Blog
本記事は、PFN2024 夏季インターンシッププログラムで勤務された奈良亮耶さんによる寄稿です。
こんにちは。PFN2024 夏季インターンシップに参加していた東京大学修士1年の奈良亮耶です。大学では画像処理を取り扱う研究室に所属しており、私自身は敵対的攻撃に関する研究を行っています。その他、Web開発が好きで、個人でWeb開発の勉強を行ったり、アルバイトや個人プロジェクトでWebサービス開発のプロジェクトに携わったりしていました。
この度、私はMatlantisチームにおいて、「Kubernetes環境におけるLog Alertの実現」というテーマで取り組みました(Matlantisは、クラウドサービスとして株式会社 Preferred Computational Chemistryから提供されている汎用原子レベルシミュレータです)。大学での研究とは全く関係がなく、また今まで経験してきたWeb開発とも全く異なる技術領域だったのですが、メンターの方々の助けもあり、非常に多くのことを学ぶことができました。
本ブログでは、今回のインターンシップで私が取り組んだ内容について紹介します。
背景
サービスの開発・運用に関わる業務の一つとして、監視があります。監視を実現するには、システムの状態に関する情報を収集したり、システムの異常などの際に通知 (Alert) したりする必要があります。また、システムの内部状況を把握する代表的なデータとして、Metrics(メモリ使用量・アクセス数など)・Log・Traceが使われます。
