Blog
エンジニアの清水です。PFNでは、計算アクセラレータとしてGPUを採用するMN-2と自社開発のMN-Coreを採用するMN-3をKubernetesクラスタとして運用しており、その中でCNI Pluginを内製開発して使っています。このブログでは、内製CNI Pluginの話を中心にこれまでPFNのKubernetesクラスタのネットワーク部分、特に、CNI Pluginの構成とその変遷について紹介し、また最後に今後の展望についても触れます。
目次
- なぜCNI Pluginを内製したのか?
- 内製CNI Pluginの特徴
- Kubernetesクラスタのネットワーク構成(第1世代)
- 運用中に見つかった課題
- Kubernetesクラスタのネットワーク構成(第2世代)
- まとめと今後
なぜCNI Pluginを内製したのか?
PFNのクラスタは機械学習向けのクラスタであり、深層学習を高速に実行できることが求められます。深層学習の高速化手法である分散深層学習を効率的に実行するためには、ノード間の通信は高帯域で低遅延である必要があります。高帯域で低遅延な通信を実現するために、PFNではホストに対して複数本の100ギガビットイーサネット(100GbE)のインターフェイスを搭載し、また、イーサネット上でRDMA (Remote Direct Memory Access)を実現するRoCE (RDMA over Converged Ethernet)を採用しています。
Kubernetesクラスタにおいてワークロードが実行されるpod上のネットワーク環境は使用するCNI Pluginによって決まります。ホストに搭載された複数の100GbEのインターフェイスを活用したRDMAをpodから利用するためには、この要件に対応するCNI Pluginを用いる必要があります。一方で、CalicoやFlannelなどのよく使われるCNI Pluginは、RDMAに対応しておらず、また、複数のネットワークインターフェイスにも対応していません。Kubernetes上でRDMAと複数のネットワークインターフェイスに対応するという要求を両方満たすためには、何らかの特殊なCNI Pluginが必要であり、最終的にCNI Pluginを内製することにしました。
内製CNI Pluginの特徴
内製のCNI Pluginの特徴の一つは、ホストにあるネットワークインターフェイスを直接podに割り当てることです。典型的なCNI Pluginの実装では、vethインターフェイスのペアを作成し、片側をpodのnetwork namespaceに所属させ、もう片側をホストのnetwork namespaceに所属させます。
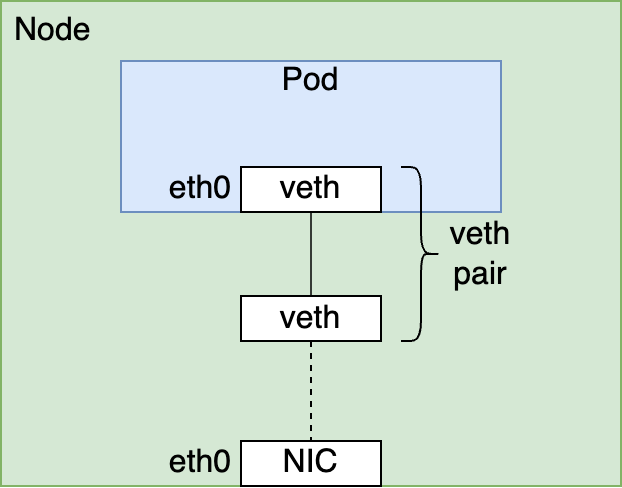
