Blog
2025.03.03
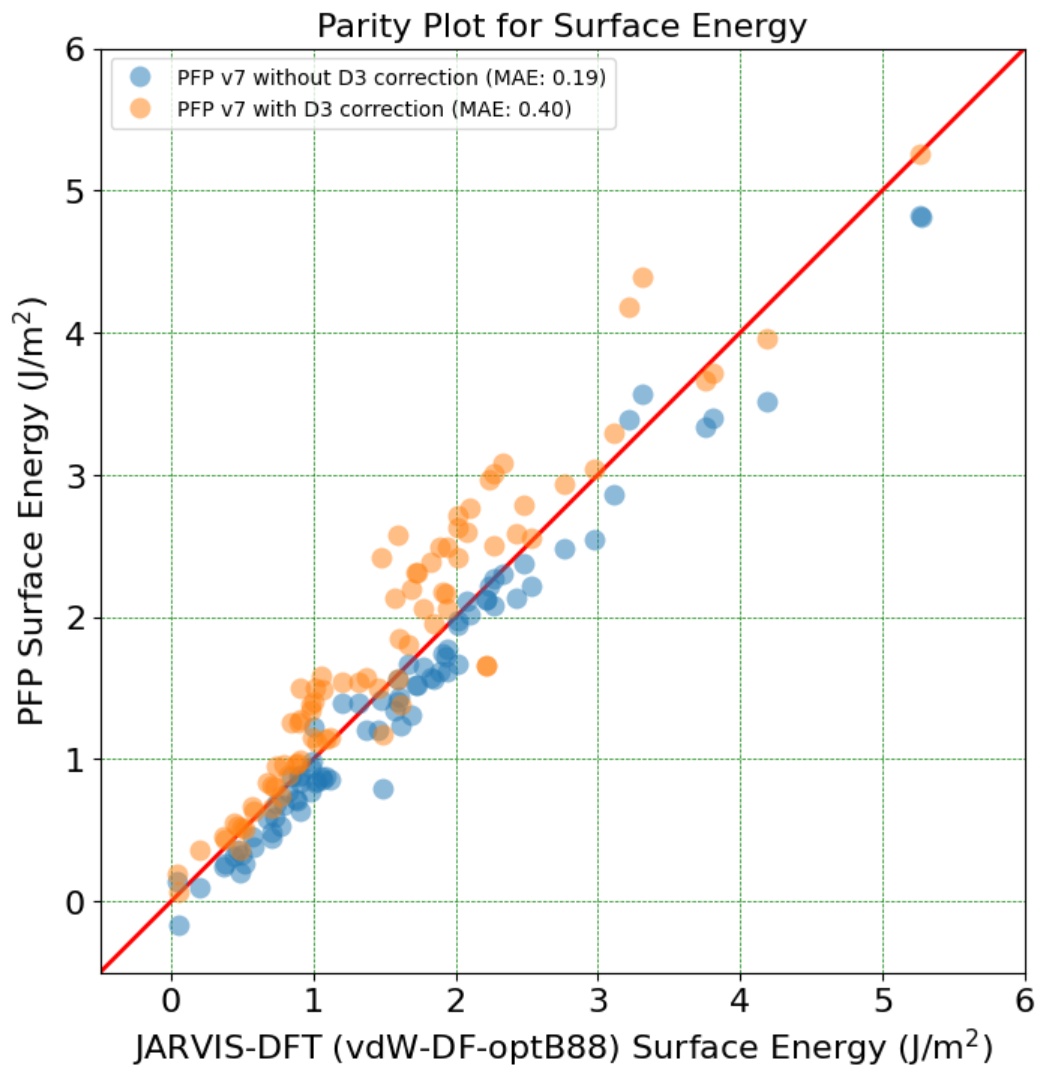
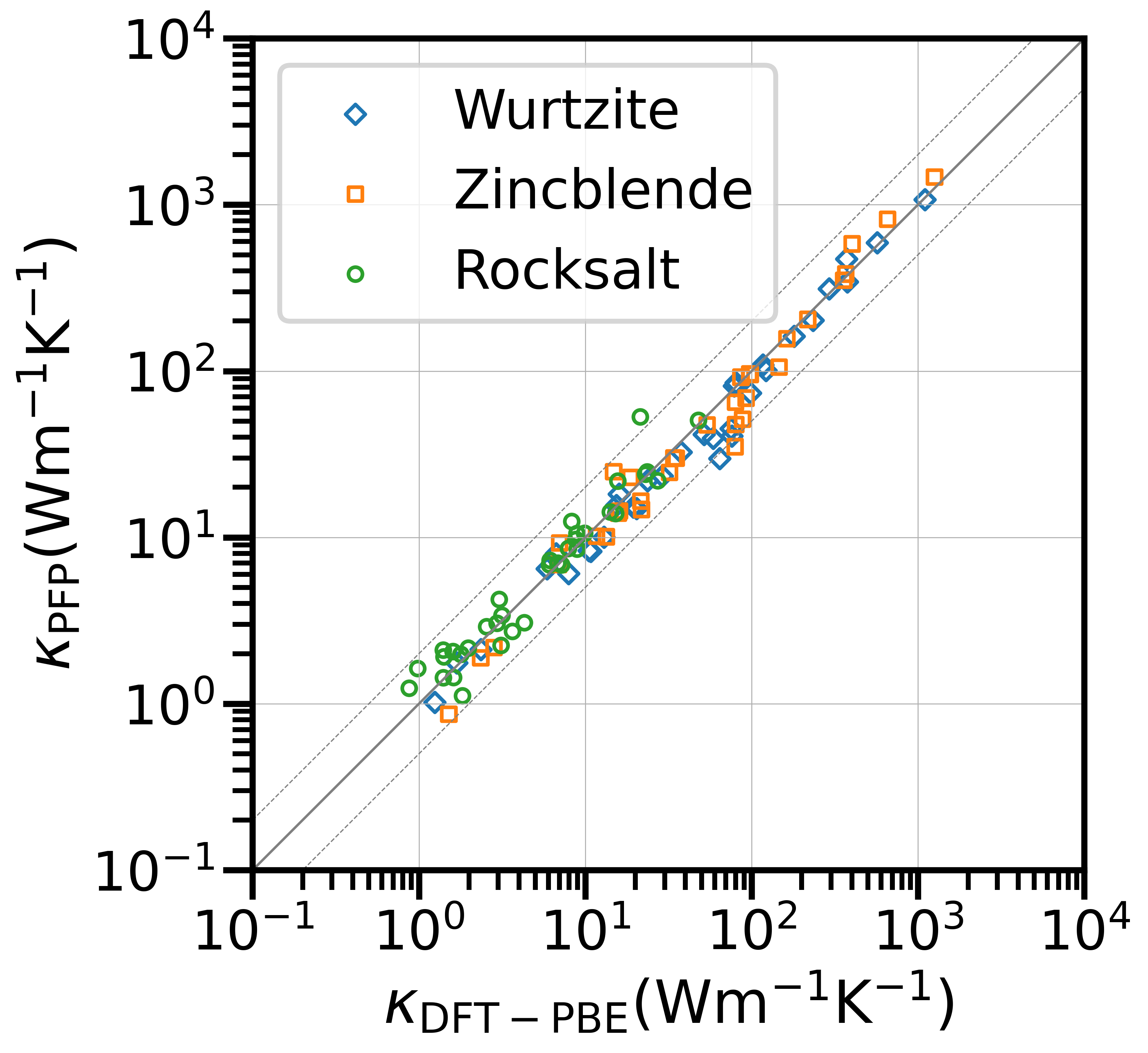
The Power of PFP Descriptors: Enhancing Prediction Tasks with Pre-trained Neural Network Potentials
Zetian Mao
Abstract
Deep learning has revolutionized materials science, enabling precise property predictions. The Matlantis product (https://matlantis.com/) provides a universal machine learning potential (PFP) for diverse-purpose atomistic simulations. This study evaluates descriptors from the pretrained PFP across multiple material property prediction tasks using the Matbench benchmark. PFP descriptors achieve comparable or superior performance to state-of-the-art models with simple training models, highlighting their effectiveness for transfer learning in materials informatics for wide applications.
Introduction
The landscape of materials science has been revolutionized by the rise of deep learning technologies. With the exponential growth of chemical data, deep learning models have become powerful tools for predicting new materials with unprecedented accuracy and efficiency. However, despite the vast availability of materials data, critical knowledge gaps persist. These data bottlenecks, particularly for key material properties, hinder our ability to design and optimize materials for advanced applications.
PFP [1] is a universal neural network potential that supports 96 of the known elements pretrained on over 59 million diverse structures. For more details on the latest version of PFP, please visit https://matlantis.com/news/pfp-v7-release. Built on an equivariant graph neural network architecture, PFP generates information-rich latent embeddings across different orders of representation, including invariant scalar features and equivariant vector and tensor features. Previous studies have demonstrated PFP’s latent features’ abilities to improve the accuracy of dielectric tensor predictions while preserving equivariance, even when trained on smaller datasets containing 6.6k structures [2]. However, its advantages over other recent pretrained models remained untested. Additionally, it is essential to evaluate performance on multiple datasets to assess generalizability.
Matbench [3] is a comprehensive benchmark suite designed to evaluate machine learning (ML) models in materials science. It consists of 13 supervised learning tasks, each tailored to assess the predictive performance of ML algorithms across various material properties. These tasks span a diverse range of characteristics, including optical, thermal, electronic, thermodynamic, tensile, and elastic properties, derived from both density functional theory (DFT) calculations and experimental data. The dataset sizes within Matbench vary significantly, ranging from 312 to 132,752 samples, making it a robust platform for benchmarking ML models on both small and large datasets.
