Blog
ハイパーパラメータ自動最適化フレームワークOptunaの3番目のメジャーバージョンをリリースしました。リリースノートをぜひチェックしてください!
Optunaは2020年1月に最初のメジャーバージョンを、2020年7月に2番目のメジャーバージョンをリリースし、以来ユーザコミュニティ・開発コミュニティの双方が大きく成長し続けてきました。ユーザコミュニティについては、月間ダウンロード数が143万回に上り、GitHubにおいて6800スターを超えました。開発コミュニティについては、177名のコントリビュータと共に開発されるようになり、v2.0以降にマージされたPRは1225件にも上ります。

このv3.0で、Optunaは大きく成長することができました。我々は以下のような目標を掲げてv3.0の開発を進めてきました。
- コミュニティに向けて開発方針をオープンに
- ロードマップを公開し、GitHub issue上で開発アイテムについて議論する
- ソフトウェアとして安定性を高める
- 仕様が曖昧な部分を大幅に削減する
- 実験的に導入されていた機能を安定した機能としてリリースして良いか判断する
- 重要な機能やアルゴリズムを全てのユーザに届ける
- デフォルトの機能のパフォーマンスを改善する
- 既存の重要な機能やアルゴリズムをライトユーザが利用できるようにする(多変量TPE, constant liar戦略など)
このブログでは、これらの目的の達成によりOptunaがどのように進化したのかをお伝えします。
TL;DR
- 開発ロードマップを公開して多くのコントリビュータと力を合わせて開発を行った。
- ソフトウェアとしての安定性を高めるため、ユーザが接する機会の多い機能のAPI単純化・安定化・リファクタリングを行った。
- 初めてアルゴリズムの大規模なベンチマーキングを行い、v3.0以前に導入され開発者からの期待の高い機能の有用性を示した。
- コントリビュータの協力により予定よりも多くの新機能が導入された。
Collaboration with contributors
我々は、v3.0を成功させるためにはコミッター(Optunaのメンテナ)の力だけでは不十分であり、多くのコントリビュータの力を合わせる必要があると考えました。コミッターでない人でもv3.0の開発がどのように行われるのか理解しやすくするためにGitHubのissueを整備し、それらをまとめてロードマップを作成してGitHubのwikiで公開しました。また、v3.0の開発を進めると同時にコミッターとコントリビュータのコミュニケーションを促進するために日本国内向けに開発スプリントを企画しました。開発スプリントは全部で6回実施し、多くのコントリビュータが参加しPRを獲得することができました。開発スプリントはv3.0以降も継続して、今度は全世界的に実施していく予定なので、興味のある方はぜひご参加ください。
Improved Stability
Optunaにはユーザが接する機会の多いAPIがいくつもあります。必ずと言って良いほど使われるのはsuggest APIとStudyクラスです。結果の分析のために可視化モジュールも頻繁に使われます。v3.0ではそれらの多くが単純化・安定化・リファクタリングされました。これらの機能がどのように変化したのかを簡単にご説明します。
Simplified Suggest API
