Blog
本記事の要約
- 最適化中に生成されるファイルを様々なファイルストレージ (例: ローカルファイルシステム,Amazon S3) で管理する機能であるArtifact StoreがOptuna v4.0.0で正式にサポートされました.
- 本機能を使うことで画像や音声等の幅広いファイルをOptuna Dashboard上から直接確認できます.
- 正式サポートに伴い,ダウンロード等のPython API及びOptuna DashboardでのCSV・JSONLファイル表示機能が追加されました.
- 今回は大規模言語モデルでの実験を題材に利便性向上を解説します.
Artifact Storeにはより簡単な例やTutorialも存在するため,使い方に関してはそちらも参考にしてください.尚,Optuna v4.0.0は現在β版であるため,本記事の機能を利用するためにはβ版を明示的に指定してインストールする必要があります.
# Optuna Dashboardはv0.16.0以降である必要があります. $ pip install optuna==4.0.0b0 optuna-dashboard>=0.16.0
Artifact/Artifact Storeとは?
Artifactとは最適化中に使用もしくは生成されるファイルのことを指します.例えば,大規模言語モデルのハイパパラメータ最適化を行う際には各Trialにおいて図1の赤枠内にあるような学習曲線の画像,推論結果のCSV,モデルの学習経過 (スナップショット)等を保存するかもしれません.このようなArtifactの管理やOptuna DashboardによるArtifactの可視化を手軽に行う際にArtifact Storeが非常に便利です.
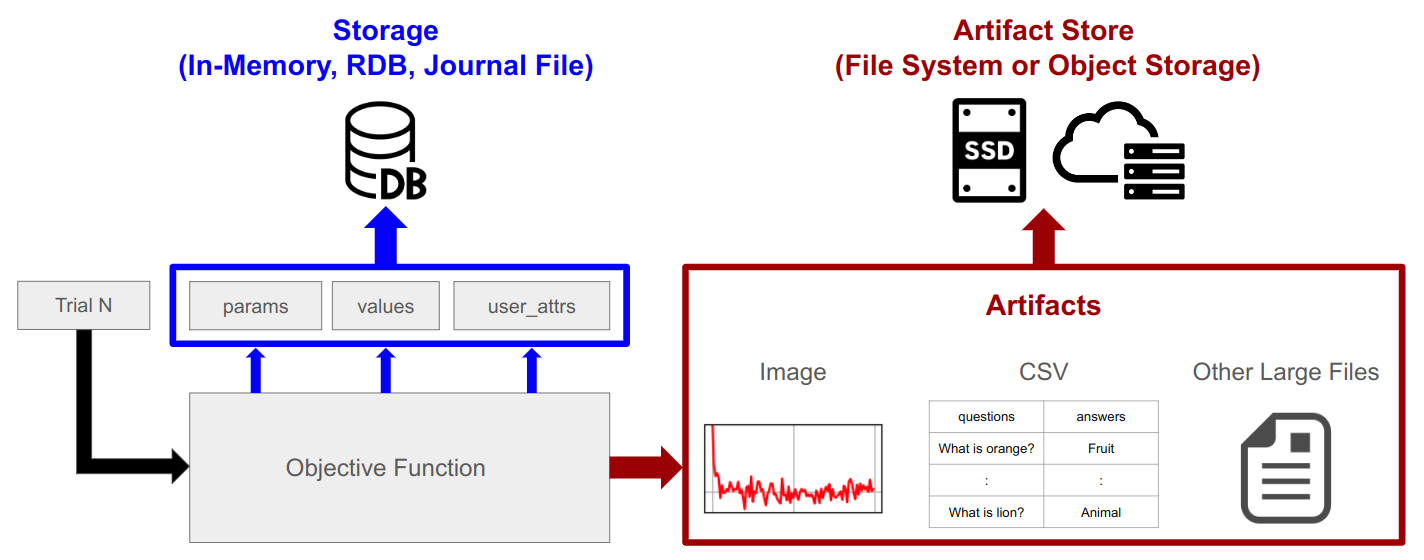
図1. OptunaにおけるArtifactの概念図.Trialを目的関数に渡すと目的関数が評価されます.目的関数内ではOptunaがパラメータ (params) を提案し,最終的に目的関数値 (values) を返す必要があります.短い文字列や簡単な辞書は従来,user_attrsに格納することでパラメータと目的関数値と共にデータベース等のストレージに格納されていました.Artifact Storeでは目的関数評価時に生成されるファイル (Artifact) を保管するために利用されます.Artifact Storeはファイルシステムやクラウドストレージを利用するため,RDB等では効率的に扱うことができないサイズの大きなデータの管理が可能になります.例えば,学習曲線画像やモデルのスナップショット等の比較的大きなデータが一例です.
