Blog
本記事は2025年度PFN夏期インターンシップで、LLMによってアルゴリズム自体を進化させ、新たな解を探索するAIエージェント(進化的探索エージェント)の開発に取り組まれた山本竜馬さんによる寄稿です。
はじめに
2025年度夏季インターンシップ (8月-9月)に参加した東京科学大学 物質理工学院 材料系 M1の山本竜馬です。普段はマテリアルズインフォマティクスの研究をしています。今回の夏季インターンでは、材料科学分野の探索問題を解く進化的探索エージェントを開発する研究に取り組みました。
背景
材料科学分野にはオープンエンドな探索問題が多くあります。
- 材料探索: 望ましい物性を持つ新規材料の探索
- 合成: 新規反応経路の発見
- プロセス構築: 膨大なパラメーターの最適化や新規プロセスアルゴリズム・手法の発見
これらの問題の探索空間は非常に広大であり、なかには、明確なゴールを定めることも困難な問題も含まれています。そのため、これらの問題を効果的に解くには、複数の探索指針を試行し、各方針の探索度合いを適切にコントロールする必要があります。
数学やコンピューターサイエンス分野の探索問題においてはGoogle DeepMindによってAlphaEvolve [1] という手法が提案されました。 AlphaEvolveは近年性能が大幅に向上しているLLMと進化的アルゴリズムを組み合わせた手法であり、様々な探索問題において成果を残しています。 一方で、材料科学のようにドメイン知識が重要な専門領域においては、その有効性の検証が十分ではありません。
そこで本研究では、AlphaEvolve の考え方に基づく進化的探索エージェントを開発し、材料科学の探索課題に適用しました。その結果、本アプローチの有効性を検証することができました。
方法
進化的探索エージェントについて
本研究で扱う進化的探索エージェントやAlphaEvolveは、LLMがプログラムを生成し、それを評価・選択しながら進化を重ねて、プログラムを改善していく仕組みです。大規模言語モデルの生成能力を活かして多様な方法を試し、評価に基づいて良いものを残すことで、時間とともにより優れたアルゴリズムに進化します。この考え方は、生物進化を模倣したもので、オープンエンド探索問題の広大な探索空間に対して効率よく良解を見つけるのに有効です。