suggest APIは、探索空間からパラメータをサンプルするために用いられるAPIです。v3.0では、suggest APIはサンプルしたい変数の型に応じて浮動小数点数のための `suggest_float`、整数のための `suggest_int`,、カテゴリカルな変数のための `suggest_catagorical`の三つに集約されました。細かい探索方法の違いは、それらのメソッドの引数によって指定されるようになりました。よりシンプルなsuggest APIを利用することで、より可読性の高いコードを記述することができるようになります。
例えば、`suggest_float`がv2系からv3でどのように変化したのか見てみましょう。`low`以上`high`未満の浮動小数点数`x`をパラメータとしてサンプルしたい場合は以下のようにします。
# v2系でのコード
x = trial.suggest_uniform("x", low, high)
# v3.0からのコード
x = trial.suggest_float("x", low, high)
もし、範囲の中で`low`付近を重点的に探索したければ以下のようにすると良いでしょう。
# v2系でのコード
x = trial.suggest_loguniform("x", low, high)
# v3.0からのコード
x = trial.suggest_float("x", low, high, log=True)
もし、`low + k`, `low + 2 * k`, `low + 3 * k`, …, のように離散的な集合からサンプルしたければ以下のようにすると良いでしょう。
# v2系でのコード
x = trial.suggest_discrete_uniform("x", low, high)
# v3.0からのコード
x = trial.suggest_float("x", low, high, step=k)
v3.0では浮動小数点数をサンプルするためのsuggest メソッドが`suggest_float`に一本化され、シンプルになっていることがわかると思います。
suggest APIの単純化は以下のコントリビュータの力によって実現されました。ありがとうございました! @himkt, @nyanhi, @nzw0301, and @xadrianzetx
Created Test Policy
Optunaのコードベースが成長していくにつれて、そのテストコードもまた大きくなっていました。しかしテストの書き方やテストケースの粒度は個々の開発者によってバラバラで、統一性を欠いた状況になっていました。我々はこのような状況を憂慮し、v3で、Optunaのテストがどのように行われるべきであるかを定めたTest policyを策定し公開しました。公開されたTest policyをもとに実際に多くのユニットテストの修正に取り組みました。
Test policyの策定やそれに基づくユニットテストの修正は多くのコントリビュータの手によって実現されました。ありがとうございました。 @HideakiImamura, @c-bata, @g-votte, @not522, @toshihikoyanase, @contramundum53, @nzw0301, @keisuke-umezawa, @knshnb
Visualization Refactoring