この方法は、ホストに搭載されたネットワークインターフェイスとpodから見えるネットワークインターフェイスの間をvethインターフェイスが仲介する構成になります。そのため、OSの処理の一部をパイパスするRDMAに対応するのが難しい実装形態になっています。
これに対して内製のCNI Pluginではvethインターフェイスを用いずに、ホストにあるネットワークインターフェイスをpodのnetwork namespaceに所属させています。これにより、podはホストにあるネットワークインターフェイスを直接利用できるようになります。実際には、内製CNI Pluginでは、SR-IOV (Single Root I/O Virtualization)の機能で作られる仮想的なネットワークインターフェイスであるVF (Virtual Function)をpodに割り当てます。VFはPF (Physical Function)と呼ばれる物理的なネットワークインターフェイスから作成される仮想的なデバイスで、1つのPFに対して複数のVFが作成できます。1つのPFを複数のVFで共有しているという点ではVFは仮想的なデバイスですが、ホスト上のOSからは一つのPCIデバイスとして認識されるため物理デバイスのように扱えます。このため、VFをpodに対して直接割り当てることでpodからのRDMAが実現出来ます。
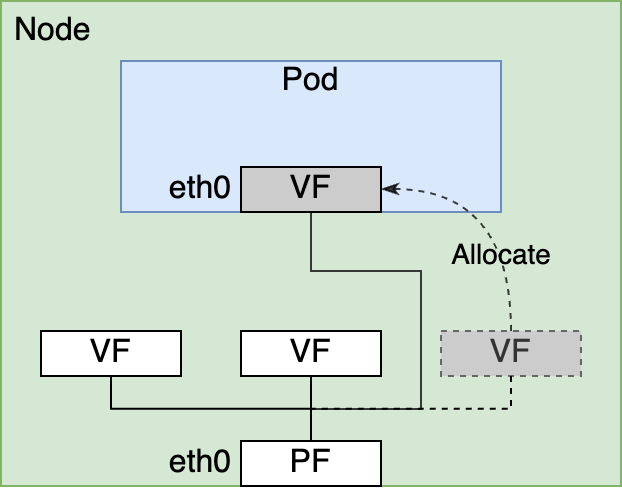
さらに内製CNI Pluginでは、podが利用するGPU数に応じて複数のVFをpodに割り当てます。この複数のVFの割り当ても内製CNI Pluginの実装上の特徴の一つです。Kubernetes自体は1つのpodが複数のネットワークインターフェイスを持つ形態をあまり考慮してなく、1つのpodに対して1つのCNI Pluginの呼び出ししか行いません。そのため、内製CNI Pluginでは1回の呼び出しで複数のVFをpodに割り当て、半ば無理矢理な形で複数インターフェイスへの対応を行っています。Podへの複数のVFの割り当てが行われる条件についてもう少し詳しく説明すると、ノードが搭載するGPU数すべてをpodが利用する場合にノードにあるPFと同じ数だけのVFをpodに割り当てるようにしています。例えば、NVIDIA V100を搭載するGPUノードにはGPUが8個あり、PFが4つあるため、8 GPUを使うpodには4つのVFが割り当てられます。この条件は、「複数ノードを使った分散深層学習を行うときはノード上にある全てのGPUを使って行う」という想定を受けた実装をしています。このようにして内製CNI Pluginでは分散深層学習を行うときには、ホスト上にある複数のネットワークインターフェイスの帯域をpodから活用できるようにしてpodから広帯域な通信を利用できるようにしています。
Kubernetesクラスタのネットワーク構成(第1世代)
