Blog
背景
弊社Preferred Networksにおいては、「MNシリーズ」[1][2] としてプライベート・スーパーコンピューターを整備しており、深層学習を始めとしたデータサイエンスの研究開発に活用しています。一般的には、このような計算機クラスタは「スーパーコンピューター」あるいは「HPCクラスタ」と呼ばれます。
ところで、大規模な計算資源というと、もうひとつ「クラウド」というものが思い浮かびます。スーパーコンピューターを使った数値シミュレーションなら、同じく大量のコンピューターが配備されているクラウドでも実行できそう気がします。しかし実際のところ「スーパーコンピューター」と「クラウド」は、似ているようで大きく違うものです。数値シミュレーションの多くは、そのままクラウドに移植しても期待する性能が得られないことが多かったのです。その要因の一つが「通信性能」の違いです。
大規模な数値シミュレーションでは、計算速度を稼ぎたい、一台の計算機のメモリにデータが収まらない、などの理由で複数台の計算機を協調させて計算を行います。その際には計算機間でのデータの交換が必須です。深層学習におけるAllreduce通信[4]などもその典型例といえるでしょう。スーパーコンピューターにおいては、高速な通信を実現するためにInfiniband(IB)をはじめとした非常に高速なネットワークを用いて計算機間が接続されています。
一方でクラウド環境では、歴史的に「データが保存されたデータベースと、独立した個別リクエストをさばくワーカー群」という構成を主要なターゲットとして発展してきました。いわゆるWebサービスなどはこの典型例です。その場合は、
- リクエストは互いに独立であるため、ワーカー間の通信は少ない
- データベースサーバーへリクエストが集中するため、サーバーのCPU・ディスク性能がボトルネックになりやすく、高いネットワーク性能が要求されることが少ない
といった理由から、高速ネットワークが配備されるケースは多くありませんでした。
Elastic Fabric Adapter
しかし、このような状況は大きく変わりつつあります。高速なネットワークが配備され、高速な数値計算が行えるようなクラウド環境が登場しつつあります。その例の1つが、AWSにおけるElastic Fabric Adapter(EFA)です。
EFAは、100 Gbpsの回線速度を持つ特定のインスタンスタイプで利用可能なMPI/NCCLに特化した低レイテンシな仮想ネットワークアダプタです。
100Gbpsという通信速度のスペックはInifinibandでいうところのEDRと呼ばれる世代に相当します。EDRの次世代であるHDRも登場しつつある今、速度という意味では目新しいものではありません。しかし、AWSにおけるIBに匹敵する高速ネットワークの登場には大きなインパクトがあると考えます。IBはHPC向けであるため高速であることが至上命題となっており、クラウド環境で採用するためには、仮想化・モニタリング機能・柔軟性などの面から制約が大きいという事情があります。AWSという巨大で柔軟性の高いクラウドプラットフォームでの利用のためにEFAというインターコネクトが独自開発されたという経緯があるだろうと私は予想しているからです(私見です)。
さて、ここからがやっと本題ですが、この度、このEFAを試す機会がありましたので、その結果をご報告したいと思います。
なぜPFNがEFAの評価を行うのか?
