Blog
本記事は、PFN2025 夏季インターンシッププログラムで勤務された竜 鶴吉さんによる寄稿です。
はじめに
PFN2025 夏季インターンシップに参加していた、早稲田大学修士1年の竜 鶴吉と申します。汎用原子シミュレータMatlantisのサービス開発・運用を行うチームにおいて、Prometheusによって収集されるメトリクスの時系列データを長期的に保存する基盤を自前で構築しました。本ブログでは、そのために利用した技術であるGrafana Mimirについて、導入の背景、主要なアーキテクチャ、そして構築時に行った設定を紹介します。
なお、ここからはメトリクスの時系列データを単に、「メトリクス」と呼ぶことにし、Grafana Mimirは「Mimir」と呼ぶことにします。
背景
Matlantisでは、メトリクスを長期的に保存する基盤としてAMP(Amazon Managed Prometheus)を使用しています。AMPは、Prometheusが収集したメトリクスを、スケーラビリティと可用性を担保しつつ長期的に保存することができます。しかし、メトリクス量が増えるにつれてAMPにかかるコストが増えてしまっていたという課題がありました。そこで、コストを削減するためにメトリクスの長期保存基盤を自前で運用するということが検討されました。Mimirは、AMPの内部で使用されているCNCFプロジェクトであるCortex[1] をforkしてパフォーマンスの改良を加えたOSSであり[2] 、Prometheusメトリクスに対して高いスケーラビリティと可用性を備えた長期保存基盤を提供します。そのため、コスト削減を目的としてAMPを代替する技術としてまずはMimirが候補として上がりました。また、実際に試算を行ったところ、AMPのコストを半分削減できるという見込みを立てることができたため、Mimirについて技術検証を行い、Matlantisの環境に導入するというテーマでインターンを行いました。
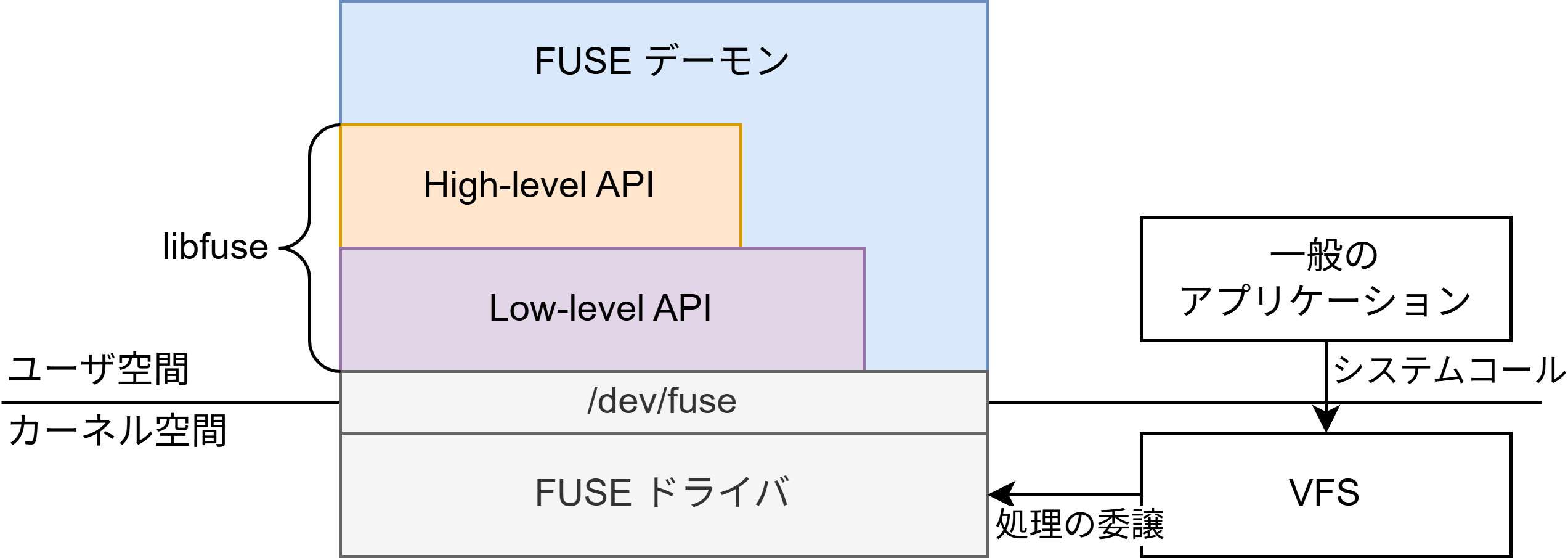
Grafana Mimirのアーキテクチャ
各コンポーネントについて
Mimirはマイクロサービスアーキテクチャを採用しており、各コンポーネントは独立して動作し、それぞれについて水平方向にスケールアウトすることができます。また、コンポーネントの多くはステートレスであるため、スケールが容易です。ここでは、Mimirを構成するコンポーネントについて紹介したいと思います。
