Blog
2024年夏季インターンシッププログラムでは「4週間グループ開発コース」を新たに設け、8月26日 (月) から9月20日 (金) までの4週間にわたってグループ開発インターンシップを実施しました。本稿では「GD02 データサイエンス」のテーマで実施した、最新気象レーダー「MP-PAWR」の観測データを用いた降水量予測の取り組みについてご紹介します。
こちらのタスクには、全国から集まったさまざまなバックグラウンドの学生16名にご参加いただき、5つのグループに分かれ、互いに競い合うデータサイエンス・コンペティションの形式で取り組んでいただきました。インターンのみなさんにとっては前例のない課題だったと思いますが、PFN にとってもこの規模でのコンペ形式でのグループ開発インターンは初めての取り組みでした。各グループで集中的に取り組んでいただき、すばらしい成果を得ることができましたので、ご紹介いたします。
目次
タスク概要
今回のコンペではマルチパラメータ・フェーズドアレイ気象レーダ (MP-PAWR) と呼ばれる新しい気象レーダーのデータを用いて、降水の現況の推定を行う Quantitative Precipitation Estimation をテーマとしました。この章では、このタスクを採用した背景とデータや評価指標について紹介します。
コンペ開催の背景
近年、豪雨による災害が増加していますが、ゲリラ豪雨に代表される局所的かつ突発的な大気現象の詳細や前兆を観測するためには、気象レーダーによるリアルタイム性の高い面的な観測が重要だと言われています。国立研究開発法人情報通信研究機構 (NICT) をはじめとする研究グループが世界に先駆けて開発した MP-PAWR は、降水粒子の観測範囲全体の3次元分布を約30秒で観測できる高速性と、複数偏波観測による高い粒子観測精度を両立した、きわめてユニークな特長を持っており、ゲリラ豪雨などの兆候をより迅速かつ正確にとらえることが可能です。一方で、現在広く使われているレーダー雨量の推定手法は、従来のレーダーの平面的な観測を前提とするものであり、MP-PAWR のリッチな観測をどのように降水量の推定に活かしていくかは非自明な問題でした。
PFN では、NICT とともに総務省から「リモートセンシング技術のユーザー最適型データ提供に関する要素技術の研究開発」(JPMI00316) という研究開発プロジェクトを受託しています (see also 「きゅむろん」を公開)。その中で、MP-PAWR の実課題への応用として、「MP-PAWR の観測からの降水量の推定」のタスクに取り組んでいます。最新の気象レーダーデータに対する機械学習による降水量推定という新しい取り組みに対して、様々なアイディア、アプローチを取り入れるために、複数のグループによるコンペティションの形式でインターンを開催しました。
今回は、観測と同時刻の降水の強度を推定する「現況」の推定をテーマとしました。天気予報のような将来の予測ではありませんが、現況の降水強度を推定するというのも重要なタスクです。もし既存のシステムの精度を大きく上回ることができれば、災害予防や公共交通機関の運用などさまざまな分野で活用が期待されます。また、MP-PAWR の観測から将来の降水を予測するモデルを構築するうえでも、現況推定での知見が大いに役に立つと考えています。
データ
MP-PAWR の観測は非常にリッチで容量も大きくなるため、今回のコンペでは時空間解像度を下げ、1分毎 500 m/pixel で提供しました。具体的には以下のとおりです。
- MP-PAWR の観測
