Blog
本記事は、2019年インターンシップとして勤務した森 雄人さんによる寄稿です。
概要
2019年PFN夏季インターンに参加していた森 雄人です. 本インターンでは高次元空間中のベイズ最適化問題について, 実装・研究していました. 特にREMBO [1] [2] やLINEBO [3] を用いた最適化を行うことで, どのようにアルゴリズムの振る舞いが異なるかを数値的に検証していました.
ブラックボックス最適化
本稿ではブラックボックス最適化問題, 特に最小化問題について考えます. 変数を\(\lambda\), 目的関数を\(L(\lambda)\)と書き, 探索空間を\(\Lambda \subset \mathbb{R}^{D}\)と書くことにします. ここで「ブラックボックス」とは, 最小化したい目的関数\(L(\lambda)\)にまつわる情報が手に入らないという想定を指します. すなわち, 自分である入力\(\lambda\)を選び, その出力\(L(\lambda)\)を得ることはできるけれども, \(L(\lambda)\)の勾配\(\nabla L(\lambda)\)などの情報は手に入れることができない, という最小化問題を扱います. このような状況では勾配法に基づく最適化アルゴリズムを用いることができないため, 異なる手法を適用する必要があります.
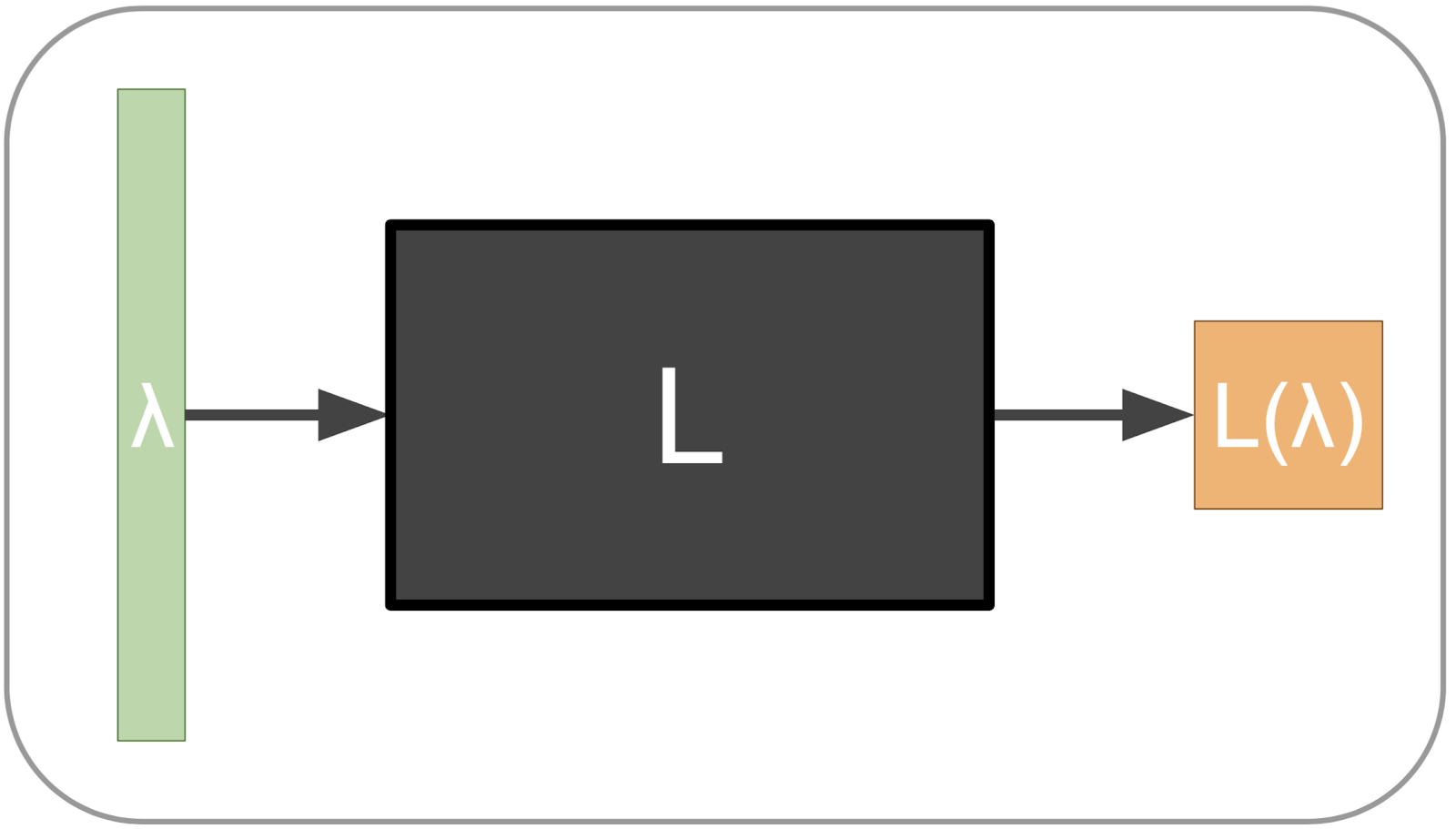
ブラックボックス最適化が必要となる代表的なシーンとしては「ハイパーパラメータ最適化」があります. 例えばSupport Vector Machine (SVM)の訓練時において, validationデータに対する損失を, SVMの最適化問題に現れる正則化項係数\(C\)や, カーネルのスケールパラメータ\(\gamma\)の関数として捉えてみましょう. するとこれはvalidationに対する損失を目的関数とした\(C, \gamma\)についてのブラックボックス最適化問題になります. 通常ハイパーパラメータ探索はランダムサーチやグリッドサーチが用いられますが, 近年次に示すベイズ最適化などのアプローチが注目されてきています.
