Blog
本記事は、2022年夏季インターンシッププログラムで勤務された勝又海さんによる寄稿です。
はじめまして。PFN の2022夏季インターンシップに参加した東京大学の勝又海です。 大学では半教師あり設定における画像生成モデルについて研究しています。
今回のインターンでは「StyleGANを用いた全身画像生成 (Full-body human image generation with StyleGAN)」というテーマで研究を行いましたので、その紹介をいたします。
全身画像生成
従来、StyleGAN[1,2]のような深層生成モデルを用いた条件なしの画像生成では、顔画像データセットであるFFHQを中心に研究が進められてきました。顔以外も含む人体の画像生成は、DeepFashion[3]データセットを利用したキーポイントから画像への画像変換タスクが主に取り組まれてきました[4]。
一方で、潜在変数を用いた画像編集手法(例えばInterFaceGAN[5], SGF[6])を利用できる条件なし画像生成は実用上の大きなポテンシャルを秘めています。今回のインターン期間が始まる2週間前、2022年7月に40,000枚の全身画像からなるデータセットSHHQ 1.0[7]が公開されたため、このデータセットを用いた全身画像生成に取り組むことにしました。
手法
SHHQデータセットが従来のベンチマークデータセットであるFFHQデータセットと異なる点として、全身画像データセットであるSSHQでは姿勢の自由度が高いという点があります。姿勢の自由度が高い場合、顔や手、指といった各パーツの画像上の位置が一定しないためにそれらの詳細がGANの学習において重視されず、十分な生成品質が得られないのではないかと考えました。
そこで、学習過程の序盤の段階において生成される姿勢に正則化をかけることで、各パーツ詳細の学習への寄与を高めるというアイデアのもと、Adaptive truncation trickとManifold learning in generatorという二つの手法を検討しました。
[手法1] Adaptive truncation trick
StyleGANには、正規分布で与える \( z \in Z\) と、\(z\) をmapping network (multi-layer linear perceptron)で変換した \( w \in W\) という2つの潜在変数が現れます。後者の \(w\) を平均値 \(\bar{w}\) へと重み \(\psi\in\mathbb{R}\) だけ近づけるように修正した値 \(w’=(1-\psi) w + \psi\bar{w}\) を画像生成に使用することで、出力の多様性をトレードオフに生成品質を向上させるテクニックはtruncation trick[1,8]として知られています。
Truncation trickは通常推論時に利用するもので、学習時には利用されることはありませんが、今回新たに考案したadaptive truncation trickでは、学習時に各ステップ \(t\) において確率 \(p_t\) でtruncation trickをかけることで生成器の出力の多様性を制限します。\(p_t\) は初期値 \(p_0=0\) とし、以下の式でアップデートします。
\[p_{t+1}=p_t+\frac{1}{500k}\mathrm{sign}\left(\eta\,-\,\mathbb{E}[\mathrm{sign}(D_{\mathrm{fake}})]\right)\]
ここで \(\mathrm{sign}\) は符号関数です。\(D_{\mathrm{fake}}\) は生成データに対する識別器の出力値で、生成データに対して負の値、リアルデータに対して正の値を出力するように学習されていると仮定します。この更新式では、生成データに対する識別器の出力符号の期待値がしきい値 \(\eta\)以下(つまり、識別器が十分に強く生成データを見抜ける)の場合には、truncationを適用する確率を上げることを意味します。
これは、識別器が強くなっているときには生成器が学習しているタスクを簡単にし、生成器が強くなっているときには生成器のタスクを難しくするということを期待しています。生成される姿勢に正則化をかけるため、出力画像の姿勢を主に支配していると考えられる[7]、生成期の最初の8ブロック(低解像度ブロック)に対してこのadaptive truncation trickを適用しました。
しきい値としては \(\eta=-0.7\) を採用しました。\(1/500k\) は \(p_t\) の学習率にあたり、GAN訓練全体のステップ数を元に決定します。
[手法2] Manifold learning in generator
