Blog
はじめに
最適化アルゴリズムの性能評価を行うベンチマーキングは、アルゴリズムの研究や開発に欠かせない重要なプロセスです。アルゴリズムの開発段階ではアイデアの効果を測定するため、発表段階では既存手法に対する提案手法の優位性を示すためにベンチマークが実施されます。また、異なる問題設定やアプリケーションに適した多様な最適化アルゴリズムが存在するように、アルゴリズムを評価するためのベンチマーク問題にも多種多様なものが存在します。
OptunaHub Benchmarksは、optunahubの最新バージョンであるv0.2.0に新たに追加された、ベンチマークを便利に行うための新機能です。本機能を用いることで、以下のような恩恵を得ることができます。
- パッケージ名を切り替えるだけで、様々なベンチマーク問題を統一されたAPIを介して使用可能
- ベンチマーク結果をoptuna.visualizationモジュールやoptuna-dashboardを用いて即座に分析可能
- 汎用APIを介してOptuna以外の最適化フレームワークからもベンチマーク問題を利用可能
- optunahubライブラリを用いて簡単に新規にベンチマーク問題を作成しパッケージとして公開可能
以下はOptunaHub Benchmarksを用いるコード例です。このように、ユーザは簡単にベンチマーク関数の読み込み、最適化の実行、結果の可視化を実現することができます(より実用的な例は、付録:実践的なベンチマークのコード例をご参照下さい)。
import optuna
import optunahub
bbob = optunahub.load_module("benchmarks/bbob")
sphere2d = bbob.Problem(function_id=1, dimension=2, instance_id=1)
study = optuna.create_study(sampler=optuna.samplers.TPESampler(seed=42), directions=sphere2d.directions)
study.optimize(sphere2d, n_trials=20)
optuna.visualization.plot_optimization_history(study).show()
本記事では、OptunaHub Benchmarksの使い方について詳しく紹介します。
OptunaHub Benchmarks
OptunaHub Benchmarksにできることは、大きく分けて以下の2つです。
- OptunaHub上に公開されているベンチマーク問題の利用
- OptunaHubへのベンチマーク問題の登録
OptunaHub Benchmarksの利用にはoptunahubの最新バージョンであるv0.2.0が必要です。記事の内容をお試しいただく前に、optunahubのインストール、アップグレードをお願いします。
pip install optunahub==0.2.0 --upgrade
公開されているベンチマーク問題の利用
OptunaHubに公開されているベンチマーク問題を利用する方法について、冒頭のサンプルコードを例にして解説します。サンプルコードの実行にはcoco-experimentのインストールが必要なことに注意してください。