まず、インターンシップ開始前にMatlantisにおいて実装されていたMetrics・Logの監視について説明します。
Metricsの監視には、Prometheusを用いています(図1)。Exporterがクラスタ内のメトリクスを収集し、Prometheus serverがexporterからMetricsをpullして、AMP (Amazon Manged Service for Prometheus) にMetricsをPushします。そしてAMPのAlertmanagerが、記録されたMetricsからシステムの異常を発見した場合、SNS (Amazon Simple Notification Service)経由でSlackやSentryにアラートを送信します。
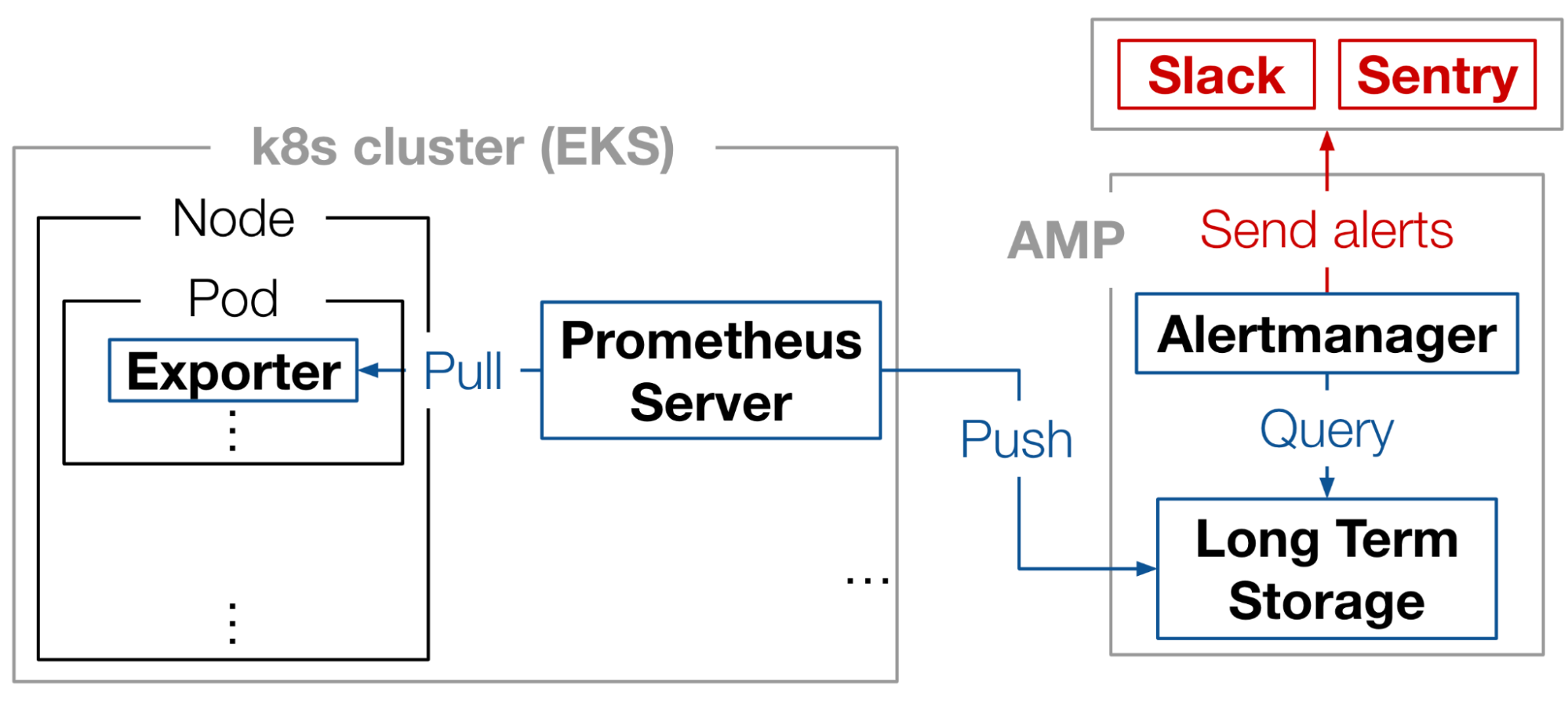
図1: MatlantisにおけるMetricsの監視システム
Logの収集には、Lokiを用いています(図2)。MatlantisではLog収集エージェントとしてFluent-bitを利用しています。Fluent-bitは各Nodeにdaemonsetとして配置されており、そこからLokiのdistributerにLogが送信され、Ingesterを経由し、最終的にS3 backendのLog DBに書き込まれます。
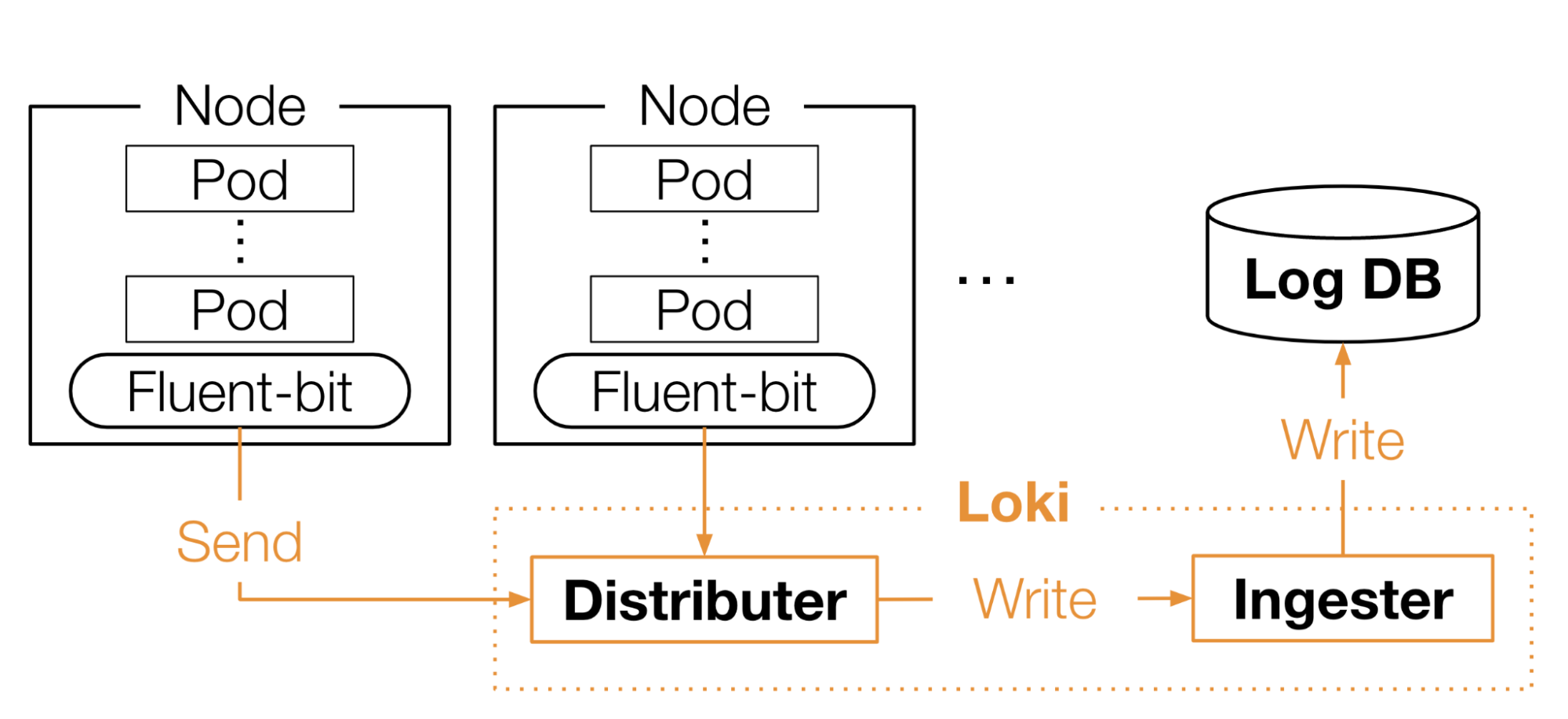
図2: MatlantisにおけるLogの収集
