Blog
はじめに
ブラックボックス最適化フレームワークOptunaの新しいバージョンであるv4.2をリリースしました。今回のリリースには、SMAC3やガウス過程ベースの制約付きベイズ最適化のサポート、大規模な並列分散最適化を実行するためのgRPCストレージプロキシ、OptunaHubによるベンチマーク関数の提供が含まれています。
ぜひ以下のコマンドを実行して、最新のOptunaおよびOptunaHubをぜひお試しください。
$ pip install -U optuna optunahub
RDBStorage向けのgRPCストレージプロキシ
Optunaでは大規模な分散最適化を可能にするためにこれまでも様々な改善を加えてきました。例えば前回のリリースであるv4.1では、RDBStorageのクエリチューニングにより大幅な速度改善を達成しました(表1)。
表1:RDBStorageの速度改善
| # Trials | v4.0.0 | v4.1.0 | Diff |
| 1000 | 72.461 sec (+/- 1.026) | 59.706 sec (+/- 1.216) | -17.60% |
| 10000 | 1153.690 sec (+/- 91.311) | 664.830 sec (+/- 9.951) | -42.37% |
| 50000 | 12118.413 sec (+/- 254.870) | 4435.961 sec (+/- 190.582) | -63.39% |
その一方で数千ワーカーを超えるようなより大規模な分散最適化によってRDBサーバーが高負荷になるケースでは、対症療法的なクエリチューニングやRDBサーバー側のパラメーターチューニングで乗り切るのは難しく根本的なアーキテクチャの見直しが必要な場合もあります。gRPCストレージプロキシはこのような非常に大規模な分散最適化を可能にするための機能です。イメージ図を図1に示します。
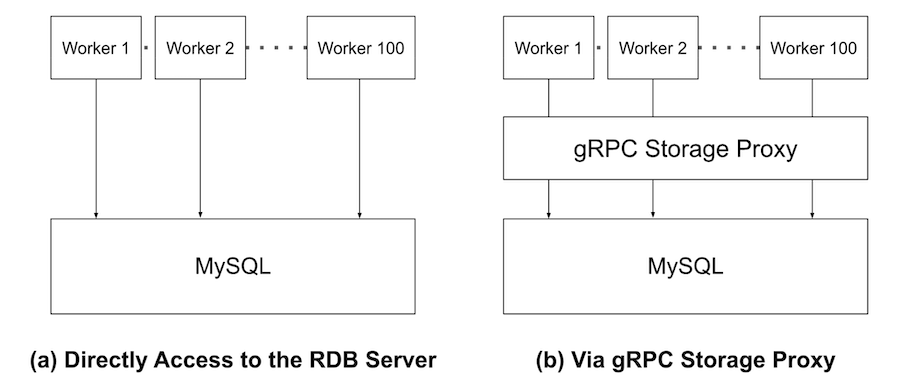
図1:gRPCストレージプロキシのイメージ図
図1にあるようにgRPCストレージプロキシは、最適化実行ワーカーとデータベースサーバーの間に入り、Storage APIの呼び出しを中継します。数百から数千のワーカーが動作する大規模な分散最適化の設定では、数十台ごとにgRPCストレージプロキシを設置することで単一障害点となるRDBサーバーの負荷を大幅に軽減できます。またOptunaのStudyやTrialといった情報をワーカーから共通に利用できるキャッシュとして管理することでも負荷の軽減が期待できます。
gRPCストレージプロキシの概念実証のため、以下のような設定でパフォーマンス比較を行いました。データベースサーバーとしてMySQLサーバーを用意します。300台のワーカーに対して10台ごとにプロキシサーバーを設置しStorage APIの呼び出しを中継することで、10000 Trialsの分散最適化をRandomSamplerを用いて実行しました。以下はワーカーごとにかかった処理時間の平均値です。この実験シナリオでは処理時間を6割削減できました(表2)。
表2:大規模分散最適化時の速度改善
| (a) gRPC Storage Proxyなし | (b) gRPC Storage Proxyあり | Diff |
| 329.05 sec | 120.14 sec | -63.49% |
なお、このパフォーマンス比較はMySQLサーバーに大きく負荷がかかる設定となっており、MySQLサーバーが十分に処理できるワーカー数であればgRPCのオーバーヘッドの分だけgRPCストレージプロキシの方が遅くなる可能性があります。実際、単一ワーカーでは1.2~1.3倍程度の速度低下を確認しています。あくまでgRPCストレージプロキシは大規模な分散最適化向けの機能であることにご注意ください。
このようにgRPCストレージプロキシを利用することで大規模な分散最適化を行う際のデータベースサーバーへの負荷を軽減することができます。さらなる利用方法の詳細は公式ドキュメントをご確認ください。
SMAC3: AutoML.orgが開発するランダムフォレストベースのベイズ最適化手法
