Blog
本記事は、2024年夏季インターンシッププログラムで勤務された佐々木 大夢さんによる寄稿です。
はじめに
こんにちは、2024 年度夏季インターンに参加させていただいた東京大学大学院修士 1 年の佐々木大夢です。今回のインターンでは、MN-Core 2 用コンパイラが持つ、実行時間を事前に推測するコンポーネントである emulate_time の性能向上に取り組みました。
MN-Core 2 の概要

図1 MN-Coreシリーズ
MN-Core シリーズ(図1)は深層学習を高速化させることに特化したプロセッサであり、PFN と神戸大学の共同開発により生まれました。MN-Core シリーズのアーキテクチャには以下のような特徴があります。
- 各々の processing element(以下 PE)がホストから直接受け取った命令列を同期して実行するため、非同期な動作のワークインバランスや同期のコストを削減しています。
- 条件分岐のない完全 Single Instruction Multiple Data (SIMD) モデルを採用しています。これにより、高密度の演算器配置による高い計算力と電力効率を実現しています。
これらの特徴により、MN-Core (MN-Core 2 ではなく初代の MN-Core)が搭載されたスーパーコンピュータ MN-3 は高い省電力性能を持ち、過去 3 度にわたってスーパーコンピュータの省電力性能ランキング Green 500 で世界 1 位を獲得しています。
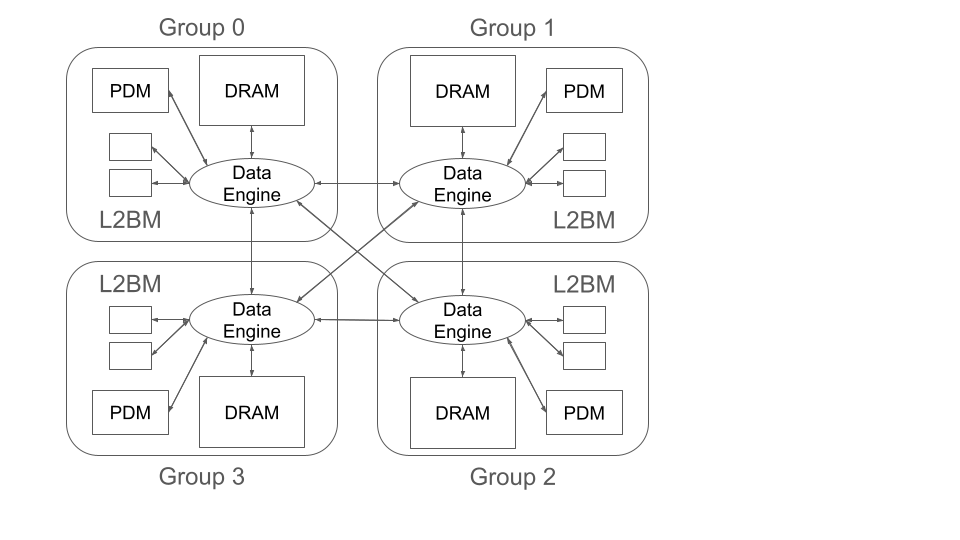
図2 MN-Core 2 の簡易構成図
次に、MN-Core 2 のメモリについて説明します。MN-Core 2 のチップ上には 4 つの Group というものが存在し、チップ上に複数存在する DRAM や SRAM、演算器が各々この Group に分散されて配置されています(図2)。
1 つの Group には複数の PE や演算器、ローカルメモリの集合である L2B が 2 個ずつ存在し、また、Group ごとに PDM という SRAM と DRAM が 1 つずつ付属しています。チップ内では、この PDM と DRAM、そして L2B がローカルに保持している SRAM、すなわち L2BM の 3 種のメモリ間で(Group 間をまたぐ転送も含めて)データ転送を行うことが可能です。より詳細な MN-Core 2 の仕様やアーキテクチャについては、以下をご参照ください。
