Blog
本記事は、2019年インターンシップとして勤務した長谷川太河さんによる寄稿です。
2019年度インターンに参加していた長谷川太河です。インターン期間中、私は推論時に計算資源の制限に応じてモデルの構成を変更できる手法を研究しました。
モチベーション
現実問題では、適用する問題によって推論時における計算資源やタスクからくる制約(例:要求される推論時間、計算量、メモリ)が異なるため、最適なニューラルネットワーク(NN)モデルの構成は異なります(以下このモデルの構成のことをconfigurationと呼びます)。例えば低レイテンシが求められるタスクにおいて、利用できる計算資源が限られているエッジデバイス上の環境では計算量の大きいNNモデルを使用することは一般的にできません。一方で、推論時の計算資源やタスクに応じて、最適なモデルを個別に準備するのは大きな労力がかかります。この問題を解決するために、モデルの入力画像サイズ(resolution)、層の数(depth)、output channelの数(width)、convolution kernelのsizeなどをモデルの学習後に変更可能にし、推論時の計算資源に合わせてこれらを最適なサイズに伸縮する方法が複数提案されています[1, 2, 3, 4]。
私はインターン期間を通じて、これら既存研究の追試や、いくつかの実験を行いました。実験では、タスクの違い(例: 画像認識, 物体検知) による最適なモデルのconfigurationの傾向の違いや既存研究から発展・改良の余地があると感じたkernel sizeの変更方法に関する検証を行いました。
関連研究
Width Slimmable Network
Width Slimmable Networkとは各Convolution層のoutput channel数(width)を訓練後に変られるnetworkです。widthの変え方により3種類のnetworkが提唱されています。
一つ目は Slimmable Neural Networks[1]です。これは、訓練前に指定したwidth ratio (例:ベースとなるモデルのwidth ratioを\(\times1.0\)として\(\times0.25\)、\(\times0.5\)や\(\times1.0\))のいずれかに切り替えることができるnetworkです。各layerで違うwidth ratioを指定することはできず、全てのlayerで共通のwidth ratioを用います。
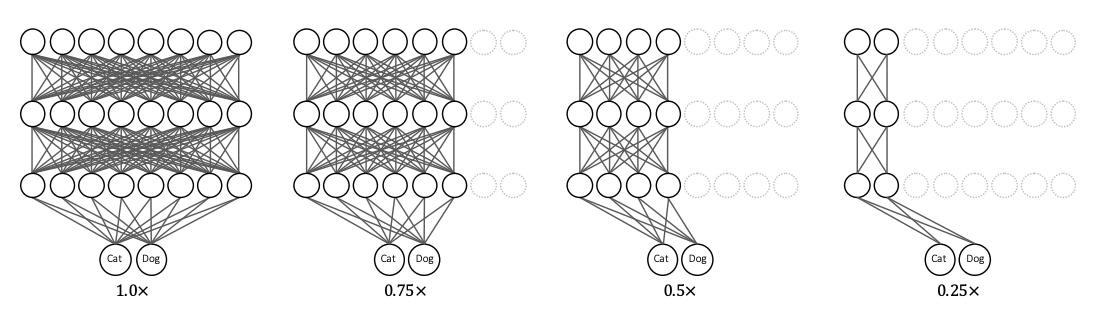
Figure 1 : width ratioの図解
[1]より参照
任意のwidth ratioを設定することで生じる問題点はbatch normalizationのmean averaged statisticsがwidth ratioの違いにより一貫しなくなることです。Auto Slim[3]は推論時にbatch sizeを大きくし、そのbatch内で平均と分散を求めることで、各width ratioに適したmean averaged statisticsを近似しています。この手法をAuto Slim[3]ではGreedy Slimmingと呼んでいます。
これら3つの論文で共通して利用されている学習方法として、inplace distillationとsandwich ruleがあります。inplace distillationとは、width ratioが\(\times1.0\)のfull network以外のネットワークの学習に用いる損失関数として、full networkの出力を教師とした損失関数を用いる方法です。sandwich ruleとは毎iteration、ランダムなwidthをもつsubnetworkに加えて、必ずfull networkと一番小さいsub-networkの両方を学習させるテクニックです。この二つの学習方法を用いることで、Width Slimmable Networkの精度を向上できるとこれらの論文は主張しています。
