Blog
本日、CuPy v8.0.0をリリースしました。主要な新機能や性能向上は以下の通りです。
- TF32形式を用いた行列演算の高速化
- CUBやcuTENSORを用いたリダクション演算の高速化
- カーネル融合変換の機能拡張
- Optunaを用いたリダクション演算のカーネルパラメタの最適化
- PyTorchなどの外部ライブラリとのメモリプールの共有
本記事では、それぞれの新機能や性能向上について、リリースノートよりも詳細に解説します。
TF32形式を用いた行列演算の高速化
CUDA 11 で実装された NVIDIA Ampere アーキテクチャの新機能 TensorFloat-32 に対応しました。CuPy v8 では、float32 行列積の演算でTF32形式を用いることにより、`cupy.matmul`, `cupy.tensordot` などの演算を高速化することができます。
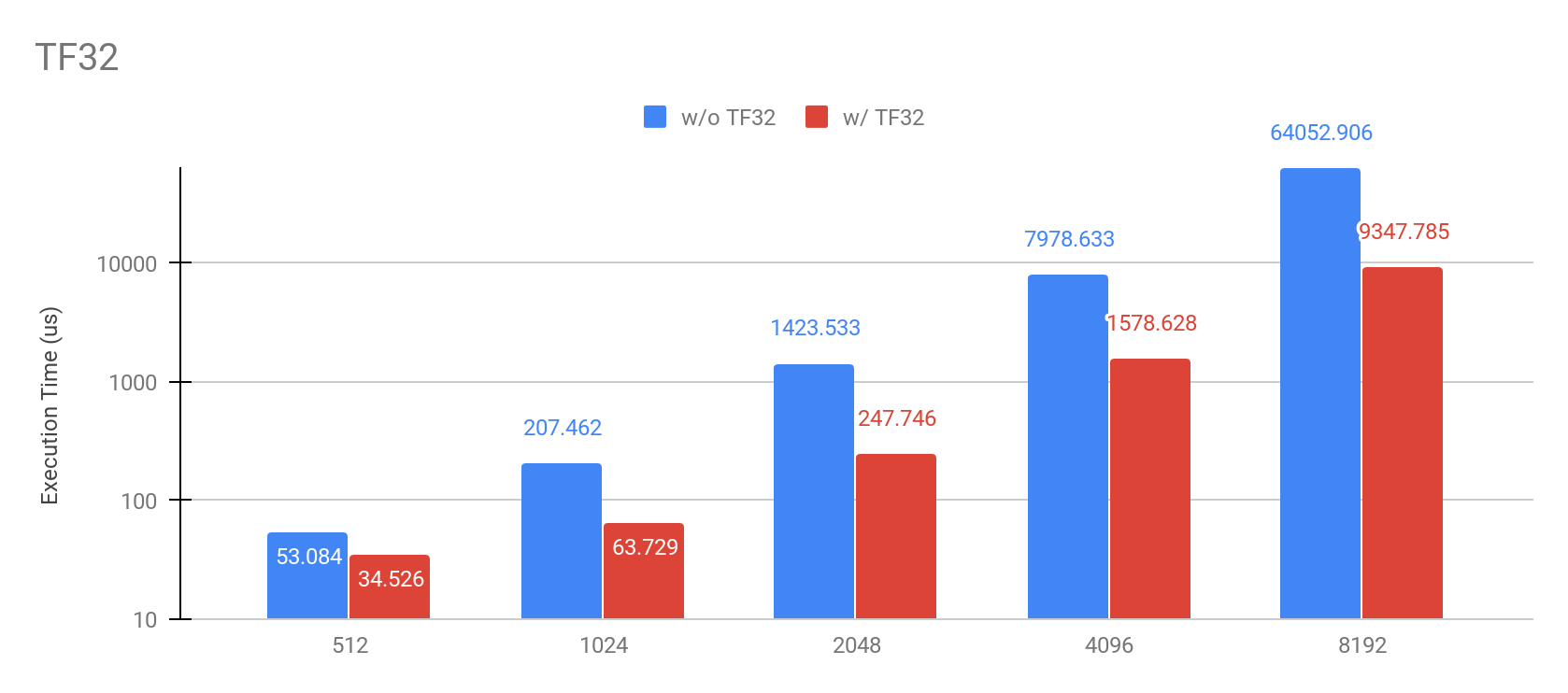
Environment: NVIDIA Ampere A100, CUDA11
