Blog
本記事は、2024 年夏季インターンシッププログラムで勤務された田村敢太さんによる寄稿です。
1. はじめに
PFN 2024 夏期国内インターンシップ「JE03. ストレージエンジニア就業体験」に参加させていただいた、大阪大学 M1の田村 敢太です。
普段はSmartNICを用いたネットワーク関連の研究を行っています。
今回のインターンシップでは、PFNの自社ストレージを管理・運用しているチームで、ストレージI/Oライブラリへのプロファイラの実装に取り組みました。
2. 背景
2.1 PFIO
PFNでは、自社でS3互換やNFSに対応したストレージを運用しており、それらに共通のインターフェースでアクセス可能にするI/O抽象化ライブラリ PFIO [1]を開発しています。
PFIO は、異なるストレージシステムの違いを吸収し、ユーザが作成した機械学習アプリケーションがデータを容易に扱えるように設計されています。
さらに、非POSIX準拠のファイルシステムにおいても効率的なデータアクセスを提供するためにキャッシュ機能も備えています。
PFIOの主な機能は以下のようになっています。
- ファイルシステムAPIの抽象化・隠蔽
S3、NFS、ローカルファイルシステムなど、異なるストレージシステム間の違いを意識せず、統一されたインターフェースでアクセスできるようにする機能です。これにより、ユーザはストレージごとのAPIを意識することなく、アプリケーションを開発できます。 - キャッシュAPIの抽象化・隠蔽
PFIOは、HttpFileCacheやMultiProcessFileCacheのようなキャッシュ機能も提供しており、データを効率的に扱えるようになっています。キャッシュ機能によって、リモートストレージへの頻繁なアクセスを抑え、ローカル環境でのデータ読み込みが高速化されます。また、MultiProcessFileCacheは複数プロセス間でのキャッシュの共有も可能で、並列処理においてもパフォーマンスを発揮します。 - アーカイブファイルの抽象化・隠蔽
多数の小さなファイルを個別に保存するとストレージやファイルシステムに対して多くの処理が発生する問題を防ぐために、アーカイブ形式で保存することが効果的です。データ利用時にアーカイブ形式を解凍してからファイルにアクセスするのでは二度手間になるため、PFIOではアーカイブファイル (ZIP) 内のデータを直接読み込める設計となっています。これによって、アーカイブ形式で大量のデータを扱うケースでも、効率的にファイルアクセスが行えるように設計されています。
これらの機能は個別に使用することも可能ですが、組み合わせて使用することで、機械学習フレームワークのデータローダに対して、ファイルシステムの違いを抽象化しつつ、効率的なキャッシュ処理とアーカイブファイルへのアクセスを提供することが可能です。
これにより、機械学習におけるデータの読み書きを効率化し、学習の高速化が期待できます。
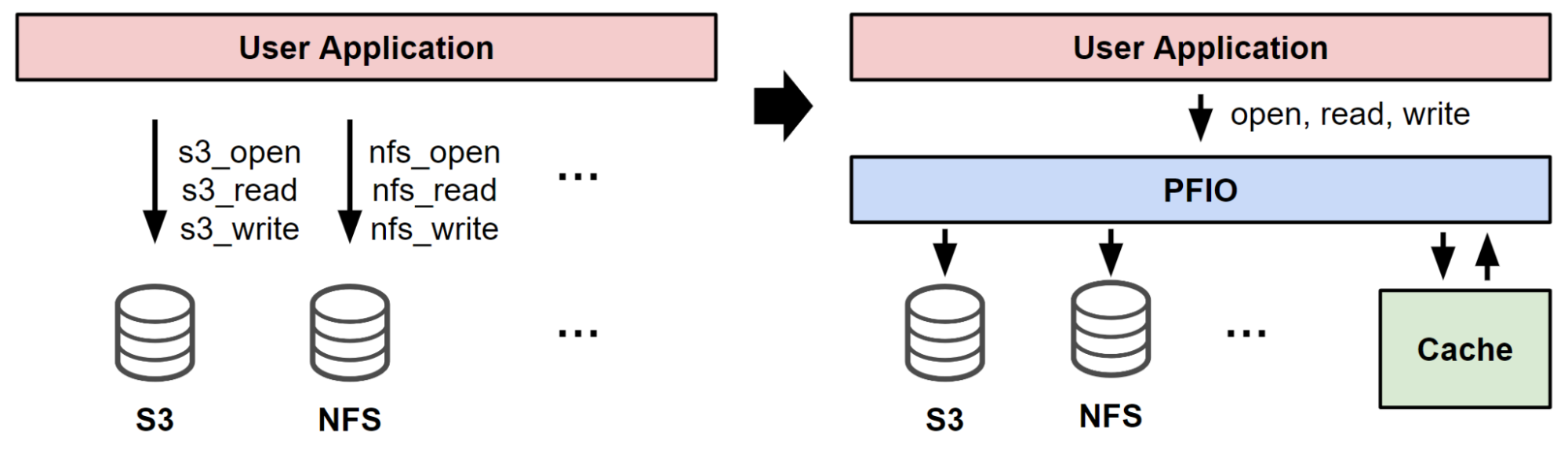
2.2 I/Oプロファイラの必要性