SMAC3 [1] はAutoMLで著名な研究グループであるAutoML.orgによって開発されているハイパーパラメータ最適化フレームワークです。今回AutoML.orgのメンバーであるDifan Deng氏 (@dengdifan) によってOptunaHubにSMAC3を登録していただきました。これによって、AutoMLの研究や応用で最も利用されている手法の1つであるランダムフォレストベースのベイズ最適化手法をOptunaでも利用できるようになりました。簡単な利用方法を以下に示します。
$ pip install optunahub smac==2.2.0
import optuna
import optunahub
from optuna.distributions import FloatDistribution
def objective(trial: optuna.Trial) -> float:
x = trial.suggest_float("x", -10, 10)
y = trial.suggest_float("y", -10, 10)
return x**2 + y**2
smac_mod = optunahub.load_module("samplers/smac_sampler")
n_trials = 100
sampler = smac_mod.SMACSampler(
{"x": FloatDistribution(-10, 10), "y": FloatDistribution(-10, 10)},
n_trials=n_trials,
)
study = optuna.create_study(sampler=sampler)
study.optimize(objective, n_trials=n_trials)
こちらのOptunaHubのWebサイト を参考にSMACSamplerをぜひご利用ください。
[1] M. Lindauer, K. Eggensperger, M. Feurer, A. Biedenkapp, D. Deng, C. Benjamins, R. Sass, and F. Hutter. SMAC3: A Versatile Bayesian Optimization Package for Hyperparameter Optimization. Journal of Machine Learning Research, 23(54), 1-9.
OptunaHubによるベンチマーク関数の提供
最適化アルゴリズムの性能評価を行うベンチマーキングは、アルゴリズムの研究や開発に欠かせない重要なプロセスです。Optuna v4.2と合わせてリリースされたoptunahubの最新バージョンであるv0.2.0に新たに追加されたOptunaHub Benchmarksは、ユーザがベンチマークを便利に行うための新機能です。
次のサンプルコードでは、ブラックボックス最適化の研究コミュニティで広く用いられているBlackbox Optimization Benchmarking (BBOB)と呼ばれるベンチマーク関数群に含まれる2次元のSphere関数を使って4種類のサンプラーの性能を比較して表示します(図2)。
import optuna
import optunahub
bbob_mod = optunahub.load_module("benchmarks/bbob")
smac_mod = optunahub.load_module("samplers/smac_sampler")
sphere2d = bbob_mod.Problem(function_id=1, dimension=2)
n_trials = 100
studies = []
for study_name, sampler in [
("random", optuna.samplers.RandomSampler(seed=1)),
("tpe", optuna.samplers.TPESampler(seed=1)),
("cmaes", optuna.samplers.CmaEsSampler(seed=1)),
("smac", smac_mod.SMACSampler(sphere2d.search_space, n_trials, seed=1)),
]:
study = optuna.create_study(directions=sphere2d.directions,
sampler=sampler, study_name=study_name)