MN-Core 2 用コンパイラと emulate_time
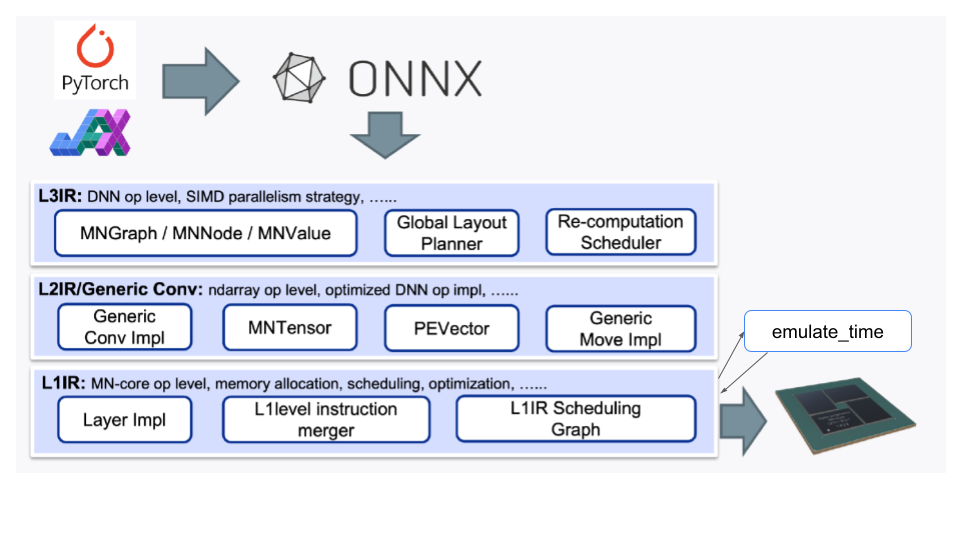
図3 MN-Core シリーズ向けコンパイラのソフトウェアスタック
PFN では MN-Core シリーズ向けのコンパイラが開発されています。これは、PyTorch や JAX などの高位言語から生成された ONNX という形式の計算グラフを、アセンブリに変換します。計算グラフレベルの操作からアセンブリレベルの命令列最適化までを効率的に行うために、図3のようにいくつかのレイヤーに分けてコンパイルを行っています。
ここから今回のインターンのテーマで主に扱った、コンパイラ内部のコンポーネントの 1 つ、emulate_time について説明します。アセンブリに含まれるほとんどの命令は、その実行サイクル数が固定、すなわち、どの命令に何サイクルかかるかが一意に定まります。しかし、DRAM-SRAM 間のデータ転送にかかるサイクル数は、一意に定まりません。これは主に以下の原因によるものです。
- データ転送命令は並行に複数実行することが可能ですが、並行に実行中の他のデータ転送命令の影響を受けて、スループットが変化します。より具体的には、同じパスを使用するか否かで並列に転送できるかどうかが変わったり、並列に転送している際には命令ごとのスループットが変化したりします。
- DRAM は MN-Core 2 のチップ本体とは異なるクロックで非同期的に動作しています。
- DRAM はメモリのリフレッシュ等、実行中定期的にアセンブリとは関係ない挙動が挟まることがあります。
このデータ転送に依存する後続の命令を発行する際、データ転送時間を過小に見積もると後続の命令を待たせてしまい、過大に見積もると後続の命令を過剰に遅らせてしまいます。そのためデータ転送時間の推測は、正確であるほど効率的なアセンブリを生成できます。
emulate_time は、この不定であるデータ転送のサイクル数を推測するコンポーネントであり、コンパイラは、emulate_time のサポートを受けることで、より効率的なアセンブリ命令列を生成することが可能になります。また、emulate_time は、直接アセンブリを入力にとり、その実行時間を推測することも可能になっています。
モチベーション
今回のインターンでは、emulate_time の推測精度を向上させることを目的としています。これにより、実行結果が同じまま、コンパイラが、より高速実行可能なアセンブリを出力することができるようになることを期待します。
