Blog
本記事は,2019年度インターン生だった東京大学 D1 の中島蒼さんによる寄稿です.中島さんはインターンシップにおいて,畳み込みニューラルネットワークの学習について研究を行いました.この記事は,インターンシップ中に文献調査していたimplicit bias に関するレビューとなっています.
NN の学習はなぜうまくいくのか
畳み込みニューラルネットワーク(Convolutional NN; CNN)は画像処理など様々な分野に応用され,大きな成功を納めています.すなわち,様々なデータについて,訓練データから学習したニューラルネットワーク(Neural Network; NN)を用いて未知のデータについての予測や分類が行われています.このようにNN の学習が上手くいく,すなわち未知データに良く汎化することは経験的には分かっていますが,理論的な説明はまだ完全には成功していません.
NN に限らず学習一般において,訓練データだけから未知なデータについて予測をするのは本来原理的に不可能です.未知のデータに対しては,何が起こってもおかしくないからです.それにも関わらず学習が上手くいくのは,未知のデータに関しても何らかの仮定ができ(帰納バイアス; inductive bias),その仮定を利用することで既知のデータから帰納的に推論が行えるためです.例えば,「データの生成過程は単純であり,学習されたモデルが単純なら未知のデータについても予測できる」と仮定し,過学習を抑制し単純なモデルが学習されるようにする正則化が良く行われてきました.NN の学習が上手くいく背景にも,このような正則化が働いていると考えられます.
しかしながら,現実に使われている NN はパラメタ数がデータより非常に多く,一見すると自由度が高すぎて過学習が起きやすいモデルに思えます.それにも関わらず,なぜ NN の学習は上手くいくのでしょうか?実はパラメタ数が多くなっても,学習された NN は過学習を起こしにくいことが実験的に示唆されています.例えば,Neyshabur ら [1] による実験では,NN のパラメタ数が増えても未知のデータに対する予測精度は保たれていて,過学習が防げていることが分かります.Zhang ら [2] による別の実験でも,\(l_2\)-正則化などの明示的な正則化がなくても学習後のNN の性能は良いことが示されています.これらの結果は,パラメタ数が多く明示的に正則化が行われない状況でも,何らかの形で過学習が抑制される正則化がかかっていることを示唆しています.
この暗黙的な正則化(implicit bias)の正体は何なのでしょうか?Neyshabur ら [1] は最適化アルゴリズムの性質によるものだという仮説を提示しました.例えば,確率的勾配降下法 (Stochastic Gradient Descent; SGD) は連続的にパラメタを更新していくアルゴリズムなため,初期値からあまり離れることができません.そのため,初期値が非常に小さい場合は,学習されたパラメタのノルムが小さくなると期待されます(図1).この小ノルム性が正則化として機能し,未知のデータに対する汎化性能に効いているのだというのが彼らの仮説です.Zhang ら [2] も同様に SGD に起因する小ノルム性に基づいた議論を行っています.
