Blog
ImageNetを15分で学習して以来 [1]、Chainerと沢山のGPUを使って深層学習を並列化し、一回の学習に必要な時間を大きく短縮することができるようになりました。その後、ImageNetの学習は深層学習における並列化 ・高速化のデファクト標準ベンチマークとなりました [2]。それと同時に、深層学習の並列化および大規模化は進み、複数GPUどころか複数ノードで学習することは当たり前のこととなりました。深層学習の計算が大規模化し所要時間はどんどん短くなりましたが、一般的にはノードが増えれば増えただけ部分故障の確率は高くなります。また、大規模なクラスタでは個々の分散ジョブをスケールアウトしたりスケールダウンする機能、つまり可塑性をもとにした計算資源のやりくりが運用上重要になってきます。そこでChainerを拡張し、分散深層学習に耐故障性だけでなく可塑性を導入する実験を行いましたので、ここで報告したいと思います。また、実験に利用したライブラリを eChainer として公開しました [3]。
深層学習の計算が大規模化し所要時間はどんどん短くなりましたが、一般的にはノードが増えれば増えただけ部分故障の確率は高くなります。そこで、部分故障があっても計算が継続できるような仕組みがあれば、このような問題に頭を悩ませるようなこともなくなります。
また、ノードが途中で減っても動作継続できるということは、大抵の場合はノードを途中で追加しても動作継続できるということです。これができると、学習を実行中にGPUを追加することで学習を加速することができます。これは、大規模なクラスタ環境ではとてもメリットが大きいことで、例えば、ジョブ終了や失敗などが原因で、クラスタ上の別の場所で余っていた計算資源を動的にジョブに追加することで、ジョブを早く終わらせることができるようになり、クラスタ上のリソース配分の柔軟性が増します。リソース利用効率を上げることができ、同じ計算基盤への投資でより多くのリターン(よいモデル、よい計算結果)を得ることができるようになります。動的に計算資源と追加したり減らしたりできることを、そのシステムに可塑性(Elasticity)があるといいます。 eChainer というプロトタイプ名は、 Elastic Chainer を短縮してつけたものです。
基本設計とシステム構成
Chainerには、分散学習用の内部コンポーネントが含まれており、ChainerMN という名前がついています。これを使ったこれまでの分散深層学習については、弊社鈴木の解説[4] や、その肝となる AllReduce の計算についてはインターンの上野さんの寄稿 [5] をご覧ください。ChainerMNの Communicator [6] [7] は、MPIにおけるCommunicatorをPythonのインターフェースクラスとして表現し、それを実装したものです。ChainerMNにおける分散深層学習は、基本的に全てこのCommunicatorを使っています。Communicator の実装クラス PureNcclCommunicator を通じて NCCLを利用した場合のイメージを図1に示します。NCCLは、NVIDIAが開発しているGPU専用の集団通信ライブラリです[8] 。ChainerMNでは、CuPyのCythonの実装を通じてNCCLを利用します。