2019年から運用を開始したMN-2では、運用当初からこの内製CNI Pluginを使って運用を行っています。まず、MN-2の運用当初のネットワーク構成についてCNI Pluginを中心とした観点から紹介します。ここで、「運用当初の」とわざわざ書いているのはMN-2の運用を開始したときのCNI Pluginの構成と現在運用しているCNI Pluginの構成が異なっているためです。以下では、運用当初の構成のことを第1世代の構成と呼び、2022年10月現在運用をしている構成のことを第2世代の構成と呼んで説明を進めます。
第1世代の構成では内製のCNI PluginのみをCNI Pluginとして用いてpod間のネットワークを作っています。内製CNI Pluginは特徴の説明で触れたようにノード上で利用可能なVFをpodに割り当てます。つまり、第1世代の構成では全てのpodが1つもしくは複数のVFを割り当てられていて、pod間の通信はこのpodに割り当てられたVFを使って行われます。MN-2のNVIDIA V100を搭載するGPUノードを例に取ると、1つのノードに4本の100GbEインターフェイス、つまり、4つのPFがあります。NVIDIA V100搭載のGPUノードでは1 PFにつき16 VFを作成する設定にしていたため、1つのノードには全体で64 VFが起動時に作成されます。PFおよびVFに設定するIPアドレスは共に事前に割り当てが決められており、起動時に設定が行われます。各ノード間を接続する物理ネットワークはLeaf-SpineトポロジのBGPを使ったL3ファブリックになっていて、任意のノードの任意のPFおよびVF間でパケットが疎通します。そのため、podは割り当てられたVFを使うことで、任意のpod間でIP reachableな状態になっています。ちなみに、podに割り当てたVFに対して行うIPアドレスの設定とデフォルトルートの設定は内製CNI Pluginが行う実装になっています。
Podに割り当てられたVFを使うことでpod間でNATを行わずに通信ができ、Kubernetesのネットワークモデルを実現しています。しかし、この内製CNI Pluginを使った構成では実際のKubernetesクラスタの運用においてはまだ問題があります。それは、ServiceのCluster IPを使った通信が行えないことです。Cluster IPが使えない理由は内製CNI Pluginのホスト上のVFを直接podに割り当てるという動作に関係しています。
Cluster IPは通常各ノードで実行されているkube-proxyによって実現されており、kube-proxyがノードにiptablesのルールを設定するというのがよく採用されいてるCluster IP実現の方法です。この時、kube-proxyはホストのnetwork namespaceに対してiptablesのルールの設定を行います。vethインターフェイスを用いた典型的なCNI Pluginの実装では、podからのパケットはvethインターフェイスを経由してホストのnetwork namespaceを通過します。このため、kube-proxyが設定したホストのnetwork namespaceに対するiptablesのルールが適用され、Cluster IPでの通信が行えます。