多様体学習では、データ分布の低次元の多様体表現を学習することで、データの非線形圧縮を行います。最近、多様体学習をGANの識別器の中間表現へと適用することで表現能力を制限し、過学習を防ぐというアプローチが発表されました[9]。この手法では、アトムと呼ばれるk個のベクトルからなるコードブックを用意し、各観測データ(中間表現の多チャンネルピクセル値)に対して、近傍アトムの重み付き和によって精度良く近似できるようにアトムを反復的に最適化します。
アトムの近傍点ネットワークで表現される多様体は典型的なデータ分布を表現していると考えられるので、この多様体からの距離が大きい点は、非典型的な特徴を持っていると考えられます。識別器の中間表現をピクセルごとにこの多様体上へと射影することで、主要な情報は失わずに表現力を制限するというのがこの手法の基本的な考え方です。
今回のインターンでは、生成される姿勢の正則化のためにこのアイデアを生成器へと応用することを試みました。
生成器の各ブロック\(l\)において、ブロックの出力である特徴量 \(\tilde{X}_l\) と コードブックを用いたエンコーディング \(h_l(\tilde{X}_l)\) の補間 \( X_{l+1}=(1-\beta)\tilde{X}_l + \beta h_l(\tilde{X}_l)\) を取ることで正則化を行います。
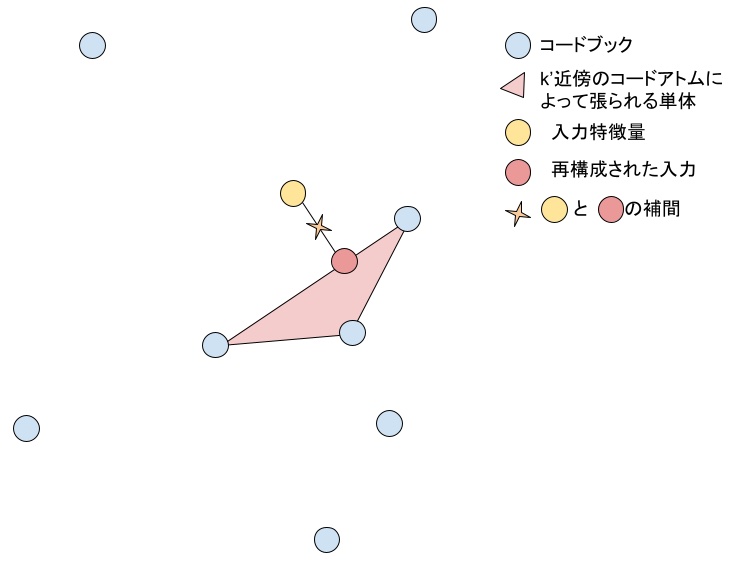
エンコーディング \(h_l\) にはLocality-constrained Soft Assignment (LCSA)と呼ばれるアルゴリズムを用います。LCSAは \(k\) 個の ベクトルからなるコードブック \(M\) を用いて入力特徴量 \(\tilde{X}_l\) の近似を行います。コードブックの各ベクトルは入力される \(\tilde{X}_l\) が構成する空間の代表点として空間内の任意の点を精度良く近似できるよう配置されます。LCSAにおいてエンコーディング \(h_l\) はsoft assignment \(a \in \mathbb{R}^k\) を用いて
\[h_l(x) = Ma(x; M)\]
として定義されます。\(a\) は \(x\) と \(M\) の各ベクトルの距離を用いた温度付きソフトマックスで、\(x\)の\(k’\)近傍\((k’ \leq k)\)のみを用いて計算します。
\[a(x; M) = S(\|x-m_1\|_2, …, \|x-m_k\|_2)\]
\(S\) の \(j\) 番目の要素は
\[S(d_1, …, d_k)_j = \frac{\mathrm{knn}(x; M, k’, j)\exp(-d_j^2/2\sigma^2)}{\sum_i \mathrm{knn}(x; M, k’, i)\exp(-d_i^2/2\sigma^2)}\]
とし、ここで\(\mathrm{knn}(x; M, k’, i)\) は \(i\) 番目のコードが \(x\) の \(M\) における \(k’\) 近傍内に含まれていれば1、含まれていなければ0を返す関数とします。LCSAは以下の図のようにコードブックから入力特徴量 \(\tilde{X}_l\) の \(k’\) 近傍を選択し、その近傍によって張られる単体を用いて\(\tilde{X}_l\)の近似を行います。
実験設定
ベースのアーキテクチャをStyleGAN v2 [2]としてそれぞれの手法で、のべ2500万枚の画像を用いた学習を行います。
実験設定1: 生成品質評価
定量的な生成品質の評価として生成画像と学習画像間のFIDを用いて評価を行います。
実験設定2: 生成姿勢評価
全身画像生成の課題としてデータセット中の姿勢の多様性が高いことが挙げられます。そこで生成品質の評価に加えて、実データに近い姿勢を生成できるかを評価するためにOpenPose[10]によって推定された姿勢の分布を比較を行います。OpenPoseでは18キーポイントの座標を推定します。
結果
実験設定1: 生成品質評価
下表にStyleGAN v2、[手法1] Adaptive truncation trick、[手法2] Manifold learning in generatorを学習したときのFIDを示します。
| FID↓ | |
| StyleGAN v2 | 3.19 |
| Adaptive truncation trick | 3.43 |
| Manifold learning in generator | 4.00 |
FIDを用いた定量評価では今回実装した手法1,2ともに既存のStyleGAN v2を上回ることはできませんでした。
実験設定2: 生成姿勢評価
続いて生成姿勢の評価を行います。下図に各キーポイントの学習データの分布(青線)と各手法による生成データの分布(黄線)の等高線を示します。19個あるキーポイントのうち、8つのキーポイントの分布を示しました。
StyleGAN v2

