Blog
はじめに
Preferred Networksの加藤です。AIプロダクト・ソリューションチーム所属で、AutoMLチームも兼務しています。PFNでは Preferred AI という生成AIを活用したプロダクト群を開発しており、その1つである PreferredAI Work Suite (以下、Work Suite) に自動プロンプト最適化を行える新機能を実装しました (※画面は開発中のものです)。
図1: 自動プロンプト最適化を行える新機能の紹介GIF
Work Suite は、社内データを活用し、業務のAIによる効率化・自動化を支援するプラットフォームです。Work Suite の機能の1つとして、「ワークフロー」機能があります。ユーザは自動化したい業務フローを、複数のステップに分解し、各ステップの処理を「ブロック」として定義して組み合わせることでワークフローを構築することができます。以下は、「与えられた質問に対し、必要な情報をWeb検索し、その情報をもとに回答を生成する」ワークフローの例です:
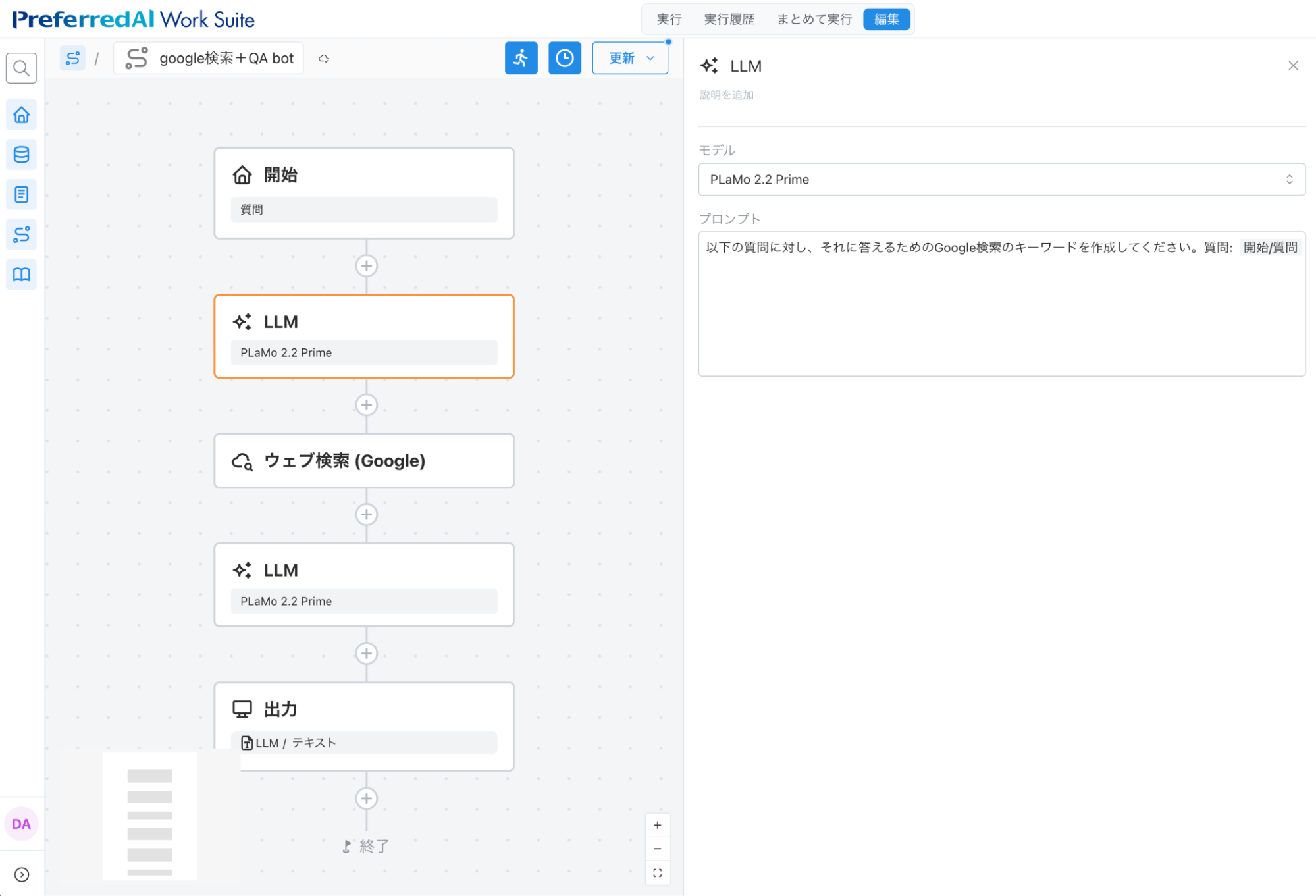
図2: 与えられた質問に対し、必要な情報をWeb検索し、その情報をもとに回答を生成するワークフローの例
ブロックの一種である「LLMブロック」は、ユーザが任意のプロンプトを入力し、汎用的に利用することができますが、簡潔に記述したプロンプトでは望み通りの働きをしてくれない場合があるため、ユーザは自身のプロンプトを手作業で改善する必要がありました。特にワークフロー全体のブロック数が増えてくると、全てのプロンプトを人手で直していくのは骨が折れる作業になります。