- 偏波観測によって得られる ZH、ZDR、ρHV、種々の手法で計算した KDP などの特徴量 (参考資料)
- Cartesian 座標系のテンソル: (Z, Y, X) = (33 px, 241 px, 241 px) = (16 km, 120 km, 120 km)
- 約 7000 時間分
- 気象庁 AMeDAS で観測された 10 分間降水量
MP-PAWR の観測はこの解像度でも 2 TB 超となり依然扱いが難しいため、PFN インターン運営が提供した Baseline のために前処理された 300 GB 程度のデータも提供しました。また、インターン期間中の Public Discussion に投稿して運営の許可が出たものは External Data として使用可能とするルールを設け、解析雨量などいくつかの追加データが使用されました。
評価指標
AMeDAS 観測点が存在しない位置への汎化を評価するため、AMeDAS と異なる観測システムである POTEKA のデータを使って評価を行いました。テストデータの各観測点、各時刻についての推定結果を1時間雨量の形でまとめ、POTEKA の実測データとの一致度合いを Critical Success Index (CSI) を用いて評価しました。ある閾値 t について CSI@t は以下のように計算されます。
![]()
ここで、TP、FP、FN はそれぞれ閾値 t で二値化したときの True Positive、False Positive、False Negative の数です。図 1 に例を示します。
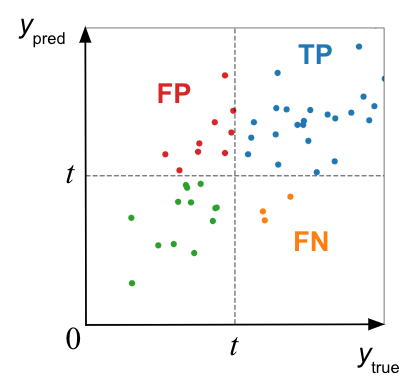 図1. TP、FP、FN の例
図1. TP、FP、FN の例
この CSI を [0.5, 1.0, 2.0, 4.0, 8.0, 16.0] の 6 つの閾値で計算した平均をスコアとして順位の決定に用いました。
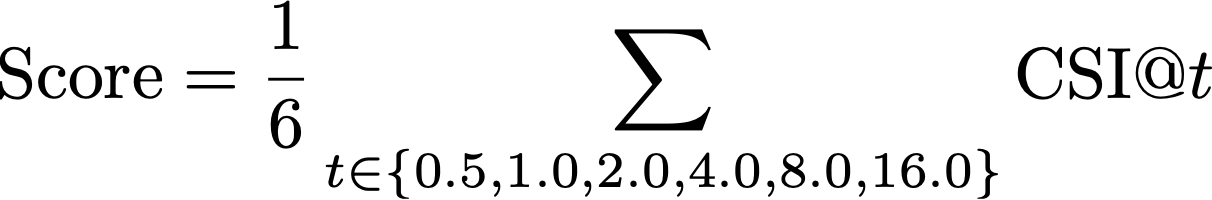
16 mm/h を超えるような強雨での性能も重要ではありますが、そのような強い雨のデータは少なく、少ないデータでの評価は評価結果のブレが大きくなってしまいます。運の要素を軽減し、コンペとして成立させるためにこのような設定としました。
環境
インターン生向けにコンペを開催するのは PFN としても初めての経験で、コンペ運営側にとっても試行錯誤の多い取り組みでした。ここではグループ開発インターン向けの計算環境や Submission の仕組み、インターン中のオフライン環境などを紹介します。
計算環境
チームごとに用意された JupyterLab にインターネット経由でアクセスできるような環境を Google Cloud Platform 上に構築しました。
具体的なインスタンスの構成としては、GPU が8枚搭載されたインスタンスを3台設置し、各インスタンスを2グループで使用しました。docker-compose を用いて各インスタンスで2個のコンテナを立ち上げ、その中で JupyterLab を起動しました。コンテナから使用できる GPU・CPU・メモリなどの計算資源やストレージを制限することによって、計算資源やソースコードの分離を行いました。
各チームの JupyterLab にインターネット経由でアクセスできるようにする方法として、Google Cloud Load Balancer を使用しました。安全なアクセスを確保するため、Identity Aware Proxy を使って Google アカウントによる認証を義務付け、自分のグループが割り当てられた JupyterLab にのみアクセスできるようにしました。
