Blog
Optuna 開発メンバの小嵜 (@smly) です。この記事では Optuna の拡張機能として開発している LightGBM Tuner について紹介します。
LightGBM Tuner は LightGBM に特化したハイパーパラメータ自動最適化のためのモジュールです。Pyhton コードの import 文を 1 行変更するだけで簡単に利用できます。LightGBM Tuner はエキスパートの経験則を自動化しコードに落とし込むことで、従来より短い時間で最適なハイパーパラメータを探索できます。また記事の後半では従来手法と比較したベンチマーク結果についても紹介します。ベンチマークをとることで、従来の方法と比較して効率的に探索できることを確認しました。
ナイーブな LightGBM のハイパーパラメータチューニング
LightGBM は勾配ブースティング法の高速な実装を提供する人気のライブラリです。様々な機能が実装されており便利である反面、多くのハイパーパラメータが用意されています。例えば、決定木の葉の数や深さを制御するハイパーパラメータ、決定木ごとにサンプリングする特徴量の割合、決定木の葉に割り当てられる最小のサンプル数などなど。これらを複数回の試行なしにチューニングすることは容易ではありません。Optuna はこうしたハイパーパラメータのチューニングを手助けするフレームワークです。過去の試行結果に基づいて、効率的に最適なハイパーパラメータを探索する手助けをします。
Optuna を使って LightGBM のハイパーパラメータをチューニングするとき、ナイーブに実装すると次のようになります。
def objective(trial):
data, target = sklearn.datasets.load_breast_cancer(return_X_y=True)
train_x, test_x, train_y, test_y = train_test_split(data, target, test_size=0.25)
dtrain = lgb.Dataset(train_x, label=train_y)
param = {
'objective': 'binary',
'metric': 'binary_logloss',
'lambda_l1': trial.suggest_loguniform('lambda_l1', 1e-8, 10.0),
'lambda_l2': trial.suggest_loguniform('lambda_l2', 1e-8, 10.0),
'num_leaves': trial.suggest_int('num_leaves', 2, 256),
