Blog
はじめに
皆さん、こんにちは。Optunaコミッタの今村です。皆さんは、ブラックボックス最適化フレームワークOptunaを利用していますか?Optunaは単一のプロセスだけでも動作する便利なフレームワークですが、実は外部の関係データベース(Relational Database, RDB)と連携することで、最適化結果を永続化したり分散最適化を実施したりする事ができます。
Optunaでは、RDBとの連携のためにRDBStorageというクラスが用意されています。RDBStorageはOptuna v1.0.0の頃から存在しましたが、その処理性能はバージョンを経るごとに改善しており、特にv4.1.0では数万規模のトライアルを高速に処理できるように大きく改善されました。本稿では、我々がOptuna v4.1.0で実施したRDBStorageの高速化に向けての取り組みをご紹介します。
TL;DR
- RDBStorageがRDBに発行するSQLクエリの詳細を分析・改善することで、最大63%程度速度性能が改善しました。
- Optuna開発では、データベースの知識・経験を持った人材が活躍できる場が多く存在します。興味のある方はぜひGitHubで開発に参加してみて下さい!
RDBStorageとは
RDBStorageは、OptunaにおいてRDBと連携して最適化結果を永続化したり分散最適化を実行したりするための機能です。多くのユーザにとって RDBStorageの実体を気にせずとも利用できるように、以下のようにStudyを作成する際のstorage引数にSQLAlchemyのEngine URLを文字列として渡すだけで有効化されます。
コード1: URLを渡すことでRDBStorageを用いる例
import optuna
study = optuna.create_study(
study_name="test_study",
storage="mysql://root@localhost/example",
)
上記のコードではMySQLサーバのURLがoptuna.create_study関数のstorage引数に渡されているので、準備として以下のようにローカルのPCにMySQLを利用したRDBサーバを起動しておきましょう。インストールガイドを参考に、必要に応じてMySQLをインストールしてください。
mysql -u root -e "CREATE DATABASE IF NOT EXISTS example"
コード1は以下のようにRDBStorageを直接インスタンス化してstorage引数に渡すことと等価です。
コード2: RDBStorageのインスタンスを渡すことでRDBStorageを用いる例
import optuna
storage = optuna.storages.RDBStorage(url="mysql://root@localhost/example")
study = optuna.create_study(
study_name="test_study",
storage=storage,
)
このようにStudyを作成すると、MySQLサーバにStudyの情報が永続化されます。作成したStudyはプログラムが一度終了した後に読み込む事ができ、最適化を再開したい場合や最適化終了後の分析を行いたい場合に利用できます。
RDBStorageの利用方法については公式から提供されている以下のチュートリアルをぜひ参考にしてみて下さい。
v4.1.0でRDBStorageがどのように高速化されたか
Optunaは元々機械学習のハイパーパラメータ最適化向けに開発されたソフトウェアです。そのためトライアル数としては高々数百程度を想定して設計されており、RDBStorageの処理能力もそれに見合ったものでした。ところがOptunaの応用領域が、機械学習のハイパーパラメータ最適化から材料探索シミュレーションなどの多様なブラックボックス最適化問題に広がっていくにつれて、要求されるトライアル数は増大を続け、現在では数万規模のトライアルを数百並列で処理できる性能が求められつつあります。RDBStorageが数万規模のトライアルを高速に処理できるように、Optuna v4.1.0では以下のような取り組みを実施しました。
- RDBStorage.get_all_trialsにおける差分更新の単純化 (#5704)
- RDBStorage.set_trial_paramにおけるSELECT文の数を削減 (#5709)
- RDBStorage.set_trial_user_attr/set_trial_system_attrにおけるUPSERTの導入 (#5703)
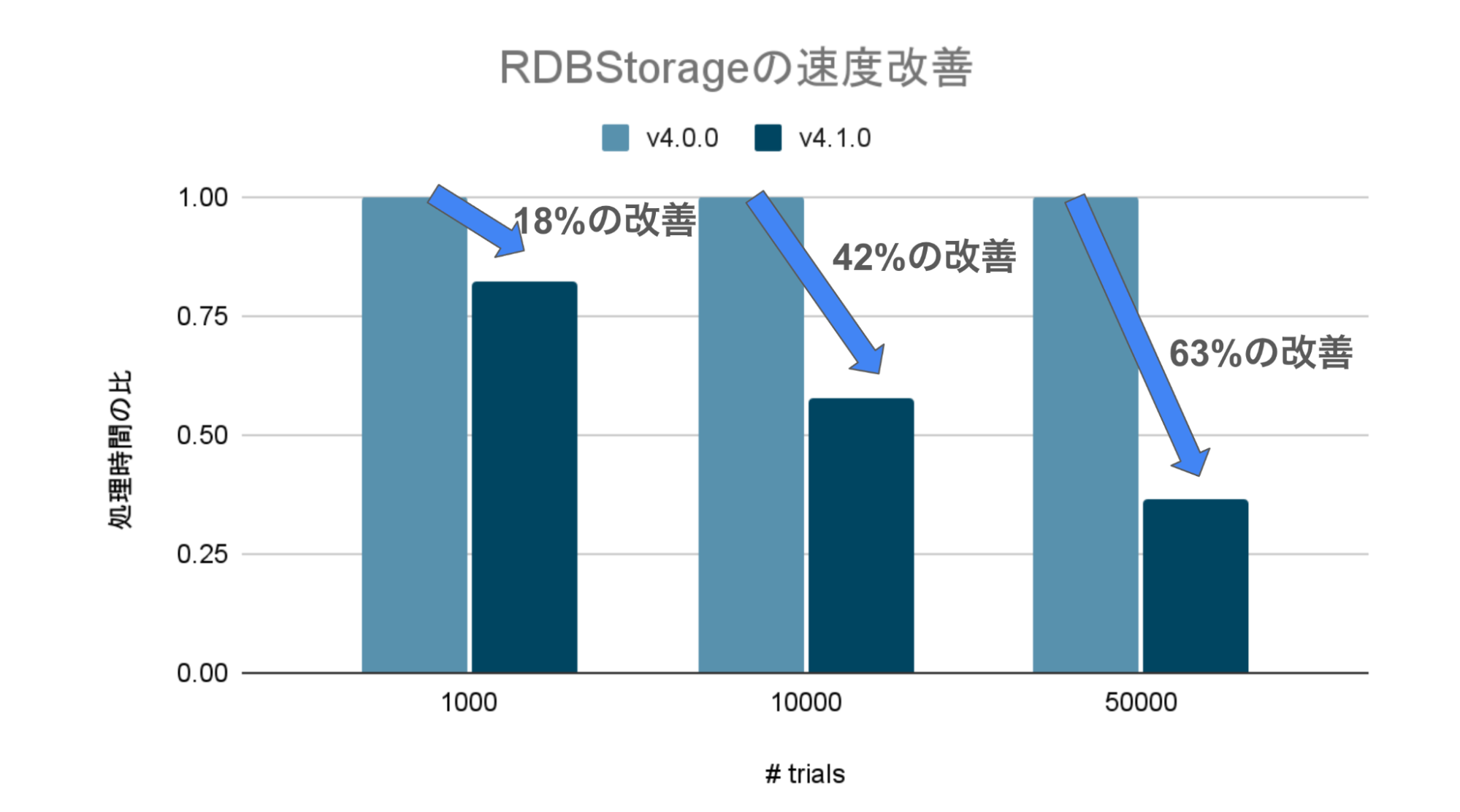