Submission/Leaderboard
運営からの Announce や Discussion を Slack で行うのに合わせて、Slack Bot を作成して Slack 上で「Submission」「過去の Submission の確認」「Final Submission の選択」を行えるようにしました。Submission の結果、いずれかのグループの Public Best Score が更新された場合は、Leaderboard 用の Channel に Leaderboard が画像で Post されるようにしました。
 図2. Slack bot のメニュー選択画面
図2. Slack bot のメニュー選択画面
オフィス環境
今回のグループ開発インターンは、グループでの議論や情報共有を活発に行えるよう、原則として毎日オフィスに出社していただく形で実施しました。大手町オフィスにある Cafe スペースには、休憩用のソファなどに加えて、業務用のブースやスタンディングデスクが備わっています。そのため、一般的な教室やオフィス環境と比べてにぎやかで、周囲に気兼ねなく気軽に議論を交わしながら、リラックスした雰囲気で業務に取りくむことができます。期待通り、各グループで活発に議論を交わしながら集中的に開発を進めていただきました。


 図3. インターン開発風景
図3. インターン開発風景
コンペ結果
コンペの結果を紹介します。
まず、コンペ期間中の Public Leaderboard の遷移を図 5 に示します。期間を通して継続的に改善していっていること、最終日まで追い越し追い越されのデッドヒートが繰り広げられていたことが確認できると思います。
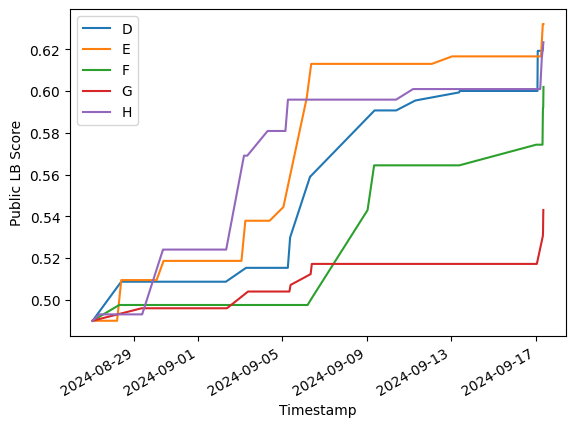 図4. Public Leaderboard Score の推移
図4. Public Leaderboard Score の推移
Private Leaderboard は図 6 の通りで Group E が優勝となりました🎉🎉🎉
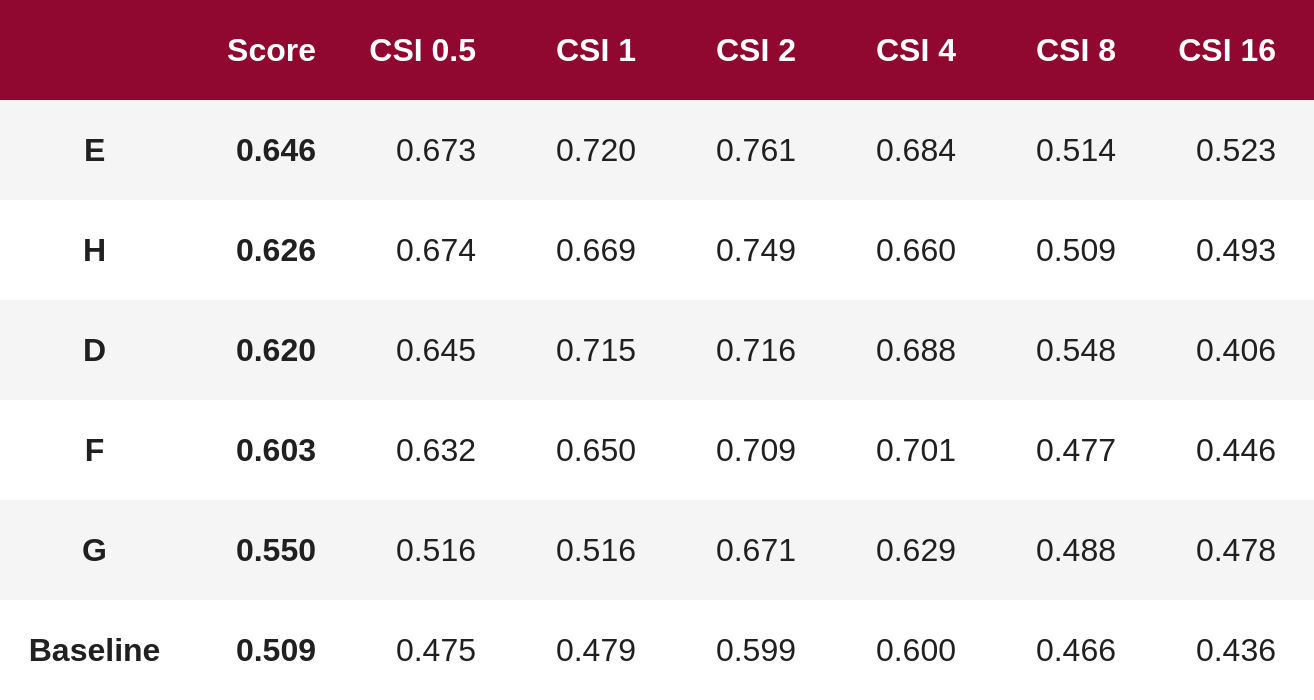 図5. Private Leaderboard
図5. Private Leaderboard
全グループがベースラインを大きく上回るスコアを達成しました。この結果がどの程度良いものなのかを伝えるために、図7 に既存のシステムである XRAIN と 解析雨量 (Analyzed Precipitation) との比較を示します。
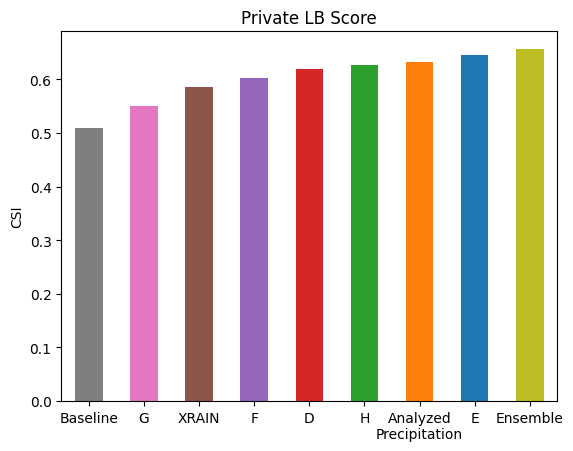 図6. 各グループと既存のシステムのスコアの比較
図6. 各グループと既存のシステムのスコアの比較
Group E のスコアは XRAIN のみならず解析雨量のスコアも超えていることが確認できます。XRAIN は複数のレーダーの観測を使用しており MP-PAWR から遠い地点に関して S/N 的に有利なこと、解析雨量は実際の雨量計の観測を使った補正によってリアルタイム性を犠牲に精度を向上させている推定結果であることを踏まえると、それらを MP-PAWR 一台の観測から上回ることができたというのは、とても素晴らしい結果だと考えています。
