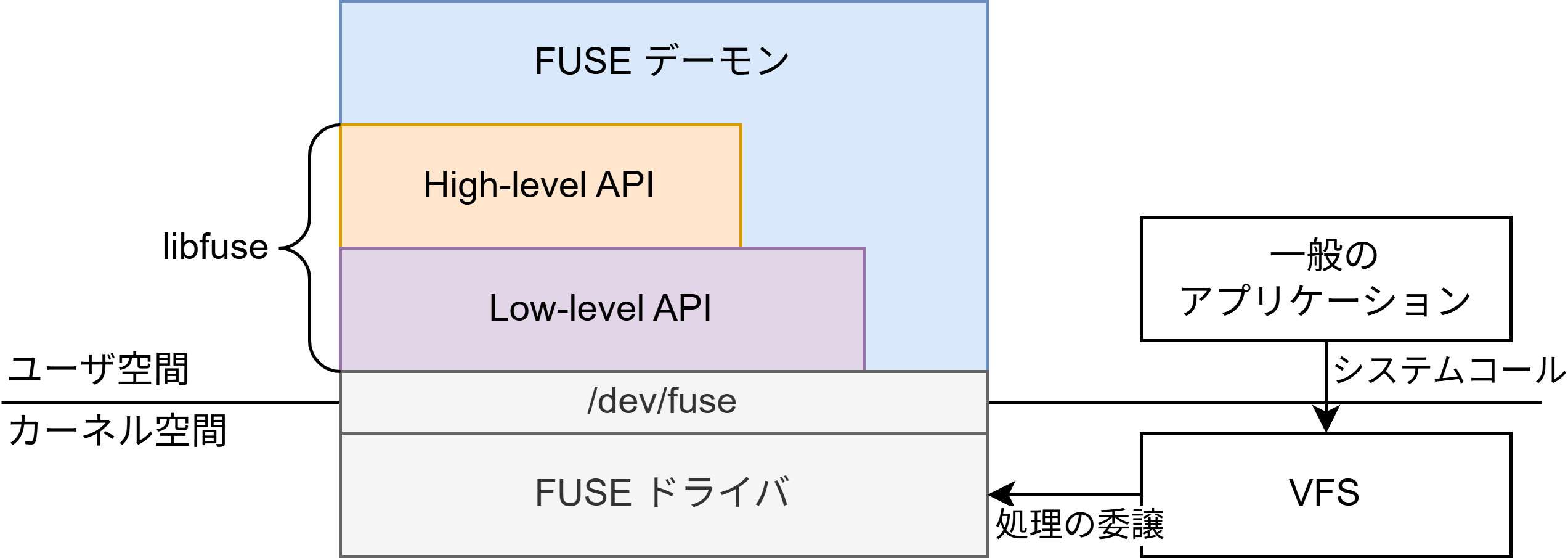
Blog
この記事は、2025 年 PFN 夏期インターンで勤務された坂内理人さんによる寄稿です。
こんにちは、慶應義塾大学政策・メディア研究科修士1年の坂内理人(rihib)と申します。PFN 2025夏期国内インターンシップ7週間研究開発コースに参加させていただきました。私は、こちら で紹介されている「超高効率AI計算基盤の研究開発」に関連して、超高効率AI計算基盤向けのKubernetesスケジューラの概念実証(PoC)の開発を行いました。また評価に伴って、大規模シナリオの実行に対応した独自のKubernetesスケジューラ評価ツールであるkube-scheduler-evaluatorも併せて開発しました。
超高効率 AI 計算基盤向け Kubernetes スケジューラ
「超高効率AI計算基盤の研究開発」については前述の記事を読んでいただきたいのですが、これに関連してソフトウェア側でもAI計算基盤と協調動作して効率的なリソーススケジューリングを実現するKubernetesスケジューラを作成することになり、私は今回のインターンでその概念実証(PoC)を開発しました。
Least Slack Time Scheduling
今回開発したスケジューラでは、コアとなる機能としてLeast slack time (LST) schedulingを行うカスタムプラグインを実装しました。Slack time(余裕時間)とは、ジョブが今実行開始された場合に実行完了時にデッドライン(ジョブの実行締切時刻)に対して残る時間のことを指します。LST schedulingはslack timeが小さいジョブを優先して実行するスケジューリングアルゴリズムです。
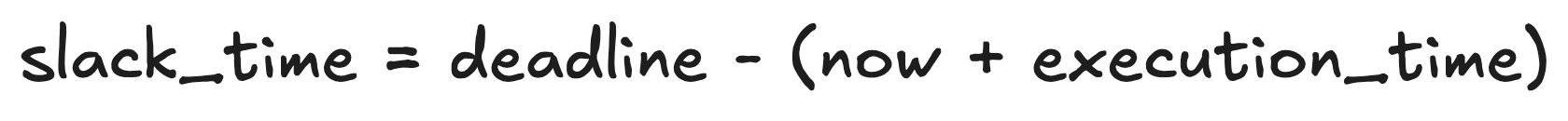
一般的にジョブを実行する際、そのジョブにはいつまでに終わって欲しいというユーザー側の要求や期待が暗黙的に含まれているはずです。その要求を明示的に考慮してスケジューリングできるようにすることで、デッドラインまでに完了するジョブの割合を最大化し、より良いAI計算基盤を実現することを目指してこの機能を開発しました。
slack timeを求めるには、ジョブの実行時間とデッドラインを予め把握している必要があります。今回のPoCでは、外部の予測モデルによってある程度正確なジョブの実行時間が与えられており、デッドラインも同様にユーザーまたはユーザーとの間に存在するコンポーネントによって与えられているという前提を置いて開発を行いました。ここでのデッドラインは必ず守る必要のあるハードデッドラインではなく、ベストエフォートなソフトデッドラインを意味します。ユーザビリティの観点からはデッドラインを過ぎることが分かった時点でユーザーに早期にエラーを返すことが望ましいですが、今回のPoCでは考慮していません。
