Blog
はじめに
AutoSamplerは、状況に応じてOptunaに実装されているものの中からSamplerを自動で選択し、解の探索を行います。ユーザは、下記のコード例のようにAutoSamplerを使用するだけで、最適化アルゴリズムの使い分けを意識することなく、Optunaのデフォルトと比較して同等かそれ以上の最適化パフォーマンスを得ることができます。
study = optuna.create_study(
sampler=optunahub.load_module(
"samplers/auto_sampler"
).AutoSampler() # 内部でアルゴリズムを自動選択
)
本記事では、OptunaHubに10月31日に公開されたAutoSamplerについて、「なぜ最適化アルゴリズムの使い分けが必要なのか」といった背景やSamplerの自動選択ルールの設計方針について共有し、その後、具体的な利用方法や簡易的なベンチマークの結果を紹介します。
なぜ最適化アルゴリズムの使い分けが必要なのか
この世界には様々な最適化問題が存在し、対して学術界では様々な新しい最適化アルゴリズムが提案され続けています。その背景にはいくつかの事情が存在します。
様々な問題設定が存在することはそのなかでもとりわけ大きな課題のひとつとして知られています。整数変数を含むケース、目的関数が複数存在するケース、評価回数が少ないケースへの対応をはじめとして、ほかにも様々な問題設定があります。このような問題設定に上手く対応するため、日々新しいアルゴリズムを提案・改良する研究活動がなされています。
これに対して、Optunaの公式ドキュメントでは問題設定に応じたアルゴリズム選択の手助けとなるようSampler比較表を公開しています(表1)。この表を参照することで、ユーザは各種問題設定のサポート状況や最大評価回数から利用すべきSamplerの候補を簡単に知ることができます。
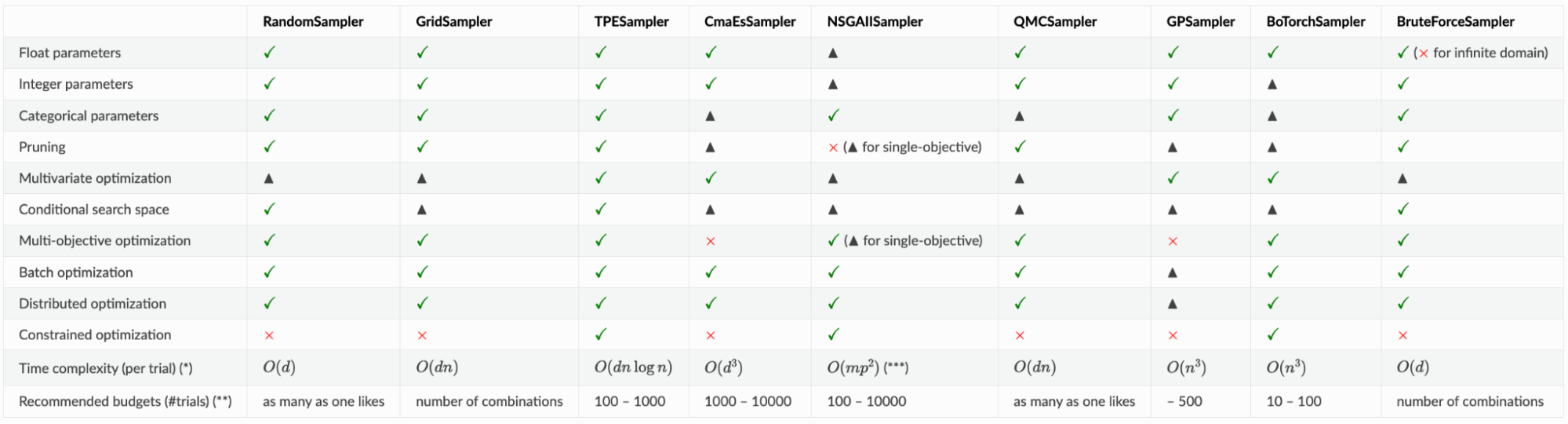
表1: Sampler比較表
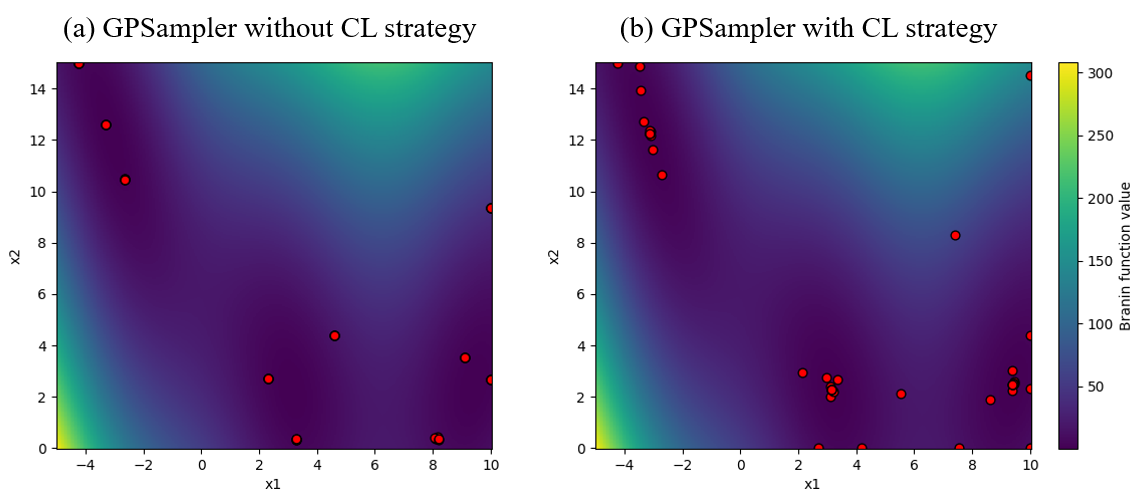