Matlantisにおける、監視のアーキテクチャの全体像は図3のようになっていました。
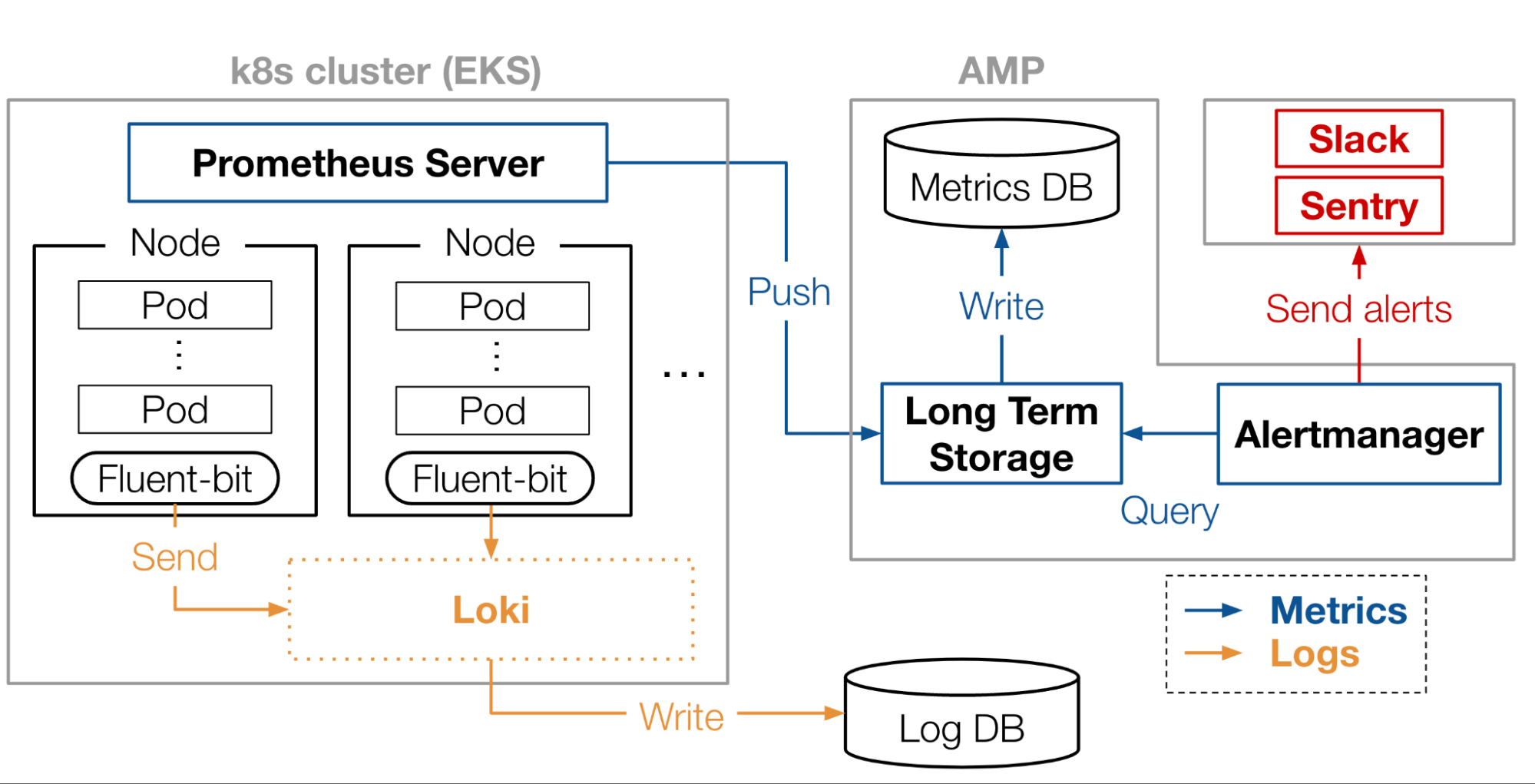
図3: Matlantisの全体アーキテクチャ
課題・成果
本インターンシップ開始前のMatlantisの監視には、LogのAlertが実装されていませんでした。システムの異常の中には、Logにのみ現れる異常もあります (例: OOM Kill)。しかし、MetricsのAlertは行っているものの、LogについてはAlertを行っておりませんでした。つまり、Logにのみ現れる異常を開発者が見逃してしまう可能性がありました。
Logにのみ現れる異常を既存の仕組みで通知しようとすると、図4のように、対応するError logを吐いている箇所でAlertのための修正を加える必要があります。しかし、これではContainer内部のコードを直接改変する必要があり、アプリケーションのリリースやデプロイといった作業が発生します。しかも、Matlantisでは多くのOSSを用いており、それらにAlertのための修正を加えることは、OSSのメンテナの意向にも影響されるため現実的ではありません。
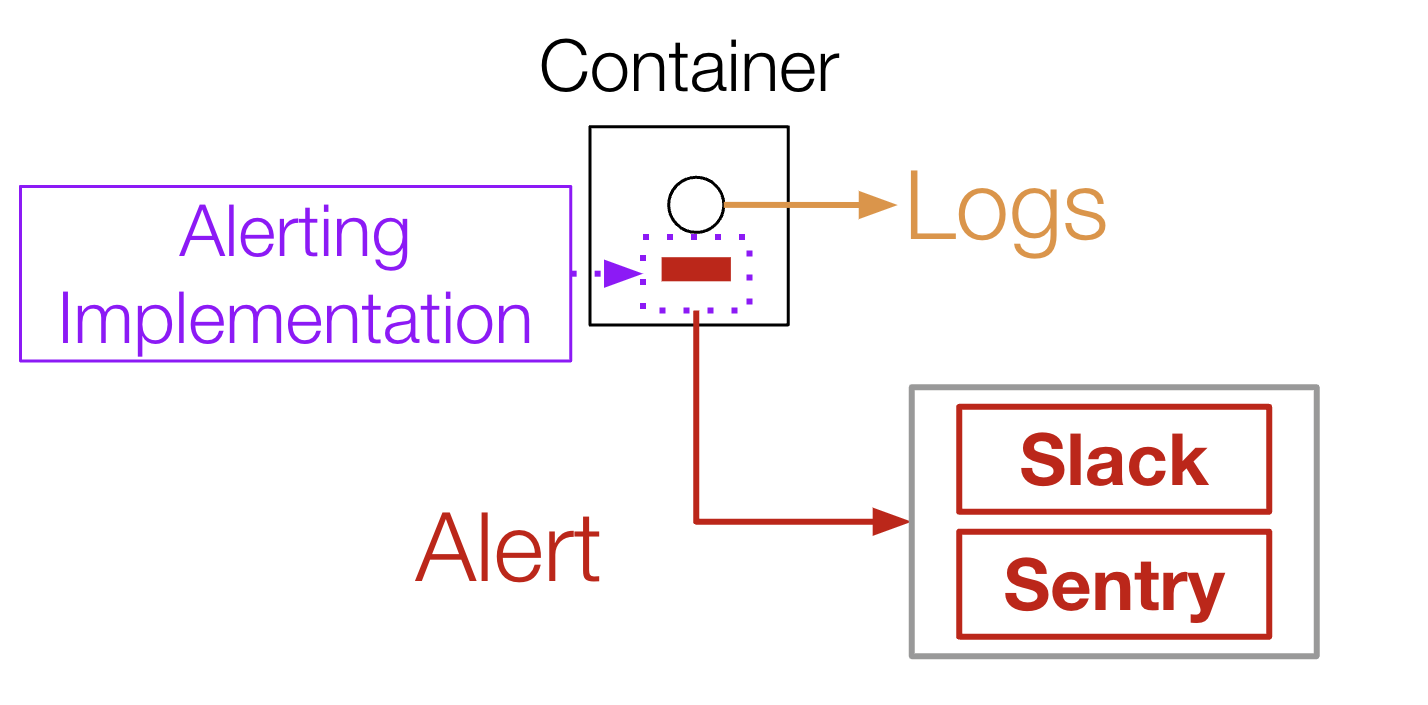
図4: コード追加によるAlert
そこで、本インターンシップにおいて、私はMatlantisの環境上にLog Alertを実装しました。Log Alertでは、Containerから出力されたLogを元にAlertを行うので、Container内部のコードを改変せずにAlertを行うことができます。