この機能は Compute capability 8.0 以上のGPUで利用することができ、以下のように環境変数CUPY_TF32を用いて有効にすることができます。
$ CUPY_TF32=1 python run.py
CUBやcuTENSORを用いた演算の高速化
CuPyの演算でCUBやcuTENSORといった高速な演算を行うライブラリを用いることで、`cupy.sum` を始めとする一部のリダクション演算を高速化しました。
例えば、長さ 400000 の1次元の float32 array をリダクションすると、性能は以下のようになります。
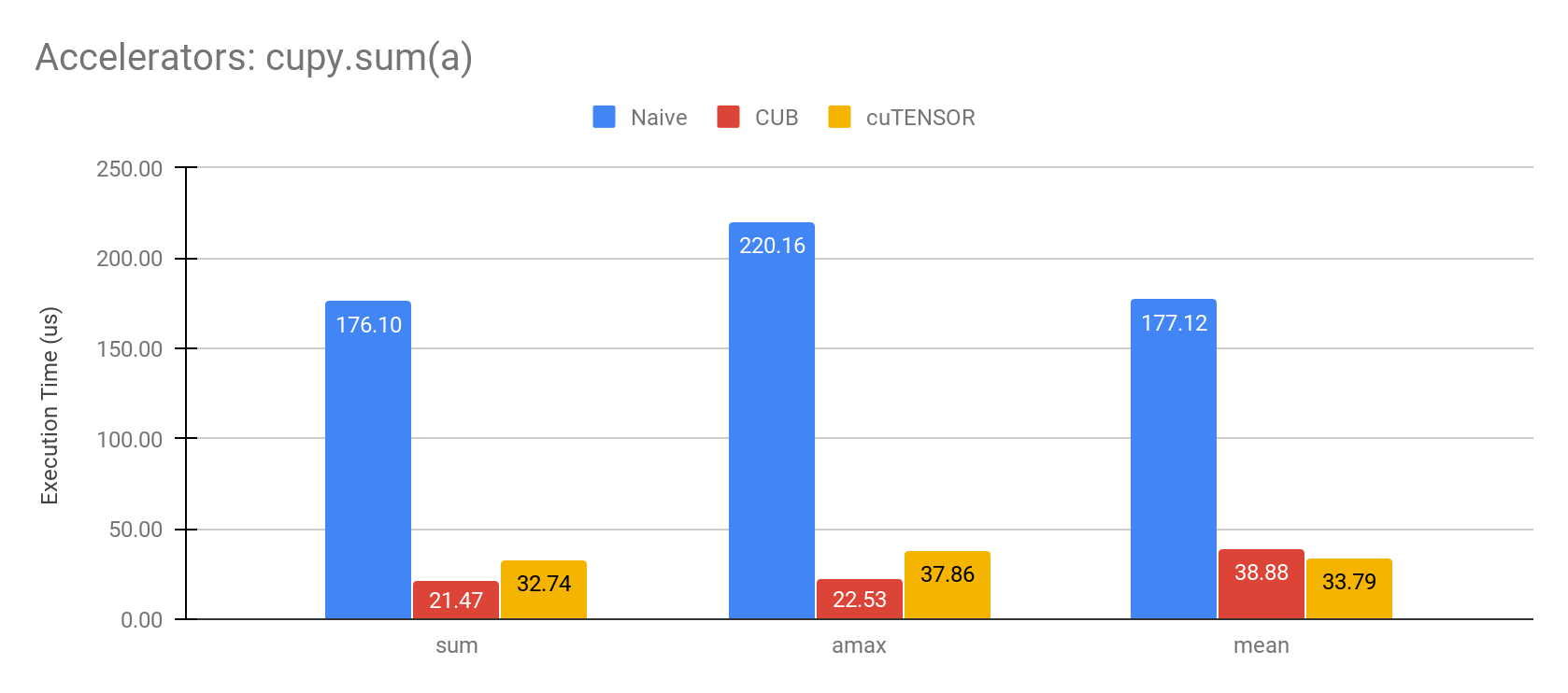
Environment: NVIDIA Tesla V100, CUDA11
また、多次元配列のリダクション演算を行う軸が指定された場合にも部分的に対応しており、shape=(400, 400, 400) の float32 array をそれぞれの軸でリダクションすると、性能は以下のようになります。
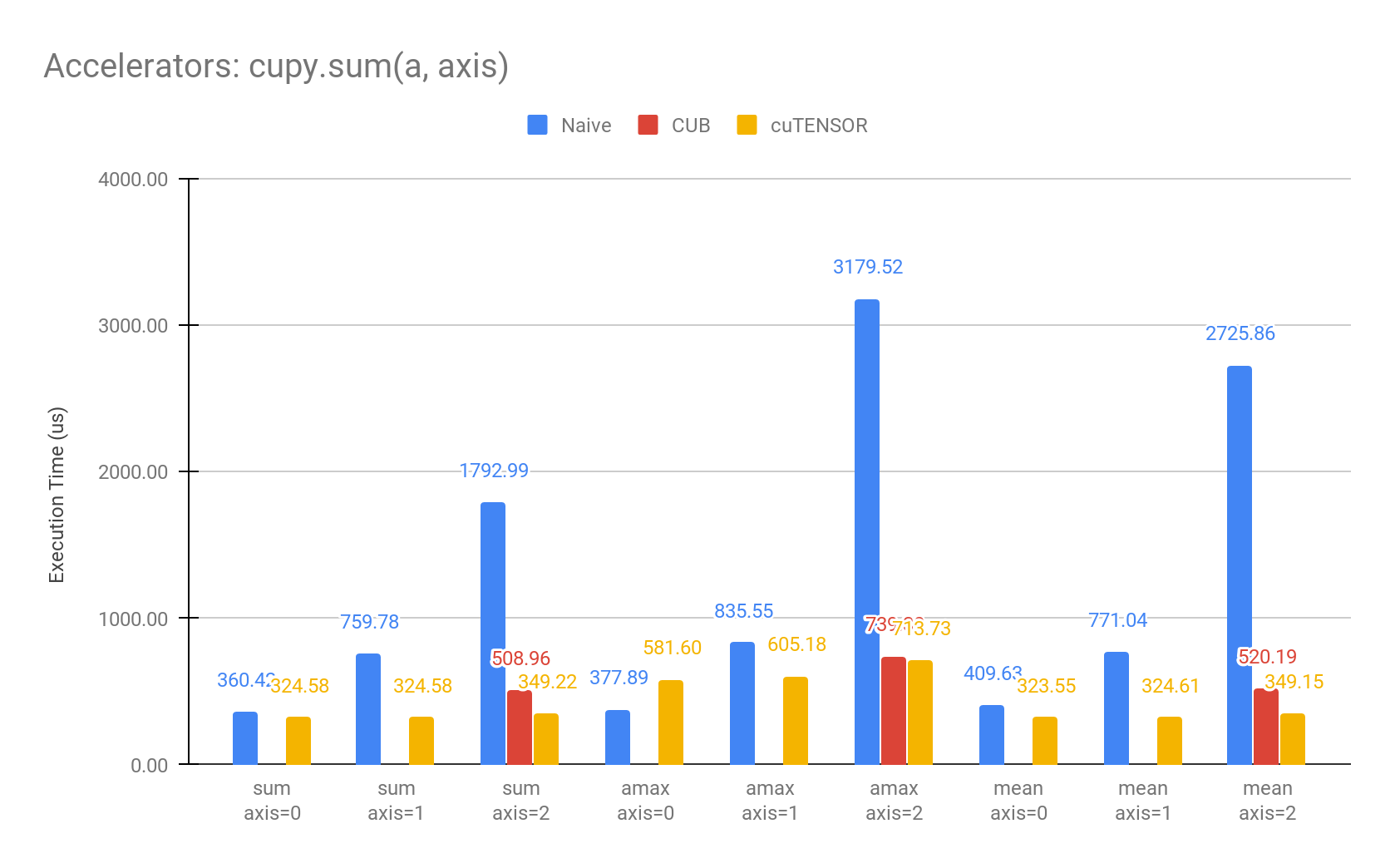
Environment: NVIDIA Tesla V100, CUDA11