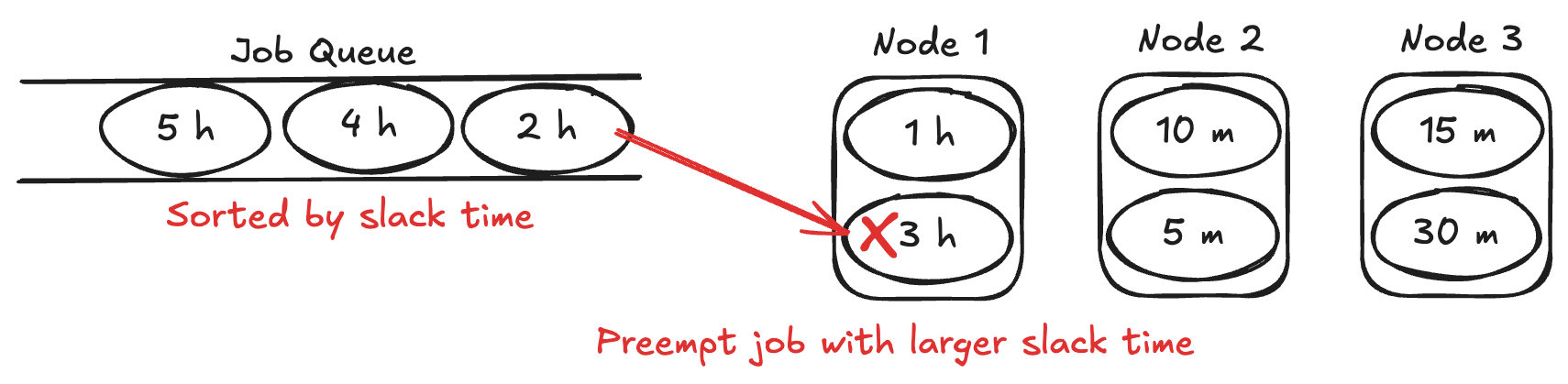
基本的な挙動としては、Podのアノテーションとしてジョブの予測実行時間やデッドラインを与えると、スケジューラの内部でslack timeを計算して、slack timeの小さいPodから順にスケジューリングを行います。既にクラスタリソースが占有されていてスケジュールできない場合はslack timeのより大きいPodをプリエンプションします。
挙動としては優先度に近いですが、優先度が主観的な指標になりがちなのに対して、デッドラインという明確で定量的な指標に基づいてより細やかなスケジューリングが可能になるというメリットがあります。一方でジョブの投入時にデッドラインを指定する必要があるため、ユーザーの負担が増えてしまうのではないかという懸念も考えられます。しかし、ジョブの予測実行時間に基づいて自動で最適なデッドラインを生成するコンポーネントを実装することで、運用によってこの課題は十分に解決可能だと考えています。ただ今回のPoCではその点について特に考慮はしていません。
ちなみに実行中のジョブに関してslack timeを計算する際に、すでに実行した時間を考慮した残りの実行時間を用いることはしませんでした。たとえば予測実行時間が60分のジョブがある場合にすでに10分実行したからといってslack timeの計算をする際に予測実行時間を50分として計算することはせず、60分のままで計算します。理由としては2つあります。1つはチェックポイントに対応しないジョブの存在です。このようなジョブがプリエンプションされた場合、計算を最初から実行し直す必要があります。そのため実行した時間を考慮しても意味がありません。もう1つは、プリエンプションが連続して発生し続けてしまう危険があるためです。slack timeの大きいジョブAをプリエンプションして代わりにジョブBを実行した場合、実行されていないジョブAのslack timeは小さくなっていくのに対して、実行中のジョブBのslack timeは変わらないため、あるタイミングでジョブAのslack timeの方が小さくなると再度プリエンプションが発生し、これが交互に繰り返されてしまいます。
PoCとdefault-schedulerの挙動を比較するために、Kind上で下記のシナリオをそれぞれのスケジューラに対して実行しました。Kind上では同時に実行できるPod数を最大10個に制限しています。
シナリオ:
- 実行時間30分、デッドライン1時間後のジョブ(job-large)を10個投入
