Blog
本記事は、2019年インターンシップに参加された蕭喬仁さんによる寄稿です。
はじめまして。PFN の2019夏季インターンシップに参加した東京大学の蕭喬仁です。 大学では自然言語処理について研究しており、SNS からのマイニングに興味があります。
今回のインターンでは「Disentangled な表現の教師なし学習手法の検証 (Unsupervised Disentangled Representation Learning)」というテーマで研究を行いましたので、その紹介をいたします。
実験に使用したコードはこちら https://github.com/pfnet-research/chainer-disentanglement-lib で公開しています。
Disentangledな表現
映画 Star Wars がお好きな方は ”imperial entanglements” という表現でおなじみかもしれませんが、entangle とはもつれるという意味の英単語です。したがって Disentangled Representation とは直訳するともつれを解いた表現ということを指します。
では、もつれを解いた表現とは何なのでしょうか?実は disentangled な表現の定義は研究者の間でもまだ定まったものが無いのですが、多くの研究では潜在空間中の各次元が観測データ中の因子や性状ごとに分かれているような状態を disentangled な表現としています。たとえば、画像認識における disentangled な表現の各次元は被写体の「色」「形」「大きさ」などをそれぞれ表すことが期待されます。このような性質を持つ表現はある1つの次元を変動させても観測データ中の複数の要素が同時に変わる事が無いため、観測データの情報が解釈可能で低次元な潜在空間に圧縮された表現とも言えます。そのため教師有り・半教師有り学習などの機械学習タスクや few-shot learning, domain adaptation などに有用であるとされており、様々な手法が近年提案されてきました。
先行研究
教師なしで disentangled な表現を得る手法として state-of-the-art を主張している論文の多くは変分オートエンコーダ (Variational AutoEncoder; VAE) [1] をベースにした手法を採用しています。
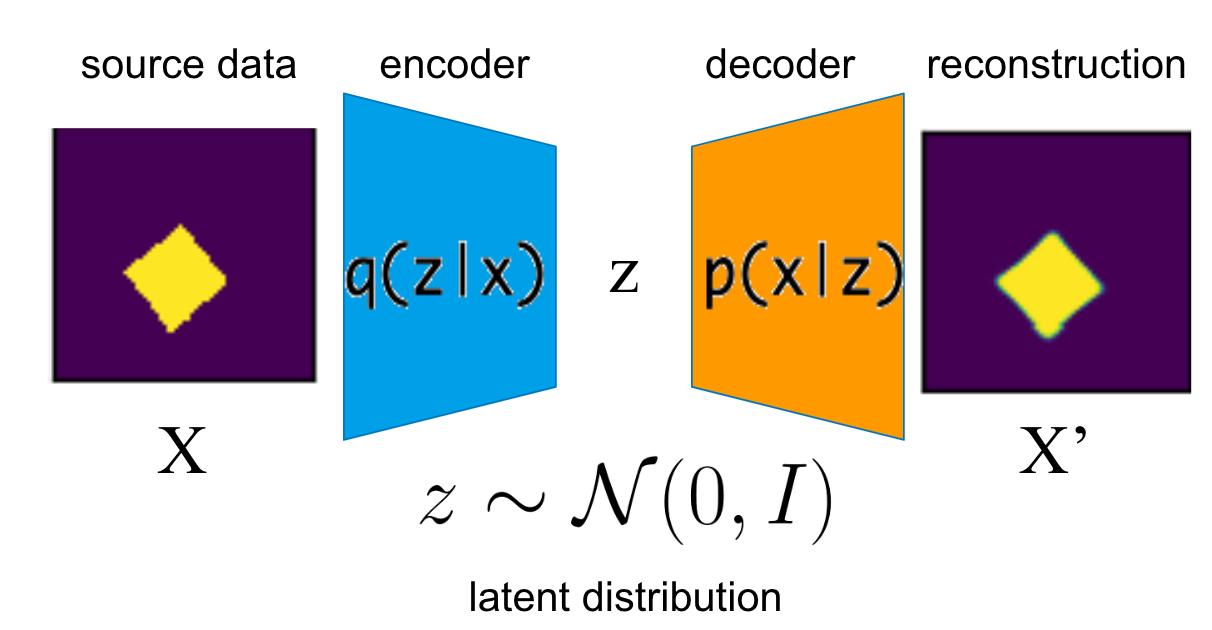
図1. VAE の概念図
VAE では潜在変数の確率分布を標準正規分布に近づけながら学習を行いますが、disentangled な表現を得るためには潜在変数の事後分布がより標準正規分布に近い必要があります。データ \(X\) を生成している真の因子は各々独立であることを仮定しているからです。このような仮定のもと近年提案されてきた手法は VAE にどのような正則化項を加えるかで以下のように分類することができます。
- 近似事後分布 \(q(z \mid x) \) をより事前分布である標準正規分布に近づける正則化項を加えた β-VAE [2]
- aggregated variational posterior \(q(z) \) が各成分独立になるような正則化項を加えた FactorVAE [3] や β-TCVAE [4]
- aggregated variational posterior \(q(z) \) が事前分布と近くなるような正則化項を加えた DIPVAE-1/DIPVAE-2 [5]
また、潜在変数に離散変数を使えるようにした、JointVAE [6] や CascadeVAE [7] などの手法もあります。
様々なモデルの提案と同時に disentangled な表現を定量的に評価する指標も数多く提案されています。評価指標には以下のような2系統が存在しますが、いずれの指標でも値の計算のためにデータの真の生成因子が必要となります。こちらでは紹介していませんが、インターンに参加していた8月中にも新しい評価指標 [8] が提案されており、どの指標を用いるべきかは研究者の間でも定まっていません。
- データ \(X \) のある生成因子を固定した状態でその他の因子を変化させた時の潜在変数の変化をみる BetaVAE metric [2], FactorVAE metric [3], IRS [9]
- エンコードした潜在変数から真の生成因子をどれだけ予測可能かをみる MIG [4], SAP-SCORE [5], DCI [10]
一方で、disentangled な表現を完全に教師無しで学習することは困難なのではないかという主張が最近なされるようになりました。Locattello らの研究 [11] では近年 state-of-the-art を主張してきた手法に対して大規模な検証実験を行い以下のようなことを示しています。
- モデルや正則化項等のハイパーパラメータよりも乱数による影響が大きいということ。