Once for All
Width Slimmable Networkはwidthのみを可変にしていましたが、Once for All[4]は、widthだけでなく層の数(depth), 入力画像サイズ(resolution), kernel sizeも推論時に変更できます。MobileNetV3[12]をベースに学習しており、ImageNet[6]で高い精度を達成しています。Once for All[4]では、Progressive Shrinkingという学習方法を提案しています。Progressive Shrinkingとは、まずfull networkを学習させ、その後kernel \(\rightarrow\) depth \(\rightarrow\) widthの順に可変にしfine tuneしていく学習方法です。
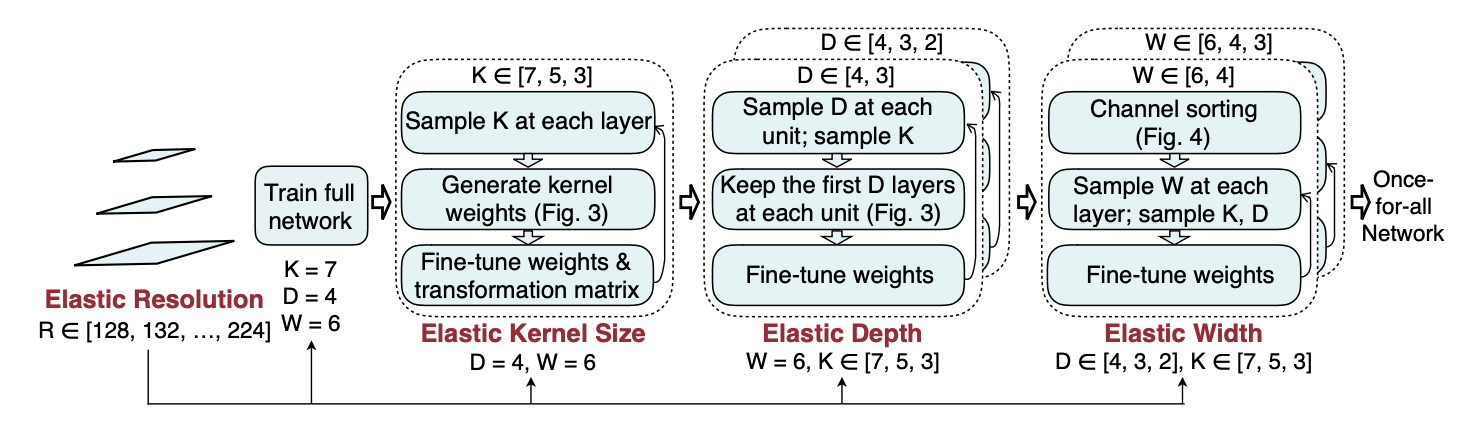
Figure 2 : Progressive Shrinking
R : Resolution, K : Kernel size, D : Depth, W : Width
[4]より参照
検証内容
Width Slimmable Network[1,2,3]やOnce for All[4]の追試を行うとともに、対象とするタスクによってどのようなネットワークのconfigurationが選ばれる傾向があるかについて調べました。また、既存のconvolution kernel sizeの切り替え方は複雑だと感じたため、他のよりシンプルな切り替え方についても検証を行いました。
Kernel sizeの変え方
Convolution kernel sizeを切り替えるとは、学習後にconvolution kernel sizeを許容される計算資源の制約に応じて\(7\times7\), \(5\times5\), \(3\times3\)のいずれかに切り替えることを意味します。しかし各convolution layerで各サイズについて別の重みを持たせるとパラメーター数が増え、学習に時間がかかるため、その3つで重みを共有しつつkernel sizeを切り替えられる手法が用いられています。
まず考えられる方法はconvolution kernelをcropする方法です(Figure 3の一番上)。具体的には、最も大きい\(7\times7\)の重みを用意し、\(5\times5\)に切り替える際には、\(7\times7\)の中心の\(5\times5\)をcropし、それを\(5\times5\)のconvolution kernel とする方法です。同様に\(5\times5\)の中心の\(3\times3\)をcropし、それを\(3\times3\)のconvolution kernel とします。
cropはカーネルサイズを切り替える単純な方法ですが、Once for All[4]では、まず\(7\times7\)の重みを用意し、cropした\(5\times5\)の重みを線形変換することで\(5\times5\)の convolution kernel に変換します。同様に、\(5\times5\)のconvolution kernel の中心の\(3\times3\)をcropし線形変換をすることで\(3\times3\)のconvolution kernelを得ます (Figure 1の一番下)。この線形変換も学習を行います。
