Blog
概要
- Multi Agent 手法の一種である LLM Debate を通して、GPT-4oと弊社開発の医療LLM Preferred-MedLLM-Qwen72B の持つ知識を最大限活用する方法を検討しました
- 上記手法により医師国家試験において9割を超える正解率を実現しました
- PFNでは引き続きLLM Agentやドメイン特化モデルの開発を進めてまいります
Multi Agentについて
近年OpenAIをはじめとしてLLMの性能は推論能力やコンテキスト幅、ツール使用など様々な面において急速に伸びており、それに伴ってLLMを用いたMulti Agent[1, 2]のフレームワークが注目されています。Multi Agentとは、様々な役割を持つAgentが、相互作用を通してシステム全体の目標を達成する仕組みであり、例えば問題をより小さな部分問題に分割して統合するなどがこれに該当します。こうしたMulti Agentを用いることはベンチマークのスコアを上昇させるなど単純にLLMの推論能力を高めるだけでなく、従来のLLMの枠組みでは解くことができなかったようなタスクも解けるようになってきました。例えば、AnthropicのClaude Research Mode[3]はこのMulti Agentのフレームワークを用いて実現されていることが報告されています[4]。
Multi Agentの枠組みにおいてLLM同士を協力させる方法は様々研究されていますが[5]、本稿ではLLM Debate[6]と呼ばれる手法を考えます。LLM Debateはその名の通り、異なる種類のLLMや同じLLMでも異なる分野の専門家の役割を与えて、それぞれ違う視点を交えながら最良の解を議論して導くといった枠組みです。
LLM Debateをはじめ、Multi Agentでは性質の異なるLLM同士を協調させた方が知識の多様性が確保されるなどの理由で性能が高くなることが報告されています[7]。一方でLLM Agent間の間違いの相関が高いと同じ論点を繰り返して収束しないなどの課題も報告されており[8]、どのようなLLMをどのように組み合わせればうまくいくのかといった難しさも存在します。
LLM Debateを通した知識活用
PFNでは医師国家試験をはじめとした医療ドメインに特化したLLMの開発を進めております[9, 10]。これらの研究の中でPFNが独自に構築したデータセットによって学習されたモデルが医師国家試験において高い成績を収めることが報告されていますが、よりその能力を活用するための有力な手段の一つとしてGPT-4oをはじめとした他のモデルの持つ知識と適切に組み合わせることが考えられます。様々な知識を持つLLMを協調させることで回答の頑健性が増すのはもちろんのこと、個々のモデルでは達成できないような性能を引き出すことも期待できます。
実際、この様な傾向は医師国家試験においても確認されていて、PFN独自の医療ドメインのコーパスで事後学習を行ったPreferred-MedLLM-Qwen-72Bと2024年5月13日時点のGPT-4oは2018年の医師国家試験においてそれぞれ431点と436点と両者高い点数を取っていながらも両者の正解した問題の和を取って集計するとその得点は466点まで伸びることがわかりました。これは両者の得意/不得意な問題には明確な差があり上手くその知識を協調させることでまだまだ性能を引き出す余地があることを示しています。
この様な課題意識から、本稿ではLLM Debateを通してPreferred-MedLLM-Qwen-72BとGPT-4oの持つ知識を最大限に活用して、医師国家試験のスコアをさらに引き上げることを試みます。前段でも述べたとおり、この二つのモデルの得意/不得意な問題は異なり、それぞれの特性が異なることから適切にLLM Debateを行うことでさらに質の高い回答が生成できることが期待されます。