MV 命令
精度向上の話に入っていく前に、MN-Core 2 のアセンブリにおける 3 種のメモリ(L2BM, PDM, DRAM)間のデータ転送命令である MV 命令について詳しく説明します。
mvxx/n<data length><tag> <src> <dst> (other instructions) wait <tag>
まず、MV 命令の使用方法を説明します。MV 命令にはいくつか種類が存在しますが、どの MV 命令もデータ転送元と転送先のメモリの種類、アドレスを指定して使用します。そして、この転送の終了を wait で待つことができ、MV 命令と wait の間で MV 命令を含めた他の命令を発行することが可能です。これにより、複数の MV 命令を並行して発行することができます。命令によっては転送に使用されるパスが異なることもあるので、実際に並列して実行可能な MV 命令の組み合わせもあります。具体的には、転送に使用するハードウェア上のパスが異なる転送命令は並列に実行可能だと考えられます。
次に、MV 命令のデータ転送にかかる時間について説明します。データ転送時間は主に 2 つの成分、スループット成分とレイテンシ成分からなります。スループット成分は、データ転送量をその命令のスループットで割ることで求められ、データ転送そのものにかかる時間と言えます。レイテンシ成分は、データ転送が始まるまでや終わった後、命令そのもののスループットとは別にかかる時間です。同じパスを使用する MV 命令を並行に発行した際、スループット成分は隠蔽されませんが、レイテンシ成分は隠蔽されると考えることができます。
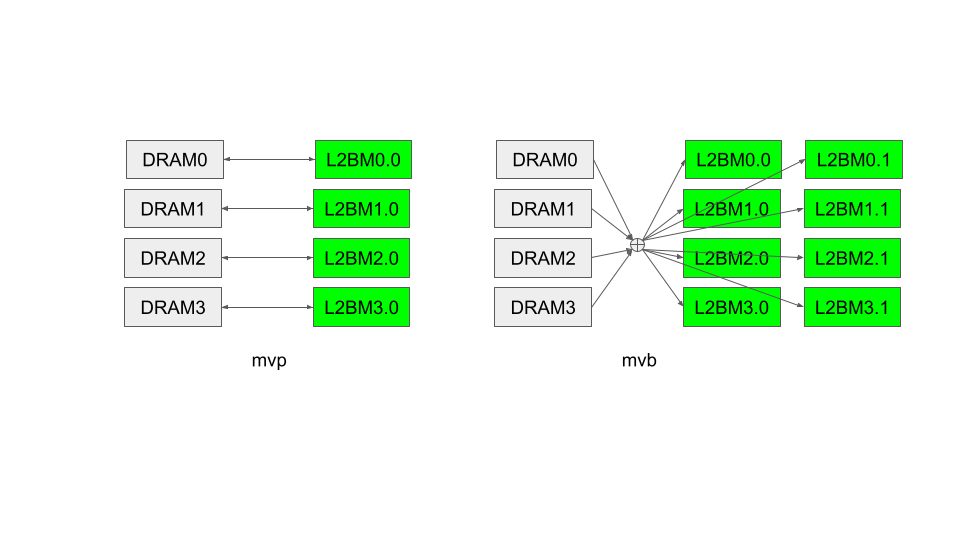
図4 個別転送 (mvp) と放送転送 (mvb)
最後に、この後の文中に出てくる mvp 命令と mvb 命令について説明します。図4においては、Group i に付属する DRAM を DRAMi、Group i の j 番目の L2BM を L2BM i.j の形で示しています。mvp 命令は同じ Group の DRAM と L2BM 間で並列にデータ転送を行う命令です。DRAM から L2BM への並列転送、L2BM から DRAM への並列転送どちらも同じ命令を使用します。また、mvb 命令は全ての Group に付属する DRAM からデータを読み出して結合し、全ての L2BM に放送する命令です。より詳細な仕様については前述したマニュアルをご参照ください。