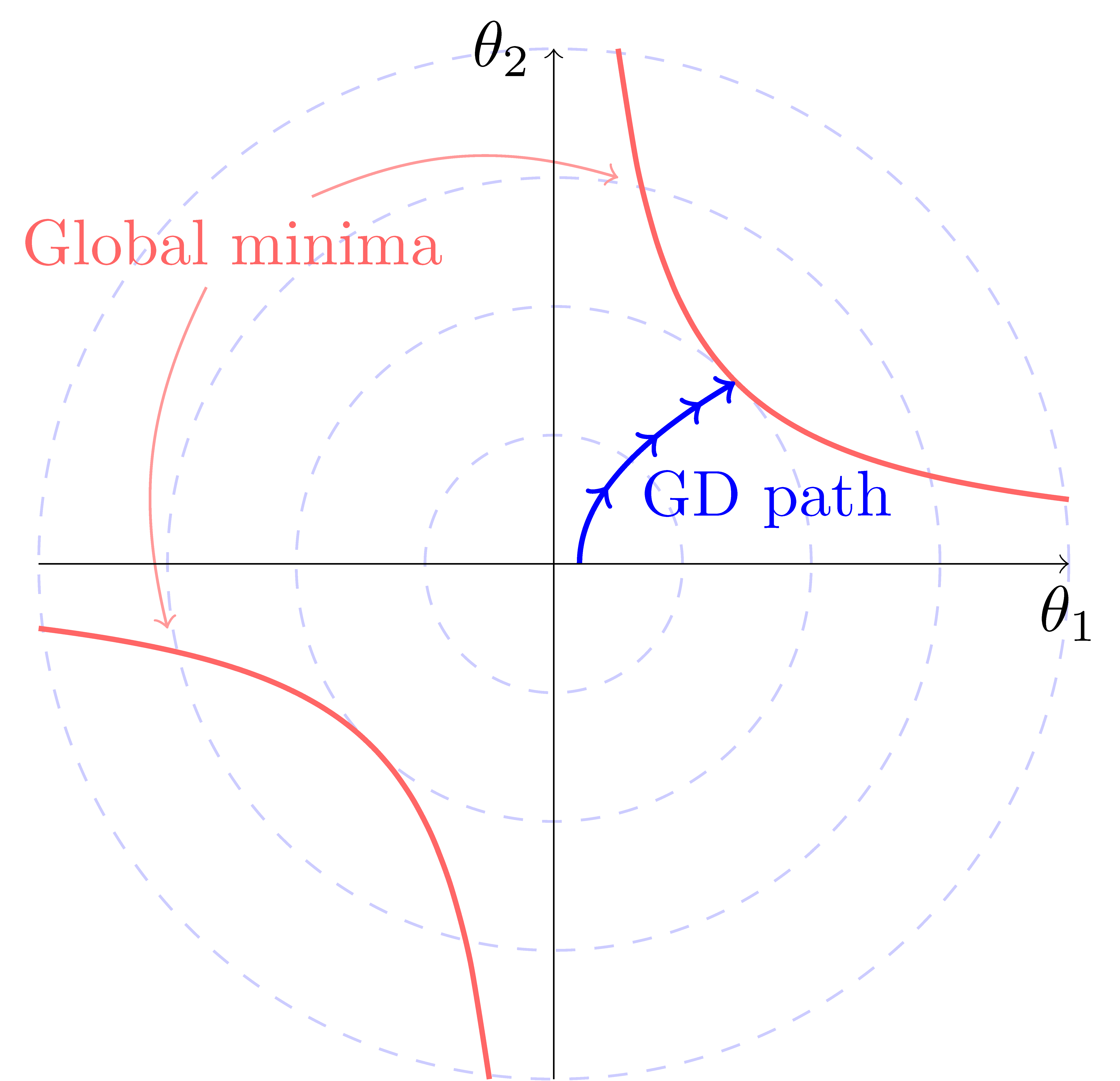
図1:SGD に起因する implicit bias.パラメタ \(\boldsymbol{\theta} = (\theta_i)_{i=1,2,\dots,}\) の数がデータより多い場合,大域的最適解(訓練誤差がゼロになる点)は典型的には複数あり,連続的に存在していることもあります.ゼロに近い初期値からSGD で最適化する場合,このように複数ある大域的最適解のうちで,ノルムが小さいものが得られることが期待できます.特に,行列補完という問題では,ノルムが最小な大域的最適解に到達するといくつかの状況で示されています.
Neyshabur ら [1] の議論は,行列補完という問題で,小ノルム性が良い解につながるという既存の知見に着想を得ています.行列補完は,行列 \(X \in \mathbb{R}^{n \times n}\) の成分の線形和がいくつか分かっているときに,すべての成分を求める問題です.具体的には,行列 \(A^{(\lambda)} \in \mathbb{R}^{n \times n}\) \(\lambda = 1,2,\dots, m\) と線形和 \(o^{(\lambda)} := \sum_{i,j = 1}^n A_{i,j}^{(\lambda)} X_{i,j} \) が与えられたとき,行列 \(X\) を推定する問題になります.行列補完は,線形 NN による回帰を具体例として含んでいて,NN の学習を単純化した問題とも捉えられます.線形話の個数 \(m\) が \(X\) の要素数 \(n^2\) より少ない場合,線形和の条件を満たす \(X\) は複数存在するため,元々の \(X\) を決定することは原理的には不可能です.しかし,\(X\) が低ランクであると分かっている場合には,トレースノルムを最小にする手法が上手くいくことが知られています.すなわち,線形和に関する条件を満たす \(X\) のうちで,トレースノルムを最小にするものを求めることで,元々の \(X\) を良く復元できることが知られています [3].ここで,行列 \(X\) のトレースノルムは,\(X\) の特異値が \(\{\sigma_i\}_{i=1,2,\dots,n}\) であるとき,以下の式で定義されます.
\[ \|X\|_{\mathrm{trace}} = \sum_{i=1}^n \sigma_i\].
Implicit bias は存在するのか
では,最適化手法に起因してパラメタのノルムが小さくなるという implicit bias は本当に起こっているのでしょうか?いくつかのモデルについては,implicit bias があることが理論・実験的に検証されています.例えば,先述した行列補完 [4,5,6] や,巡回畳み込みを行う線形 CNN [7] で証明されています.この記事では,行列補完に関する implicit bias について紹介します.