単にcropするのではなく、cropした重みに線形変換を行う理由として、「\(7\times7\), \(5\times5\), \(3\times3\)のconvolution kernelでは果たすべき役割が違うため、重みのスケールや分布が違うべきであるかもしれない」とOnce for All[4]では述べられています。
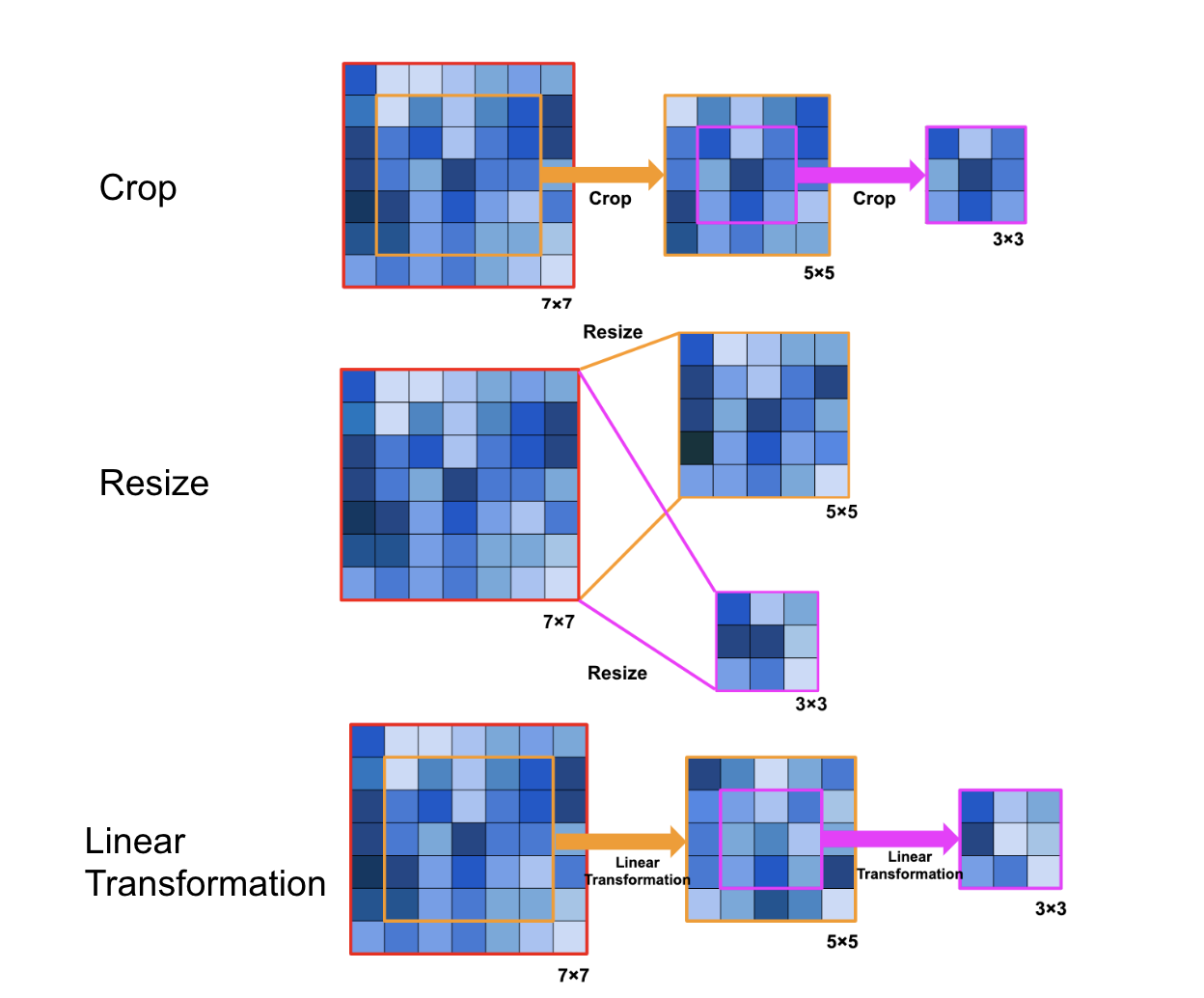
Figure 3 : convolution kernel sizeの変更の仕方
上段 : crop, 中段 : resize, 下段 : linear transformation
cropと線形変換以外にもkernel sizeを変更する手段はあります。それはFigure 3の中段にあるkernel sizeを\(7\times7\)から\(5\times5\), \(3\times3\)にresizeする手法です(具体的にはkernelの重みをchainer.functions.resizeでresizeします)。具体的には、Figure 4のように、各convolution layerでconvolution kernelだけでなく入力画像もresizeすることで、convolution kernelと入力のsizeが常に同じ割合になるようにし、kernel sizeを変えてもconvolution kernel の果たすべき役割が変わらないようにします。例えば\(3\times3\)のときの入力画像サイズが\(224\times224\)である場合、\(7\times7\)のconvolution kernelを適用するときは入力画像サイズを7/3倍の\(522\times522\)にアップサンプルし、それに\(7\times7\)のconvolution kernelを適用します。同様に、\(5\times5\)のconvolution kernelの際は、\(7\times7\)のconvolution kernelを\(5\times5\)にresizeし、入力画像も\(224\times224\)の5/3倍の\(373\times373\)にアップサンプルし畳み込みを実行します。\(3\times3\)のconvolution kernelに切り替える際は、\(7\times7\)のconvolution kernelを\(3\times3\)にresizeし、入力画像サイズは\(224\times224\)を用います。これを各convolution layerのkernelと入力に対し適用します。各convolution layerの出力に関しては、元の入力サイズである224*224 に畳み込み処理を行ったときと同じ出力サイズになるようにダウンサンプルをすることで、\(3\times3\), \(5\times5\), \(7\times7\)の畳み込み処理の出力サイズを同じにします。
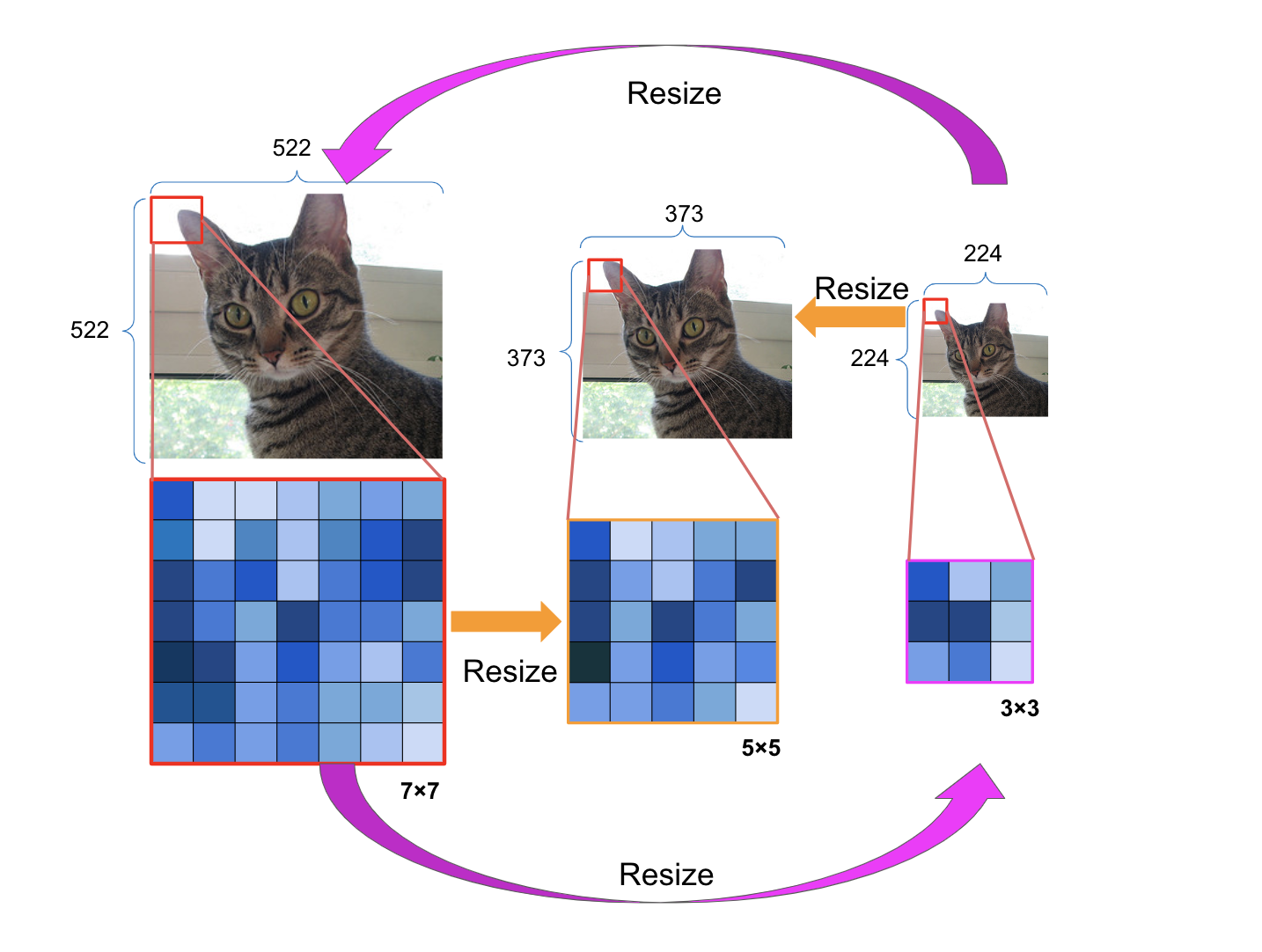
Figure 4 : resizeによるconvolution kernel sizeの変更の仕方の詳細
Once for All[4]では、線形変換を学習し、それを用いてconvolution kernel sizeの変更を行う方法が用いられていますが、線形変換を学習する必要のない、より単純なresizeとcropによるconvolution kernel sizeの変更の仕方とどの程度の違いが生まれるかが検証されていなかったため、検証を行いました。
学習の方法
まず、kernel sizeの変更の仕方による違いを説明するため、kernel sizeだけを可変にしたモデル(以下KR-Netsと呼びます)の学習アルゴリズムを紹介します。Width Slimmable Networks[1,2,3]と同様に、inplace distillationとsandwich ruleを適用しました。