'feature_fraction': trial.suggest_uniform('feature_fraction', 0.4, 1.0),
'bagging_fraction': trial.suggest_uniform('bagging_fraction', 0.4, 1.0),
'bagging_freq': trial.suggest_int('bagging_freq', 1, 7),
'min_child_samples': trial.suggest_int('min_child_samples', 5, 100),
}
gbm = lgb.train(param, dtrain)
preds = gbm.predict(test_x)
pred_labels = np.rint(preds)
accuracy = sklearn.metrics.accuracy_score(test_y, pred_labels)
return accuracy
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=100)
print('Number of finished trials:', len(study.trials))
print('Best trial:', study.best_trial.params)
この例では、feature_fraction, num_leaves など合計 7 個のハイパーパラメータから、最適な組み合わせを探索します。この組み合わせの数は掛け算で決まるため、膨大な探索空間になります(下図)。

Step-wise algorithm
ハイパーパラメータの自動チューニングにおける大きな課題の一つは、なるべく少ない試行回数でより良い評価を得ることです。特に機械学習のタスクでは一回の試行に長い実行時間を必要とするため、安易に試行回数を増やすことができません。
少ない試行で最大の成果を得る探索手法は様々ありますが、探索手法ではなく探索空間について考えてみましょう。手動で勾配ブースティングのハイパーパラメータをチューニングしてきた経験者の間では「重要なハイパーパラメータから順に最適なハイパーパラメータをチューニングする」といった方法が広く用いられています [1][2]。
順次ハイパーパラメータを決定していくため、この探索の組み合わせの数は足し算で決まり、探索空間を大きく狭めることができます。

LightGBM Tuner は「重要なハイパーパラメータから順に最適なハイパーパラメータをチューニングする」という経験則をコードに落とし込み、実装したモジュールです。経験的に影響力が大きいと思われるハイパーパラメータから順次チューニングを行います。