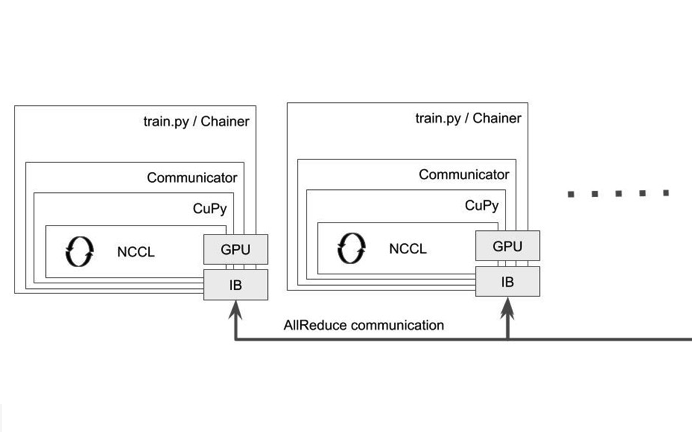
図1: Chainerを使った分散深層学習の内部コンポーネントの構成図: PureNcclCommunicator はCuPy を通じてNCCLを呼び出す
いくつかあるCommunicatorの実装は、いずれもシステムの部分故障を前提としたものにはなっていません。最も利用されているのは PureNcclCommunicator ですが、その内部で利用しているNCCLが 2.3 まではシステムの部分故障を前提としたものになっていませんでした。例えば ncclAllReduce() の集団通信に参加しているプロセスがひとつでも故障すると、他のプロセスで呼ばれた ncclAllReduce() は永遠にブロックされたままになります。
このとき、Communicatorの内部で起きていることを詳しく解説します。ChainerMNは内部的にはCuPy経由で ncclAllReduce() を利用します。CuPy は Cython 経由で全ての関数を呼び出します。ところがPythonのC拡張の仕様では、ユーザーから送られるUnixシグナルはPythonが設定したシグナルハンドラによって擬似的にブロックされた状態になり、シグナルに対するコールバックはPython上の実行に戻ってから呼ばれます [9] 。つまり、ncclAllReduce() の呼び出しが戻らない限りは SIGTERM等を全く受け付けず、ずっと ncclAllReduce() の中で止まったままになります。集団通信に参加しているプロセスが一つでも故障すると、その集団通信はずっと終わらないままブロックするということになります。この様子を図 2 に示します。
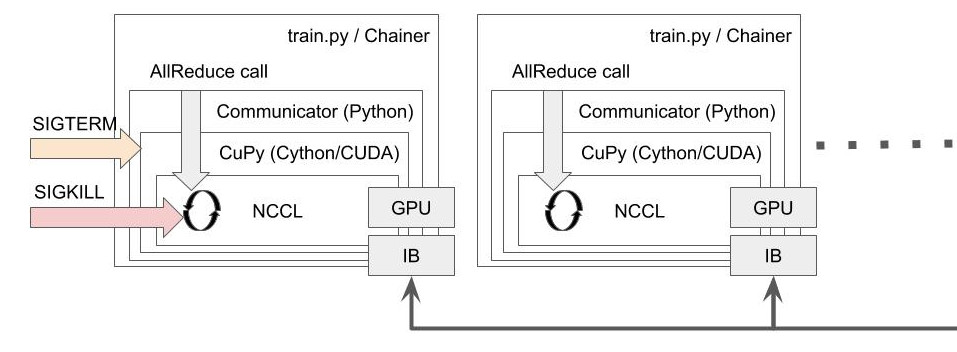
図2: AllReduce を呼んでいる最中はSIGTERMが擬似的にブロックされ、 ncclAllReduce() 中のループから抜け出すまでユーザー側で処理をすることはできない。ncclAllReduce() は故障プロセスを含む他のプロセスからの通信を待ち続ける。
実用的には、集団通信がハングしていることを検知して、シグナルハンドラを設定できないSIGKILL等で各ノードでひとつひとつ手動でkillしてまわらなければならなくなります。 OpenMPIはこの状態は検知してジョブを強制終了するといったことはできませんから、ジョブが進行しないまま半永久的に計算リソースを占拠し続けることになります。これが、 ncclDestroy() のAPI導入前の状態でした。
