Blog
本記事は、2025年度PFN夏季インターンシップで勤務された山野亮介さんによる寄稿です。
はじめに
こんにちは。2025年度夏季インターンに参加させていただいた、東京大学情報理工学系研究科修士1年(当時)の山野亮介です。大学では主に文字列に関する研究を行っています。今回のインターンでは、MN-Coreをシェーダー言語の一つであるOpenGL Shading Language (GLSL) から利用するために、GLSLコードをMN-Coreが効率よく処理できるPyTorchコードに変換するトランスパイラを実装しました。
背景
PFNでは高い並列性能を持つ深層学習アクセラレータであるMN-Coreを開発しています。深層学習はGPUを用いて実行されるのが一般的ですが、元々GPUはその名の通りグラフィクス処理が主な用途でした。例えばFull-HDの1920 × 1080画素のように多くの画素を素早く処理するには並列処理が欠かせず、MN-Coreもグラフィックス処理が得意と期待できます。深層学習以外にもMN-Coreの用途を拡げる一歩として、GLSLで書かれた一般的なシェーダー作品である Seascape をMN-Core上で動かすことを今回の目標としました。
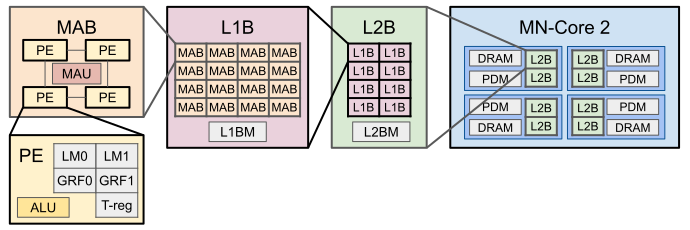
図1: MN-Core 2の階層構造
図1のようにMN-Coreは階層状の構造を持ち、巨大なSIMDとなっていて、1ボードにある4096個の演算ユニット(PE)が同じ命令を完全に同期して実行します。1命令につき 4Cycle同じ命令種を実行し、1Cycle 内でも2個の単精度浮動小数(f32)を並行して処理するので、1命令で合計32768個のf32を処理できます。今回扱うGLSLは行列演算が少ない上そのサイズも小さいので、最終的に行列演算を利用せず、普通のf32 SIMDにあたるベクトルモードですべて計算しましたが、MN-Core 2は本来行列演算に強みがあり、1MABあたりベクトルモードでは1Cycleにつき8回の積和演算を行うのに対し、行列演算なら32積和演算、さらに行列演算でのみサポートされる疑似単精度ならば64積和演算を行うことができます。
MN-Core上でひとまず動かす