進化サイクル
新たなプログラムが生成されるサイクルはFigure 1のように表されます。
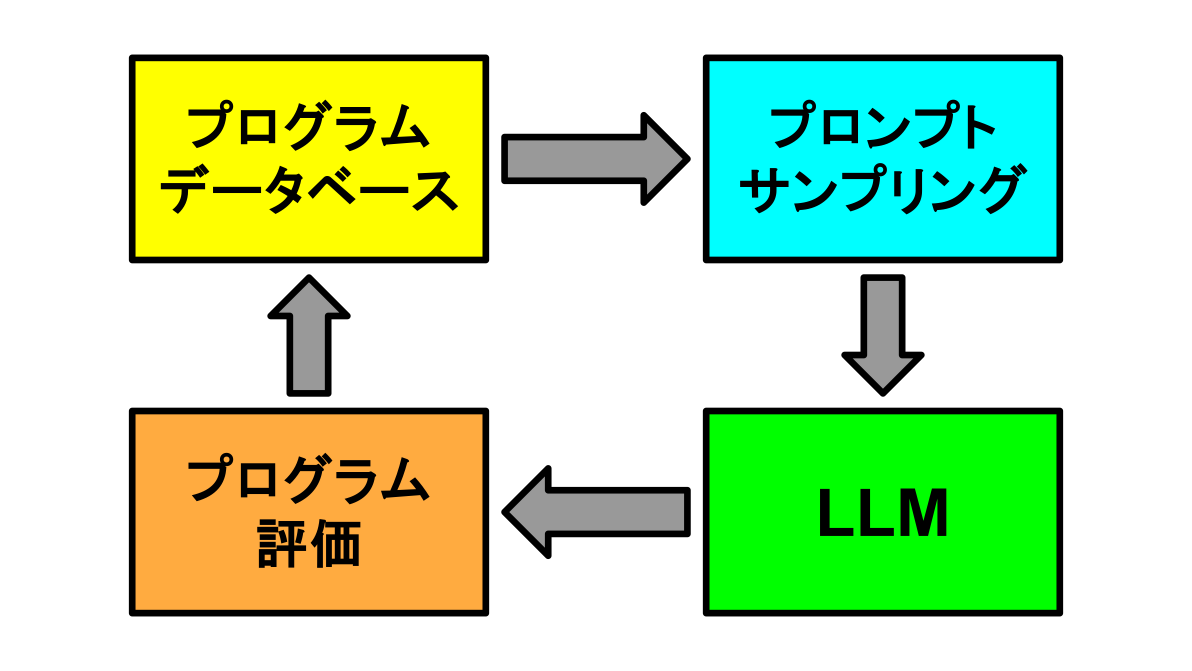
Figure 1: 新たなプログラムを生成するサイクル
- 生成されたプログラムの集合であるデータベースから進化のベースとなるプログラム (以下、ベースプログラム)を性能や成熟度を基にサンプリング
- 同様にデータベースからインスピレーションとなるプログラムをサンプリングし、ベースプログラムとともにプロンプトに埋め込み、LLMへ入力する
- LLMは変更箇所を出力し、新たなプログラムを生成する
- 生成されたプログラムは問題ごとに定義する評価関数によってその性能を評価され、データベースに追加される
インスピレーションプログラムのサンプリングでは、プログラムのコード長とコードのembeddingを元に管理するMAP-Elites algorithm [2] によって同じようなプログラムでもより性能の良いプログラムをサンプリングします。また、LLMへ入力するプロンプトにはサンプリングされたプログラム以外にもベースプログラムの性能や改善のプラン、目標とする改善の度合いなど多様な情報を埋め込んでいます。
Island-based population modelsによる進化
本研究ではデータベースにおけるプログラムの管理方法としてAlphaEvolveでのアイデアを基にIsland-based population models (以下、Island Model)を用いました。 Island Modelは全体のプログラムを複数の集合 (島)に分割してそれぞれ独立で進化させる方法であり、多様なプログラムが生成されやすいというメリットがあります。 さらには非同期的な並列処理にも適しており、効率的な進化プロセスを可能にします。 また、Island Modelは定期的に島間でプログラムの移住を行い、優秀なプログラムの共有や方針が異なるプログラム同士の交差を可能にします。
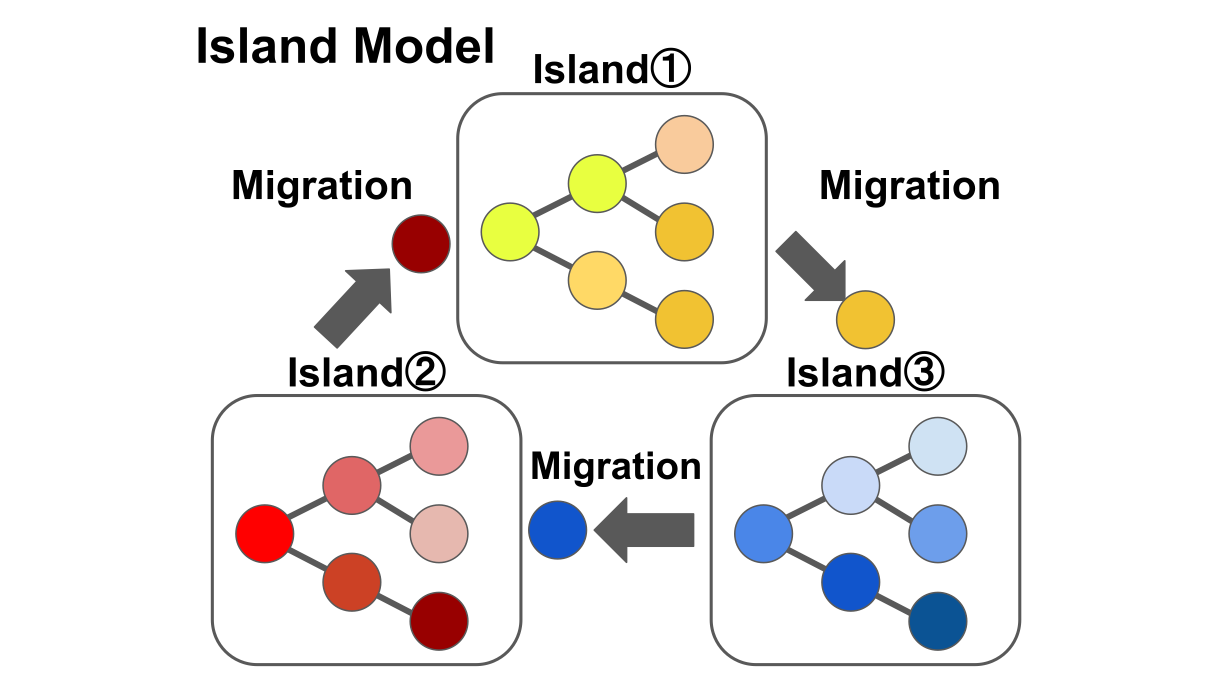
Figure 2: Island-based population modelsの概要
ベースプログラムの選択