これらの取り組みによってv4.1.0ではRDBStorageの速度がv4.0.0に比べて下図のように改善しました。下図では、v4.0.0に比べたv4.1.0のRDBStorageの速度の比を示しています。詳細な実験結果は速度比較ベンチマーク結果のセクションで説明します。
以下、それぞれの取り組みについて簡単に説明します。
RDBStorage.get_all_trialsにおける差分更新の単純化
RDBStorage.get_all_trialsは、Study.get_trialsといったトライアルの一覧を取得する際に呼び出されるメソッド内で呼ばれ、どんなOptunaの応用でも毎トライアル必ず呼び出される処理です。予備実験としてcProfileを用いたプロファイリングを実施し、その結果からこのメソッドがボトルネックであると特定して高速化を実施しました。
RDBStorageは内部にキャッシュ層を持っており、毎回全てのトライアルをRDBから取得することなく差分更新を行うよう実装されています。v4.1.0未満のOptunaでは、トライアル一覧の取得を2回のステップに分けて実行していました。まず最初のステップでは、キャッシュの有無にかかわらず取得対象となるすべてのトライアルID一覧を列挙、次のステップでキャッシュと照らしあわせて差分となる新しいトライアルの情報を取得していました。
これに対してOptuna v4.1.0では、前者のステップを省略することでクエリを単純化しています。結果として各get_all_trialsの呼び出しにおけるRDBへのクエリ回数が減少し、処理が大きく高速化されました。
RDBStorage.set_trial_paramにおけるSELECT文の数を削減
RDBStorage.set_trial_paramは、OptunaにおけるサジェストAPI (Trial.suggest_floatなど)の中で呼び出され、サンプルしたパラメータの値をRDBに保存する処理です。下記の例に示す10個のパラメーターをサンプルする目的関数では、10回の trial.suggest_float の呼び出しに対して合計40回のSELECT文が(すなわち、1回の呼び出しに対して4回のクエリ)実行されていました。
def objective(trial: optuna.Trial) -> float:
s = 0
for i in range(10):
s += trial.suggest_float(f"x{i}", -10, 10) ** 2
return s
4回の内訳は次のとおりです。下記に示す4回のクエリ発行のうち、2回目と3回目のクエリは実装の修正により省略しました。結果として上記の例では、trial.suggest_float()メソッドが発行するクエリ回数が40回から20回に減らすことができます。
- SELECT * FROM trials WHERE trial_id = ? : Trialのstateを取得し、そのTrialが更新可能かどうかをチェックします。
- SELECT * FROM trial_params WHERE trial_id = ? AND param_name = ? : 同じparam_nameがすでにセットされているかを確認します。存在したらUPDATE、存在しなければINSERTを発行しますが、UPSERTに変更することでこのクエリは不要になります。
- SELECT * FROM trials WHERE trial_id = ? : 1つめのクエリで取得している内容と重複しており実装の修正により省略できます。
- SELECT * FROM trial_params JOIN trials ON … WHERE study_id = ? AND param_name = ?`: 過去のTrialでサンプルされているパラメーターの定義との一致を確認します。
RDBStorage.set_trial_user_attr/set_trial_system_attrにおけるUPSERTの導入
RDBStorage.set_trial_user_attrおよびRDBStorage.set_trial_system_attrは、それぞれTrialのユーザアトリビュートおよびシステムアトリビュートを設定する処理です。Optuna v4.1.0未満は、アトリビュートの設定のためには当該アトリビュートの名前で既に値が登録されているかをチェックし、されていれば値を更新・されていなければ新しく値を追加するという処理が行われていました。