GLSLの構文解析ライブラリ が公開されているので、これを用いてまず抽象構文木(AST)情報を取得します。高い抽象度のまま対応関係をわかりやすくするために、これをPyTorchのモデルとして実行する形に変換することにしました。GLSLのビルトイン関数をPyTorchのライブラリとして記述できて楽というメリットもあります。一旦PyTorchコードに変換してしまえば、あとは図2の通り、既存のフローにのっとってMN-Core上で実行することができます。PFVMは深層学習モデルを実行するためのコンパイラであり、モデルの保存形式の一つであるONNX形式の入力を受け取ります。PythonコードをONNXに変換するONNX Exporterについては、PFVM向けのONNXエクスポータの開発 もご覧ください。
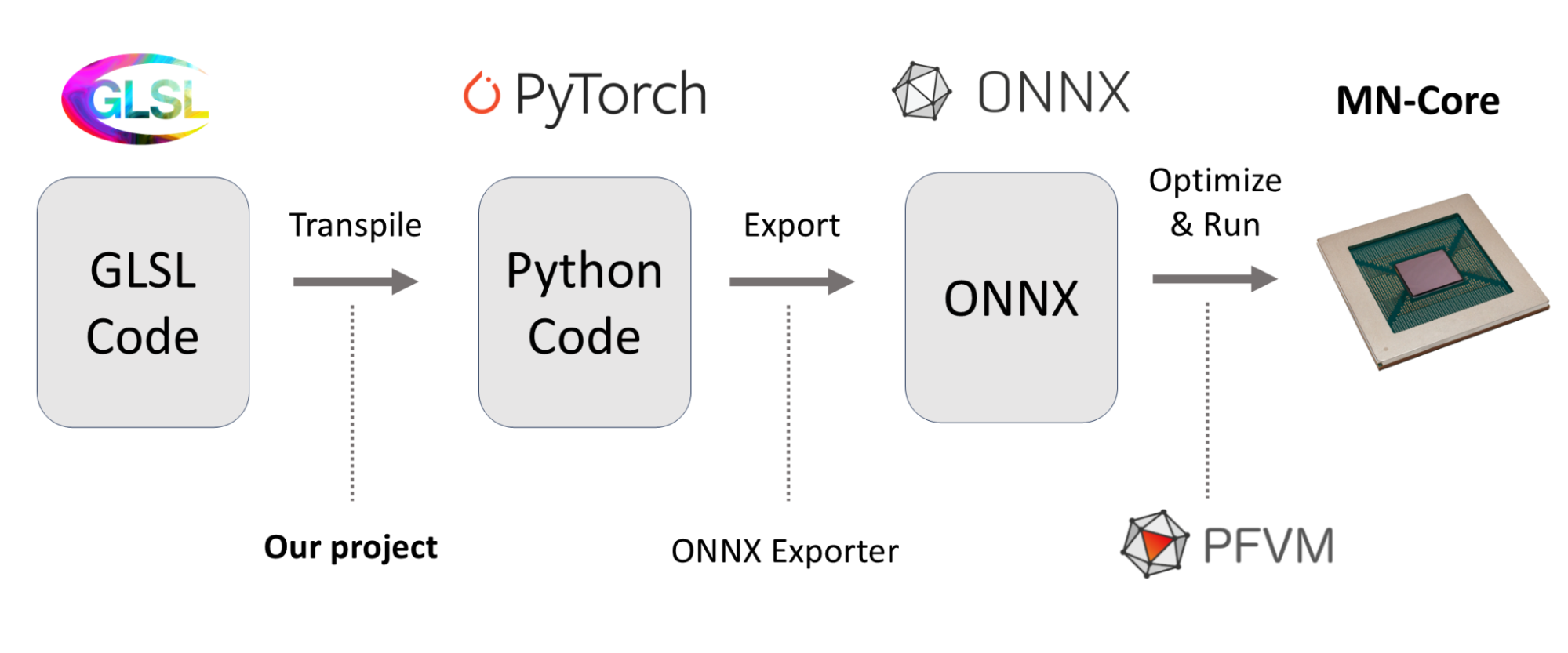
図2: GLSLコードをMN-Core上で実行するまでのフロー
基本的に各演算について一対一対応が取れますが、大きく異なる点として、GLSLでは座標を一つ受け取ってそこに塗る色を返す関数として記述するのに対し、PyTorch側では、画素数分の座標をテンソルとして受け取り、色をまた画素数分のテンソルとして返すという点です。つまり、明示的にバッチ処理として記述する必要があります。GLSLはC言語のようにfloatのスカラー変数を扱えますが、他にも大きさnのベクトル型に対応するvecn型や、n x nの行列型に対応するmatn型が存在します(n = 2,3,4)。描画する画像の解像度を縦Hピクセル、横Wピクセルとして、GLSL上でのスカラーは(H,W)の2次元テンソルに、vecn型は(H,W,n)の3次元テンソルに、matn型は(H,W,n,n)の4次元テンソルに暫定的に型を対応付けることにしました。ただしこの処理のみ行って生成したPyTorchは動きません。主に3つの問題点があります。
一つ目は、ブロードキャストの問題です。GLSL上ではスカラーとベクトル型との掛け算のような処理を書くことができますが、これは自動的にスカラーがベクトルの要素数分だけ拡張されるブロードキャストが行われるからです。これをバッチ処理用に変換した3次元テンソルと2次元テンソル同士の掛け算として記述するとこれはテンソルの shape 不一致エラーとなります。単純な解決策としては2次元テンソルに torch.unsqueeze 演算を適用し、(H,W)の形を(H,W,1)の3次元テンソルに形を変えることです。次元数が揃っていて、片方の大きさが1ならば、PyTorch側でブロードキャストを行ってくれます。