AlphaEvolveやFunSearch [3]、 AB-MCTS [4] などの先行研究ではプログラムのサンプリング方法に着目しています。本研究ではそれらの研究と同様に、プログラムの多様さと高性能さを両方向上させるプログラムのサンプリングを目指しました。
まず、進化初期におけるプログラムの作成方法について、出力形式を満たすが性能が低い簡単なプログラムをベースプログラムとして用いると、プログラムの性能が向上するまで多くの探索を必要とするだけでなく、生成されるプログラムの多様性も低いことが分かりました。
そこで、本研究では進化プロセスを開始する前にLLMを用いて問題から考えうる方針とそれに関連する情報 (以下、初期方針)を生成し、進化プロセス初期にはランダムにサンプルした初期方針と出力形式のみ指定された空の関数からベースプログラムを生成しました。このことにより、強制的にプログラムの多様性を作ることが可能なだけでなく、LLMによるプログラムの実装精度も向上することが分かりました。
また、生成したプログラムのデータベースからベースプログラムをサンプリングする際には以下の2種類のサンプリング法を確率的に選択することによって多様性と性能のバランスを操作できるようにしました。
- Performance-based sampling
- 高い性能を持つプログラムを優先的にサンプリングする
- Family tree-based sampling
- 初期プログラムからの世代数が少ない、またはそのプログラムから生成されたプログラムの数が少ないプログラムを優先的にサンプリングする
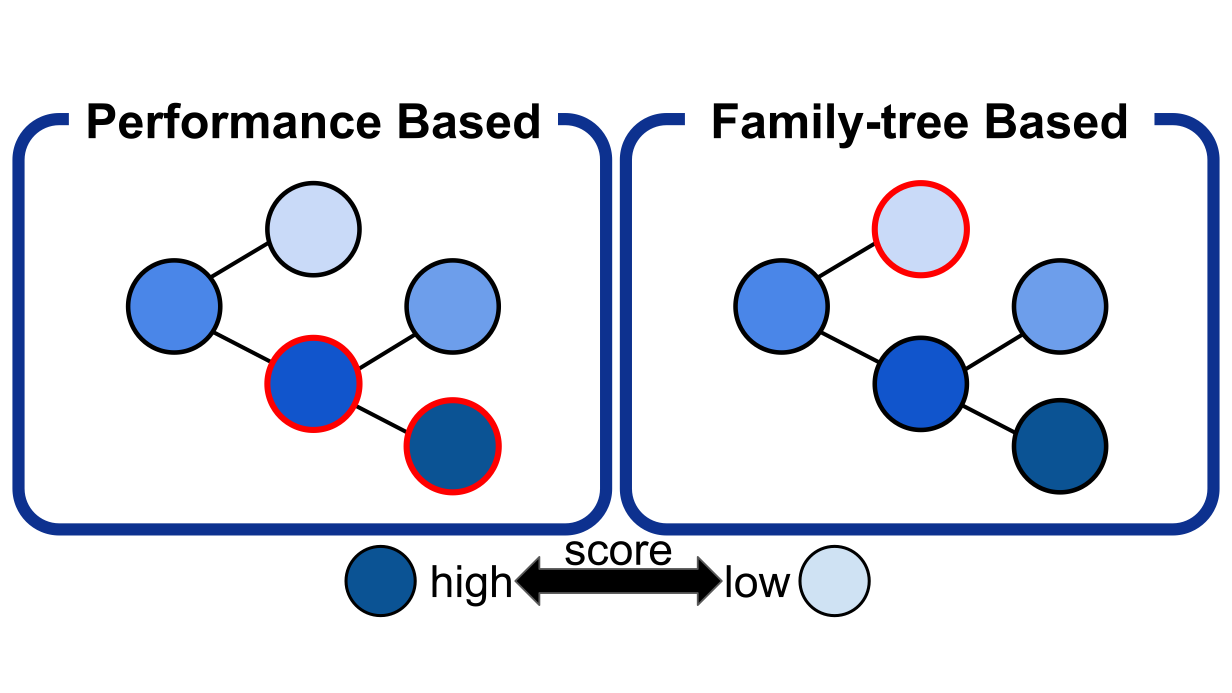
Figure 3: ベースプログラム選択アルゴリズムの比較、各円はプログラムを表し、赤枠で囲われている円は優先して選択されることを表す
プログラムの評価プロセス
生成されたプログラムは実行結果をもとに評価が行われます。 解を評価する際、例えば第一原理計算を行い物性値を求めるような場合に、毎回のプログラムを実行し、解を検証していると評価に多くの時間が必要になり、非効率になる可能性があります。そこで本研究では評価プロセスにおいて以下のような段階的評価を行いました。
- 1段階目
- 出力された解が問題の条件を満たしているかを評価
- 大規模な計算を必要とする問題の場合には簡単な計算で大まかな性能を評価
