Blog
この記事は、パートタイムエンジニアの司 怜央さんによる寄稿です。
はじめに
インターネットで医療に関する情報を検索する際、数多くの不正確な情報に遭遇することが多いです。特に、がんは患者の命にかかわる場合があり、正確な情報を提供することが重要です。この問題を解決するためには、信頼できる情報源を基にした情報提供が必要とされています。信頼できる情報源として、在宅がんウィット(https://ganwit.jhocc.jp)やがん情報サービス(https://ganjoho.jp/)があります。在宅がんウィットは一般財団法人在宅がん療養財団が、がんを患った方が在宅で過ごすときに役立つ情報をQ&A形式で提供しているサイトで、がん情報サービスは国立がん研究センターが、がんに関する情報を提供しているサイトです。在宅がんウィットに寄せられた質問の回答には、医療従事者から成るチームが回答案を作成・レビューしているため、回答の作成に時間がかかり、回答できる数にも制約がある問題が生じています。このように、現状では専門家のレビューを受けた質の高い回答は、多くは作り出せない問題があります。 しかし、最近の大規模言語モデル(LLM)の登場で、状況は変わりつつあります。LLMは高度なテキスト生成能力を有しており、このLLMの高いテキスト生成能力の活用により、一人一人の状況に応じた、きめ細やかな情報提供が可能になることが期待されています。ただし、LLMは専門的な知識に関して誤った情報(ハルシネーション)を生成するリスクも存在します。この問題に対処するため、Retrieval-Augmented Generation(RAG)と呼ばれる技術を活用しました。RAGは、LLMに外部の情報を組み合わせることで、出力される情報の精度を向上させることができます。具体的には、がんに関する質問への回答精度を高めるために、RAGを用いて在宅がんウィットとがん情報サービスの外部情報を参照するチャットボットの研究を行いました。なお、本研究は現在研究段階であり、診断目的での使用は想定しておりません。
方法と結果
ベンチマークの作成
RAGの評価を行うため、がんに関する質問のベンチマークの作成を行いました。ベンチマークの質問は、実際のがん患者が抱える疑問に近い内容を取り入れました。質問とPLaMoによる回答の例を図1に示します。

図1. ベンチマークの質問と回答の例
ベンチマークの質問に対する回答を調査した結果、特にSMARCA4など近年報告された疾患はRAGを用いることで回答の精度が向上することが分かりました(図2)。

図2. RAGにより回答が改善した例
外部情報の分割
RAGにおいては、質問と関連する外部情報を取り出すために、まず外部情報をLLMのエンコーダーによってベクトルに埋め込みます。同様に、与えられた質問もエンコーダーによってベクトルに変換します。そのあと、外部情報のベクトルと質問のベクトルの類似度を計算することで、質問と関連性の高い外部情報を特定することができます。このプロセスを行うためには、外部情報を適切に分割しておくことが重要です。一定のチャンクサイズで分割する方法がよく用いられますが、外部情報をmarkdown形式で管理し、ヘッダー(#や##など)によって意味のある単位で区切ることによって、より精度の高いベクトル検索が可能になることが分かりました。
multi query
multi query retrieverシステムを導入することで、類似の質問を複数生成することで回答の精度を向上させることができました。multi queryはLLMを用いることで、1つの質問に対して類似した複数の質問を生成し、それぞれにベクトルの検索を行う手法です。これにより、より豊かな情報が含まれた検索結果を提供できるため、回答精度を向上させることができます。
モデルの比較
独自のベンチマークを用いた医師によるスコアリング評価では、OpenAI社のLLMモデル(GPT-4oやGPT-4o mini)とPreferred Networks社のPLaMoモデルを比較し、PLaMoは4oと比較と同等の精度を示しました。在宅がん療養財団に試験的に使用していただいたところ、こちらでも精度は同等であるという評価をいただきました。(※)
また、すべてのモデルに共通の問題として、薬品名のカタカナ表記に誤りが見られる場合がありました。英語表記では正確であることから、一度薬品名を英語で出力し、日本語に変換することで正確な情報が提供できる可能性があります。
※ 当初、PLaMo にはコンテキスト長の制限が小さめであったため、出力が途中で切れることがまれにありました。この問題は研究を行っていた当時は解決できなかったものの、その後、4倍のコンテキスト長を入力できるようになるPLaMoモデルのアップデートによって解決しました。(https://tech.preferred.jp/ja/blog/extending-plamo-context-length/)。
プロンプトの指示とtemperature
正確な薬品名を出力させるため、PLaMoが指示されたプロンプトに基づき薬品名を英語で出力させられるかどうかを調べました。試験には「ナイトロジェンマスタード系のアルキル化剤に分類される抗腫瘍薬は?」という質問を用い、PLaMoの応答を調査しました。プロンプトは2種類用意し、1つ目は単に薬品名を英語で出力するよう指示し、2つ目は質問と回答の例を複数提示し、few-shot学習を行いました。出力のばらつきを変化させるために、temperatureパラメータは0、0.3、0.7、1.0の設定で試しました。PLaMoの応答の評価は、出力された薬品名がどれだけ英語表記であるかに基づいて行われました。具体的には、薬品名が完全に日本語であれば0点、日本語と英語が混在していれば0.5点、完全に英語であれば1点と採点されました。各設定で3回の出力を行い、それぞれの平均スコアを算出しました。結果は図3にて示されており、質問と回答例をプロンプトに加えた場合や、temperatureが高い設定で、PLaMoが薬品名を英語で出力する傾向が強いことが確認されました。
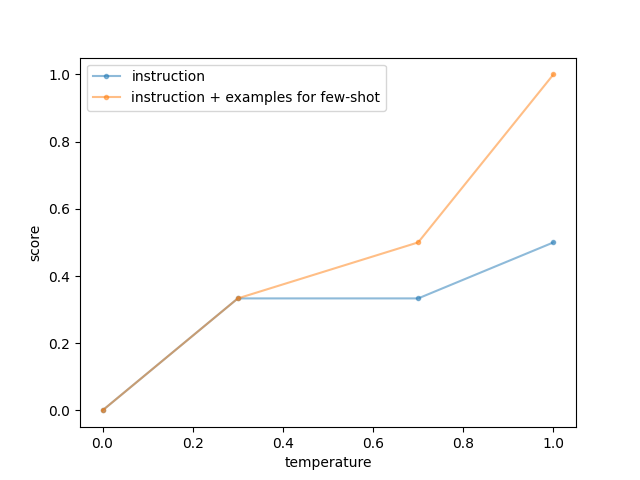
図3. PLaMoが指示に従うかどうかは、プロンプトやtemperatureに影響される
まとめ
がんに関する情報の精度を向上させるため、Retrieval-Augmented Generation(RAG)を用いて、信頼できる情報源を参照した医療チャットボットの開発を行いました。独自のベンチマークを作成することで、医療的な質問に対して回答の精度の向上する条件を明らかにすることができました。
謝辞
本課題の遂行にあたって、データやフィードバックを提供してくださった一般財団法人在宅がん療養財団の皆様、特に会長の児玉龍彦東京大学名誉教授に感謝申し上げます。また、環境整備や議論に加わっていただいたPFNの社員の皆様、特にメンターを務めてくださった岩澤さん、小田さんに感謝申し上げます。