ちょうどよいタイミングで、昨年の今頃のことでしたが、NCCL 2.4から導入される ncclDestroy() というAPIをリリース前にテストすることができました [10]。この関数は、NCCLを使ったアプリケーションに耐故障性を導入するために、最小限でありながら十分な機能追加です。個人的なことですが、NCCLの開発者とメールをやり取りしてこのアイディアを聞いたときはに本当に感心しました。わたしが一年近く悩んでいたこの問題について、既存のコードに影響を与えず問題をエレガントに解決するベストなアプローチだったからです。
ChainerMNを利用した分散深層学習が全てCommunicatorに立脚しているということは、これさえ故障に耐えうる仕様になれば、ChainerMN上の分散深層学習は全て耐故障性を備えることができるようになります。ということで、まずはCommunicatorに耐故障性をもたせるためにncclDestroy() を導入することを目指します。 ncclDestroy() は、任意のタイミングで特定の ncclCommunicator (混乱しそうですが、これはNCCLで内部的に利用するオブジェクトです)を破壊して、そのタイミングで実行されていたあらゆる集団通信を強制終了させることができます。つまり、 ncclAllReduce() が故障したプロセスからの永久にこないメッセージを待っているときに横から強制終了させることができるということです。これによって、NCCLの集団通信中にブロックされた状態から戻れなくなるという問題が解決できます。あとは、NCCLを利用するアプリケーションが、どのようにシステムとして故障を検出し、 ncclDestroy() によってどのようにncclAllReduce() の強制終了をハンドリングするかという問題になります。
まず、ノードの死活監視のために etcd を導入します [11]。Chainerを使っている学習プロセス内で etcd クライアントを別スレッド上で動作させ、このスレッドが etcd とKeepAliveをします。これによって、システムの基本構成は図3 のようになります。
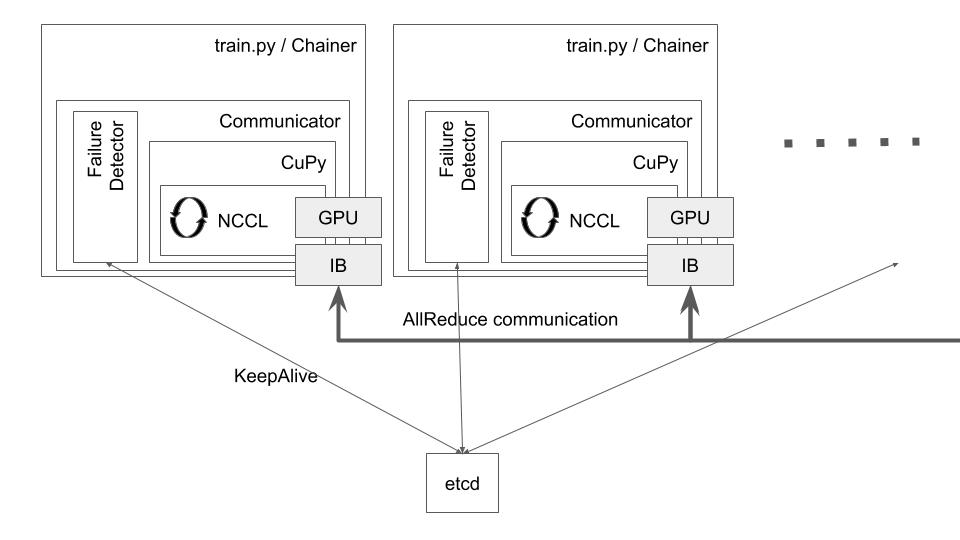
図3: eChainer を使った学習プロセスの基本構成: Communicator 内にetcd を用いた故障検出器を追加した。
このように死活監視するチャンネルを設けることによって、ひとつのプロセスの故障を全体に通知することができるようになります。具体的には、各プロセスは etcd の特定のprefix上にエフェメラルファイルを作って、それをお互いに監視することで死活監視とします。エフェメラルファイルとは、クライアントとサーバーの双方が正常に動作してKeepAliveが維持されているときにだけ保持されるファイルです。例えばクライアントが故障すると、一定時間後にこのエフェメラルファイルが消滅し、他のプロセスはこのエフェメラルファイルが消滅した通知を受け取ることができます。実はここが分散システムで最も難しい故障検出の問題を解決している部分なのですが、etcdを使うことで複雑な実装も簡単に済ませることができました。