実験設定
本実験ではベンチマークとしてIgakuQA[11]を用いました。IgakuQA は Jungo Kasaiさんらによって開発された LLM 用のベンチマークであり、2018~2022年の日本医師国家試験の問題を LLM に解かせることができ、この5年分の医師国家試験の問題で性能の比較を行います。
LLM Debateは全部で5round行います。1round目は通常のCoTで問題を解きます。ここでは[9]の結果と比較するため、1round目の結果として[9]の実験で得られた出力をそのまま用います。そのため2024年5月13日当時の結果を用いるため、現時点のGPT-4oとは厳密には同じではない点に注意してください。
2~5roundでは前roundで得られた二つの回答をベースに最良の解を生成するようにそれぞれのモデルに指示し、回答が一致したらそれを出力とし、一致しなかったら次のroundに進みます。これを最大5roundまで回答が一致するまで繰り返し、5round目でも一致しなかった場合はPreferred-MedLLM-Qwen-72BなどのOSSのモデルの回答を最終的な回答として採用します。
LLM Debateの実験ではDebateを5round行います。のPreferred-MedLLM-Qwen-72BとGPT-4oを用いるものと、対照実験として継続事前学習前のQwen 2.5-72BとGPT-4oを用いるもの、そして1round目だけQwen 2.5-72BとGPT-4oを用いて2round目以降はPreferred-MedLLM-Qwen-72BとGPT-4oを用いるものの合計3パターンについて行います。
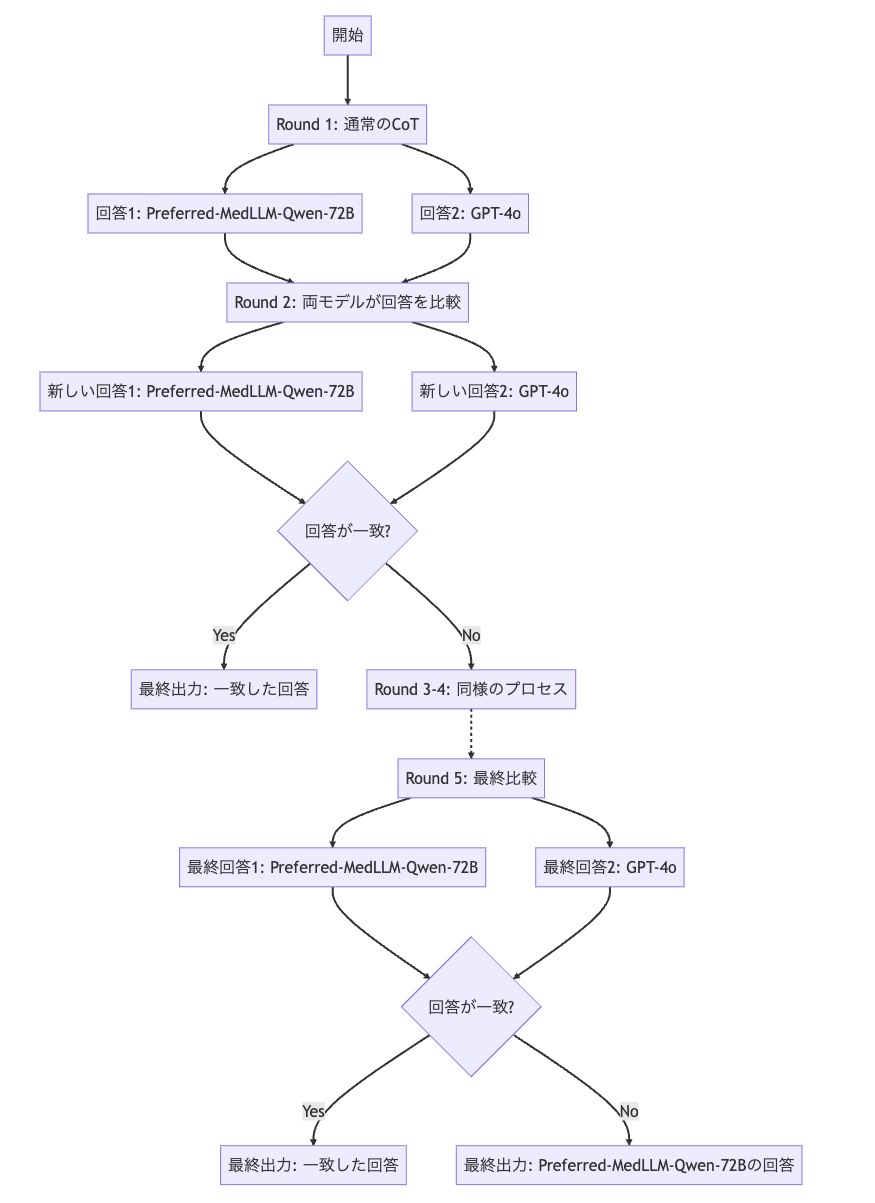
図1. Preferred-MedLLM-Qwen-72BとGPT-4oのLLM Debateの模式図
round2~5のpromptは以下の通りです。問題と前roundの二つの回答を与えてそれをベースに最良の解を生成する様に指示しています。round1のpromptはIgakuQAで用いられているCoT用のものをそのまま用いています。
あなたはAIアシスタントです。以下の問題について、他のAIが提示した回答も参考にして、最終的な回答を生成してください。
### 前回の議論 ###
AI-1の回答:
(Preferred-MedLLM-Qwen-72Bなどの回答)
AI-2の回答:
(GPT-4oの回答)
上記の議論を踏まえ、以下の問題に再度回答してください。
### 問題 ###
(問題文)
### あなたの最終回答 ###
考察を記述しても構いませんが、最終的な回答の行は「答え: 」という形式でなければなりません。
回答には、選択肢に対応するアルファベットのみをカンマ区切りで含めてください。
答え:
実験結果と考察
| 2018 | 2019 | 2020 | 2021 | 2022 | 平均 | |
| Gpt-4o + Preferred-MedLLM-Qwen-72B | 456 | 444 | 449 | 451 | 454 | 450.8 |
| Gpt-4o + Qwen2.5-72B | 455 | 429 | 429 | 433 | 437 | 436.6 |
| 1round目だけQwen2.5-72Bでそれ以降Preferred-MedLLM-Qwen-72B | 449 | 435 | 448 | 444 | 448 | 444.8 |
| Preferred-MedLLM-Qwen-72B | 431 | 430 | 424 | 435 | 438 | 431.6 |