そこで今回、LLMブロックが複数存在するワークフローにおいて、ユーザがワークフロー全体に対して単一に与えるフィードバックをもとに、自動でプロンプトを最適化する仕組みを考案し、実装を行いました。本ブログでは、この新機能の技術詳細についてご紹介します。
Optunaベースでプロンプト最適化を行う内製フレームワーク
PFN社内では、自動プロンプト最適化を行うためのフレームワークを内製しています。このフレームワークは、PFNが開発・公開しているOSSである Optuna をベースにしており、Optuna と同様のインターフェースで利用できるように設計されています [1] 。
例えば、最適化対象(プロンプトの探索空間)を定義し、各 trial で候補プロンプトを生成して評価し、その結果をもとに次の候補を提案する、といった基本的な流れは Optuna と同じです。加えて、Optuna が提供している試行履歴の管理・可視化・永続化といった機能をそのまま活用できるため、実運用上の利点もあります。今回 Work Suite に実装した新機能は、この内製フレームワークを拡張することで実現しました。
ユーザフィードバック駆動型のプロンプト最適化手法の考案
今回考案したのは、「ユーザがワークフロー全体に対して与える、定性的なフィードバック」から出発して、複数の LLM ブロックのプロンプト(複数のプロンプトをまとめて「プロンプト群」と呼ぶことにします)を自動で改善していくアルゴリズムです。このアルゴリズムは、以下の特徴を持ちます:
- ユーザの定性的フィードバックに基づいて改善を行う
- 評価値は accept / reject (「この結果でよい」か「まだ直したい」か)の2値
- accept された候補が出たら、直ちにその候補へ遷移する。以降は accept されたプロンプト群を親として探索することとし、それまでの履歴をクリアする。こうすることで、不必要に履歴が膨大になり、改善の方向性がブレることを防ぐ。