- 次に実行時間15分、デッドライン25分後のジョブ(job-middle)を10個投入
- 次に実行時間5分、デッドライン10分後のジョブ(job-small)を10個投入
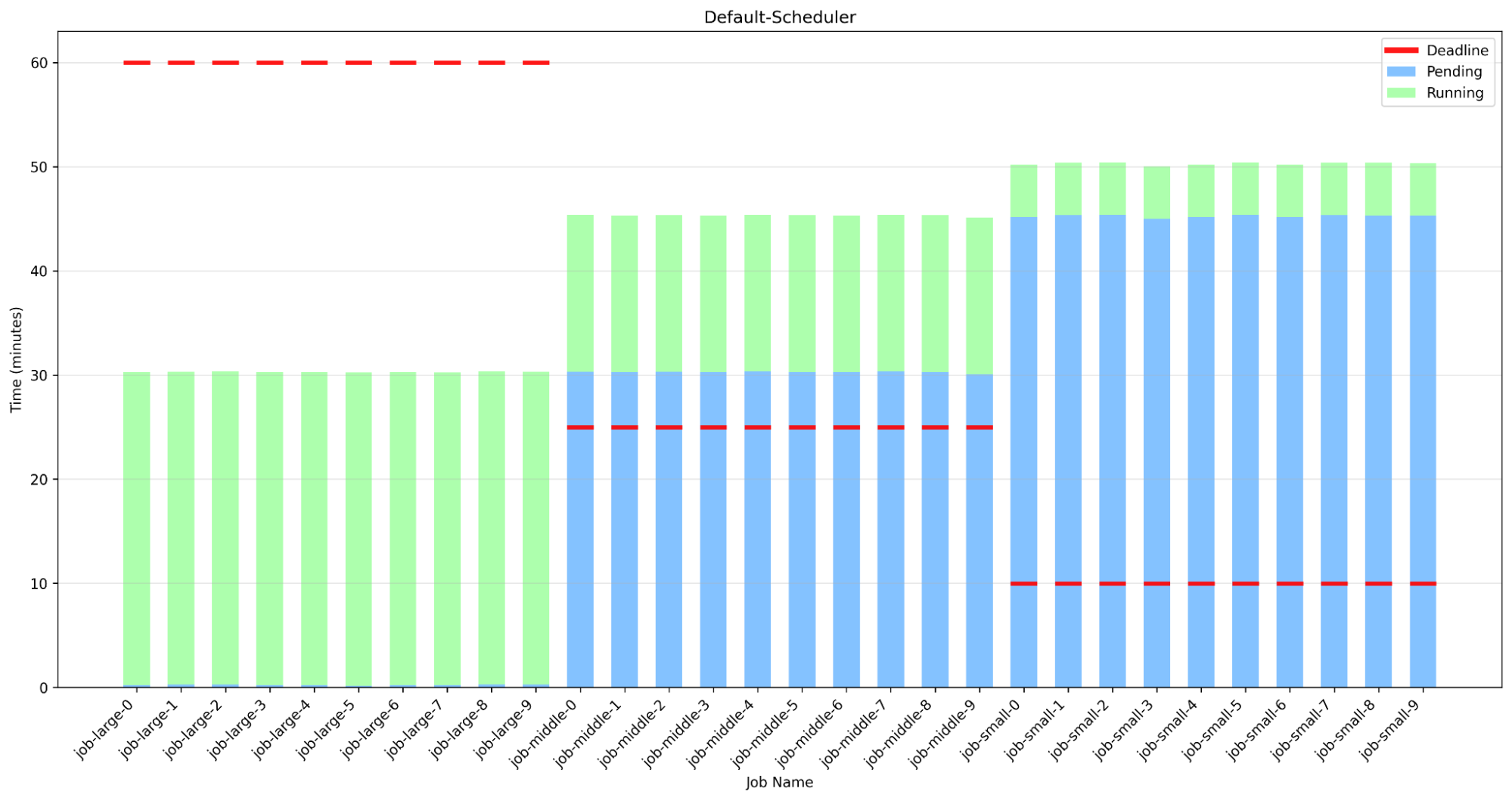
下記はdefault-schedulerの挙動を可視化したグラフです。ジョブごとに1つの棒グラフで表しています。棒グラフの縦軸はジョブが作成されてからの分単位の経過時間です。棒グラフの青い部分(Pending)はジョブが作成されてから実行が開始されるまでの期間を表します。緑の部分(Running)はジョブが実行されている期間を表します。赤い線はジョブのデッドラインです。
default-schedulerでは先にjob-largeによってクラスタ全体が占有されてしまい、後から投入されたjob-middleやjob-smallについては、実行が開始される前にデッドラインを過ぎてしまっていることがわかります。
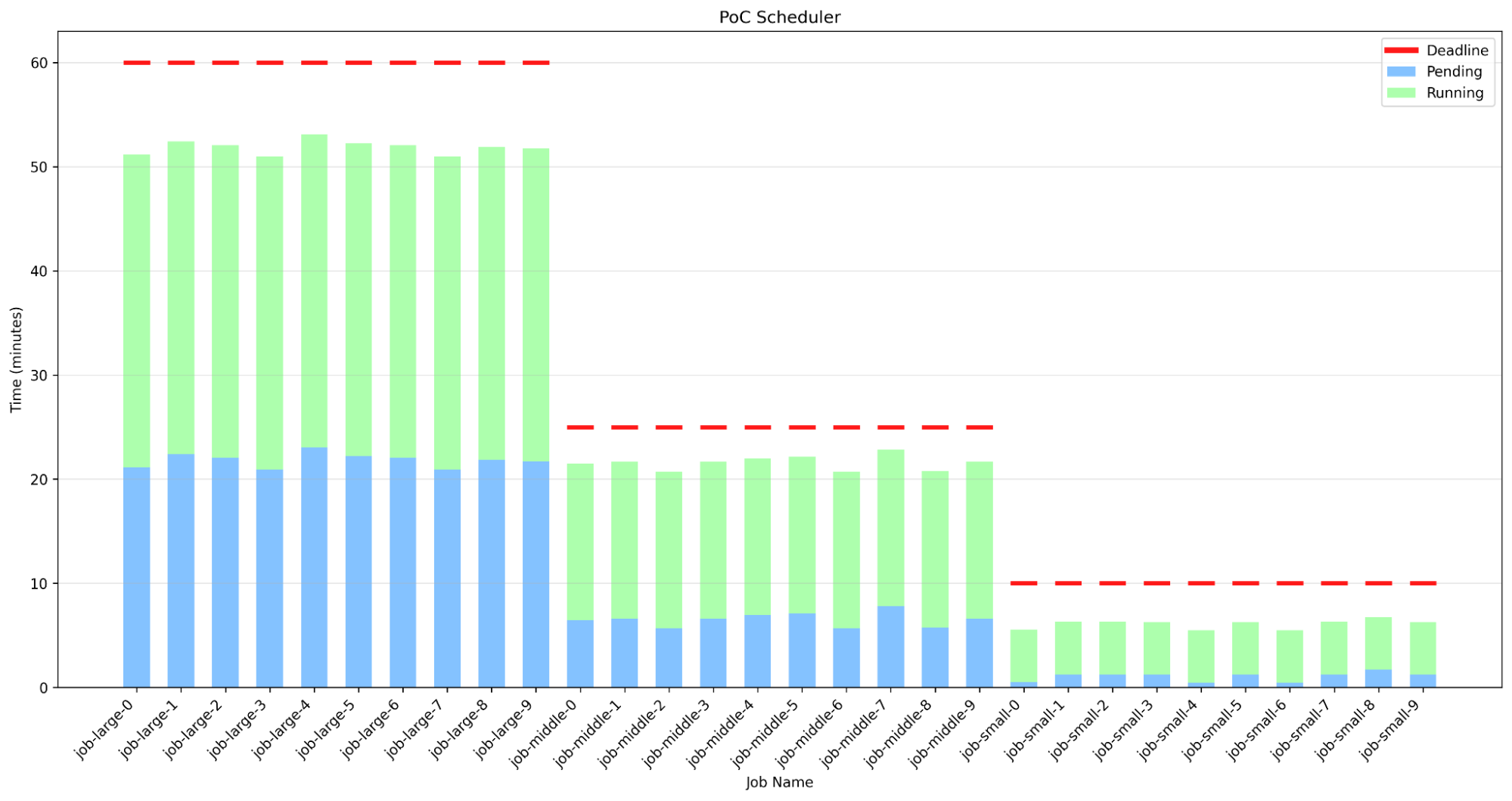
下記はPoCの挙動を可視化したグラフです。default-schedulerと異なり、job-largeが先に投入されたにもかかわらず、プリエンプションによって後から投入されたjob-smallやjob-middleから順に実行が開始されていることがわかります。これによって全てのジョブがデッドラインを超えないように実行されています。
Gang Scheduling
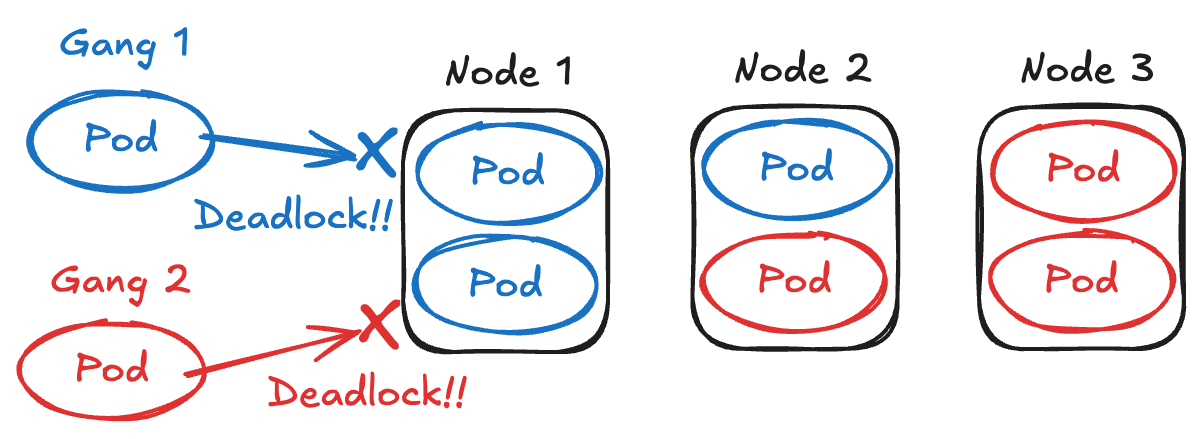
AI計算基盤では機械学習ジョブを実行できることが求められます。特にマルチノード分散学習などを行う場合はGang Schedulingを行う必要があります。Gang Schedulingとは複数のPodから構成されるジョブ(Gang)に対し、それらのPodを全て同時にスケジュールするか、1つでもスケジュールできない場合は全てのPodをスケジュールしないというスケジューリングアルゴリズムです。
Gang Schedulingが必要な理由として、まず1つはGangの全てのPodがスケジュールされない限り、ジョブの実行を進められないため、一部のPodのみを先にスケジュールしてしまうと、残りのPodがスケジュールされるまでの間はリソースが無駄に占有されてしまうことが挙げられます。もう1つは、一部のPodのみがスケジュールされた不完全なGangが複数存在し、それらによってクラスタ全体が占有されてしまうとデッドロックが発生してしまうためです。