二つ目は、演算子のオーバーロードです。GLSLでは、同じ * の演算子で、スカラーやベクトル同士の要素積と、行列同士や行列とベクトルとの行列積の両方の可能性があります。これをPyTorch側では要素積なら*、行列積なら@と区別する必要があります。この区別を行うためには各項の型を持つ必要がありますが、保持しているASTには型情報は付与されていないので、型環境を自分で作る必要がありました。基本的には変数宣言時に型も宣言するので型の収集は楽なのですが、少し複雑なのは複合式が現れる場合です。複合式は部分式の計算結果を変数に束縛せず一時的に利用します。ここで部分式の結果の型は宣言されないので、こちら側で推論する必要があります。そこで一時変数を適宜挿入することで複合式を分解し、追加した一時変数の型を推論して型情報を持っておくという前処理を行うことにしました。図3に具体例を示しています。このとき、複合式をもたないレベルの中間言語に対応する構文木を定義し、この構文木にASTを移しました。また、変数名に被りがあると型環境の保持が面倒なので、変数のスコープに気を付けつつ、異なる変数には異なる名前を付けなおすという前処理も行っておきます。
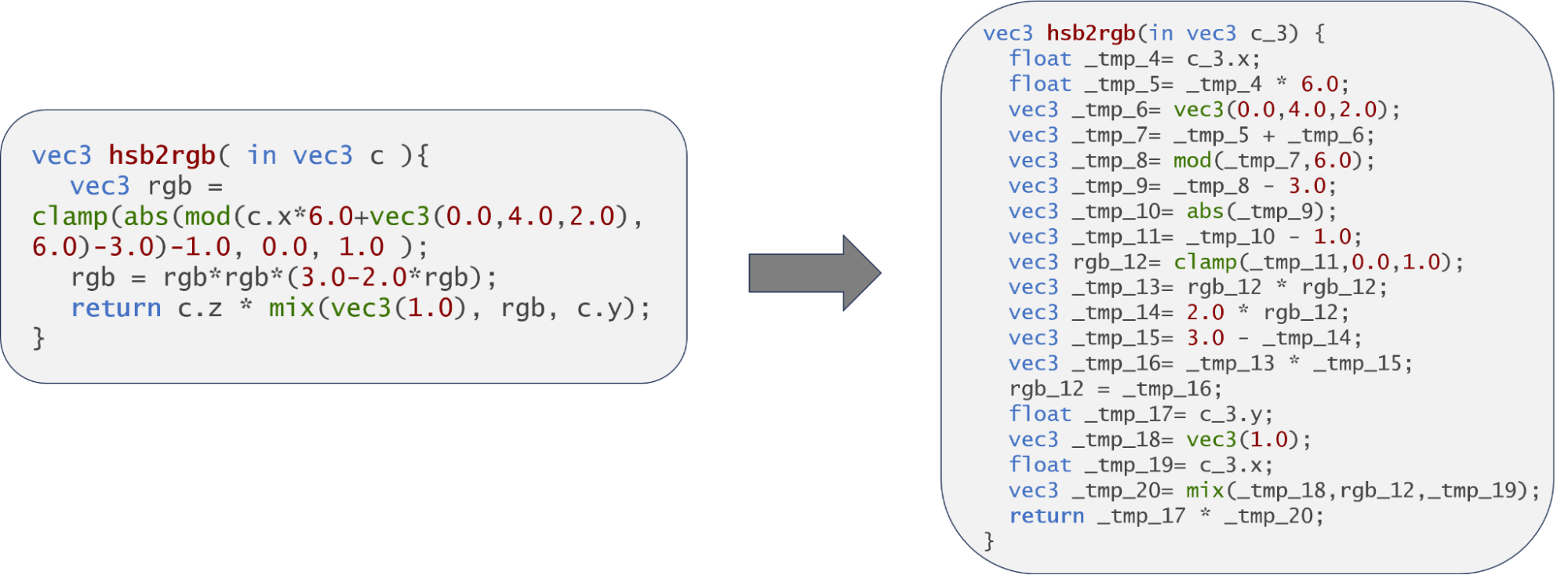
図3: hsb2rgb関数に対する部分式分解の例
三つ目は、if文の処理です。GLSLではC言語等と同じようにif文を記述することができますが、座標ごとに分岐の結果が異なることがあります。しかしこれは座標のバッチ処理と相性が悪いです。そこで基本的に torch.where とマスクビットを用いる処理として記述することにしました。具体的には図4のように、if文の記述が現れる度、その条件式からマスクビットを生成し、各ifブロックに入る度に現在の分岐条件に対応するマスクビットを条件式のビットアンド積として管理しておきます。そして、計算結果を変数に束縛するときにそのマスクビットが真である座標にのみ行うようにするためにtorch.where を用いるようにしました。