pip install coco-experiment # サンプルコードの依存
OptunaHubのベンチマークはSampler等と同様にpackageとして実装されており、benchmarksカテゴリ以下に登録されています。このため、他のカテゴリのpackageと同様にload_module関数を用いて簡単に読み込むことができます。
冒頭のサンプルコードの4行目では、"benchmarks/bbob"パッケージ(以下bbobパッケージ)を使用しています。bbobパッケージは、Blackbox Optimization Benchmarking (BBOB)と呼ばれるブラックボックス最適化の研究コミュニティで広く用いられている24種類のベンチマーク関数からなる問題集を提供するもので、オリジナル実装である COCO (COmparing Continuous Optimizers) experimentライブラリのOptuna向けのラッパー実装になっています。
bbob = optunahub.load_module("benchmarks/bbob")
5行目では、bbob.Problemにfunction_id=1, dimension=2, instance_id=1を設定しインスタンス化することで、24種類のベンチマーク関数のうちfunction_idが1番のSphere関数の2次元版でinstance_idが1番の問題オブジェクトを取得しています。
sphere2d = bbob.Problem(function_id=1, dimension=2, instance_id=1)
6-7行目では、studyを作成し、最適化を実行しています。問題オブジェクトには、最適化方向を表すdirections属性やOptunaの目的関数として利用できる形式の__call__(trial)メソッドが適切に定義されており、簡単に最適化を実行できます。
study = optuna.create_study(sampler=optuna.samplers.TPESampler(seed=42), directions=sphere2d.directions) study.optimize(sphere2d, n_trials=20)
このようにOptunaHub Benchmarksのbbobパッケージを利用することで、COCOを直接利用してOptunaの目的関数を自前で定義する場合に比べて、ユーザコードの記述量は半分程度になります(図1)。
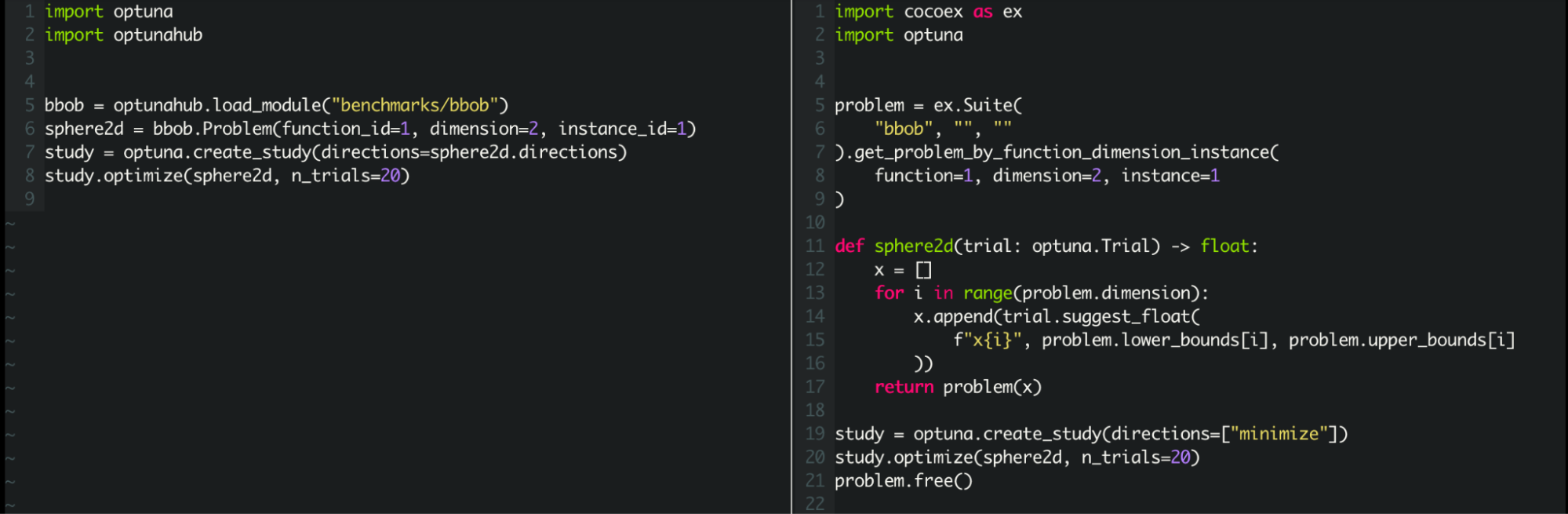
図1:OptunaHub Benchmarksを利用する場合(左)と、COCOを直接利用する場合(右)のユーザコードの比較
bbobパッケージでは、Problemに渡すfunction_idを変えることで24種類のベンチマーク関数(図2)を切り替えることができるほか、dimensionやinstance_idを設定することで次元や最適解の位置が異なる各関数の複数のバリエーションを利用可能です。詳細はbbobパッケージのドキュメントを参照してください。
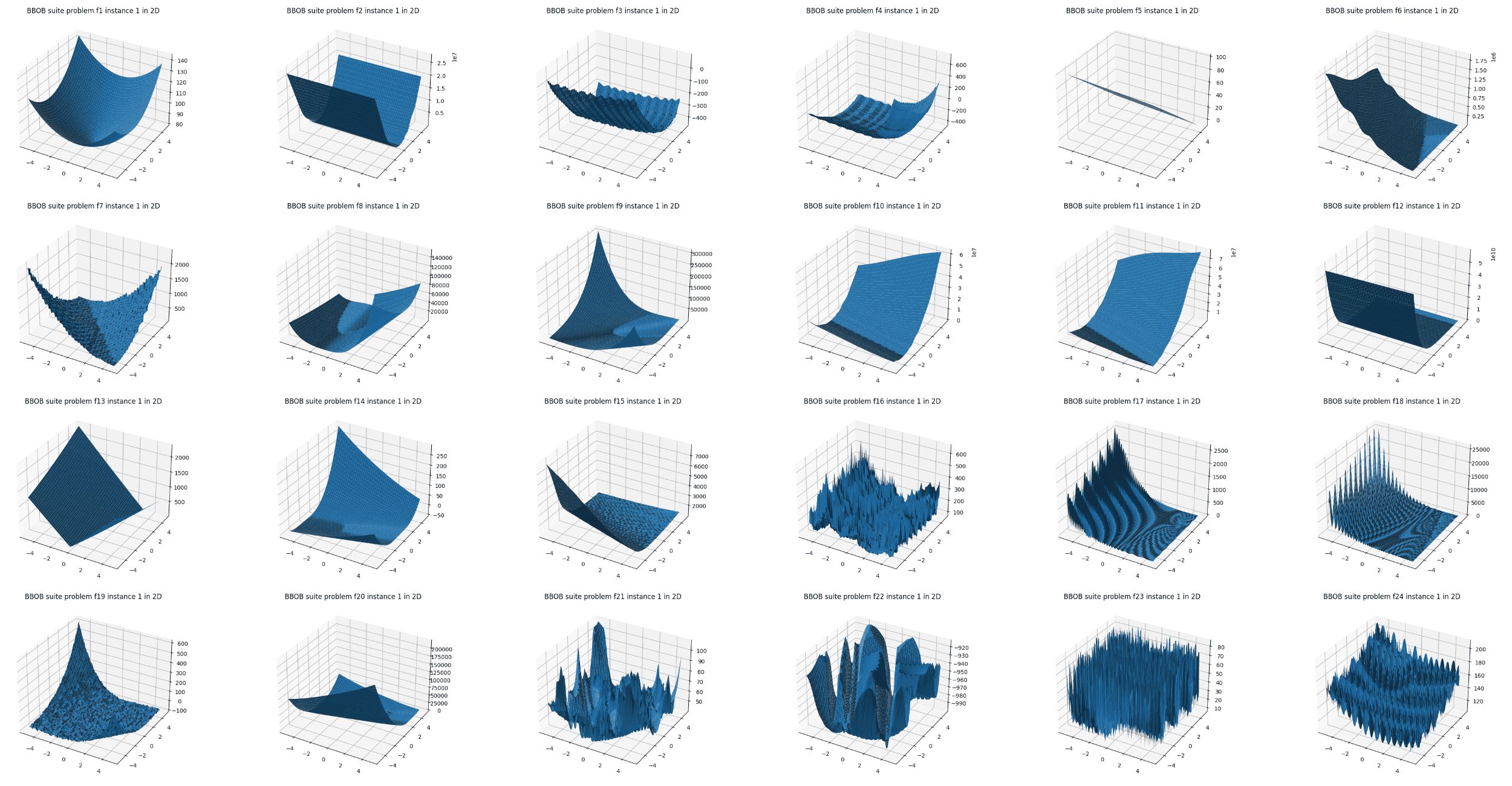