PFNには独自に開発したGang Scheduling プラグインが既に存在しているため、今回開発したPoCのスケジューラと組み合わせることで、slack timeに基づいたGangのスケジューリングとプリエンプションを行えるようにしました。これによってマルチノード分散学習などの機械学習ジョブの実行にも対応できるようになります。
Custom Bin Packing
追加の機能として独自のビンパッキングを行うプラグインも実装しました。一般的なビンパッキングは実行ノード数を最小化することを目的にしていますが、今回実装したビンパッキングはGPUやPFNが開発しているMN-Coreなどのアクセラレータの断片化を防ぐことを目的としています。
たとえばアクセラレータを8個持つノードが3つあり、アクセラレータを2つ要求するPodを3つスケジュールしたい場合、3つのノードにPodを1つずつ分散してスケジュールしてしまうと、後からアクセラレータを8個要求するPodをスケジュールできなくなります。このような状況を断片化と呼び、これを防ぐには3つのPodを同じノードにスケジュールする必要があります。このようにジョブを詰め込むようにスケジュールすることをビンパッキングと呼びます。Webサービスなどの恒常的に動作することが求められるPodの場合は負荷分散や冗長性のためになるべく分散するようにスケジュールされますが、ジョブのように一定時間で終了するPodに関してはリソース使用効率を高めるためにビンパッキングを行うことが一般的です。
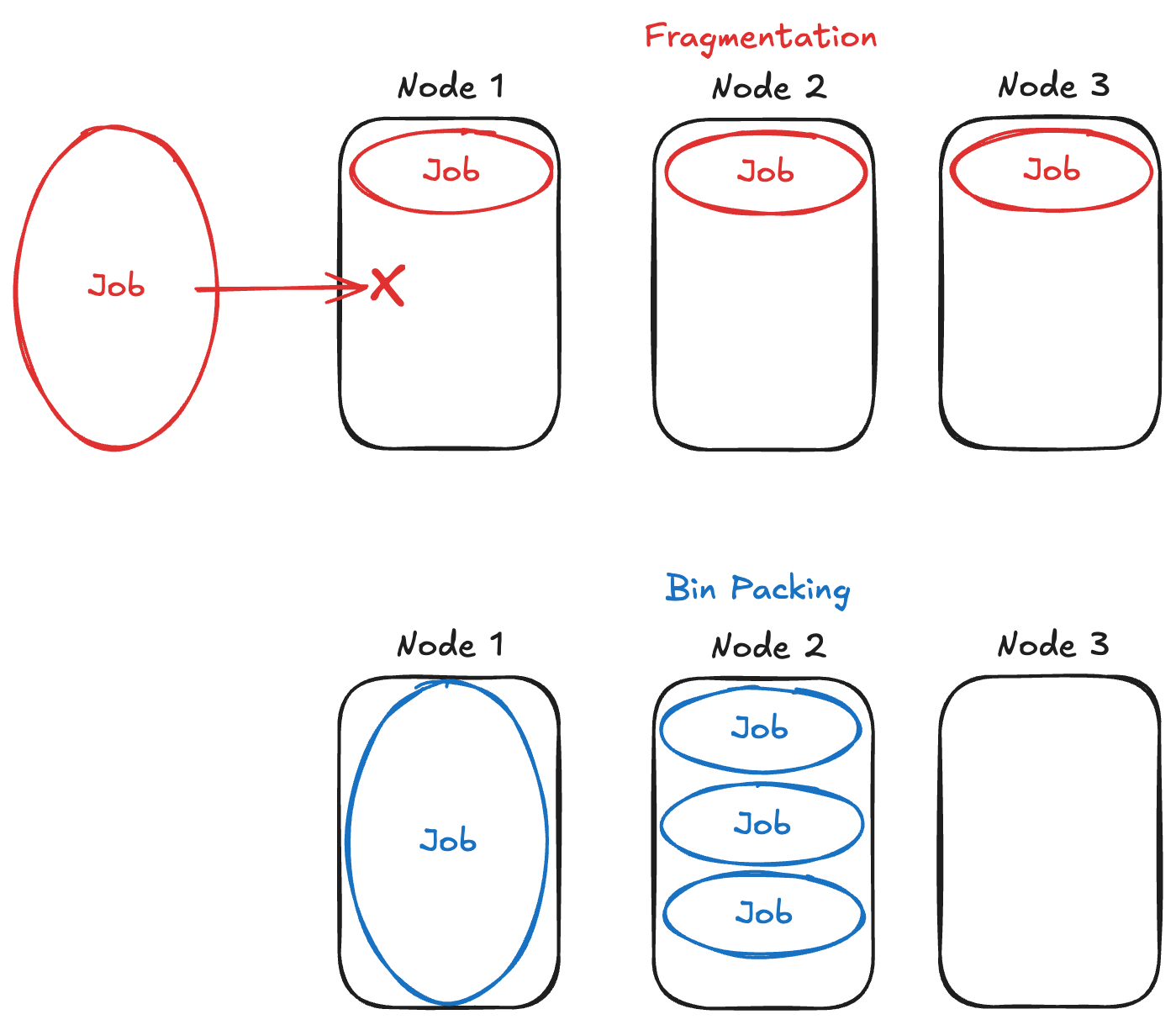
一般的なビンパッキングはアクセラレータの使用率に基づいて使用率のより高いノードを優先してジョブをスケジューリングするのに対し、今回実装したビンパッキングは使用可能なアクセラレータの個数がより少ないノードを優先してジョブをスケジューリングします。似ているように思えますが、ノードごとに使用可能なアクセラレータ数が異なる場合に違いが生まれます。
たとえば下記のような2つのノードがあり、新たに アクセラレータ を1つ要求するジョブをスケジューリングするとき、一般的なビンパッキングの場合は使用率の高いノード1を選択しますが、今回実装したビンパッキングの場合は使用可能なアクセラレータ数の少ないノード2を選択します。実行ノード数を最小化したい場合は一般的なビンパッキングの挙動の方が適していますが、アクセラレータの断片化を防ぎたい場合は今回実装したビンパッキングの挙動の方が適切です。
- ノード1:アクセラレータ8個のうち6個が使用中(使用率75%)
- ノード2:アクセラレータ1個のうち0個が使用中(使用率0%)
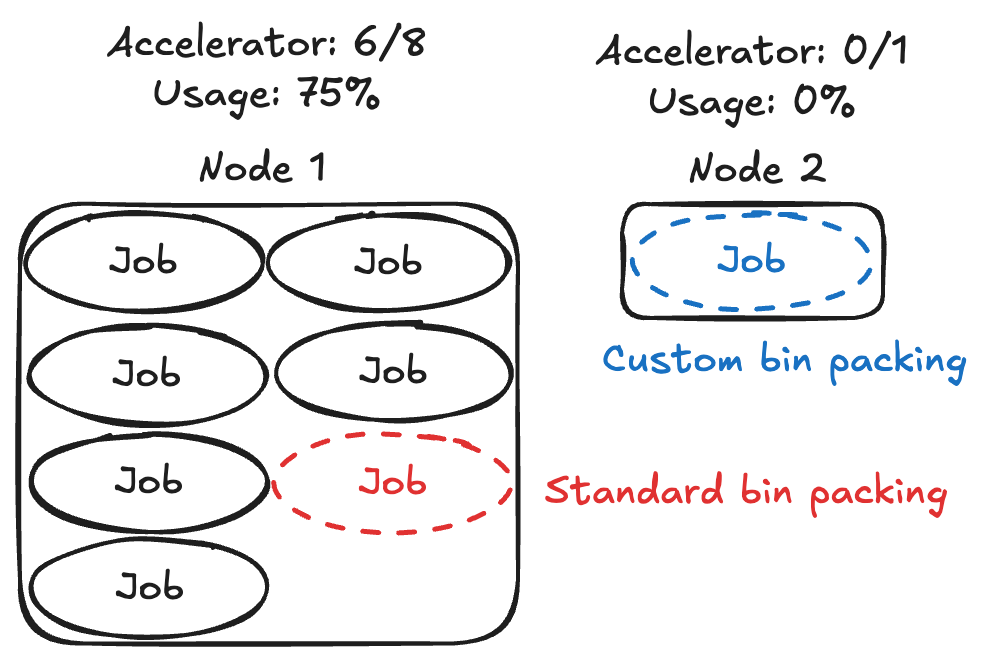
