Blog
本記事はアルバイトとして勤務されている加藤大地さんによる寄稿です。
はじめに
Python 3.13 より、PEP 703 で提案された free threading が実験的にサポートされるようになりました。これまで、Python(厳密にはCPython)のインタプリタでは、global interpreter lock (GIL) という機構によって、同時刻において1つのスレッドしか実行できないようになっており、これによってスレッドセーフであることを保証していました。しかし、3.13 で導入された free threading により、複数のスレッドが同時に実行できるようになったことで、実行時間の短縮が見込まれます。
その一方、C-APIにいくつかの後方互換性のない変更が加わったことで、一部のC拡張モジュールがfree threading モードでは正しく動作しなくなる可能性があり、pure PythonなパッケージであるOptunaにおいても依存関係に含まれているC拡張モジュールの動作状況の検証が必要です。また、Python 3.13リリース時点では、シングルスレッド性能が著しく悪化することも知られています。そこで本ブログでは、Optuna での free threading 動作状況の検証と、free threading の導入前後での簡単なベンチマークによる実行時間比較を行った結果をまとめました。
TL;DR
- Python 3.13で実験的に導入された free threading (No GIL) モードに対して、Optunaの主要なSampler、Storageの動作状況を整理しました。一部のSampler、Storageは、まだfree threadingモードに対応していない外部パッケージに依存している等の原因で、動作しないことを確認しました。
- free threading モードの導入により、一部処理が高速化する一方、大幅に遅くなるケースもあることを、基礎的なベンチマークスクリプトで確認し、簡単な考察を行いました。
- free threadingは非常に初期段階であり、Optunaチームとしても対応を継続して進めていく予定です。
動作確認のための環境準備
free threading は実験的な機能であり、通常の Python 3.13 では有効化することができないため、 python 3.13t と呼ばれる別の処理系を用意する必要があります。本ブログの動作確認では、以下のように pyenv を利用して実行環境を準備しています。なお、pyenvのバージョンは執筆時点で2.4.19です。
pyenv install 3.13t pyenv shell 3.13t
free threadingを有効化して実行を行うには、以下のように -X gil=0 というオプションをつけます:
python -X gil=0 <your_script>.py
また、動作確認には、 pytest-freethreaded というpytestのプラグインを利用しました。このプラグインにより、テストをマルチスレッドで同時に実行させることができるようになり、free threading 環境での動作確認を簡単に行うことができます。なお、 pytest-freethreaded はpipでインストール可能です:
pip install pytest pytest-freethreaded
Optunaでの動作状況
Optunaは全てPythonで実装されたpure Pythonなパッケージなので、Optunaのコード自体に対応の必要はないと考えられます。しかし、Optunaが依存しているパッケージ(NumPy、SciPy、PyTorchや、各種DBドライバ等)はC拡張で書かれたものもあり、free threadingモードに対して未対応なものも存在します。
上記を踏まえ、Optunaに含まれるsamplerとstorageの動作状況の確認と整理を行いました。本記事公開後も、引き続きこちらのissueで状況を追っていく予定です。なお、主要パッケージの free threading への対応状況は、こちらでトラッキングされています。
Sampler
Samplerの動作状況の一覧と、動作確認に使用したコードは次のとおりです。
| Sampler | 3.13tでの利用可否 | 補足 |
| RandomSampler | ⚪︎ | – |
| NSGAIISampler | ⚪︎ | – |
| TPESampler | ⚪︎ | NumPyに依存しているが、NumPyはすでに3.13t対応済なので利用可能 |
| GridSampler | ⚪︎ | 同上 |
| NSGAIIISampler | ⚪︎ | 同上 |
| BruteForceSampler | × | 本samplerの実装はpure Pythonであるにも関わらず、Python 3.13tでマルチスレッドで実行すると RuntimeError: dictionary changed size during iteration で落ちることを確認。現在、原因を調査中。pytest-freethreadedを使わずにエラーを再現するコードはこちら。 |
| CmaEsSampler | ⚪︎ | NumPyほか、cmaesにも依存しているが、cmaesもすでに3.13t対応済なので利用可能 |
| GPSampler | × | PyTorchへの依存があり、PyTorchは未対応 |
| QMCSampler | × | SciPyへの依存があり、SciPyは未対応 |
動作確認コード
import pytest
import optuna
optuna.logging.set_verbosity(optuna.logging.WARNING)
@pytest.mark.parametrize(
"sampler_type,args",
[
(optuna.samplers.RandomSampler, []),
(optuna.samplers.NSGAIISampler, []),
(optuna.samplers.TPESampler, []),
(optuna.samplers.GridSampler, [{f"x{i}": [0, 5, 10] for i in range(10)}]),
(optuna.samplers.NSGAIIISampler, []),
(optuna.samplers.BruteForceSampler, []),
(optuna.samplers.CmaEsSampler, []),
(optuna.samplers.GPSampler, []),
(optuna.samplers.QMCSampler, []),
],
)
def test_free_threaded(sampler_type: optuna.samplers.BaseSampler, args):
try:
sampler = sampler_type(*args)
study = optuna.create_study(sampler=sampler)
def objective(trial):
s = 0
for i in range(10):
s += trial.suggest_int(f"x{i}", 0, 10)
return s
study.optimize(
objective,
n_trials=50,
n_jobs=5,
)
except ModuleNotFoundError:
pytest.skip(f"{sampler_type} is not available.")