私が実装したLog Alertは、すでにMatlantisの本番環境に組み込まれています。
技術詳細
今回は、LokiのRulerというコンポーネントを活用した方法を採用しました(図5)。LokiのRulerには、Recording ruleというものを設定し、それに基づいてLogを集計してPrometheusのMetricsに変換することができます。たとえば図5のようなRecording ruleを設定すると、”ruler-test”というnamespaceのLogのうち、”Reconciler error”という文字列を含むものを5分間収集し、1秒あたりの個数に変換します。このようにして得られたMetricsをAMPに書き込みます。これにより、AMPのalertmanagerでLogアラートが実現できます。
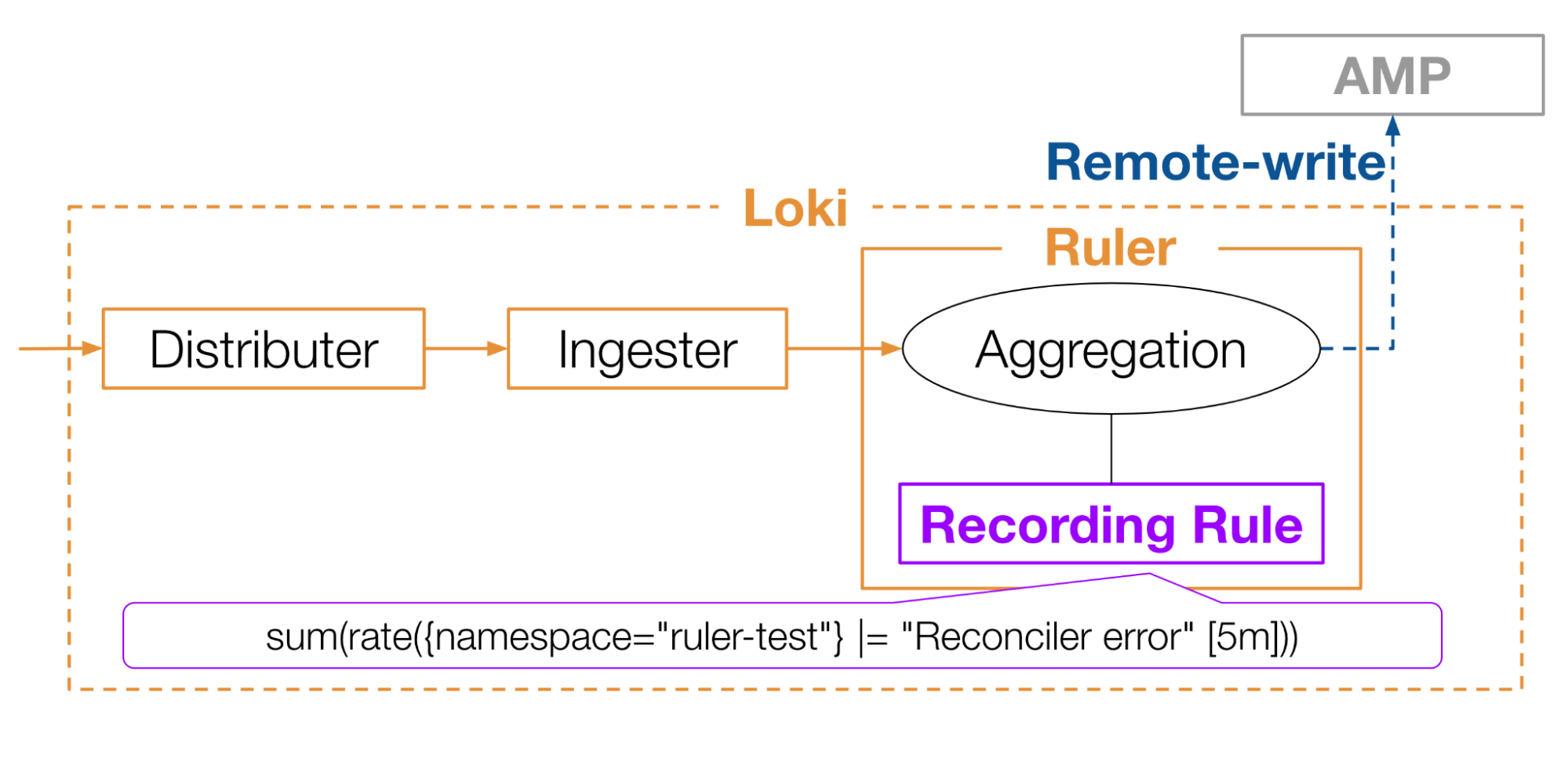
図5: Loki Rulerを使ったログのメトリクス化
最終的な目標のアーキテクチャの全体像は図6になっています。Loki RulerからAMPへの書き込みにより、すでに構築されているMetrics Alertの仕組みと繋がったことが分かると思います。
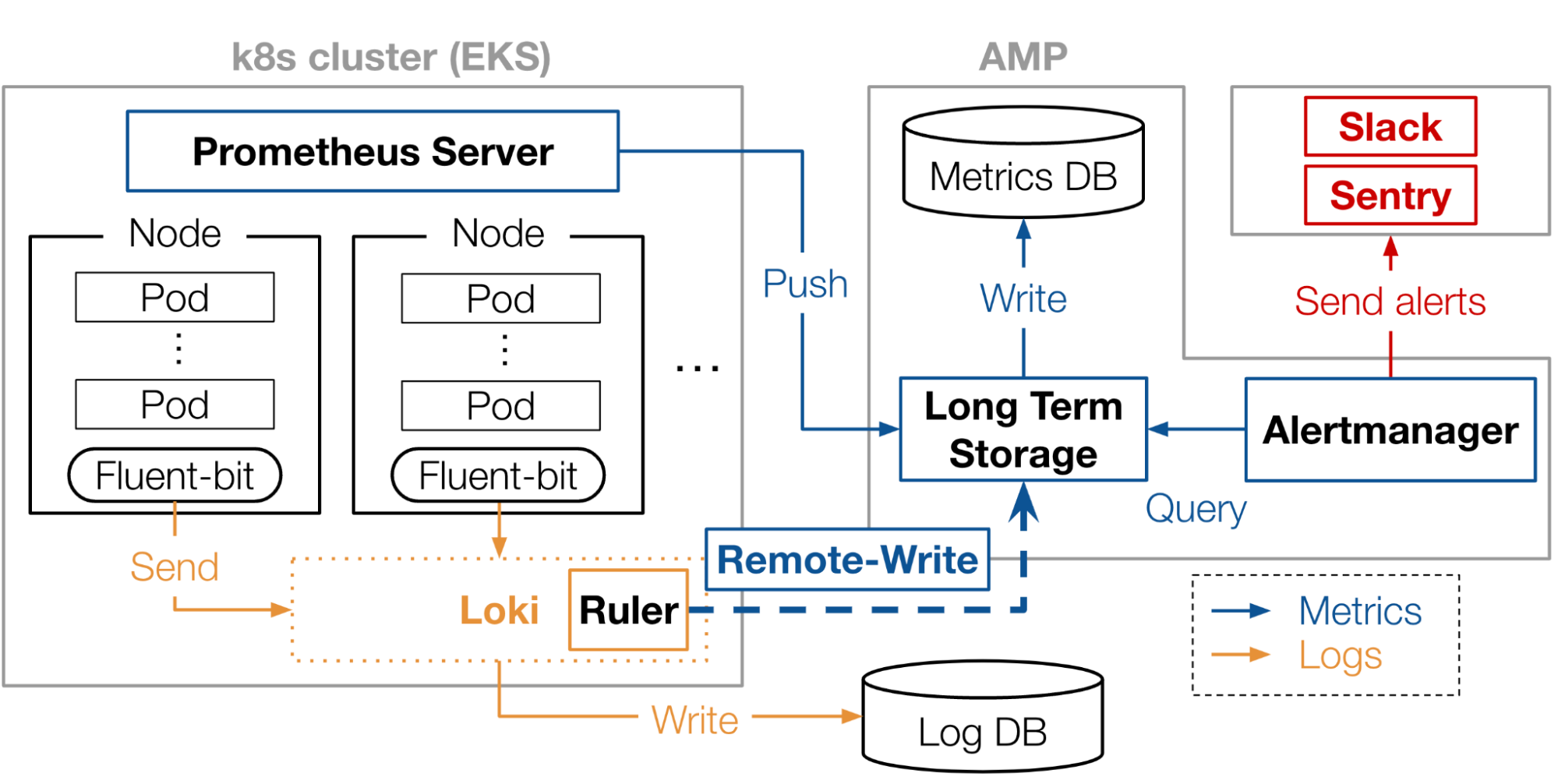
図6: 目標のアーキテクチャ