In this blog, we aim to further evaluate the performance of PFP descriptors across multiple material properties using MatBench by:
- Comparing PFP against MACE [4], an open-source state-of-the-art equivariant neural network potential.
- Conducting an ablation study to assess the impact of PFP’s equivariant descriptors, specifically latent vector and tensor features.
- Comparing PFP descriptors with shallower feature representations.
Results
Overview
Details on the post-model used for mapping descriptors to target properties, as well as the ablation studies, can be found in the Methods section. We strictly adhere to the Matbench evaluation pipeline and assess the models using 5-fold cross-validation on the Matbench datasets. For our evaluation, we selected eight tasks that specifically involve structural data as input: matbench_jdft2d, matbench_mp_dielectric, matbench_log_grvh, matbench_log_krvh, matbench_perovskites, matbench_mp_e_form, matbench_mp_gap, and matbench_mp_is_metal. Among these, matbench_mp_is_metal is a binary classification task, while the rest are regression tasks. Considering the computational cost, we focus on the first five tasks—matbench_jdft2d, matbench_mp_dielectric, matbench_log_grvh, matbench_log_krvh, and matbench_perovskites—as they have relatively smaller datasets, with sizes of 636, 4764, 10,987, 10,987, and 18,928, respectively.
We compare two modeling approaches using PFP version 7 with calculation mode of CRYSTAL_U0 (crystal systems without U correction) : (1) using only scalar descriptors processed by a gated multilayer perceptrons (MLP) and (2) incorporating scalar, vector, and tensor descriptors, processed by the gated equivariant model (GEM). Based on the number of graph convolution layers used to extract information from PFP, we denote these models as PFP-MLP/GEM-Li, where i (1 ≤ i ≤ 5) represents the number of layers.
MACE is a machine learning architecture based on a higher-order equivariant message passing neural network, designed for highly accurate and efficient predictions of interatomic potentials. It leverages equivariant message passing with higher-order interactions to model complex atomic systems. The officially released pretrained MACE models come in several versions, each trained on different datasets, such as Materials Project, sAlex, and OMat24 [5]. These models are denoted as MACE-MP, MACE-MPA-0, and MACE-OMAT, respectively. For MACE-MP, three variants exist, differing in model complexity, specifically, in the equivariant orders used in their irreducible representations. In this comparison, we focus on the medium and large MACE-MP models, which encode more structural information. These models incorporate up to l1 and l2 order representations and are denoted as MACE-MP- l1 and MACE-MP- l2, respectively.
We evaluated only the performance of MACE scalar descriptors, as MACE employs spherical harmonic-expanded representations, which are not compatible with our architecture. For a fair comparison, we used the same gated MLP as for PFP scalar descriptors with a consistent 61.5k parameter count. The results are summarized in the following figures, benchmarked against the top five models from the Matbench leaderboard. The bars represent the mean MAEs and mean RMSEs from the 5-fold cross-validation results, while the error bars indicate the standard deviations of the MAEs.
matbench_jdft2d
The matbench_jdft2d task, adapted from the JARVIS DFT database [6], predicts exfoliation energies (meV/atom) from crystal structure. In materials science, exfoliation energy is the energy needed to detach a single layer from a bulk layered material. This property is crucial for 2D materials, where separating layers is important for applications like nanoelectronics, catalysis, and energy storage.
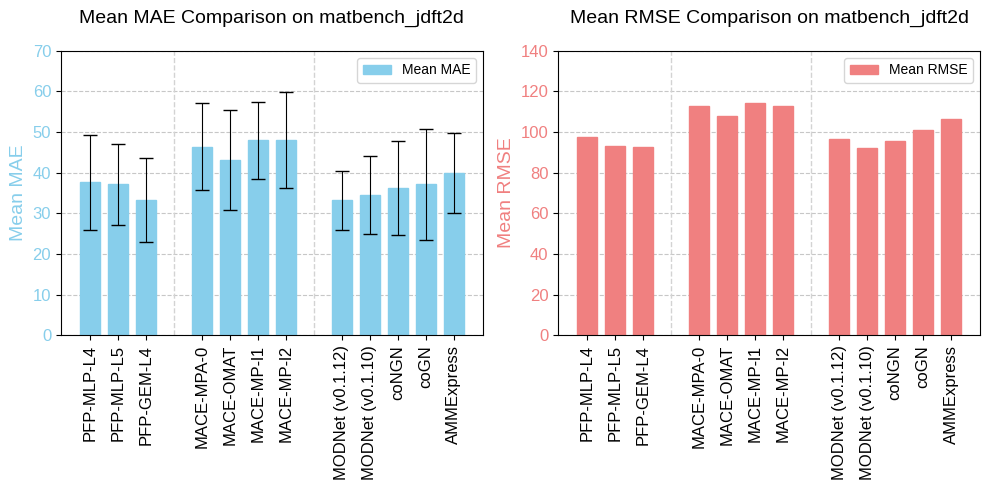
Fig. 1 Benchmarking results of matbench_jdft2d.
matbench_dielectric
The matbench_dielectric task, adapted from the Materials Project database, predicts refractive index from structure. The refractive index is a fundamental optical property of a material that describes how light propagates through it. It is defined as the ratio of the speed of light in a vacuum (c) to the speed of light in the material (v): n=c/v. Since it is expressed as a ratio, the refractive index is a unitless quantity.