図4: if文の処理の例
また、MN-Core特有の事情として、非対応のONNX演算を利用できないという制約があり、具体的にはテンソルへの部分的な代入は行えません。vec4の一要素のみを変更するというようなGLSL上の操作が、PyTorch上ではテンソルの部分スライスへの代入という形となり、このままだとコンパイルできません。これは後述するvecnやmatnのスカラーのリストへの分解を行うことで解消されますが、この時点では変更を加えない部分を再度コピーして全体の再代入という形に変換することでひとまず対応しました。
これらの処理を行うことでめでたくGLSLの出力画像に対応するテンソルがMN-Core上で計算できるようになりました。しかし、とりあえず動いたというだけで、当初 256 x 256 の画像1フレームを生成するのに0.5ms程かかるなど、MN-Coreの演算能力を全く生かせていませんでした。MN-Coreの性能を引き出すために記述の仕方を工夫していく必要があります。
MN-Coreに優しくする
プロファイラを見てまず気になった点は、メモリの退避 (Spill) が頻繁に行われていたということです。図1のようにMN-Coreは階層状の構造となっていて、基本的に一番下の階層のPEで演算を行います。しかし各PEの記憶領域にデータが収まらない場合、溢れたデータを一番上の階層にあるDRAM領域にまで転送して保存しておき (MNCoreUpload = MN-Core 用語で、PE から DRAM に転送すること)、また必要になったときにDRAM領域からPEまで転送してくる (MNCoreDownload = DRAM から PE に転送すること) が必要となりますが、これらの処理は多大な時間を要するので、できるだけ排除したいです。今回の場合、理想的には、パラメータとして与えるいくつかの変数(経過時間やマウス座標等)のMNCoreDownloadと、最終結果となるテンソルのMNCoreUploadのみにこれらのUpload/Downloadを限定したいです。ここで大きな問題となっていたのは、vecnやmatnのテンソル表現でした。GLSLで登場するvecnやmatnは大きくてもvec4やmat4程度の大きさしかありません。