「Ensemble」で示したのは全グループの結果を線形結合したもののスコアで、Group E のみのスコアよりも改善していることがわかります。係数は Public テストデータで Fitting しているため多少有利な設定になっている可能性は否定できませんが、各グループのユニークな解法が予測結果の多様性を生み Ensemble 結果の改善に繋がったと考えています。
参加者の感想
優勝した E グループの3人に、参加者代表としてインターンシップの感想を伺いました。
八代康希さん(京都大学 M1)
この度は全チームが多様で素晴らしい解法を提案した中で優勝することができ、大変嬉しく思います。コンペティション形式ということもあり、優勝に向けてより意欲的に議論や開発に取り組むことができ、非常に刺激的で楽しい4週間となりました。予測精度を向上させるための綿密な調査やチーム内の活発な議論が結果に繋がったことは貴重な経験であり、今後の活動にも繋がると考えています。この4週間、密に協力し優勝に導いてくれたチームメンバー、そしてインターンシップを主催してくださった関係者の皆様に心より感謝申し上げます。
杉原壮馬さん(東京大学 M1)
グループでの機械学習コンペティションのような形式の開発に参加するのは初めてのことでしたが、優勝できて嬉しく思っています。我々のチームでは非常に活発に議論を行いながら開発を進めてきましたが、これはグループ開発ならではのことで、とても楽しくインターン期間を過ごすことができました。チームで協力しながらアイデアを出し、実装し、そして実際に降水量予測の精度が上がった時の喜びは忘れられません。自分にとって、今後研究、開発をしていく上で良い経験になりました。ありがとうございました。
染谷健太郎さん(東京工業大学 M1)
この度、優れたチームが多く参加する中で優秀な成績を収めることができ、大変光栄に感じております。初めて取り組んだ気象予測のタスクでしたが、PFN の社員の方々やチームメンバーのおかげで、非常に楽しく取り組むことができました。また、グループでの開発を通じて「Learn or Die」の精神を深める貴重な経験となりました。今回の経験を今後の研究や活動に存分に活かしていきたいと考えております。心より感謝申し上げます。
各グループの Solution
各グループの開発成果について、簡単にご紹介します。
Group D
メンバー:張 洪瑞、チァボシアン セイエッド モハマド、李 彦淳
Following rigorous data analysis and preprocesses such as data selection, we developed a solution centered on a highly accurate regressor, supplemented by targeted classifiers for specific precipitation ranges. Our regressor employs EfficientNet as the backbone and incorporates a Time Shift Module for temporal processing. A key innovation was the use of loss functions to address the imbalance in precipitation distribution. Additionally, we customized loss weights for different precipitation ranges to mitigate issues related to overfitting and under-fitting.