現状では、CUBを適用できるのはリダクションを行う軸が連続したメモリ領域である場合 (上の棒グラフにおける axis=2 のケース) のみですが、それ以外の場合についても今後のリリースで対応していく予定です。
CuPyでは、CUBやcuTENSORのような高速な演算を行うために用いる外部ライブラリをアクセラレータと呼んでいます。アクセラレータはデフォルトでは用いられず、以下のように環境変数 CUPY_ACCELERATORS に使用したいアクセラレータをカンマ区切りで設定することで有効化することができます。
$ CUPY_ACCELERATORS=cub,cutensor python run.py
カーネル融合変換の機能拡張
複数の演算をひとつのカーネルに融合変換する機能 cupy.fuse で、複数のリダクション演算 (cupy.sumなど) の融合変換をサポートしました。例えば、以下のようにカーネルを生成することができます。
@cupy.fuse() def batchnorm(x, gamma, beta, running_mean, running_var, size, adjust): decay = 0.9 eps = 2e-5 expander = (None, slice(None), None, None) gamma = gamma[expander] beta = beta[expander] mean = cupy.sum(x, axis=(0, 2, 3)) / size diff = x - mean[expander] var = cupy.sum(diff * diff, axis=(0, 2, 3)) / size inv_std = 1. / cupy.sqrt(var + eps) y = gamma * diff * inv_std[expander] + beta running_mean *= decay running_mean += (1 - decay) * mean running_var *= decay running_var += (1 - decay) * adjust * var return y
Optunaを用いたカーネルパラメタの最適化
CuPyのリダクション演算で起動するCUDAカーネルのブロック数などのパラメタをOptunaを用いて最適化することで、より高速にリダクション演算を行えるようにしました。