この記事をお読みの方々の中には、「なぜ自社プライベートスーパーコンピューターを保有しているPFNがAWSの評価を行うのか?」と疑問をお持ちの方もいらしゃることと思います。その理由はいくつかありますが、
- 自社利用だけではなく、Chainer/ChainerMNを利用していただいている方々が、EFA環境でも問題なく、より高速な学習を行えるように検証すること
- エンジニアとして最先端の環境に触れてみたかったこと
- 自社クラスタを保持しているとはいえ、社内の研究開発がどんどん活発になる中、論文締め切り前などのピーク期には計算リソースが不足する事態も考えられるので、長期的にそれに備える予備評価として
があります。
EFAの利用方法と実験設定
EFAを利用するためには、AWSにおいて p3dn.24xlarge インスタンスを利用します。APIとしてはlibfabricが採用されており、これを利用できるアプリケーション・ライブラリであればEFAの恩恵を受けることができます。現実的には、MPIもしくはNCCL[13]を使うことになると思います。それ以外の細かい利用方法については公式ドキュメント[6][7]に譲り、割愛させていただきます。注意点としては、
- libfabricとCUDAを利用できるようにMPIを自分でビルドすること。公式で用意されているビルド済みMPIはCUDA-awareではありません。
- libfabricを利用できるように、libfabric用アダプター[8] を利用してNCCLも自分でビルドすること。
- Cluster Placement Groupをきちんと指定すること(こうしないと性能が出ません)
今回は、MPIとNCCLのそれぞれについて測定を行いました。バンド幅とレイテンシの測定には、オハイオ大学で開発されているOSU Microbenchmarkを用い、Open MPI 3.1.3上で測定しました。NCCLの測定では、ChainerMNを用いたImageNet学習をモデル化したベンチマークを用いました。バンド幅とレイテンシの計測では2インスタンス、comm_benchベンチマークでは8インスタンスを利用しました。いずれも、US West (Oregon) us-west-2 のリージョンにて測定しました。
実験
測定(1)バンド幅評価
まず、弊社の初代スーパーコンピューターであるMN-1a(IB−FDR搭載)とバンド幅についての性能を比較してみました。
先述の通りEFAはEDR相当のバンド幅を持っていますが、ここでは測定の都合上、FDR(54Gbps)との比較としました。なので、理論性能値に対しての比率の比較となっています。5回測定の平均値となっています。
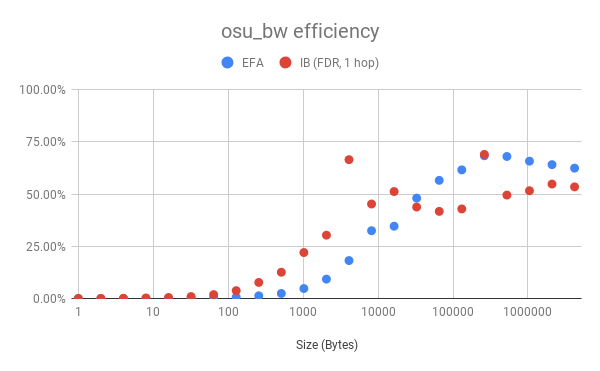
Fig.1 osu_bwによるバンド幅評価
接続トポロジについてですが、IB(弊社MN-1aにおけるInfininband FDR環境)は、単独のスイッチにぶら下がった二台のノードを使っています。それに対し、EFAについては具体的なトポロジは公開されていません。ですので、1つのスイッチを介した接続(1 hop)かもしれないし、複数のスイッチを介して接続されているかもしれません。
全体的な傾向としては、送信バッファが10KB付近までは、最大通信速度に対する割合はIBのほうが良好ですが、それを超えるとEFAのほうが良好であるという傾向が見られました。なお、IBの方はデータサイズによって効率が激しく上下する様子が観察されますが、複数回の計測について安定した結果が得られていましたので、偶発的なスパイクではなく、何らかの理由があるものと考えています。
測定(2)レイテンシ評価
性能上、バンド幅と並んで重要なのがレイテンシです。特に、小さいメッセージを多数送受信するような場合はレイテンシが支配的になります。なお、分散深層学習におけるAllreduce通信においても、小さく分割したデータをバケツリレー的に送信し合うので、レイテンシが重要となるケースです。
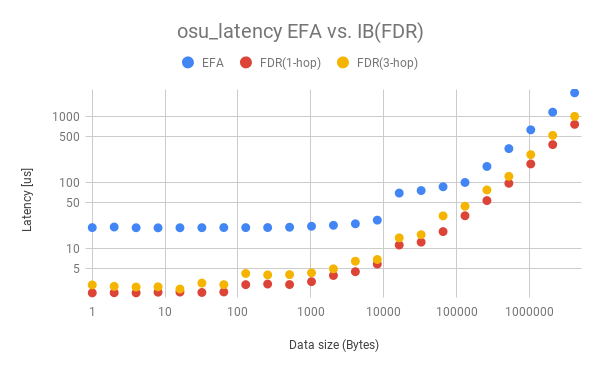
Fig.2 osu_latencyによるレイテンシ評価
本実験では通信しあう二台の計算機の間の距離(ホップ数)が重要ですので、IBについては2パターンの計測を行いました。スイッチを1台経由するパターン(Fig.3)、3台経由するパターン(Fig.4)です。また、前述のように、AWS上のEFAに関しては物理トポロジは不明です。