これらに対し内積計算をするときに縮約演算を利用するため、vec4に対応する(H,W,4)の形の3次元テンソルを(H,W,16)のようにパディングを行っていて演算器が無駄になっていました。また、H,Wとして1920,1080をそのまま用いていたので、この一つのデータだけで、全PEのローカルメモリのほとんどを埋め尽くしてしまいます。さらにブロードキャストによるテンソルの shape 不一致エラーの解消のためにtorch.unsqueezeを呼び出すとメモリレイアウトの変更 (MNCoreLayoutSwitch) が発生し、これもまた大きなボトルネックとなっていました。
そこで、vecnやmatnのnが小さいことに注目し、これを分けることにしました。例えばvec2なら(H,W,2)サイズのテンソルではなく、(H,W)サイズのテンソル2個のリストとして表現し、mat2のような行列も(H,W)サイズのテンソル4個のリストとして表現します。行列積の計算は、掛け算と足し算に分解して記述し直し、ブロードキャストが起きる場合も適宜型情報を参照してトランスパイラ側でデータを分配する処理を記述するようにしました。こうすることで、ブロードキャストのためのtorch.unsqueezeが不要になり、同時に保持しておく必要のあるメモリも減りました。理論上は、ローカルメモリにおさまるギリギリまでメモリを利用する方がMAU/ALUの稼働率を上げられるはずですが、現状のMN-Coreコンパイラはあまりメモリを使いすぎると失敗することが多いので、今回は、1命令で処理できるf32の数である32768個ごとに画素を処理することにしました。つまり、高解像度の画像を出力したい場合でも一度にすべての画素を処理するのではなく、例えば H = 256, W = 128 として H x W = 32768 となるような長方形領域ごとに分けて処理を行うようにしました。さらに、各座標はすべて独立に色を計算できるので、隣接関係に特に意味はなく、平坦化することができます。最終的には (H*W,)サイズの1次元テンソルのリストとしてベクトルや行列を保持するようになりました。図5にこれらの変換を適用する具体例を示しています。
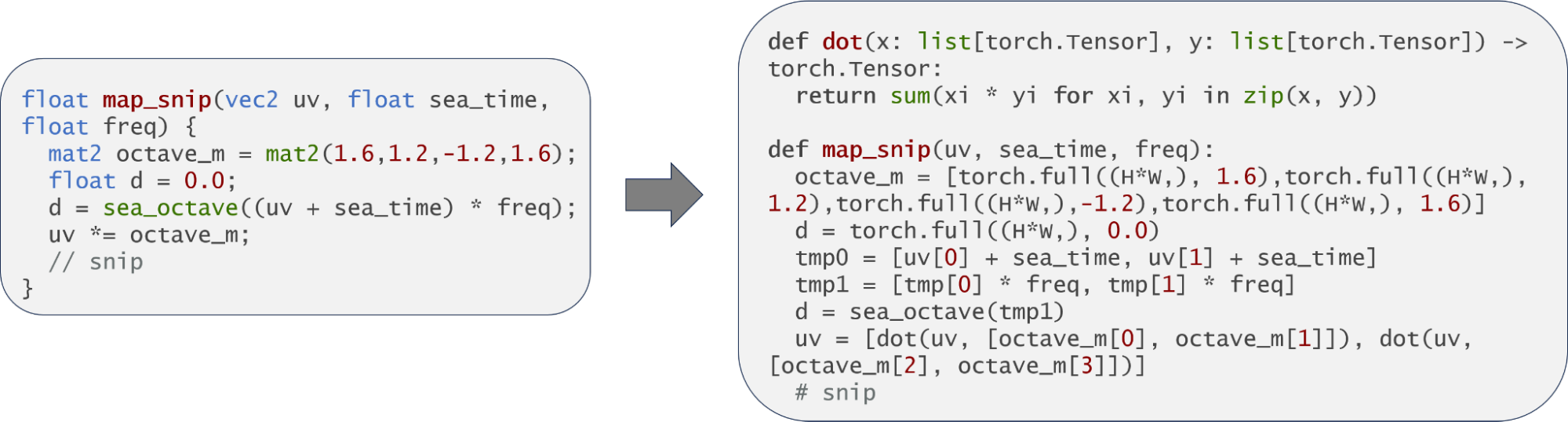
図5: vecnとmatnのスカラーのリストへの分解の例
