Blog

写真1 Green500 No.1の証書
1. はじめに
2020年6月22日深夜(日本時間)にリモート開催されたISC2020のTOP500セッションで、PFNが作った深層学習用スーパーコンピュータ、MN-3が21.11 GFlops/WのHPLベンチマークの実行性能をあげ、Green500ランキングで500システム中No.1になりました(写真1)。開発チームの一員として、ここに至るまでの苦労の連続を思うと、とても嬉しいです。
なお、同日発表されたTOP500, HPCG, Graph500, HPL-AIベンチマークでは、理研に設置された「富岳」システムが各々500システム中1位、68システム中1位、10システム中1位、2システム中1位と、1位を多数達成したことも、ポスト京プロジェクト(富岳と命名される前の名前)の前座プロジェクトや、システム評価にかかわったものとして嬉しく思います。
このBlogでは最近増えてきてちょっと混乱状態の上記の様々なベンチマークプログラムで何が判るのか、Green500やTOP500でNo.1となることの意義などに触れてみたいと思います。
コンピュータの性能を測り、比較したいという試みはコンピュータの歴史において非常に古くからありました。ある程度標準性のある早期のこころみは、命令実行時間の重み付き平均をつかう、Gibson MixやScientific Mixのように命令速度から計算速度を測りました。パイプラインアーキテクチャやキャッシュメモリのように、実行する命令の順序や状況により実行速度がかわるようになると、〇〇Mixと命令の実行数の比率が近くなるような、プログラムとしては意味のない合成ベンチマークプログラムが使われるようになりました。Whetstoneベンチマーク(浮動小数点性能測定用)やDhrystone(整数性能測定用)です。Dhrystone値は、MIPS値とも呼ばれ、基準のコンピュータ(例えばDEC社のVAX11/780)を1MIPSと定義して、計算機の速度を現すものとして使われました。特に、Dhrystoneはプロセッサーの整数実行性能を知る簡易なわりに精度の高い方法なので、現在でも良く使われます。
では、このようなコンピュータのベンチマークプログラムが何故広く使われるようになったのか?
ユーザーがコンピュータを新たに購入する時、特に大型コンピュータは高価なので性能が良く、コストパフォーマンスが良いものを買いたいからです。また、並列コンピュータが普及する前は、問題が1台のコンピュータで解けることがもとめられますので、速度は非常に重要なファクターでした。このことから、コンピュータメーカー各社は性能数値を少しでも上げる最適化にしのぎを削りました。その結果、絶対性能が一番高速であるかコストパフォーマンスが最高でないメーカーは戦線から離脱せざるを得ないので、ベンチマーク値は会社の命運を決める重要なものとして扱われました。
一方、科学技術計算が主な目的のコンピュータ、スーパーコンピュータでは整数性能だけでなく、浮動小数点演算性能がプログラムの高速化にとり重要です。
科学技術計算用コンピュータを目的としたベンチマークプログラムでは、初期の科学技術計算の中心がCFD(計算空気力学、航空機の設計に使う)やFEM(有限要素法、原子炉の設計などの構造計算に使う)であり、これらの解法の中心が連立一次方程式の求解であったことから、一次方程式を解くことがベンチマークプログラムとして使われました。これがLinpackベンチマークの始まりです[1]。LINPACKは最初は100×100の行列計算から始まり、測定する行列サイズは変化したもののスーパーコンピュータのベンチマークとしてTOP500, Green500を始め現在でも多用されています。それは、連立一次方程式を解くこと、およびその中で使われる行列積が数値計算だけでなく、ディープラーニングをはじめとする多くの分野でも使用されるからです。
その後、ベクトル計算機が多用されるようになり、ベクトル計算機による高速化を評価するローレンスリバモアループ[2]が多用されるようになりました。リバモアループは、14個または24個の数値計算プログラムに頻出する数行のカーネル部分を取り出して実行速度を計測するものです。例えば:
S = S + X(i)
Y(i) = X(i) – X(i-1)
等をiに関してループを回して実行します。なお、現在ではベクトル計算機が殆ど使われなくなったこと、並列コンピュータの登場によりローレンスリバモアループは殆ど使われなくなっています。