- reject の場合はユーザからreject 理由を受け取り、プロンプトとreject理由の履歴を保持しながら次の候補を探索
- プロンプト群を同時に最適化できる
アルゴリズムの流れ
最適化対象となる初期プロンプト群を prompt_set_0 とします。なお、プロンプト群は1つ以上のプロンプト (prompt_set_0 の1つ目、prompt_set_0 の 2つ目、…) で構成されます。Work Suiteであれば、1つ以上の「LLMブロック」のプロンプトを合わせてここでは「プロンプト群」と呼んでいることに注意してください。

ユーザは prompt_set_0 に対して「どう変更したいか」を表す定性的なフィードバックを入力します。アルゴリズムはそのフィードバックをもとに prompt_set_1 を生成します。なお、新たにプロンプト群を生成する際には、プロンプト群に含まれる各プロンプトに「テキスト勾配 [2] 」と呼ばれる手法を用いています。
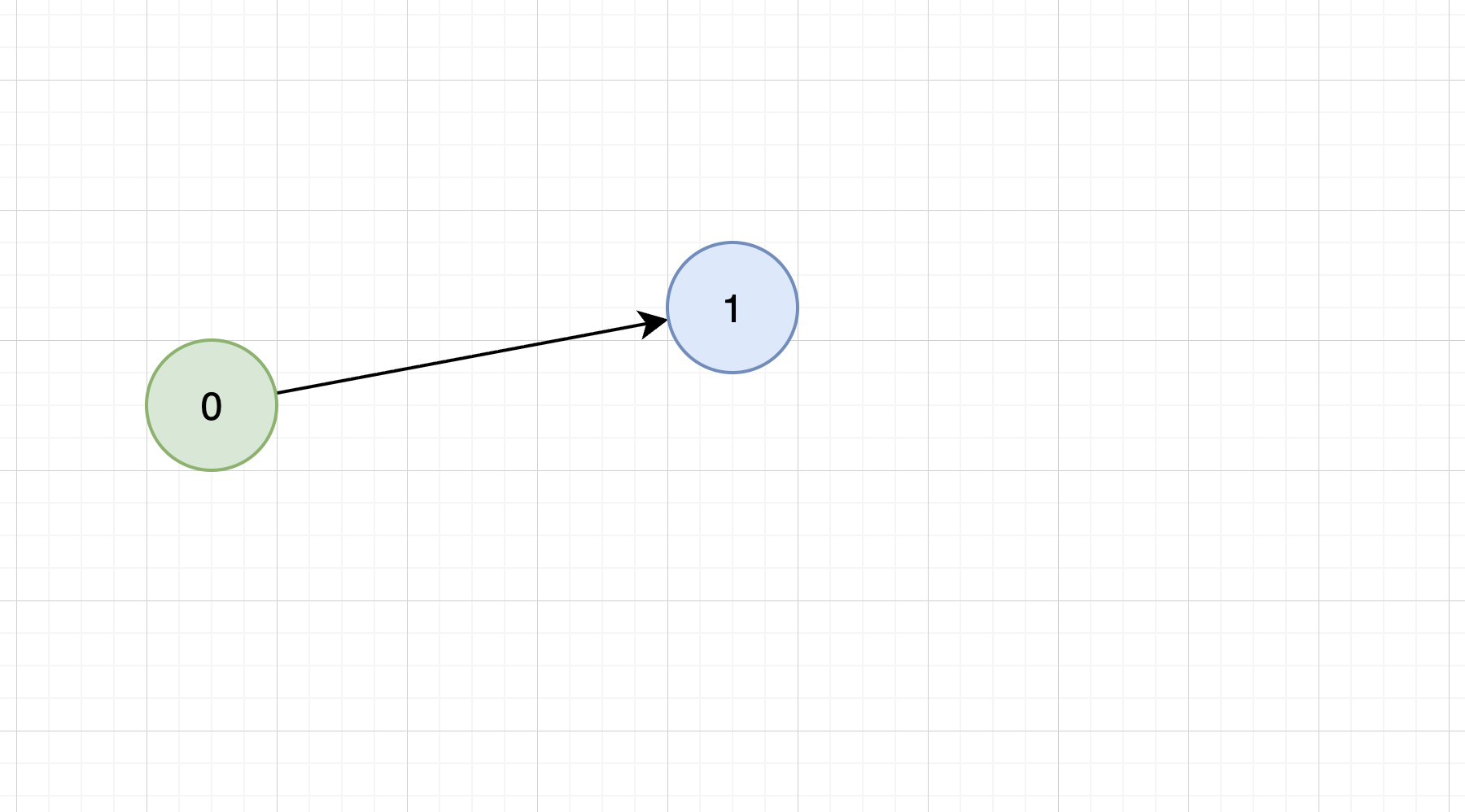
ユーザは prompt_set_1 をもとに、 accept / reject を選びます。ここから分岐します。
accept の場合
prompt_set_1 を新たな親プロンプト群として採用し、今後の探索は prompt_set_1 から再開します。これ以降、 prompt_set_0 やここで得たフィードバックを使うことはありません。「そのフィードバックは満たせた」とみなして、次の改善(別のフィードバック)へ進む、もしくは、これ以上のフィードバックがなければ探索(改善作業)を終了します。