| Gpt-4o-2024-05-13 | 434 | 433 | 443 | 435 | 443 | 437.6 |
| Qwen2.5-72B_Instruct | 409 | 402 | 403 | 415 | 413 | 408.4 |
表1: 3つの設定でLLM Debateを行なった場合と元のモデルの5年分のIgakuQAのスコア
実験結果を表1に示します。上から順にPreferred-MedLLM-Qwen-72BとGPT-4oを用いたLLM Debate、Qwen 2.5-72BとGPT-4oを用いたLM Debate、1round目だけQwen 2.5-72BとGPT-4oを用いて2round目以降はPreferred-MedLLM-Qwen-72BとGPT-4oを用いたLLM Debate、そして比較用のPreferred-MedLLM-Qwen-72B、GPT-4oとQwen2.5-72B_InstructのCoTの結果となります。Preferred-MedLLM-Qwen-72B、GPT-4oとQwen2.5-72B_Instructの結果はそれぞれのLLM Debateの1round目にそのまま用いています。
Preferred-MedLLM-Qwen-72BとGPT-4oのLLM Debateの得点は両モデルを単体で使用した場合と比較して平均点が約15点向上し、正解率は90%に到達しました。これは、両モデルの持つ知識が効果的に補完しあうことで、解答精度が大幅に向上したことを示しています。
対照的に、ドメイン特化の継続事前学習を行っていないQwen 2.5 72BとGPT-4oを協調させた場合、スコアの向上はほとんど見られませんでした。この結果は継続事前学習の有効性を明確に示しており、Preferred MedQwen 72Bが持つ医師国家試験に関する深い専門知識が、協調プロセスにおいて不可欠であったと考えられます。
さらに興味深いのは、LLM Debateのround 2以降のフェーズ(回答の評価・推敲)でのみPreferred MedQwen 72Bを適用した場合でも、スコアが向上した点です。round 1がCoTを用いて問題を解くタスクであるのに対し、round 2以降は提示された複数の回答を吟味・判定するという、より高度で異なる種類の推論が求められます。
先行研究[10]では、Preferred MedQwen 72Bがround 1に相当する「問題解答タスク」で高い性能を持つことは報告されていました。本実験により、同モデルがround 2以降の「回答評価タスク」という異なるタスクにおいても優れた能力を発揮することが初めて明らかになりました。これは、Preferred MedQwen 72Bが、深いドメイン知識を獲得しつつも、多様な指示やタスクに対応できる汎化性能を保持していることを強く示唆する結果です。
最後に
本稿ではMulti Agentの枠組みで特化型モデルと汎用モデルを組み合わせることでさらに推論の性能を高めることができました。この結果は強力なフロンティアモデルのAPIと適切に学習された特化型モデルを共に活用することに大きな意味があることを示唆しています。本稿で得られた知見は今後の社内における研究開発やソリューション開発にも活用していく予定です。
PFNでは様々なドメインにおけるLLM Agentの社会実装やそれに必要な技術の研究開発を進めています。
今回の取り組みに興味を持っていただいた企業の方はぜひお問い合わせフォームよりご連絡ください。
最後に、Preferred Networks では採用を行っております。今回の記事で興味を持っていただけた方はぜひご応募ください。