ベイズ最適化 (Bayesian Optimization)
ベイズ最適化とは不確かさを用いながら次に探索すべき点を決定するブラックボックス最適化アルゴリズムです. 具体的なアルゴリズムとしては次のようになります.

キーとなるステップは非常に単純です.
- 今まで調べた点を用いて真の関数\(L(\lambda)\)を近似する関数\(a(\lambda)\)を作る
- \(a(\lambda)\)を最小化する点\(\hat{\lambda}\)を求める
- \(L(\hat{\lambda})\)を求め, 調べた点のリストに追加する
真の関数\(L(\lambda)\)を近似した関数\(a(\lambda)\)を獲得関数 (acquisition function) と言います. この獲得関数の構成に確率過程, 特にガウス過程を用いる手法がベイズ最適化と呼ばれます.
次に示す図は\(a(\lambda)\)としてLower Confidence Bound (LCB) を用いた図です. 今までチェックした点から, 探索できていない領域の不確かさをも含めて関数を近似し, 次に探索すべき点を探す流れを表しています.
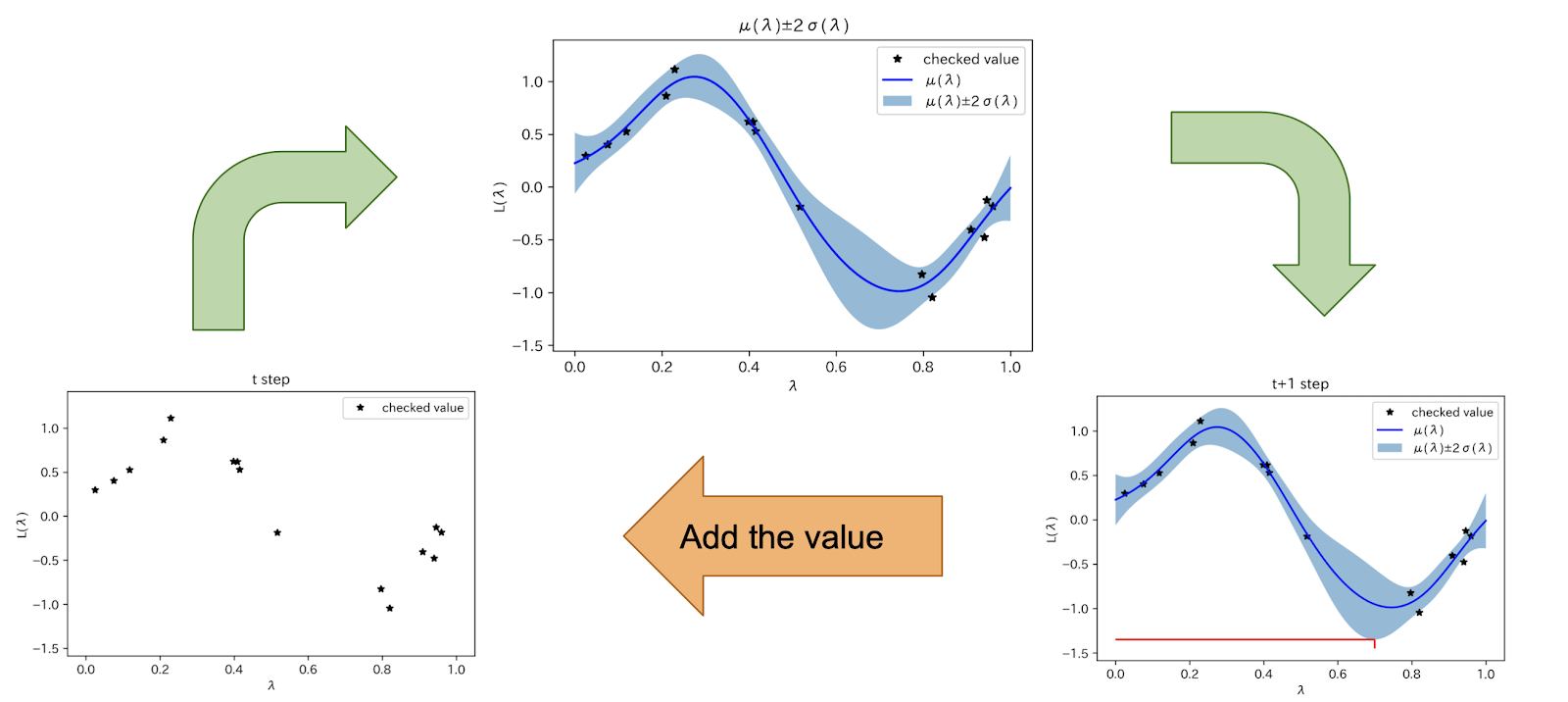
ベイズ最適化は一般に, 20次元以上ほどの高次元空間では局所解に陥ってしまったり, 獲得関数の最小化がうまくいかないなどの理由で, 度々うまく動かないことがあります. そこで高次元空間中のベイズ最適化問題が研究されてきています.
REMBO
Random EMbedding Bayesian Optimization (REMBO) [1] [2] は, ランダム行列を用いて低次元空間を高次元空間に埋め込むことで, 高次元空間を陽に扱わずにベイズ最適化を行う手法です. この手法は真の関数\(L(\lambda)\)に
$$ L(\lambda_{\top} \oplus \lambda_{\perp}) = L(\lambda_{\top} \oplus 0) $$
という「縮退した線形空間があって, ある方向に動かしても\(L(\lambda)\)の値が変わらない」性質がある場合に効果を発揮します. これは\(\lambda\)の中に冗長なパラメータがある場合や, \(L(\lambda)\)に寄与しないノイズのような次元があるときに対応しています.