図2:Blackbox Optimization Benchmarking (BBOB) Suiteに含まれる24種類のベンチマーク関数
現在OptunaHubのbenchmarksカテゴリには、bbobパッケージの他にも54種類の制約付き最適化問題を収録したbbob-constrainedや、多目的最適化で実績のあるWFGベンチマーク、ハイパパラメータ最適化のベンチマーク問題集であるHPOBenchなどが登録されており、同様に利用することができます。ぜひお試し下さい。また、利用可能なベンチマークは今後も拡充させていく予定です。
Optuna以外の最適化フレームワークからのベンチマークの利用(汎用API)
bbob.ProblemクラスにはoptunaのTrialを引数に取り目的関数値を返す__call__(trial)に加えて、変数名と値の組からなる辞書を引数に取り目的関数値を返すevaluateメソッドも定義されているため、Optuna以外からも簡単にベンチマークを利用できます。
sphere2d.evaluate({"x0": 0, "x1": 0}) # 辞書を入力として目的関数を評価することも可能
以下はOptunaの代わりにscipy.optimize.minimizeを用いて先程のsphere2dを最適化する例です。目的関数として簡単なlambda式を用意し、内部でevaluateを呼び出しています。また、bbob packageのProblemからはBBOBのオリジナル実装であるCOCOが提供するattributesも利用出来るようになっており、ここではx0およびboundsの取得にinitial_solution, lower_bounds, upper_bounds attributesをそれぞれ利用しています。
import scipy
result = scipy.optimize.minimize(
fun=lambda x: sphere2d.evaluate({f"x{d}": x[d] for d in range(sphere2d.dimension)}),
x0=sphere2d.initial_solution,
bounds=scipy.optimize.Bounds(
lb=sphere2d.lower_bounds, ub=sphere2d.upper_bounds
)
)
ベンチマーク問題の作成と公開
OptunaHub Benchmarksでは、既存のベンチマークを便利に利用出来るだけでなく、あなた自身が実装したベンチマークをパッケージとして新規に公開することも出来ます。ここでは、ベンチマーク問題の作成と公開方法について解説します。
新しい問題を作成するには、optunahub.benchmarks.BaseProblemを継承したクラスを作成し、以下のsearch_space, directions, evaluateを定義するだけです。
search_space(self) -> dict[str, optuna.distributions.BaseDistribution]- ベンチマーク問題の変数名と分布の組からなる探索空間を返すメソッドを実装します。