Lokiの内部にAlertmanagerを実装して、Lokiから直接Log Alertを行うことも可能です。しかし、MatlantisではすでにAMPのAlertmanagerを活用してMetrics alertを実装していました。なので、Lokiに新たにAlertmanagerを立ててしまうと、図7左のように、全く同じAlertの仕組みを2箇所で設定することになり、保守が難しくなります。そこで、今回私はLokiのAlertmanagerを使わず、AMPのAlertmanagerにLog Alertを任せることで、Metrics alertとLog alertを集約するようにしました(図7右)。
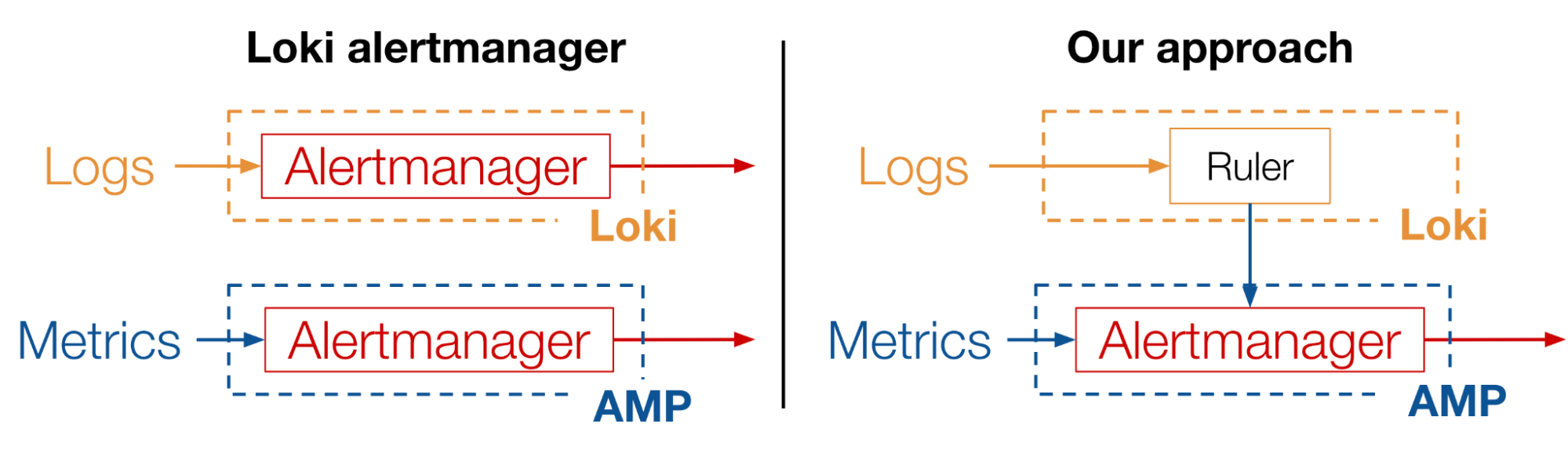
図7: LokiのAlertmanagerを使う方法と、今回の実装方法の比較
デプロイメント
ここまで、Loki Rulerを用いたLog Alertの方法について解説してきました。ここからは、LokiのRulerをどのようにデプロイするかについて解説します。
Rulerのデプロイメントを設定する際に気をつけなければいけないことは、可用性 (High availability) と拡張性 (Scalability) を保つことです。つまり、障害が起きてもLogアラートの仕組みを維持し(High availability)、多くのRuleを設定できるようにする (Scalability) 必要があります。
本インターンシップでは、図8のようにRulerをデプロイしました。まず、High availabilityを保つため、podAntiAffinityを適切に設定し、各Rulerを異なるNodeに1つずつ配置します。これにより、Nodeが1つ落ちても、他のNodeにあるRulerが代わりを担うことで、Metrics変換の仕組みを保ち続けることができます。