上記のコードを、 pytest –threads 10 –iterations 20 –require-gil-disabled free-threaded-optuna-sampler-check.pyで実行しています。
Storage
Storageの動作状況の一覧と、動作確認に使用したコードは次のとおりです。
| storage | 3.13tでの利用可否 | 補足 |
| InMemoryStorage | ⚪︎ | – |
| RDBStorage (sqlite) | △ | 実行によって sqlite3.OperationalError が出ることがあるが、これはGILの有無に起因するものではなく、sqliteが高い並列数には対応していないことによるものである。スレッド数を減らす(n_jobsや–threadsの値を小さくする)か、sqliteのtimeoutまでの時間を長くすることでエラーを解消することはできるが、多数のスレッドで並行処理を行うケースにおいて、Optunaではsqliteの使用は推奨していない(参考)。 |
| RDBStorage (MySQL) | × | cryptographyのインストールが必要だが、cryptographyは3.13t未対応 |
| JournalStorage (File) | ⚪︎ | – |
| JournalStorage (Redis) | × | 本storageの実装はpure Pythonであるにも関わらず、Python 3.13tでマルチスレッドで実行すると RuntimeError: dictionary changed size during iteration で落ちることを確認。現在、原因を調査中。pytest-freethreadedを使わずにエラーを再現するコードはこちら。 |
動作確認コード
import pytest
import optuna
import optuna.storages.journal
optuna.logging.set_verbosity(optuna.logging.WARNING)
@pytest.mark.parametrize(
"storage_type,args",
[
(optuna.storages.InMemoryStorage, []),
(optuna.storages.RDBStorage, ["sqlite:///sample.db"]),
(optuna.storages.RDBStorage, ["mysql+pymysql://optuna:password@127.0.0.1:3306/optuna"]),
(
optuna.storages.JournalStorage,
[optuna.storages.journal.JournalFileBackend("sample.log")],
),
(
optuna.storages.JournalStorage,
[optuna.storages.journal.JournalRedisBackend("redis://localhost:6379")],
),
],
)
def test_free_threaded(storage_type, args):
try:
storage = storage_type(*args)
study = optuna.create_study(storage=storage)
def objective(trial):
s = 0
for i in range(10):
s += trial.suggest_int(f"x{i}", 0, 10)
return s
study.optimize(
objective,
n_trials=50,
n_jobs=5,
)
except ModuleNotFoundError:
pytest.skip(f"{storage_type} is not available.")
