Blog
米サンフランシスコで開催された「Deep Learning Summit 2017」にて、PFN は Chainer のマルチノードでの分散学習対応への取り組みについて発表しました。本記事では、その発表について詳しく説明していきます。
分散深層学習の重要性と現状
GPU の性能は継続的に向上していますが、より大きなデータを活用してより精度の高いモデルを実現するために、深層学習で使われるモデルのパラメータ数や計算量も増大しています。そのため、現在でも、Chainer を含む一般的なフレームワークを用いた標準的な学習では 1 週間以上かかってしまうようなユースケースが少なくありません。より大規模なデータを扱ったり、試行錯誤のイテレーションを効率化するために、複数の GPU を連携させ学習を高速化させることは重要な課題です。そこで、我々は Chainer にマルチノードでの分散学習の機能を追加するパッケージ ChainerMN を開発しています。
ChainerMN の実装方針
今回の実装はデータ並列と呼ばれるアプローチを採用しており、その中でも同期型の実装を採用しています。これは、各ワーカーがモデルのコピーを持ち、1 イテレーションのミニバッチを分割し全ワーカーで協力して勾配を計算する、というアプローチです。
実装には MPI を利用しており、ノード外の通信は MPI を通じて行うことにより、InfiniBand のような高性能なネットワークの性能を活用できます。ノード内の GPU 間の通信には NVIDIA 公式の NCCL というライブラリを利用しています。
性能測定の結果
ImageNet の画像分類データセットを使って性能を測定しました。CNN のモデルとしては ResNet-50 を使いました。実験にはさくらインターネットの高火力コンピューティングを利用しています。詳しい実験の設定については記事末尾の付録をご覧ください。