Despite these enhancements, the regressor exhibited weaknesses near certain threshold values, which we identified during extensive validations. To improve them, we integrated binary classifiers specialized in correcting predictions across specific precipitation ranges. For example, one classifier is dedicated solely to detecting the presence of any precipitation, critical due to the dominance of sunny days. Other classifiers were designed to adjust predictions around key precipitation thresholds, further enhancing our model’s overall performance.
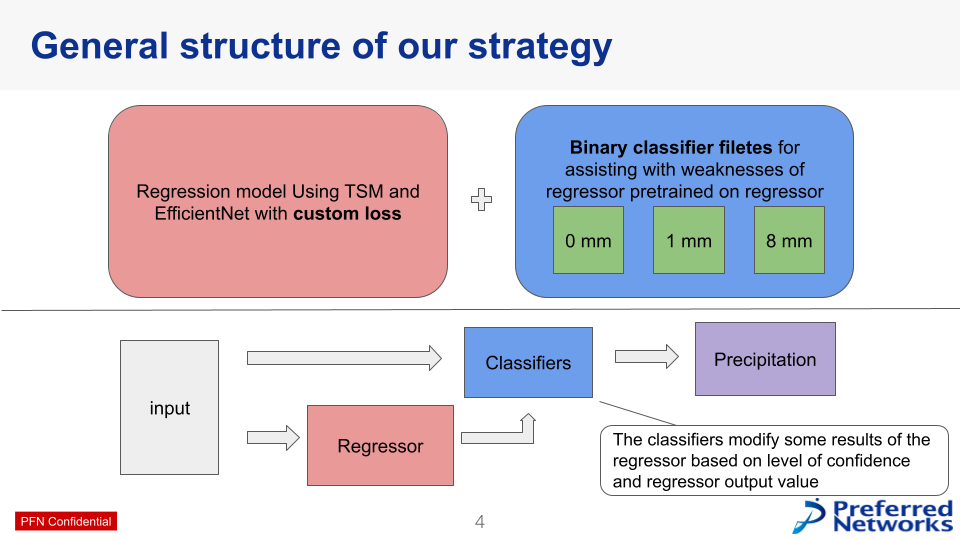 図7. Dグループの解法
図7. Dグループの解法
Group E
メンバー:八代 康希、杉原 壮馬、染谷 健太郎
前処理は特に重要度が高いと考え、データの特徴を考えて適切に行いました。また使用する特徴量についても手元の validation を参考にして決定しました。