上図では簡略化されていますが、相互作用の大きいハイパーパラメータは同時にチューニングを行います。具体的には bootstrap aggregating を制御するハイパーパラメータである bagging_fraction と bagging_freq 、正則化項のハイパーパラメータである reg_lambda と reg_alpha は同時にチューニングを行います。
LightGBM Tuner の使い方
LightGBM Tuner は Optuna v0.18.0 に実験的な機能としてリリースされました。以下のように import 行を 1 行変更することで試すことができます。

Python コード中の lgb.train() が呼ばれたタイミングでハイパーパラメータのチューニングが実行されます。チューニングにおける「最適なパラメータ」や「探索履歴」は `lgb.train()` のキーワード引数にオブジェクトを渡すことで得ることができます。
best_params, tuning_history = dict(), list()
booster = lgb.train(params, dtrain, valid_sets=dval,
verbose_eval=0,
best_params=best_params,
tuning_history=tuning_history)
print(‘Best Params:’, best_params)
print(‘Tuning history:’, tuning_history)
現在は LightGBM API の train() のみサポートしています。
実データを使ったベンチマーク
LightGBM Tuner は、果たしてナイーブな LightGBM のハイパーパラメータチューニングと比較して優れた性能を発揮できるのでしょうか。この質問に応えるために、ハイパーパラメータの探索手法を比較するベンチマークをとりました。ベンチマークに使ったデータセットは以下の表の通りです。
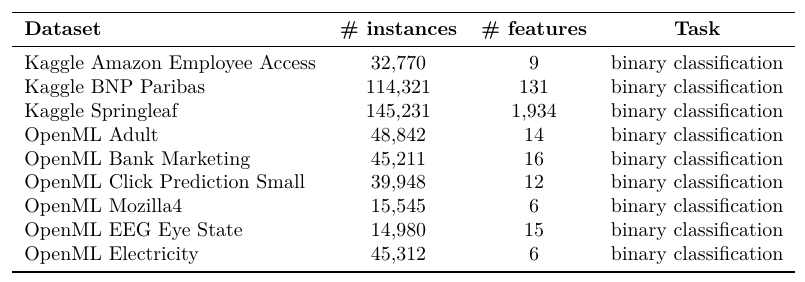
比較手法は以下の 3 つを選択しました。
- LightGBM Tuner による Step-wise algorithm を使ったチューニング
- TPE (Tree-structured Parzen Estimator) [3] +ナイーブなチューニング
- ランダムサンプリング +ナイーブなチューニング
TPE は確率モデルを用いて効率的に探索する手法の一つで、Optuna が使うデフォルトのサンプリングアルゴリズムです。ベンチマークでは [4] と同様に検証セットにおける評価と試行回数のトレードオフを調べることで、探索手法の優劣を比較しました。
