーネルの計算が数us程度で終了することも珍しくなくなっています。このような細粒度のカーネル呼び出しが多数行われるようなプログラムにおいては、プログラム全体の実行時間においてカーネル起動のオーバーヘッドが占める時間が支配的となり、CUDAカーネル自体の改善がプログラムの高速化に繋がらないため、カーネル起動のオーバーヘッドを削減する事による高速化を行う必要があります。
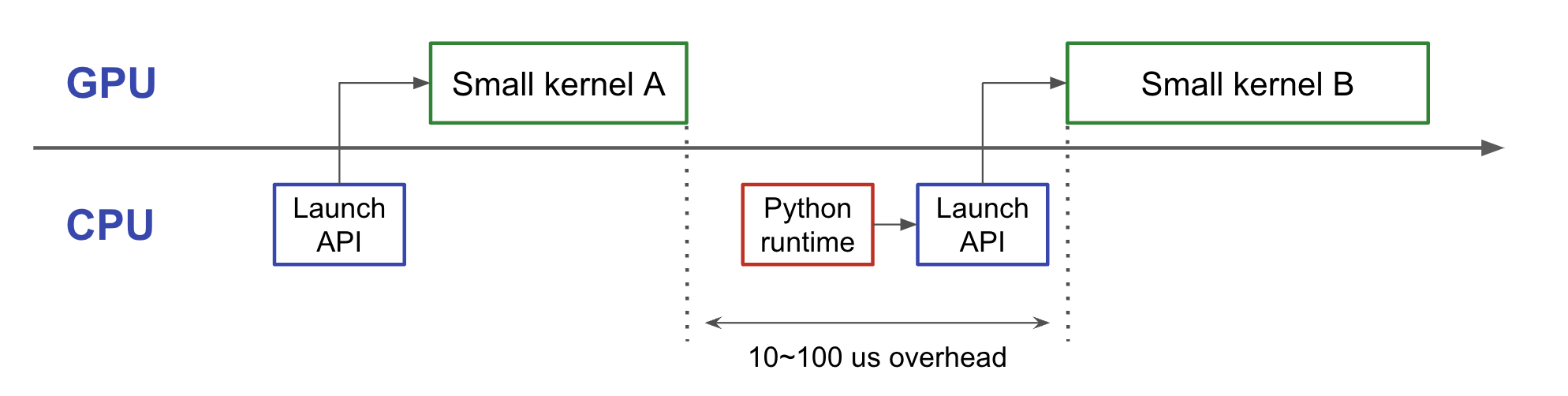
図 1 一般的なCUDAカーネルの起動とオーバーヘッド
CUDAでは、カーネル起動のオーバーヘッドを削減するための機能として、CUDA Graphという機能を提供しています。CUDA Graphでは、複数のCUDAカーネルについて、実行前に実行順序や起動時の引数の値などの依存関係をグラフに構築し、そのグラフを一度にGPUに投入することで、一度のグラフ起動のオーバヘッドのみで実行できるという機能になっています (図2)。このCUDA Graph自体は2019年にリリースされたCUDA 10で導入された機能であり、すでにCuPyからも利用することができます。

図 2 CUDA Graphの概略
CUDA Graph Conditional Node
基本的にCUDA Graphは実行前に事前にkernelの依存関係が決定される必要があるため、条件分岐やループのあるプログラム全体をグラフ化することはできませんでした。また、このようなプログラムにおいて、条件判定の部分はCPUで行わなければならないため、条件判定のたびにGPU-CPU間で同期を行い、GPUからCPUへのデータ転送を行うことが必要になっていました。GPU-CPU間の同期とデータ転送を行う場合は、単なるカーネル起動よりも大きな数十us程度のオーバーヘッドがかかります。
このように、条件分岐やループのあるCUDAプログラムをCUDA Graphによって高速化することは難しかったのですが、2023年10月にリリースされたCUDA 12.3からCUDA Graphに対してConditional Nodeというものが追加され、制御構造を含むプログラムについてもCUDA Graphを利用して高速化することができるようになりました (図 3)。