Optuna v4.0.0で正式サポートされるArtifact Storeでは,TrialやStudyとファイルの紐付けを管理することができます.Artifact Storeは様々な保存先に対応しており,ファイルシステムだけでなく,Amazon S3と互換性のあるオブジェクトストレージとGoogle Cloud Storage (GCS) を指定することもできます.
前述した通り,Artifact Storeの強みはOptuna DashboardでArtifactを直接確認できることです.例えば,図2にあるようにJSONL (もしくはCSV) ファイルを表形式で表示することができます.また,音声ファイルや動画ファイルのArtifactをOptuna Dashboardで再生することも可能になっています.
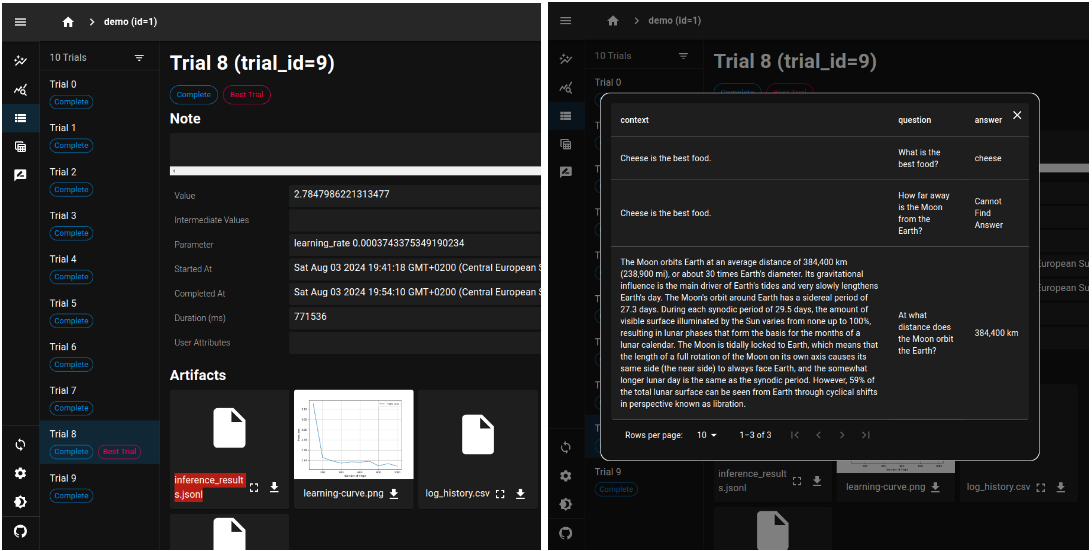
図2. Optuna Dashboard上での各TrialのArtifactとして与えられたJSONLファイルの可視化例.図ではLLMのハイパパラメータ最適化を利用しました.左側: Trialの詳細ページ.各Trialに対してLLMの訓練後に文脈 (Context) と質問 (Question) を与えたときの回答 (answer) をinference-results.jsonl (オレンジのハイライト) というファイルとして保存し,Artifact Storeにアップロードしました.右側: 各Trialの詳細ベージから該当ファイル (今回だとinference_results.jsonl) の横にある拡大のアイコンをクリックすることでファイル内容を表形式で閲覧することができます.
Optuna v4.0.0での変更点
Optuna v4.0.0では図2にあるようなOptuna DashboardのArtifact表示機能の強化に留まらず,Python API側からの利便性向上に取り組みました.具体的には,Optuna v3.6時点で提供されていたArtifactのアップロードのAPI安定化に加えて,ArtifactをダウンロードするAPI及びArtifactのダウンロード時に必要となる (TrialやStudyに紐づく) Artifactのメタ情報を列挙するAPIを追加しました.