Algorithm 1
Algorithm 1のように、1回のiteration内で、まずfull networkの損失を計算し、その後sandwich ruleに従い一番小さいnetworkとランダムなkernel sizeをもつnetworkの損失を計算します。その際、inplace distillationを用い、一番小さいnetworkとランダムなkernel sizeをもつnetworkの損失はground truthのラベルではなくfull networkの出力である、\(\hat{y}\)を教師として計算します。sandwich ruleとinplace distillationの両方を用いた学習アルゴリズムが、どちらか少なくとも一方を使わない学習アルゴリズムよりもKR-Netsの精度が向上しました(詳細はKR-Netsの実験の章を参照)。
しかし、Once for All[4]ではground truthラベルを用いて計算した損失とfull networkの出力を用いて計算した損失の重み和をとって、それを損失としています。Once for All[4]内では、その損失を用いる理由は述べられていませんが、代わりに、その理由はSelf Distillation Amplifies Reguralization in Hilbert Space[5]が参考になると考えています。この論文によると、distillationはある種のregularizationなので、全ての学習iterationでinplace distillationを適用するより、最初の何iterationのみにdistillationを適用し、残りのiterationはground truthのラベルを用いた方が良いと述べられています。実際、私が実験した際も、最初の30epochだけinplace distillationを適用し、残りはground truthのラベルを用いて学習するというアルゴリズムの方が、全てのepochでinplace distillationを適用して学習したモデルより精度が1%ほど高くなりました。
KR-Netsの実験
実験の設定
各convolution層でkernel sizeを\(3\times3\), \(5\times5\), \(7\times7\)のいずれかからランダムに選択し、様々なconfigurationのKR-Netsで評価します。その際、GFLOPsと精度を計測し、あるGFLOPsの範囲内(例: 4.3~4.5GFLOPs)で精度が一番高いときの結果をプロットしていきます。ただし、一様にランダムな選び方で各層のkernel sizeを選択すると探索範囲の中間あたりの計算量をもつKR-Netsばかりが選択されてしまうので、kernel size選択時に、\(3\times3\)に大きい重みをかけたり、\(7\times7\)に大きい重みをかけたりすることで探索範囲の中で小さい計算量や大きい計算量をもつKR-Netsも選択されやすくしています。データはImageNet[6]を用いています。
ResNet50をベースにした場合
Figure 5はkernel sizeをcropで切り替えるKR-NetsをResNet50[7]をベースに学習した結果を、学習アルゴリズム毎にプロットしています。sandwich ruleとinplace distillationの両方を利用して学習したモデルの結果が、sandwich ruleのみを利用したモデルとinplace distillation, sandiwch ruleを共に使わないnaiveな学習をしたモデルと比較して精度が高いことがわかります。以上から、sandwich ruleとinplace distillationは、KR-Netsでも有用であることが確認できます。