Prometheus serverからメトリクスが書き込まれる際の流れは以下のようになります。
- Distributor
- Prometheus serverから時系列データを受け取り、主にRate-limitingとValidationを行い、Ingesterに送信します。
- Ingester
- Distributorから受け取った時系列データをメモリに溜め込みながら、周期的にGCSやS3等のストレージにデータをアップロードします。メモリに書き込んだデータはWALとしてディスクに書き込まれ、Ingesterが何らかの理由でダウンしメモリ上のデータが消失したとしてもディスクから復元することができ、データの耐障害性を高めます。
- Compactor
- ストレージ上の重複データを圧縮しストレージのデータサイズを削減します。
Grafanaからメトリクスを読み込む際には、以下の流れになります。
- Query-frontend
- 数日間または数ヶ月間にわたる大規模なクエリが、後述するQuerierで実行されることによるOOMを防ぎ、クエリ実行を高速化するために長期間のクエリを短期間の複数のクエリに分割します。
- Querier
- Query-frontendから受け取ったPromQLクエリを元に、該当するデータを取得するために直近のデータであればIngesterに、古いデータであればStore-gatewayに接続しメトリクスのデータを取得します。そして、取得したデータを元にクエリの計算を行いその結果を返します。
- Store-gateway
- 実際に、GCSやS3といったストレージからデータの取得を行います。
Mimirのアーキテクチャについて、簡単に示した図は以下のようになります。[3]
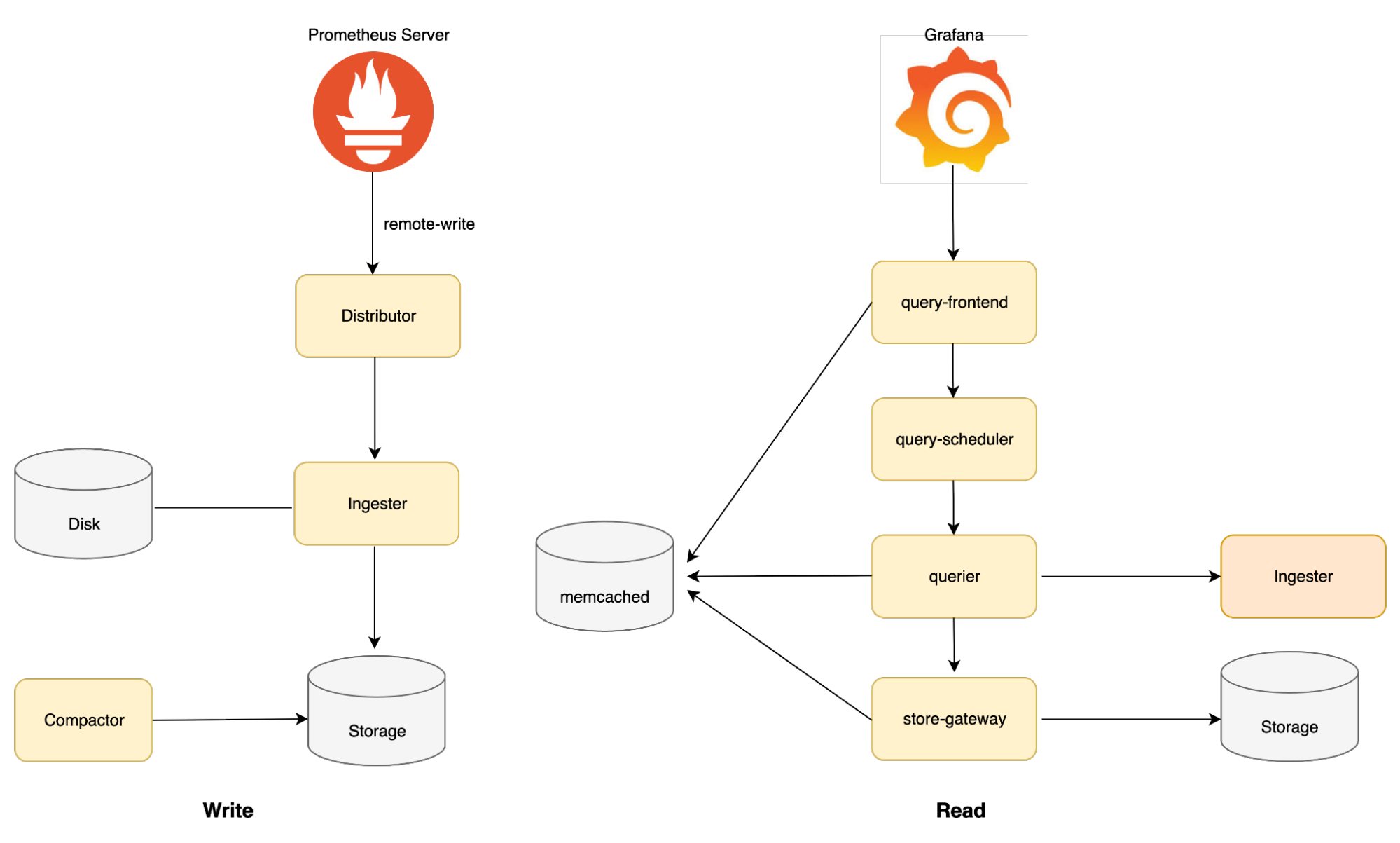
このようにMimirの各コンポーネントは、それぞれが独立した役割を果たすことで、システム全体の機能を実現しています。次に、これらのコンポーネントがどのように連携し、Mimirの高いスケーラビリティや耐障害性を支えているのかを紹介していきます。
コンシステントハッシュによるスケーラビリティ向上
Ingester等のMimirの各コンポーネントは、コンシステントハッシュを用いて、ハッシュリングと呼ばれる仮想的なリングを形成します。これは、どのノードがどのデータを担当するかを効率的に決めるための仕組みです。この方式の最大の利点は、ノードの台数が増減した際の影響を最小限に抑えられる点です。一般的なハッシュ方式による負荷分散では、ノードが1台変わるだけで、ほぼ全てのデータの担当を再計算する必要があり、大規模なデータ移動が発生してしまいますが、コンシステントハッシュでは、影響を受ける対象がリング上で隣接するノードの一部データのみに限定されます。これにより、ノード数が増減する場合についてデータ再配置のコストを最小限に抑えることができます。[4]