これらの変更により,最適化終了後の実験解析や最善のTrialに紐づくArtifactのユーザコードでの利用が簡単になります.例えば,各Trialで訓練したLLMのスナップショットを圧縮ファイルにしてArtifact Storeにアップロードしていた場合,最適化終了後に最善のTrialのスナップショットをローカルファイルシステムに容易にダウンロードすることができます.次の節で実際のコードを利用して,具体的に説明したいと思います.
Artifact Storeの利用例: LLMのハイパパラメータ最適化
ここではローカルファイルシステムを用いたArtifact Storeの使用方法を説明します.まずはLLMのハイパパラメータ最適化を行い,その結果をOptuna Dashboardに表示してみようと思います.実際に利用したコードをGistに公開してあります.
今回の例では各Trialで以下のArtifactを保存したいと思います.
- LLM訓練時のログ (CSVファイル)
- 訓練後のLLMによる質問と対応する回答のまとめ (JSONLファイル)
- 訓練時の学習曲線 (PNGファイル)
- 訓練時のモデルスナップショット (GZipファイル)
実際にGist上にあるコードを実行した際に得られる結果を基にOptuna Dashboardを起動してみます.
# RDBのURLとArtifactの存在するパス (base_path)を指定してOptuna Dashboardを起動します. $ optuna-dashboard sqlite:///demo.db --artifact-dir artifacts
起動してみると,以下の動画のような結果が可視化されます.
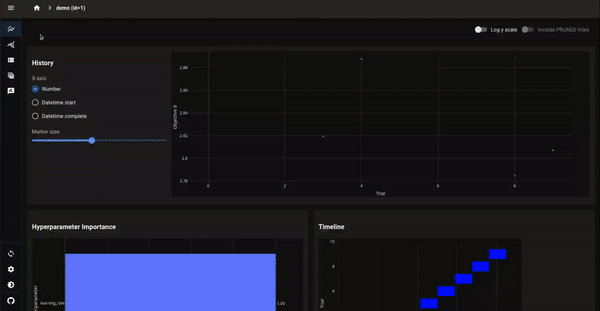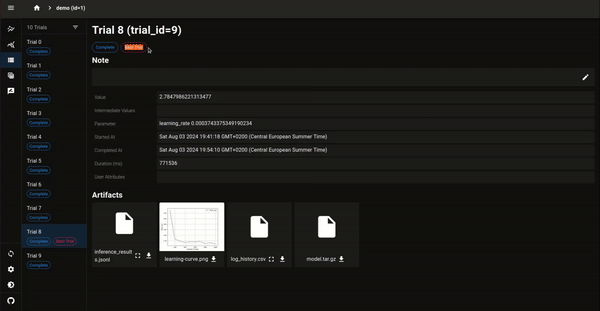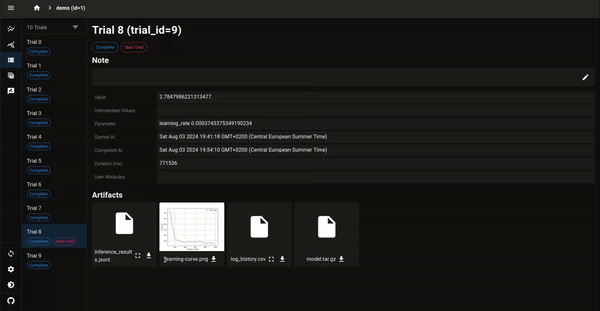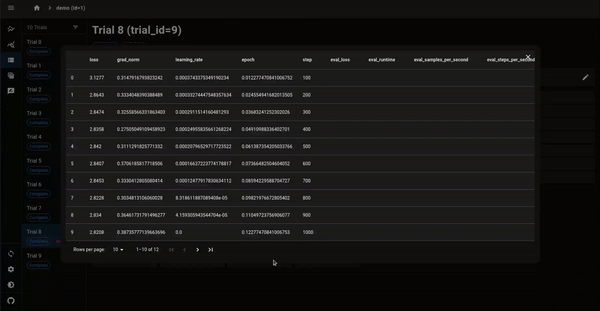
図3. 今回の利用例でOptuna Dashboardを起動したときの可視化.各Trialの詳細ページにアップロードされたArtifactが一覧となっています.CSVファイルとJSONLファイルに関しては拡大アイコンをクリックすることで表形式になります.画像ファイルに関してはサムネイルが表示されます.CSV (訓練時のログ)とJSONLファイル (訓練後のLLMの回答集) が表形式で確認できます.