Once for All[4]の論文ではcropでkernel sizeを切り替えるとスケールや分布が適切にならないので精度が落ちる可能性があると書いてありました。しかし、Figure5を見ると、sandwich ruleとinplace distillationの両方を用いたモデルの精度は76.0%~76.6%の間にあり、ベースとなるResNet50[7]の精度76.5%と比較しても精度が大きく落ちていません。この理由はdepthwise convolutionと普通のconvolutionの表現力の差だと考えられます。
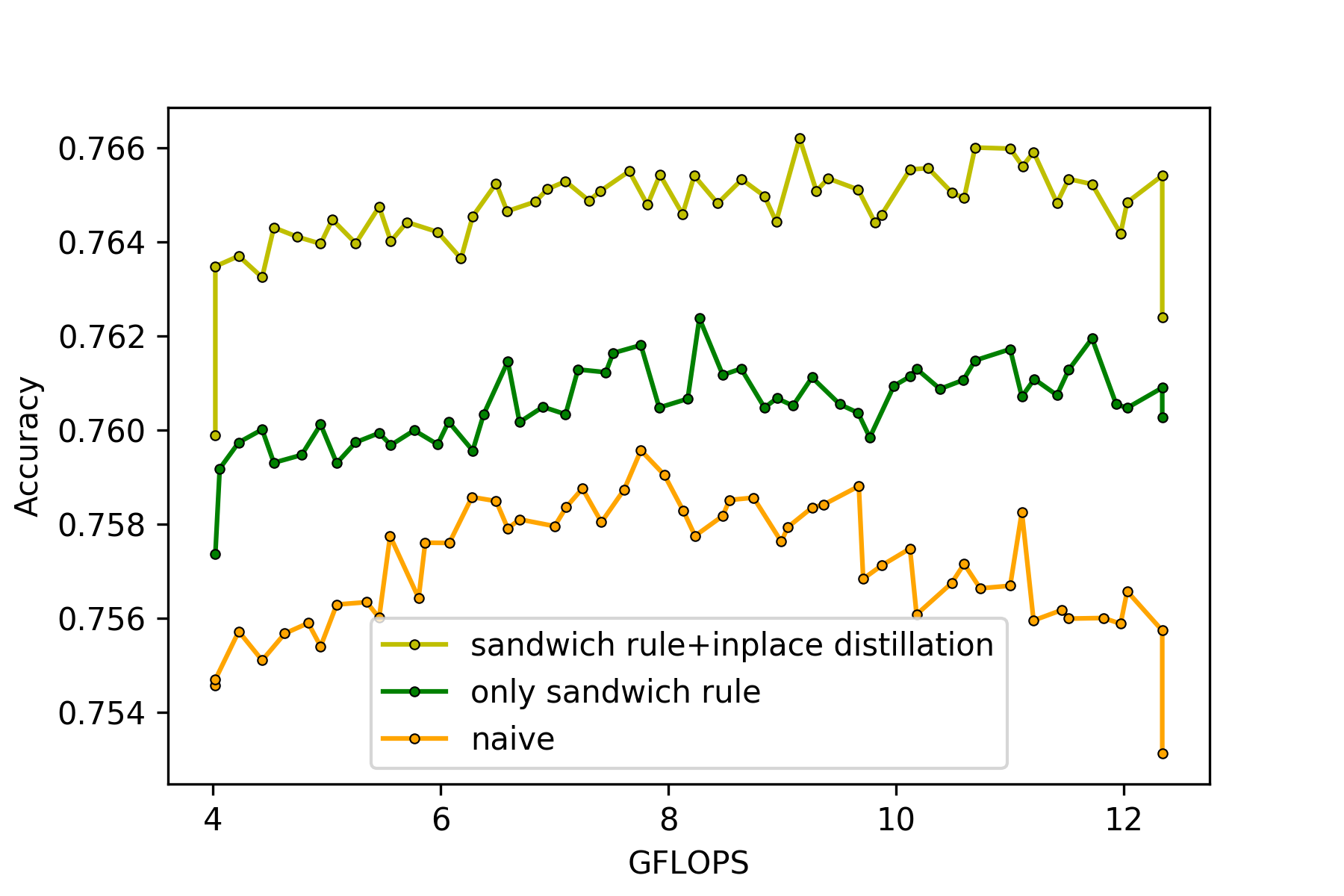
Figure 5 : cropでkernel sizeを切り替えることのできるResNet50を様々な学習アルゴリズムで学習した結果
*ベースとなっているResNet50のGFLOPsは3.9GFLOPs, 76.5% top1 accuracy
MobileNetV2をベースにして学習した場合
MobileNetV2[8]をベースに、kernel sizeの切り替え方をcrop, resize, 線形変換の3パターンで比較しました。学習方法はinplace distillationとsandwich ruleを適用しています。普通のconvolutionではcropによるkernel sizeの切り替えでも精度が落ちませんでしたが、depthwiseのconvolutionを用いているMobileNetV2では、cropによるkernel sizeの切り替えを用いると精度が落ちることを確認しました(Figure 6の左側、ベースのMobileNetV2[8]は0.31gFLOPsで72%のtop1 accuracy)。
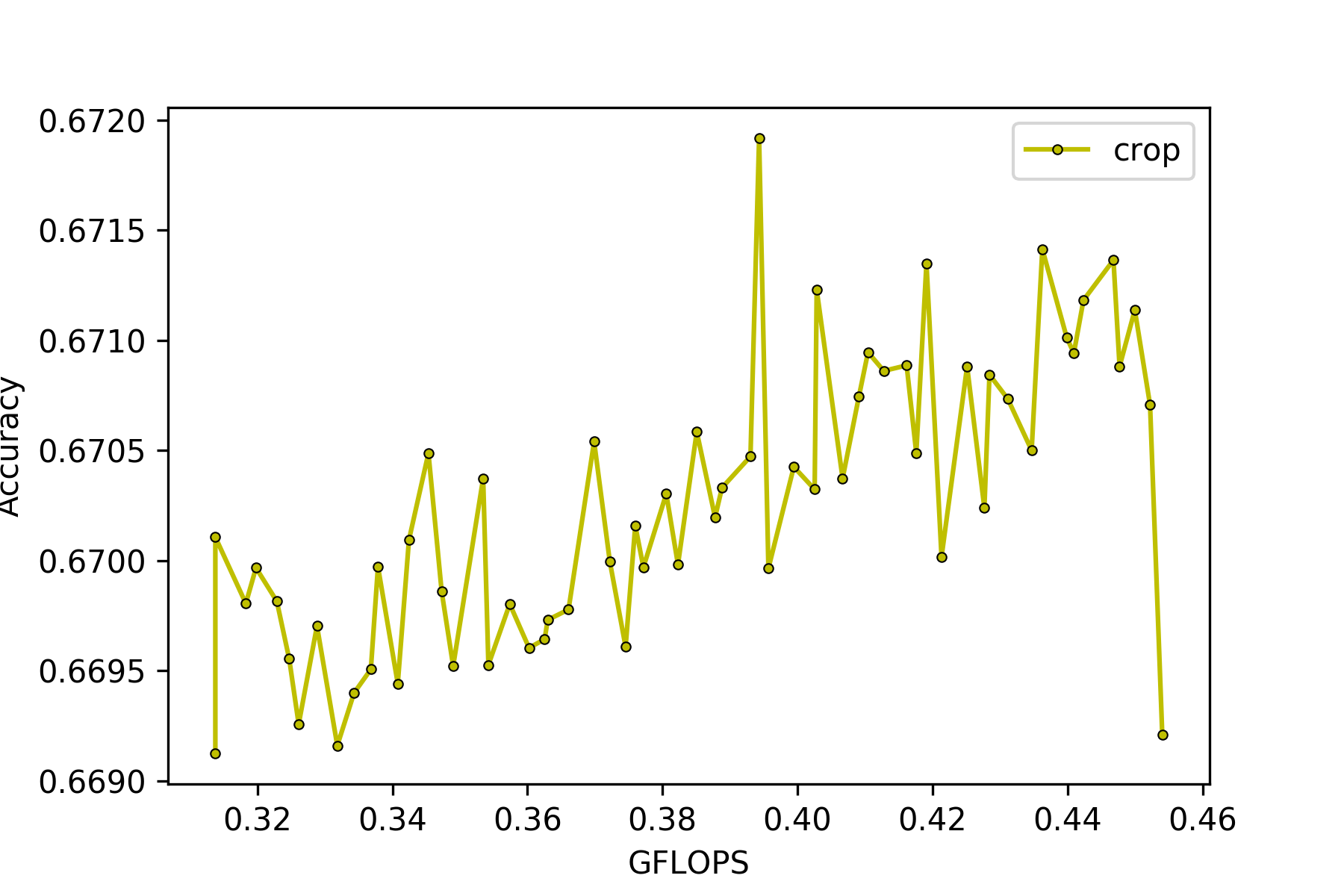
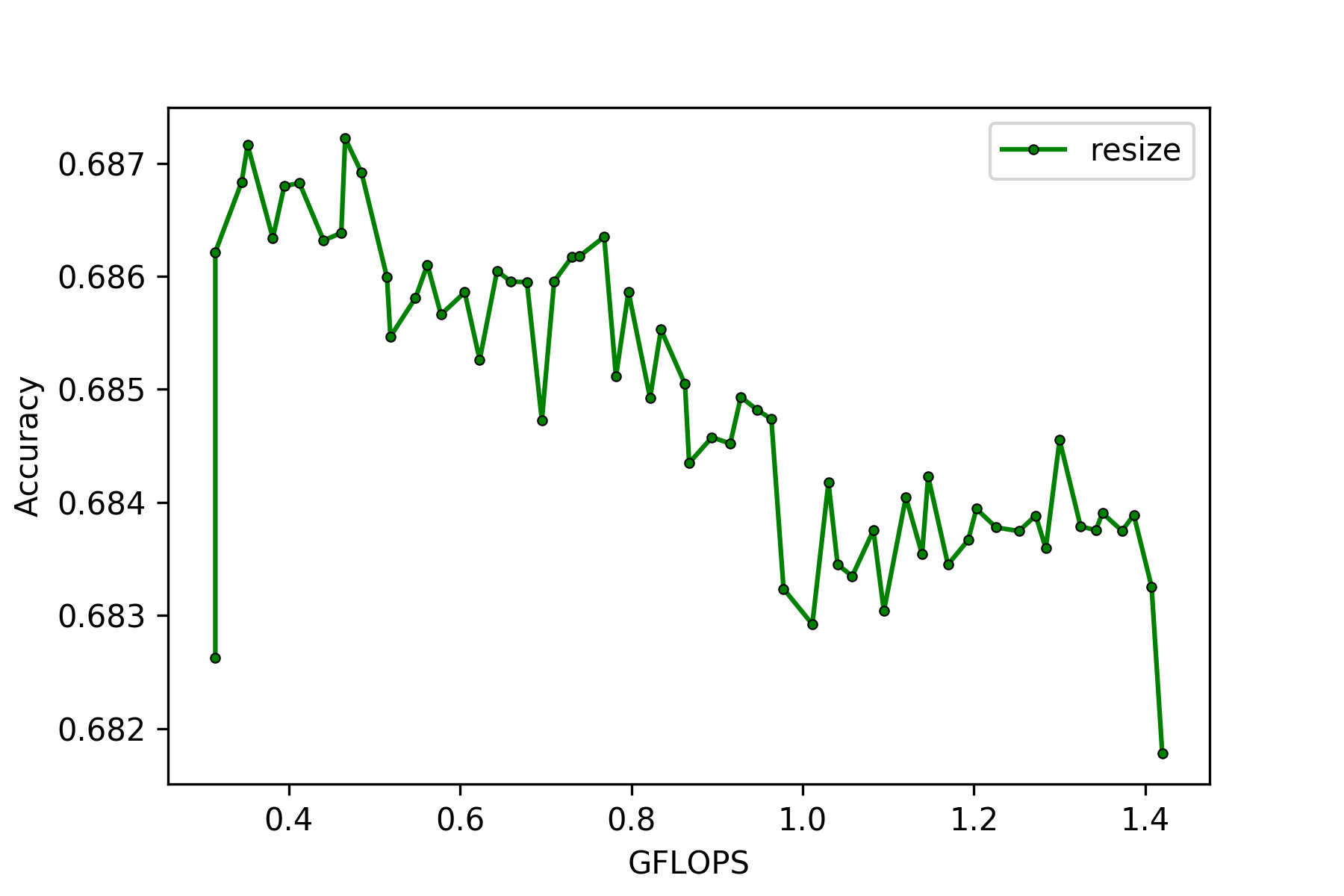
Figure 6
左側:Cropでkernel sizeを変更した場合, 右側:Resizeでkernel sizeを変更した場合
*ベースとなっているMobileNetV2の計算量は0.31GFLOPs, 72% top1 accuracy
*resizeのGFLOPsはkernelのresize分の計算量も含まれている
Figure 6を見てわかるように、resizeや線形変換を用いてkernel sizeを切り替えられるKR-Netsはcropでkernel sizeを切り替えられるKR-Netsと比較して精度が2~3%以上あがります(線形変換はFigure 6にはありませんが、全てのconvolution layerのkernel sizeが\(3\times3\)のとき:68.9%, \(5\times5\)のとき:69.2%, \(7\times7\)のとき : 69.5%のtop1 accuracyでした)。Resizeを用いてkernel sizeを切り替えられるモデルの精度が右肩下がりになっている理由の一つとして、単純なアップサンプルで画像サイズを大きくしても本質的な情報量は変わらないため、\(7\times7\)の畳み込みと\(3\times3\)の畳み込みで抽出可能な情報量がほぼ変わらないことが考えられます。
タスク毎による良いモデルの構成
私は、cropでkernel sizeを切り替えるKR-Netsを、さらに各layerでwidth ratioも自由に選択できるようにしました。これをResNet50[7]に適用させ学習したモデルを以下ではKernel Resizeable & Width Slimmable ResNet50(KR&WS-ResNet50)と呼びます。