directions(self) -> list[optuna.study.StudyDirection]- 最適化方向のリストを返すメソッドを実装します。最小化問題なら
[optuna.study.StudyDirection.MINIMIZE]、最大化問題なら[optuna.study.StudyDirection.MAXIMIZE]、多目的最適化問題であれば各目的関数に対応する方向を格納したリストを返す必要があります。
- 最適化方向のリストを返すメソッドを実装します。最小化問題なら
evaluate(self, params: dict[str, float]) -> float | Sequence[float]- 辞書を引数に取り、目的関数値を返すメソッドを実装します。
2次元のSphere関数の実装例は以下のようになります。
class Sphere2D(optunahub.benchmarks.BaseProblem):
@property
def search_space(self) -> dict[str, optuna.distributions.BaseDistribution]:
return {
"x0": optuna.distributions.FloatDistribution(low=-5, high=5),
"x1": optuna.distributions.FloatDistribution(low=-5, high=5),
}
@property
def directions(self) -> list[optuna.study.StudyDirection]:
return [optuna.study.StudyDirection.MINIMIZE]
def evaluate(self, params: dict[str, float]) -> float:
return params["x0"]**2 + params["x1"]**2
上記はオリジナルの問題を作成するための最も簡単な構成ですが、これに加えて任意の追加のattributeやメソッドを持たせることも可能です。例えば、__init__()メソッドに追加の引数を独自に定義して可変次元にすることができます(チュートリアルのSphereNDを参照)。先程紹介したbbobパッケージもoptunahub.benchmarks.BaseProblemを継承して実装されているので、気になる方はぜひ実装を見てみて下さい。
実装したベンチマーク問題は、パッケージとしてoptunahub-registryリポジトリにプルリクエストを作成することでOptunaHubへの登録が可能です。詳しくは以下の各種チュートリアルをご覧下さい。
おわりに
本記事では、optunahub v0.2.0で追加されたベンチマークのための新機能であるOptunaHub Benchmarksについて紹介しました。
OptunaHub Benchmarksを利用することで、気軽に様々な問題を利用してアルゴリズムのベンチマークを行うことができます。アルゴリズムの研究開発用途のほかにも、実問題に取り組む前の簡単な予備実験での利用、アルゴリズム学習時のトイプロブレムとしての利用など、色々なユースケースが考えられる機能なので、ぜひともご活用していただければと思います!