このとおりPFIOにはいくつかの機能があり、ユーザはこれらを組み合わせることでストレージI/Oを効率化できますが、その組み合わせ方は状況によって異なるため自明ではありません。場合によっては、ユーザがストレージに関して最適な設計ができず、期待する性能が出ない場合もあります。
アプリケーションの性能が十分に発揮されない場合、I/Oの遅延やデータ処理の遅さが原因かを判断することは非常に困難です。これはPFIOによって、ストレージやキャッシュ、アーカイブファイルを抽象化しているため、どのストレージが使われているのか、キャッシュが効いているのか、ZIPファイルがどのように扱われているのかが実行時にわかりにくくなっていることが原因です。I/Oプロファイリングを行うことで、これらの詳細を把握し、問題の原因を迅速に突き止めることが可能になります。
社内サポートにおいても、これまでは各プロジェクトの実装を個別に確認しデバッグしていたと聞いています。I/Oプロファイラがあれば実アプリケーションの実行結果と一緒にプロファイル結果を確認するだけで問題を特定できるため、サポートの負担も軽減され、効率的な対応が可能になります。
3. PFIOへのプロファイル機能の対応
3.1 pytorch_pfn_extras
pytorch_pfn_extras (以下PPE) [2] は、PyTorchにおけるユーザ体験を向上させるためのライブラリです。
このライブラリは、学習の進捗状況をわかりやすく表示したり、損失値などのログを効率的に出力する機能を提供します。
さらに、PPE では、Trace Event Format [3] で結果を保存できるプロファイラを搭載しており、学習のプロファイル結果を視覚的に確認することが可能です。
Trace Event Format で出力されたJSONファイルは、ChromeのTrace Event Profiling Tool [4] によって下図のように、プロセスID (pid)、タグ (tag)、実行時間 (dur) などの情報をタイムライン形式でブラウザで表示できます。
これにより、学習中における各タスクの実行時間や、どの部分がボトルネックになっているかを簡単に特定することができ、モデルの学習の高速化を支援します。

PPEのプロファイラの使い方は、次のコード例のように record コンテキスト内での処理が開始してから終了するまでの時間とタグを保存し、その情報をTrace Event Profiling Tool で読み込めるJSONファイルとして出力します。また、trace オプションを用いることで、プロファイリングを有効化するか無効化するかを選択できます。
with ppe.profiler.record("func_a", trace=True):
a()
with ppe.profiler.record("func_b", trace=False):
b()
with ppe.profiler.record("func_c", trace=True):
c()

図に示すように、trace=True の場合はプロファイラが有効化され、指定された関数の実行時間が記録されます。一方、trace=False に設定すると、該当箇所はプロファイリングの対象外になります。