このKR&WS-ResNet50を、ImageNet[6]のimage classificationタスクとCOCO[9]のobject detectionタスクに適用しました。object detectionに関してはImageNet[6]で学習済みのKR&WS-ResNet50をFPN-FasterRCNN-ResNet50[10]のbackboneとして用い、このモデルをElastic-FPN-FasterRCNNと名付けます。
Elastic-FPN-FasterRCNNは、毎iteration、backboneのkernel sizeやwidthをランダムに選択してから損失を計算しfinetuneを行い学習をします。COCO[9]で評価したところ、Elastic-FPN-FasterRCNNのmmAPは30%前後とベースとなっているFPN-FasterRCNN-ResNet50[10]のmmAP 37.1%と比べ低くなりました。
精度は低くなったものの、与えられた計算資源の制限下で良い精度を達成するモデルのconfigurationにはどのような特徴があるかを検証することはモデル設計の一助になるという点で有益です。以下では、image classificationとobject detectionというタスクの違いにより、良い精度を達成するモデルの構成の特徴にどのような違いがあるかを重点的に解説します。
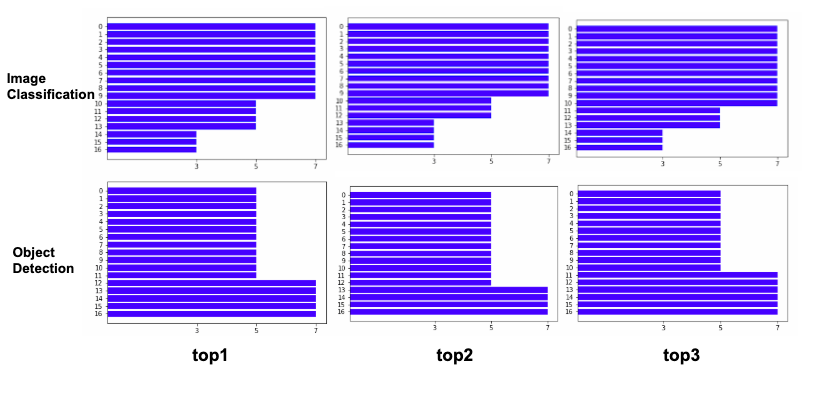
Figure 7 : タスク毎による精度の高かったモデルの構成top 3
横軸はkernel sizeを表しており、左から\(3\times3\), \(5\times5\), \(7\times7\)です。縦軸は上が入力層で下が出力層です。
上段:画像認識、下段:物体検出
Width ratioとkernel sizeを各layerで変更し、様々なconfigurationでKR&WS-ResNet50とElastic-FPN-FasterRCNNの評価をした中で(これを便宜上Step1と呼びます)、精度が一番高かった3つのモデルのconfigurationを示したものがFigure 7です。Figure 7にあるnetworkは、全てのlayerのwidth ratioが\(\times1.0\)のとき、精度が一番高くなったので、Figure 7からwidthに関する図は省略しています。Figure 7を見ると、画像認識のタスクでは入力層に近い層に\(7\times7\)のconovlution層が固まっており、出力層に近付くにつれて小さいkernel sizeが選好されていることがわかります。一方、物体認識のタスクにおいては、入力層に近い層に\(3\times3\)のconvolution層が固まり、出力層に近付くにつれて大きいkernel sizeが選好されていることがわかります。
また、Step1で良い精度を達成したconfigurationでモデルを再学習させたElastic-FPN-FasterRCNNと、Step1であまり良い精度が出なかったconfigurationのモデルを再学習させたElastic-FPN-FasterRCNNとを比較したところ、依然としてStep1で良い精度を達成したconfigurationのモデルの方が良い精度を達成できることも確認できました。
Kernel sizeだけでなくwidth, depth, resolutionも可変にしたnetwork