次にPython APIを見るために,Gist上のコードを以下に改変・抜粋します.
import optuna
# Artifactはこのディレクトリに保存されます.
base_path = "artifacts"
# Artifactを保存するディレクトリを作成します.
os.makedirs(base_path, exist_ok=True)
# 上記のディレクトリパスを指定してArtifact Storeをインスタンス化します.
artifact_store = optuna.artifacts.FileSystemArtifactStore(base_path)
def objective(trial):
# Optunaによってパラメータの提案をします.
train_params = suggest_train_params(...)
# Optunaによって提案されたパラメータを利用してモデルを訓練します.
trainer = ...; trainer.train()
# 訓練したモデルにいくつかの質問を回答させて,その結果をファイルに記録します.
inference(...)
# 回答集ファイルをartifact_storeにアップロードします.
optuna.artifacts.upload_artifact(study_or_trial=trial, file_path=inference_path, artifact_store=artifact_store)
# 学習曲線画像,ログ,モデルのスナップショットも同様に生成して,アップロードします.
...
valid_loss = ...
return valid_loss
storage = optuna.storages.RDBStorage("sqlite:///demo.db")
study = optuna.create_study(storage=storage, study_name="demo")
study.optimize(objective, n_trials=10)
この例ではArtifact StoreのユーザAPIの一つである upload_artifact を利用して,各ファイルをFileSystemArtifactStoreで指定している base_path にアップロードしています.上記の例にあるように,アップロードしたいファイルがファイルシステム上に存在していれば,Artifactのアップロードは1行で済みます.
また,Optuna v4.0.0で強化されたAPIを利用すれば,最善のTrialで得られたモデルファイルのダウンロードもユーザコードから容易に行うことができます.
# 最善のTrialを取得します. best_trial = study.best_trial # これはアップロート時に利用したモデルのスナップショットが保管されたファイル名です. model_file_name = "model.tar.gz" # 最善のTrialに紐づく全てのArtifactのメタ情報を取得します. artifact_meta = optuna.artifacts.get_all_artifact_meta(trial, storage=storage) # モデルのスナップショットファイルのArtifact IDを取得します. artifact_id_for_model = [am.artifact_id for am in artifact_meta if am.filename == model_file_name][0] # 最善のTrialで訓練されたモデルのスナップショットをdownload_file_pathにダウンロードします. download_file_path = "./best_model.tar.gz" optuna.artifacts.download_artifact( artifact_store=artifact_store, file_path=download_file_path, artifact_id=artifact_id_for_model, )
上記のコードにより,モデルのスナップショットをPython APIから指定したパスにダウンロードできました.ダウンロードのPython APIが提供されたことにより,ユーザコードからのArtifactの再利用が容易になりました.
まとめ
Optuna v4.0.0でArtifact Storeによる実験管理機能のPython APIを強化しました.今回示した例にあるとおり,最適化後のユーザコードからのArtifact再利用が簡単になりました.また,Optuna Dashboard上での可視化機能も改善されて,表形式の表示が可能になりました.今回の利用例は以上になりますが,Artifact StoreにはTutorialやより簡単な例も用意されているため,そちらも参考にしてください.
Optunaチームでは一緒にOptunaやOptunaHubを開発するパートタイムエンジニアを随時募集しています.また,OptunaHubの機能開発をメインとした短期の募集も開始しました.本記事を通して,ご興味を持っていただけたという方はぜひ下記ページより詳細をご確認ください.
- Software engineer (Optuna) / ソフトウェアエンジニア(Optuna) / 株式会社Preferred Networks
- Software engineer (Optuna – Short Term) / ソフトウェアエンジニア(Optuna・短期)/ 株式会社Preferred Networks
Tag