- 問題の条件を満たしていない場合や性能が閾値に満たない場合には2段階目に進まず、最低スコア(多くの問題の場合0)をつけて評価を終了
- 2段階目
- 実際に問題の評価関数を用いてスコアをつける
結果
AlphaEvolveなどで検証されていた数学的な問題や材料科学領域における問題について、本研究で開発した進化的探索エージェントを用いた検証を行いました。
それぞれの問題では、ユーザーである人間が以下の要素を定義する必要があります。
- 問題文を含むシステムプロンプト
- 生成プログラムの要件
- 入出力の形式
- 最大実行時間
- プログラム評価関数
- 最大化するスコア
- 出力に要求される条件
サークルパッキング
まず簡単なベンチマークとしてAlphaEvolveの研究内で検証が行われていた1×1の大きさの正方形に26個の任意の径の円を充填するアルゴリズムを探索するサークルパッキング問題について進化的探索エージェントを適用します。
この問題では円充填アルゴリズムを最適化対象とし、出力される配置の円の半径の合計値を最大化することを目指します。
まず初めに、初期方針を作成することによる効果を測るため、以下の条件で50回の探索を5回試行し、比較を行いました。
- 初期方針を作成する場合
- 最初に初期方針を複数生成し、各Islandの最初の4回の探索について、「空の出力関数」+「初期方針」からプログラムを生成。
- 初期方針を作成しない場合
- 始めに「空の出力関数」からプログラムを生成。
Figure 4に示した結果より、初期方針を作成することによってより早い段階から性能の良いプログラムを作成することが分かります。さらには、初期方針を作成しなかった場合において、ある程度進化が進んでも非常に性能の良い (半径の合計値が〜2.6になるような)プログラムを生成できていないことが分かります。以上のことから、初期プログラムが後のプログラムに与える影響の大きさが分かります。
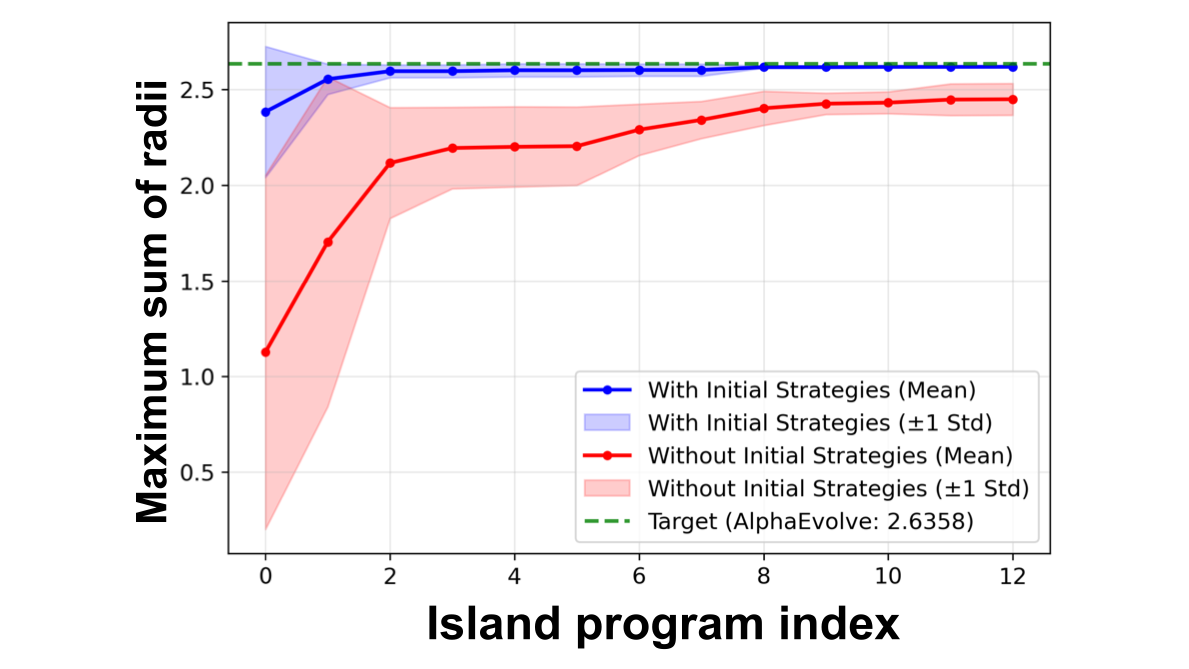
Figure 4: 初期方針を作成した場合 (青色)と初期方針を作成しなかった場合 (赤色)におけるIslandごとのプログラム生成回数に対する全体最大値の推移 (5回試行)、Island数: 4