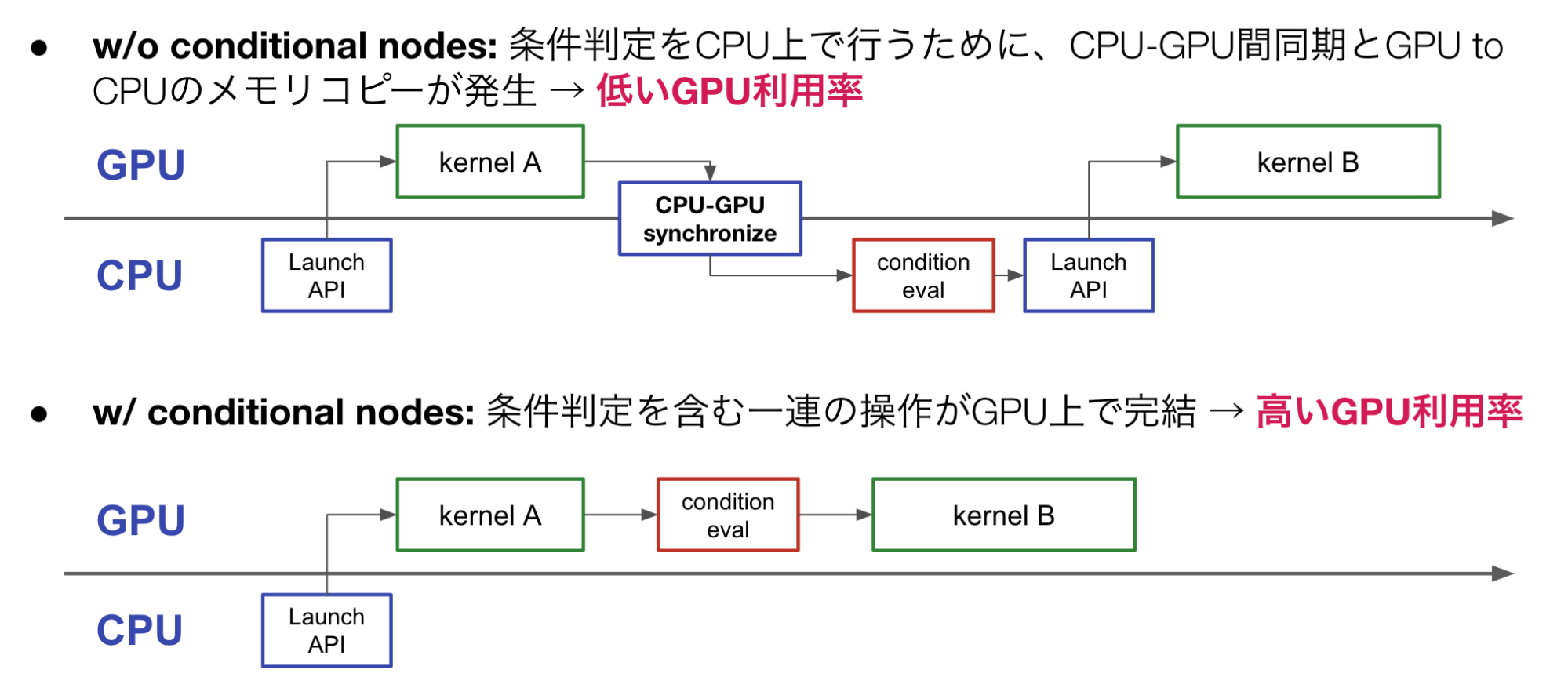
図 3 Conditional nodeの有無による条件判定部分の実行の違い
Conditional Nodeは条件分岐やループをCUDA Graphに対して追加できるノードであり、特殊な変数 (conditional handle) を介して条件判定のための値をCUDA Graph内のカーネルからセットすることにより、これらの制御構造をCUDA Graphに対して追加できます。Conditional Nodeを利用すると、条件分岐の処理をユーザーのプログラムに返すことなくGPU内で完結できるので、より様々なプログラムを高速化できるようになると期待できます。
実装
CuPyにおけるConditional Nodeサポートの実装は、以下の2段階で行いました。
- CUDA Graphのセマンティクスを陽に意識して利用するlow-levelなAPIの実装
- low-levelなAPIをラップして、CUDA Graphのセマンティクスを意識せずに利用できるようにするFunctional APIの実装
前提: 既存のCuPyのCUDA Graph対応
Conditional Nodeを利用しない単純なCUDA Graphであれば、既存のCuPyでも利用することができます。CuPyにおいてCUDA GraphはCUDA Streamを利用して構築されます (プログラム 1)。CUDA Streamは複数のCUDAカーネルを非同期に実行するためのCUDA runtimeの機能ですが、CUDA Streamをcapture modeとしてCUDAカーネルを起動すると、実際の実行は伴わず実行順序と起動時の引数が記録されます。そして、最終的にcapture modeを終了するときに、記録されたカーネルの依存関係からCUDA Graphが構築されます。
st = cupy.cuda.Stream()
a = cupy.array(...)
b = cupy.array(...)