- モデルが学習した disentangled な表現が人間の直感に合う保証が無いこと。
- 再構成誤差や ELBO などの教師無しで得られるモデルの評価指標と教師有りの disentangled な表現の評価指標には相関が見られないこと。
- データ \(X \) を生成する確率 \(P(X) \) しか持っていない状況では、disentangled な潜在変数 \(p(z) \) と entangled な潜在変数 \(p(z^\prime) \) の識別が数学的に不可能であること。
ただし、論文では適切な帰納バイアスを取り入れることで教師ラベルを用いる事なく disentangled な表現を得ることは可能かもしれないとされており、別の論文 [12] でも損失関数に潜在変数の事前分布を適切に調整することでより良い disentangled な表現を得ることが可能であったという報告もされています。disentangled な表現を得る試みはまだまだ始まったばかりと言えるでしょう。
実験設定
今回のインターンでは、先行研究では検証されていなかった潜在変数の次元数や種類がパフォーマンスにどのような影響を与えるかを検証するために state-of-the-art を主張してきた BetaVAE, FactorVAE, DIPVAE-1/-2 に加えて離散変数を潜在変数として扱える JointVAE の Chainer 実装を行い、2つのデータセットを用いて実験をしました。モデル間で公平な比較を行うために、encoder/decoder の構造や optimizer・バッチサイズ・iteration の数などは共通にした上で、モデルごとに30個のシードで学習を実施しました。
本記事では代表的な実験結果として、データセットのうちの dSprites データに関する結果を紹介したいと思います。このデータセットにはハートや楕円などの物体がサイズや位置を変えて配置された2次元画像が納められており、データを生成する真の因子には物体の種類・物体の大きさ・物体の回転・x軸座標・y軸座標の5種類があります。

図2. データセットの例
実験設定1
上で紹介したモデルを使用する時にまず気になるのが潜在因子の次元数をどのように設定するべきかだと思います。そこで、今回は連続変数を潜在変数とする BetaVAE, FactorVAE, DIPVAE-1/-2 に関して、潜在変数の次元数を真の生成因子の数の半分・同じ・倍の3パターンのモデルを用意して学習結果を比較しました。
実験設定2
実務で使用する際には、dSprites データのように因子の全組み合わせに対応する網羅的なデータを用意することは現実的ではないことが考えられます。そこで、x座標と物体の大きさに相関ができるように因子の組み合わせを半分削除したデータと、比較対象として因子の組み合わせをランダムに半分削除したデータを dSprites データセットから人工的に作成し、パフォーマンスがどの程度落ちるのかを検証しました。
結果
実験1
以下に、潜在変数のある次元だけを動かして、その他の次元を固定した時にデータがどのように変化するかを見た latent traversal という図を掲載します。一番左の列は VAE に与えた元のデータを示しており、その右隣の画像は VAE による再構成画像です。その他の列は潜在変数中の各次元を \(-1.5 \) から \(1.5 \) まで動かした時の画像の変化を順番に描画しています。
潜在変数を3次元とした場合
| BetaVAE |  |
| FactorVAE |  |
| DIPVAE-1 |  |
| DIPVAE-2 |  |
潜在変数を5次元とした場合
| BetaVAE |  |
| FactorVAE |  |
| DIPVAE-1 |  |
| DIPVAE-2 |  |
潜在変数を10次元とした場合
| BetaVAE |  |
| FactorVAE |  |
| DIPVAE-1 |  |
| DIPVAE-2 |  |
潜在変数の次元数が小さい場合は、各画像の左から2番目、つまり再構成画像を見ると、どのモデルを使っても画像の再構成が上手くいかず、物体の形がぼやけてしまっているのが見て取れます。どうやら次元数を少なくしすぎるのは問題のようです。しかし、BetaVAE は潜在変数を大きくしても再構成があまり上手くいっておらず物体の形がぼやけてしまっています。実はこの問題は FactorVAE を提唱した論文でも述べられており、BetaVAE に観測データ \(X \) と潜在変数 \(Z \) の相互情報量を小さくするような効果があるから起きるとされています。次元数を真の生成因子と同じ5次元にした場合は、FactorVAE はx軸座標とy軸座標、サイズの変化を disentangle できていますが、DIPVAE-1/-2 では entangled された特徴が学習されてしまっています。次元数が10次元の場合も FactorVAE が5つの因子を disentangle できているのに対して、DIPVAE-1/-2 は直感的ではない特徴を学んでしまっているように見えます。次元数を真の生成因子の数よりも多くした場合は全てのモデルで latent traversal 上で動かない次元が出てきていますが、FactorVAE では真の生成因子の学習が上手くいっていることから、実務で使用する際には潜在変数の次元数は出来るだけ余分にとっておいたほうがいいことが推察されます。