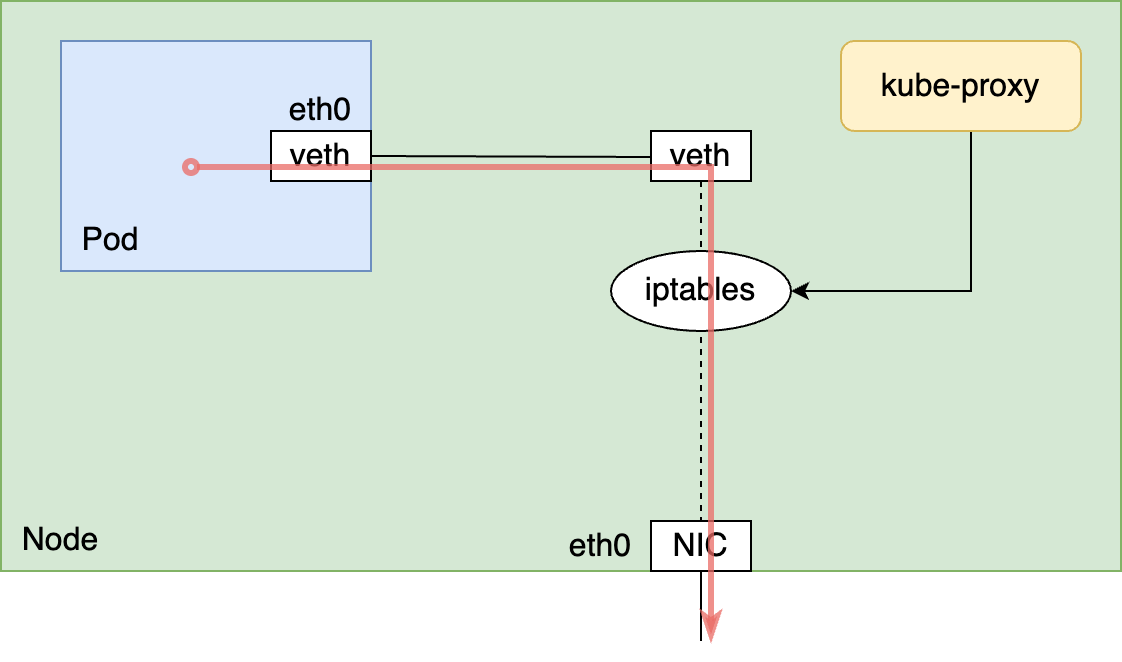
しかし、内製CNI Pluginを使った場合、podが通信に使うVFはホストのnetwork namespaceからpodのnetwork namespaceに移されているため、ホストのnetwork namespaceはpod間の通信に関与しません。そのため、kube-proxyが設定するiptablesのルールは適用されず、このままではCluster IPを使った通信が行えません。
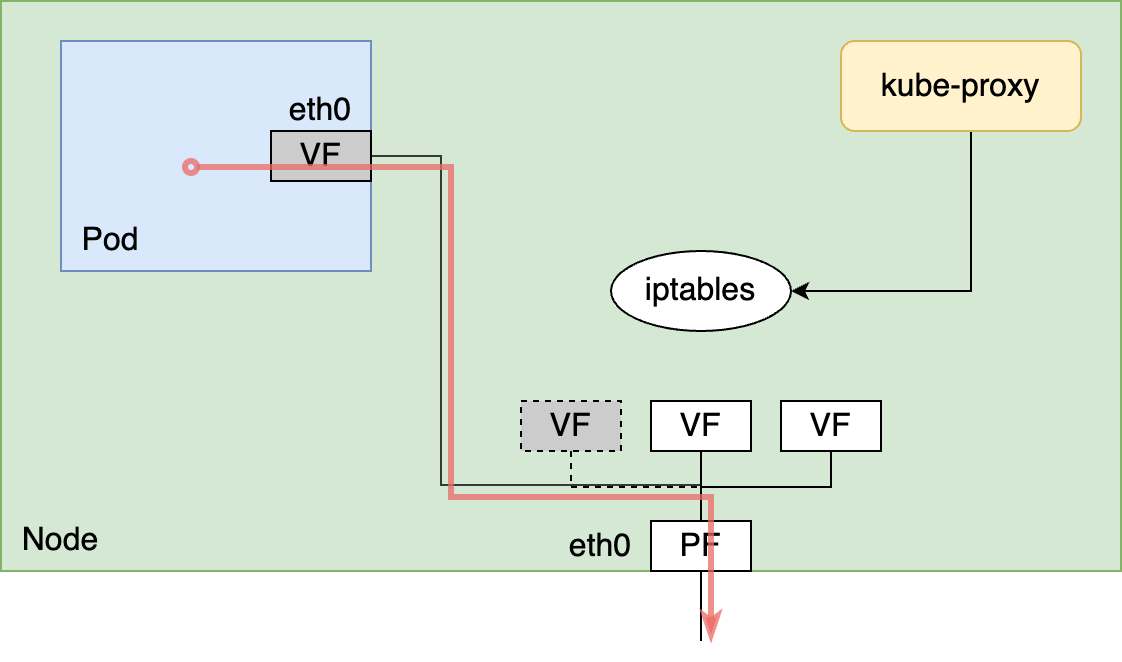
Cluster IPが使えないとCoreDNSと通信ができず、podから名前解決ができなくなるため、Kubernetesクラスタとして実質的に機能しません。
このCluster IPの問題を解決する一つのアプローチとして、kube-proxyがホストのnetwork namespaceに設定するiptablesのルールと同一のルールをpodのnetwork namespaceに対しても設定するという方法があります。第1世代の構成ではこのアプローチをとってCluster IPの問題の解決に当たりました。実際の実装方法としては、kube-proxyにパッチを当てる方法をとりました。ホストのnetwork namespaceだけでなく、ノードに存在する全podのnetwork namespace(正確にはホストネットワークを使わないpodのnetwork namespaceに限定)に対してもiptablesのルールを設定するようなパッチを作成しkube-proxyに適用しました。
運用中に見つかった課題
MN-2の運用開始時から第1世代の構成で運用を行っていましたが、実際に運用を行っていくうちにいくつかの課題が見つかりました。この運用を始めてから見つかった課題について紹介します。
時間が経過すると割り当て可能なVFが無くなる
運用を始めて比較的早い段階でpodにVFが割り当てられない状態になるノードが発生するという問題が見つかりました。内製CNI Pluginはノード上に存在するVFから、インターフェイス名とリンク状態を条件にしてpodに割り当て可能なVFを識別しています。問題が発生したノードを調べてみると、VFのインターフェイス名が起動時に設定されているものから devXX (XX の部分は数字) のような見たことのない名前に変わっていて、CNI Pluginが割り当て可能なVFを正しく認識出来ない状態になっていました。