Blog
※この記事はChainer Blogの抄訳です
Chainer にマルチノードでの分散学習機能を追加するパッケージであるChainerMN に、ネットワークスループットが低いシステム向けの以下の2つの機能をv1.2.0とv1.3.0で追加しました。
- Double bufferingによる通信時間の隠ぺい機能
- 半精度浮動小数点数(FP16)によるAll-Reduce機能
ChainerMNは高速なネットワークを持つスーパーコンピュータやMicrosoft Azureのようなシステムを想定して開発してきたため、高速なネットワークのない環境では高い並列性能を達成するのが難しいという問題がありました。しかし、これらの機能を使うことで、GTC2018で発表したようにAmazon Web Services (AWS)のような一般的なシステムでもChainerMNによって高い並列性能を達成することができるようになりました。
背景
データ並列による分散深層学習においては、学習時間のうちノード毎に計算したgradientの和を計算するAll-Reduceにかかる時間が支配的になります。以前、我々が実施した1024 GPUを利用した大規模な学習では、スーパーコンピュータでも利用される高速なインターコネクトであるInfiniBandと高速なAll-Reduceを実現可能なNVIDIA Collective Communications Library (NCCL)を利用することで解決しました [1]。一方、AWSのような一般的なシステムはInfiniBandのような高速なインターコネクトがないため、通信に時間がかかってしまいます。この結果、ノード数を増やしても学習が速くならない場合がありました。これらを解決するためにChainerMN v1.2.0, v1.3.0でdouble bufferingによる通信時間の隠ぺい機能とFP16によるAll-Reduce機能の2つを追加しました。
Double bufferingによる通信時間の隠ぺい機能
この機能は、計算(foward, backward, optimize)と通信(All-Reduce)をオーバーラップすることで通信にかかる時間を隠ぺいし、全体の計算時間を短縮する機能です。通常のChainerMNの場合、1イテレーションは下図のように forward, backward, All-Reduce, optimize の 4 つのステップからなります。

一方、double bufferingによる通信時間の隠ぺい機能を使うと以下のように計算の部分と 通信の部分をオーバーラップすることができます。

この際、optimizeには一つ前のイテレーションのgradientを利用して行います。これにより、精度に影響がでる可能性が考えられます。しかし、後ほど示す実験の通り、ImageNetの学習の場合、実際はほとんど精度を低下させずに学習を行うことができます。
この機能は以下のようにマルチノード用のoptimizerを作成していた部分で、double_buffering=Trueとするだけで使用できます。
optimizer = chainermn.create_multi_node_optimizer(optimizer, comm, double_buffering=True)
現在、この機能はpure_ncclのcommunicatorにのみ対応しています。
FP16によるAll-Reduce機能
v1.2.0のChainerMNはFP32のAll-Reduceにのみ対応していましたが、v1.3.0ではFP16にも対応しました。これにより、FP16のモデルでもChainerMNを利用して分散学習を実行することができるようになりました。All-ReduceにFP16を用いた場合、FP32のときと比較して、通信量が半分になるため、All-Reduceの大幅な時間短縮を期待できます。
また、計算においてFP32を使っていても、All-ReduceだけはFP16を利用し、All-Reduceにかかる時間を短縮するということも同時にできるようになりました。これは我々が1024 GPUを利用したImageNetの学習で利用したテクニックです[1]。
FP16のモデルの場合は特に変更を加えなくても、FP16のAll-Reduceが利用されます。また、計算とAll-Reduceで違うデータタイプを使用したい場合は、以下のようにcommunicatorを作成する際に、allreduce_grad_dtype='float16'とすることで利用することができます。
comm = chainermn.create_communicator('pure_nccl', allreduce_grad_dtype='float16')
この機能も現在はpure_ncclのcommunicatorにのみ対応しています。
実験結果
2つの新機能により、高い並列性能を得られることを示すために、ImageNet の画像分類データセットを使って性能を測定しました。CNN のモデルとしては ResNet-50 を使いました。実験には、低速なネットワークとしてPFNのスーパーコンピュータであるMN-1の10 Gb Ethernetと、AWSを利用しています。詳しい実験の設定については記事末尾の付録をご覧ください。
10Gb Ethernetによる評価
下記の図では、MN-1を利用し、InfiniBand FDRと10 Gb Ethernetを使った場合、さらに10 Gb Ethernet上で2つの新機能を使った場合の3通りで、GPU 数を増やしたときのスループットを示しています。
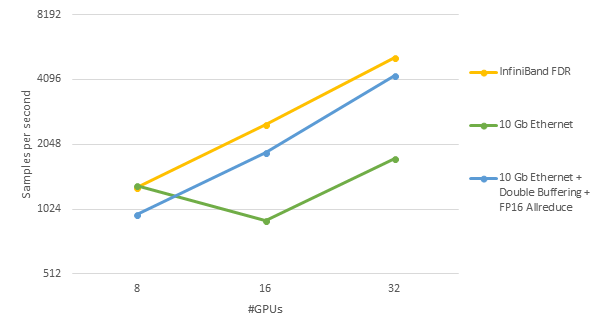