今回は、このPPEのプロファイル機能を用いてPFIOにI/Oプロファイラを追加します。
3.2 PFIOにおけるプロファイル機能の実装
実装にあたって、いくつか注意した点があります。
まず、PPE が導入されていなければ、プロファイラは有効にならない設計にしています。これは、PFIO自体がPPEに依存しない設計であるためであり、プロファイラ機能はPPEに依存しているため、PPEが導入されている場合にのみプロファイラが動作するようにして、既存のコードや機能に影響を与えないようにしました。
つぎに、ユーザがプロファイラの有効/無効を自由に選択できる設計を行いました。これは、プロファイラは主にデバッグ用であり、プロファイラを有効にするとわずかにパフォーマンスが低下する可能性があるため、この選択肢を提供しています。
ここで、ファイルシステム (FS) のオブジェクトを生成するときにオプションとして渡すことで、透過的にプロファイル対応を導入できるように設計しました。この設計によって、ユーザはアプリケーションのI/Oコールをすべて修正する必要がなくなり、既存のコードの変更は最小限に抑えられます。
このように、パフォーマンスへの影響も最小限に抑えつつ、デバッグ時には詳細なI/O情報を得られる設計を目指しました。
- PPEに依存しない設計
PPEが存在しない場合でも正常に動作するために、以下のコードのようにimportに失敗した場合にPPEのrecord関数に代わり、ダミーのrecord関数を用いるように実装しました。

- ユーザによるプロファイラの有効/無効の選択
from_url や open_url のようなFSを生成する関数に trace オプションを追加しました。デフォルト値は False に設定しています。この trace オプションは各ファイルシステムのAPIで使われている record 関数に伝搬し、値に応じてプロファイリングが有効化されます。

3.3 インターン期間の目標
今回のインターンのゴールは、PFIOにプロファイラを実装し、ライブラリの利用者がストレージI/Oのパフォーマンス問題をより簡単に特定できるようにすることです。具体的には、PFIO内のいくつかの主要コンポーネントに対してプロファイラ機能を追加しました。
どのコンポーネントに対応するかを選ぶ際に、まずはコードベースに慣れることも考慮して、ローカルのファイルシステム (pfio.v2.Local)などのシンプルな部分から着手しました。これにより、コード全体の理解を深めつつ、プロファイラ機能の基本的な実装方法に慣れることができました。
次に、利用頻度が高いコンポーネントを優先してプロファイラ実装を行いました。PFIOの主要機能(ストレージ、キャッシュ、アーカイブファイルなど)は多くのアプリケーションで利用されているため、これらを優先することで、多くのユーザーにとって実用性の高い機能拡張となるようにしました。その後、PFIOのIssue #258に挙げられているコンポーネントについて、順番にプロファイリング機能を追加していきました。以降の章ではプロファイラ機能の実装手法について各クラスごとに解説します。