Gossipプロトコルによる障害検知
また、ハッシュリング上の各ノードは、ハートビートにより互いのステータスを管理し、Unhealthyなノードを検知します。ハートビートだけでは、ノード数がN台の場合N*(N-1)回ものハートビートのやり取りが必要になるため、計算量はO(N²)となりノード数が増えるに従ってネットワーク全体の通信量が爆発的に増加し、システムのスケーラビリティを著しく低下させます。この問題を避けるために、Gossipプロトコルを使用します。Gossipプロトコルを用いる場合、各ノードは、システム内の他の全てのノードと通信するのではなく、周期的にランダムに選んだ少数のノードとのみ情報を交換します。このプロセスを繰り返すことで、情報は確率的な伝搬を経て最終的にシステム全体に行き渡ります。各ノードが通信する相手は少数の固定数であるため、ノード数Nが増えても通信量が爆発的に増加することはありません。その結果、システム全体のメッセージ計算量は O(N log N) または O(N) となり、ハートビートのみと比較して計算量を十分に抑えることができるため、スケーラビリティが向上します。[5]
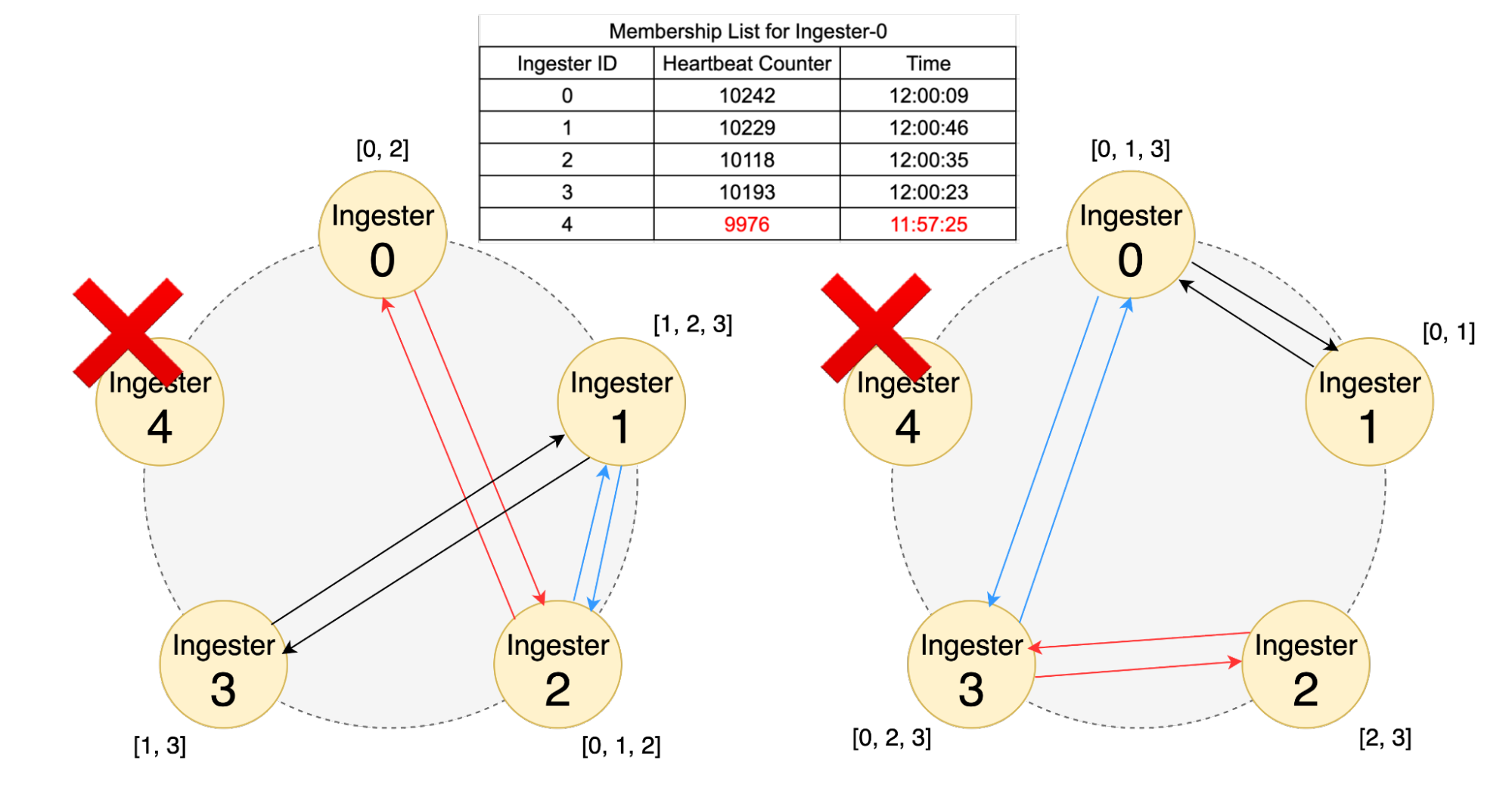
ハートビートとGossipプロトコルにより、リング上でUnhealthyなノードが検知されると、その情報は迅速に共有されます。ハッシュリングの状態はMimirの各コンポーネントから参照できるため、Distributor等の他のコンポーネントはHealthyなIngesterにのみデータを送信するようになり、Unhealthyなノードへのリクエストを回避できます。
Zone Aware Replicationによるデータ分散
Mimirでは、Ingesterのようなコンポーネントの耐障害性を高めるため、データを複数のノードに対し非同期に複製すると同時に、システム全体を複数のAZ(Availability Zone)にまたがって展開するMulti-AZ構成が推奨されています。この時、仮にデータの複製を持つノードが全て同じAZに偏ってしまうと、そのAZで障害が発生した際に該当のデータが完全に利用できなくなってしまいます。