2. MN-3システム
本稿を書くきっかけとなった、深層学習用超省電力スーパーコンピュータMN-3を紹介します。MN-3(写真2)は、著者が所属するPFNが神戸大学の協力を得て開発したコンピュータで、社内における深層学習の計算需要を満たすために使われます。MN-3の心臓部は、PFNと神戸大学の牧野淳一郎教授による共同研究により開発された深層学習専用の超省電力アクセラレータMN-Core™(写真3)で、4個のシリコンダイを実装したチップを多層プリント基板に実装したものです。MN-3は、JAMSTEC (国立研究開発法人 海洋研究開発機構) 横浜研究所 シミュレータ棟に設置され、2020年5月より稼働を開始しています。

写真2 深層学習用スーパーコンピュータMN-3

写真3 MN-Core深層学習用アクセラレータ

写真4 MN-Core チップ
MN-3およびMN-Coreの主要諸元を表1、表2に示します。
| 項目 | 内容 |
| パッケージ | 4シリコンダイで構成 |
| 消費電力(予測値) | 4シリコンダイで最大500W |
| 電力効率(設計値) | DP: 32.8 Tops / 0.066 Tops/W |
| SP: 131 Tops / 0.26 Tops/W | |
| HP: 524 Tops / 1 Tops/W | |
| アーキテクチャ | 階層的SIMD |
| チップ内メモリ | SRAM(容量は非公開) |
| メモリ容量 | 32GB |
表1 MN-Coreの主要諸元
| 項目 | 内容 |
| 1ボード性能 | |
| HGEMM | 1.23TFLOPS/W (効率100%) |
| HPL性能 | |
| システム規模 | 160ボード(40ノード) |
| 電力効率 | 21.11Gflops/W |
| Rmax | 1.62Pflops |
| 消費電力 | 76.8Kw |
| Rpeak | 3.92 Pflops |
| Rmax効率 | 41% |
| インターコネクト | RoCEv2/MN-Core DirectConnect |
表2 MN-3の主要諸元
なお、Green500で使われたデータは、MN-3のうち40ノード、MN-Core160個を用いて測定されました。
MN-Core設計の源流をたどると、2004年から文部科学省科学技術振興調整費により筆者と牧野淳一郎(当時東京大学理学系研究科助教授)が実施したGRAPE-DRプロジェクトと、そのプロジェクトが開発したGRAPE-DR省電力スーパーコンピュータシステムに行きつきます。GRAPE-DRがLittle-Green500でNo.1になった2010年6月からちょうど10年の歳月を経てふたたびMN-Coreを用いて省電力世界一を達成できたことに、なにか運命を感じます。
3. TOP500とGreen500
TOP500はLinpackプログラムを用い、問題サイズを任意の大きさとして与えられた問題の解を求め、総演算回数を計算に要した時間で除することにより、Linpackにおける平均計算速度を求め、TOP500.orgに申告されたシステム性能をNo.1からNo.500までリストにしたものです。1993年に始まり、以後毎年6月と11月に更新されます。
TOP500がそれまでのベンチマークプログラムと大きく違う点は
- 問題サイズを無制限にしたため、計算時間はかかるが大規模並列スーパーコンピュータの性能が比較できるようになった
- TOP500以前に広く使われていたNAS Parallel Benchmarkは共有メモリ並列コンピュータを目的としていたので、大規模並列コンピュータでは性能が大きく落ち評価に向かなかったことに対し、Gustavsonの再帰的分割アルゴリズム[3]を使うと、各要素プロセッサーのメモリバンド幅と演算速度の比(B/F比と呼ばれる)をメモリ量を大きくすれば小さくすることが可能となり、巨大なシステムでもスケーラブルな性能が得やすく、超大型スーパーコンピュータの性能比較に使える
- TOP500を作る主な目的をスーパーコンピュータセンターの管理者や予算源である政府関係者へのアピールに絞り、より多くのスーパーコンピュータに予算が付き易くすることに焦点をあてている。特に地球シミュレータが2年半連続でNo.1を獲得した時や中国の天河、神威・太湖之光がNo.1を連続的に占めた時にTOP500リストが米国のスーパーコンピュータ増強について使われていたことは記憶に新しいところです。