先行研究を基に Multi-task 学習を実装しました。具体的には、降水量の回帰予測と降水量の分類タスクを同時に学習するようなモデルを提案しました。また損失関数を、エポックごとに切り替えるカリキュラム的な学習をしました。
奇抜な方法にこだわることなく、基礎的な手法を試していくことが結果的に精度向上に結び付きました。また上手くいかなかった提案手法も数多くありましたが、様々な手法を試すことで多くの示唆を得ることができ、開発を効率的に進めていくことができたと思います。
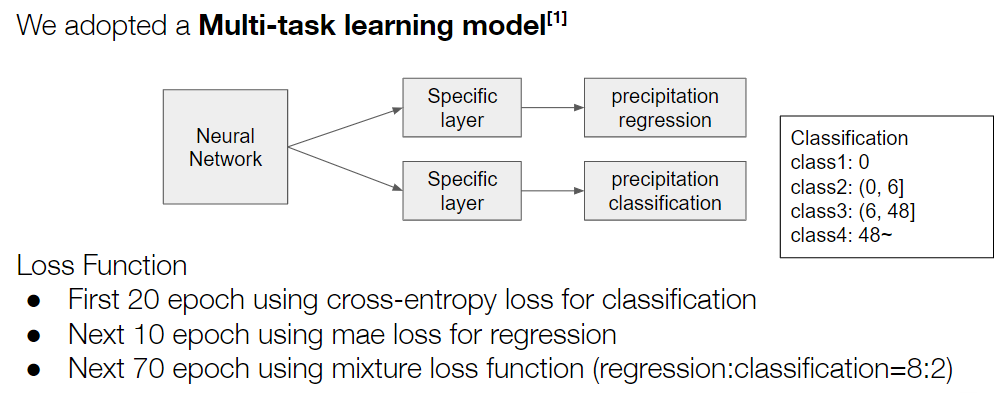 図8. Eグループの解法
図8. Eグループの解法
Group F
メンバー:鈴木 颯斗、佐藤 大地、高橋 創
データの分布とリークに気をつけ、データ分割を実施しました。分析から得られたデータの特性を考慮し、データの前処理を行いました。
降水量を推定するには「雲の高度 (Z)」と「過去 (時間T)」の情報が重要であると考え、入力の形式を工夫しました。具体的には、4次元 (XYZT) のうち、ZT の2次元スライスを XY 方向に並べた大きな画像を作成してモデルへの入力としました。CNN 系や ViT モデルを中心に検討した結果、CNN 系のモデルを採用し、降水量の回帰予測と分類でアンサンブル学習を実施しました。
問題の定式化からコードの構成に至るまで様々な議論を活発に行い、開発を進めることができました。メンターの中西さん初め、インターンの運営をしてくださった社員の皆様のおかげで楽しいインターン生活でした!ありがとうございました!