以下の性能測定の結果は、完全に公平とは言えない可能性がある事をご留意下さい。まず、性能測定を行った環境は我々が開発を行った環境でもあるため、測定環境に特に適した実装になっている可能性があります。また、他のフレームワークに関しても、性能を出すためにある程度の試行錯誤をしたものの、我々は十分な経験を持ち合わせていないため、完全に性能を出し切れているとは限りません。第三者による検証を推奨するため、比較に利用したプログラムは他フレームワークのものも含めて公開予定です。
ChainerMN の性能
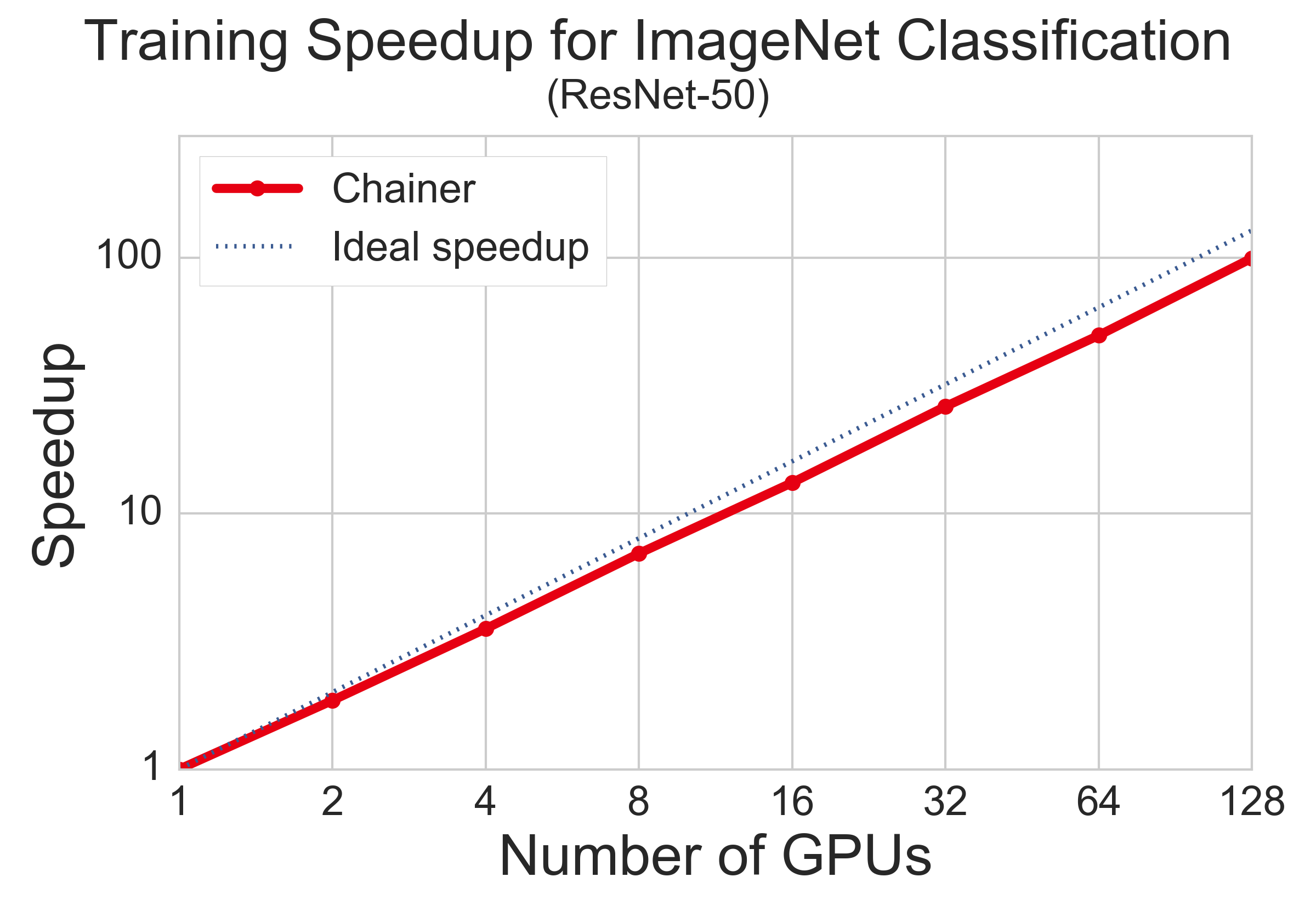
下図は、GPU 数を増やしたときに学習完了にかかる時間がどのように高速化されるかを表した図です。学習完了とは同じエポック数の学習を行うこととしています。4 GPU までが同じノード内で、8 GPU 以上ではノードを跨いでいます。比較的理想的な高速化を達成しており、今回の設定では 128 GPU で 100 倍程度の高速化となりました。
下図は、横軸に実時間、縦軸に validation accuracy を描いた学習曲線です。2 度精度がジャンプするところは、学習率を 0.1 倍しているタイミングであり、ImageNet 系の学習曲線で見られる一般的な現象です。この図から、今回の設定では 128 GPU を使った場合でもちゃんと精度が上がってきていることが確認できます。

他フレームワークとの比較
下図は、128 GPU を用いる同じ設定下で各フレームワークが学習完了に要する時間です。開発チームとしても実は意外な結果だったのですが、ChainerMN が最も高速という結果になりました。この理由については次の実験と併せて考察していきます。