4. PFIOの各クラスへの実装
4.1 pfio.v2.Local
対応コミット:https://github.com/pfnet/pfio/commit/bdc81e5f3ae4fc0c8aaa6e46cdd725b4aafd1e4b
pfio.v2.Local クラスは、ローカルストレージやマウントされたNFSストレージを扱うクラスです。このクラスにプロファイラを追加する作業は、基本的には with record() でコードを囲むだけなので、比較的簡単に対応できます。ただし、ファイルシステムに対する実際のread や write 操作は標準モジュールである io.open() のインスタンスにより呼び出されるため、これらの関数の挙動を追跡可能にする必要があります。しかしながら、io モジュールの全ての関数呼び出しに対してrecordを追加するのはDRYの観点からも現実的ではありません。
この問題を解決するために、BufferedReader などをラップするクラスを定義し、メソッドが呼ばれるたびにプロファイラを追加しています。以下のコードはそのラップクラスの実装例です。
class LocalProfileIOWrapper:
def __getattr__(self, name):
attr = getattr(self.fp, name)
def wrapper(*args, **kwargs):
with record(f"pfio.v2.Local:{attr.__name__}", trace=True):
return attr(*args, **kwargs)
return wrapper
このクラスは、ファイル操作時にプロファイラを挿入するためのラッパーで、__getattr__ メソッドを利用してファイル操作(例えば read や write)が行われる際に、自動的にプロファイリングが適用されるようにしています。
動作確認
動作確認として、特定のディレクトリ下のファイルに対して open や read を繰り返し実行しました (下図)。このとき、ファイルの open → read → close という一連の処理が正常にプロファイルされていることが確認できました。さらに、プロファイリング結果から、操作がマイクロ秒(μsec)単位で行われていることが分かり、I/O処理が全体の処理時間に占める割合は比較的小さいことが chrome::tracing の出力から容易に得られることがわかりました。

4.2 pfio.v2.S3
対応コミット:https://github.com/pfnet/pfio/commit/43ea5de63bb90f04b7202536ab349babdd7bac39
pfio.v2.s3 クラスは、S3互換のファイルシステムを扱うクラスです。このクラスに対するプロファイラの追加は、基本的には pfio.v2.Local クラスの場合と同様に行いますが、S3特有の要素として、 AWS API (boto3 [5])の発行時間もプロファイルしています。これにより、どの程度の頻度でAWSのAPI呼び出しが発生しているかや、その実行時間も把握できます。