study.optimize(sphere2d, n_trials=n_trials)
studies.append(study)
optuna.visualization.plot_optimization_history(studies).show()
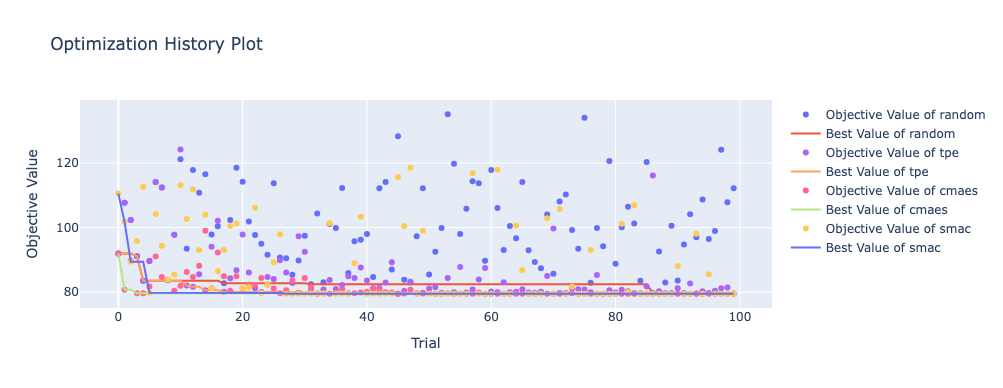
図2:ベンチマークの実行結果
OptunaHub Benchmarksを利用することで、気軽に様々な問題を利用してアルゴリズムのベンチマークを行うことができます。アルゴリズムの研究開発用途のほかにも、実問題に取り組む前の簡単な予備実験での利用、アルゴリズム学習時のトイプロブレムとしての利用など、色々なユースケースが考えられる機能なので、ぜひともご活用していただければと思います!
ガウス過程ベースの制約付きベイズ最適化サポート
ガウス過程ベースのベイズ最適化は材料科学や航空機設計等を初めとした様々な分野で根強い人気のある手法です。Optunaではv3.6よりGPSamplerを提供してきましたが、Optuna 4.2ではさらなる拡張を加え不等式制約付き最適化 [1,2] に対応しました。以下に簡単な利用方法を示します。
import optuna $ pip install optuna==4.2.0 # GPSamplerはOptunaの依存関係に加えて,scipyとtorchが必要です. $ pip install scipy $ pip install torch --extra-index-url https://download.pytorch.org/whl/cpu
import numpy as np
import optuna
def objective(trial: optuna.Trial) -> float:
x = trial.suggest_float("x", 0.0, 2 * np.pi)
y = trial.suggest_float("y", 0.0, 2 * np.pi)
c = float(np.sin(x) * np.sin(y) + 0.95)
trial.set_user_attr("c", c)
return float(np.sin(x) + y)
def constraints(trial: optuna.trial.FrozenTrial) -> tuple[float]:
return (trial.user_attrs["c"],)
sampler = optuna.samplers.GPSampler(constraints_func=constraints)
study = optuna.create_study(sampler=sampler)
study.optimize(objective, n_trials=50)
制約付きGPSamplerとOptuna標準の制約付きSampler (TPESampler)の最適化性能を比較しました。結果を図3に示します。この問題は低予算かつ探索空間が数値パラメータのみであるため、GPSamplerが高性能を残しています。実施可能なTrial回数が小さい場合に制約付きGPSamplerをぜひご利用してみてください!
![図3. 制約付きGPSamplerとOptuna標準の制約付きSampler (TPESampler) の比較。問題としては J. Gardner et al. [1] の Simulation 2を利用し、各Samplerは10個の乱数で実験しました。横軸はTrial数で縦軸は制約充足した目的関数値を示しています。](https://tech.preferred.jp/wp-content/uploads/2025/01/image2-3.png)
図3. 制約付きGPSamplerとOptuna標準の制約付きSampler (TPESampler) の比較。問題としては J. Gardner et al. [1] の Simulation 2を利用し、各Samplerは10個の乱数で実験しました。横軸はTrial数で縦軸は制約充足した目的関数値を示しています。
[2] M. Gelbart, J. Snoek, and R. Adams. Bayesian optimization with unknown constraints. arXiv:1403.5607, 2014.