計測
どのような場合に emulate_time によって推測された時間と実機における実行時間との間に差が生じるかを確認するために実験を行いました。具体的な実験内容としては、下記のように異なる MV 命令を交互に、かつ並行に実行される MV 命令数が最大 2 個になるように並べたアセンブリ(図5)の実行時間を emulate_time によって推測、また、実機によって計測しました。計測の際には、命令の種類と 1 命令あたりの転送データ量を変更しながら行いました。
mvp/n128i01 $d0 $lc0@.0 nop/3 mvb/n128i02 $d128 $lc128 nop; wait i01 nop/2 mvp/n128i01 $d256 $lc256@.0 nop; wait i02 nop/2 mvb/n128i02 $d384 $lc384 nop; wait i01 ……
図5 計測に用いたアセンブリ
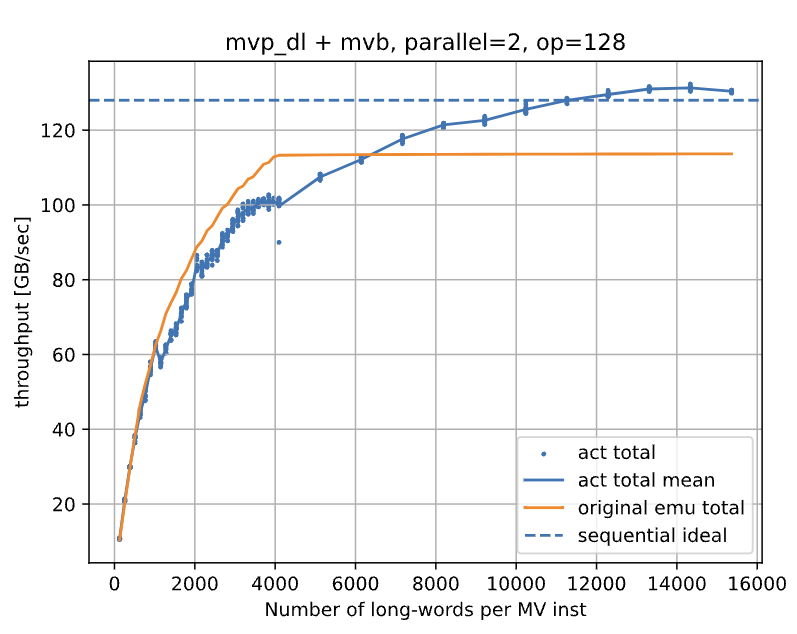
図6 計測結果(改良前)
いくつかの計測(推測)結果が得られましたが、そのうち、DRAM から L2BM にデータを転送する mvp, mvb 命令を交互に発行したアセンブリの計測(推測)結果を図6に示します。上のグラフは横軸を 1 命令あたりの転送データ量(正確には転送する長語数)、縦軸をアセンブリ全体でのデータ転送量を実行時間で割ったスループットとして、emulate_time が推測したスループットと実機で実行したスループットをプロットしています。act total (mean) が実機で実行したスループット、original emu total が emulate_time が推測したスループットを示しており、sequential ideal は、mvp 命令と mvb 命令のスループットの調和平均を示しています。グラフより、プロット1 命令あたりの転送データ量が大きい時に emulate_time が推測しているスループットが実機で実行したものよりも低い値に収束していることがわかります。補足ですが、グラフが 1 命令あたりの転送データ量が大きくなるにつれスループットが上昇し、ある値に収束しているように見えるのは、1 命令あたりの転送データ量が小さい時には全体の実行時間におけるレイテンシの割合が大きいため、実際の転送スループットよりも低い値が出ており、1 命令あたりの転送データ量が大きくなるとレイテンシが無視できる程相対的に小さくなるからです。
