Blog
本記事は、2023年夏季インターンシッププログラムで勤務された藤井一喜さんによる寄稿です。
はじめに
PFN2023 夏季インターンに参加した藤井一喜です。普段は東京工業大学 横田理央研究室にて大規模深層学習における分散並列学習手法について研究しています。
今回のインターンでは、大学の研究に関係するHPC、 NLPではなく物体検出モデルをWeb Applicationとして利用可能にする開発に取り組みました。
以下ではMMDetection を利用した物体検出モデル(Object Detection)をWeb Serviceとしてデプロイを行う際に直面した問題をどのように解決したのかについて紹介します。
アプリケーション概要
まず、今回のインターンにて作成したWeb Applicationの概要についてです。
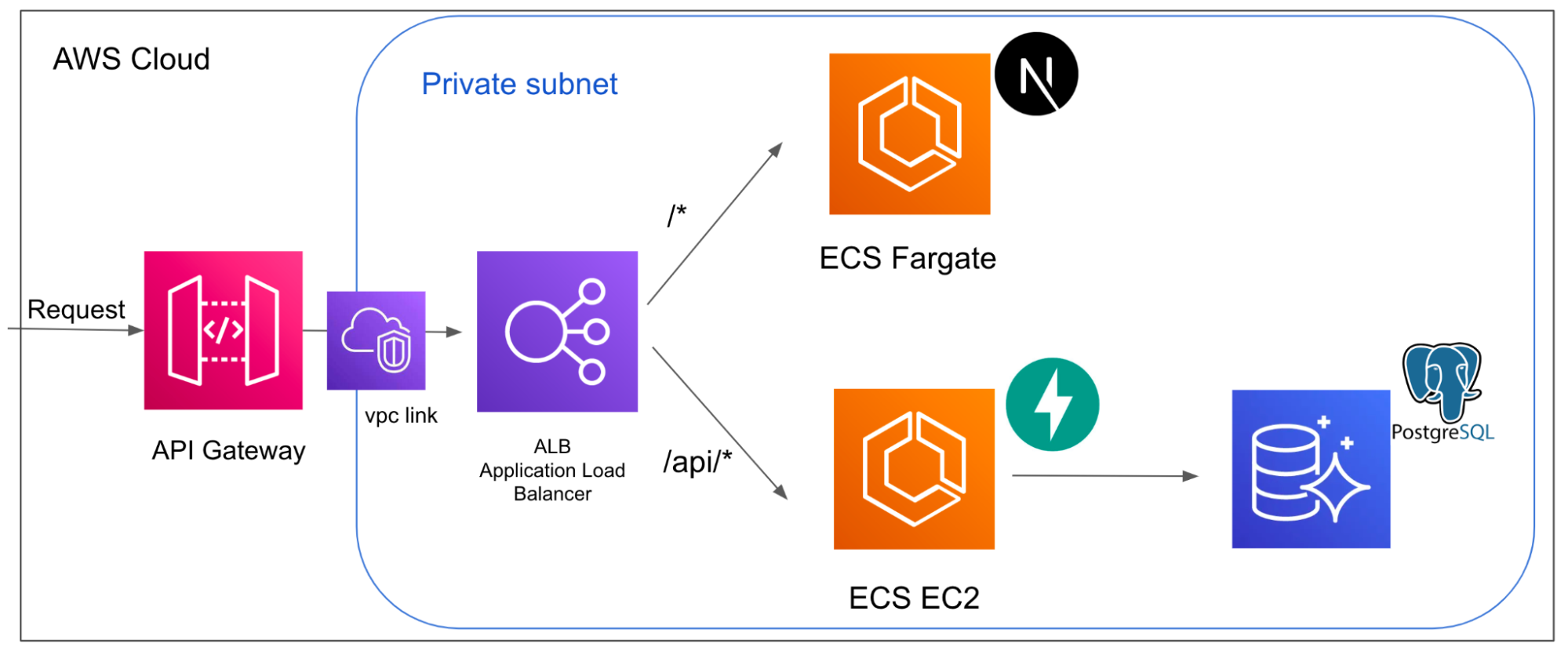
RequestをAPI Gatewayで受けつけ、VPC Linkを利用してALB(Application Load Balancer)にTrafficを流します。その後、Application Load Balancerはリクエストパスに応じてフロントエンド(Next.js)とバックエンド(FastAPI)にトラフィックを分散する形になっています。
フロントエンドではユーザーから画像のuploadを受けつけたり、物体検出結果をダッシュボードに表示する役割を担います。バックエンドではユーザーがuploadした画像を用いて、物体検出モデルの推論を行い、Bounding Boxの座標位置、信頼度、ラベルなどをDB(PostgreSQL)へ保存したり、画像をS3に保存したりする処理を行います。また、フロントエンドからのリクエストに応じてDBやS3からデータを取得し、データを返す役割も担っています。
技術選定
MMDetectionのモデルを動かす箇所はPyTorchで書く必要があるため、バックエンド(API Server)では開発言語としてPythonを選定しました。チーム内で使用されている技術を参考に将来的な統合をみすえて、フロントエンドはNext.js、バックエンドはFastAPIに決定しました。
Application Load Balancer を Private VPC 内に配置する
AWS ECS(Elastic Container Service)上で起動されるフロントエンドのserviceやバックエンドへのserviceに外部から直接アクセスできる状態にあることは、セキュリティ的な観点から望ましくありません。そのため、上図のようにPrivate Subnetにリソースを配置しました。しかし、API Gatewayは外部からアクセスを行う際のエンドポイントとしての役割を担っているため、インターネット上に公開されている必要があります。
(API GatewayにmTLSを設定し、特定のデバイスのみからアクセスできるようにすることを想定していたため、このような構成になっています。インターン期間中にmTLSの設定までは行えませんでした。)
実際にサービスを運用するためには、外部からのリクエストを何らかの方法を用いてPrivate Subnet内に流す必要があります。これを実現するのがVPC linkです。