Optunaは最適化だけでなく、最適化結果の分析にも用いることができます。Optunaの可視化モジュールは、最適化結果を可視化して分析するために用いる機能です。現在OptunaにはPlotlyをバックエンドとして可視化するモジュール(optuna.visualizationにある可視化関数)と、Matplotlibをバックエンドとして可視化するモジュール(optuna.visualization.matplotlibにある可視化関数)があります。歴史的には前者がまず実装され、しばらく経った後に後者が実験的に導入されました。これまで両者は別々に開発されてきたため、片方にある機能がもう片方になかったり、フォーマットに統一性がなかったり、内部実装の差異が大きかったりという問題を抱えていました。
このタスクは、機能的な差異の解消にとどまらず、内部実装の共通化やテスト戦略の改善など、様々な技術的問題を包含し、それらは多くのコントリビュータの手によって一つ一つ解決されました。普段は一緒に仕事をすることのない人々が、OptunaというOSSの場で協力し、このプロジェクトを成功に導いたということは、v3.0の成功を象徴する大きな成果の一つです。以下はこのプロジェクトに関わったコントリビュータたちです。ありがとうございました!
@HideakiImamura, @IEP, @MasahitoKumada, @TakuyaInoue-github, @akawashiro, @belldandyxtq, @c-bata, @contramundum53, @divyanshugit, @divyanshugit, @dubey-anshuman, @fukatani, @harupy, @himkt, @kasparthommen, @keisukefukuda, @knshnb, @makinzm, @nzw0301, @semiexp, @shu65, @sidshrivastav, @takoika, @xadrianzetx
Stabilized Features
v2系まで、我々は多くの機能をOptunaに導入してきました。それらの機能の多くは仕様の曖昧性・潜在的なバグの存在・ユースケース分析の不足等によりexperimentalなものでした。我々はv3.0の開発を通して、多くのexperimentalな機能について仕様の明確化・バグフィックス・ユースケース分析等を行い、それらを安定した機能として提供することにしました。以下はv3.0で安定化された機能の一覧です。
- optuna.study.MaxTrialsCallback
- optuna.study.Study.enqueue_trial
- optuna.study.Study.add_trial
- optuna.study.Study.add_trials
- optuna.study.copy_study
- optuna.trial.create_trial
- optuna.visualization.plot_pareto_front
これらの機能の安定化は多くのコントリビュータの手によって実現されました。ありがとうございました。 @contramundum53, @knshnb, @HideakiImamura, and @himkt
Performance Verification
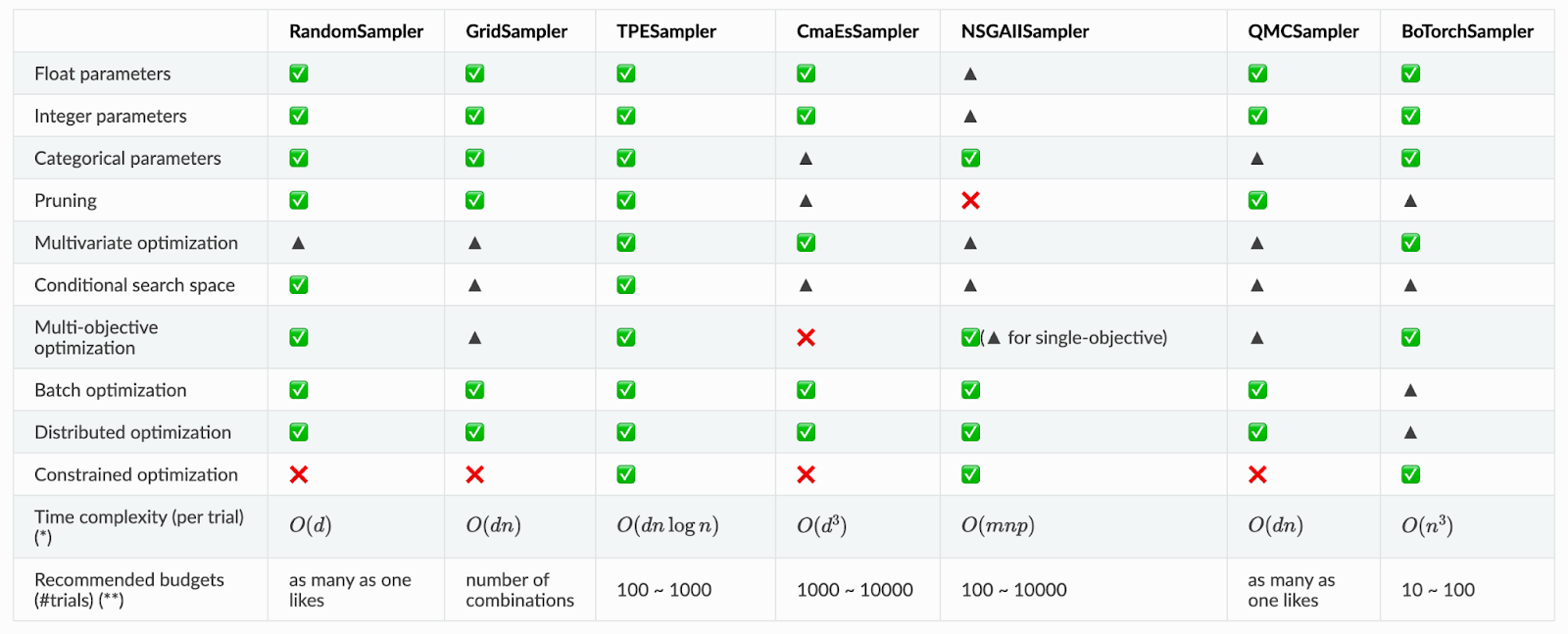
Optunaにはブラックボックス最適化問題を解くための多くの最適化アルゴリズムが実装されています。現在のデフォルトはTree-structured Parzen Estimator (TPE)と呼ばれるベイズ最適化のアルゴリズムです。まずv3.0では、経験的に知られていたアルゴリズムの振る舞いやOptunaにおける実装の特徴をまとめて表として公開しました。