この図に示す通り、10 Gb Ethernetを使った場合、GPU数が増えても性能が上がっていないことがわかります。一方、新機能を使った場合は、線形に性能向上が得られており、理想的な高速化が達成できています。また、下記の表に32GPUを使って90 epochまでの学習を5回実行した際の平均validation accuracyと平均学習時間を示します。
| Validation Accuracy (%) | 学習時間 (hour) | |
|---|---|---|
| InfiniBand FDR | 76.4 | 6.96 |
| 10 Gb Ethernet | 76.4 | 21.3 |
| 10 Gb Ethernet + Double Buffering + FP16 Allreduce |
75.8 | 7.71 |
精度に関しては、2つの新機能を使ってもほとんど影響が出ていないことがわかります。また、学習時間については10 Gb Ethernetと2つの新機能を使った場合には、InfiniBand FDRを使った場合に比べて11%しか計算時間が増加しませんでした。このことから、2つの新機能を使うことで、InfiniBand のような高速なネットワークを利用しなくても、精度を維持したまま高い並列性能を得られることがわかりました。
AWSによる評価
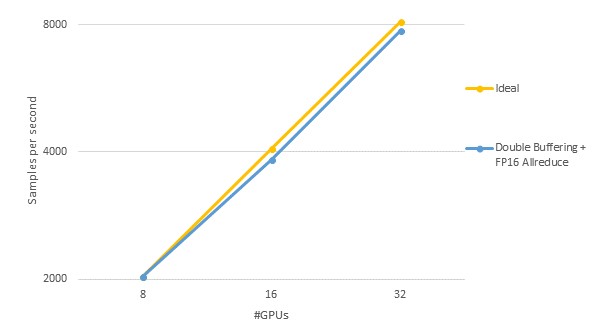
AWSの検証ではp3.16xlargeを利用しました。このインスタンスは最新のGPUであるV100を8個搭載しています。このインスタンスを利用してGPU 数を増やしたときのスループットを以下の図に示します。
どれだけ並列性能がでているかの指標として並列化効率が良く用いられます。今回の実験の場合、基準となるスループットを\(t_0\)、基準から\(n\)倍のGPUを使用したときのスループットを\(t\)とすると、並列化効率\(e\)は以下のように計算できます。
$$e = t/(t_0*n)$$
この並列化効率が1(100%)に近いほど高い並列性能を達成していることを示しています。
この実験においては、8GPUを基準とした32GPUを利用した場合の並列化効率は96%となり、新機能を使うことにより高い並列化性能を達成できることがわかります。
今後の展望
今後、ChainerMNは多くの学習モデルにおいてデータ並列では実現できない多様なモデルの並列化に対応するために、モデル並列をはじめとした機能や、耐障害性を向上するための機能を追加していく予定です。また、我々のチームではChainerMNの開発だけでなく, ChainerとCuPyを含めた高速化、P100を1024機搭載したMN-1やV100を512機搭載した次のクラスタを全台使うような大規模実験に関する研究開発を行っています。このような分野に興味のある方のご応募お待ちしております。
付録
性能測定の詳細について
実験設定
データセット:ImageNet-1k
モデル:ResNet-50 (入力画像サイズ 224×224)
スループット測定時の設定
バッチサイズ:64
学習率:固定
Data augmentation:Goyal et al. [2]と同じ手法を利用
最適化:Momentum SGD (momentum=0.9)
Weight decay: 0.0001
測定回数:400イテレーション
90エポックまで学習させたときの設定
バッチサイズ:30エポックまで各 GPU が 64、その後、128
学習率:5エポックまでGradual warmup、30 エポックのとき0.2 倍、60エポック、80エポックで0.1倍
Data augmentation:Goyal et al. [2]と同じ手法を利用
最適化:Momentum SGD (momentum=0.9)
Weight decay: 0.0001
エポック数:90 エポック
この設定は基本的にGoyal et al. [2]をベースに、Smith et al. [3]のテクニックを利用した設定になっています。
10Gb Ethernetによる検証に使用した実験環境
実験環境
最大4ノード、計 32 GPUs
ノード
GPU: 8 * NVIDIA Tesla P100 GPUs
CPU: 2 * Intel Xeon E5-2667 processors (3.20 GHz, 8 cores)
ネットワーク: InfiniBand FDR
学習データの保存先:ローカルディスク
AWSによる検証に使用した実験環境
実験環境
最大4ノード、計 32 GPUs
ノード(p3.16xlarge)
GPU: 8 * NVIDIA Tesla V100 GPUs
CPU: 64 vCPUs
ネットワーク: 25 Gbps のネットワーク
学習データの保存先:RAM disk
References
[1] Akiba, T., et al. Extremely Large Minibatch SGD: Training ResNet-50 on ImageNet in 15 Minutes. CoRR, abs/1711.04325, 2017.
[2] Goyal, P., et al. Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour. CoRR, abs/1706.02677, 2017.
[3] Smith, S. L., et al. Don’t Decay the Learning Rate, Increase the Batch Size. CoRR, abs/1711.00489, 2017.