Optunaは、様々な問題に上手く対処できるよう異なる特徴を持った多数のアルゴリズムを取り揃えています。アルゴリズムの違いをみるために簡単な例を示します。図1左はベンチマーク関数(8次元のStyblinski-Tang関数)に対してGPSamplerとCmaEsSamplerを用いてそれぞれ最小化を行った結果例です。図1右は関数の持つ変数のうち半分 (x4-x8) を整数変数に置き換えて同様に実行した結果例です。前者ではあまり差が見られません(この実行例ではCmaEsSamplerが僅かによい結果です)が、後者ではGPSamplerが大幅によい結果を達成しています。これはOptunaのGPSamplerが相対的にCmaEsSamplerよりも整数変数の扱いに長けているためです。
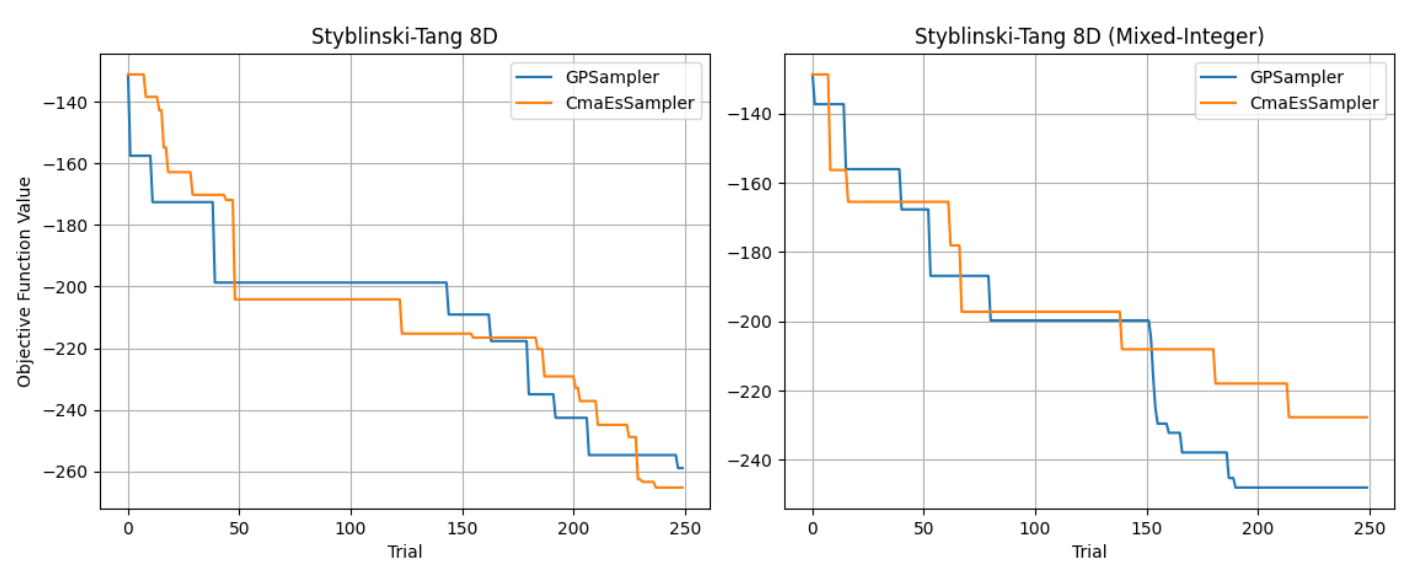
図1: 問題ごとにSamplerがよい性能を達成できるかどうかは変わりうる
このように、問題に対するアルゴリズムの適切な使い分けは極めて重要です。しかしながら、ユーザにとって各種アルゴリズムの動作原理や特徴・得手不得手を理解し選択を行うことは高度な専門性を要する難しいタスクであり、大きな負担といえるでしょう。
AutoSampler
今回、Optuna開発メンバーはSampler比較表からさらに一歩踏み込んで「Samplerの特徴理解や選択に労力を割かずに上手く問題を解きたい」というユーザの課題を解決するための機能であるAutoSamplerを開発しました。AutoSamplerは、以下の2点を実現するために設計されたSampler選択ルールを備えており、最適化中にOptunaの提供するSamplerの中から適切と思われるものを自動的かつ動的に内部で選択します(図2)。
- 評価回数、探索空間、制約の有無や目的数等の問題設定に応じて、それらを適切に扱えるSamplerを自動選択する
- デフォルトのSamplerを常に用いた場合と比べて、経験的に同等かより良い探索結果が得られるようにSamplerを自動選択する