具体的には、read や write 実行中のAWS API発行にかかった割合もプロファイルできます。また、特にwrite 操作においては、PFIOは独自のObjectWriterによって32MBにバッファリングしてからboto3のアップロードAPIを呼び出す構造となっているため、実際にデータがどのタイミングでS3に書き込まれているかも記録できるようにしました。これにより、バッファリングとAPI発行のタイミングが視覚化されます。
動作確認
動作確認として、社内で運用されているS3互換ストレージ [6] に対してデータを書き込む処理を実行しました (下図)。
ここで、PFIOのバッファリング動作も確認するために、8MBのデータを繰り返しストレージに書き込むサンプルプログラムを実行しました。
pfio.v2.S3:write タグが複数回現れているが、実際に書き込みが行われた (boto3 APIが発行された) のは4回目であり、32MBバッファリングしてから書き込んでいることが確認できました。

4.3 pfio.v2.Zip
対応コミット:https://github.com/pfnet/pfio/commit/14f023288f626e9e742ac1704c978ba550b501e7
pfio.v2.Zip クラスは、アーカイブファイル (ZIP) を扱うクラスです。このクラスは、初期化時に zipfile.ZipFile オブジェクトを生成し、以降のread や write 操作には Local や S3 クラスを用いて、アーカイブ全体を展開することなくアーカイブファイル中の部分データの入出力を行います。
初期化時にアーカイブファイルをロードする際に時間がかかることがあるため、この部分も追加でプロファイラで記録します。これにより、アーカイブファイルのロード時間がどの程度パフォーマンスに影響を与えているかを把握することができます。
動作確認
動作確認として、ローカルファイルシステムにあるzipファイルを開き、アーカイブされているファイルを1つずつ読み込む処理を実行しました (下図)。
Local.read のタグが zip.read のタグ内に含まれますが、これは、Zip クラスが内部的に Local や S3 のクラスを使用してファイルを操作しているため、ネストされたプロファイリング結果が得られています。
このように、zipファイル操作時の実際のI/Oの占める割合を視覚的に確認することができます。

4.4 pfio.cache.MultiProcessFileCache
対応コミット:https://github.com/pfnet/pfio/commit/09e15ed30cb864b80903edb0b95eae4001c784d5
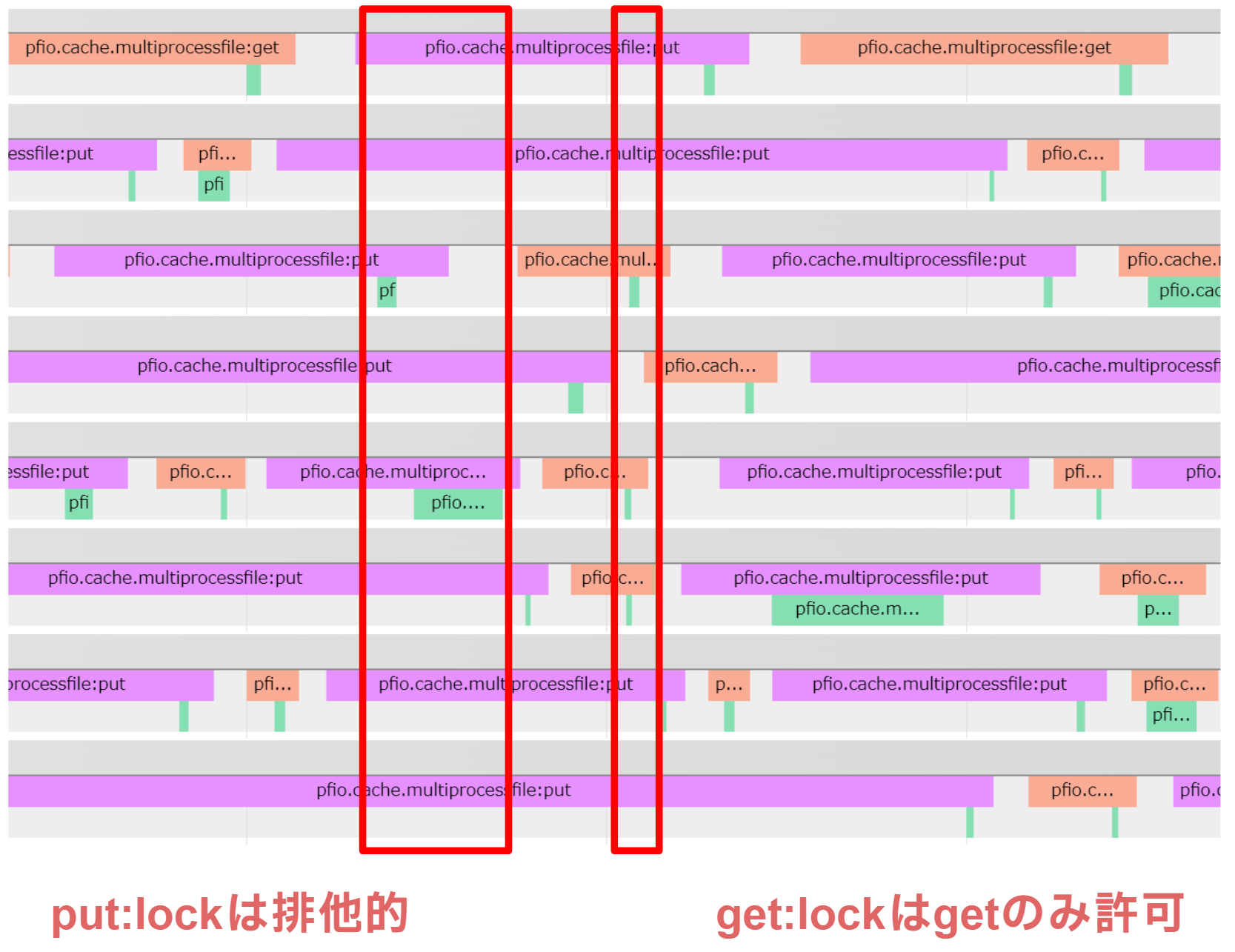