またFigure 5に示したように、165回の探索を行った結果からAlphaEvolveで発見された最高性能のプログラム (半径の合計値: 2.6358)を超えるような配置が生成可能なプログラムを得ることができました。AlphaEvolveの詳細な実験条件は公開されていませんが、我々の円の重なり判定のアルゴリズムでは誤差を10-6まで許容しており、実際に想定される半径の合計値の誤差は10-5から10-6程度です。したがって、この配置はAlphaEvolveを上回る良い配置であると考えられます。また、AlphaEvolveのオープンソース実装であるOpenEvolve (https://github.com/codelion/openevolve) の結果と比較すると最良の結果を得るまでに必要とした探索回数を大幅に減らすことができていると分かります。
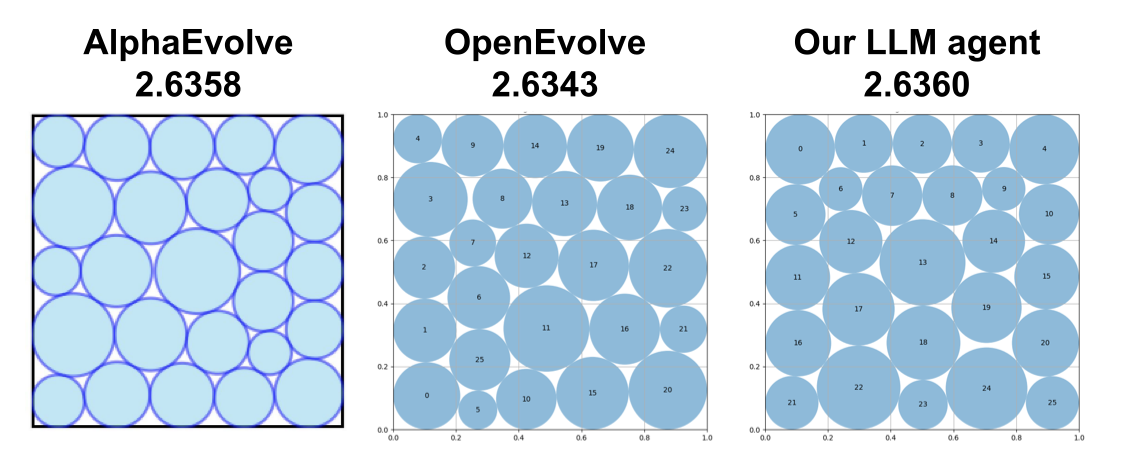
Figure 5: サークルパッキング問題に対するAlphaEvolve, OpenEvolve, 本研究の進化的探索エージェントの半径の合計値が最大になった配置の比較、OpenEvolveは460回の探索による結果、我々の進化的探索エージェントは165回の探索による結果
3次元原子配置の最適化アルゴリズム
Lennard-Jonesポテンシャルを用いたポテンシャルエネルギーが最小になる三次元空間上の原子配置最適化アルゴリズムを探索する問題について進化的探索エージェントを適用します。 この問題は2023年度PFN夏季インターンで実際に出題されたテーマ別課題です。
問題の詳細
https://github.com/pfnet/intern-coding-tasks/blob/main/2023/ThematicTask/theme13/JE13_task.ipynb
この問題では、安定な原子配置を探索するアルゴリズムを最適化対象とし、出力される三次元構造のエネルギーを最小にすることを目指します。
本研究の進化的探索エージェントによって300回の探索を行った結果をFigure 6に示します。参考として、同様のプロンプトを入力し、生成したGPT-5-thinking (2025/09/22時点)によるプログラムの実行結果 (-252.5 ± 6.7 a.u.、5回試行)を示します。