次に、Scalabilityを保つため、Rulerのsharding機能を有効化し、各RulerにRecording ruleを水平分割します。これにより、Recording ruleをたくさん設定し、多くのMetricsを計測する場合でも、RulerのPod1つあたりの負荷を下げることができます。
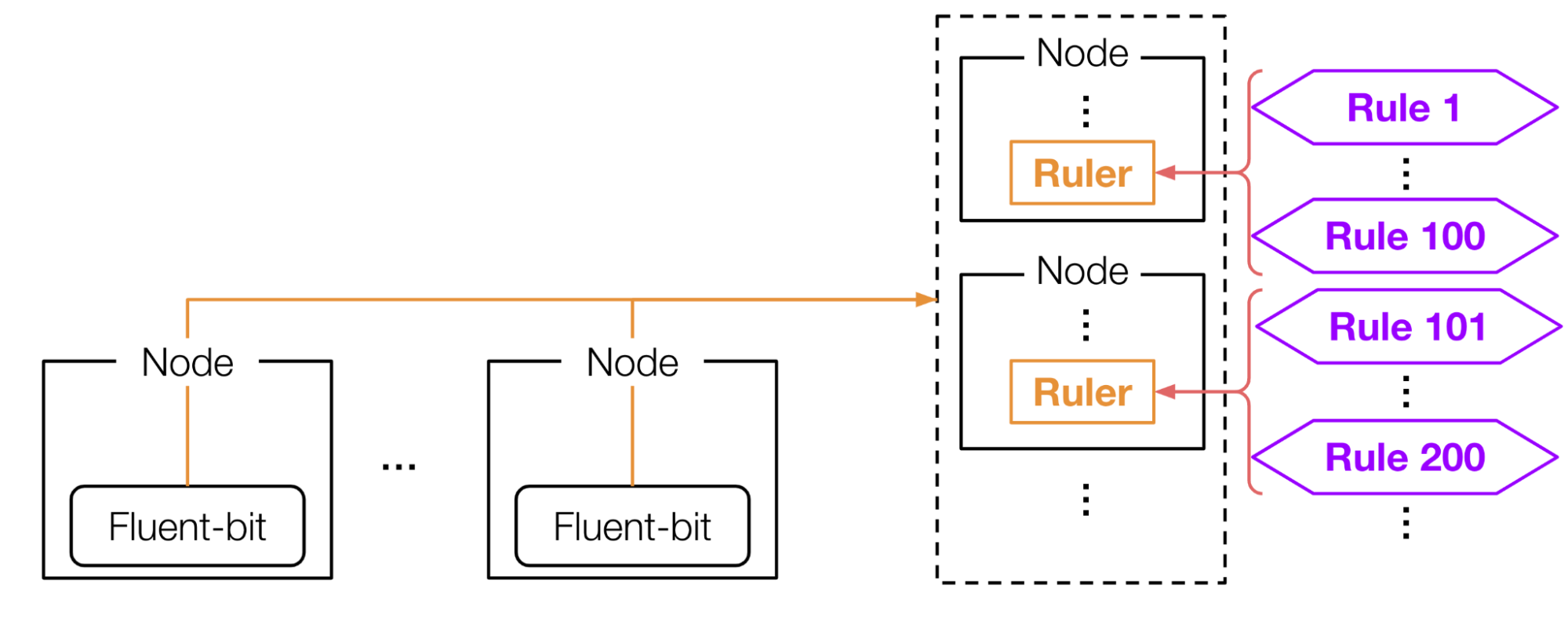
図8: Recording ruleの分割
しかし、ここで1つ疑問が沸きます。Recording ruleを水平分割した場合、Availabilityは保たれるのでしょうか。例えば、図9のようにあるNodeが落ちた際に、そのノード内のRulerのpodが担当しているRecording ruleはどのRulerのPodにも割り当てられず、継続的なLog alertが実現できていないように思えます。
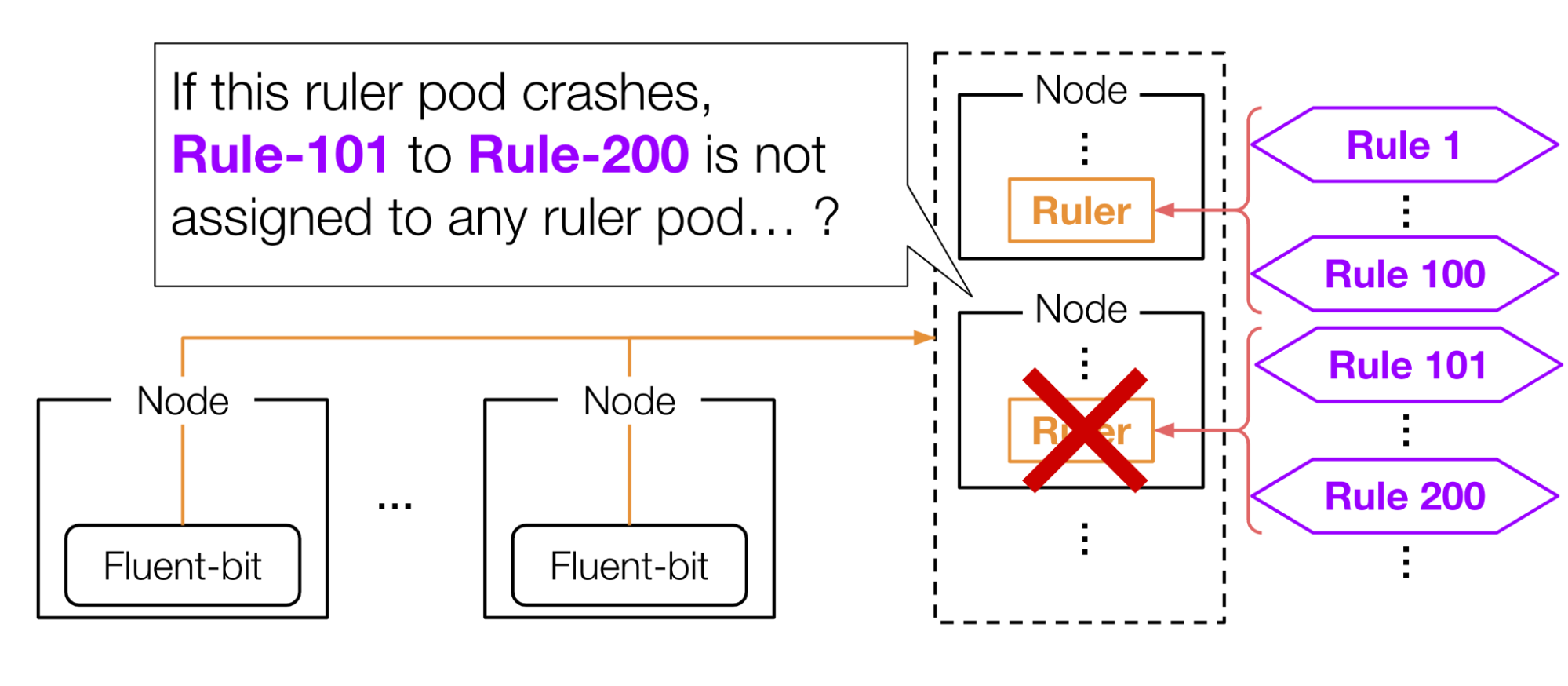
図9: Rulerが落ちた場合
しかし、Loki Rulerはこの課題を回避するため、Recording ruleをRulerに割り当てる際に、Consistent hashingというアルゴリズムを用いています。
(1) Rulerに対するRuleの割り当て方
