Blog
本記事は、PFNのインターンシップを経て現在はアルバイトとして勤務されている上田蒼一朗さんによる寄稿です。
はじめに
Preferred Networks(以下PFN)ではKubernetesを用いた機械学習基盤の開発・運用を行っています。本記事ではPFNで開発しているKubernetesのスケジューラに対するパフォーマンステストの取り組みについて紹介します。
PFNのKubernetesスケジューラ
Kubernetesにおけるスケジューラとは、Podをクラスタ内のどのNode上で実行するか決定するコンポーネントです。KubernetesのスケジューラにはScheduling Frameworkと呼ばれる仕組みがあり、これにより各スケジューラごとに独自のロジックをプラグインとして実装することが可能になっています。PFNのクラスタではこれを利用した様々なプラグインを開発し導入しています。
PFNが開発したプラグインの例として、Gangスケジューリングを行うものがあります。これは複数の関連するPodが同時にスケジューリングされるようにするスケジューリングアルゴリズムです。例えば分散学習のワークロードでは、単一のPodだけスケジューリングされても他のPodがすべてスケジューリングされなければ学習を開始することができず待機することになり、不必要にリソースを確保することになります。一方、Gangスケジューリングがあれば分散学習を開始できる状態になって初めてスケジューリングが行われるため、Podが起動してすぐに学習を開始することができるようになります。また、このプラグインはOSSとして公開されています。GitHubレポジトリはこちらです。 https://github.com/pfnet/scheduler-plugins
他には、GPUのスケジューリング向けのプラグインも開発しています。分散学習を行うPodはそれらがなるべく近いところに、そうでないPodはGPUの断片化を防ぐためにPodが要求するGPUの枚数と使用可能なGPUの枚数が近いNodeにスケジューリングされるようにスコア付けをするようにしています。これらのロジックは以前までLuaスクリプトで実装していましたが、パフォーマンスへの影響の大きさから最近Goで実装し直しました。
こういったスケジューラの拡張についての詳細は続・PFN のオンプレML基盤の取り組みや2022年のPFNの機械学習基盤をご覧ください。
kubernetes/kubernetesにおけるスケジューラのベンチマークテスト
kubernetes/kubernetesにはscheduler_perfというスケジューラのベンチマークテストが用意されています。内容としては、etcdとapi-serverとスケジューラを起動しておき、そこにNodeやPodなどのリソースをapplyしていったとき、Podがスケジューリングされるまでの時間など各種メトリクスを取得するというものです。Worker Nodeは動かさずcontrol planeのコンポーネントのみで実行することで、単一のマシン上で大規模のクラスタを模した環境で実行することが可能になっています。
scheduler_perfではベンチマークのシナリオをYAMLファイルで記述することができます。例えば以下のような設定ができます。
- name: SchedulingBasic
defaultPodTemplatePath: ../templates/pod-default.yaml # 追加するPodのマニフェスト
workloadTemplate: # シナリオの内容を設定
- opcode: createNodes # まずworker nodeを追加する
countParam: $initNodes
- opcode: createPods # 初期状態のPodを追加する
countParam: $initPods
- opcode: createPods # Podを追加しそのときのスケジューラのメトリクスを計測する
countParam: $measurePods
collectMetrics: true
workloads:
- name: 500Nodes # シナリオのパラメータ(Pod数やNode数)を設定
labels: [performance, short]
params:
initNodes: 500
initPods: 500
measurePods: 1000