結果を比較すると、進化的探索エージェントはどのIslandも2回程度の探索によってGPT-5-thinkingのプログラムと同程度の性能を持つプログラムを生成することができています。また、探索回数が増えるごとにプログラムを改善していき、最終的にはGPT-5-thinkingよりさらに30 a.u.ほどエネルギーが小さな配置を見つけることができる探索アルゴリズムを生成することができています。この結果は人間が計算科学や最適化の知識を用いてプログラムを作成した時の典型的な結果 (Human’s typical)を大きく上回っています。
さらには、生成されたプログラムの最適化戦略を分析すると、basin-hoppingやsimulated annealingをはじめとして様々なアプローチの手法が見られ、プログラムの多様化についても成功していることが分かりました。この傾向は最適な戦略が未知であるような問題に対しても、エージェントが効果的に探索できる可能性を示していると考えられます。
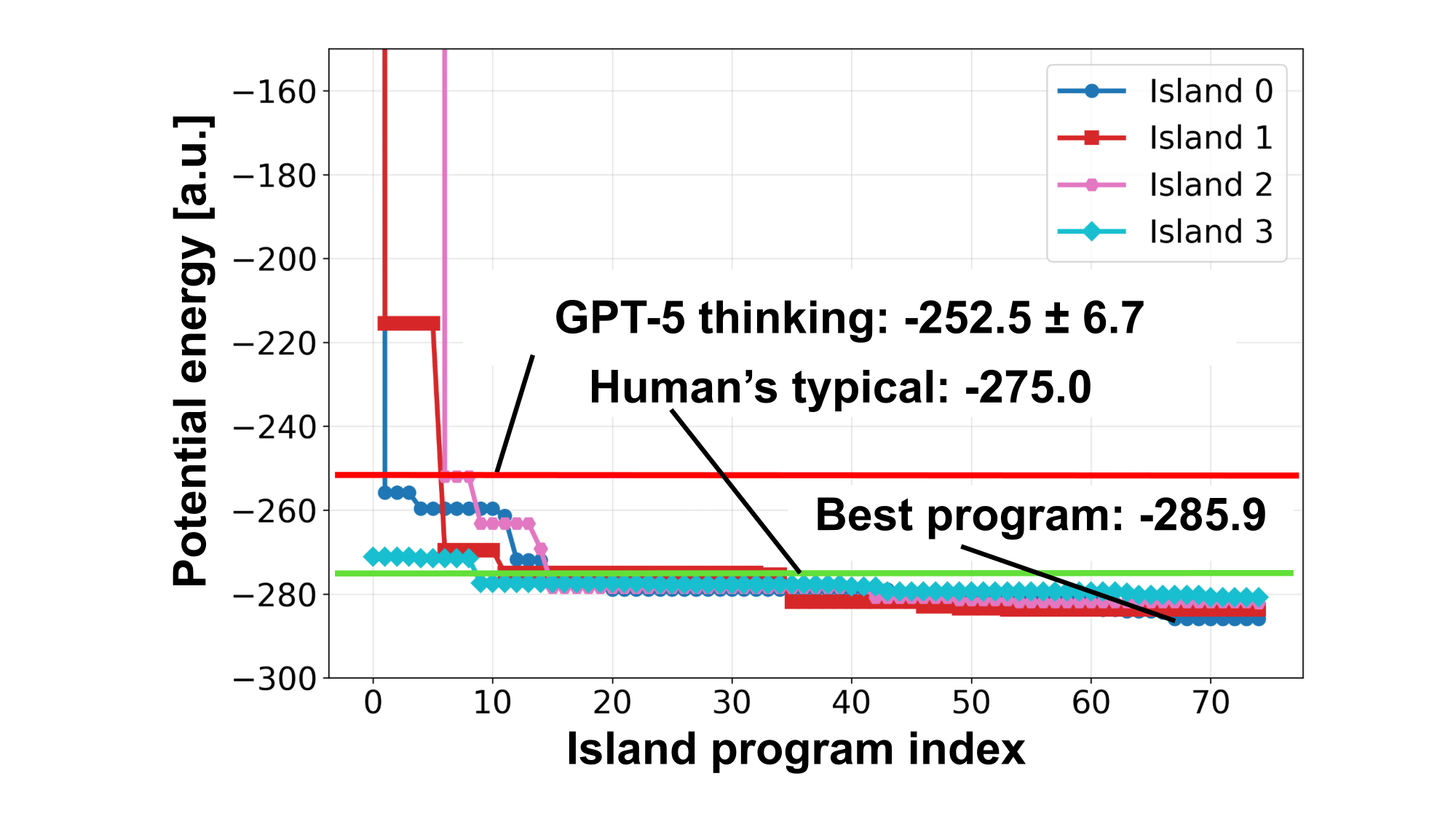
Figure 6: 各島のプログラム生成回数に対するプログラムによって生成された構造のポテンシャルエネルギー、赤線: GPT-5-thinkingによる結果、緑線: 人間による典型的な結果
MDシミュレーションにおける液体平衡化スケジュールの最適化
次に、材料科学領域における最適化問題について考えます。 液体のシミュレーションでは、自然な液体構造を作成するために、以下のような手順が前処理として行われます。
- 分子のパッキング
- エネルギー最小化
- 平衡化
- 本番シミュレーション
この中でも平衡化は分子の詰まった系を実際の液体の挙動に近づけるために重要です。 そして、この平衡化は温度、気圧、ステップ数を指定した複数のMDシミュレーション (平衡化スケジュール) に沿って行われますが、このスケジュールについての明確な最良の方法は定まっていません。
以上の背景を踏まえ、本研究では平衡化スケジュールの最適化を対象とし、特にベンゼン液体における平衡化ステップ数の最小化を目指します。さらに、高分子系で一般的に用いられる平衡化スケジュール5, 6を比較対象とし、両者の違いを検討します。一般に、高分子に比べてベンゼンでは必要な平衡化ステップが少なくて済むと予想されます。