このような表は、ユーザが自分の目的に応じて最適化アルゴリズムを選ぶ際の助けになるでしょう。しかし、定量的にアルゴリズムの性能を評価するためにはこれだけでは不十分です。我々は、v3.0においてOptunaのアルゴリズムのパフォーマンス評価を行うためにベンチマーク環境を整備し、デフォルトアルゴリズムの変更を視野に入れてパフォーマンス評価実験を行いました。以下では、整備したベンチマーク環境とパフォーマンス評価実験について簡単に説明します。
Benchmark Environment
ベンチマーク環境を整備するにあたって、我々は誰でも簡単に実験を再現できることが重要であると考えました。ベンチマーク環境は、samplerやprunerを指定して特定の問題を解くためのスクリプトと、それをGitHub Actions上で動かす仕組みから成ります。Optunaで現在利用できる問題は、機械学習のハイパーパラーメータ最適化や有名なテスト関数を含む170種類以上です。ユーザやコントリビュータは、自分のローカル環境でスクリプトを実行することもできますし、自分のoptunaのforkのGitHub Actions上で手軽にワークフローを実行することもできます。ベンチマーク環境の詳細について知りたい方は、こちらをご覧ください。
ベンチマークスクリプトの実装やGitHub Actions上のワークフローの整備には多くのコントリビュータが関わりました。ありがとうございました。 @HideakiImamura, @drumehiron, @xadrianzetx, @kei-mo, @contramundum53, @shu65
Benchmark Experiment
整備したベンチマーク環境を用いて、我々はパフォーマンス評価実験を行いました。これはOptunaに実装されているアルゴリズムを様々な問題設定においてフェアに比較し、それらのデフォルト引数の変更またはOptunaのデフォルトアルゴリズムの変更を行うためです。
全てのsamplerとprunerの全ての引数の組み合わせに対して実験をおこなうことは非現実的なため、我々は重要な引数に絞ってベンチマークをとりました。それでも30種類上のsamplerとprunerと170種類上のproblemの組み合わせに対して1000trialを100study実行し、実に5億トライアル以上の巨大な実験を行いました。これは我々の知る限り最も多様で多くの問題を扱ったブラックボックス最適化問題のベンチマークです。もちろんこれを全てGitHub Actions上で行うことは難しいため、Preferred Networks, Incの保有する計算クラスタを用いて凡そ7000CPU並列で3日程度の時間をかけて実験を実施しました。以下はベンチマーク結果の簡単なまとめです。
- Samplerベンチマーク
- `TPESampler` はOptunaの現在のデフォルトサンプリングアルゴリズムです。`TPESampler`は現在のデフォルトの引数のまま用いることで多くの設定で高い性能を発揮しました。しかし問題の種類やトライアル数の大きさによっては、別のサンプラーが高い性能を発揮することもわかりました。