reject の場合
ユーザは同時にreject した理由を入力します。アルゴリズム側はこの reject 理由を履歴として保持します。次の候補 prompt_set_2 を生成する際には、次のものを材料にして、 prompt_set_2 を生成します:
prompt_set_1およびユーザが入力したreject 理由- 0→1 の遷移の際に用いたフィードバック
- 参照元の親プロンプト群(
prompt_set_0)
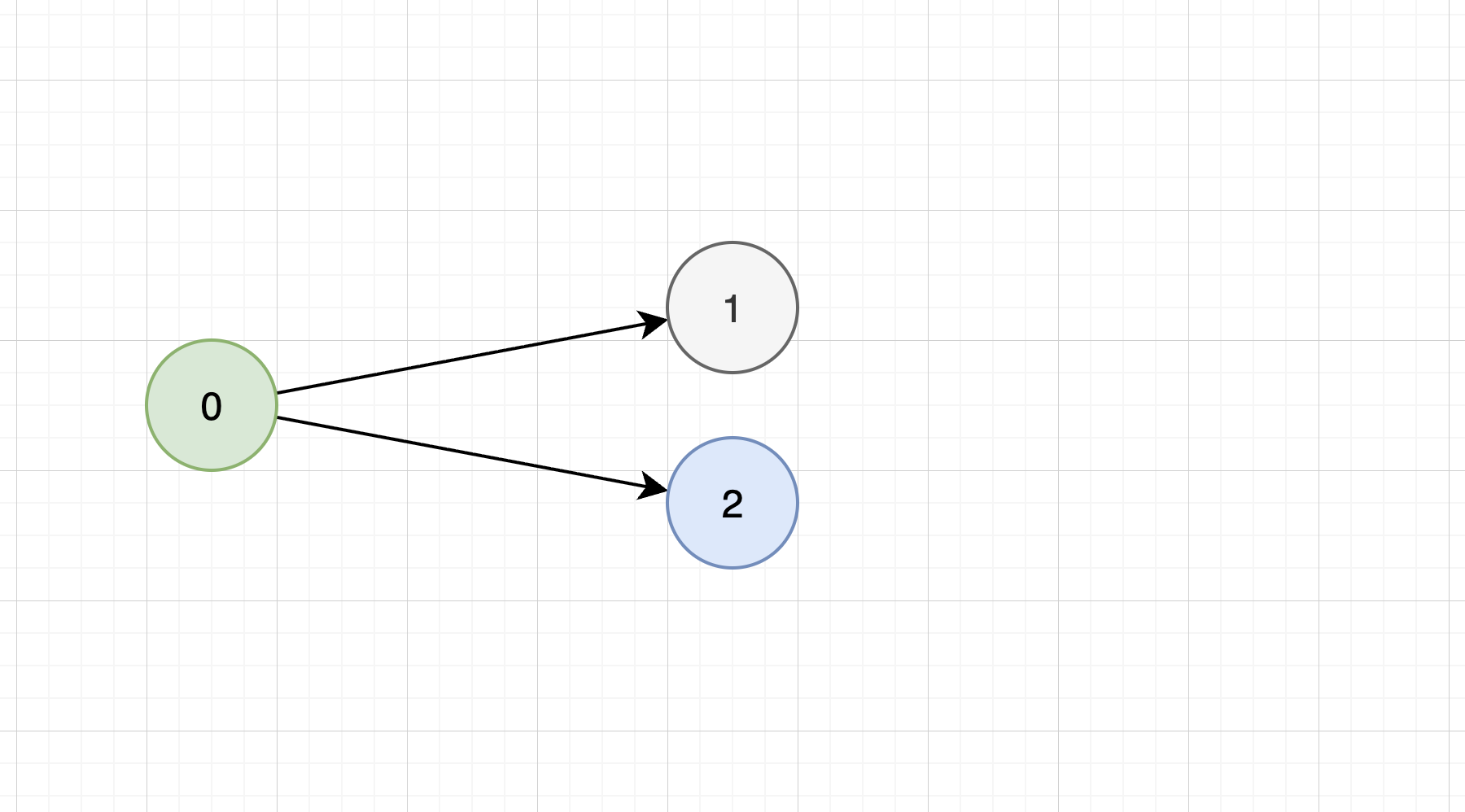
ユーザは、prompt_set_2 をもとに、再び accept / reject を判断します。
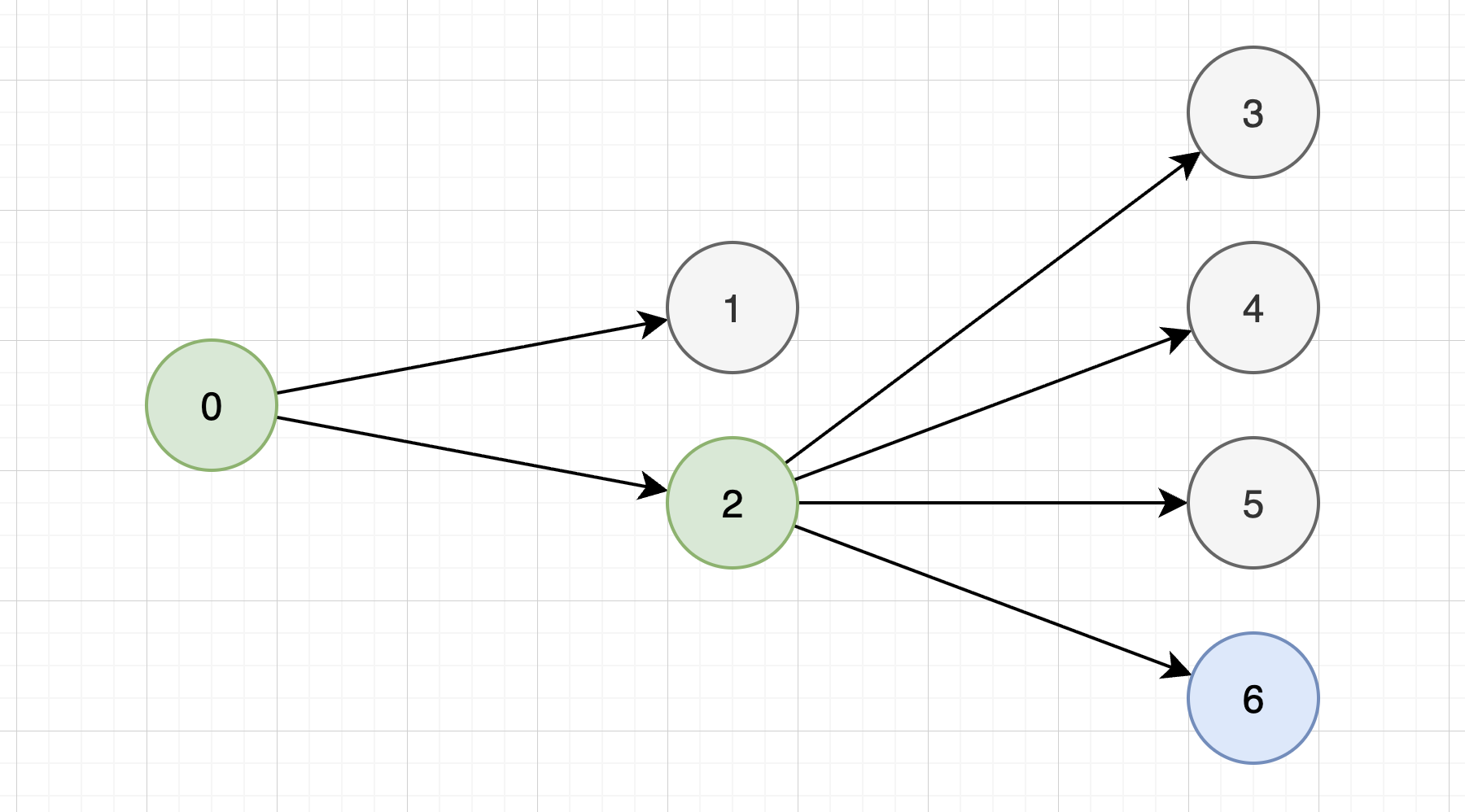
この手順を繰り返します。reject されたプロンプト群とその理由は、ユーザが accept するまで履歴として保持されます。
たとえば prompt_set_2 を親として 2→3 の遷移をした後に prompt_set_3, prompt_set_4, prompt_set_5 が連続で reject された場合、次の prompt_set_6 生成では prompt_set_2, 3, 4, 5 および 3/4/5 の reject 理由の履歴、そして 2→3 の際のフィードバックが材料となります。過去の失敗を蓄積しながら探索を進めつつ、accept が出た時点で素早く状態が更新されていく仕組みです。
プロンプト群(複数 LLM ブロック)対応のための工夫
前節にて説明した通り、Work Suite のワークフローでは、1つのワークフローの中に複数の LLM ブロックが存在することもあります。