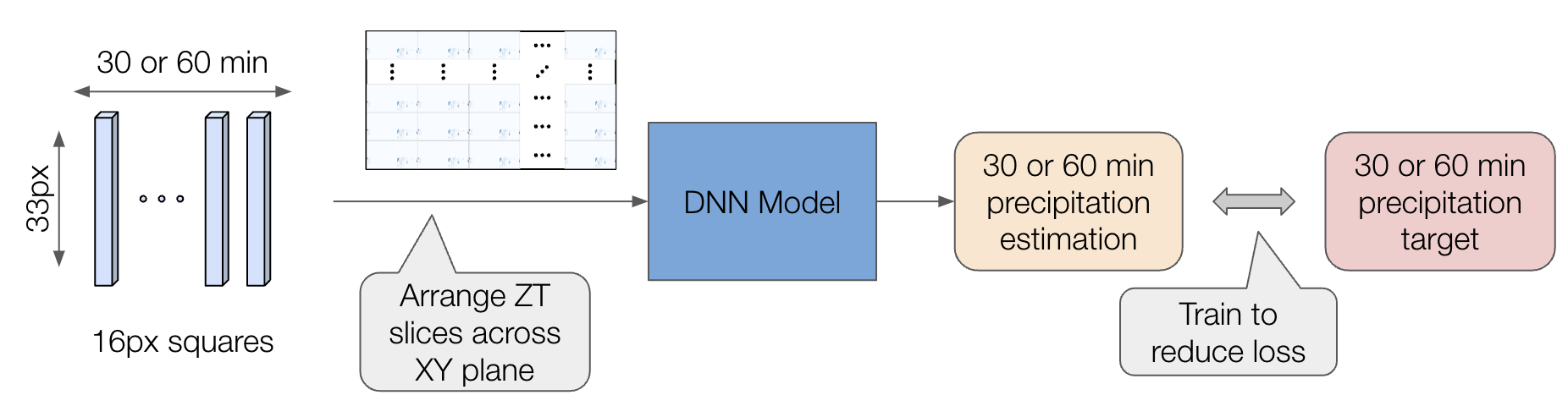 図9. Fグループの解法
図9. Fグループの解法
Group G
メンバー:上田 裕大、竹内 耀平、辻本
それぞれの特徴量の分布を可視化し、そこから補完など前処理の方法を検討しました。
今回開発したモデルは ResNet と Swin-transformer のアンサンブルです。Loss には高い降水量と低い降水量の差を強調させる工夫を加えました。Validation データで用いるデータを training データでも用いるため、K-Fold を活用しました。
スクラムプランニングによりタスクサイズの推定やタスクの優先順位を明確にし、効率的なチーム運営を心がけました。メンターの斉藤さんをはじめ、サポートいただいた社員の皆様に心より感謝申し上げます。
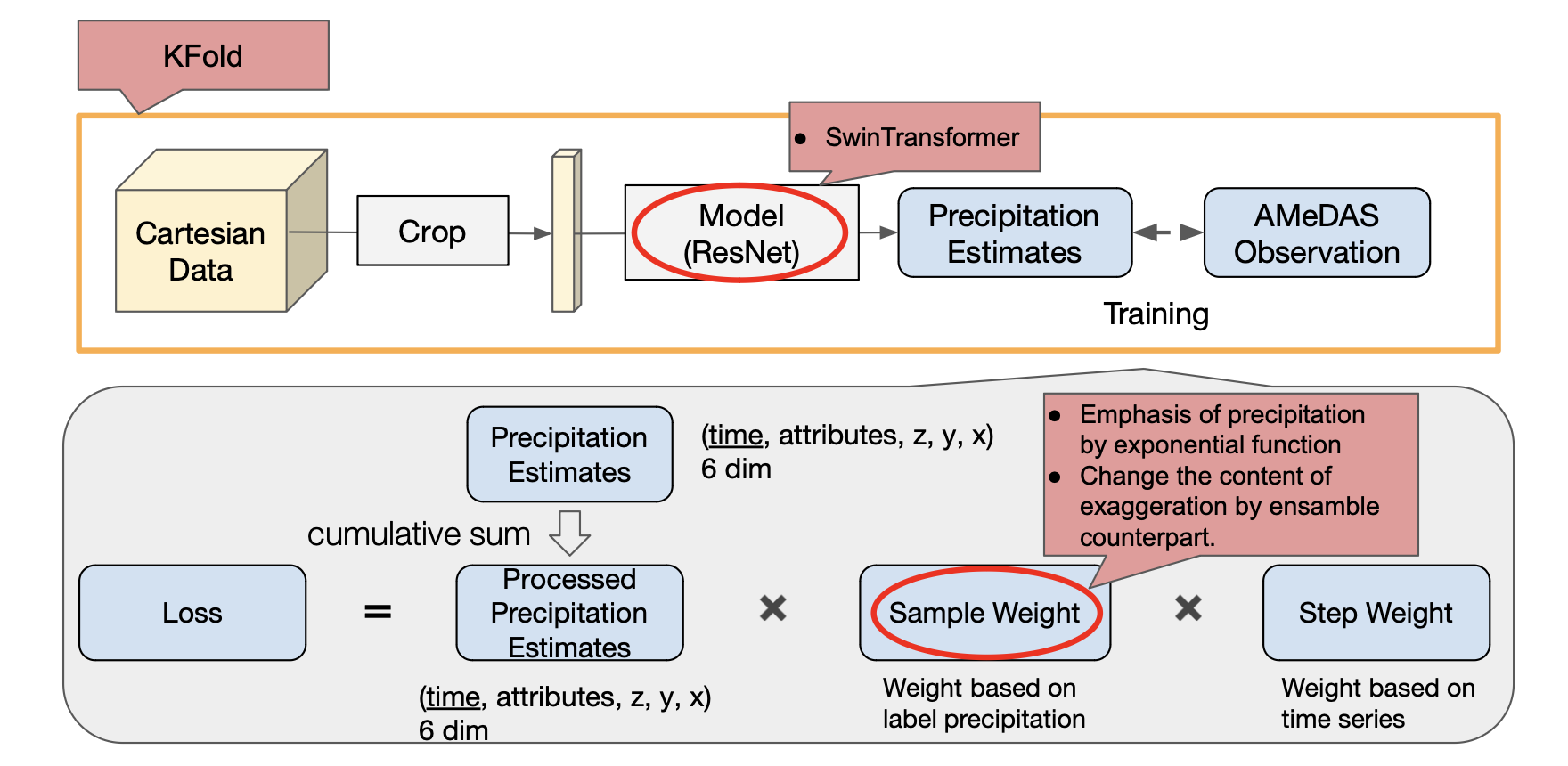 図10. Gグループの解法
図10. Gグループの解法
Group H
メンバー:秦 淇策、松本 佳晟、高橋 大翔、内藤 匠海
コンペの初期設定ではデータ量が少なかったこと、またデータの偏りの是正のために、解析雨量データを従来の正解ラベルの代わりとして用いるように加工し、学習データセットに加えました。
降水量が少ないところとそれ以外の部分での違いに着目し、特化モデルや汎用モデルを学習し、アンサンブルを行いました。各モデルは以下のように作成しました。RegNet ベースのモデルです。
- 低降水量帯特化モデル (~ 0.5 mm/h 未満):低降水量のデータを増やしデータの偏りを増やして学習