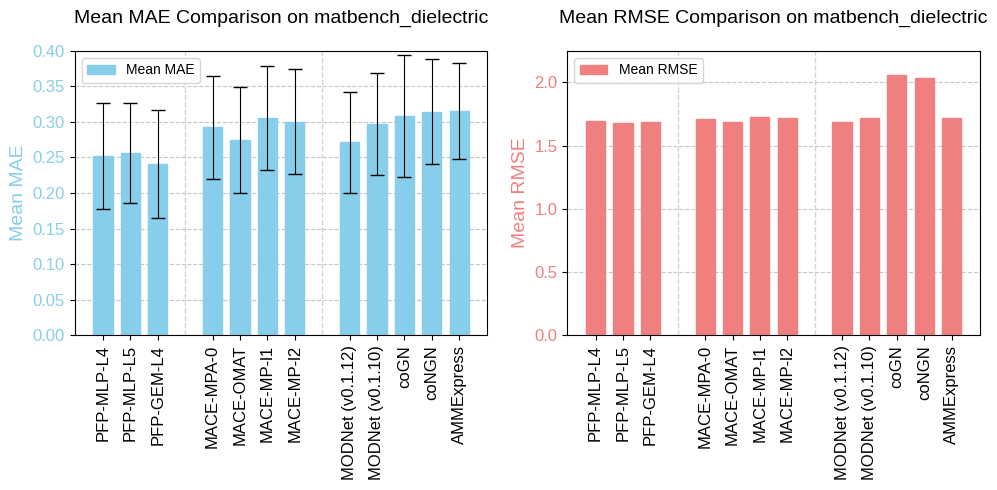
Fig. 2 Benchmarking results of matbench_dielectric.
matbench_log_gvrh
The task matbench_log_gvrh, adapted from the Materials Project database, predicts DFT log10 VRH-average shear modulus from structure. The log(G_VRH) property refers to the logarithm of the Voigt-Reuss-Hill (VRH) average of the shear modulus (G) of a material, measuring how much force is required to deform a material without changing its volume. Its unit is log10(GPa).
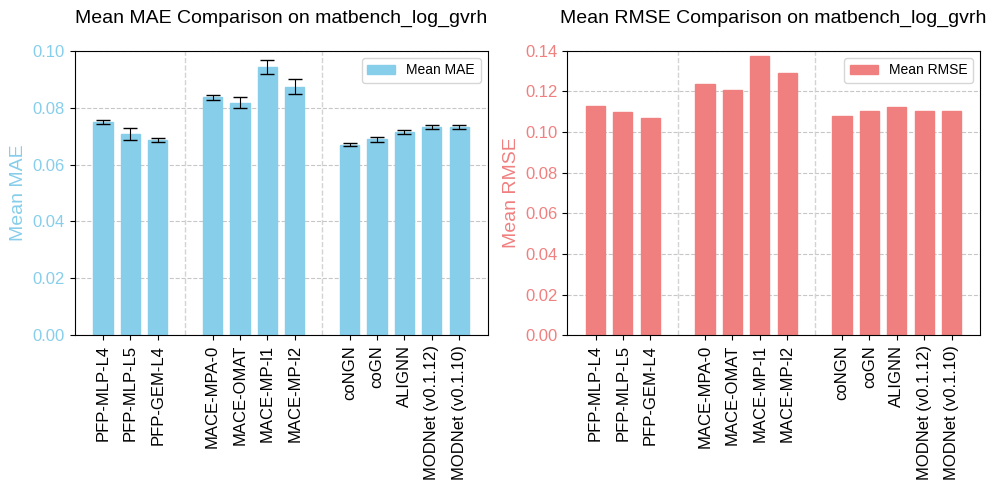
Fig. 3 Benchmarking results of matbench_log_gvrh.
matbench_log_kvrh
The task matbench_log_kvrh, adapted from the Materials Project database, predicts DFT log10 VRH-average bulk modulus from structure. Similar to log(G_VRH), log(K_VRH) refers to the logarithm of the Voigt-Reuss-Hill (VRH) average of the bulk modulus (K) of a material, measuring how much pressure is required to compress a material isotropically. Its unit is log10(GPa).