行列補完
先述した行列補完については,implicit bias の存在が理論的に証明されています.すなわち,明示的にトレースノルムを最小にする正則化を行わなくても,初期値が十分小さいなら勾配法の結果としてトレースノルム最小解が得られると,いくつかの状況で示されています.ここで,勾配法では,線形和についての二乗誤差
\[ \sum_{\lambda = 1}^m \left \| o^{\lambda} – \sum_{i,j=1}^n A_{i,j}^{(\lambda)} X_{i,j} \right\|_2^2 \]
を最小化します.また,最適化するパラメタとしては,\(X = U^\top U\) と分解された \(U\) を用います.この設定の下,Gunasekar ら [4] は,線形和を決めている行列 \(A^{(\lambda)}\) たちが可換であるときにimplicit bias の存在を証明しています.また,Li ら [5] は,線形和についてある種の等方性を仮定することで,implicit bias を示しています.一方で,Arora ら [6] は,より多層な分解 \(X = U_1 U_2 \dots U_n\) についての implicit bias を [4] と同じ設定の下で示しています.また,一般にはトレースノルムではなくeffective rank [8] という量が小さくなる正則化が起こっているのではないかと実験的に議論しています.行列補完は線形 NN による回帰を含んでいたので,これらの結果は線形 NN で回帰をする場合には implicit bias が存在することを意味しています.
まとめ
この記事では,パラメタ数が多く一見すると過学習が置きそうに思える NN であっても,学習アルゴリズムによる implicit bias のため過学習が抑制され,良い汎化性能につながっているという仮説を紹介しました.Implicit bias の存在は,限定的な状況ではありますが,いくつかの例では理論的に証明されていました.現実的な状況では,常にノルムの最小化が行われるわけではなく,アルゴリズムに起因する小ノルム性と勾配の関係で学習されるパラメタが決定されていると考えられますが,このような状況での実験・理論の両面での解析は未だに発展の余地があるものになっています.また,NN の学習を説明する試みは, Neural Tangent Kernel [9] のように他にも存在しています.
最後に,NN の学習という挑戦的で面白い課題に取り組む機会を与えてくださった PFN やサポートしてくださった皆さんにこの場を借りて謝意を表します.特に,メンターの林浩平さんと南賢太郎さんには,日々の議論など様々な面でご支援いただきました.本当にありがとうございました.
参考文献
[1] Behnam Neyshabur, Ryota Tomioka, Nathan Srebro: In Search of the Real Inductive Bias: On the Role of Implicit Regularization in Deep Learning. ICLR (Workshop) 2015.
[2] Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, Oriol Vinyals: Understanding deep learning requires rethinking generalization. ICLR 2017.
[3] Emmanuel J. Candès, Benjamin Recht: Exact matrix completion via convex optimization. Commun. ACM 55(6): 111-119 2012.
[4] Suriya Gunasekar, Blake E. Woodworth, Srinadh Bhojanapalli, Behnam Neyshabur, Nati Srebro: Implicit Regularization in Matrix Factorization. NIPS 2017: 6151-6159.
[5] Yuanzhi Li, Tengyu Ma, Hongyang Zhang: Algorithmic Regularization in Over-parameterized Matrix Sensing and Neural Networks with Quadratic Activations. COLT 2018: 2-47
[6] Sanjeev Arora, Nadav Cohen, Wei Hu, Yuping Luo: Implicit Regularization in Deep Matrix Factorization. NIPS 2019, to appear.
[7] Suriya Gunasekar, Jason D. Lee, Daniel Soudry, Nati Srebro: Implicit Bias of Gradient Descent on Linear Convolutional Networks. NeurIPS 2018: 9482-9491.
[8] Olivier Roy and Martin Vetterli. The effective rank: A measure of effective dimensionality. In15th European Signal Processing Conference, IEEE: 606–610. 2007.
[9] Arthur Jacot, Clément Hongler, Franck Gabriel: Neural Tangent Kernel: Convergence and Generalization in Neural Networks. NeurIPS 2018: 8580-8589.
総評
今回のインターンシップでは,中島さんには「最適化由来の正則化効果」という機械学習の中でも比較的新しいトピックに取り組んでいただきました.本記事で紹介されている implicit bias は理論研究としての側面が強く,正則化効果が発生することは限られた条件下では理論的に証明されているものの,現段階では工学的応用には結びついていません.しかしながら,implicit bias は最適化によって自動的に生じるため,追加の計算量を必要としない「経済的な」手法であるといえます.また,ニューラルネットワークがどのようにしてその強力な汎化能力を得ているのか,その原理の解明につながる一歩としても興味深い存在です.
PFNインターンでは,このような理論的トピックにも果敢に挑戦できる環境を提供しています.同様の興味を持つ学生の方はぜひ次の機会にご応募ください.
リサーチャー 林浩平,リサーチャー 南賢太郎