このとき、Application Load Balancerの設定に注意する必要があります。
まず、Application Load BalancerはPrivate VPC内部にあるので load balancer の属性を internal にする必要があります。internet facing とすると上手く動作しないので注意してください。(以下はTerraoformでALBのリソースを定義する例です)
resource "aws_lb" "application_name_alb" {
name = "${application_name}-alb-internal"
load_balancer_type = "application"
internal = true
ip_address_type = "ipv4"
security_groups = [
aws_security_group.application_name_alb.id,
]
subnets = [
aws_subnet.application_name_subnet_private_1.id,
aws_subnet.application_name_subnet_private_2.id,
]
}
(上記のTerraformはマルチAvailability Zoneにデプロイする場合です)
また、ALBのTarget Groupは以下のように設定します。
resource "aws_lb_target_group" "application_name_lb_target_group" {
name = replace("${application-name}-lb-tg", "_", "-")
vpc_id = aws_vpc.application_name_vpc.id
target_type = "ip"
port = <your container application port>
protocol = "HTTP"
deregistration_delay = 60
health_check { path = "/" }
}
以上のように定義することで、API Gateway → VPC link → ALB → ECS Containerのようにトラフィックを適切に流すことが可能になります。
EC2 Instance を ECS Clusterのリソースとして認識させる
先に述べたように物体検出モデルを用いたWeb Applicationであるため、物体検出モデル(MMDetection)が動作するバックエンドではGPUが必要です。しかしデプロイが比較的簡単なECS FargateではGPUリソースが使用できないので、EC2を起動タイプとするECSをバックエンド(FastAPI)として採用する必要がありました。
開発をしている段階において、EC2 Instanceは起動するがECS Instanceとして認識されない現象に直面しました。以下エラー文
service <service-name> was unable to place a task because no container instance met all of its requirements. Reason: No Container Instances were found in your cluster. For more information, see the Troubleshooting section of the Amazon ECS Developer Guide.