Adaptive truncation trick

Manifold learning in generator

StyleGANでは生成される姿勢の分布の裾が狭くなり、生成できていない範囲が多く見られますが、Adaptive Truncation TrickやManifold learningではStyleGANと比較して学習データに忠実な姿勢を生成できていました。とりわけManifold learningでは峰と裾の等高線どちらも学習データにほぼ一致しています。
アプリケーション: Manifold learningを用いたArtifact removal
生成品質姿勢の評価を行う過程で、Manifold learningの手法で学習した多様体を、生成画像からアーティファクトを除去するために利用できることを発見しました。
アーティファクトとは、身体のパーツが欠けていたり不自然に伸びたり溶けている、画像として破綻しているといった生成画像に問題が生じている部位のことですが、これらは画像生成過程で特徴量が何らかの非典型的な値を取ってしまっていることが一つの要因となっていると推測されます。
従って、問題が生じている部分の特徴量を典型的な値=多様体上の点へと近づけることで、アーティファクトが除去できるのではないかというアイデアです。直観的には、特定のピクセルのみにtruncation trickを適用するというような考え方となります。
以下のその実例を示します。Artifactの存在するInitial画像とArtifact removalを適用する範囲を示すMask、適用する強さが異なるArtifact removalを適用したModified画像を示します。



1つ目の例では削れていた帽子が復元できており、2つ目の例では服の裾の長さを揃えることができています。3つ目の例についてもズボンの長さを揃えることができました。
上記の例ではLCSAで選択された近傍のコードアトムを用いてArtifact removalを行いました。次の例ではLCSAで選ばれた近傍ではなく、人が選択したコードアトムを用いたArtifact removalを示します。1枚目がLCSAを用いた例と2枚目が選ばれたコードアトムを用いた例となります。


LCSAで選ばれた近傍の場合には腕のオクルージョンが解消されていませんでしたが、注意深くコードアトムを選択することでオクルージョンを解消することができました。こうした適切なアトム選択の自動化など、学習された多様体の活用方法については今後さらに深掘りする研究が期待できます。
まとめ
本インターンではStyleGANを用いた全身画像生成に取り組みました。実装した2手法(Adaptive truncation trick、Manifold learning in generator)はFIDという生成品質の定量的評価ではベースラインに対しては優位性を示すことはできませんでしたが、OpenPoseを用いた生成姿勢の定量的評価ではベースラインよりも学習データに忠実な姿勢を生成できていました。また、Manifold learningを用いることで中間特徴量において各ピクセルのベクトルを代表的な(典型的な)ベクトルに近づけることでArtifact removalを実現することができました。
参考文献
- Tero Karras, Samuli Laine, Timo Aila. A style-based generator architecture for generative adversarial networks. CVPR 2019.
- Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, Timo Aila. Analyzing and Improving the Image Quality of StyleGAN. CVPR 2020.
- Ziwei Liu, Ping Luo, Shi Qiu, Xiaogang Wang, Xiaoou Tang. DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations. CVPR 2016.
- Xingran Zhou, Bo Zhang, Ting Zhang, Pan Zhang, Jianmin Bao, Dong Chen, Zhongfei Zhang, Fang Wen. CoCosNet v2: Full-Resolution Correspondence Learning for Image Translation. CVPR 2021.
- Yujun Shen, Ceyuan Yang, Xiaoou Tang, Bolei Zhou. Interfacegan: Interpreting the disentangled face representation learned by gans. TPAMI 2020.
- Minjun Li, Yanghua Jin, Huachun Zhu. Surrogate Gradient Field for Latent Space Manipulation. CVPR 2021.
- Jianglin Fu, Shikai Li, Yuming Jiang, Kwan-Yee Lin, Chen Qian, Chen Change Loy, Wayne Wu, Ziwei L iu. StyleGAN-Human: A Data-Centric Odyssey of Human Generation. ECCV 2022.
- Andrew Brock, Jeff Donahue, Karen Simonyan. Large Scale GAN Training for High Fidelity Natural Image Synthesis. ICLR 2019.
- Yao Ni, Piotr Koniusz, Richard Hartley, Richard Nock. Manifold Learning Benefits GANs, CVPR 2022.
- Zhe Cao, Ginés Hidalgo Martinez, Tomas Simon, Shih-En Wei, Yaser Sheikh. OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. TPAMI 2019.