検証では200回の探索を行いました。Figure 7に示した各島のプログラム生成回数に対する生成されたスケジュールの総ステップ数から、探索の初期では白抜きの平衡化に失敗するスケジュールが多く生成されたのに対して、探索が進むにつれ平衡化に成功しているスケジュールが増えていることが分かります。
また、Figure 8から、温度を変化させたNVTと気圧を変化させたNPTを繰り返しながら平衡化を目指す典型的なスケジュールに対して、今回生成されたスケジュールは最初にNVTを行った後に温度と気圧を同時に変化させることによって半分以下のステップ数で効率的に平衡化を行うことができていると分かります。
本研究では着手していませんが、進化的探索エージェントの枠組みではスケジュールだけではなくそれを実行するプログラム自体を進化させることが可能であり、今後さらなる最適化や、多くの分子について適用可能な汎用的かつ効率的な平衡化アルゴリズムの作成も期待できます。
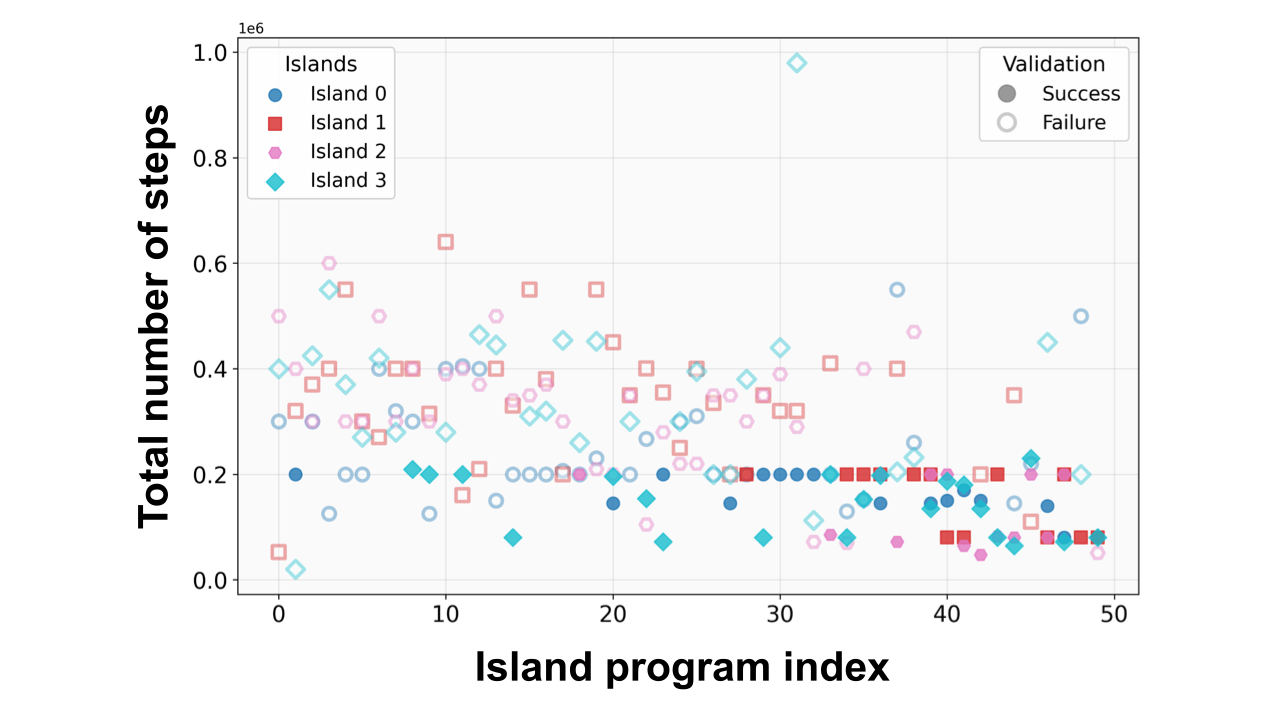
Figure 7. 各島におけるプログラム生成回数と生成スケジュールの総ステップ数の関係、白抜きのマーカーは平衡化に失敗したスケジュールを示す、Island数: 4
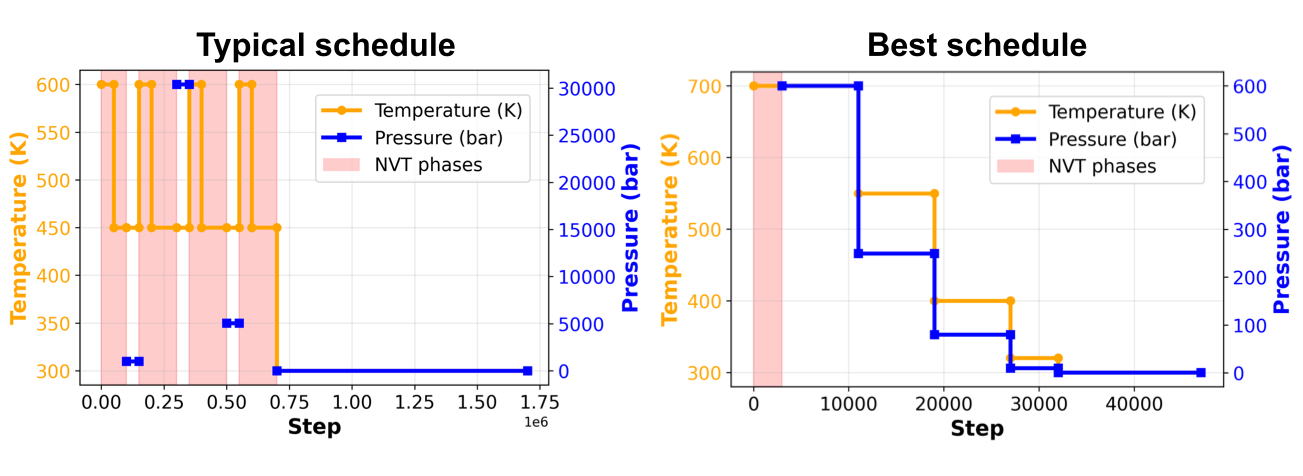
Figure 8. 典型的な平衡化スケジュールと今回の検証で生成された最もステップ数の少ない平衡化スケジュールの比較
まとめ
本研究では、材料科学分野のオープンエンド探索問題に適用することを目的としてAlphaEvolveのアイデアを元にした進化的探索エージェントを実装しました。また、探索の効率と性能の両立や生成されるプログラムの多様性の向上を目的として探索アルゴリズムの改良を行いました。今後の展望としては、さらに複雑な探索問題への適用や文献などの背景知識の取り込みなどの拡張が考えられます。
終わりに
今回のインターンでの活動は多くの方に支えられました。
まず、主メンターとして常に方向性を示し、丁寧に指導してくださった織茂さん、そしてサブメンターとして細やかにサポートしてくださった澤田さんに心から感謝します。また、液体平衡化について貴重な知見を共有してくださった宮崎さんにも深く感謝いたします。