この状態を避けるために、MimirではZone aware replicationを設定することが推奨されています。Zone aware replicationは、設定されたReplication Factor(RF)の数だけのZoneに分散してデータを複製する仕組みです。Ingester等のステートフルなコンポーネントについてこの設定をしておくことで、AZ障害が発生した場合でもデータ損失を防ぎ、システムを稼働し続けることができます。
ここで、このデータ分散が具体的にどのような仕組みで行われているかを確認するために、Prometheus serverからDistributorにデータが書き込まれる際の実装を見てみたいと思います。
データを受け取ったDistributorは、Ingesterに対して書き込みを行う際に、各Zoneから適切な数のIngesterインスタンスを選択します。RF=3、 Zone数が3の場合は各Zoneから1台ずつ選択するような形です。
(https://github.com/grafana/mimir/blob/mimir-2.17.1/vendor/github.com/grafana/dskit/ring/ring.go#L544 より)
targetHostsPerZone = max(1, replicationFactor/maxZones)
ここで選択されたインスタンス群の中で、正常なインスタンス数が過半数(floor(RF / 2) + 1)以上である必要があります。先ほどの例だと、「2台以上のIngesterが正常である必要である」ということになります。Mimirは、書き込み処理の前にこの条件が満たされていることを検証します。このため、書き込みを行う際に、十分にZone分散されたIngesterインスタンスがデータを受け取れていることを保証し、耐障害性を強化します。
なお、Zone分散された正常なIngesterインスタンスの数が不足しておりクォーラムを満たさない場合、エラーを意図的に返し、Ingesterへの書き込み操作を失敗させるような実装となっています。
minSuccess := (replicationFactor / 2) + 1
// This is just a shortcut - if there are not minSuccess available instances,
// after filtering out dead ones, don't even bother trying.