また、Spill以外でもMNCoreDownloadが多く発生しており、原因としては、定数を即値として処理せず、その場でのみ使う変数として、MNCoreDownloadで値を読み込んでいたからでした。これはPyTorchの記述の仕方の問題であり、torch.tensor(1.0)のような記述ではなく、torch.full((H, W), 1.0) のように明示的にブロードキャストして形をそろえるように記述を変更することでMN-Coreコンパイラに定数と認識してもらえるようになり、命令への即値埋め込みが進みました。
さらなる高速化の一つとして、解像度に応じて与えられる座標集合の計算の仕方の工夫が挙げられます。2次元座標の集合をx座標とy座標のそれぞれ二つのテンソルに分けたことで、[0,1,2,…,W-1,0,…,W-1,…]と[0,…,W-1]をH回繰り返すx座標と、[0,…,0,1,…,1,…,H-1,…,H-1]と、[0,…,H-1]の各値をW回ずつ繰り返すy座標が必要となります。これらを Tensor.repeat のような処理を用いて計算するとテンソルの形が変わり、MNCoreLayoutSwitch が起こって時間がかかってしまいます。そこで床関数を利用してrepeatやexpandを用いない計算方法に変えることで、Seascapeの計算においてさらに5%程の高速化につながりました。
また、GPUには超越関数演算ユニット(SFU)が存在し三角関数や指数関数等を高速に近似計算できるので、GLSL上ではこれらの関数を低コストな関数として大量に呼び出しますが、MN-CoreにはSFUに相当する機能がありません。結果、図6の通り、これらの呼び出しがボトルネックとなっていました。そこでグラフィックス用の低精度な関数を独自に定義してこれを用いるようにすることで高速化を図りましたが、ソフトウェアによる実装なのでGPUに比べると依然不利な点になります。
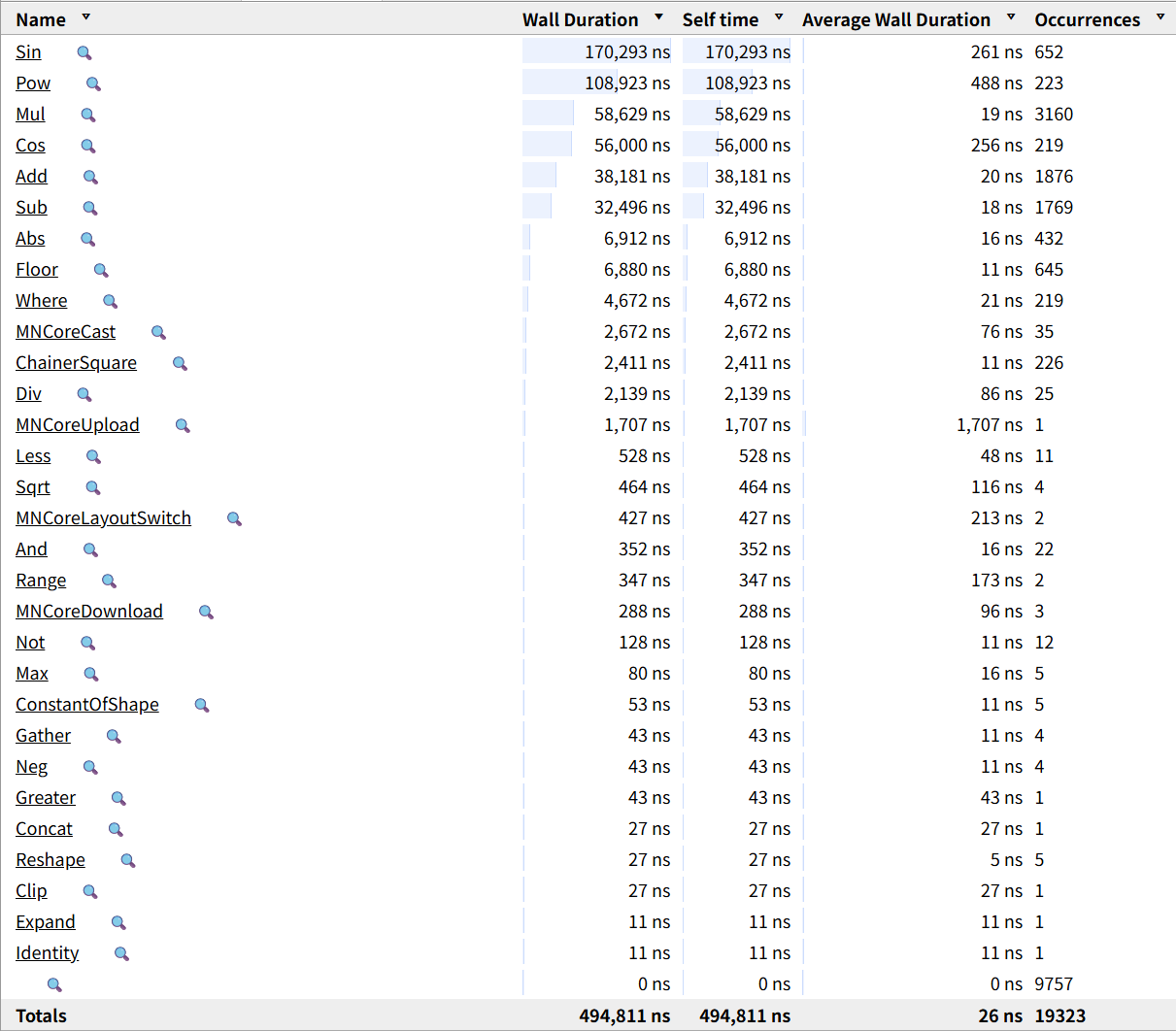
図6: 演算の統計