with st:
st.begin_capture() # capture modeの開始
a += b
a *= b
g = st.end_capture() # capture modeの終了・graphの取得
g.launch() # graphの起動
プログラム 1 既存のCuPyのCUDA Graph利用のためのAPI
Low-levelなAPIの実装
まず、PythonのプログラムからConditional Nodeを構築できるようにするために必要な、CUDA runtimeの各種APIの薄いラッパーをCuPyに対して追加しました (プログラム 2)。このAPIは、Conditional Nodeのbodyのグラフや大元のグラフのキャプチャは既存のstream captureを通じて行い、conditional handleの作成の部分などはCUDA Graphのセマンティクスを露出したようなAPIとなっています。
st1 = cupy.cuda.Stream()
st2 = cupy.cuda.Stream()
with st1:
st.begin_capture()
handle = _create_conditional_handle(st1)
set_condition_value(handle, ...) # handleに値をセットするカーネルの起動
body_graph = _append_conditional_node(
st1, "while", handle) # whileノードの追加
with st2:
st2.begin_capture(dest_graph=body_graph)
... # capture while loop body
st2.end_capture()
root_graph = st1.end_capture()
root_graph.launch()
プログラム 2 Low-levelなConditional Node追加のためのAPI
Functional API
Low-levelなAPIですが、利用にはCUDA Graphのセマンティクスを深い理解が必要で、ユーザーが使いやすいAPIとは言えません。そこで、Pythonの関数ベースでCUDA Graphを構築するためのfunctional APIというものを新たに設計し、実装しました (プログラム3) 。Functional APIでは、生のConditional Nodeのconditional handleによる条件の特殊な取り回しを隠蔽し、一般的なプログラムに近いフローでグラフを記述できるようになっています。