この通知をトリガーにして、全てのプロセスは学習(および集団通信)を一旦停止します。このときに ncclDestroy() を利用します。これによって動作中の ncclAllReduce() と、それを利用していた NCCL のリングは全プロセスで破棄されます。ncclAllReduce() は同期的な集団通信で、全てのプロセスが同じ iteration 中にいることが保証されていますから、このように破棄されたことをPythonの例外によって表現することができます。これで、アプリケーションからも故障を検出をできるようになりました。その様子を図4 に示します。
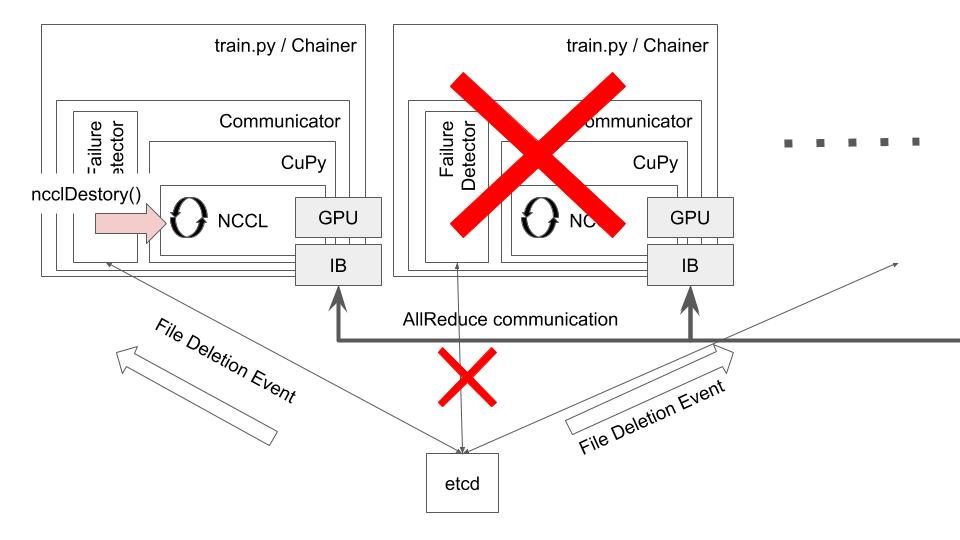
図4: プロセス故障の検出はファイル削除のイベントとして全ノードに通知され、それをもとに ncclDestroy() が呼ばれる。ncclDestory() であれば、通信待ちの ncclAllReduce() を強制的に終了させることができる
このようにノードの離脱を etcd のイベントとして表現しましたが、実は、ノードの追加も同様に etcd のイベント(エフェメラルファイルの追加)として表現することができます。同様に、 ncclDestroy() を発行してNCCLのリングを破棄して、あらたに追加されたノートを加えてNCCLのリングを再構築することにより、分散学習の動的なスケールアウトを実現することができます。
しかしながら、NCCLのリングの破棄と再構築はCommunicator の size や rank の変更を必要とします。つまり、全体のプロセス数が変わった場合は、配った学習データを割り当てなおしたり、学習率のスケールルール[12] に従って、改めて学習率を設定する必要があります。また、新しく追加されたプロセスはモデルのパラメータやオプティマイザのパラメータなどの学習の途中状態を知りませんから、学習を再開するためには、これらの情報を別のプロセスのメモリから集めてやる必要があります。これらの処理はなるべく共通化してユーザーが書かなくてもよいようにしたいところでしたが、今回の実験ではImageNetにフォーカスして学習スクリプト上に作り込むことにしました。基本的には、プロセス増減の例外を受けて、
- 学習データの割当をやり直す
- Optimizer やモデルのオブジェクトを作り直す
- ChainerのTrainerを作り直してプロセス間で配り直す
- 学習を再開する
という処理をフラットに while ループの中に実装しました。詳しくは eChainer に付属するサンプルコードをご覧ください。
ここまで基本的な設計を解説しましたが、実はこのアプローチには難しい問題がひとつあります。ノードの追加や故障は、現実的にはそうそう起こるものではありませんが、追加や故障を受けた際に計算を再開してよいかどうかの条件は自明ではありません。以下は簡単な例ですが、
- 分散深層学習を実行するプロセス数が大きく減ると、学習率の調整によって学習自体は続けることができるが、学習にかかる時間は大きく延びる。例えば48時間で終わると思っていた学習が、途中でプロセスが大きく減って残りETAが64時間まで伸びてしまった。この学習を途中で停止してやり直した方が早くはないか?