- `TPESampler`の`multivariate`オプションは、多変量サンプリングを有効化するためのオプションです。`multivariate`オプションのデフォルト値は現在`False`です。`multivariate`オプションの値を`True`に設定することで多くのケースでパフォーマンスが上がることを確認しましたが、いくつかの設定、特に高次元の問題に対しては、むしろ性能が悪化することがわかりました。デフォルト引数の変更は、非常に多くのユーザに対して影響を及ぼします。我々は、今回は保守的な立場を取り、`multivariate`オプションのデフォルト値を`True`には変更しないと結論しました。
- また、既存の`asv`に基づいた環境を用いて速度ベンチマークも実施しました。`multivariate`オプションを`True`に設定することでサンプリングの速度が向上することを確認しました。ただし、この速度の差は実装に依存したものであり、将来的に状況が変わる可能性があります。
- 分散最適化におけるSamplerベンチマーク
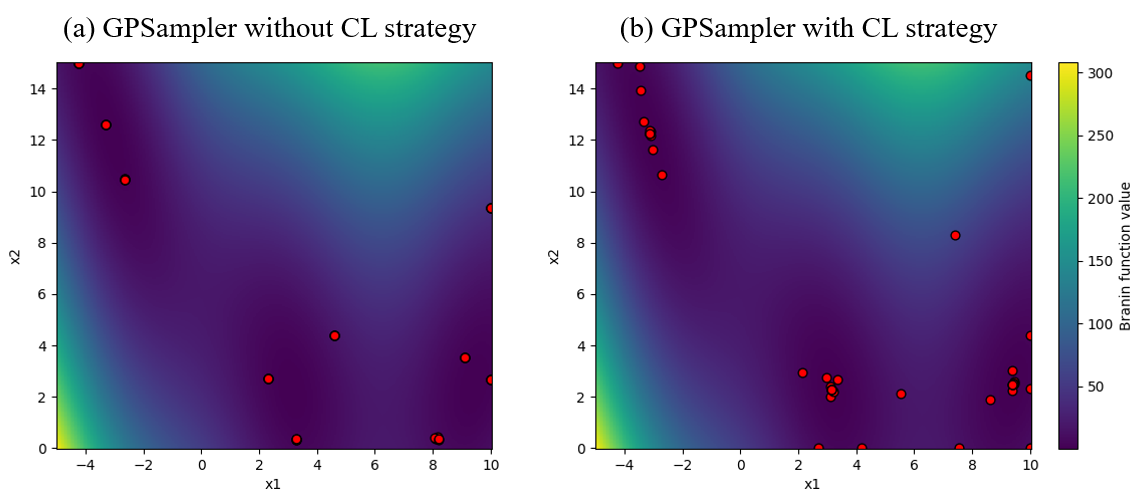
- 我々は分散最適化におけるベンチマークを実施しました。`TPESampler`の`constant_liar`オプションは、constant liar戦略と呼ばれるアルゴリズムを有効化するためのオプションです。我々は、`constant_liar`オプションを`True`に設定したとしても、パフォーマンスが改善するとは限らないということを確認しました。また、問題の種類によっては、ガウス過程に基づくアルゴリズムが実装されている`BoTorchSampler`が高い性能を発揮することがわかりました。`TPESampler`の`constant_liar`オプションのデフォルトの値は`False`ですが、我々はこれを`True`には変更しないと結論しました。
- Prunerベンチマーク
- `MedianPruner`はOptunaの現在のデフォルト枝刈りアルゴリズムです。一方で、`HyperbandPruner`はコミッタからの期待の高い先進的なprunerです。実験結果からは、いくつかのケースでは`MedianPruner`の方が性能が高いことがわかりましたが、また別のケースでは`HyperbandPruner`の方が性能が高いことがわかりました。ただし、本実験においては全てのprunerについて、そのデフォルト引数を用いています。引数を問題に合わせて調整することで、異なる結果が得られる可能性があることに注意してください。以上の結果を受けて、我々は現段階ではデフォルトの枝刈りアルゴリズムを変更しないと結論しました。
また、以下は各samplerのデフォルト引数について、HPO bench (naval)というproblemにおける、そのtrialまでに得られた最適な目的関数の値の変化をプロットしたものです。今回の実験では、このようなグラフが他にも170枚以上得られています。
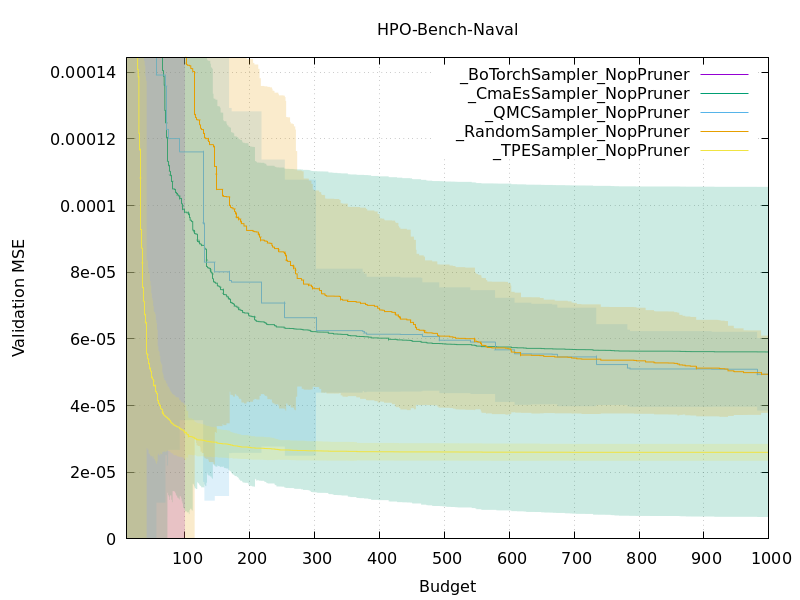
これらのベンチマーク実験はGitHub Actions上で容易に再現できます。GitHub Actionsのリソース制限の関係上全てを短期間に再現できませんが、特定のアルゴリズムの振る舞いについてもっと詳細に調べたい場合はぜひご自分でもおためしください。ベンチマーク実験の詳細な結果に興味のあるかたは、#2964や #2906 をご確認ください。
What’s Next
ここまで読んでいただきありがとうございました。次の後編では、Optuna v3.0に追加された様々な新機能と、ロードマップにはありましたが紆余曲折を経て実際には取り組まなかった開発アイテムについてお話しします。お楽しみに!
後編へ続く…