- 分類モデル (~ 2.0 mm/h 未満):データの偏りを是正して分類予測モデルとして学習
- 汎用モデル (その他の範囲に対応):データの偏りを是正して回帰予測モデルとして学習
低降水量帯の予測が得意なモデルを複数作成し、それらをルールベースでアンサンブルすることで予測を行いました。
結果は 2 位と惜しかったですが、この 4 週間を通して、楽しみながら様々なことを試行錯誤し学ぶことができました。インターンが終わっても Learn or Die の精神を大事にしていこうと思います!メンターの中本さんをはじめ、本インターンのサポートをしていただいた社員の皆様、本当にありがとうございました。
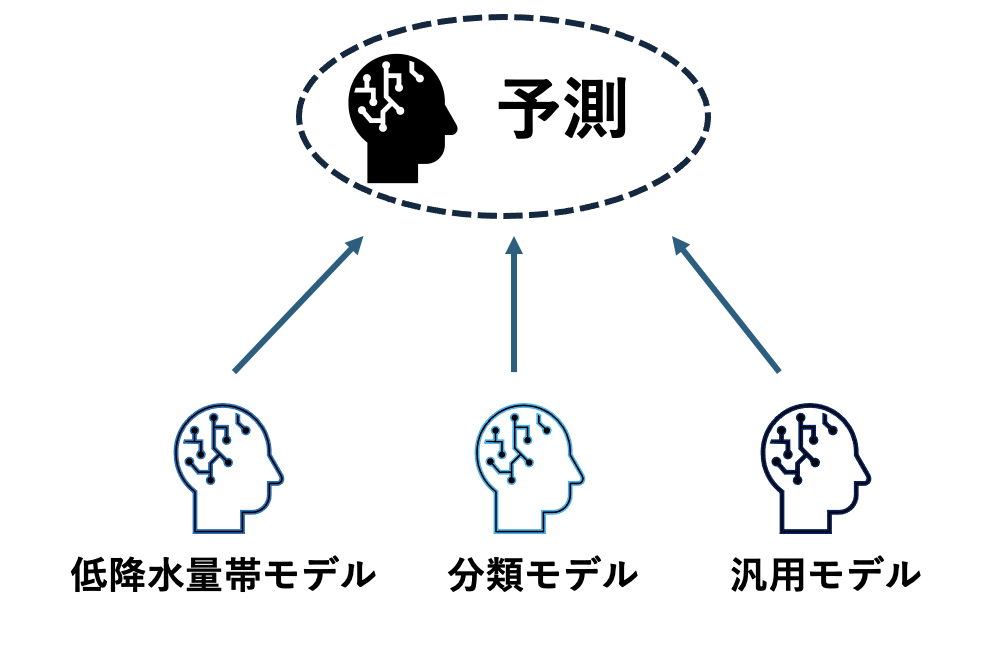 図11. Hグループの解法
図11. Hグループの解法
おわりに
今回のグループ開発インターンシップの「GD02 データサイエンス」テーマでは、最新の気象レーダー MP-PAWR を用いた降水量予測という挑戦的なテーマに対して、コンペの形式で取り組んでいただきました。インターン生の皆さんが発揮した創意工夫により、既存のシステムを上回る素晴らしい結果が得られ、運営チームとしても非常に喜ばしく思います。この経験がインターン生の皆さんの今後の学びやキャリアに役立つことを願っています。
本インターンプログラムは、総務省から受託した「リモートセンシング技術のユーザー最適型データ提供に関する要素技術の研究開発」(JPMI00316)の支援を受け行われました。ここに感謝します。
Preferred Networks では一緒に働くメンバーを募集しています。みなさまのご応募をお待ちしています!