- 分散深層学習を実行するプロセス数が増えると、学習率の調整によって学習を続けることはできるが、例えばバッチサイズが64000まで増えてしまったら、32000のときとは別の学習レシピが必要になる(LARS [13] 等)。バッチサイズをある範囲でコントロールしたい
- ノード追加のタイミングがすこしバラバラになってしまって、 8プロセス(8GPU)追加するときに1回ずつ認識されてしまい、計8回の例外が投げられてしまい、NCCLのリング再構築やモデルの再同期など重い処理が不必要に走ってしまうと非効率
- ある学習レシピは32プロセス8GPUでしか動作しない(バッチサイズなどのパラメータが慎重に設計されている)。重要な学習なので、1プロセスの失敗で止まることなく、自動的に動作継続はしてほしいが、1プロセス減った状態で勝手に計算を再開させることなく、再度計算リソースが追加するまで待ちたい
- ジョブの進捗が8割を過ぎていたら頑張って動作継続をしてほしいが、5割程度の進捗ならまた別途やり直してもよい
といったことがあります。こういった、計算資源の増減に対する複雑な対応や要件をすべて単一の実装で実現したり、設定ファイルで記述させるといったことは簡単ではありません。そこで、Chainerが持っている Define-by-Run という考え方[14]に触発されて、私もこれをDefine-by-Runで実現することができないかと考えました。
Define-by-Run Re-configuration
Define-by-Runの基本的な考え方は、 (1) やりたいことをプログラムで表現する (2) そのプログラム表現と実行が 1:1 で対応する、というものです。こうやって書くと当たり前のことに見えますが、これによって、高い表現力と、任意の条件判断を追加できる、失敗した箇所がスタックトレースと対応するなどのメリットがあります。 Chainerではニューラルネットワークの入力、途中の forward 処理、出力を表現して実行することが目的でしたが、 eChainer では計算資源の増減と、それに対してジョブがとるべき対応を表現して実行することが目的となります。 eChainer では、これを ScalePolicy() の継承クラス として実装してCommunicatorに渡すことで、学習時にポリシーが評価および実行されるようになります。ScalePolicy()を継承して、ok2run(self, hosts, initial) というメソッドを実装するだけです。例えば、Fail-stopといわれる最も簡単なポリシーを表現するには、以下で十分です。
class FailStop(echainer.ScalePolicy):
def __init__(self, n): self.n = n
def ok2run(self, hosts, initial):
if len(hosts) == self.n: return “ok”
elif initial: return “wait”
else: return “fail”
ok2run() は、計算を再開してよければ “ok” を返します。規定の条件を満たすまで待機するべきであれば “wait” を返します。このジョブを失敗として終了するには、 “fail” を返します。このオブジェクトはジョブの実行中は保持されますから、Optimizerなどの任意の状態や条件をこのオブジェクトのメンバーとして持たせることによって、上記で述べたような条件を好きなように設定することができます。ユーザーは計算の再開、待機、中止を決定する任意の条件をプログラムによって表現することができます。
このPolicyとetcdのアクセス先を渡すことで、ChainerMNのCommunicatorと互換で、耐障害性のあるCommunicatorを作ることができます。