# 普通のCuPy/NumPyによるwhile loopの実装 (xp = cupy or numpy)
a = xp.zeros(size)
while xp.all(a < N):
a += 1
# Conditional Nodeを利用した実装
gb = GraphBuilder()
@gb.graphify
def func(a):
def while_fn(a):
a += 1
gb.while_loop(
lambda a: cupy.all(a < N), # condition
while_fn, # body
(a,), # while body argument
)
プログラム 3 functional APIの例
また、Conditional Nodeを含むCUDA Graph特有の問題にも対処しています。例えば、一般的にループのあるプログラムにおいて、cupyの関数は必ずしもin-placeな操作で行われる保証はないため、プログラム内で同一の変数が指し示すメモリ上の位置は動的に変化します。一方で、CUDA Graphは実行時にカーネルの引数の値が変更されてはならないため、一見正しそうに見えるプログラムでも、意図通りのメモリ領域に対して演算が行われないため、正しい結果が得られないということがあります。このような事態を防ぐために、Functional APIではループ中で繰り越される変数は、ループ関数の引数に取るようにするという制約を入れ、ポインタが変更された場合には自動でコピーを行うようにするようにしています (図 4)。
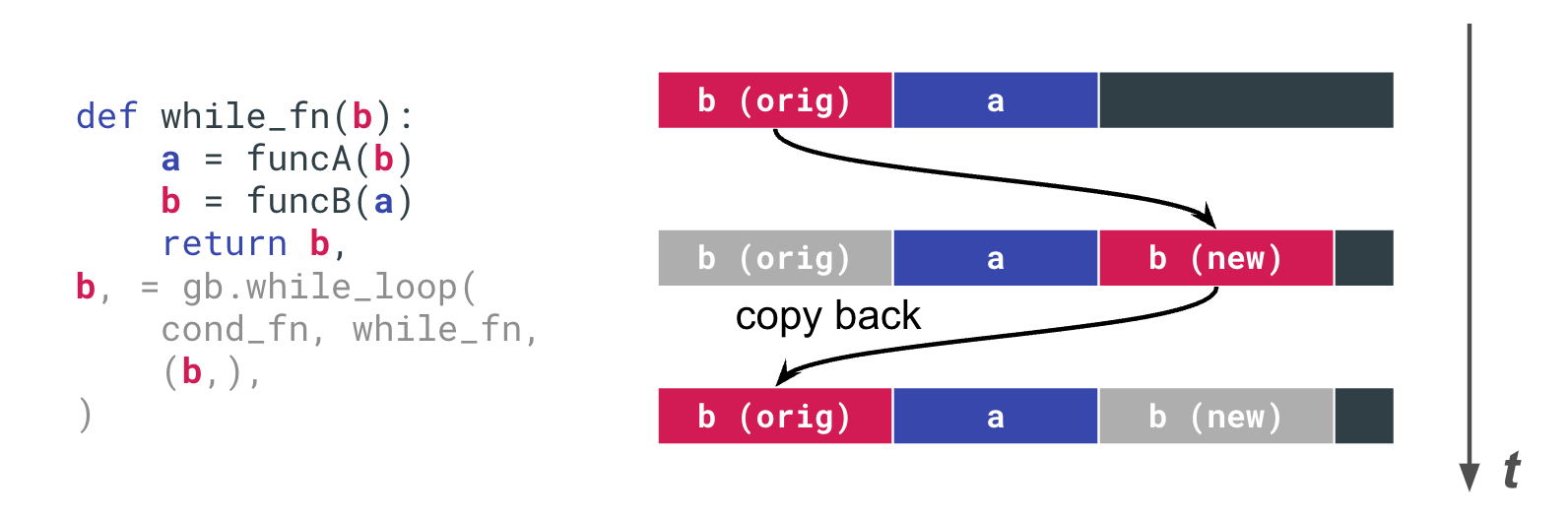
図 4 ループ間で繰り越される変数の扱い
評価
簡単なループプログラムによる評価
まず、Conditional Nodeの効果が最も顕著に現れるような例として、cupy.ndarrayを利用したシンプルなwhileループを利用した評価をしました。
具体的には、プログラム3のようにループ内でndarrayの各要素の値をインクリメントし、値が N 以下である間ループを回すというような処理を利用しています。
実行時間
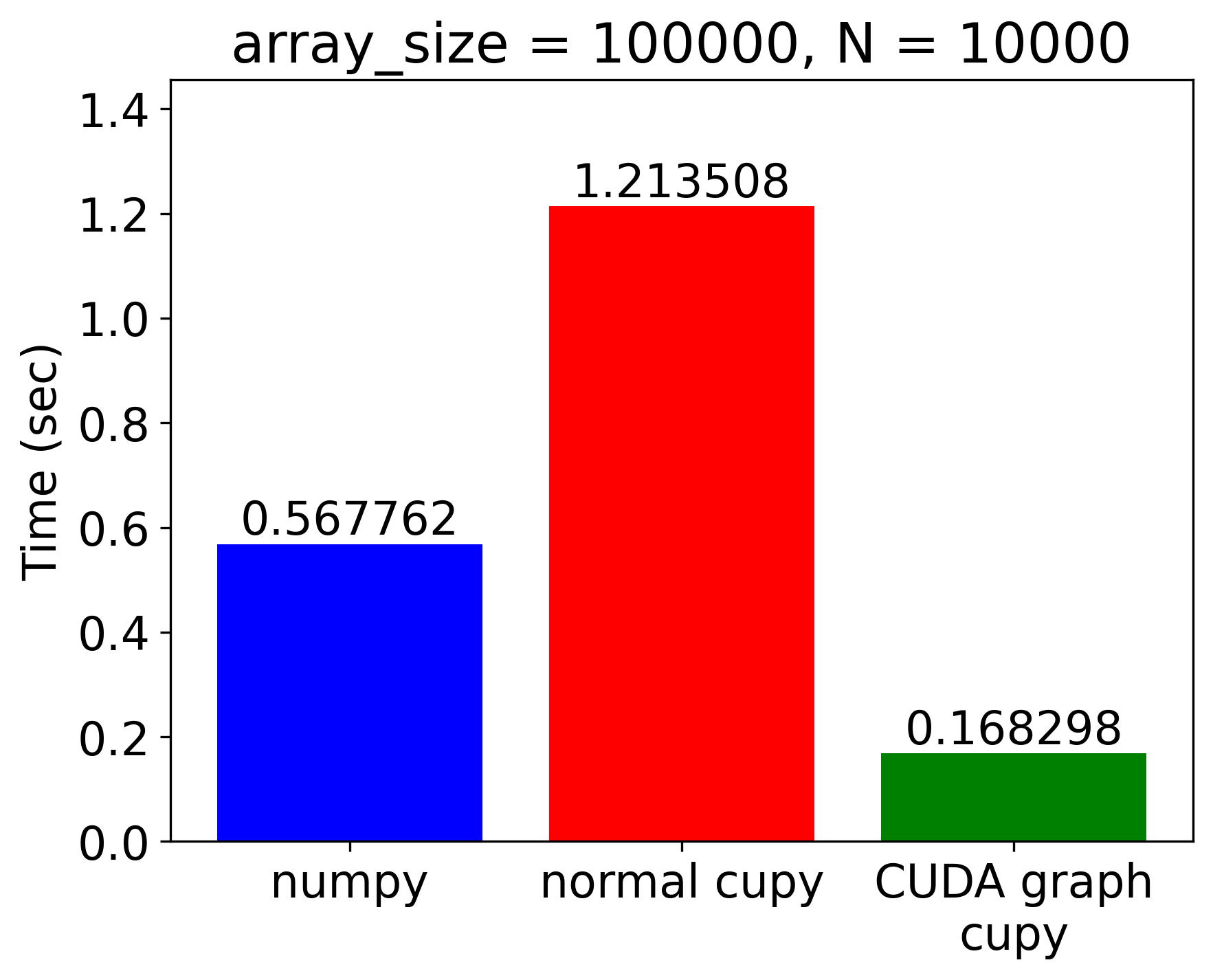 |
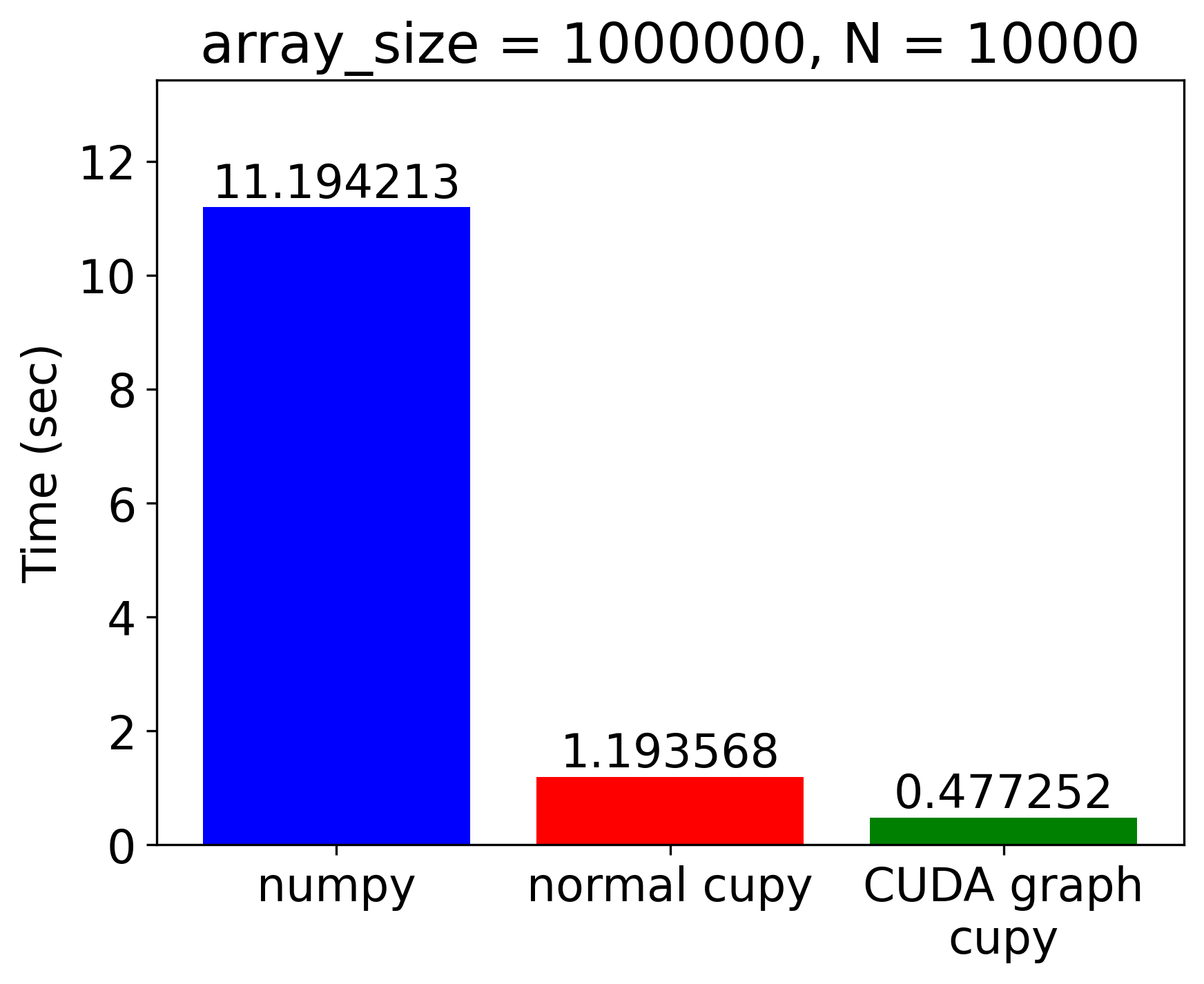 |
図 5 単純なループプログラムの実行時間の計測結果