さらに、Chemチームのインターン同期の仲間たちと切磋琢磨できたことは大きな励みになりました。そしてチームのメンバー全員が温かく迎えてくださり、気軽に相談できる雰囲気を作ってくださったことにも感謝しています。
本当にありがとうございました!
References
[1] A. Novikov et al., AlphaEvolve: a coding agent for scientific and algorithmic discovery, arXiv:2506.13131 (2025).
[2] J.-B. Mouret and J. Clune, Illuminating search spaces by mapping elites, arXiv:1504.04909 (2015).
[3] B. Romera-Paredes et al., Mathematical discoveries from program search with large language models, Nature 625, 468–475 (2024).
[4] Y. Inoue et al., Wider or deeper? Scaling LLM inference-time compute with adaptive branching tree search, arXiv:2503.04412 (2025).
[5] D. Hofmann et al., Detailed-atomistic molecular modeling of small molecule diffusion and solution processes in polymeric membrane materials, Macromol. Theory Simul. 9, 293–327 (2000).
[6] N. C. Karayiannis, V. G. Mavrantzas, and D. N. Theodorou, Detailed atomistic simulation of the segmental dynamics and barrier properties of amorphous poly(ethylene terephthalate) and poly(ethylene isophthalate), Macromolecules 37, 2978–2995 (2004).