以前のバージョンでは、パラメタをヒューリスティックに決めていましたが、GPUによっては最適なパラメタの値を選べないことがありました。そこで、実行にかかる実時間を複数のパラメタで計測して、最適なパラメタを入力形式ごとにキャッシュする機能を追加しました。
サイズ 200000 の float32 array を shape を変えて性能測定したところ、以下のようになります。
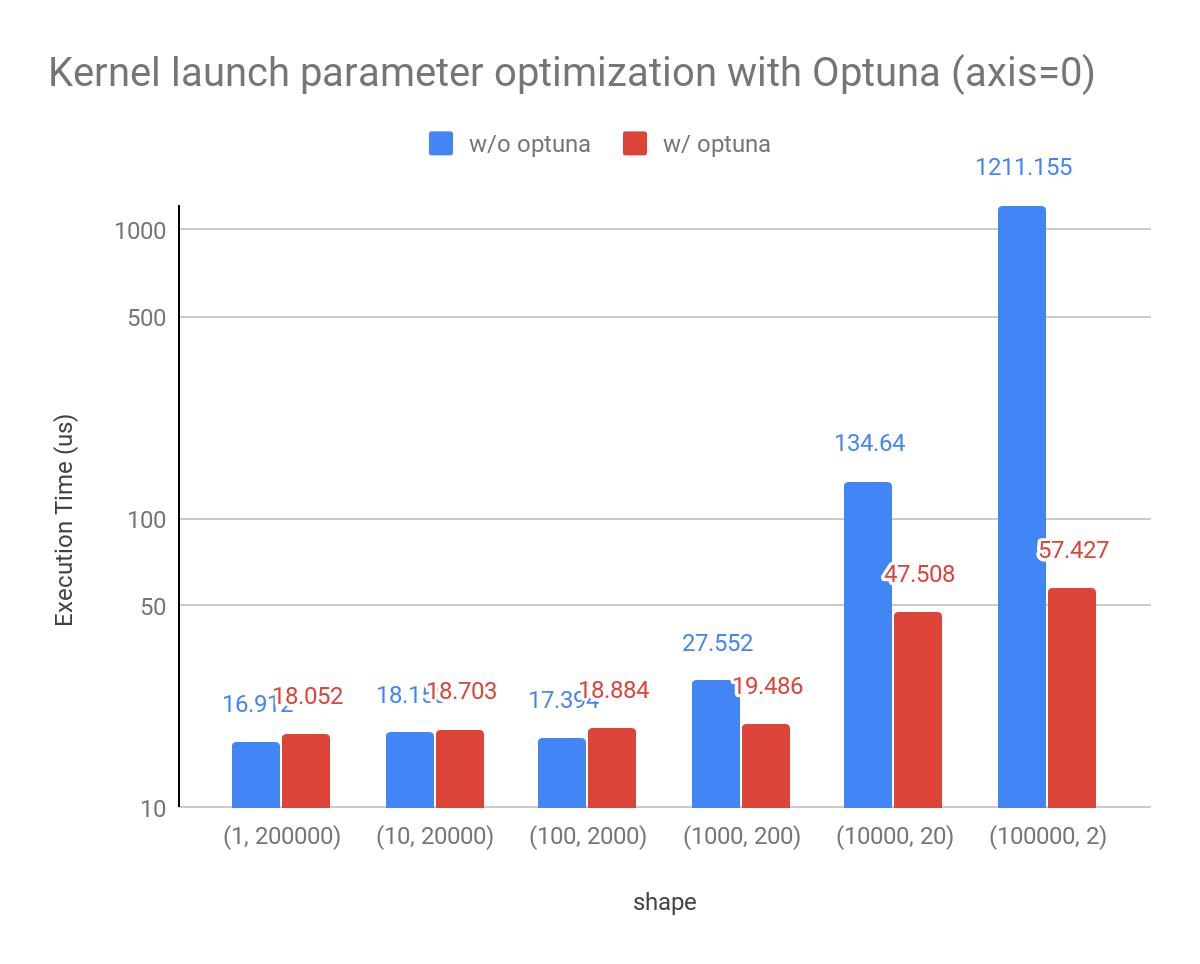
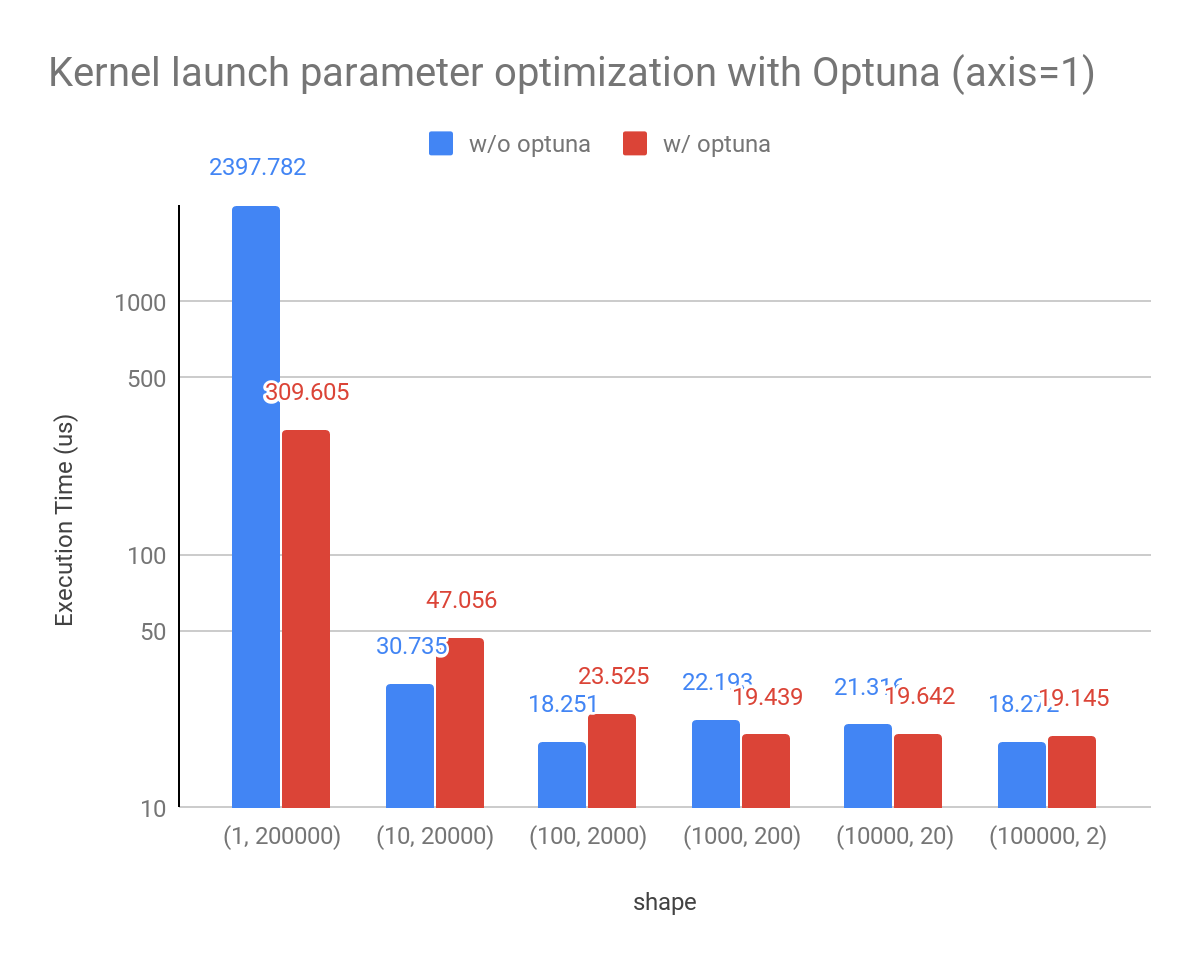
Environment: NVIDIA Tesla V100, CUDA11
この機能はcupyx.optimizing.optimize を用いて有効にできます。
import cupyx.optimizing with cupyx.optimizing.optimize(): y = cupy.sum(x)
外部ライブラリとのメモリプール共有
CuPy で外部ライブラリとメモリプールを共有するための機能として cupy.cuda.memory.PythonFunctionAllocator を実装しました。例えば、ユーザーが定義した関数 malloc_func, free_func を用いて以下のように CuPy のメモリプールを差し替えることができます。
python_alloc = cupy.cuda.memory.PythonFunctionAllocator(malloc_func, free_func) cupy.cuda.memory.set_allocator(python_alloc.malloc)
なお、PyTorch用のPythonFunctionAllocatorが pytorch-pfn-extras (v0.3.1以降) で実装されています。pytorch_pfn_extras.cuda.use_torch_mempool_in_cupy() を呼び出すことで、CuPyからPyTorchのGPUメモリプールを使うことができるため、CuPyとPyTorchを組み合わせて使うケース(例えば、CuPyで前処理を行なったデータをPyTorchの入力に利用する場合など)でメモリの使用効率が向上します。より詳細な説明は pytorch-pfn-extras 内のドキュメントをご覧ください。