if len(instances) < minSuccess {
if zoneAwarenessEnabled {
err = fmt.Errorf("at least %d live replicas required across different availability zones, could only find %d%s", minSuccess, len(instances), unhealthyStr)
}
WAL(Write Ahead Log)による耐障害性の強化
Ingesterが予期せず終了した際に、メモリ上の時系列データを復旧するための仕組みとして、WALを使用しています。Distributorから受信したデータは、Ingester上のメモリに保持されると同時にWALとしてディスクにも書き込まれます 。そのため、もしIngesterに障害が発生しても、WALからメモリ上のデータを復元できるためデータの耐障害性が強化されます。IngesterはStatefulsetとして定義され、永続ディスク(Persistent Volume)にWALを保存できるように設定しておく必要があります。
なお、WALとレプリケーションについては、両方設定することが推奨されています。
WALがあるもののレプリカが1台だけだと、ディスク障害時にデータ損失する可能性があります。そして、レプリカが複数あるもののWALを利用していない場合、全Ingester障害時にストレージに書き込む前にデータ損失をする可能性があります。
Compactorによる重複データの排除
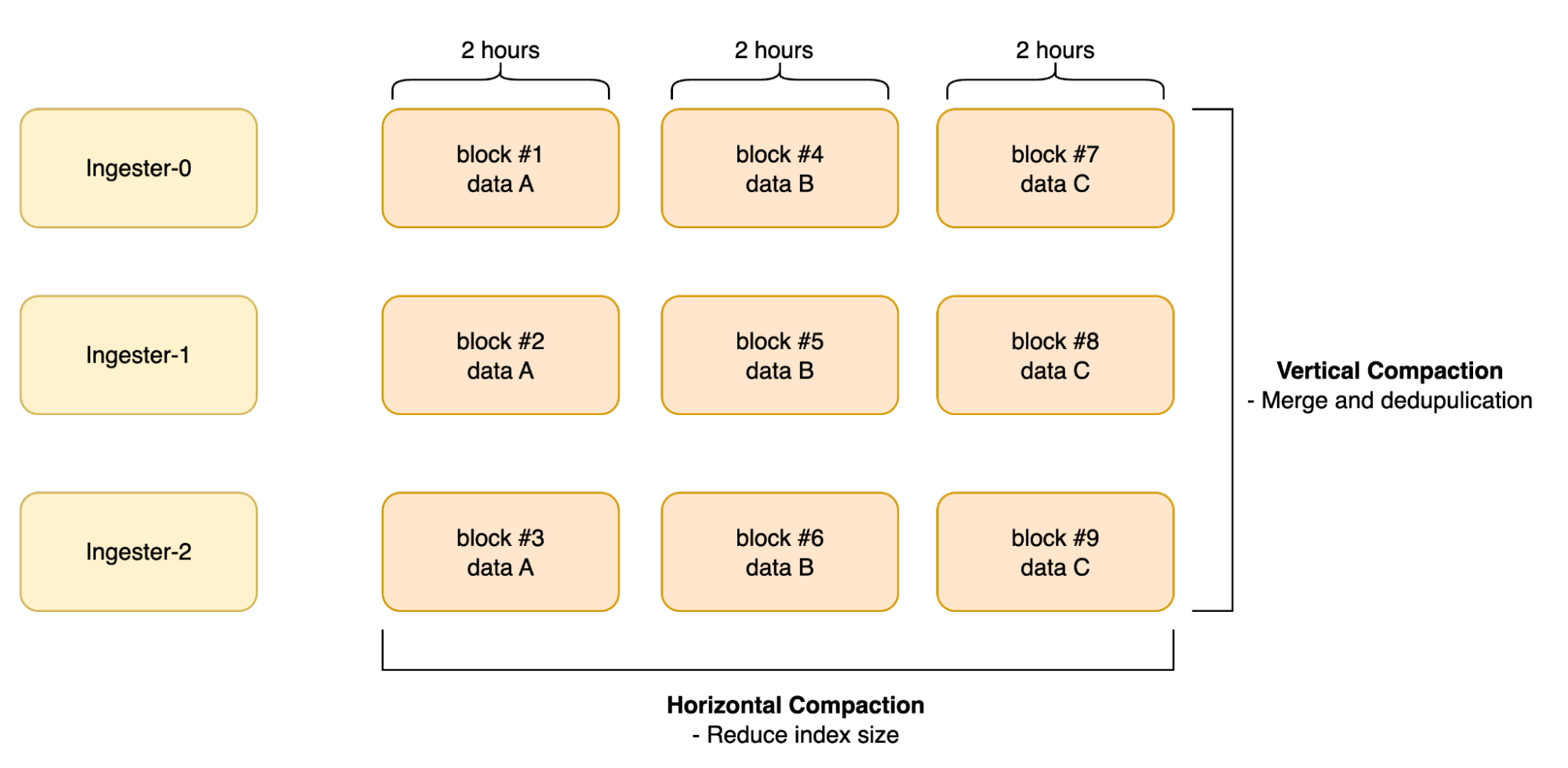
冗長化のため、複数のIngesterから同じデータがストレージに保存されます。GCSやS3も内部で冗長化が行われるため同じデータを重複した状態でストレージに保存しておくことは無駄であると言えます。そこで、Compactorはストレージ上のblockを圧縮する役割を持ちます。具体的には垂直方向と水平方向の、2段階の圧縮プロセスを通じてクエリ性能の向上とストレージ使用量の削減を実現します。
まず、同じ時間範囲(デフォルトでは2時間)に複数のIngesterからアップロードされた全ブロックを、1つのブロックに統合します。この仕組みにより、レプリケーションによって重複して書き込まれたデータが削除されます。そして、垂直方向の圧縮が終わると、隣接する時間範囲を持つ複数のブロックを、さらに大きな1つのブロックにまとめます。このような水平方向の圧縮により、ブロックのインデックスサイズが大幅に削減され、結果としてクエリのパフォーマンスが向上します。
この仕組みを表した図を以下に示します。[6]
Mimir導入時の設定
Helmでのインストール