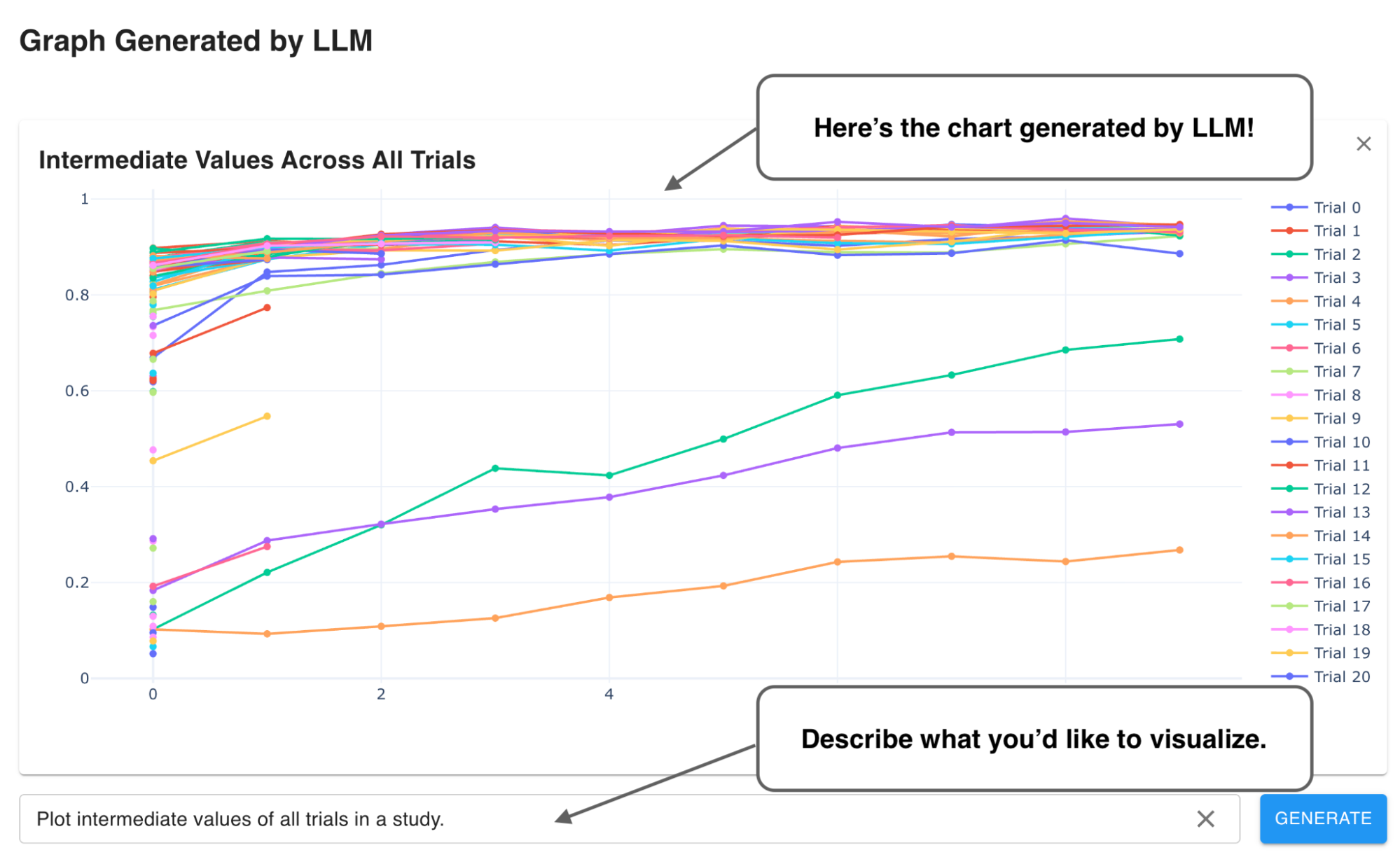
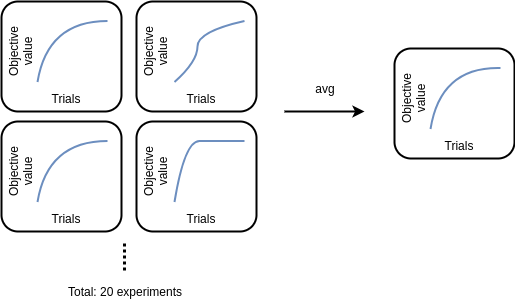
「乱数によって、たまたま早期に良いハイパーパラメータがサンプリングされる」というランダム性による影響を排除するため、それぞれのデータセットで合計 20 回実験し、試行回数ごとに平均をとりました (下図)。
ベンチマークの結果を折れ線図にまとめたものが以下の図となります。折れ線の緑がランダム、オレンジがTPE、青が LightGBM Tuner による検証セットでの評価値となります。赤のバツ印はチューニングを一切行わずに LightGBM のデフォルトのパラメータを使った場合の結果を示しています。ヨコ軸は試行回数、タテ軸はこれまでの試行における最適な評価値です。評価指標には AUC を用いており、数値が大きいほど良い結果であることを示しています。
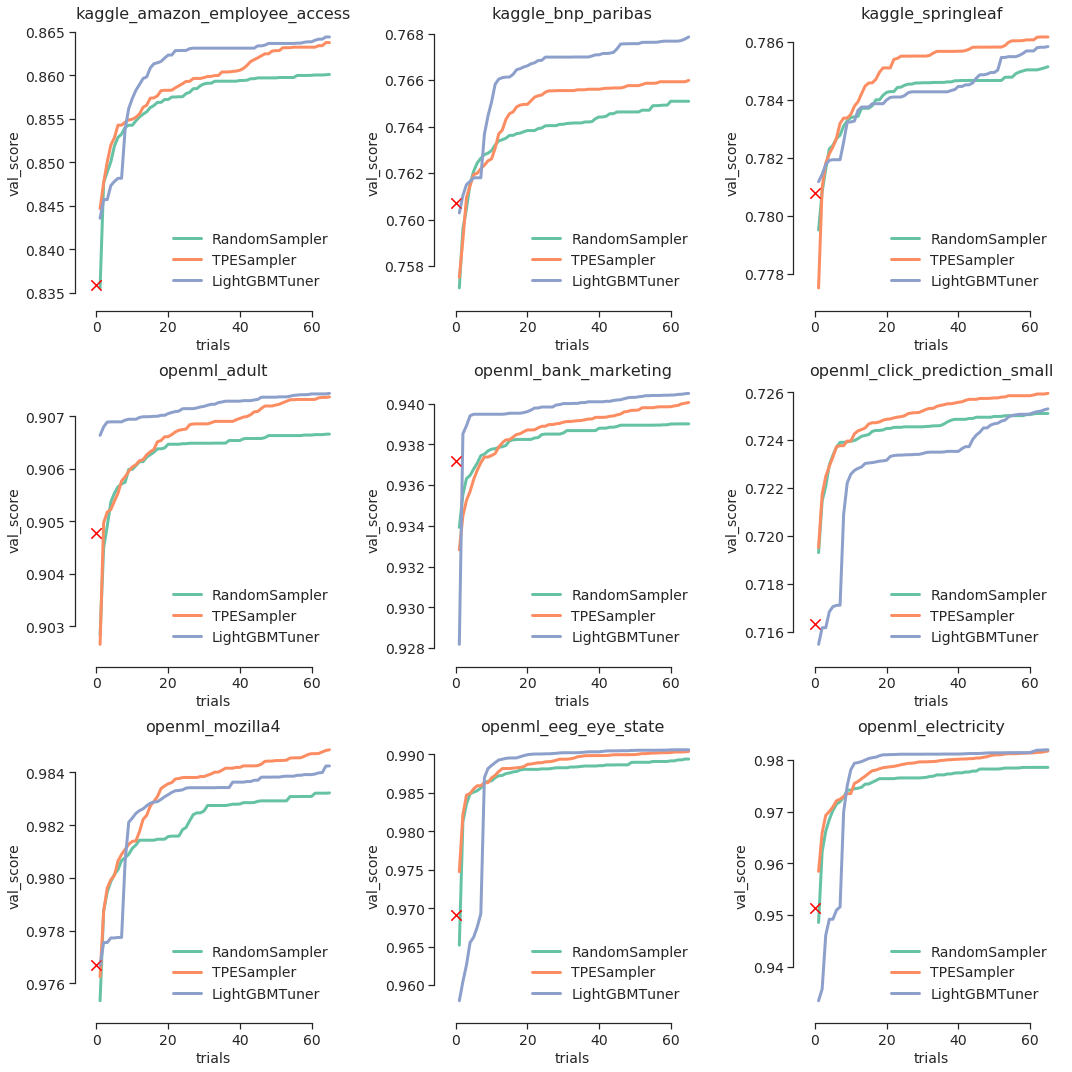
このベンチマークでは、9 のデータセットのうち 6 のデータセットで LightGBM Tuner のほうが優れた結果が出せることがわかりました。
定性的な評価:重要なハイパーパラメータを調べる
LightGBM Tuner は他の探索方法と比較して優れた性能を発揮することが確認できました。一方で、LightGBM Tuner より TPE のほうが優れている結果も 3 例ありました。実データを使ったチューニングにおける振る舞いを深堀りし、アルゴリズムの改善方法について考察します。
LightGBM Tuner ではステップごとにチューニングするハイパーパラメータを選びます。たとえば feature_fraction だけをチューニングするステップ、num_leaves だけをチューニングするステップと続きます。これらの項目のうち、どの項目をチューニングすることが最適化において重要であったのでしょうか。LightGBM Tuner のチューニングのうち、それぞれのハイパーパラメータを調整したときの validation score の変化をバイオリンプロットによって確認した結果が以下の図となります。
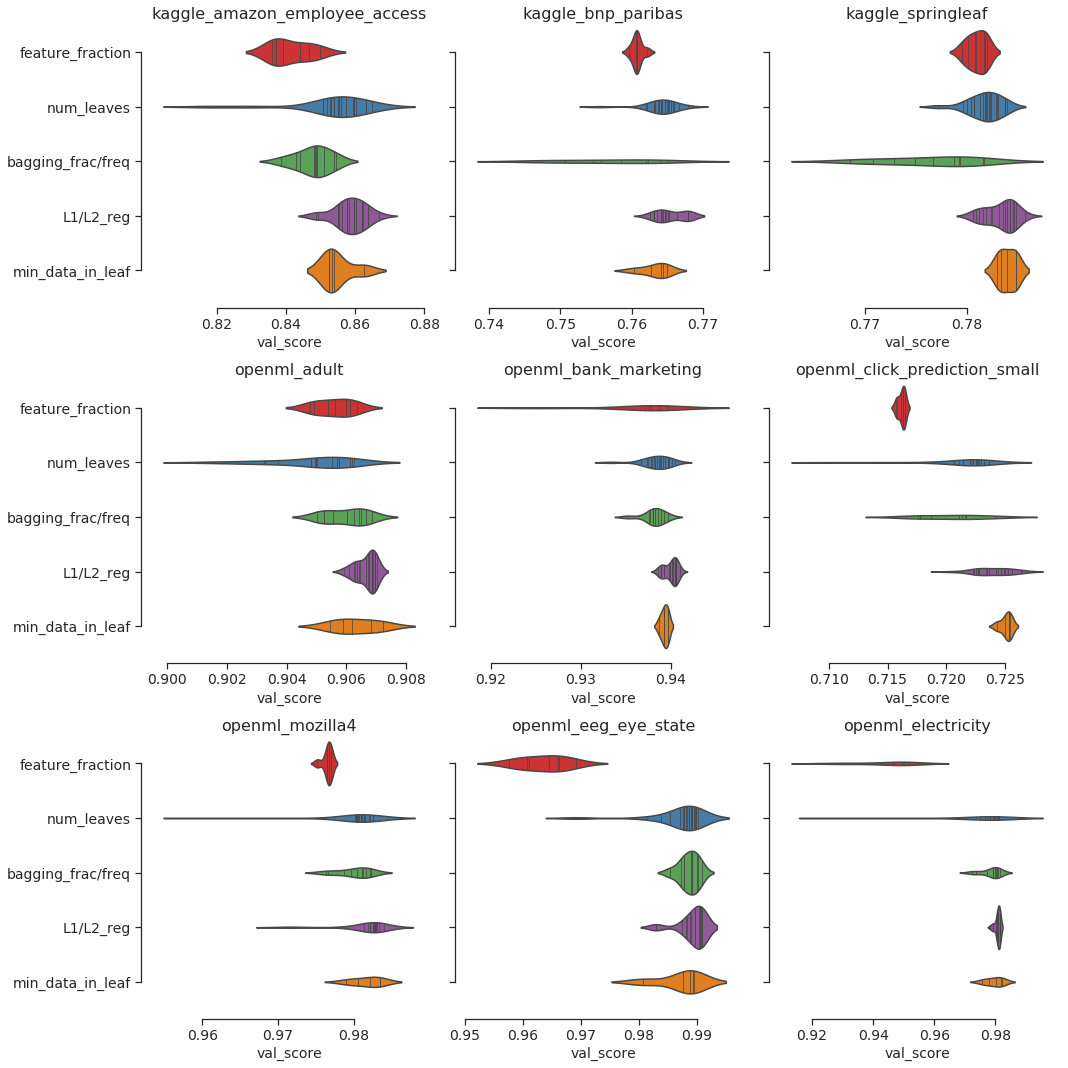
横長であるほど評価値の変化が大きい、すなわち項目をチューニングする上で影響が大きいことがわかります。データセットによって feature fraction, num_leaves, bagging_fraction および bagging_freq のいずれかによる変化が大きく、最も影響力の大きなハイパーパラメータはデータセットによって異なるという結果が確認できます。