実行時間の計測結果を図 5に示します。CPUで実行されるNumPyのプログラム (numpy)、conditional nodeを使わないCuPyのプログラム (normal cupy)、conditional nodeを利用して高速化したプログラム (CUDA graph cupy) の3種類について時間を計測しています。また、配列のサイズは比較的小さな100,000要素のものとより大きな1,000,000要素のものに対して計測を行いました。
まず、要素数100,000の比較的小さな配列に対する計算では、普通のCuPyプログラムでは、CPU上で実行されるNumPyのプログラムよりも実行が遅くなってしまっていることがわかります。これは、カーネル起動のオーバーヘッドやGPU-CPU間の同期とデータ転送によるものであると考えられますが、CUDA Graph版の実装においてはそれらのオーバーヘッドが改善されているため、NumPy実装から3.4倍・元のCuPy実装からは7.2倍程度の高速化を達成できています。
要素数1,000,000の大きな配列については、元のCuPyプログラムでもNumPy実装からの高速化を達成できていますが、Conditional Nodeを利用することでより大きな高速化率を達成することができ、NumPy実装から23.4倍・元のCuPy実装からも2.5倍の高速化ができていることが確認できました。
プロファイリング
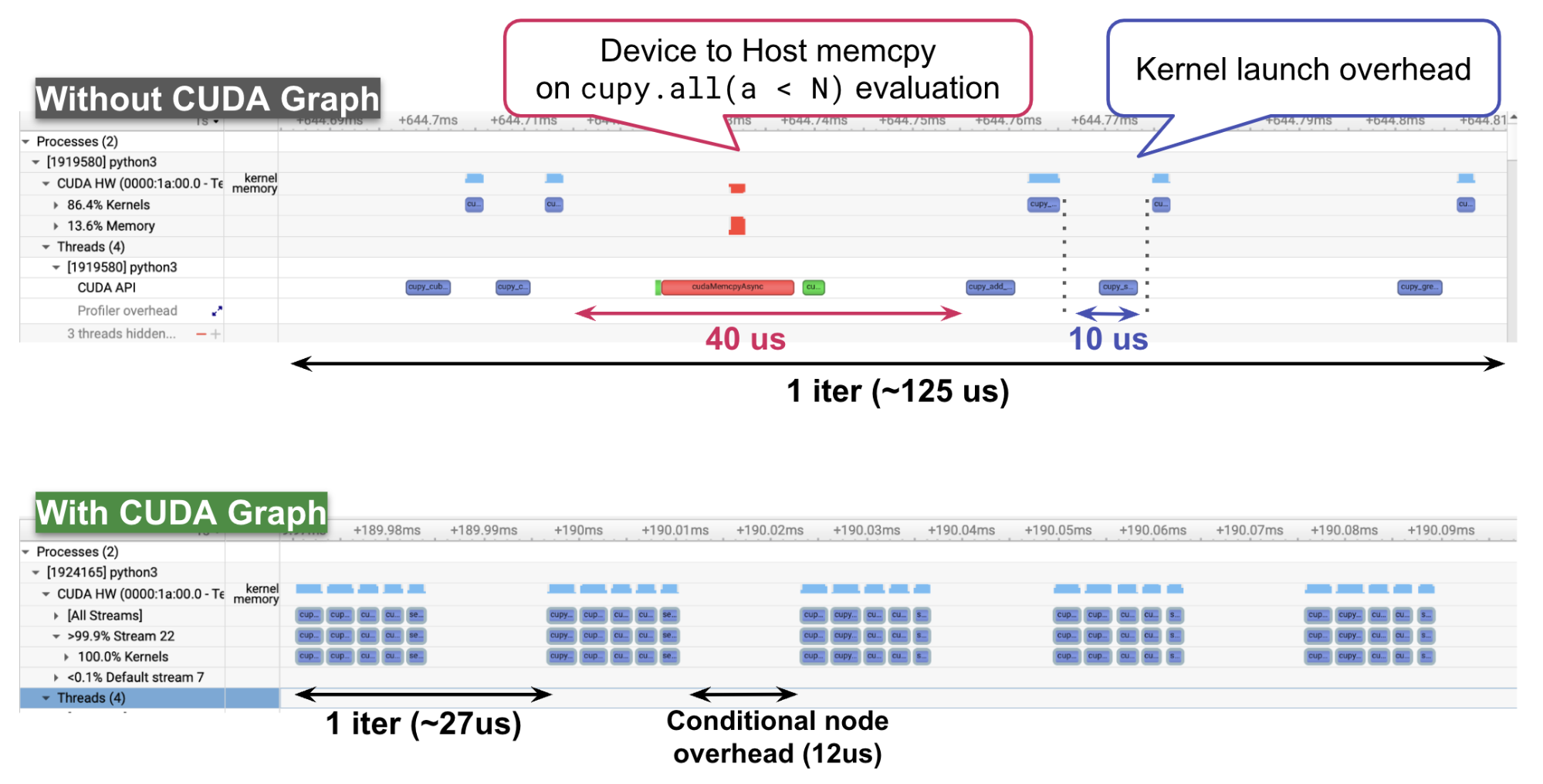
図 6 単純なループプログラムのプロファイリング結果
CUDA Graph Conditional Nodeを利用することでどのようにプログラムが高速化されているかをより詳細に確認するために、Nsight Systemsを利用したプロファイリングを行いました[1]。(図 6)
プロファイリング結果からは、CUDA Graphの利用によって元々10us程度あったカーネル起動のオーバヘッドがほとんどなくなっていることや、whileの条件判定のために発生していたdevice to hostのメモリコピーがなくなり、ループのiteration間の時間も短縮されていることがわかります。
より実用的なアプリケーション (LSMR) の移植による評価
より実用的なアプリケーションとして、cupyx.scipy.sparse.linalg.lsmr (反復法による疎行列向け最小二乗法ソルバ) のCUDA Graphを利用した実装を行い、性能を評価しました。
移植に必要な変更点