一方で、ユーザが与えるフィードバックは「ワークフロー全体に対して1つ」です。そのため、例えば、「与えられた質問に対し、必要な情報をWeb検索し、その情報をもとに回答を生成する」ワークフローにおいて、ユーザが「クエリ生成側ではキーワードだけ出してほしい」という意図でフィードバックを書いたとしても、何も工夫がなければ回答生成側のプロンプトまで同時に変化してしまい、改善がブレてしまいます。
この問題に対して、「ワークフロー全体としての改善」という枠組みは維持しつつ、意図しないプロンプトの破壊的変更を抑える仕組みを導入しています。具体的には、全てのプロンプトに内部的な識別子(採番)を付与し、各プロンプトを更新する際に「ユーザのフィードバックはプロンプト群全体に対するものであり、必ずしもこのパラメータ(= このプロンプト)に関係するとは限らない」ことを明示しています。これにより、ユーザのフィードバックに直接関係しないプロンプトには更新の影響が及ばないように制御しています。
プロンプト最適化の具体例
実際のプロンプト最適化の様子を、Work Suiteの画面上で説明します。ここでも、「与えられた質問に対し、必要な情報をWeb検索し、その情報をもとに回答を生成する」ワークフローを説明の例として用います。「Preferred Networks の住所は?」という入力を質問とします。
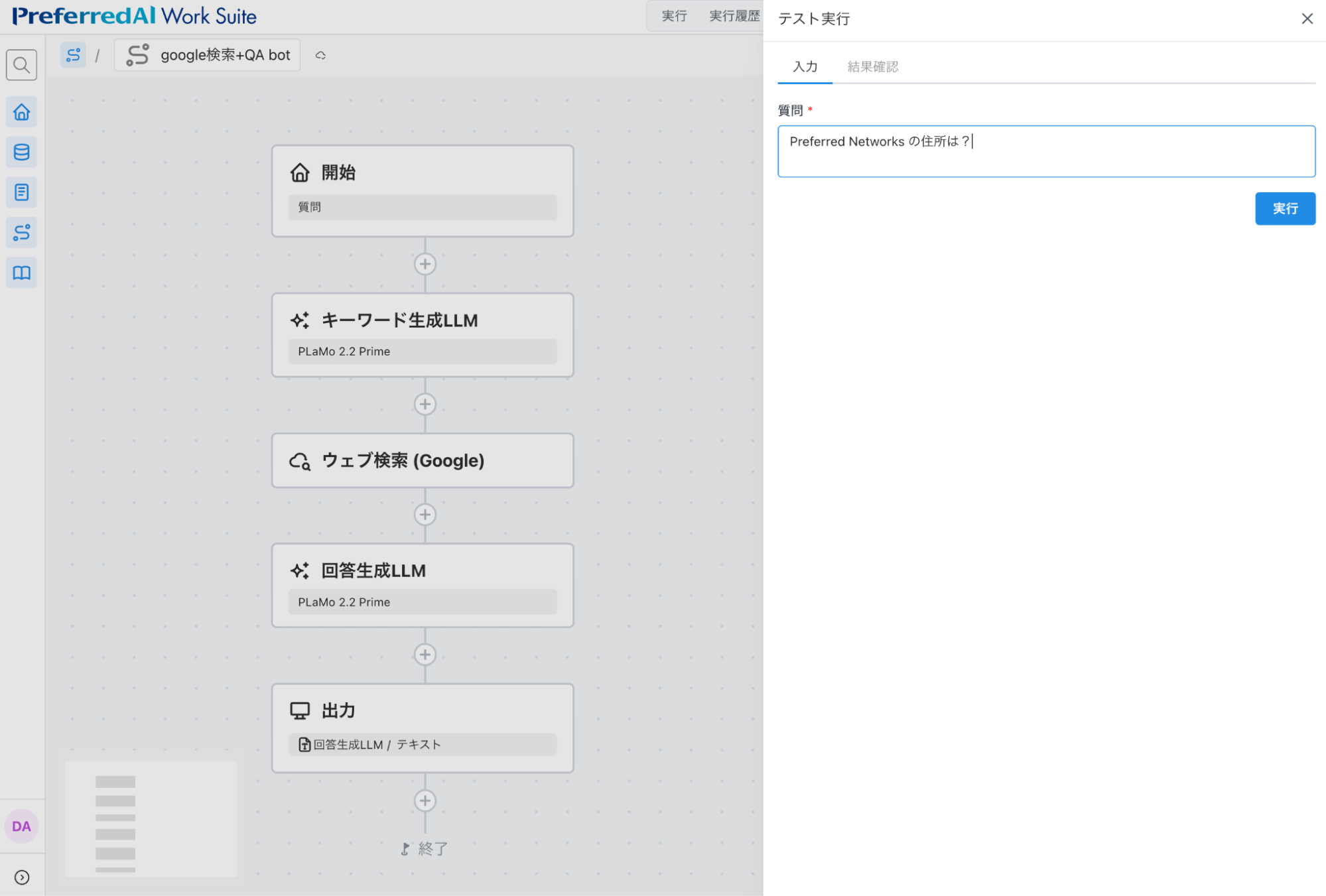
図3: 「Preferred Networks の住所は?」という入力を入れる様子
初期状態のプロンプト群 (= prompt_set_0) は、以下の通りです:
- キーワード生成LLM (=
prompt_set_0の1つ目のプロンプト):「以下の質問に対し、それに答えるためのWeb検索のキーワードを作成してください。質問: {{ ユーザの入力 }} 」 - 回答生成LLM (=