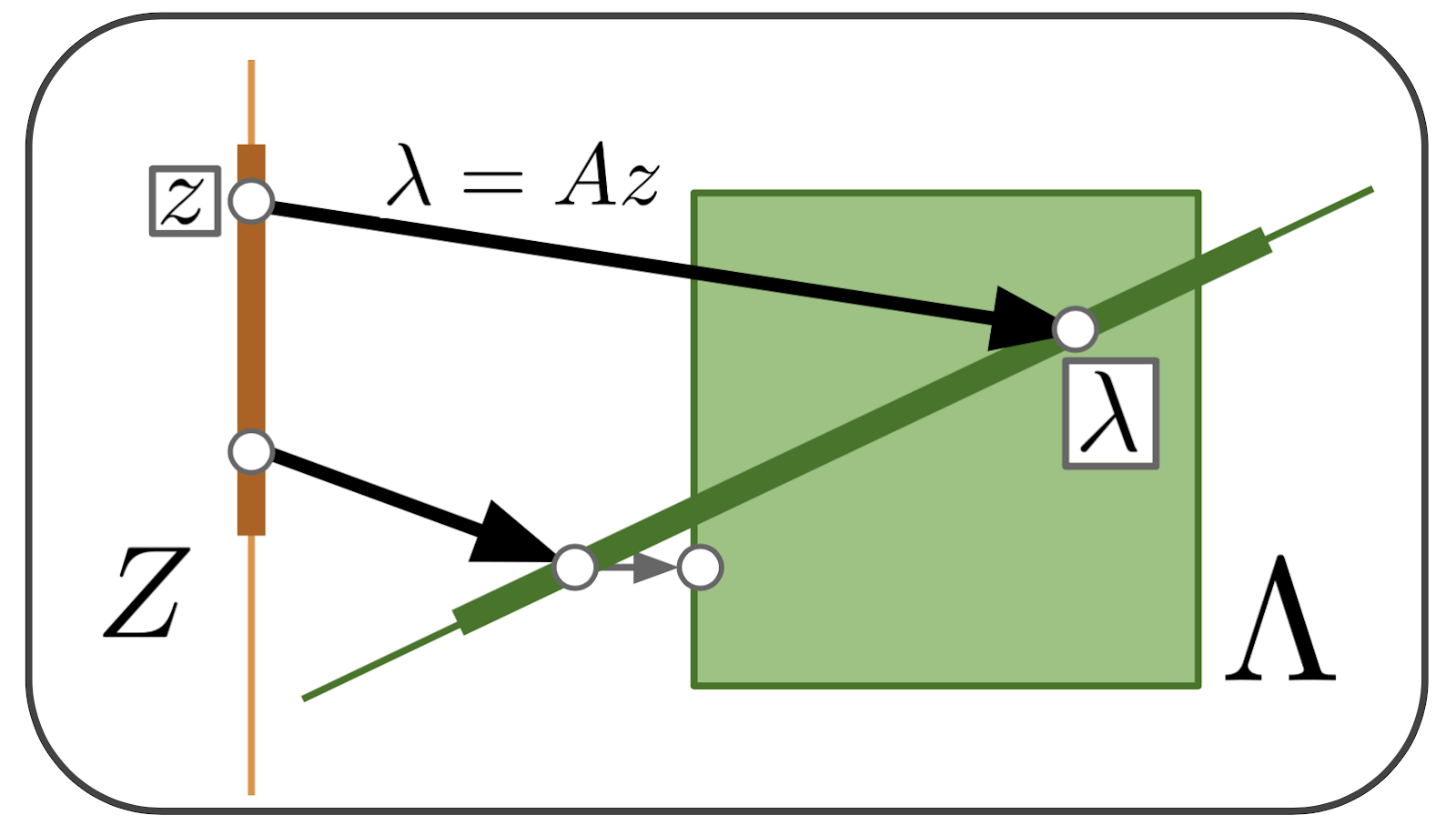
アルゴリズムとしては直接, 高次元空間\(\Lambda\)を扱うのではなく, 低次元空間\(Z \subset \mathbb{R}^{d}\)上でガウス過程を構成し, この空間内で最適化を行います. このとき\(z \in Z\)に対し, 各成分が独立な正規分布\(\mathcal{N}(0, 1)\)に従うランダム行列\(A \in \mathbb{R}^{D \times d}\)を用いて\(L(Az)\)を求めることで真の関数の評価を得ます. なお, 埋め込んだ\(\lambda = Az\)が現在考えている探索空間\(\Lambda\)の外に出てしまっている場合は探索空間上に射影を行います.
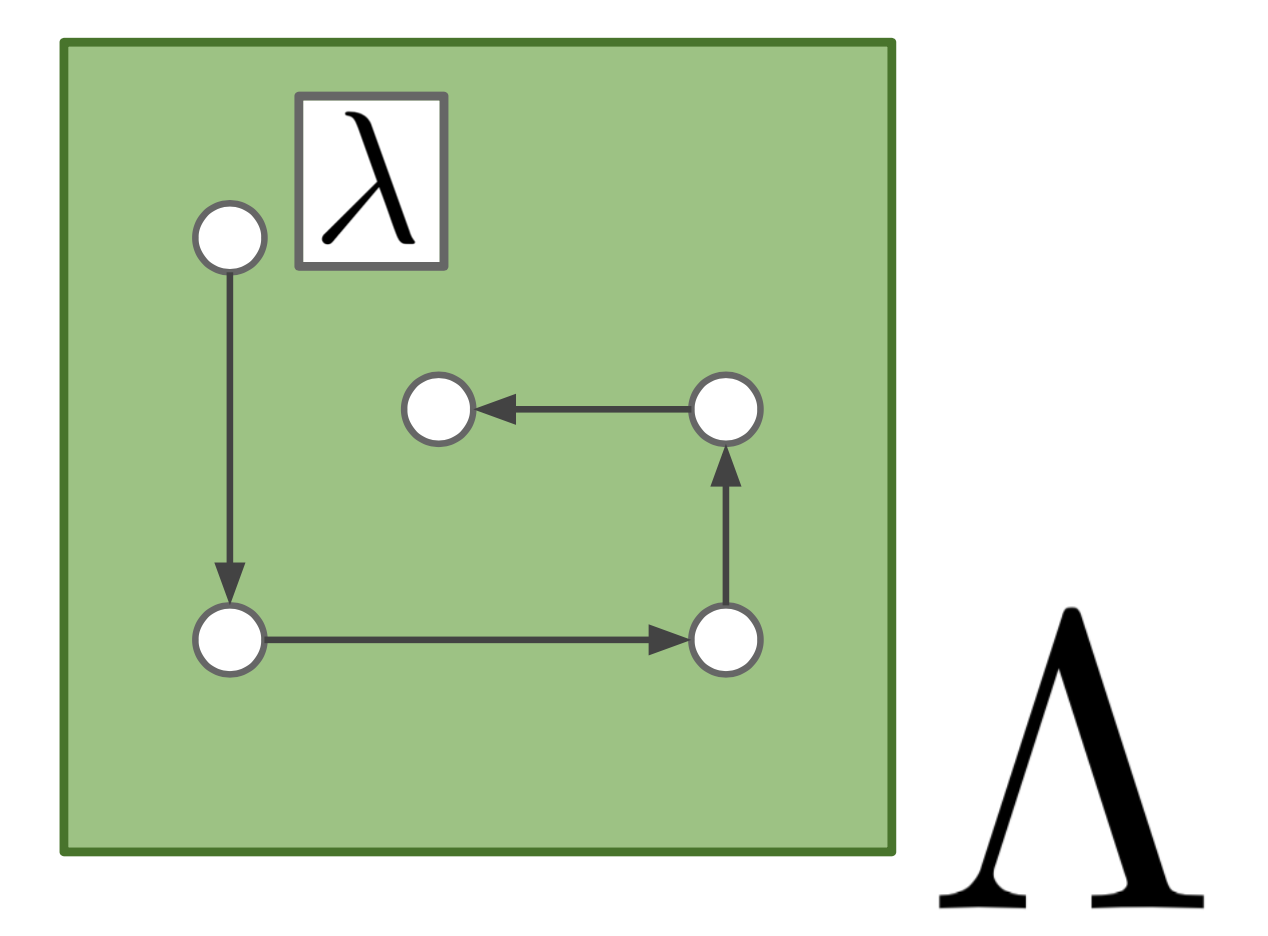
LINEBO
Line Bayesian Optimization (LINEBO) [3] は獲得関数の最小化を1次元空間に制限した上で行う手法です. 探索空間を1次元空間に制限する方法はいくつか考えられますが, \(\lambda\)を座標降下させる方法, または\(– \nabla a(\lambda)\)の方向に下る方法が比較的優位であることが数値的に示されています.
実験・観察
本稿ではテスト関数\(L(\lambda)\)としてSTYBLINSKI-TANG関数を用います. これはブラックボックス最適化のベンチマークとして使われる標準的な関数の一つで, 入力の次元数\(D\)を柔軟に設定することができます. 今回はベイズ最適化にとって比較的高次元とされる次元数である25に設定し, 探索空間\(\Lambda\)は通常用いられる\([-5.0, 5.0]^{25}\)としています.
実装としてはGPyTorch [4] をベースにしたベイズ最適化ライブラリBoTorchを用いています. GPyTorch・BoTorchを用いることの利点として, 従来ベイズ最適化の計算量のボトルネックであった「ガウス過程の予測」の段階における高速化が挙げられます.
さて, 次に示すのはアルゴリズムごとに各ステップにおける評価値\(L(\lambda)\)をプロットした図です.