現在の LightGBM Tuner はチューニングの順番や探索回数を固定しています。影響の大きいハイパーパラメータを探索し、重点的にチューニングできるよう工夫することで、さらなる改善ができるかもしれません。
まとめ
Optuna に導入した新しい拡張機能である LightGBM Tuner が効率的にハイパーパラメータをチューニングできることを紹介し、ベンチマークによって実験的にその性能を検証しました。加えて、実験結果を分析することでハイパーパラメータチューニングのどの項目が重要であるかはデータセットによって異ることを確認し、チューニングアルゴリズムのさらなる改善点について考察しました。
LightGBM Tuner の最大の利点はハイパーパラメータを何も考えることなく、手軽に 1 行の変更だけで試せる点です。実験的にも良い結果が得られているため、特に LightGBM のチューニングに慣れていないユーザーにとって、強力な助っ人となり得るのではないかと思います。
今後はアルゴリズムを更に改善したり、分散実行や Meta Learning の文脈で研究されている枝刈りなどの機能追加 [5] を検討し、更に便利にしていきたいと考えています。
参考文献
[1] Jean-François Puget. “Beyond Feature Engineering and HPO“, presented at Kaggle Days Paris
[2] 門脇大祐, 坂田隆司, 保坂桂佑, 平松雄司. “Kaggleで勝つデータ分析の技術”, 技術評論社
[3] James Bergstra, Rémi Bardenet, Yoshua Bengio, Balázs Kégl, “Algorithms for Hyper-Parameter Optimization”, In Proc. of the International Conference on Advances in Neural Information Processing Systems (NeurIPS’11).
[4] Stefan Falkner, Aaron Klein, Frank Hutter, “BOHB: Robust and Efficient Hyperparameter Optimization at Scale”, In Proc. of the 35th International Conference on Machine Learning (ICML’18).
[5] Johanna Sommer, Dimitrios Sarigiannis, Thomas Parnell, “Learning to Tune XGBoost with XGBoost”, arXiv:1909.07218