実験2
以下では実験1で定性的に性能がよかった FactorVAE による結果を掲載しています。x座標と物体の大きさに相関があるデータで学習したものは、latent traversal 上でもx座標の移動とともに物体の大きさが変化していることがわかります。また、y軸方向の移動とともに物体の形状が変化しているのをみると、その他の因子の学習にも悪影響を及ぼしていてそうです。ランダムな欠損を与えたデータでは、完全なデータと同じレベルとまではいかないものの、ある程度は5つの因子を獲得できています。今回は全データの半分を削除したので、データを削除しすぎた可能性もあります。しかし、実務で使用する際に生成因子の全ての組み合わせのデータの準備が難しい場合は、せめて因子に相関がないようなデータに整えた上で学習を行うべきである事がこの結果から推察できます。
| 完全なデータ |   |
| x座標と物体の大きさに相関があるデータ |   |
| ランダムな欠損を与えたデータ |   |
メンターからのコメント
メンターを担当した PFN の仲田と吉川です。
本文中でも触れられている通り、disentangled な表現の教師なし学習は few-shot learning や domain adaptation といった分野への応用や、機械学習モデルの解釈性の向上が期待できます。これらは現実世界への機械学習の適用をする際にいつも直面する課題です。
深層学習などの先端技術による現実世界の課題解決をミッションとする PFN としても以前から取り組んではいるのですが、タスク自体の難しさはもちろん、問題設定をおこなうことも難しい分野です。インターン期間中は手法の再現性や各種文献の実装の読解などにお互い苦労しましたが、最終的には代表的な手法を一通り Chainer で実装し、様々なデータやパラメータ、評価指標を広く調査して頂いた蕭さんの今回の成果は、今後の PFN における研究開発にあたっての足がかりとなることと思います。
参考文献
- [1] Kingma & Welling, 2014, Auto-Encoding Variational Bayes
- [2] Higgins et al., 2017, β-VAE: LEARNING BASIC VISUAL CONCEPTS WITH A CONSTRAINED VARIATIONAL FRAMEWORK
- [3] Kim & Mnih, 2018, Disentangling by Factorising
- [4] Chen et al., 2018, Isolating Sources of Disentanglement in Variational Autoencoders
- [5] Kumar et al. 2018, Variational Inference of Disentangled Latent Concepts from Unlabeled Observations
- [6] Dupont, 2018, Learning Disentangled Joint Continuous and Discrete Representations
- [7] Jeong & Song, 2019, Learning Discrete and Continuous Factors of Data via Alternating Disentanglement
- [8] Do and Tran, 2019, Theory and Evaluation Metrics for Learning Disentangled Representations
- [9] Suter et al., 2019, Robustly Disentangled Causal Mechanisms: Validating Deep Representations for Interventional Robustness
- [10] Eastwood & Williams, 2018, A FRAMEWORK FOR THE QUANTITATIVE EVALUATION OF DISENTANGLED REPRESENTATIONS
- [11] Locatello et al., 2018, Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representation
- [12] Mathieu et al., 2019, Disentangling Disentanglement in Variational Autoencoders