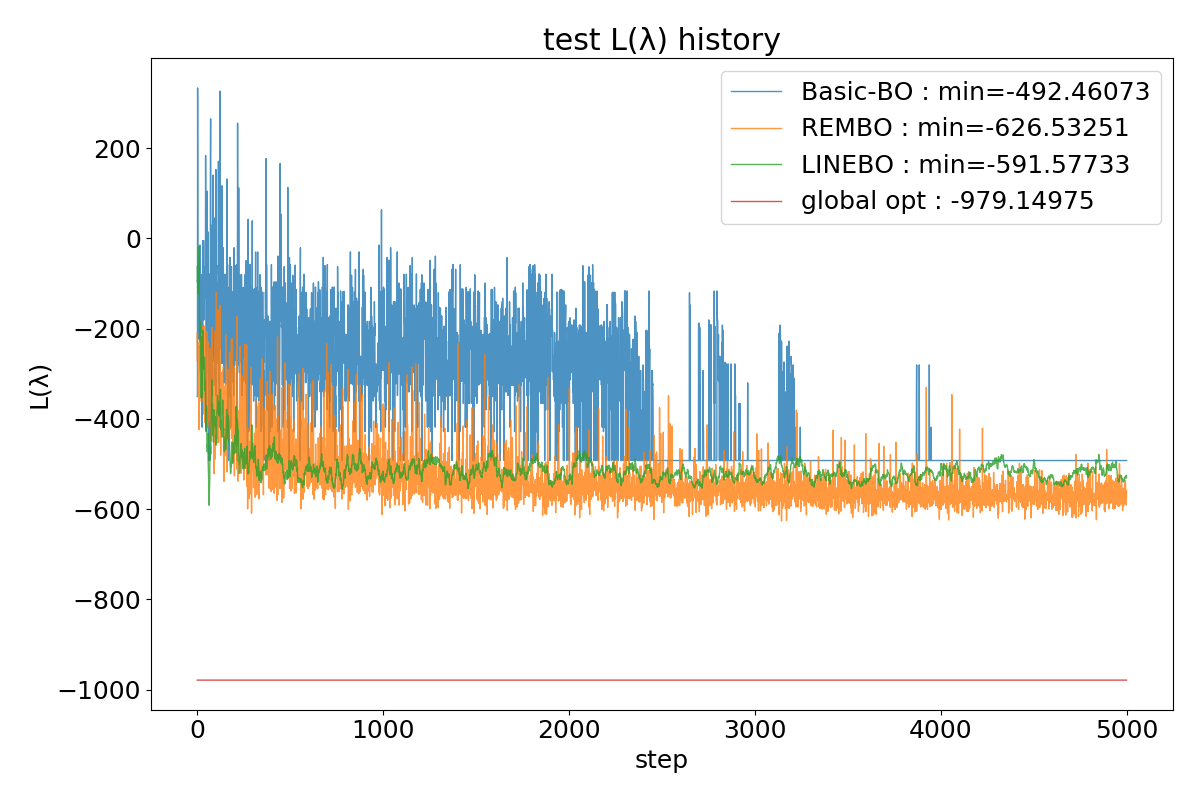
ここで実験設定の詳細についてさらに述べておきます. Basic-BOとは獲得関数の最小化の際に特に何もせず, そのまま25次元空間上を探索するアルゴリズムを指します. またREMBOにおいて, 低次元空間の次元数は10次元, 探索空間\(Z\)は\([-1.0, 1.0]^{10}\)に設定しています. LINEBOでは降下方向として各次元の軸に沿った方向, すなわち座標降下法を用いています. 降下する軸の選び方は25次元の中から一様ランダムに選んでいます. global optとは25次元STYBLINSKI-TANG関数の大域的最適解\(\lambda^{*}\)における\(L(\lambda^{*})\)の値を示しています.
また, アルゴリズムに依らずカーネル関数はRBFカーネル, 獲得関数はLCB, 初期点の数は200で統一しています. REMBOのみ探索空間が低次元空間であるため, 初期点は低次元探索空間\(Z\)上から, Basic-BOとLINEBOは\(\Lambda\)から一様にサンプリングしてきた共通のものを使用しています.
実験結果から得られる観察として, まずどのアルゴリズムも大域的な最適解に収束できていない様子が見られます. 各アルゴリズムごとに見ると, Basic-BOはステップ数が増え, 探索点が増えていった場合にほとんど同じ評価値を取り続けており, 探索が十分に行われていない様子が見られます. 一方でREMBO, LINEBOはステップ数が増えた場合にも探索が行われている様子が確認できますが, 評価値の大きな改善には至っていないことがわかります. しかし, REMBO, LINEBOはBasic-BOに比べ少ないステップ数でより小さい評価値を得ていることがわかります.
結論
本稿では高次元空間中のベイズ最適化手法の収束性について数値的に検証しました. 結果として, どのアルゴリズムもテスト関数に対して大域的な解を得ることはできていなかったものの, REMBO, LINEBOは高次元空間中でも探索する様子が見られ, 標準的なベイズ最適化よりも速い収束性が観察されました.
一点注意すべき点としてベイズ最適化はフレームワークとして柔軟であるが故に, カスタマイズできる点が複数あることが挙げられます. 例えば, 「どのような獲得関数を使うか」, 「カーネル関数はどのようなものを用いるか」, 「初期点はどれぐらいにするか」などといった点です. そのため, 本稿での実験結果がそのままベイズ最適化の限界を表している訳ではないことに留意すべきです.
実際の業務ではテスト関数に留まらず, より複雑な関数に対してベイズ最適化を適用し, どのような結果が得られるか, どのような発展が考えられるかを試行していました. 今回, このような大変刺激的なテーマで研究する機会を頂いたことに感謝致します.