上記のコードを、 pytest –threads 10 –iterations 20 –require-gil-disabled free-threaded-optuna-storage-check.pyで実行しています。
ベンチマークによる速度比較
free threadingを導入することによる実行時間の差異の検証も行いました。スレッド数10のマルチスレッドの設定で、trial数が1000の最適化を10回行い、その平均値を算出しました。使用したコードはこちらです。実行環境は、Mac Studio (M2 Max 12 core, 64GB RAM) です。
結果は以下のようになりました:
| sampler | 3.13 | 3.13t | 差分 |
| RandomSampler | 0.4557 +/- 0.0173 sec | 0.2536 +/- 0.0049 sec | -44.3% |
| TPESampler | 24.5709 +/- 0.1606 sec | 45.8566 +/- 0.1664 sec | +86.6% |
| CmaEsSampler | 0.8552 +/- 0.0058 sec | 2.6238 +/- 0.0969 sec | +206.8% |
| NSGAIISampler | 0.7606 +/- 0.0071 sec | 0.7628 +/- 0.0315 sec | +0.3% |
3.13に対する3.13tでの実行に関して、RandomSamplerはGILの無くなった並行処理により実行時間が短くなりましたが、NSGAIISamplerではほぼ同一、TPESampler、CmaEsSamplerの実行時間はむしろ長くなる、という結果となりました。
3.13tでは3.13には無かったオーバーヘッドが存在しており、シングルスレッド性能が大幅に低下するケースがあることが指摘されているため(参考)、実装の並列処理の度合いによって、マルチスレッド性能も遅くなり得ます。
TPESamplerを例にとり、プロファイラを用いてどの部分が実行のボトルネックになっているかを簡単に検証してみました。profileパッケージを用いてstatsファイルを生成し(コード)、gprof2dotを用いて可視化すると、以下のようなグラフを得られました:
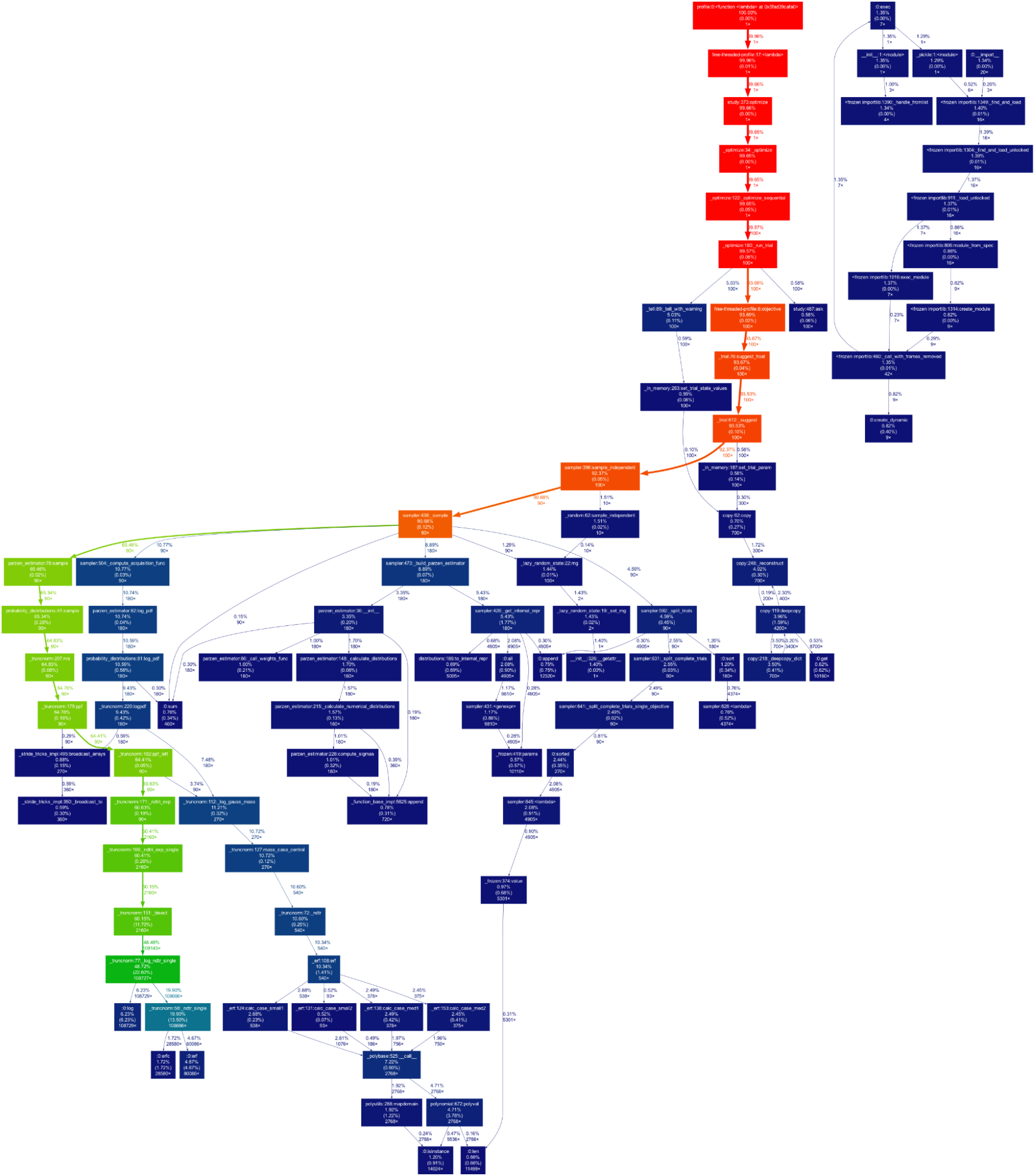
グラフから、TPESampler内部のfloatの比較や四則演算などのプリミティブな演算が、60%以上の実行時間を占めていることがわかりました。そこで、3.13に対する3.13tのプリミティブな演算の実行時間の差分を計算してみると、以下のようになりました(コード):
| 演算式 | 3.13に対する3.13tでの演算実行時間の差分 |
| 10 ** 10 | +33.4% |
| 1000 + 1000 | +36.7% |
| 10 < 20 | +53.9% |
このように、単純な演算の処理が遅くなっていることは、TPESamplerにおいて3.13tでの全体の実行時間が遅くなっていることの原因の1つであると言えそうです。ただし、最も差が開いた比較演算の差分が約+54%であるのに対して、全体の実行時間の差分はより大きい約+87%であることから、単純な演算が遅くなっていること以外にも、別の大きな要因があると考えられます。引き続き、検証を続けていこうと思います。
おわりに
本ブログでは、Python 3.13で free threading モードが実験的に追加されたことを踏まえ、Optunaの free threading モードでの動作状況の整理と、簡単なベンチマークによる速度比較を行いました。
free-threadingモードはまだまだ対応の初期段階にあり、不安定な部分も多く、日夜改善やバグの修正が進められています。Optunaチームとしても引き続き、最新の情報をキャッチアップしながら、free-threadingモードへの対応を進めていく予定です。