c-TPE: TPEの制約付き最適化手法サポート
Optunaの標準SamplerであるTPESamplerはv3.0.0以降で制約付き最適化をサポートしています。一方で、この制約付き最適化アルゴリズムの設計や他手法との性能比較等は公に精査されてきていません。今回原著者 (@nabenabe0928) によってOptunaHubに導入されたc-TPE [1] は人工知能分野の主要な会議であるIJCAIに採択された論文の手法であり、設計及び他手法との性能比較が査読を通して精査された手法となります。以下に使い方を記します。
$ pip install optunahub
import numpy as np
import optuna
import optunahub
def objective(trial: optuna.Trial) -> float:
x = trial.suggest_float("x", 0.0, 2 * np.pi)
y = trial.suggest_float("y", 0.0, 2 * np.pi)
c = float(np.sin(x) * np.sin(y) + 0.95)
trial.set_user_attr("c", c)
return float(np.sin(x) + y)
def constraints(trial: optuna.trial.FrozenTrial) -> tuple[float]:
return (trial.user_attrs["c"],)
sampler = optunahub.load_module("samplers/ctpe").cTPESampler(
constraints_func=constraints
)
study = optuna.create_study(sampler=sampler)
study.optimize(objective, n_trials=50)
表3に示す通り、54種類の制約付き最適化問題で比較実験をしたところ、cTPESamplerはTPESamplerよりも大幅に多くの問題でより良い性能(目的関数値)を示しました。また、cTPESamplerの利点はGPSamplerよりも大幅に少ない時間で各Trialの提案が可能なところです。従って、高性能かつ高速なSamplerを利用されたい場合はぜひcTPESamplerをご利用ください。
表3. Optuna標準の制約付TPESamplerとcTPESamplerの比較。bbob-constrainedにある54種類の5次元の制約付き最適化問題を100 Trialsで解いたときの性能比較を行いました。各行の値はN Trialsまで最適化を実施した際に得られたbest_trialの目的関数値が比較手法よりも良かった問題設定の数を示します。尚各問題における性能比較は異なる10個のStudyで得られたbest_trialの目的関数値の中央値比較によって行いました。例えば、100 Trialsまで評価したときにcTPESamplerは46の問題でTPESamplerよりも良い結果を得ることができました。いくつかの問題ではTPESamplerとcTPESamplerが引き分けたため、各行の和が54にはならないことに注意してください。
| 25 Trials | 50 Trials | 75 Trials | 100 Trials | |
| cTPESampler | 22 | 35 | 45 | 46 |
| TPESampler | 2 | 3 | 5 | 6 |
[1] S. Watanabe and F. Hutter. c-TPE: Tree-Structured Parzen Estimator with Inequality Constraints for Expensive Hyperparameter Optimization. International Joint Conference on Artificial Intelligence (IJCAI), 2023.
今後の開発計画について
Optuna 4.2では、機能共有プラットフォームOptunaHubを活用して最新のアルゴリズムを数多く導入するとともに、gRPCストレージプロキシといった大規模分散最適化を必要とするユーザーに向けた重要な機能開発を行いました。
今後も継続して新機能追加や改善を進めながらも、しばらく先にはなりますが次のメジャーリリースであるv5に向けた準備や検討も始めていきたいと思います。Optunaでは、ユーザーの皆様からのフィードバックや機能追加要望が非常に大切だと考えています。何か要望やv5にむけたアイディアがある方は、下記のGitHub Discussionにて我々にフィードバックをいただければ幸いです。
Share Your Feedback and Suggestions for Optuna 5.0! · optuna/optuna · Discussion #5930
貢献者一覧
v4.2のリリースは多くのコントリビュータの力無しには実現しませんでした。以下は、v4.2の開発に関わった開発者の方々の一覧です。
@HideakiImamura, @JLX0, @KannanShilen, @SimonPop, @boringbyte, @c-bata, @fusawa-yugo, @gen740, @himkt, @iamarunbrahma, @kAIto47802, @ktns, @mist714, @nabenabe0928, @not522, @nzw0301, @porink0424, @sawa3030, @sulan, @unKnownNG, @willdavidson05, @y0z
開発者の方々、ユーザの皆様、全てのOptunaに関わってくださる人に感謝を。これからもOptunaをよろしくお願いいたします。