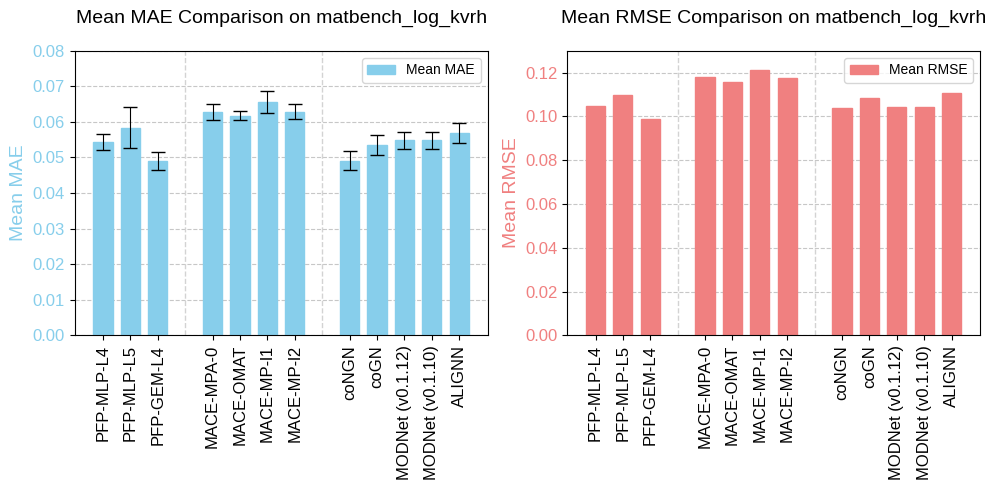
Fig. 4 Benchmarking results of matbench_log_kvrh.
matbench_perovskites
The task matbench_perovskites, adapted from an original dataset [5], predicts formation energy from crystal structure, i.e., the energy required to form the perovskite structure from its constituent elements or compounds. It is a key thermodynamic property used to assess the stability of perovskite materials. The unit for this property is eV per unit cell.
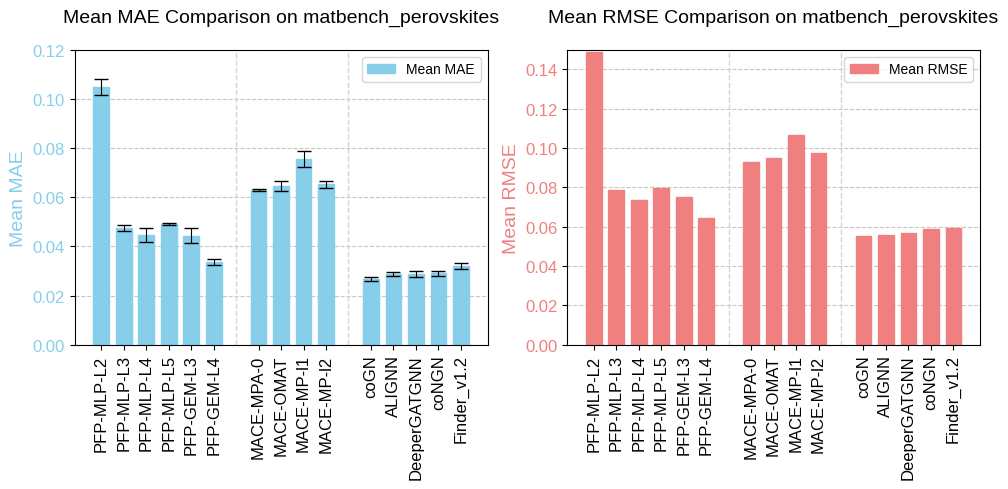
Fig. 5 Benchmarking results of matbench_perovskites.
matbench_mp_gap
The task matbench_mp_gap, adapted from the Materials Project database, predicts DFT band gap (PBE functional, unit: eV) from structure. The band gap is the energy difference between the valence band and the conduction band in a material’s electronic structure. It determines whether a material behaves as a conductor, semiconductor, or insulator.
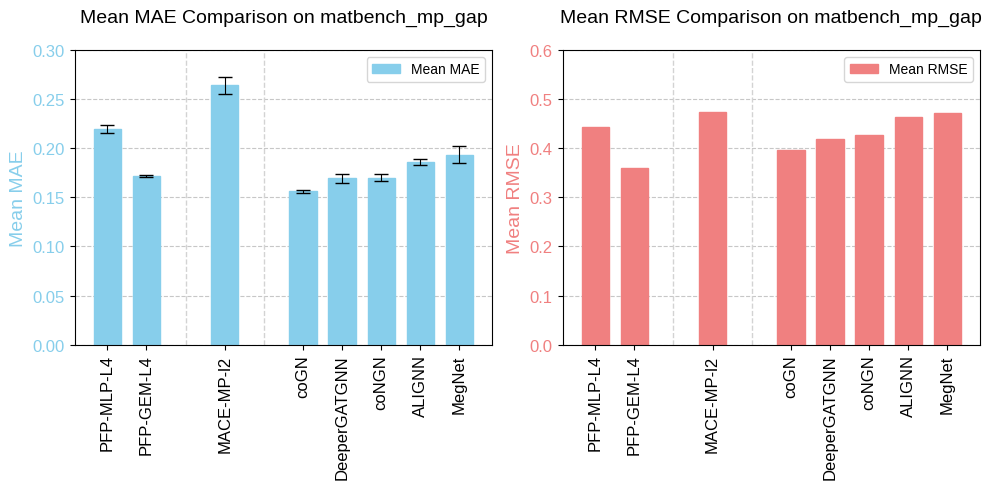
Fig. 6 Benchmarking results of matbench_mp_gap.