さらに調査を進めると、VFのインターフェイス名が変わった状態でノード上に出現する現象は、podを作成直後に削除する場合に発生することが分かりました。この現象が一度起きてしまうとCNI Pluginが認識する割り当て可能VF数が減少したままになります。そのため、長い時間たつとそのうちCNI Pluginが認識する割り当て可能なVFがノード上から無くなり、そのノードではpodの実行に失敗し続ける状態になります。内製CNI Pluginは複数のVFのpodへの割り当てに対応しているため、複数のVFを割り当てたpodでインターフェイス名が変わってしまう現象が発生すると、一度に複数のVFが以後割り当て不可能なってしまい、割り当て可能なVFが枯渇するまでのスピードが加速するのも問題をより深刻にします。この問題に対しては、インターフェイス名が変わったVFをヒューリスティックで判断してインターフェイス名を元に戻す回復処理を内製CNI Pluginに実装することで対応しました。この回復処理の一環として、IPアドレスやリンク状態の修正処理も一緒に行うようにしました。
Podの起動直後にCluster IPを使った通信ができない
運用始めて判明した課題の中にはkube-proxyにパッチを当てたことに起因することもありました。そのひとつは、podの起動直後だとCluster IPへの疎通ができないことがあるという問題です。パッチを当てたkube-proxyはホストのnetwork namespaceに対して行われるiptablesのルールの設定と同一の設定をpodのnetwork namespaceに対して行いますが、この処理はpodの起動タイミングと同期して実行されるわけではないため、podの起動直後にはCluster IPを使うために必要なiptablesのルールが設定されていないことがあり得ます。この問題に対しては、対症療法としてCluster IPへの疎通ができるようになるまでウェイトを行うコンテナ(injected-sleepと呼んでいます)をpodのinit containerとして設定するようなmutating webhookを実装することで対応しました。しかしながら、この対処法はpodが起動するまでの時間が延びるという副作用を生みました。
kube-proxyのリソース使用量が増加し続ける
また、kube-proxyのCPU使用率、メモリ使用量が時間の経過と共に増加していたことが分かりました。CPU使用率もメモリ使用量も時間が経過に応じて右肩上がりに増加をし続け、起動時間によってはCPU使用率は25%、メモリ使用量は2 GB近くを消費するような状態でした。
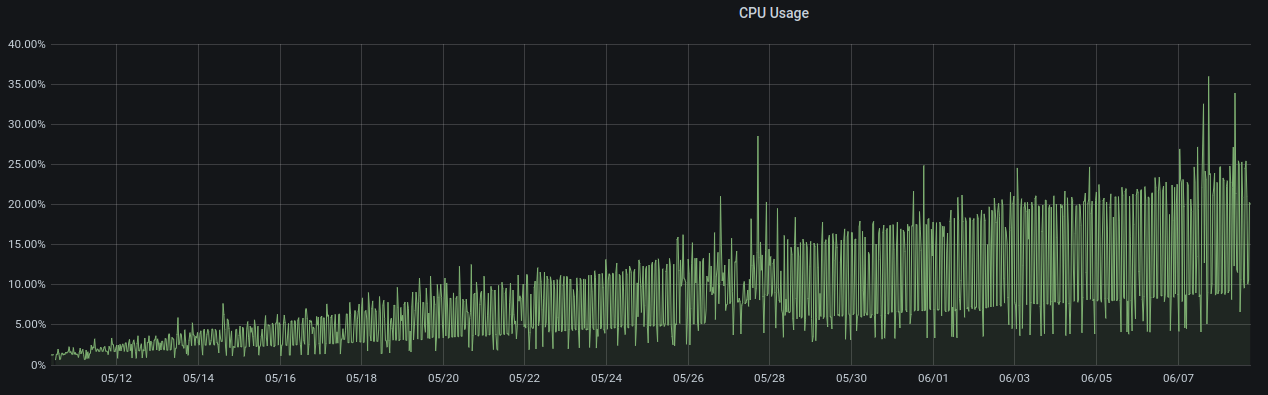
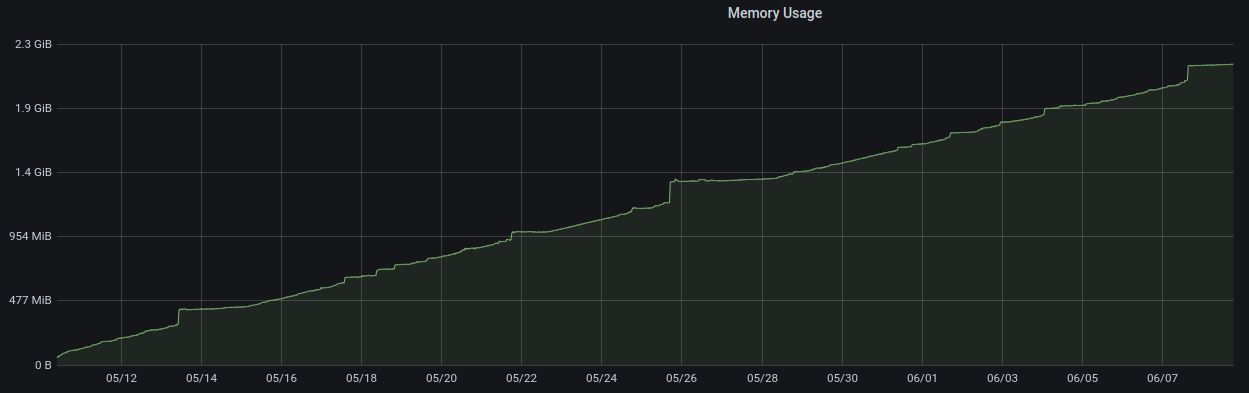