この設定では、最初に500個のNodeとPodを用意しておいた状態で、1000個Podを追加するときのスケジューラのメトリクスを計測します。
計測結果は以下のようなJSONファイルで出力されます。
{
"data": {
"Average": 213.95953420343739,
"Perc50": 55.986911435831445,
"Perc90": 371.93215697104336,
"Perc95": 371.93215697104336,
"Perc99": 371.93215697104336
},
"unit": "pods/s",
"labels": {
"Metric": "SchedulingThroughput",
"Name": "BenchmarkPerfScheduling/SchedulingBasic/500Nodes/namespace-2",
"event": "not applicable",
"extension_point": "not applicable",
"plugin": "not applicable",
"result": "not applicable"
}
},
このJSONオブジェクトはこのシナリオにおけるSchedulingThroughtputというメトリクスの値の平均やパーセンタイルを示しています。このように各シナリオごとに様々なメトリクスが計測されます。他のメトリクスとしては、各プラグインの実行時間などがあります。
kubernetes/kubernetesにおいて、scheduler_perfはCIで実行されその結果はPerfdashというツールによって可視化され perf-dash.k8s.io に掲載されます。図1のようにscheduler_perfの結果の推移が見られるようになっています。また、各シナリオについてメトリクスに閾値が設定されていることがあり、それを下回る結果が出た場合はCIが失敗するようになっています。
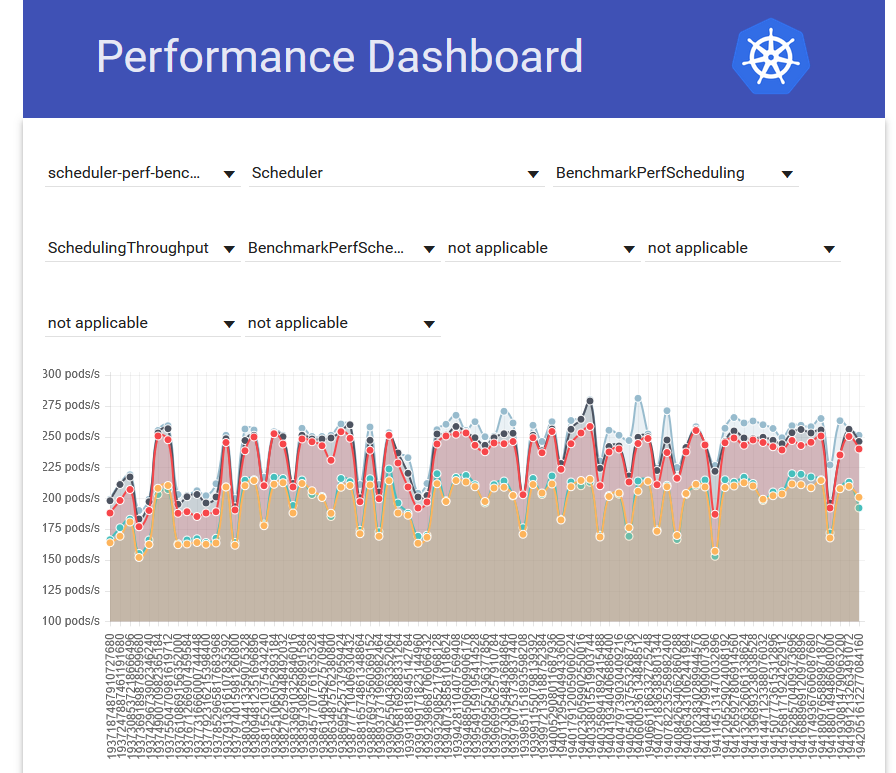
図1: Perfdashで可視化されたscheduler_perfの結果
こうしたベンチマークがCIに組み込まれている背景として、スケジューラのパフォーマンスの重要性があります。scheduler_perfはスケジューラに対する機能追加などの変更でパフォーマンスに致命的な影響が出ることを防ぎ、設定された閾値程度以上のスループットが出ることを保証しています。
PFNにおけるscheduler_perfの利用
PFNのスケジューラには上述の通り様々な拡張を施しているため、これらによるパフォーマンスへの影響を確認しておく必要があります。そのためにPFNのスケジューラでもscheduler_perfを利用していました。しかしscheduler_perfの利用について我々は2つの課題を抱えていました。
1つ目に、scheduler_perfのメンテナンスコストです。scheduler_perfはGo言語のテストコードとして実装されていたためパッケージとして切り出されていませんでした。そのためscheduler_perfをPFNのスケジューラに対して実行するために、scheduler_perfのコードベース自体をPFNのスケジューラのコードベースにコピペして利用する形を取る必要がありました。すると、Kubernetesのバージョンを上げるたびにscheduler_perfで変更された箇所をPFNのスケジューラの方に取り込むための作業が必要になります。この作業がKubernetesのバージョンアップの際に負担となっていました。
2つ目にscheduler_perfがCIに載っておらず手動で実行する形になっていたことです。そのためスケジューラに対して変更を行ったときに自動的にパフォーマンスの変化を知ることができず、リリースが完了してからパフォーマンスの悪化に気付き改善を行うというフローになっていました。このためパフォーマンスの悪化に対応するのが遅くなってしまったり、その原因究明が難しくなってしまったりしていました。
以下ではこれらの課題を解決するために取り組んだ最近の施策を紹介します。
scheduler_perfのimport