また、利用可能なベンチマークのパッケージを今後も充実させていきたいと考えているので、具体的なベンチマーク問題のリクエストや、ベンチマーク実装者からのプルリクエストについてもoptunahub-registryリポジトリにてお待ちしております!
付録:実践的なベンチマークのコード例
ここでは、より実践的なベンチマークのコード例を結果の可視化も含めて紹介します。
ベンチマークの実験設定を以下のように定めます。
- BBOBの24種類の関数でベンチマークを実行
- 関数の次元数は2次元 (
dimension=2)、インスタンスは1番 (instance_id=1) で固定 - 比較対象は
TPESamplerとCmaEsSampler - 各問題に対して、Samplerのランダムシードを変えた10試行の平均性能を評価し、平均値と標準誤差をプロット
上記の実験設定でベンチマークを行うコード例は以下のようになります。
import itertools
import matplotlib.pyplot as plt
import numpy as np
import optuna
import optunahub
import pandas as pd
plt.rcParams["font.family"] = "Times New Roman"
plt.rcParams["mathtext.fontset"] = "stix" # The math font setup.
plt.rcParams["text.usetex"] = True
samplers = [optuna.samplers.TPESampler, optuna.samplers.CmaEsSampler]
def collect_results(
dimension: int = 2, instance_id: int = 1, n_seeds: int = 10, n_trials: int = 100
) -> pd.DataFrame:
bbob = optunahub.load_module("benchmarks/bbob")
results = []
# Compare TPESampler and CmaEsSampler using BBOB 24 problems over 10 random seeds.
for sampler_class, function_id, seed in itertools.product(
*(samplers, range(1, 25), range(n_seeds))
):
sampler = sampler_class(seed=seed)
objective = bbob.Problem(function_id, dimension, instance_id)
study = optuna.create_study(sampler=sampler, directions=objective.directions)
study.optimize(objective, n_trials=n_trials)
results.append(
{
"sampler_name": sampler_class.__name__,
"seed": seed,
"function_id": function_id,
"values": np.minimum.accumulate([t.value for t in study.trials]),