ここまでで、主にどのようにして耐障害性や可用性を高めているかという観点からMimirのアーキテクチャを説明しました。ここからは、実際にMimirをKubernetes環境に導入する際に行った特徴的な設定について述べたいと思います。
Mimirは、公式のHelm Chartsが用意されているため、EKS上で稼働しているMatlantisの環境に導入する際には、こちらを利用して構築を行いました。そして、デフォルトの設定値を上書きしたい場合などは、mimir.structuredConfigやruntimeConfigで定義することができます。パラメータについてはGrafana Mimir configuration parametersを参考にすることで設定を行うことができます。
可用性を維持するための追加設定
MatlantisではMimirに対して以下の設定を行うことでシステムの可用性を向上しています。
まず、各コンポーネントはMulti-AZ構成としています。ステートフルなコンポーネントについてはZone Aware Replicationを設定し各Zoneに自動で分散して配置し複製されるようにしています。ステートレスなコンポーネントについては、TopologySpreadConstraintsにより明示的にZone分散を行っています。
また、Mimirはマイクロサービス構成を取っていることから、コンポーネントごとにスケールすることができます。Matlantisでは、KEDAを用いることでメトリクス量に応じてコンポーネントごとのHPAを実現しています。
Deduplication設定
Compactorはデータを圧縮することで重複の排除を行いますが、冗長化されたPrometheus serverからDistributorがメトリクスデータを受け取る際においても重複を避ける仕組み(Deduplication)があります。Matlantisでは、可用性を高めるためにPrometheus serverを別々のAZに1台ずつ配置しメトリクスをAMPとMimirにremote-writeしています。(現在MatlantisではAMPとMimirを両方使用していますが、最終的にはMimirに置き換えようとしています。)2台のPrometheus serverが同じデータを送信するので、Distributorは重複したデータを受け取ることになります。そこで、Distributorはリーダー選出を行い、リーダーとなっているPrometheus serverからのデータのみを受け取り、リーダーでない方から受け取ったデータを破棄します。この仕組みを実現するには、DistributorにおいてHA Trackerを有効化し、リーダー選出の状態を保存するためのKVストア(memberlist, etcd, consul)を設定しておく必要があります。[7] なお、MimirのHA Trackerは単純なリーダー選出に特化しているため、Raftといった複雑な分散合意アルゴリズムは使用していません。代わりに、KVストアに対するCAS(Compare-and-Swap)操作によって、複数のDistributorインスタンス間でデータの一貫性を保ちつつ、高速にリーダー選出を行っています。[8]