policy = YourOwnCoolScalePolicy(...) etcd = “etcd://e1:2379,e2:2379,e3:2379/your-job-name” listen = “10.0.0.1:9889” comm = echainer.NcclCommunicator(policy, etcd, listen)
実験
この eChainer を使って、実際にImageNetの学習をスケールアップさせたり、スケールダウンさせる実験を行いました。
ChainerCVの example にあるImageNetの学習スクリプトをベースにしたので、学習レシピは [12] と同じです。実験に用いた環境はMN-1b上のKubernetesを使ったコンテナです。ncclAllReduce は InfiniBand HDR上で動作しますが、その他の通信は 10GbE上のTCP/IP上で行われます。2-4 ノード(16−32GPU)の間で増減する実験をしました。ノード故障は簡単に SIGTERM で行われています。ScalePolicy は MinMax というものを実装しました。プロセス数が一定範囲内にある限り動作を継続するというものです。
まず、ノードの増減がなく正常に終了した学習の進捗です。以下の図はいずれも横軸に実時間、縦時間にImageNetの学習エポックをプロットしています。
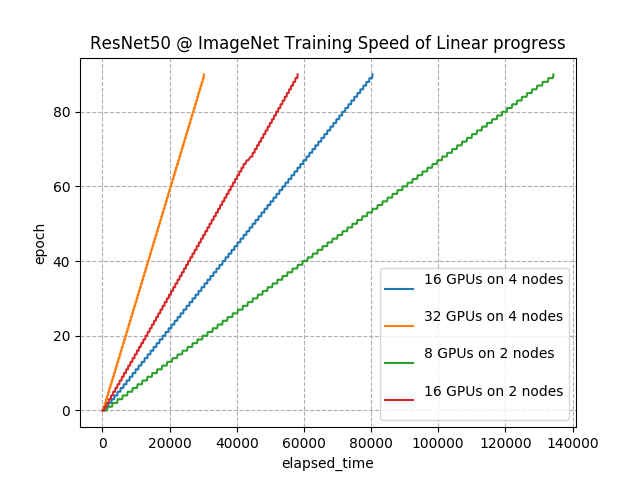
図5: さまざまなGPU数でImageNet を学習した際の速度
GPUの数に応じて学習の速度(線の傾き)が変化しているのがわかります。以降のグラフもそうなのですが、 epoch が離散的に変化するために線が破線状になっています。次に、学習の途中で2ノード(8GPU)追加してみます。
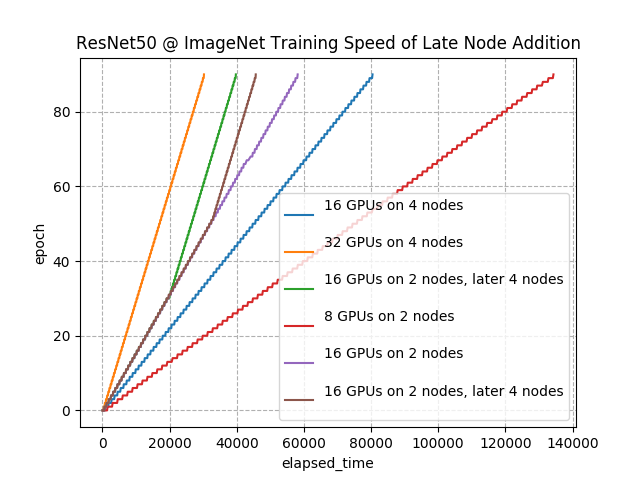
図6: 学習途中でノード追加した場合の学習速度の変化
緑の線と、茶色の線がそれぞれ別のタイミングで途中ノードを追加したものです。追加の前後でも同様に学習が動作していることがわかります。それぞれ、20000秒付近、34000秒付近で学習の速度が変化し、32GPUと同じ速度になっていることがわかります。また、このときのvalidation set に対する最終精度は 76.4% でした。1回だけの測定ですが、元の論文[12]と同程度の精度がノード追加にも関わらず再現できました。
次に、ノードが途中離脱した場合です。32GPUと16GPUで実行していたジョブを、それぞれ途中でプロセスを落とすことでGPU数を減らしています。
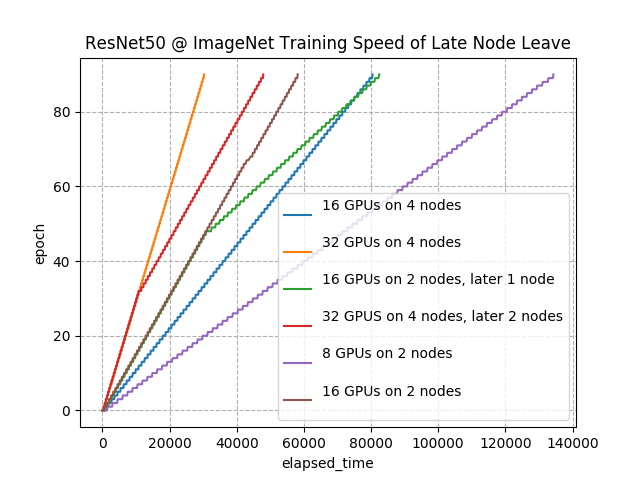
図7: 学習途中でノード削除した場合の学習速度の変化
赤線では、GPU数が32から16に途中で減っています。同じタイミングで、線の傾きも16GPUのそれと同じになっています。同様に、16から8に減った緑線の場合でも8GPUと同じ速度に傾きが落ち込んでいることがわかります。また、プロセスが離脱する前後でもジョブ全体が落ちることはなく動作継続することができました。このときのvalidation set に対する最終精度は 76.0% でした(1回測定)。スケールダウンのときと比較して 0.4% 低下していますが、これが常に下がるものなのかどうかは原因も含めて今後調査する必要があります。
このように、分散深層学習のジョブを実行中に動的に計算資源を追加することにより学習の進行速度を上げたり、ジョブを止めることなく動的に計算資源を一部取り除くことができるようになりました。
関連研究および関連システム
分散深層学習の先駆けであるDistBeliefはもともとGoogleの大規模分散システム上で耐障害性を持って動作していました[15]。この系譜を受け継ぐ TensorFlow はパラメーターサーバーを持つモデルで、パラメーターサーバー以外のワーカーノードが故障しても、その部分のミニバッチを別のノードで再計算すれば済みました。これは非同期(Asynchronous) SGD といわれる分散方式で、始めから耐障害性を考慮されたものです。しかしながら、これにはパラメーターサーバーに負荷が集中してボトルネックになりやすい、古い勾配を使って学習してしまうなどの問題がありました。