}
)
return pd.DataFrame(results)
def plot_results(df: pd.DataFrame, dimension: int = 2, instance_id: int = 1) -> None:
sampler_names = [sampler_class.__name__ for sampler_class in samplers]
n_seeds = len(df["seed"].unique())
x_axis = np.arange(len(df["values"].iloc[0])) + 1
fig, axes = plt.subplots(4, 6, figsize=(20, 10), sharex=True, tight_layout=True)
lines = [None] * len(sampler_names)
for sampler_name, function_id in itertools.product(*(sampler_names, range(1, 25))):
target_rows = df[(df["sampler_name"] == sampler_name) & (df["function_id"] == function_id)]
mean = np.mean([vs for vs in target_rows["values"]], axis=0)
sem = np.std([vs for vs in target_rows["values"]], axis=0) / np.sqrt(n_seeds)
ax = axes[(function_id - 1) // 6, (function_id - 1) % 6]
ax.set_title(f"{function_id=}")
lines[sampler_names.index(sampler_name)], = ax.plot(x_axis, mean, label=sampler_name)
ax.fill_between(x_axis, mean - sem, mean + sem, alpha=0.3)
ax.grid(True)
fig.suptitle(f"{instance_id=} in {dimension}D", fontsize=20)
fig.supxlabel("\# of Trials", fontsize=20)
fig.supylabel("Objective", fontsize=20)
fig.legend(handles=lines, labels=sampler_names, ncol=len(sampler_names), loc="upper right", fontsize=18)
plt.show()
df = collect_results(n_seeds=10, n_trials=100)
plot_results(df)
上記コードを実行すると、図3のようなグラフを得ることができます。
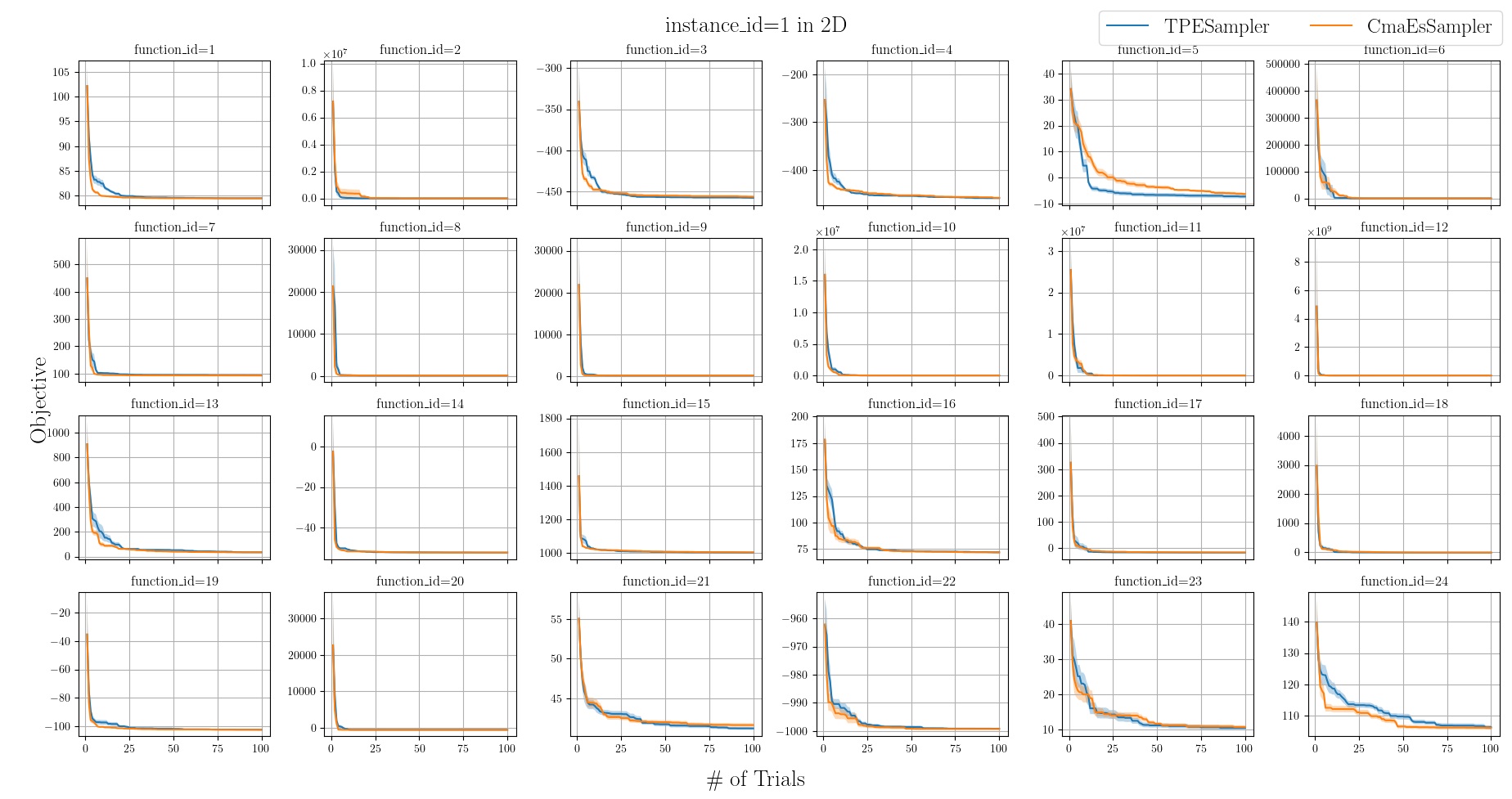
図3:BBOBを用いたTPESamplerとCmaEsSamplerのベンチマークの実行結果
実際のプロジェクトでは、この後、実験の結果をもとに考察や議論を行ったり、必要に応じて可視化方法を変更したり、結果の検定等を行うことになります。本例が、皆さんのプロジェクトにおける応用への参考になれば幸いです。