一般的にはノードごとに同じ数のアクセラレータを載せるため、両者の挙動に違いが生まれないのではないかと思われるかもしれませんが、実際はアクセラレータの故障などによってノードごとに有効なアクセラレータ数が異なる状況は十分に考えられます。そのような場合にもアクセラレータの断片化を最小限に抑えられます。
kube-scheduler-evaluator
前述したスケジューラの評価を行う際にいくつかの課題が明らかになりました。そこで今回のインターンでは、実装したスケジューラの評価の実施に伴ってそれらの課題の解決を図った評価ツールであるkube-scheduler-evaluatorも併せて開発しました。
これまでのスケジューラ評価における課題
スケジューラの評価を行うにあたって大きく3つの課題が明らかになりました。1つ目の課題はKubernetesで公式に開発されているスケジューラ評価ツールが存在しないというものです。パフォーマンステストを行うscheduler_perfや、kind、kwok、kube-scheduler-simulatorなどのツールは存在しますが、スケジューラに対して定義したシナリオを実行して任意のメトリクスを取得できる評価ツールは少なくとも公式では存在しておらず、広く使われているサードパーティツールも存在しません。
2つ目の課題は評価を行うにあたって、実際の物理リソースを用意する必要があったり、ジョブの実行時間を考慮する場合は実行が完了するまで待つ必要があるというものです。kwokを使う場合は実際のリソースを用意する必要はありませんが、ジョブの実行時間を再現することが難しいです(kwokには実行時間を指定できるstagesという機能がありますが、非常に扱いづらくなかなか意図通りに動作しません)。またkindは実際にコンテナを実行するのでジョブの実行時間を再現しやすいですが、実際のリソースを消費するため大量のPodの実行には向きません。またどちらもジョブの実行時間を再現する場合、実際に実行が完了するのを待つ必要があります。たとえば機械学習ジョブの中には実行に数時間や数日かかるものも珍しくなく、時には1ヶ月以上かかるジョブもあります。このようなジョブが含まれるシナリオを実際に実行してスケジューラを評価することは現実的ではありません。
3つ目の課題は既存のツールでは大規模かつ複雑なシナリオを実行しづらいというものです。たとえば数個のノードを持つクラスタ上で数分の実行時間を持つ数個のジョブを実行する程度であればkindやkwokなどを用いて任意の評価を実行することは容易です。しかし、たとえば1000個のノードを持つクラスタ上でランダムな要求リソースと1時間〜1週間のランダムな実行時間を持つ5000個のジョブを5分〜1時間のランダムな間隔で投入するというシナリオを実行したい場合はどうでしょうか。YAMLファイルで少量のジョブを定義して実行することが一般的に想定されている既存のツールではこのような大規模で複雑なシナリオを柔軟に定義し、安定的に実行して評価メトリクスを収集することは容易ではなく、実行したとしても実行時間の長いジョブが含まれているため評価が完了するまでに1ヶ月などの長い時間がかかってしまいます。