matbench_mp_e_form
The task matbench_mp_e_form, adapted from the Materials Project database, predicts DFT formation energy from structure. Similar to matbench_perovskites, but this task includes a diverse range of crystal types rather than being limited to perovskites. The unit for this task is eV/atom.
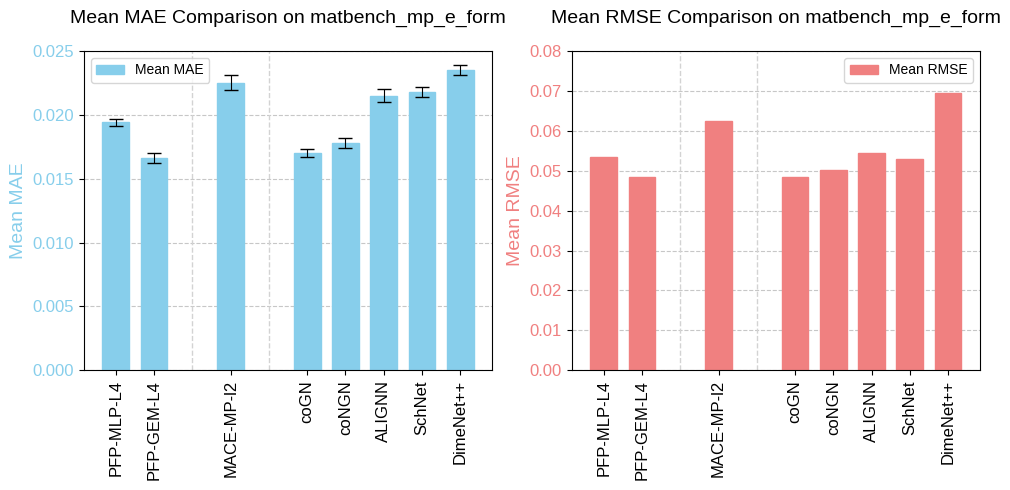
Fig. 7 Benchmarking results of matbench_mp_e_form.
matbench_mp_is_metal
The task matbench_mp_is_metal, adapted from the Materials Project database, predicts DFT metallicity from structure. This is a binary classification task aimed at predicting whether a given material is a metal or non-metal based on its structure and elemental composition.
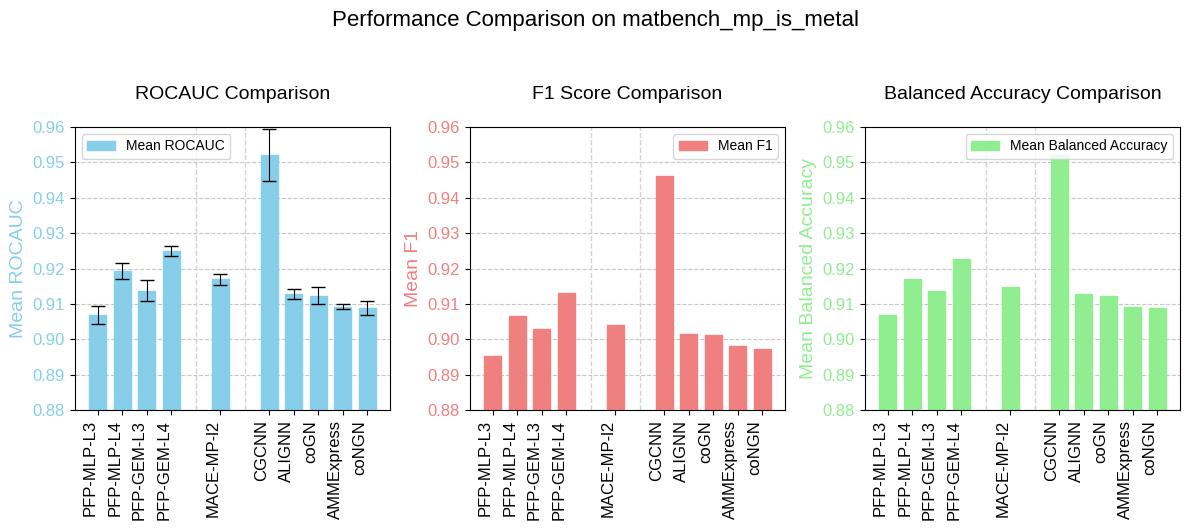
Fig. 8 Benchmarking results of matbench_mp_is_metal.