PFNのように拡張したスケジューラに対してscheduler_perfを実行したいというユースケースを満たすために、Kubernetes v1.30からscheduler_perfをライブラリとしてimportできるようになっています。当該PRはこちらです。PFNでもこれを利用してコピペではなくimportする形でscheduler_perfを利用するように変更しました。scheduler_perfを実行するには、以下のようにテストコードで RunBenchmarkPerfScheduling 関数を呼び出すだけです。
import (
"testing"
perf "k8s.io/kubernetes/test/integration/scheduler_perf"
)
func BenchmarkPerfScheduling(b *testing.B) {
perf.RunBenchmarkPerfScheduling(b, "/path/to/scheduler_perf_config.yaml", "", outOfTreeRegistry)
}
ところが、これを使う際に1つ問題が起こりました。それはscheduler_perfの実行時にCRDを追加できないことです。PFNのスケジューラにはCRDを必要とするプラグインがあります。例えばkube-throttlerというPodのスロットリングを行うプラグインはThrottleやClusterThrottleというCRDを導入してこれらをスケジューリング時に参照しています。こういったプラグインを動かすためには必要なCRDをインストールしておく必要があります。scheduler_perfのコードベースごとコピーしていた頃には、実行前にクラスタにCRDを追加するパッチを当てることで対応していました。一方でimportする方法の場合は、RunBenchmarkPerfScheduling 関数の中でapi-serverやetcdの起動からscheduler_perfの実行までしてしまうので、api-serverへ直接アクセスする方法がなくCRDを追加できませんでした。
このような問題はPFNだけではなく、拡張されたスケジューラでscheduler_perfを実行しているユーザーすべてに起こりうるものです。そのためscheduler_perf実行前にapi-serverに対して任意の処理を実行する機能が必要であることをアップストリームにフィードバックし、Pull Requestのマージまで行いました。当該PRは scheduler-perf: add option to enable api-server initialization #131149 です。
このPRによって、WithPrepareFnというオプションを使ってscheduler_perfが実行される前に呼び出されるコールバック関数を設定できます。このコールバック関数の中ではapi-serverのクライアントにアクセスすることができ、以下のようにCRDなどのリソースを追加することができます。
perf.RunBenchmarkPerfScheduling(b, "config/performance-config.yaml", "hogehoge", outOfTreeRegistry, perf.WithPrepareFn(func(tCtx ktesting.TContext) error {
client := tCtx.APIExtensions()
_, err := client.ApiextensionsV1().CustomResourceDefinitions().Create(tCtx,
&apiextensionsv1.CustomResourceDefinition{
// Custom Resource Definition
},
metav1.CreateOptions{})
return err
}))
この機能はKubernetes v1.34でリリースされます。まだPFNのスケジューラで使うことはできておらず、現状ではCRDの必要なプラグインだけ除くことで対応しています。
scheduler_perfをCIで実行する
PFNで用意しているscheduler_perfのシナリオは実行するのに10分以上かかります。そのため、PRをマージするたびにscheduler_perfを回していると開発スピードに悪影響が出る可能性があります。そのため、PRをマージするタイミングではなくリリースする直前のタイミングで実行するようにしました。
PFNのスケジューラのリリース手順は以下のようになっています。