kube-scheduler-evaluator の特徴
これらの課題を解決するために、kube-scheduler-evaluatorというスケジューラ評価ツールを開発しました。このツールは、YAMLではなくGo言語を用いてシナリオを定義可能にすることで、大規模かつ複雑なシナリオを柔軟かつ容易に定義できます。
下記はユーザーが実装するシナリオのコード例です。ユーザーは与えられたチャネルに対して実行したいイベントを送信するgenerator関数を実装することでシナリオを定義できます。
func Generator(ch chan <- Event) {
/*
Create Nodes
*/
for range numNode {
node := &corev1.Node{
ObjectMeta: metav1.ObjectMeta{
GenerateName: "node-",
},
Status: corev1.NodeStatus{
Capacity: corev1.ResourceList{
corev1.ResourceCPU: resource.MustParse(nodeCPU),
corev1.ResourceMemory: resource.MustParse(nodeMem),
corev1.ResourcePods: resource.MustParse("110"),
"nvidia.com/gpu": resource.MustParse(nodeGPU),
},
Allocatable: corev1.ResourceList{
corev1.ResourceCPU: resource.MustParse(nodeCPU),
corev1.ResourceMemory: resource.MustParse(nodeMem),
corev1.ResourcePods: resource.MustParse("110"),
"nvidia.com/gpu": resource.MustParse(nodeGPU),
},
},
}
node.SetGroupVersionKind(corev1.SchemeGroupVersion.WithKind("Node"))
event := NewEvent(
EventTypeCreate,
node,
interval,
)