このようにkube-proxyの負荷が高い状態になると、init containerとして挿入しているinjected-sleepでの疎通性チェックがタイムアウトに達するまで失敗することも起きていました。injected-sleepが失敗するとpod自体の起動が失敗してしまうため、対症療法に対症療法を重ねる形でkube-proxyを定期的に再起動するような対応を行っていました。完全には根本原因を特定していませんが、このkube-proxyのリソースリークの問題もkube-proxyにパッチを当てていることによるものだと考えています。
kube-proxyにパッチを当てると、Kubernetesのバージョンアップの度にアップストリームの変更に追従した変更を適用し、動作の検証を行わなくてはいけなくなります。これはKubernetesのアップグレードの際の手間を増やすため、クラスタのKubernetesのバージョンアップを行うボトルネックとなり、バージョンアップのペースを律速する要因になり得ます。PFNでは2021年4月からCluster APIを導入し、クラスタをタイムリーにバージョンアップすることができる基盤を整えています。そのため、kube-proxyにパッチを当てていることがKubernetesのバージョンアップの足かせとして顕在化してきました。
Kubernetesクラスタのネットワーク構成(第2世代)
これらの課題を解決するためにはkube-proxyへのパッチが不要な構成にする必要があると判断し、これを実現可能な新しい構成の検討を行いました。この新しい構成を以降では第2世代の構成と呼んで話を進めます。第2世代の構成では、これまで内製CNI Pluginによって実現していた複数インターフェイスを使ったRDMAを引き続きサポートしつつkube-proxyへのパッチを不要にすることが求められます。パッチをしないkube-proxyを使うためには典型的なCNI Pluginの実装で行うようにvethインターフェイスを使ってpodの通信に関係するパケットがホストのnetwork namespaceを通過するようにするのが自然な実現方法です。しかしながら、この方法ではRDMAをサポートするのが難しいというのは前に説明した通りです。
検討の結果、最終的にはMultusという特殊なCNI Pluginを使ってRDMAを行わない一般的な通信とRDMAを行う通信とで使用するCNI Pluginを使い分ける方法を採用することにしました。MultusはMeta CNI Pluginと呼ばれていて、これ自体はpodに対してネットワークインターフェイスの割り当ては行わず、他のCNI Pluginに処理を委譲することによってpodに対して使用するCNI Pluginを切り換えたり、複数のCNI Pluginを使って複数のネットワークインターフェイスを割り当て可能にするCNI Pluginです。Multusを使うことで、RDMAを行わない一般的な通信に対してはCalicoなどのvethインターフェイスを使う一般的なCNI Pluginを使用し、RDMAを行う場合にはRDMAをサポートするCNI Pluginを使用するように、用途に応じてCNI Pluginを使い分けられるようになります。そのため、kube-proxyのパッチを無くすこととRDMAをサポートすることを両立できます。