Once for All[4]では、Progressive Shrinkingを用い学習ましたが、全ての要素(width, depth, kernel size, resolution)を最初から同時に可変にしつつも、最初は可変にできる範囲を狭くし、次第に広くするという学習方法(Figure 8)も考えられたので、MobileNetV2[8]をベースにImageNet[6]で学習しました(ただしOnce for AllがMobileNetV3をベースに実験していたことに気付かず、今回はMobileNetV2をベースに実験を進めてしまいました)。

Figure 8 : 次第に可変にできる範囲を広げる方法
R : Resolution, K : Kernel size, D : Depth, W : Width
Once for All[4]がMobileNetV3[12]ベースでD=4, W=6, K=3, R=224のとき76%のtop1 accuracyであったと報告しているのに対し、MobileNetV2をベースとして可変な範囲を学習とともに広げる手法を試したところ、D=4, W=6, K=3, R=224のとき74%のtop1 accuracyでした。ResNet50[7]をベースに学習もしましたが、kernel sizeの変え方がcropの場合で16日、線形変換やresizeの場合で26日ほど学習時間がかかるため、インターン期間中では実験を完了できませんでした。一方、MobileNetV2[8]をベースに学習したところ、6~8日ほどで学習ができました。
まとめと今後の展望
ResNet50[7]をベースにしたKR-Netsは、kernel sizeをcropで切り替えても、ベースであるResNet50[7]からの精度の低下はあまり見られなかったため、単純なcropによるkernel sizeの切り替えで十分です。一方、MobileNetV2[8]で学習を行う際は、cropよりresizeや線形変換でkernel sizeを切り替えた方が良いと思われます。
またresizeによりkernel sizeを切り替えるKR-Netsの精度はcropよりは良いですが、入力画像もresizeしているため、\(5\times5\)や\(7\times7\)を用いた際の計算量はベースのモデルと比較して大きくなってしまいます。さらにOnce for All[4]は入力画像サイズとkernel sizeを別個に変えていましたが、私が考案したresizeの場合はどちらも同時に変えている点に違いがあります。
KR&WS-Netsを画像認識や物体検出のタスクのそれぞれに適したモデルの構成の特徴は、画像認識では入力層に近い層に大きなkernel sizeが選好され、一方、物体検出では出力層に近い層に大きなkernel sizeが選好されることでした。
Once for All[4]は学習にかかる計算時間が長く、またアーキテクチャに関する勘違いもあったため、十分に検証できたとは言いづらい点はありますが、kernel sizeの変更方法や学習方法に関する実験からは、線形変換によるkernel sizeの切り替えやProgressive Shrinkingが有効であることが示唆されました。
今後どのように研究を発展させられるかについて最後にいくつか箇条書きします。
Progressive Shrinikingではkernel \(\rightarrow\) depth \(\rightarrow\) widthの順で可変にできる要素を増やし学習していましたが、その順番が果たして最適であるか。
Once for All[4]とEfficientDet[11]で述べられているBiFPNとWeighted Feature Fusionを組み合わせることで、detectionやinstance segementationで良い結果が得られるか。
kernel size, depth, width, resolutionそれぞれを変更した際の、それぞれの要素にどのような関係性があるか。特にEfficientNet[13]ではkernel sizeと他の3つの要素の関係性には触れていないので、そこを重点的に調べていきたいです。