TOP500でNo.1を獲得するためにはできるだけ大規模なスーパーコンピュータを作ることが必要であり、(1)十分な予算(1千億円レベル)、(2)十分な電力を供給できるスーパーコンピュータセンターの設備(30~50MWクラス)、(3)巨大システムが長期間安定に動作する信頼性が揃うことが必要です。その困難さからNo.1の獲得が国家間の国際競争にすらなっています。しかしながら、TOP500は国家規模のスーパーコンピュータのベンチマークとしては有益ではあるが、産業用に使われる規模に対するベンチマークとしては運用コストなど必要な観点が弱く、十分なものとは言えません。
Green500はこのような背景から、スーパーコンピュータを導入するためのコストパフォーマンスという視点で、スーパーコンピュータの消費電力効率を取り上げた点が優れていると考えています。実際、スーパーコンピュータの使用期間として5年から6年を考えるとスーパーコンピュータの購入費を電気代が上回ることが多いと思います。
Green500リストは、Green supercomputingの提唱者であるバージニア工科大学の Feng 教授を中心とするグループが 2007年11月から年 2回発表し、2016年からはTOP500リストとマージされ、TOP500リストを1W当たりのLinpack演算速度でソートしなおしたものとして発表されています。
実際、2007年から2020年までの13年間で、Green500リストのNo.1システムの電力効率は60倍向上しています(図4)。Green500の重要性は以下の諸点にまとめられます。
(1)高い省電力性はスーパーコンピュータの使用開始から停止までの電力料金、冷却費用を含めたトータルコストを下げ、経済的である。
(2)高い省電力性をもつプロセッサー・アクセラレータを用いると同じ使用電力の制限中で、より高い性能のシステムを構築することが可能である。
(3)省電力性能はシステムの規模に依存しない、技術力が示される指標である。
それでは、何故PFNがGreen500に代表される省電力スーパーコンピューティングに興味を持ったか?深層学習用プロセッサーにとり消費電力を著しく下げることの意味はなにか?これらについて次節で説明します。
4. 深層学習と省電力スーパーコンピューティング
PFNでは現在深層学習システムと、深層学習の応用分野に重点を置いて活動しています。深層学習用スーパーコンピュータMN-3は、こうした社内の深層学習計算需要を低コストで満たすために開発されました。電力効率が高いことにより、深層学習用コンピュータの運用経費が大きく削減できるからです。特に、MN-3で用いている深層学習用アクセラレータは深層学習で多用する半精度浮動小数点の実行効率を高くする基本設計を用いているため、深層学習においてはGreen500における1Wあたり演算速度の数十倍の省電力効率を実現します。
更に、超省電力の深層学習用アクセラレータの実現にはコスト削減以上のインパクトがあります。深層学習は大別して、多数のデータから特徴などを抽出する「学習(Training)」と、学習結果を現実社会からの入力データに適用する「推論(Inference)」に分かれ、これまではデータセンターにある深層学習用スーパーコンピュータで学習を担当し、エッジデバイス(ロボット、自動車など)では小型の推論用プロセッサーを用いていました。
しかしながら、将来の深層学習を用いる知的システムではエッジ側でも常に学習を行うことが必要であり、そのための消費電力がエッジデバイスの小型化を実現する上での障害になります。例えば、電池で駆動する深層学習用コンピュータが、現在の大規模学習用スーパーコンピュータと並ぶ能力を得るためには、更に何十分の1という省電力化を実現することが必要です。
MN-3で達成し、Green500リストのNo.1になったことは、将来どこにでも存在する学習能力への第一歩といえます。その実現が将来の社会に与えるインパクトは非常に大きいと考えています。現在のMN-3は電池駆動が可能である1Wで、最新のサーバ用汎用プロセッサーが100Wを要する学習能力を持つことができます。5年後から10年後のどこでも学習する社会の姿に向けて、更に研究開発を続けたいと考えています。
参考文献
- [1] LINPACK Users’ Guide (J. J. Dongarra, J. R. Bunch, C. B. Moler and G. W. Stewart), SIAM Review, 1979.