![]()
リソース割り当て量の調整
Mimirの場合、コンポーネントごとにリソースの消費量が大きく異なる点が特徴的です。例えば、IngesterはCPUに対して多くのメモリを消費します。これは、ネットワークI/Oを効率化するためにDistributorから受け取ったデータを一定期間インメモリ上に溜め込み、一定時間ごとにブロックに圧縮しバッチ処理によりストレージに送信するためです。以下の図がその流れを示しています。[9]
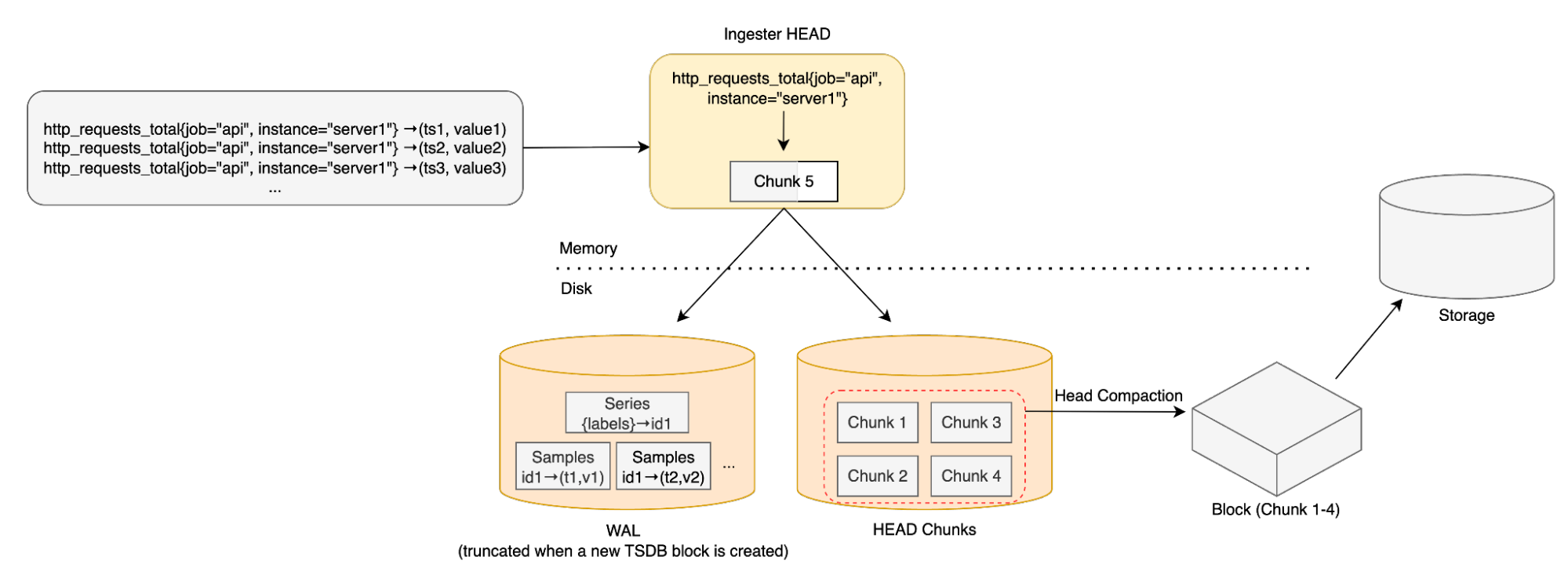
Ingesterへのメモリ割り当て量を少なく見積もった状態で設定してしまうと、OOMが発生しカスケード障害にまで発展してしまう可能性があります。そのため、Ingesterへのメモリの割り当ては多めに見積もった状態で設定を行い、必要に応じてコストパフォーマンスを加味したEC2インスタンスの選定も行うべきと思われます。
インスタンス選定に関する余談ですが、例えば以下の点に注意する必要があります。
Nodeのリソースについては、kubeletなどがリソースを予約するためインスタンスのCapacityに対してApplication PodへのAllocatableの値は少なく、インスタンスのリソースを全て活用できるわけではありません。また、Nodeごとに起動できるPodの最大数に関する制限もあり(参考)、この値が小さいインスタンスだとDaemonsetだけでNodeが占有されてしまい、リソース上の余裕があってもApplication Podが起動できないこともあります。
理論上Podのスケジューリングが行われるはずであるのにも関わらず、上記の内容が原因でPodがスケジューリングされないというケースに遭遇したので、紹介してみました。
まとめ
Grafana Mimirを用いた自前でのメトリクス長期保存基盤について設計及び構築を行いました。その中で、本番環境での運用を見据えて可用性や耐障害性を意識した設計を行ったり、キャッシュの活用によりパフォーマンスの向上を図りました。ここに記載した内容以外でも、例えばデータの保持期間を調整したり、Rulerへのアラートルールの追加など運用上必要な設定について導入を行いました。
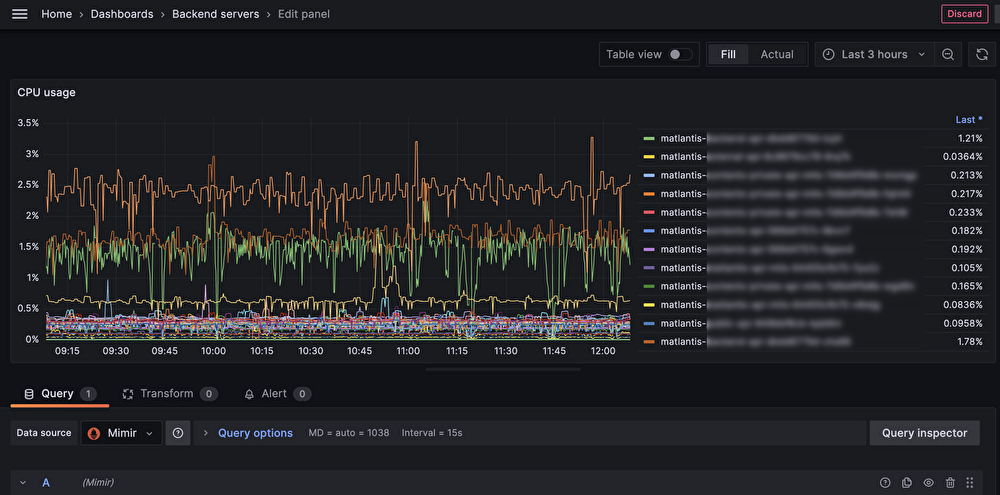
こちらはMatlantisのバックエンドにおけるpodのCPU使用率のメトリクスですが、データソースをMimirに選択している状態でメトリクスを確認することができています。
感想