ChainerMNを始めとするMPIベースの分散深層学習では、同期(Synchronous) SGDといわれる分散方式を採用し、HPC技術の恩恵を受けて上記の問題点を解決し、深層学習の高速化に寄与しました。しかしながら、HPC技術の恩恵を受ける代わりに、非同期SGDが持っていた耐障害性を失うこととなりました。
HPCの分野でも、もちろん同期的な集団通信に耐障害性を与える研究が行われています。中でもULFM (User Level Fault Mitigation) [15][16] はMPIのWGで精力的に標準化が検討されています。これはMPIに障害のハンドリングするAPIを追加しようとするものです。
まとめ
分散深層学習に耐障害性と、可塑性を導入する実験的なライブラリ eChainer と、その実験結果をまとめました。特にプロセス数が増減したときのハンドリングをどう行うかについて、 Define-by-Run の考え方に基づいた表現方法を提案しました。
[1] T. Akiba, S. Suzuki and K. Fukuda, “Extremely Large Minibatch SGD: Training ResNet-50 on ImageNet in 15 Minutes,” arXiv:1711.04325, 2017.
[2] https://mlperf.org
[3] eChainer
[4] 分散深層学習とChainerMNについて
[5] 分散深層学習を支える技術:AllReduceアルゴリズム
[6] 分散深層学習パッケージ ChainerMN 公開
[7] Chainer Doc: Communicators
[8] NVIDIA Collective Communications Library (NCCL) https://developer.nvidia.com/nccl
[9] signal — Set handlers for asynchronous events
[10] Preliminary abort mechanism and an API for querying asynchronous errors.
[11] https://etcd.io
[12] P. Goyal, P. Dollár, R. Girshick, P. Noordhuis, L. Wesolowski, A. Kyrola, A. Tulloch, Y. Jia and K. He, “Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour,” arXiv:1706.02677, 2017.
[13] Y. You, I. Gitman, and B. Ginsburg. Large Batch Training Of Convolutional Networks. arXiv:1708.03888, 2017.
[14] Tokui, Seiya, et al. “Chainer: A Deep Learning Framework for Accelerating the Research Cycle.” Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM, 2019.
[15] ULFM 2.0 Release
[16] George Bosilca , Aurelien Bouteiller , Amina Guermouche , Thomas Herault , Yves Robert , Pierre Sens , Jack Dongarra, Failure detection and propagation in HPC systems, SC’16.