- [2] F. H. McMahon. Livermore fortran kernels: A computer test of numerical performance range. Technical Report UCRL-53745, Lawrence Livermore National Laboratory, Livermore, CA, December 1986. NTIS report #DE87009360
- [3] F. G. Gustavson, Recursion leads to automatic variable blocking for dense linear-algebra algorithms, IBM Journal of Research and Development, November 1997
https://doi.org/10.1147/rd.416.0737
付録
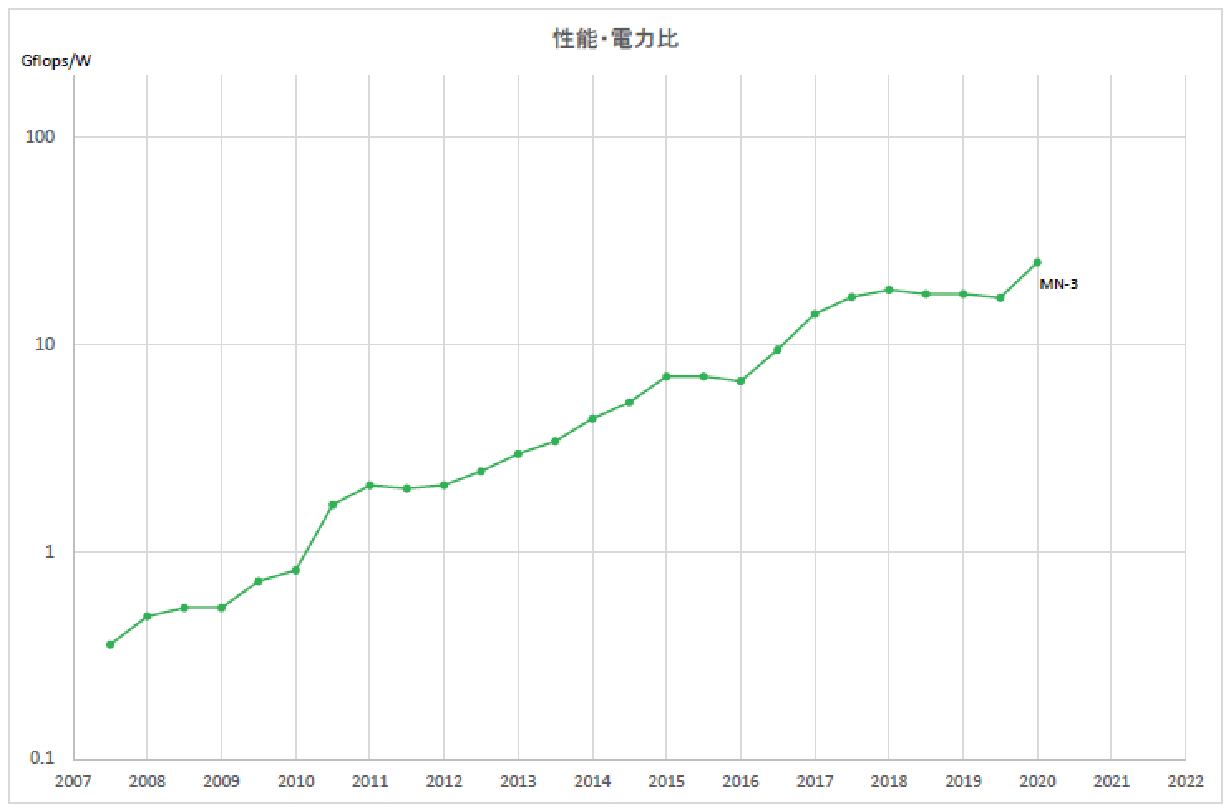
図4 Green500の性能向上の推移
著者略歴
東京大学理学系研究科物理学専門課程修了理学博士。電子技術総合研究所、IBM社T.J.Watson研究センター、東京大学理学部助教授、東京大学情報理工学系研究科教授を経て現在Preferred Networksシニアリサーチャー。東京大学名誉教授。コンピュータ・アーキテクチャ、並列分散計算、再構成可能デバイスを用いた計算、超高速ネットワーク、分散共有ファイルシステム研究に従事。
Area