prompt_set_0の2つ目のプロンプト):「以下の検索結果をもとに、次の質問に答えてください。 検索結果:{{ ウェブ検索の結果 }} 質問:{{ ユーザの入力 }}」
こちらのワークフローを実行すると、次のような出力となりました:
申し訳ありませんが、 検索結果にはPreferred Networksの具体的な住所に関する情報は含まれていませんでした。 そのため、Preferred Networksの住所についてお答えすることはできません。 ... (後略)
正しく検索結果を得られていないようです。そこでキーワード生成LLMの出力を見てみると、以下のような結果が返ってきていました:
Preferred Networksの住所を調べるためのWeb検索のキーワードとしては、 以下のようなものが適切でしょう: - **「Preferred Networks 本社 住所」** - **「Preferred Networks 所在地」** - **「Preferred Networks 会社住所 東京都」**(Preferred Networksは東京都に本社があるため) - **「Preferred Networks アクセス」 ... (後略)
Web検索ではこちらの出力がそのまま入力として使われます。追加の説明等は不要で、キーワードのみを出力して欲しいので、そのようにフィードバックをしてみます。
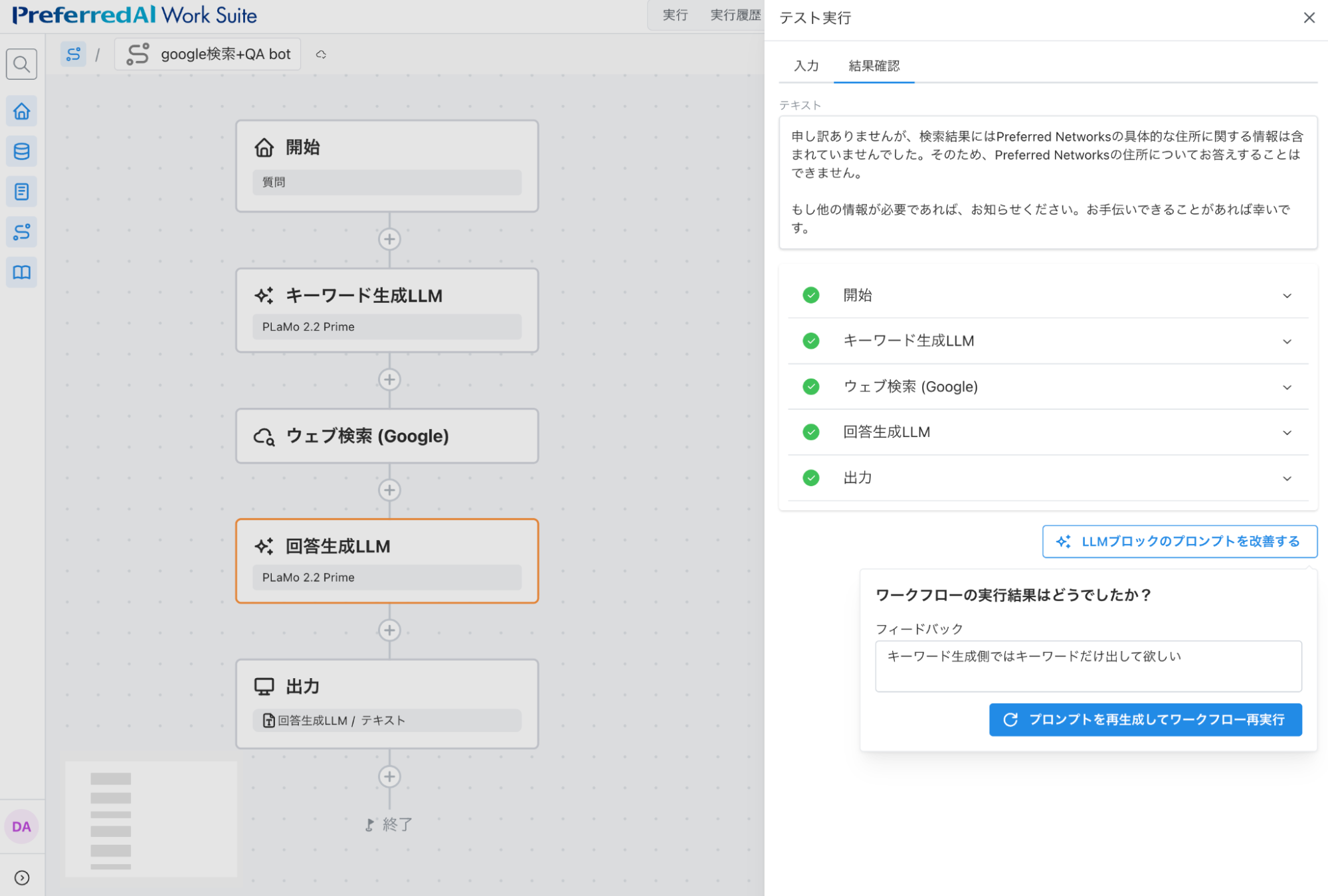
図4: 「キーワード生成側ではキーワードだけ出して欲しい」とフィードバックをする様子
すると、以下のようなプロンプト群に改善されました:
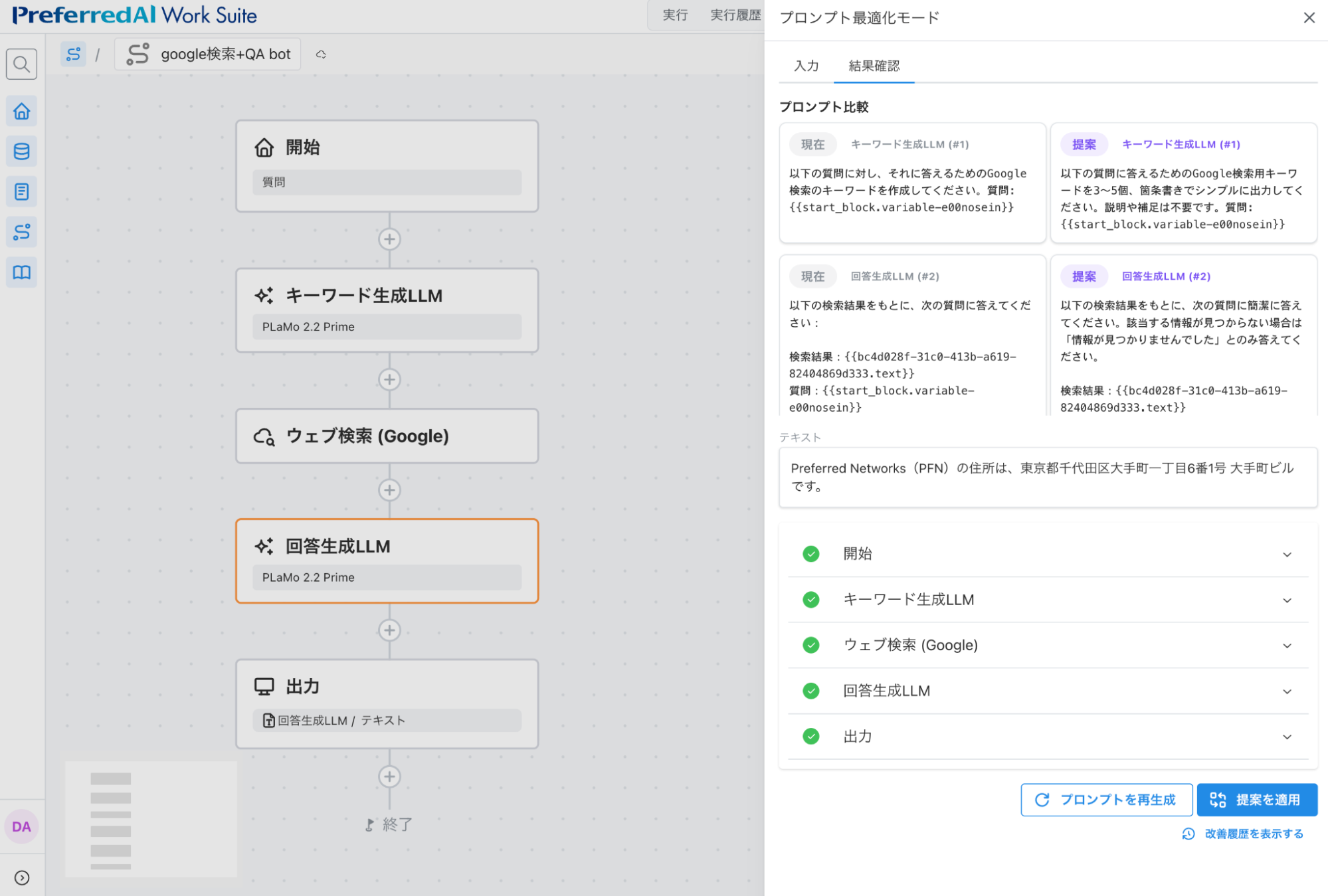