ただ動くものを構築するだけでなく、実運用でのコーナーケースを想定し信頼性の高いアーキテクチャを構築する重要性を認識した点は、個人的には大きな学びでした。
例えば、AZ障害が発生した場合においてどのように可用性を担保するか、といった問題です。このような問題に対応するためには、システムのアーキテクチャを深く理解したり、Mimirの場合、分散システムに関する知見を持っていることが重要になると考えています。その重要性を実践を通じて学べたことは、個人的には非常に大きな収穫でした。同時に、今後もこのような領域に関する知見をより広げていきたいと感じ刺激になりました。
中間発表や最終発表では、普段コミュニケーションを取っている方以外からも多くのフィードバックを頂いたり、議論を行う機会がありました。それをもとに追加の調査を行ったりすることも多く、大変ありがたかったです。
最後になりますが、日々サポートしてくださったメンターの鈴木さん、坂田さんをはじめとしたMatlantisのチームの皆様、さらには他のインターン中に関わってくださった方たちのおかげで非常に充実した期間を過ごすことができました。本当にありがとうございました!
参考文献
[1] https://aws.amazon.com/jp/prometheus/faqs/#topic-0
[2] https://grafana.com/blog/2022/03/30/announcing-grafana-mimir/
[3] https://grafana.com/docs/mimir/latest/get-started/about-grafana-mimir-architecture/
[4] https://grafana.com/docs/mimir/latest/references/architecture/hash-ring/
[5] https://www.designgurus.io/answers/detail/what-is-a-gossip-protocol-in-distributed-systems-and-how-is-it-used-for-data-or-state-dissemination
[6] https://grafana.com/docs/mimir/latest/references/architecture/components/compactor/
[7] https://grafana.com/docs/mimir/latest/configure/configure-high-availability-deduplication/#how-to-configure-grafana-mimir
[8] https://github.com/grafana/mimir/blob/mimir-2.17.1/pkg/distributor/ha_tracker.go#L654-L711
[9] https://youtu.be/35TAaAESLcc