Effectiveness of Equivariant Descriptors
Our results indicate that when using information from the same convolution layer, PFP-GEM models consistently outperform PFP-MLP models of the same size. Furthermore, in several benchmarks, PFP-GEM models demonstrate competitive or even superior performance compared to top-ranking models on the Matbench leaderboard. This suggests that vector and tensor descriptors capture additional structural information beyond scalars, leading to improved performance. The contribution of these higher-order latent features aligns well with our previous study [1], where transferring equivariant descriptors for dielectric tensor prediction resulted in higher accuracy compared to several state-of-the-art algorithms.
Comparison with MACE
The overall trend in performance among descriptors from pretrained MACE models follows the order: MACE-OMAT > MACE-MPA-0 > MACE-MP. This aligns well with the generalization capacity of their respective training datasets. OMAT is trained on over 110 million structures, combining single-point non-equilibrium calculations and structural relaxations, whereas MACE-MPA-0 and MACE-MP are trained on sAlex + MPtraj and MPtraj only, respectively—datasets that are significantly smaller, in the range of just a few million structures. The richer training data in OMAT enables the model to encode more informative latent features, leading to improved accuracy after transfer learning.
However, despite its smaller training dataset, PFP-MLP consistently outperforms all MACE models, even when using the same dimensionality of scalar descriptors and identical post-model architectures. While PFP’s training data is smaller than OMAT’s, its higher dataset diversity may contribute to better data efficiency—a case where less is more, as evidenced by the stronger performance of its latent descriptors.
Effectiveness of Convolution Layers
For the matbench_mp_is_metal and matbench_perovskites tasks, we also evaluated the performance of PFP descriptors from shallower convolution layers. The results indicate that descriptors from the 4th layer yield better performance than those from the 3rd layer in both PFP-MLP and PFP-GEM models. Descriptors from deeper layers are expected to capture broader environmental embeddings, which may contribute to improved predictions of these global-level intensive properties.
Additionally, we tested 5th-layer scalar descriptors in some tasks. However, since the vector and tensor components in the final graph convolution layer of PFP are not trained, their corresponding features lack meaningful information for analysis. The 5th-layer descriptor performs similarly to the 4th-layer descriptor, showing better results in 2 out of 5 benchmark tasks. This may be due to the latent information in the final pretrained layer being more localized and aligned with the original training target—specifically, the potential energy surface, which could limit its transferability to other property predictions.
Conclusions
In this blog, we emphasize the information-rich nature of PFP descriptors across multiple benchmarking tasks in Matbench, where they often outperform alternatives and compete effectively, achieving accuracy on par with the top models on the leaderboard.
In terms of PFP, beyond scalar descriptors, higher-order equivariant descriptors (vectors and tensors) provide additional structural information, leading to improved accuracy when processed by an equivariant post-model rather than a gated MLP. Additionally, deeper-layer descriptors capture more global structural features, further enhancing predictive accuracy for test targets.
Methods
We adopted the base architecture from the reference [2] with modification visualized in Fig. 9. For detailed implementation, please refer to the original publication. Two key modifications were made to ensure compatibility with our study:
- We removed edge-related components in the equivariant block, including the MLP for edge scalar processing and the linear layer for edge vector transformation. In this study, only node descriptors are used for transfer learning.
- We eliminated the expansion operations in the readout block. The original model was designed for predicting 3×3 equivariant dielectric tensors, whereas our current study focuses on scalar property predictions or binary classification from the Matbench dataset [3].
To investigate the effectiveness of the equivariant descriptors generated by PFP, we conducted an ablation study by setting the number of equivariant blocks to zero (N = 0). In this case, only scalar descriptors are trained and directly passed through the gated MLP in the readout block. For a fair comparison, when equivariant blocks are omitted, we increase the latent dimensionality of the gated MLP to maintain a similar total number of model parameters. This ensures that differences in performance are due to equivariant features rather than model capacity. As a result, the number of trainable parameters remains comparable: 61.6k with equivariant blocks and 61.5k without them.
We define the model that incorporates equivariant blocks for equivariant processing as PFP-GEM (Gated Equivariant Model), while the model that skips these equivariant blocks and consists solely of gated MLPs in the readout block is referred to as PFP-MLP. Notably, neither PFP-GEM nor PFP-MLP includes node-wise message passing, which is a key distinction between these transfer learning models and traditional graph neural networks (GNNs). Instead, both GEM and MLP operate by processing individual node features without inter-node communication and ultimately aggregating node features into atomic system-level representations.