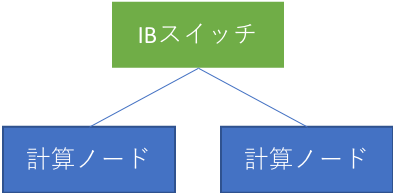
Fig.3 スイッチを1台経由するパターン
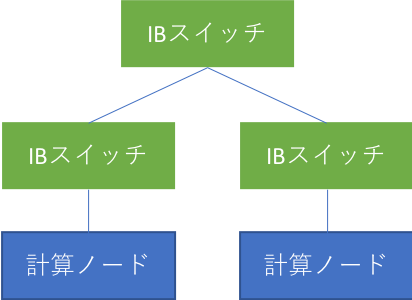
Fig.4 スイッチを3台経由するパターン
レイテンシ性能は、IBのほうが大幅に高速という結果になりました。データサイズが大きく性能が安定した領域では約6倍程度の差があり、また通信サイズが小さい時では最大20倍程度の差となります。これについては、AWSがクラウド環境として仮想化などを通じたサービスの利便性を提供していることを考えると、技術的なトレードオフの結果として仕方ないことだと考えます。また、レイテンシは、その時々で確保されたインスタンスの物理配置ににも大きく依存すると考えられますのでご注意ください。
comm_benchベンチマーク
最後に、実アプリケーションに近いベンチマークとして、ImageNet on ResNet50 の学習を模した comm_bench[9] を、通信ライブラリNCCLを用いて計測しました。ResNet50モデルに相当する約105MBの通信バッファを、FP16を用いてAllreduceする(よって通信バッファのサイズは約50MB)ベンチマークです。経験上、このベンチマークの性能は、素直にImageNet学習へ反映されます。
いままでの2つの実験と違い、今回はIBの測定環境が変わっています。弊社MN-1bを用いているので、インターコネクトはIB EDRであり、スペック上の通信速度はIB/EFAともに100Gbpsで同等です。測定に際しては、10イテレーション実行して平均を取っています
NCCLを用いる際には最適化のためのパラメータ調整が必要とされるケースがあります。特に重要なのは、最近のNCCLにはAllreduceの通信アルゴリズムそのものを切り替える機能[10]です。これについては考察の章で述べたいと思います。今回の測定では、パラメーターチューニングの点からはEFAに不利な設定になっていると思われます。
また、IB側とEFA側ではGPU数が異なっています。これはIB側については別件での測定結果を流用しているためです。IBの測定では512GPU、EFAの測定では64GPUと、IB側のGPU数が大幅に多くなっていますのでApple-to-appleの比較とはなってないことに注意してください。この点では、IB側にやや不利な設定となっています。しかし、このIBの実験はMN-1bクラスタを全システム専有して計測したもののため、他のアプリケーションやジョブの通信から受ける影響はありません。この点では逆にIB側有利といえます。
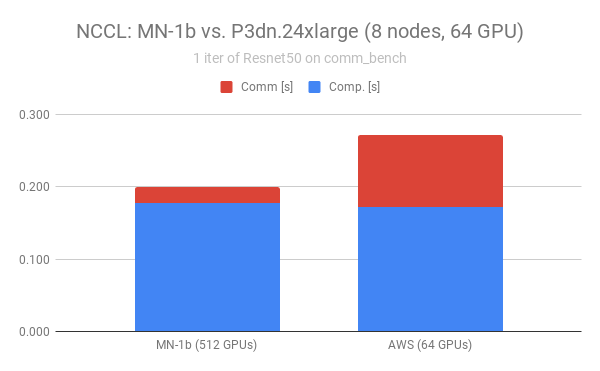
Fig.5 comm_benchによる通信速度評価
さて、結果を見てみましょう(Fig.5)。棒グラフの青い部分が、いわゆるForward/Backwardと呼ばれる計算部分です。データロードは実行してないため無視できます。計算部分については、両者ともに同じモデルのGPU(NVIDIA V100)上で同じ計算をしているため、性能には差がありません。
その上の赤い部分が通信時間です。IBのほうが約6倍の高い性能を出しています。
考察
バンド幅
バンド幅の性能については、データサイズによって優劣が別れる結果となりました。詳細な理由は未検証ですが、MPIの内部実装によるものか、あるいは各種パラメーターによるものかもしれません。IBについては奇妙な性能特性を示しているため、これは弊社のクラスタを用いて今後も検証していきたいと思います。
レイテンシ
レイテンシについては、IBの圧勝となりました。前述しましたが、これは単純にIBのほうが技術として優れているというわけではありません。クラウド環境という利便性と制約、モニタリングや仮想化などの機能を通じた技術的なトレードオフの結果と言えると思います。
よく用いられている伝統的なアプリケーションでレイテンシが問題になるものは、例えば格子を用いた流体解析が挙げられます。しかし、このようなアプリでも(実装次第ですが)レイテンシを隠蔽する方法が知られているので(計算と通信のオーバーラップなど)、回避は可能だと思われます。
comm_bench
今回の計測では、IBを用いたNCCLのほうが大幅に高性能という結果が出ました。しかし、これについては留保があります。通常のAllreduce通信では、Ring Allreduceというアルゴリズムが用いられますが、これは小さいデータ領域を繰り返しバケツリレーするもので、レイテンシの影響を大きく受けます(Ring-Allreduceについては[4]の説明を参照してください)。