先程の単純な例とは異なり、元々のLSMRのプログラムはループの内部でネストした条件分岐が呼ばれていたり、GPUで計算した結果をCPU上に戻して一部のスカラ値の計算をCPU上で行ったりしています。ネストした条件分岐もfunctional APIではCUDA Graph化することができ、また、CPU上で計算を行っている部分に関しても、計算を行っているスカラ値をCuPyの0-dim ndarrayとして保持するようにすることで、容易にGPU上での計算に変換することができます。このように、少しのプログラムの改変でCUDA Graphを利用することができます。
実行時間の比較
次の4種類の実装について実行時間を比較しました。
- CPU: CPU実装 (scipy.sparse.linalg.lsmr)
- Normal: CUDA Graphを利用しないGPU実装 (cupyx.scipy.sparse.linalg.lsmr)
- Graph: CUDA Graph化をした実装
- Graph optimized: CUDA Graph化に加え、後述の高速化手法を部分的に取り入れた実装
また、入力する疎行列のサイズとしては 1000 x 1000、2500 x 2500、10000 x 10000 の3種類を用意しました。
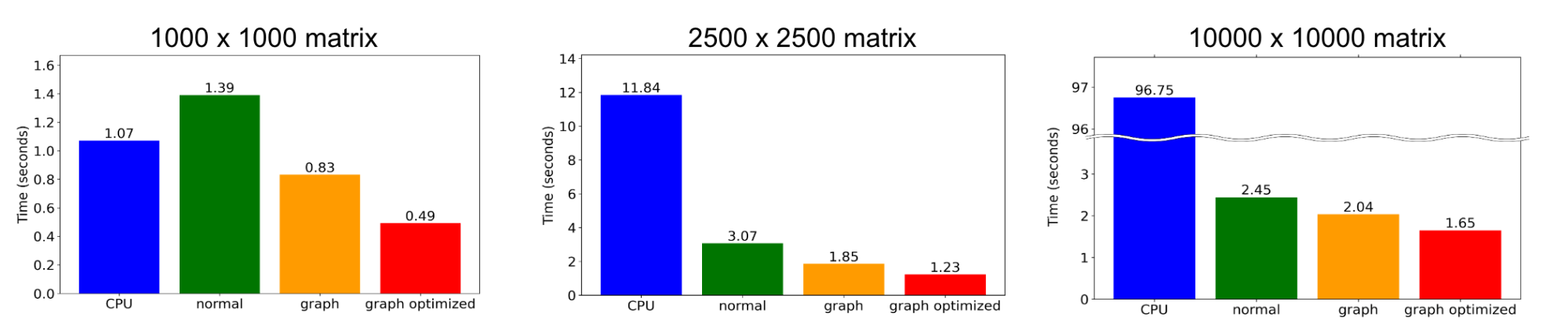
図 7 実装毎のLSMRの実行時間
図 7 にそれぞれの実装のLSMRの実行時間を示します。どのサイズの入力に対しても、CUDA Graphを利用した実装はCPU実装やCUDA Graphを用いないCuPy実装よりも高速で、最適化を施したものに関しては最大2.8倍程度の高速化を達成できました。
プロファイリング
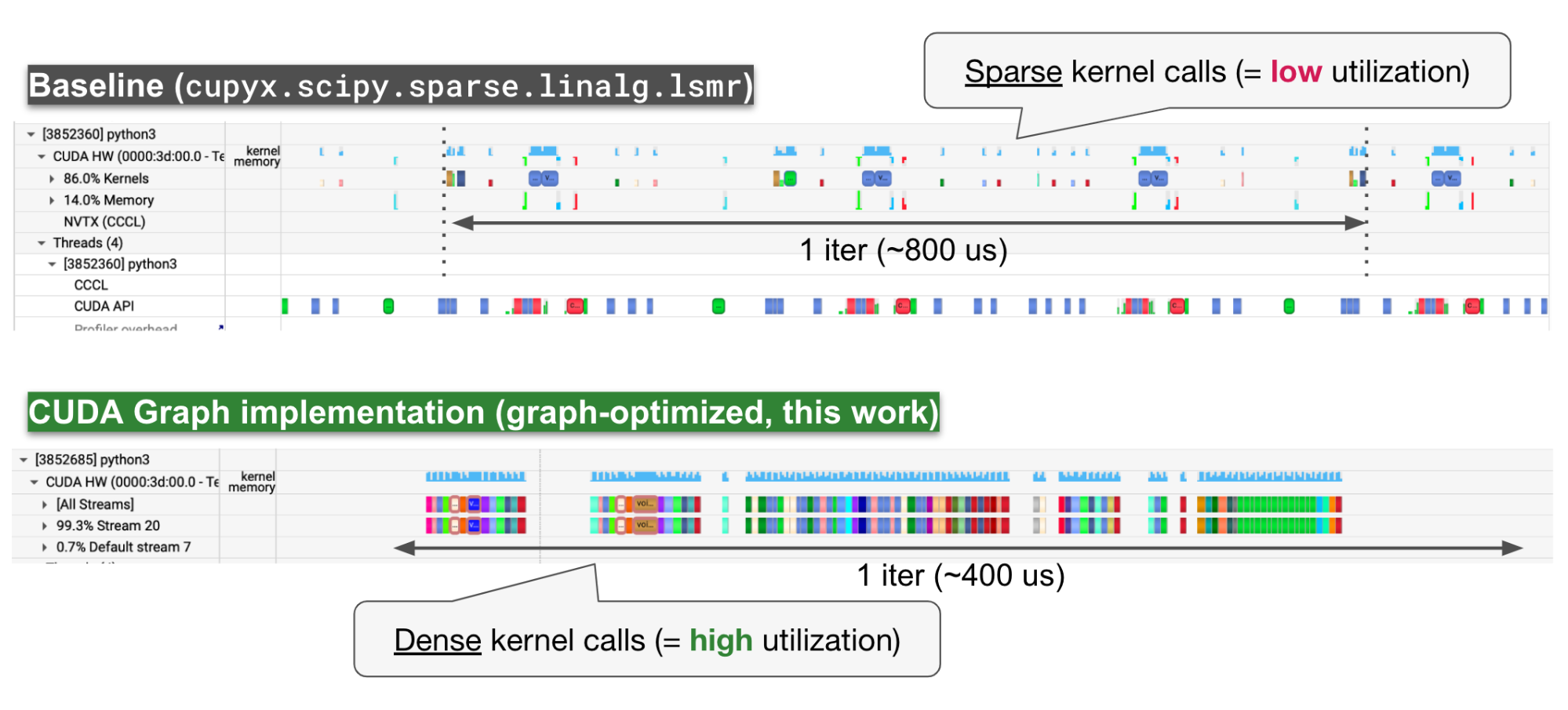
図 8 LSMRのプロファイル結果
Nsight Systemsを利用したプロファイリングをLSMR (1000 x 1000) に対しても行いました (図 8)。プロファイル結果から、baselineのLSMR実装ではカーネルの呼び出しの間が大きく空いてしまっていたのが、CUDA Graphを利用した実装では密に詰まって呼び出されていることがわかります。