ch <- event
}
/*
Create Jobs
*/
for range numJob {
job := &batchv1.Job{
ObjectMeta: metav1.ObjectMeta{
GenerateName: "job-",
Namespace: "default",
},
Spec: batchv1.JobSpec{
Parallelism: ptr.To[int32](1),
Completions: ptr.To[int32](1),
Template: corev1.PodTemplateSpec{
ObjectMeta: metav1.ObjectMeta{
Labels: podLabels,
Annotations: map[string]string{
ExecutionDurationAnnotationKey(consts.UserID): execution.String(),
},
},
Spec: corev1.PodSpec{
SchedulerName: schedulerName,
Containers: []corev1.Container{
{
Name: "example-job",
Image: "registry.example.com/example-job:1.0",
Resources: corev1.ResourceRequirements{
Requests: corev1.ResourceList{
corev1.ResourceCPU: resource.MustParse(podCPU),
corev1.ResourceMemory: resource.MustParse(podMem),
"nvidia.com/gpu": resource.MustParse(podGPU),
},
Limits: corev1.ResourceList{
corev1.ResourceCPU: resource.MustParse(podCPU),
corev1.ResourceMemory: resource.MustParse(podMem),
"nvidia.com/gpu": resource.MustParse(podGPU),
},
},
},
},
},
},
},
}
job.SetGroupVersionKind(batchv1.SchemeGroupVersion.WithKind("Job"))
event := NewEvent(
EventTypeCreate,
job,
interval,
)
ch <- event
}
}