この他演算の融合等の最適化を行うことで、最終的に256×128サイズのSeascapeの1フレームがおよそ221μs程で計算できるようになり、Full HDサイズにおいて 71.5fps程の性能が出る見込みになりました。比較としてGPUでSeascapeのGLSLコードを動かした時のFPSを測ると、GeForce RTX 2080 Ti の 3840×2160サイズで 16fps、RTX A6000 の 3840×4320サイズ で 38fps となり、Full HD換算では単純計算でそれぞれ 64fps, 304fpsとなります。グラフィックス用途に設計された GPU に対し、AI アクセラレーターで CG を行わせた結果としては、まずまずの結果が得られたのではないかと思います。
Future workとしては、より詰まった効率的な命令列を生成することが挙げられます。
出力された機械語の命令列(vsm)を見て統計を取ると、単精度ベクトル積和演算のfvfmaが10175回、単精度ベクトル積演算のfvmulが6944回、単精度ベクトル和演算のfvaddが3477回と、支配的であるこれらのMAU命令の合計回数が20596回となり、ほかの命令のほとんどはALU命令となりました。MAU命令とALU命令は(ハザード等がなければ)同時に発行できるので、理想的な状況においては、vsmの命令列の長さを前述の20596行程に詰めることができそうです。一方現状のvsmの命令列は41457行(演算器を動かさない nop 命令等も含む)となっています。条件分岐の存在しないMN-Coreは実行時間が PE vsmの命令列の長さにおおよそ比例するという特徴があるので、理想的には実行時間を半分ほどに削減できる余地があると言えます。
まとめ・謝辞
今回のインターンでは、GLSLで書かれたシェーダー作品を実際にMN-Core上で動作させ、人間の目でも十分な速度でのフレーム生成が可能になりました。
MN-CoreをPytorchモデルを通じて利用する上で用いたcodegen(MLSDK)は、本来 Gemm や Softmax のようなより大きな粒度で記述された計算グラフを扱って機械語を生成することが想定されていますが、今回は Mul や Add 等の細かい粒度のONNX演算が大量に連なった計算グラフを扱うことになり、本来の想定用途とは外れた使い方となりましたが、それでも、ほどほどに最適なコードが生成されることが確認できました。
メンターの井町さん・諸戸さん・樋口さん、並びにコンパイラチームの皆さんにインターンシップ期間中大変お世話になりました。この場を借りて厚く御礼申し上げます。