非RDMAの一般的な通信に対して使用するCNI Pluginにも、RDMAを行う通信に対して使用するCNI Pluginにもそれぞれ選択肢が複数存在します。前者の選択肢としては、例えばCalicoやFlannelがあり、後者の選択肢としては内製CNI Plugin以外にもオープンソースで開発されているSR-IOV CNI Pluginがあります。結果としては、非RDMAの通信用には成熟度を考慮し無難な選択としてCalicoを選びました。RDMAの通信用にはSR-IOV CNI Pluginの採用も検討しましたが、既にPFNのクラスタでは使用していてその意味では実績のある内製CNI Pluginを引き続き使用することにしました。これは、SR-IOV CNI Pluginを採用する場合、これまでからの変更が大きく、設計や検証に時間がよりかかるという見積もりによるものです。詳細な説明は長くなるので省略しますが、ひとつの例としては、ノード内のデバイス間の位置関係を示すトポロジの表現力がKubernetesの提供するものと我々の欲するものとでギャップがあり、内製CNI Pluginと同じ振る舞いをさせるのにも相応の労力がかかることがありました。そのため、問題解決までの時間を優先し、SR-IOV CNI Pluginの採用は一旦見送る判断をしました。
第1世代の構成では内製CNI Pluginのみを使っていたのに対して、第2世代の構成ではMultusを使ってCalicoと内製CNI Pluginの2つのCNIを使う構成になっています。これが特徴として第1世代と第2世代の構成の一番の違いです。RDMAの通信を行うpodであるかどうかに関係なくCalicoはデフォルトのCNI Pluginとして常に使用し、RDMAの通信を行うpodに対してはデフォルトのCNI PluginであるCalicoに加えて内製CNI Pluginを使用する形でCalicoと内製CNI Pluginの使い分けをしています。
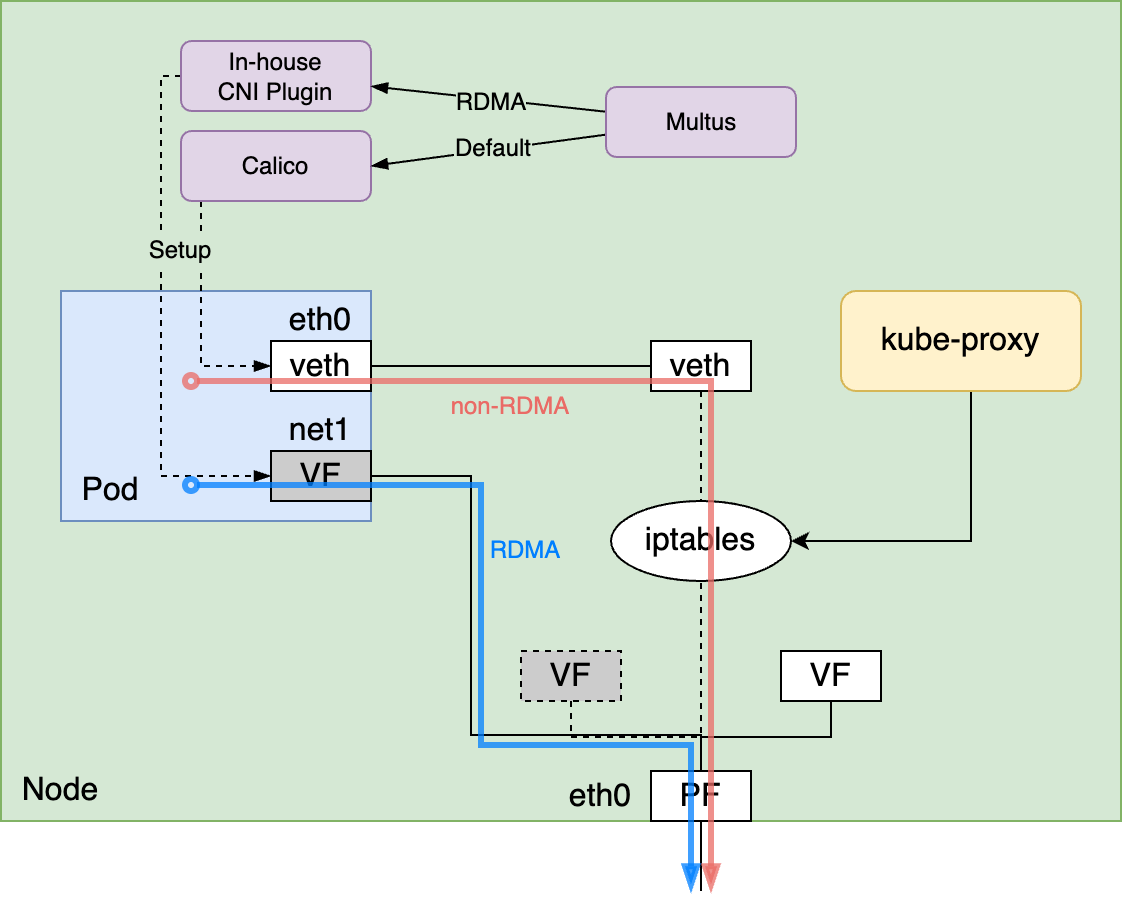
Calicoが設定するネットワークインターフェイスは常にpodに存在するため、kube-proxyにパッチを当てることなくCluster IPを使った通信は全てのpodで行えます。また、RDMAの通信を行うpodには内製CNI Pluginが追加で使われるため、GPU数に応じて複数のVFを割り当てることができ複数インターフェイスを使ったRDMAも引き続きサポートできます。