このエラーの原因は、EC2の起動AMI(Amazon Machine Image)として利用していたものがAWS Deep Learning AMIでありecs agentなどECS Instanceとして認識されるために必要なものが欠けていたからでした。CUDA環境などが事前に整っているため、Deep Learning AMIを利用することは機械学習開発においては通常よくあると思いますが、ECS Instanceとしてデプロイする際は注意が必要です。
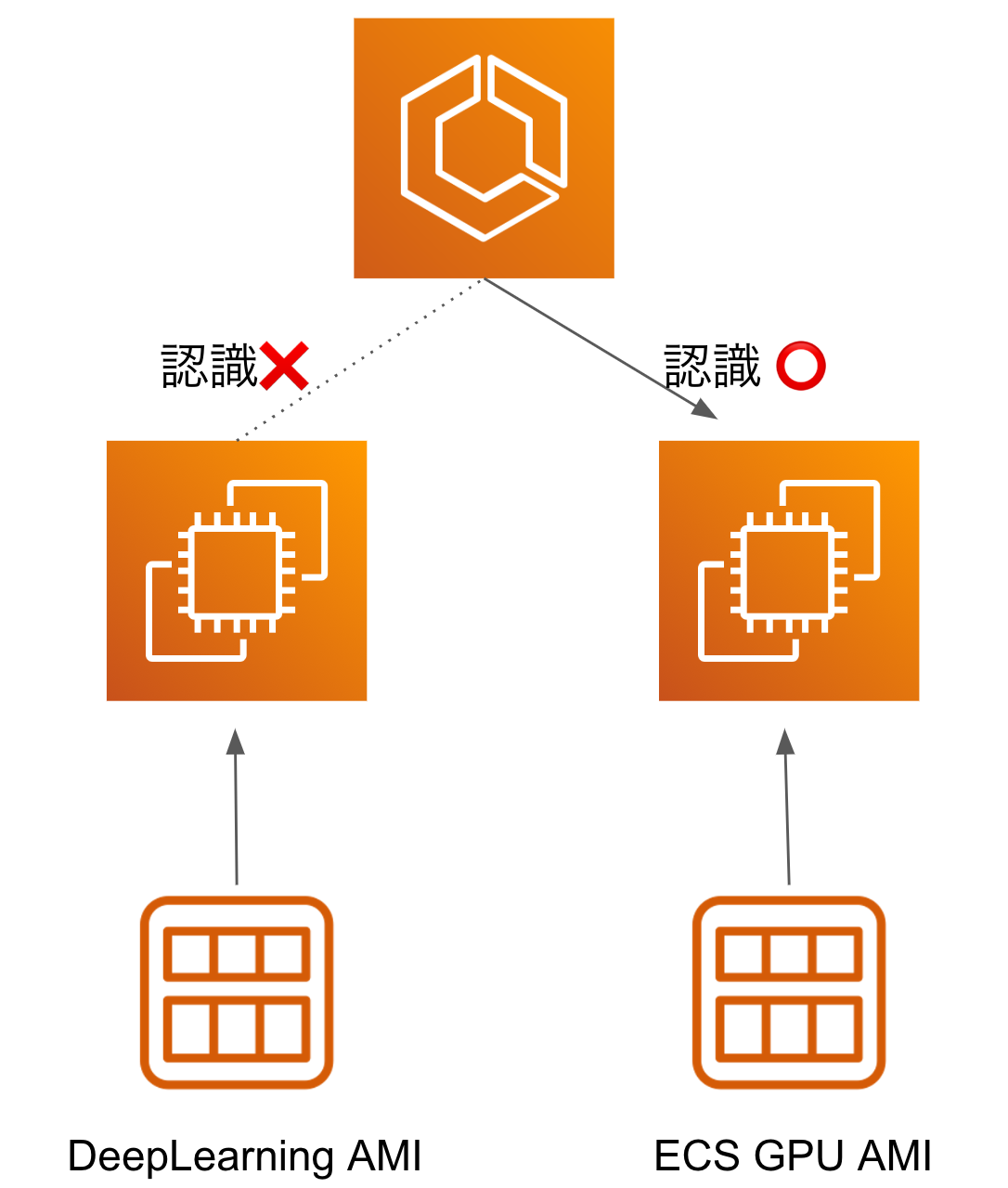
実はecs agentなどECS Instanceとして認識されるようにする処理を自前で行わなくとも amzn2-ami-ecs-gpu のようにECS対応のCUDA環境などが準備されたAMIがAWSに用意されているので、これを利用することで上記の問題を解決できます。今回のインターンでは、このECS GPU AMIを利用することでECS Instanceとして認識させることでこの問題を解決しました。
デバッグTips
AWS ECSをデプロイする際のデバッグを、AWSマネジメントコンソールだけで行うことは非常に困難です。私が今回のインターン中に経験したエラー原因だけでも、「Container ImageがPullできない/ tagの指定ミスでimageがそもそも存在しない」、「CloudWatchのロググループがない」、「ALBのヘルスチェックパスが間違っている」など上記で紹介した以外のエラーに何度も悩まされました。
しかし、tracer を利用すると、この辛さからかなりの部分開放されます。
macOSであれば、homebrewでインストール可能です。実際の使用方法を簡単に示します。
tracer <cluster-name>
このコマンドで現在起動しているECS Serviceと直近でデプロイ失敗したServiceを見ることができます。
さらに、31c407f50b50418a94c403ae3dd0ae22 のようなservice idを用いて
tracer <cluster-name> <service-id>
とすることで該当するServiceがTaskから作成される様子がcommand line上に表示できます。この機能が非常に見やすく、何度もデバッグの際に助けられました。
まとめ、謝辞
今回のインターンでは、普段の研究とは全く異なるタスクに取り組みました。フロントエンドからインフラまでの開発を一通り行い、その後デプロイを行うところまでをインターン期間という短期間で行うことは、時間的に大変でした。しかしながら、メンターの稲垣さんをはじめ、チームメンバーの方々からの的確なアドバイスや解決法を頂けたことで、どうにか期間中に一連の作業を終えることができました。
また、他のインターン生と自分が大学で研究している内容について議論する機会にも恵まれ、インターン課題以外からも多くの学びや気付きがありました。最後になりますが、このような大変貴重な機会を提供いただいたこと、深く感謝申し上げます。大変お世話になりました。ありがとうございました!