- リリースPRを作成するGitHub Actionsをworkflow_dispatchで手動で実行する。
- 作成されたリリースPRをマージする。
よって、リリースPRの作成と同じタイミングでscheduler_perfを実行するようにしました。
また、scheduler_perfの実行結果をレポートする方法については、リリースPRのdescriptionに記述するようにしました。こうすることでリリースノートにも自動でscheduler_perfの実行結果が掲載されるようになりました。また、実行結果を記述する際、前回のリリース時の結果との比較を合わせて載せるようにしました。以下のように前回の結果と今回の結果、そしてそれらの差分がシナリオごとに表示されるようになっています。これによりリリース前にパフォーマンスの変化がチェックできるようになりました。実際に計測した結果を以下の表1〜3に示します。実際には他にも計測されているメトリクスはあるのですが、ここではもっとも重要なSchedulingThroughputという1秒あたりにスケジューリングされたPodの数を示したメトリクスのみを表示しています。
| Metric | 前回の結果 | 今回の結果 | 差分 |
| SchedulingThroughput | 267.29 | 234.20 | -18.18% |
表1: 拡張されていない通常のスケジューラのスループット (pods/sec)
| Metric | 前回の結果 | 今回の結果 | 差分 |
| SchedulingThroughput | 31.66 | 26.51 | -16.28% |
表2: PFNのスケジューラのスループット (pods/sec)
| Metric | 前回の結果 | 今回の結果 | 差分 |
| SchedulingThroughput | 4.08 | 3.38 | -17.33% |
表3: Gang PodをPFNのスケジューラでスケジューリングしたときのスループット (pods/sec)
表3のGang Podのスケジューリングではスループットが非常に低くなっていますが、このシナリオではGangスケジューリングが行われそのオーバーヘッドが影響として出ているためです。
この結果を見て、PFNのスケジューラのスループットが想定していたよりも小さいことに気付きました。そこでscheduler_perfの設定を見直してみると、本番環境のスケジューラではLuaで書かれたプラグインがGoで書き直されたものに置き換えられていたのに対し、scheduler_perfで実行しているスケジューラではまだLuaが動いていたことに気付きました。そこで、LuaのプラグインをGoのものに置き換えて実行してみると以下の表4〜5のように変化しました。このようにLuaをGoで置き換えたことによってパフォーマンスが大幅に向上していたことが明らかになりました。
| Metric | 前回の結果 | 今回の結果 | 差分 |
| SchedulingThroughput | 26.51 | 374.08 | +1311.29% |
表4: PFNのスケジューラにおいてLuaのプラグインをGoに置き換えたときのスループット (pods/sec)
| Metric | 前回の結果 | 今回の結果 | 差分 |
| SchedulingThroughput | 4.08 | 19.59 | +479.91% |
表5: Gang PodをPFNのスケジューラでスケジューリングするときにLuaのプラグインをGoに置き換えたときのスループット (pods/sec)
まとめ
PFNではKubernetesのスケジューラに拡張を施しており、それによるパフォーマンスの影響をチェックするためにアップストリームで実装されているscheduler_perfというベンチマークテストを利用しています。本記事ではscheduler_perfがパッケージとして公開されているため、これをimportする形で導入することで低いメンテナンスコストで運用できるようになったことを紹介しました。また、これをリリース前に自動的に実行して前のリリースとの差分を表示することでリリースごとのパフォーマンスへの影響を確認してからリリースを行えるようになったことを紹介しました。今後もKubernetesスケジューラの拡張を開発することに伴う課題の解決に取り組んでいきます。
Area
Tag