それぞれのRulerとRuleのハッシュ値を元に、剰余計算を行います。そしてその結果を元に、リング状のハッシュテーブル上に図10のように配置します。このとき、各Ruleは、時計回りで見て一番近いRulerに割り当てられます。
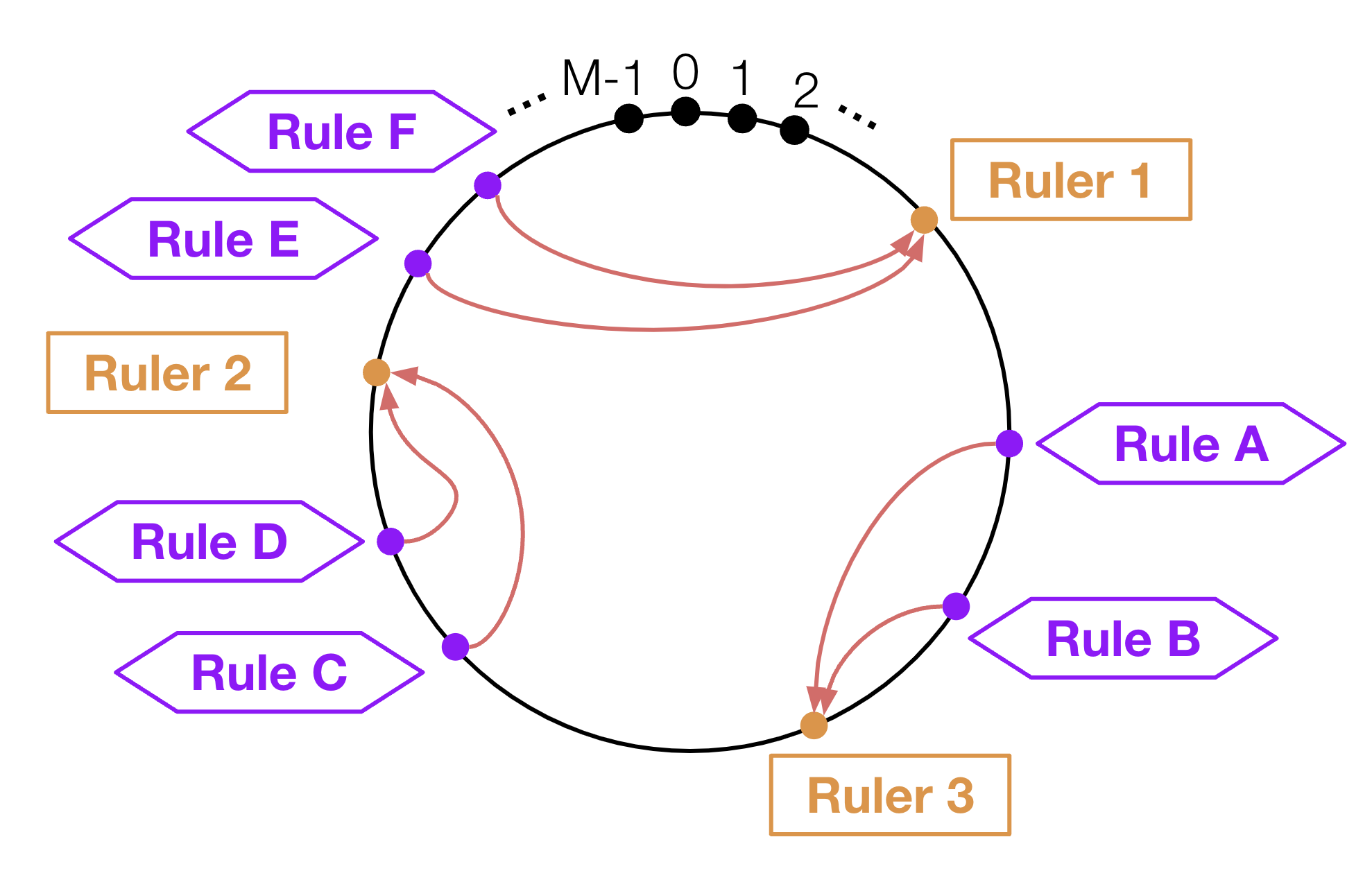
図10: Consistensh hasingに基づいたRecording ruleの割り当て
(2) Ruleの再割り当て
では、あるRulerのPodが落ちたとき、どうなるのでしょうか。このときは、図11のように、落ちたRulerの次に近いRulerへの再割り当てが行われます。このようにして、全てのRuleについてHigh availabilityが保たれます。
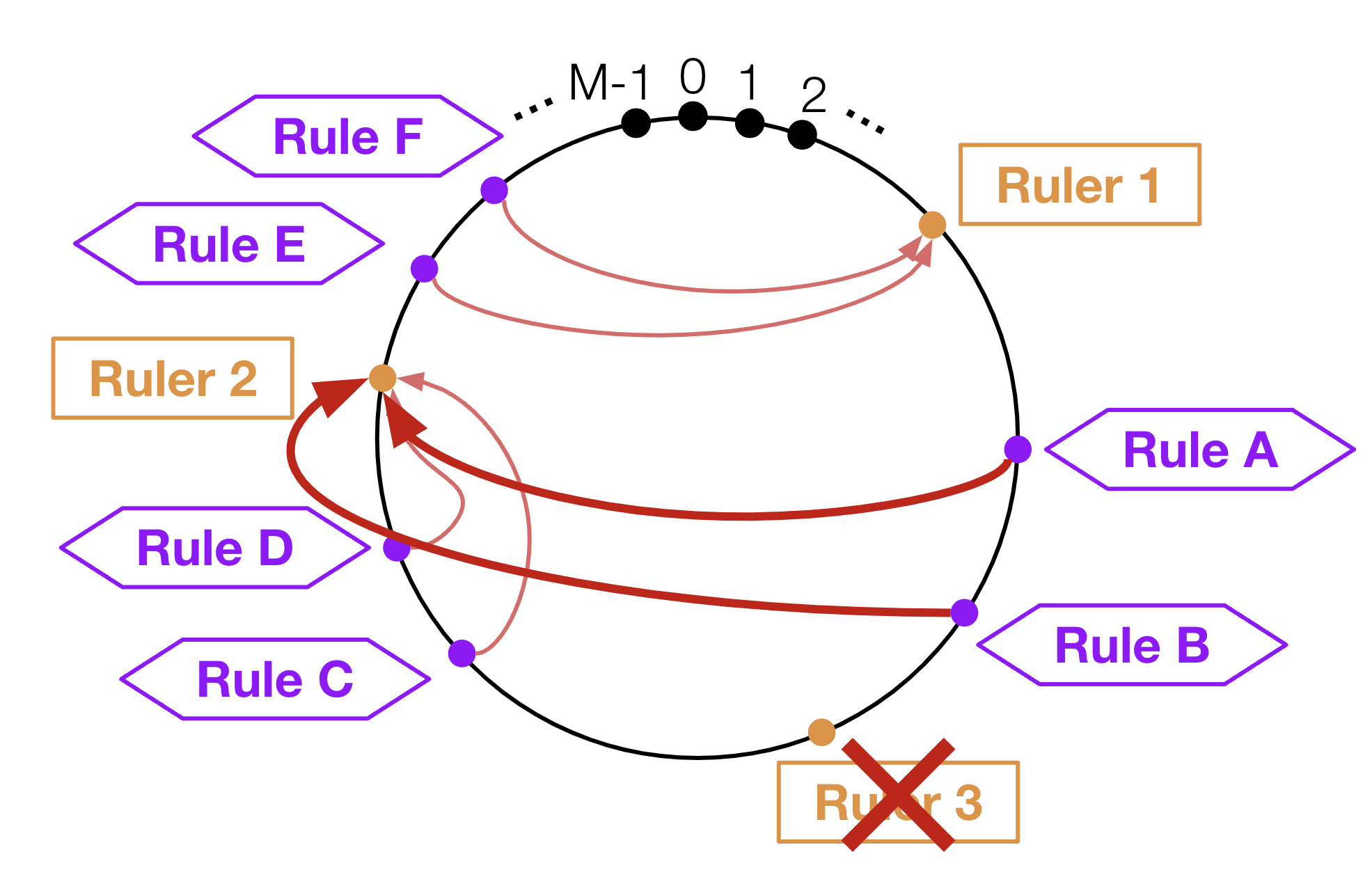
図11: Rulerが落ちた場合のReconrding ruleの再割り当て
実際には、上記のConsistent hashingアルゴリズムをそのまま用いてしまうと、各Rulerに割り当てられるRuleの数に偏りが発生してしまいます。なので、実際の実装では仮想ノードと呼ばれる手法を用いて、負荷の平準化を実現しています。
まとめ
私は本インターンシップ期間中に、Matlantisの本番環境にLogアラートの仕組みを導入しました。これにより、Logにのみ現れるようなシステムの異常を検知できるようにしました。Lokiのrulerを用いてLogをMetricsに変換し、AMPに書き込むことで、すでにMatlantisに構築されていたMetricsアラートのシステムでLogアラートも実現できるようにしました。