図5: 1度目のプロンプト改善結果
キーワード生成LLMのプロンプトに、キーワードのみを出力する旨が追加されています。また、回答生成LLMの方では、今回のフィードバックは関係なかったものと判断され、(一般的な改善を施す微修正は入ったものの) とくに大きな変更はありません。このように、フィードバックの内容に応じて、本質的に変えるべき部分はどこなのかを自動で判断して、プロンプトが最適化されていきます。「提案を適用」ボタンを押し、変更を適用します (左側ボタン「プロンプトを再生成」を押すこと、右側ボタン「提案を適用」を押すことが、それぞれ、アルゴリズムにおける reject / accept に対応しています) 。
次に、出力結果を英語に変更してみたいと思います。新たに「出力結果を英語にしたい」というフィードバックを送ります。
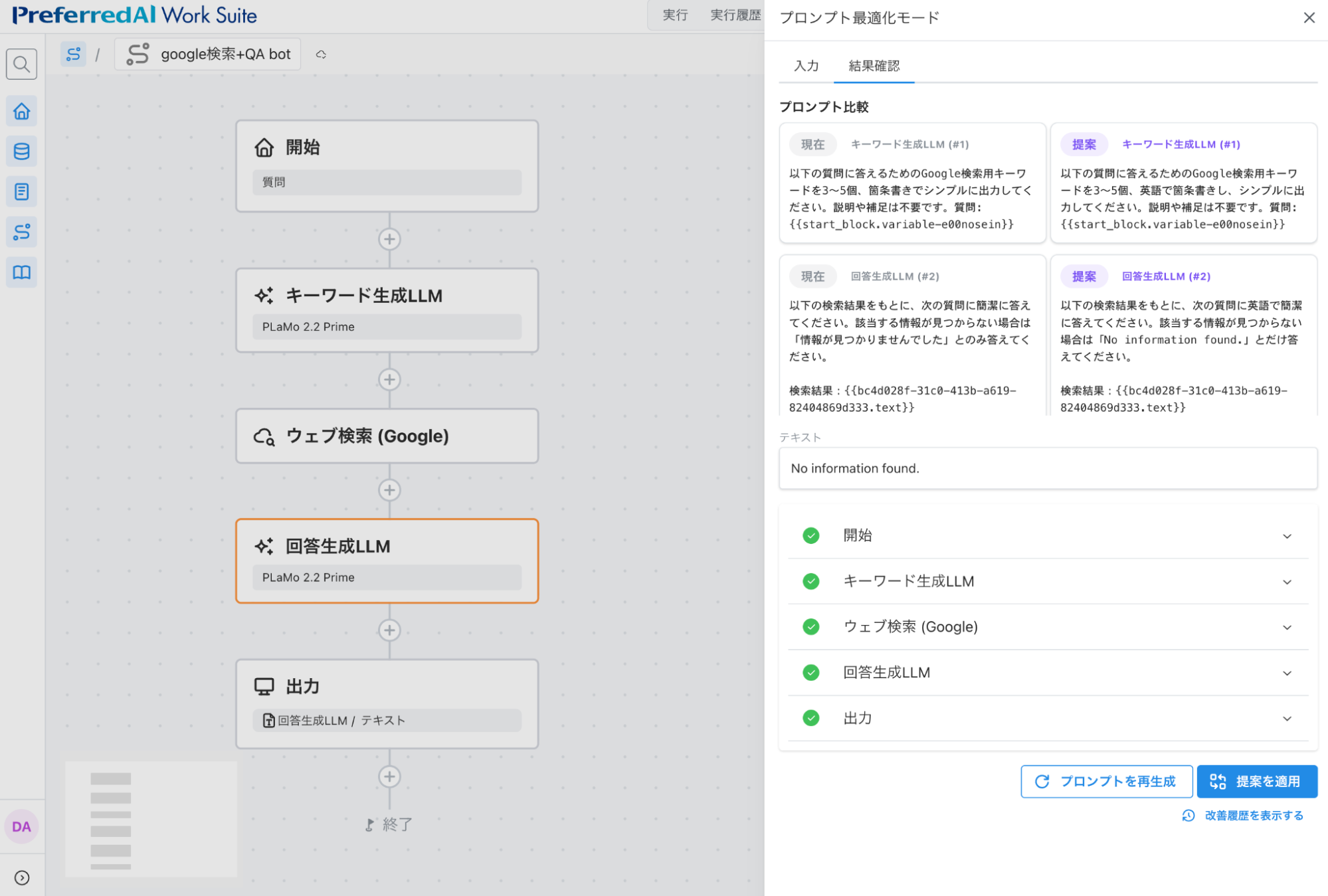
図6: 「出力結果を英語にしたい」とフィードバックをした結果
キーワード生成の方も英語で検索をするようになってしまったので、「検索は日本語でしたい」という理由でrejectしてみます。
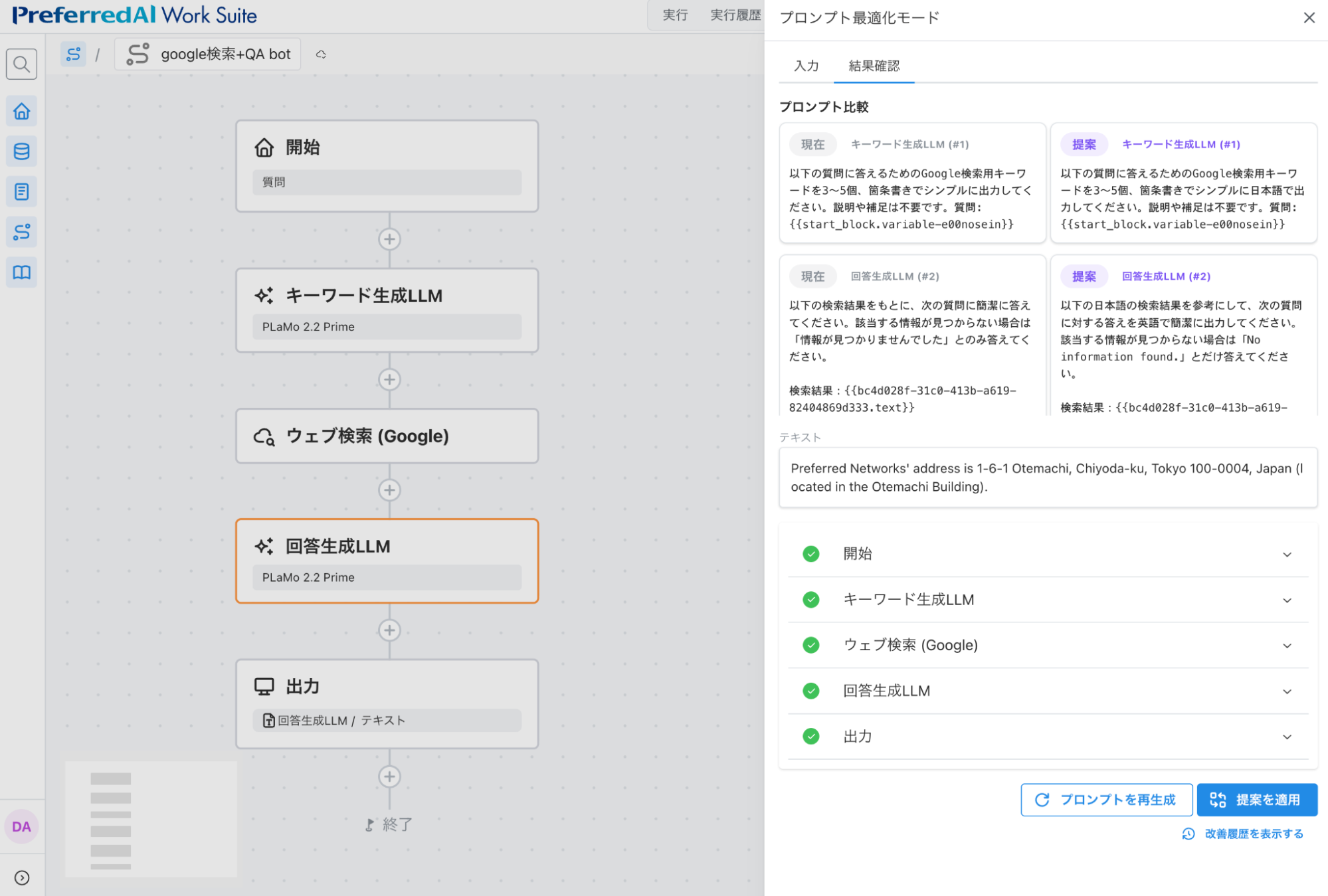
図7: 2度目のプロンプト改善結果
これで正しい結果が得られました。このように、「検索は日本語でしたい」という曖昧な指示に対しても、以前「出力結果を英語にしたい」というフィードバックをユーザが送っていたことを履歴として保持しているため、明示的に「検索は日本語で、出力は英語で」と言わなくても正しくプロンプトを改善することができました。
また、プロンプトの最適化の履歴は、ツリー形式でみることができるようになっています:
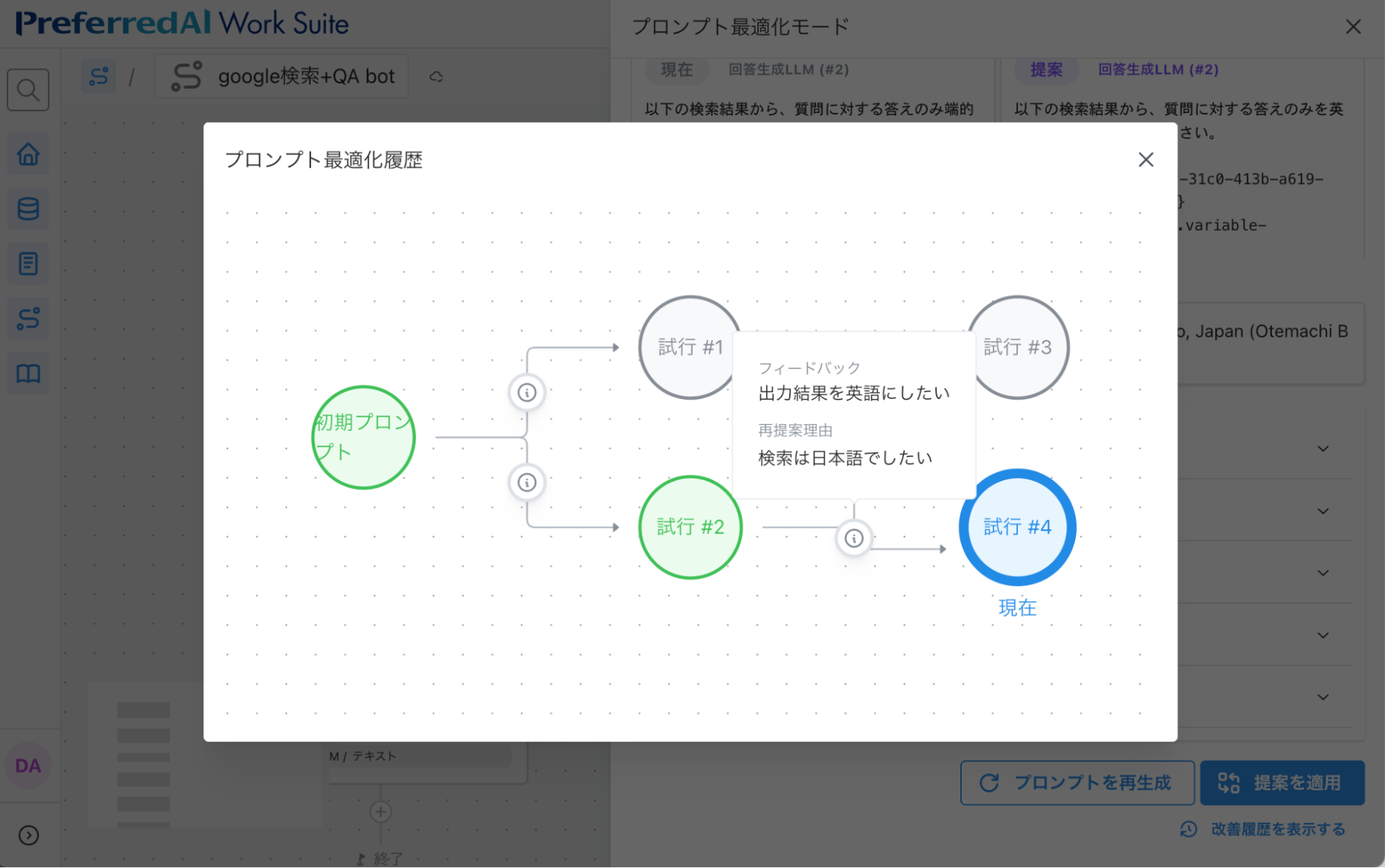
図8: プロンプト最適化の履歴をツリー構造で表すUIの様子
おわりに
本稿では、Work Suite のワークフロー機能において、ユーザがワークフロー全体に対して与える単一の定性的フィードバックを起点に、複数の LLM ブロックのプロンプト群を自動で最適化する新機能について、アルゴリズムの概要と画面上での具体例を紹介しました。
本機能は Work Suite 開発チーム単独の取り組みにとどまらず、チームの垣根を越えて、社内で育ててきた基盤技術をプロダクトへ取り込んだ事例でもあります。ベースとなった Optuna は PFN が開発する OSS で、研究用途に限らず社内の多様なプロジェクトで活用され、実運用に耐える形へ継続的に磨き込まれてきました。今回もその資産を活かしつつ、要件に合わせた拡張を行うことで、スムーズに実装へつなげることができました。
今後も、 PFN の技術力をプロダクト価値の向上に結びつけ、そこで得られた知見を基盤技術へ還元する、そのような相乗効果を持つ循環を通じて、プロダクトと技術の双方をさらに発展させていきたいと考えています。
参考文献
[1] 水野 尚人, 柳瀬 利彦, 佐野 正太郎, 自動プロンプト最適化のソフトウェア設計, 言語処理学会第30回年次大会(NLP2024), P9-2, 2024.
[2] Pryzant, Reid, et al. “Automatic Prompt Optimization with “Gradient Descent” and Beam Search.” The 2023 Conference on Empirical Methods in Natural Language Processing.