下図は、GPU 数を変えた時の各フレームワークのスループットを描いています。計測のイテレーション数を少なめにしてしまったのでやや不安定ですが、傾向が見て取れます。まず、1GPU の時には ChainerMN よりも MXNet, CNTK のほうが高速です。これは、MXNet, CNTK が C++ で記述されているのに対し、Chainer が Python で記述されているからだと考えられます。次に、4GPU の時を見ると、MXNet が少し出遅れます。この理由の1つとしては、CNTK と ChainerMN が NVIDIA NCCL の提供する高速な GPU 間集団通信を活用しているのに対し、MXNet は自前でノード内の通信を行っている、ということが言えると思います。一方で、ノード間通信では、CNTK よりも MXNet, ChainerMN のほうが良いスケーラビリティを示しています。結果、128 GPU では、ノード内・ノード間の両方で高速な通信を実現した ChainerMN が最も高速です。
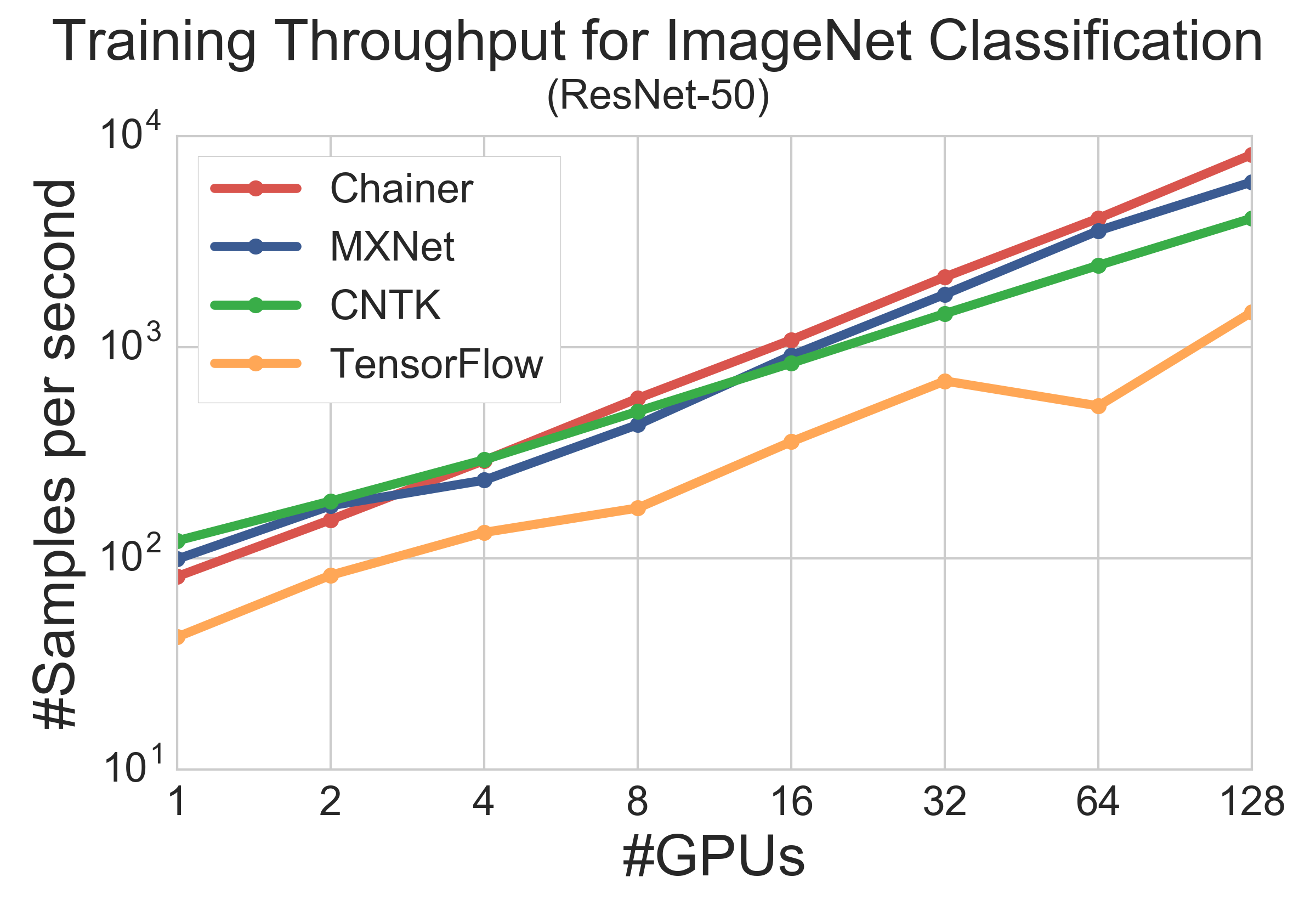
TensorFlow の結果の解釈には注意が必要です。TensorFlow は通常の利用では十分高速なフレームワークです。上図の実験で 1 GPU の時ですら低いパフォーマンスとなってしまっているのは、1 GPU でも分散実行時と同じ設定で実行しているためです。別プロセスとして起動しているパラメータサーバとの gRPC を用いた通信に大きなオーバーヘッドが存在し、1 GPU の時ですらこのような速度になってしまっています。TensorFlow の速度については、他所でのベンチマークでも同様の結果が報告されています [1, 2]。
- [1] “Benchmarking State-of-the-Art Deep Learning Software Tools”, Shaohuai Shi et al., arXiv 2017.