Optuna v4.1.0では、これを一つのSQLクエリで実施するいわゆる”UPSERT”という処理に変更しました。Optunaでは主にSQLiteやMySQL、PostgreSQLといったデータベースをメインターゲットに開発を進めていますが(他のRDBを全くサポートしていないわけではありません。)、この内我々はSQLiteとMySQLでのみUPSERTに相当する処理をサポートしています。そのためPostgreSQLでは従来通りの処理にフォールバックされています。SQLiteやMySQLをRDBとして使っている場合は、set_trial_user_attrおよびset_trial_system_attrのRDBへのクエリ回数が半減することになり、処理の高速化が期待されます。
速度比較ベンチマーク結果
RDBStorageが実際にRDBに発行するSQLクエリを分析し、不必要な処理を単純化し数を削減することで、Optuna v4.1.0では大幅な高速化を達成しました。実際に以下のような単純な速度に関するベンチマークプログラムによって、高速化の程度を評価することができます。
import optuna
import time
import os
import numpy as np
optuna.logging.set_verbosity(optuna.logging.ERROR)
storage_url = "mysql+pymysql://user:password@<ipaddr><port>/<dbname>"
n_repeat = 10
def objective(trial: optuna.Trial) -> float:
s = 0
for i in range(10):
trial.set_user_attr(f"attr{i}", "fake user attribute")
s += trial.suggest_float(f"x{i}", -10, 10) ** 2
return s
def bench(n_trials):
elapsed = []
for i in range(n_repeat):
start = time.time()
study = optuna.create_study(
storage=storage_url,
sampler=optuna.samplers.RandomSampler(),
)
study.optimize(objective, n_trials=n_trials, n_jobs=10)
elapsed.append(time.time() - start)
optuna.delete_study(study_name=study.study_name, storage=storage_url)
print(f"{np.mean(elapsed)=} {np.std(elapsed)=}")
for n_trials in [1000, 10000, 50000]:
bench(n_trials)
このプログラムを実行して得られた結果を下表に示します。トライアル数を1000, 10000, 50000と変化させ、Optuna v4.0.0とv4.1.0で実行速度を比較しました。目的関数は上記の10回のサジェストと10個のユーザアトリビュートを持ち、RDBとしてはMySQL 8.0を用いました。サンプラーはRandomSamplerで、実行環境は5個のCPUと8GiのRAMを持つKubernetes Podです。
表:RDBStorageの速度改善
| # trials | v4.0.0 | v4.1.0 | Diff |
| 1000 | 72.461 sec (±1.026) | 59.706 sec (±1.216) | -17.60% |
| 10000 | 1153.690 sec (±91.311) | 664.830 sec (±9.951) | -42.37% |
| 50000 | 12118.413 sec (±254.870) | 4435.961 sec (±190.582) | -63.39% |
Optuna v4.1.0ではOptuna v4.0.0に比べて処理が高速になっており、またその恩恵はトライアル数が増大すればするほど大きなものであることがわかります。
終わりに
Optuna v4.1.0では、実際にRDBStorageがRDBに発行するSQLクエリを分析することで、数万規模のトライアルを高速に処理できるような改善を実施しました。Optunaはブラックボックス最適化フレームワークとして世界中にユーザがいますが、その応用領域は拡大を続けており、日々様々な需要に応えられるよう開発を続けています。より高速になったRDBStorageを利用して、ぜひ大規模な探索を実施してみて下さい。
また、特に近年は最適化の大規模化に伴って、高度なデータベース・分散処理の知識や経験が開発に必要とされてきています。このブログを読んでOptuna開発に興味を持った方は、ぜひGitHubで開発に参加してみて下さい。OptunaのGitHubはこちらです。 https://github.com/optuna/optuna
それではよいブラックボックス最適化ライフを!