また、High availabilityとScalabilityを保てるように、Loki Rulerのデプロイメントを調整しました。今回実装したLog alertは、すでにMatlantisの本番環境上に組み込まれています。
感想
もともとクラウドインフラの構築が好きでしたが、Kubernetesや監視の分野は全くの未経験で、苦労することもたくさんありました。そもそもの用語の意味が理解できておらず、ドキュメントを読んでも仕様が理解できずに詰まるケースも多かったです。また、ドキュメントが整備されていないケースや、OSSのソースコードを直接確認する必要があるケース、さらにOSS自体のバグに遭遇することもあり、設定を正しく行うのには非常に苦労しました。
しかし、メンターの方々の丁寧なマネジメントに支えられ、タスクを細かく分けていただいたり、行き詰まったときには適切なヒントを与えていただいたおかげで、インターンシップ期間中に最終ゴールであるログアラートの実装まで無事にたどり着くことができました。中間発表や最終発表の際も、理解が不十分だった点を的確に指摘していただいたことで、自分の取り組みの背景や関連知識を深めることができました。
最後になりますが、今回のインターンシップに参加でき、本当に良かったと思っています。この経験は、単なる就職活動の一環を超え、私自身のキャリアに直結する成長の機会となりました。このような貴重な環境を提供してくださった皆様、本当にありがとうございました!