実験ベースの研究であり、多くの実験をインターン期間中に行いました。そのような実験をストレスなく行うことができる環境、そして研究の機会を用意してくださったPFNには大変感謝しております。特に、メンターの岡田さん、前田さん、ミーティングによく参加してくださった柳瀬さんには大変お世話になりました。ありがとうございます。このインターンで学んだことを今後活かして社会に還元していきたいです。
(補足)
*1 convolution layerを3層使ったモデルをベースにして学習した場合、 inplace distillationやsandwich ruleがよく利き、ResNet50[7]ベースのモデルより精度の上昇幅が大きかったです。
*2 ResNet50[7]は元がほぼ\(3\times3\)のconvolution layerで構成されているので、\(5\times5\)や\(7\times7\)にkernel sizeを変更するとGFLOPsが増加
してしまいます。そのため、ベースのResNet50[7]と比較できるような計算量をもつモデルを学習するにはkernel sizeだけでなくwidthやdepthなども可変にする必要があります。
参考文献
[1] J. Yu, L. Yang, N. Xu, J. Yang, and T. Huang, “Slimmable neural networks,”, 2018.
[2] J. Yu and T. Huang, “Universally slimmable networks and improved training techniques,”, 2019.
[3] J. Yu and T. Huang, “AutoSlim: Towards One-Shot Architecture Search for Channel Numbers,”, 2019.
[9] http://cocodataset.org/#home
[11] M. Tang, R. Pang, Q. V.Le, “EfficientDet: Scalable and Efficient Object Detection”, 2020.
[13] M. Tan, Q. V.Le, “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks”, 2019
メンターからのコメント
メンターを担当したPFNの岡田です。
深層学習による成果が研究レベルを超えて様々な場面で利用されるようになってきました。一方で、そうした中でも深層学習モデルの学習には高価な計算資源が必要で、実際の現実の問題を解決するアプリケーションに個別に組み込むハードルはまだまだ高いのが現状です。特に、最適なモデルを得るためにはアプリケーションが動作する環境に合わせてモデルの設計を調整し、推論時のレイテンシと精度を確認しながら再度学習し直すことを何度も繰り返す必要があり、このことがモデルを組み込む上で大きな障害となっています。
今回、長谷川さんにはこうした問題に対処するための方法について研究してもらいました。SlimmableNetを元に、チャンネル数だけでなくカーネルサイズを変更できるようにするというところから始めてもらい、長谷川さん自身のアイデアも試しながら比較のためのOnce for Allなどの再現実装も行ってもらいました。その結果、今後の研究の方向を定める上で有益な知見をいくつも見つけることができました。
PFNでは単に深層学習モデルの精度を追い求めるだけではなく、現実に役立たせるという視点からモデルにどういった性質が必要かを考えそれを実現する方法についても引き続き研究・開発していきます。