特に2点目については、ハイパパラメータ最適化などOptunaユーザが頻繁に出くわす問題例(目的関数)には偏りがあるという経験から、Optuna開発メンバーのノウハウに基づく「常にデフォルトSamplerを用いるよりも優れたSampler選択ルール」の具体化を試みました。*¹
図2: AutoSamplerのイメージ
AutoSamplerのSampler自動選択アプローチの一例を挙げると
- 探索序盤はサンプル効率に優れているが推奨される評価回数の少ないGPSamplerを用いる
- カテゴリ変数を持つ問題にはそれを柔軟に扱えるTPESamplerを用いる
などがあります。また、AutoSamplerには最適化中のダイナミックな手法の切り替えの際に性能を高められるような実装上の工夫等も施されています。
AutoSamplerの利用方法
OptunaHubに公開されているAutoSamplerを利用するのは非常に簡単です。
まず、OptunaHubに公開されているパッケージ(機能)を利用するために必要なoptunahubライブラリをはじめとする依存関係を環境にインストールします。
pip install optunahub pip install -r https://hub.optuna.org/samplers/auto_sampler/requirements.txt
そして、optunahub.load_module関数を用いて "samplers/auto_sampler" パッケージを読み込み、パッケージに含まれるAutoSamplerを実体化するだけです。以下にコピー & ペーストで実行可能なコード例を記載します。
import optuna
import optunahub
def objective(trial: optuna.Trial) -> float:
x = trial.suggest_float("x", -1, 1)
y = trial.suggest_float("y", -1, 1)
return x**2 + y**2
study = optuna.create_study(
sampler=optunahub.load_module(