一点注意として、CUDA Graph実装では1 iterationの中で呼び出されるカーネルの数が増えてしまっているという点があります。これは、CUDA Graphの実装がすべての計算をGPU上で完結させるために0-dim ndarrayに対する乗算や加算を多用しており、その演算それぞれに対してカーネルが発行されてしまっているためです。カーネル数の増加は後述する既存のCuPyの高速化手法を組み合わせることで抑えることができ、さらなる高速化ができると期待できます。
その他のConditional Nodeにより高速化が期待できるアルゴリズム例
今回取り上げたLSMRのプログラムには、次のような特徴があります。
- 細粒度のカーネル呼び出しが多数繰り返されており、カーネル起動にボトルネックが存在する
- アルゴリズム中にループ内の計算結果に依存するループの終了判定がある
同様の性質を持つプログラムであれば似たような高速化率を達成できる可能性が高く、例えば次のようなアプリケーションが有望です。
- LSMRと同様の反復法によるソルバ
- AutoregressiveなMLモデル (RNN, Transformer decoderなど、参考: CUDA Graph conditional nodeの利用によるRNN-Tの高速化例)
既存の高速化手法との比較
CuPyプログラムを高速化する手法としては、 cupy.fuse によるカーネル融合や、 cupyx.jit.rawkernel や cupy.RawKernel などのカスタムカーネルを用いる方法もありますが、これらの手法との違いや関係性についても簡単に説明しておきます。
カーネル融合
cupy.fuse により利用できるカーネル融合は複数のカーネルの演算を融合して単一のカーネルに変換することで実行時間を削減する手法です。
カーネル融合ではCUDA Graphと違い、GPUメモリアクセスの回数も減らすことができるとても強力な機能ですが、element-wiseな操作やreductionのような一部の操作にしか対応していないという欠点があります。一方で、CUDA GraphはcuBLASやcuSPARSEなどのルーチンを含む多くの演算に対して適用できる[2]他、制御構造が含まれていても高速化できるというメリットもあります。
カスタムカーネル
cupyx.jit.rawkernelやcupy.RawKernelなどを通じて利用できるカスタムカーネルでは、ユーザーが独自にCUDAカーネルを定義して利用することができます。カスタムカーネルはカーネル起動にボトルネックを持たないプログラムを含む様々なプログラムを高速化できる可能性がありますが、高速なカーネルを記述するにはCUDAに関する深い知識が必要になり、プログラムの大幅な書き換えも必要になります。