またkindとは違って実際の物理リソースを消費せず、kwokとは違ってアノテーションで指定するだけで容易にジョブの実行時間を再現できます。加えて、時系列の整合性を保ちながら内部的に仮想的な時間を進めることで、実行時間の長いジョブが含まれていても高速にシナリオの実行を進めることが可能です。実行中にリアルタイムに評価メトリクスを収集してGrafanaなどで可視化できます。同時に大規模なシナリオを実行する際、負荷の高まりによって生じるkube-apiserverの不安定さをkube-scheduler-evaluator側で吸収することで、より頑健で安定した動作を実現しました。
内部的にはkube-scheduler-evaluatorはNodeやPod、Jobなどのオブジェクトの作成・削除などのシミュレーションにkwokを使用しています。ユーザーから Go で定義された複数のシナリオを受け取り、仮想時間を管理しながらkwokに対してオブジェクトのCRUD操作を実行し、同時にVictoria Metricsなどの時系列データベースに対してメトリクスを送信します。

このようにkube-scheduler-evaluatorによって、大規模シナリオを用いたスケジューラの評価を柔軟かつ容易に、素早く実行できるようになります。kube-scheduler-evaluatorはOSS として公開しており、ただの評価ツールではなく、CIで実行するなどスケジューラ開発のプロセスの一部として組み込まれるような存在になることを目指しています。
まとめ
インターン期間中には中間発表や最終発表として社内向けに成果を発表する機会があり、社員の方々から多くのフィードバックをいただくことができました。また他にもデータセンター見学や、経営陣の方々との交流イベント、シャッフルランチなどがあり、インターン生や社員の方々と交流を深めることもできました。会社全体やチームの雰囲気はとても和気藹々としたもので、社員の方々もメンターを含め、とても物腰の柔らかい方ばかりでした。
インターンを通してKubernetesのスケジューラや機械学習基盤について多くのことを学ぶことができました。また技術面だけでなく、PFNが行っている様々な事業についても理解を深めることができました。
最後に、メンターの石原さん、サブメンターの薮内さん、同じチームの方々、EMの小松さんなど多くの方々に大変お世話になりました。このような貴重な機会をいただけたことに感謝いたします。
謝辞
この成果は、国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)の「ポスト5G情報通信システム基盤強化研究開発事業」(JPNP20017)の委託事業の結果得られたものです。
※ 画像を含む本文に記載されている会社名、製品名、ロゴ等は、一般に各社の登録商標または商標です。
Area