"samplers/auto_sampler"
).AutoSampler()
)
study.optimize(objective, n_trials=300)
print(study.best_trial.value, study.best_trial.params)
性能評価
AutoSamplerの有効性を実証するために、ベンチマーク関数を用いて簡易的な探索性能の比較評価を行いました。図3にMishra06(2), Hartmann6(6), McCourt11(8)(括弧内は問題の次元数)に対する最適化結果を示します(ベンチマーク関数の実装はこちら)。また、2次元関数であるMishra06(2)については関数値の等高線を可視化したランドスケープ図(図3右上)も併載しています。このランドスケープ図の縦軸、横軸は2つの変数に対応し、色が目的関数値に対応します。濃い色の箇所がよい目的関数値の場所を示しています。
結果からは、乱数要素の強い探索の最序盤を除いて、一貫してAutoSamplerがデフォルトのTPESamplerと同等か上回るパフォーマンスを達成できていることが確認できます。まず、灰色の点線に着目すると、AutoSamplerは1/10未満のTrial数でデフォルトの1000 Trials時点でのベストを上回る解を発見出来ています。次に、塗りつぶしの帯の狭さから探索の安定性もデフォルトより高いことが伺えます。
個別の問題の結果について見ていくと、Mishra06(2)ではAutoSamplerもTPESamplerも400 Trialsに至る前に目的関数値の改善が見受けられなくなり、何らかの局所解に収束している印象ですが、最終的な目的関数値には大きな差があり前者の方が平均的に良質な解を発見できています。Hartmann(6)では、最終的な目的関数値には大きな差はありませんが、収束に至る早さで大幅にAutoSamplerが優れていることが伺えます。McCourt11(8)では、いずれの手法も目的関数値の改善が最後まで続いており探索は収束に至っていませんが、目的関数値の改善ペースからHartmann(6)と同様にAutoSamplerの方が探索効率に優れていることが読み取れます。