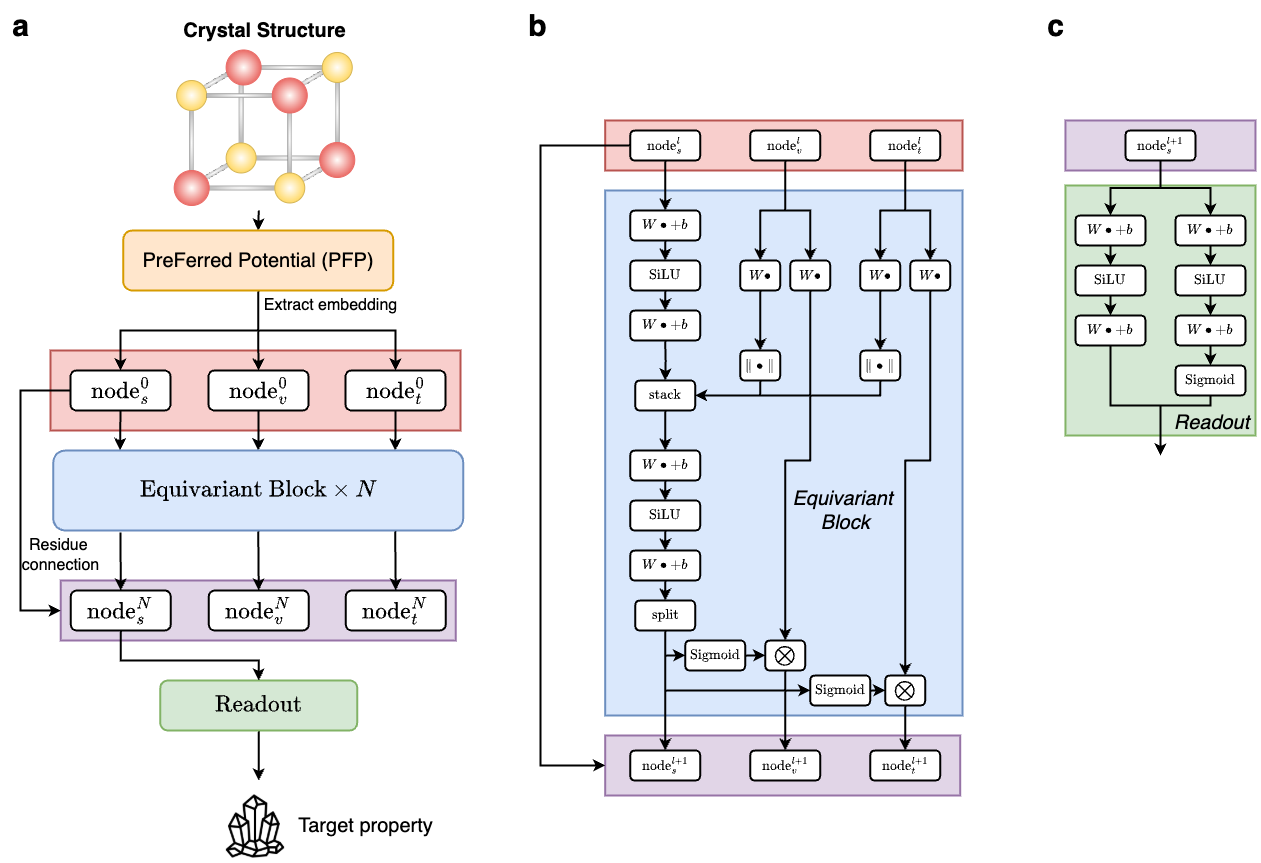
Fig. 9 Modified architecture: (a) Overview of the Gated Equivariant Model; (b) Detailed structure of the equivariant block; (c) Detailed structure of the readout block.
References
[1] Takamoto, S., Shinagawa, C., Motoki, D., et al. Towards universal neural network potential for material discovery applicable to arbitrary combination of 45 elements. Nature Communications, 13(1), 2991 (2022).
[2] Mao, Z., Li, W. & Tan, J. Dielectric tensor prediction for inorganic materials using latent information from preferred potential. npj Comput Mater 10, 265 (2024).
[3] Dunn, A., Wang, Q., Ganose, A. et al. Benchmarking materials property prediction methods: the Matbench test set and Automatminer reference algorithm. npj Comput Mater 6, 138 (2020).
[4] Batatia, I., Kovacs, D. P., Simm, G., et al. MACE: Higher order equivariant message passing neural networks for fast and accurate force fields. Advances in Neural Information Processing Systems, 35, 11423-11436 (2022).
[5] Castelli, Ivano E., David D. Landis, Kristian S. et al. New cubic perovskites for one- and two-photon water splitting using the computational materials repository. Energy & Environmental Science 5, 10 (2012): 9034-9043.
[6] Barroso-Luque, L., Shuaibi, M., Fu, X., et al. Open materials 2024 (omat24) inorganic materials dataset and models. arXiv preprint arXiv:2410.12771. (2024).
[7] Choudhary, K., Garrity, K. F., Reid, A. C., et al. The joint automated repository for various integrated simulations (JARVIS) for data-driven materials design. npj computational materials, 6(1), 173 (2020).