- [2] “Deep Learning Performance with P100 GPUs”, Rengan Xu and Nishanth Dandapanthu. Dell EMC HPC Innovation Lab. October 2016.
分散深層学習の難しさと課題について
分散深層学習の難しさの 1 つとして、スループットの向上が常にそのまま学習効率の向上になるわけではない、という点が挙げられます。例えば、データ並列のアプローチでは、GPU 数を増やすほどバッチサイズが大きくなります。しかし、ある程度以上のバッチサイズでは、バッチサイズを大きくするとモデルの学習に悪い影響があり、得られるモデルの精度が段々下がっていきます。まず、同じエポック数の学習を行う場合、イテレーション数が減ってしまうため、モデルが成熟しないことがあります。加えて、勾配の分散が小さくなることにより、性質の悪い局所解(sharp minima と呼ばれます)に進みやすくなってしまい、結果として得られるモデルの汎化性能が悪くなってしまう、という現象も知られています。
こういったことを加味せずスループットのみを報告するベンチマーク結果には意味が有りません。バッチサイズを上げたり同期頻度を下げたりすることにより、いくらでもスループットのスケーラビリティは上げることができますが、そういった設定では有用なモデルを学習させることはできません。今回も、GPU のメモリにはかなり余裕がある状況ながら、各 GPU の担当バッチサイズを小さめに抑えることで、それなりの精度のモデルを得る事ができる設定にしています。
今後について
ChainerMN は、今月中にも社内での試用を開始し、そこでのフィードバックを反映した上で、数ヶ月以内に OSS で公開予定です。
付録:性能測定の詳細について
実験環境
- 32 ノード、計 128 GPU
- ノード
- GPU: 4 * GeForce GTX TITAN X (Maxwell)
- CPU: 2 * Intel(R) Xeon(R) CPU E5-2623 v3 @ 3.00GHz
- ネットワーク
- InfiniBand FDR 4X
実験設定
- データセット:ImageNet-1k(1,281,158 画像、訓練前に 256×256 にリサイズ)
- モデル:ResNet-50 (入力画像サイズ 224×224)
- 訓練
- バッチサイズ:各 GPU が 32(GPU 数×32 が総バッチサイズ)
- 学習率:30 エポックごとに 0.1 倍
- Data augmentation:random crop, horizontal flip のみ
- 最適化:Momentum SGD (momentum=0.9)
- Weight decay: 0.0001
- 訓練エポック数:100 エポック
この設定は基本的に ResNet 元論文の設定に従っています [3]。ただし、訓練時に color augmentation や scale augmentation を使っていないのと、validation 時にも 10-crop prediction や fully-convolutional prediction を使っていません。この設定で top-1 accuracy は 71〜72% 程度に到達します。これは論文や過去の再現実験と比較すると妥当な精度だと考えています。
- [3] “Deep Residual Learning for Image Recognition”, Kaiming He et al., CVPR 2016.