原因分析と変更結果
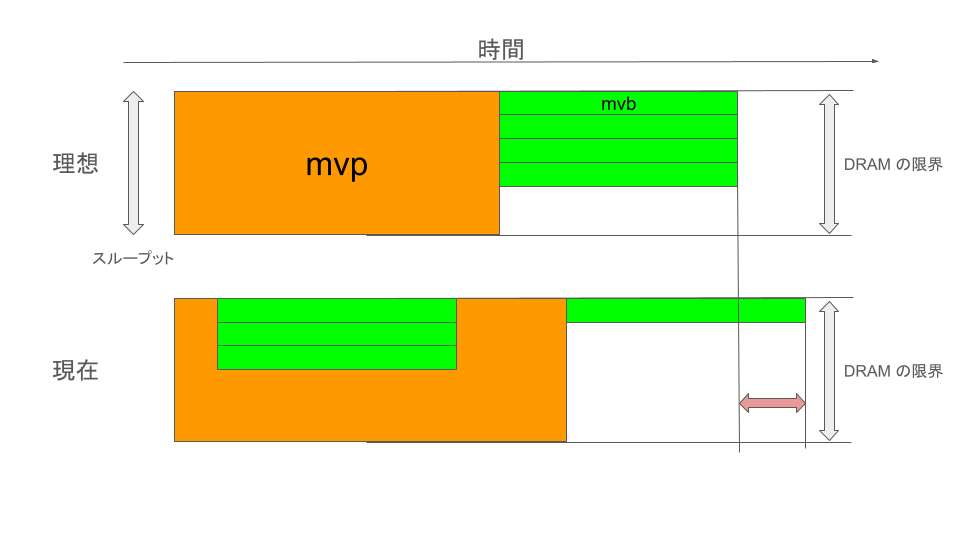
図7 各種転送命令の DRAM 占有率と転送時間の可視化
計測により判明した差の生じる原因を調べたところ、emulate_time においては、mvb 命令と mvp 命令が並行に発行された際、mvb 命令によるデータ転送が mvp 命令の転送スループットを圧迫し、実行時間が伸びると推測されていました。しかし、1命令あたりの転送データ量が大きいところでは、実機実行時間は全命令のスループット成分の総和とほとんど等しく、上記のような現象は起こってないようであることがわかりました(図7)。
そこで、どちらの命令でも十分なスループットを出せるように emulate_time に変更を加えたところ、以下のような結果になりました。
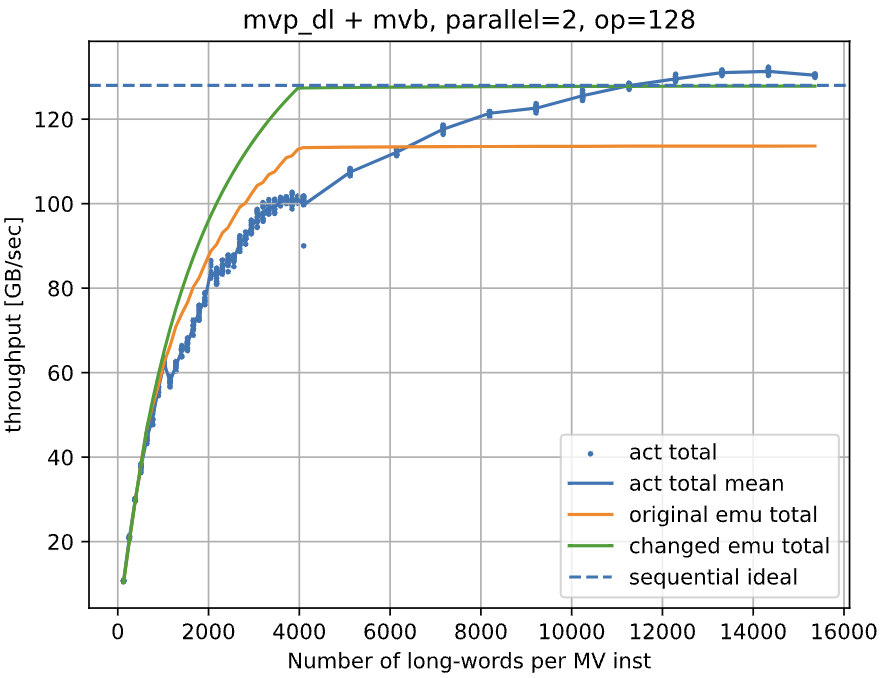
図8 計測結果(改良後)
図8より、前述のスループットを低く推測してしまっていた問題を解消できたことがわかります。しかし、1 命令あたりの転送データ量が小さい時の差は大きくなってしまっており、問題全てが解消されたわけではありません。これの原因は今のところよくわかっておりません。ただ、このブログには載せなかった実験として、同じ命令を複数並行に発行した時には同様の問題は起こらなかったので、例えば並行に命令を発行していても、レイテンシ成分が隠蔽されない命令の組み合わせが存在する可能性等が考えられます。また、1 命令あたりの転送データ量が大きい時に実機のスループットが ideal の線を超えていますが、このことにより、同じパスを使用するデータ転送命令でも、並列実行できないとは限らないことがわかります。
まとめと今後の展望
今回のインターンでは、実行時間を推測するコンポーネントである emulate_time の推測性能向上に取り組みました。今後は、今回行った他の計測結果も参考にすることで、emulate_time の性能をより向上させていくことが可能だと考えています。
最後になりましたが、メンターの樋口さん、サブメンターの押川さん、他 MN-Core チームの皆様には、日々のミーティングからインターン全体の進行まで大変お世話になりました。この場を借りて厚くお礼申し上げます。
Area