一方、現在のNCCLには、レイテンシが大きい環境において有利なTreeアルゴリズムが実装されています。本記事の測定時点ではベータ扱いであった点および時間的な制約から計測対象としませんでしたが、パラメーターを調整しTreeアルゴリズムを採用することによりIBとの性能差を大きく縮めることができる可能性があります。
なお、実際にEFA上でTreeアルゴリズムを用いてNCCLの性能測定をされた方がいます。Yaroslav Bulatov氏は、AWS上でのEthernetとEFAの性能差について詳細な計測を行っています[11][12]。氏の測定結果を詳細に調べると、EFA上のNCCLでも調整次第でIBと同等の速度を出せる可能性が示唆されています。これについては今後の調査課題としたいと思います。
まとめ
本記事は、AWS上で利用可能となっているEFAという新しいインターコネクトについて、PFNが保有するIBを用いた計算環境との速度比較を行ってみました。本記事内での計測については一部調整不足が残りましたが、ChainerMNとNCCLを用いてHPC環境と遜色ない速度で深層学習を行うことができる可能性が示唆されました。
また、それ以外のHPCアプリケーションでもHPCクラスタと匹敵する性能を出せる可能性があると思いました。IBと遜色ないバンド幅を活用し、レイテンシを隠蔽する工夫を行うことで、大規模な計算を高速に行うことができると思います。
また、EFAの登場を始めとするAWS上でのHPCアプリケーションの拡大は、従来では別物と考えられてきた「HPC」と「クラウド」が、徐々に近づき合流しつつあることを示していると思います。我々PFNが主なターゲットとしている深層学習は、アプリケーションとしてはHPC的な側面を持つ一方で、大規模なデータを保有するクラウド事業者によって研究開発がリードされてきた歴史があり、クラウドでの学習・推論が広く行われているという点でクラウド的な側面を強く持ちます。深層学習という1つのムーブメントをきっかけとして、クラウドとHPCが技術的に合流しつつあるというところが、個人的に極めて感慨深いところです。
謝辞
本記事の実験・執筆にあたって、AWS Japanの方々に多大な技術支援をいただきました。深く御礼申し上げます。
参考文献
[1] https://preferred.jp/ja/news/pr20180328/
[2] https://preferred.jp/ja/news/pr20171114/
[3] https://research.preferred.jp/2019/06/mn-2-is-up/
[4] https://research.preferred.jp/2018/07/prototype-allreduce-library/
[5] https://aws.amazon.com/jp/blogs/news/now-available-elastic-fabric-adapter-efa-for-tightly-coupled-hpc-workloads/
[6] https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/efa-start.html
[7] https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/efa-start-nccl.html
[8] https://github.com/aws/aws-ofi-nccl
[9] https://github.com/chainer/comm_bench
[10] https://docs.nvidia.com/deeplearning/sdk/nccl-developer-guide/docs/env.html#nccl-tree-threshold
[11] https://github.com/NVIDIA/nccl/issues/235
[12] https://docs.google.com/document/d/1C0iiKGI2lm-c7VaVZimlgrpBH1C8Oo2R_muxZJvjkrM/edit#heading=h.qlqwgp3iim4q
[13] https://developer.nvidia.com/nccl
Area