他の手法とCUDA Graphの併用
CUDA Graphを利用する場合、すべての演算をGPU上で行うようにする必要がありますが、LSMRのプロファイル結果の説明でも述べた通り、CuPyでそれを単純に実現する場合、0-dim ndarrayの演算としてカーネルの数が増えてしまうという問題がありました。これらのカーネルはカーネル融合やカスタムカーネルなどの手法を利用することで削減することができ、さらなる高速化を図ることができます。
まとめ
今回のインターンシップでは、CuPyに対してCUDA 12.3から追加されたCUDA Graph conditional nodeのサポートを追加し、ユーザーが利用しやすいAPIの形でまとめることができました。また、その実装を利用して実世界で利用されるアプリケーションを含むプログラムを移植し、高い高速化率を達成できることを確認できました。
インターンシップ全体を通しての感想としては、CuPyという世界的に利用されているOSSの開発を通して、大規模なソフトウェアの開発フローやCUDAの新機能を利用したプログラムの高速化を行う体験ができ、非常に楽しかったです。7週間という限られた期間ではありましたが、ある程度まとまった結果を出すことができ良かったです。
また、メンター・サブメンターの前橋さん・高木さん、チーム内でアドバイス等を頂いた今西さん・郭さんにはインターン期間を通じて大変お世話になりました。この場を借りて感謝申し上げたいと思います。
[1] Nsight SystemsではCUDA Graphのノード単位のトレースは –cuda-graph-trace=node のオプションを指定することで取得することができますが、この場合CUDA Graphの実行に対して大きなオーバーヘッドが加わる可能性があることがドキュメントに記されており、プロファイリング結果は実際の実行時間よりも遅くなっている可能性があります。
[2] cuBLASやcuSPARSEの多くの関数はCUDA Graphに対応した実装となっていますが、一部の関数は未対応であることには注意が必要です。また、cuBLASではデフォルトの挙動では内部でworkspaceと呼ばれるメモリ領域を自動的に確保しようとしますが、この動作はconditional nodeのようなchild graphに対応していません。そのため、本実装ではFunctional APIの使用時にはcublasSetWorkspaceを利用してworkspaceを事前に確保するようにしています。