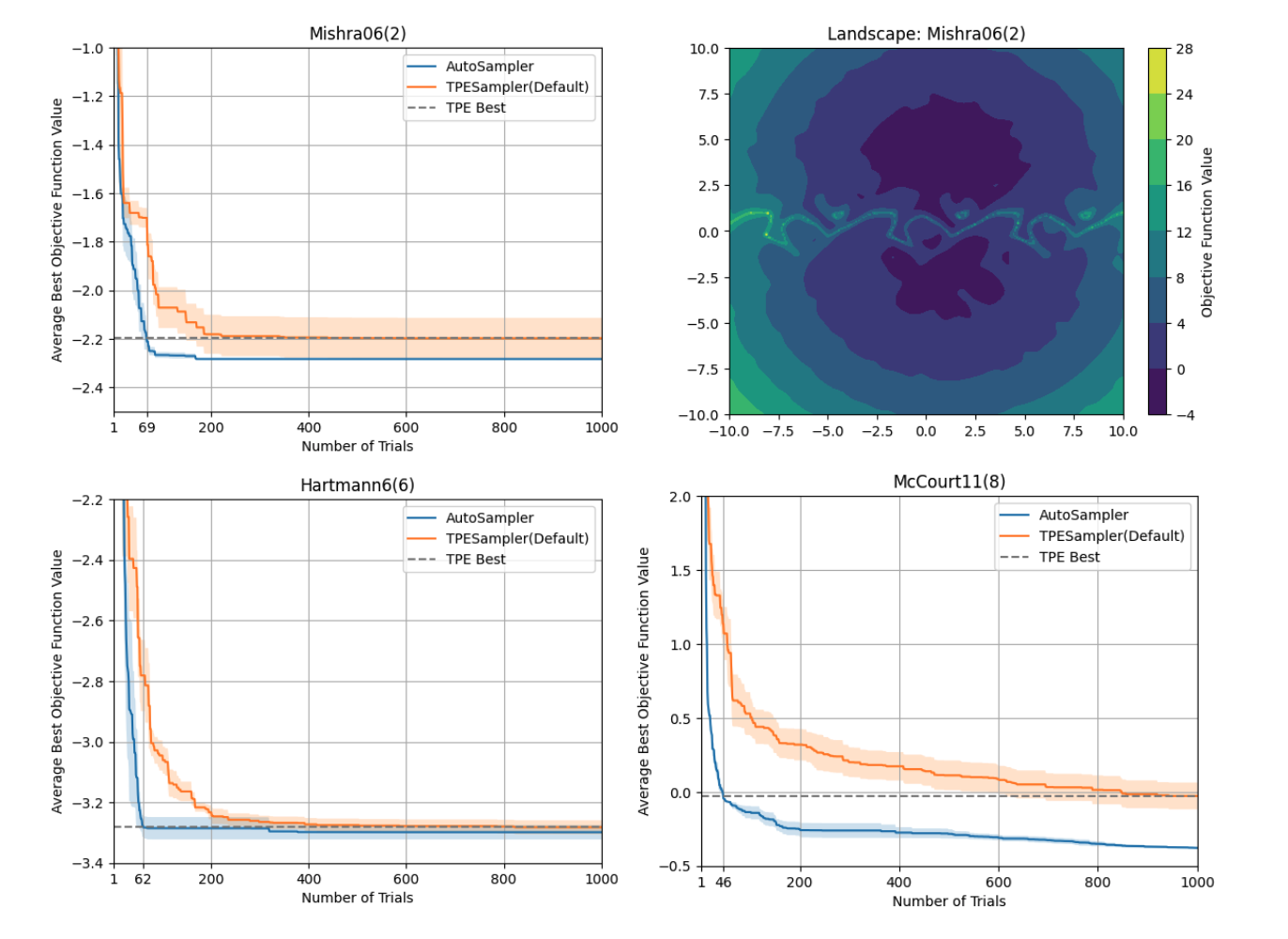
図3: 実験結果。実線はランダムシードを変更した5試行の平均値、塗り潰しは±標準誤差を表します。灰色の点線はTPESamplerが見つけた最良の解の評価値です。点線と交わる縦の灰色の線の目盛りは、その評価値をAutoSamplerが達成したときの評価回数です。
おわりに
Optunaの最適化アルゴリズムを自動選択するAutoSamplerについて紹介しました。AutoSamplerはユーザが最適化アルゴリズムの使い分けを意識することなく経験的にデフォルトSamplerと同等か上回る性能を得ることができる大変便利な機能です。*² 簡単に利用できるので、是非一度お試し下さい!
今回公開した最初のバージョンのAutoSamplerには多目的最適化や制約付き最適化の場合、デフォルトにフォールバックしているなど、まだまだ改善の余地があり、今後も改良を続ける予定です。AutoSamplerをよりよいものにしていくために、ユーザの皆様からのフィードバックを積極的に求めています。使用した感想や改善要望などがあれば気軽にOptuna Discussionsの当該スレッドに投稿をよろしくお願いいたします!
補足
*¹ ノーフリーランチ定理が存在するため、森羅万象あらゆる問題にかけての平均性能はすべての最適化アルゴリズムで等しくなることが数学的に証明されています。そのため、最適化アルゴリズムの優劣を語る上ではターゲットとする問題について何らかの仮定が必要です。
*² 読者の中には「なぜAutoSamplerをデフォルトにしないのか?」と疑問に思われる方がいらっしゃるかもしれません。ソフトウェア開発においては、最適化性能以外にも検討すべき点が多くあり、デフォルトはそれらを総合的に考えた際のバランスにおいて優れています。一例として、AutoSamplerはGPSamplerのようなExperimentalな機能やcmaesやtorchといった追加のパッケージに依存していますが、デフォルトにはそのような依存はありません。