内製CNI Pluginのみを使った第1世代の構成からMultusでCalicoと内製CNI Pluginを使い分ける第2世代の構成へ2021年7月に移行しました。CNI PluginはKubernetesクラスタにおいてかなり基本的なコンポーネントであり、podは互いに通信できるのが前提となっているため、CNI Pluginを移行するはなかなか骨の折れる作業です。非RDMAの一般的な通信で使われるCNI Pluginが内製のCNI PluginからCalicoに変わることでpodが使うIPアドレスレンジも移行の前後で全く異なったものに変わります。MultusやCalicoを新しく導入するのに加えて、ヘルパー的なコンポーネントもあわせて導入する必要があったり、kube-proxyもパッチを当てているものからパッチ無しのものに変更する必要もありました。ダウンタイム無しの移行が望ましいところではありますが、ダウンタイム無しで移行するのは技術的にも時間的にも困難さが多く、また、PFNでは月1回メンテナンスウィドウと呼ぶクラスタのダウンタイムを許容するメンテナンス時間が存在するため、移行作業はこのメンテナンスウィンドウを使って行いました。
第2世代の構成に移行したことでそれまでkube-proxyに当てていたパッチは不要になり、kube-proxyのCPU使用率とメモリ使用量が時間の経過と共に増加する現象も発生しなくなりました。加えて、init containerとして挿入していたinjected-sleepも不要になりました。また、Kubernetes自体のバージョンアップの時にパッチを当て直す必要もなくなり、Kubernetesの定期的なバージョンアップを行いやすくなりました。2021年7月に移行してから今までこの構成で運用を続けています。
まとめと今後
PFNでは、複数のネットワークインターフェイスを活用したRDMAをサポートするため内製CNI Pluginを開発し、MN-2の運用開始時から使用しています。内製CNI Pluginの運用を続けていくうちに、内製CNI Pluginのみを用いた構成の課題が大きくなり、内製CNI PluginとCalicoを組み合わせて使う構成に移行しました。
課題を解決するためにCNI Pluginの構成の移行をなるべく早く進めたいという事情もあり、必要な設計や検証があまり増えないようにある程度割り切った構成に一旦移行したのもまた事実です。例えば、RDMAの通信用に使用するCNI PluginをオープンソースのSR-IOV CNI Pluginに変更するという選択肢もありましたが、一旦は内製CNI Pluginを使い続けるという選択をしています。細かい点を見てみると、この移行では作業量と時間の関係で手を付けられなかった検討や評価があり、今後改善していきたい部分は各所にあります。今後はこういった点の検討や評価をすすめ、よりユーザに使いやすく性能の良いクラスタを提供できるようにKubernetesネットワーキング環境の改善を行っていきたいと思います。
Area