pfio.cache.MultiprocessFileCache クラスは、キャッシュにデータが存在すれば取り出す (get)、存在しなければデータを書き込む (put) 処理を行うクラスです。特にマルチプロセス環境での並列処理に対応しており、複数プロセス間でのキャッシュの共有が可能です。このクラスにプロファイラを追加するにあたり、get および put メソッドに対してプロファイリングを行い、並列環境でのI/Oパフォーマンスを詳細に観察できるようにしました。
また、書き込みや読み込み時にファイルディスクリプタ (fd) に対してロックを取得して競合を防ぐ必要があるため、ロックがかかっている期間もプロファイラで測定します。具体的には、書き込み時には1つの箇所にロックがかかり、読み込み時には get 操作のロックのみが許可されるように設計されています。
このプロファイラの追加により、ロックがどの程度の時間にわたって保持されているか、またその影響がパフォーマンスにどのように現れているかを詳細に把握することができます。
動作確認
動作確認として、複数プロセスでファイルキャッシュに書き込み・読み込みを繰り返す処理を実行しました (下図)。
書き込み時の put:lock タグは全プロセスで排他的に実行され、読み込み時の get:lock は同じgetのみ並列に動作することを許容していることが図からわかります。ここから、MultiProcessFileCacheCacheは競合条件が起きていないかどうかを確認できます。
5. 動作検証
今回実装した内容を用いることで、機械学習におけるデータセットの読み込みのプロファイルができていることをMNISTとImageNetを用いて確認します。
5.1 MNIST
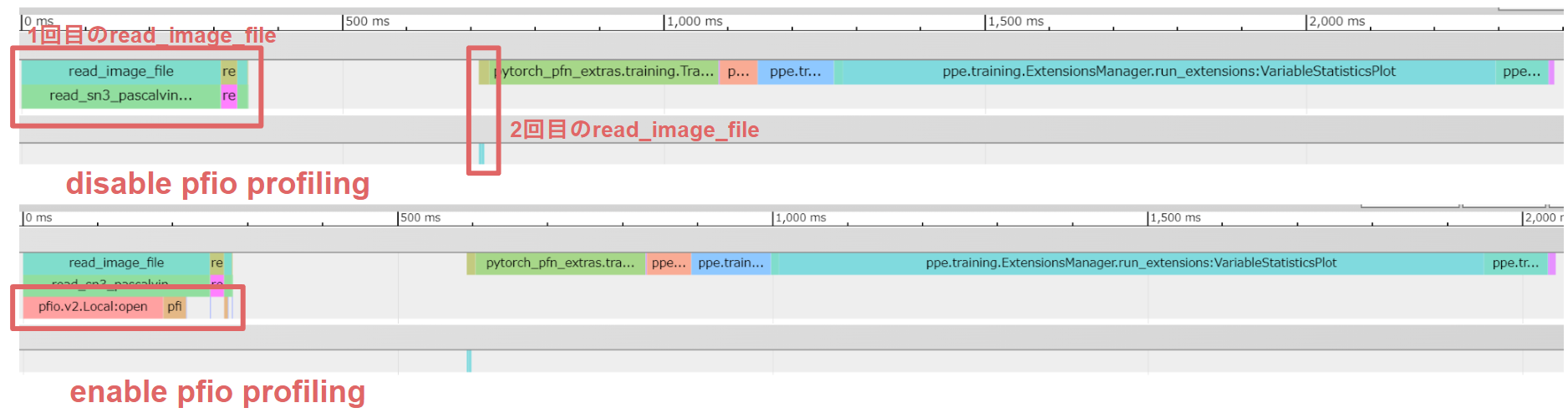
実際にPPEのMNISTサンプルコード [7] にPFIOを対応させて学習を行い、その様子をプロファイルしました。上図はPFIOのプロファイラを無効にした場合のTrace Event Profiling Toolの表示であり、下図はPFIOのプロファイラを有効にした場合の表示です。
PFIOのプロファイラが無効な場合、2箇所でデータセットが読み込まれていることを確認できます (下図のread_image_fileタグから推察)。ただし、PFIOプロファイラが有効な図を見てみると、実際にファイルから読み取っているのは前半部分のみで、後半部分はPFIOのタグがないことから、1度目の読み取りでメモリ上にデータを保存し、2度目以降はストレージではなくメモリ上からデータを取り出していることがわかります。
5.2 ImageNet – NFSストレージ上のZipファイルを用いる場合
軽量なMNISTではI/Oの負荷があまり見られないため、より大規模なデータセットであるImageNetを用いて実験を行いました。
社内にあるImageNetのサンプルコードはもともとPPEとPFIO 2.8.0を用いて実装されています。今回の実験にあたっては、from_urlでFSを作成している部分にtrace=Trueを加える一行の変更のみでプロファイルを有効にしました。キャッシュの動作も確認するためにMPIをつかって2プロセス並列でImageNetの学習を実行しています。
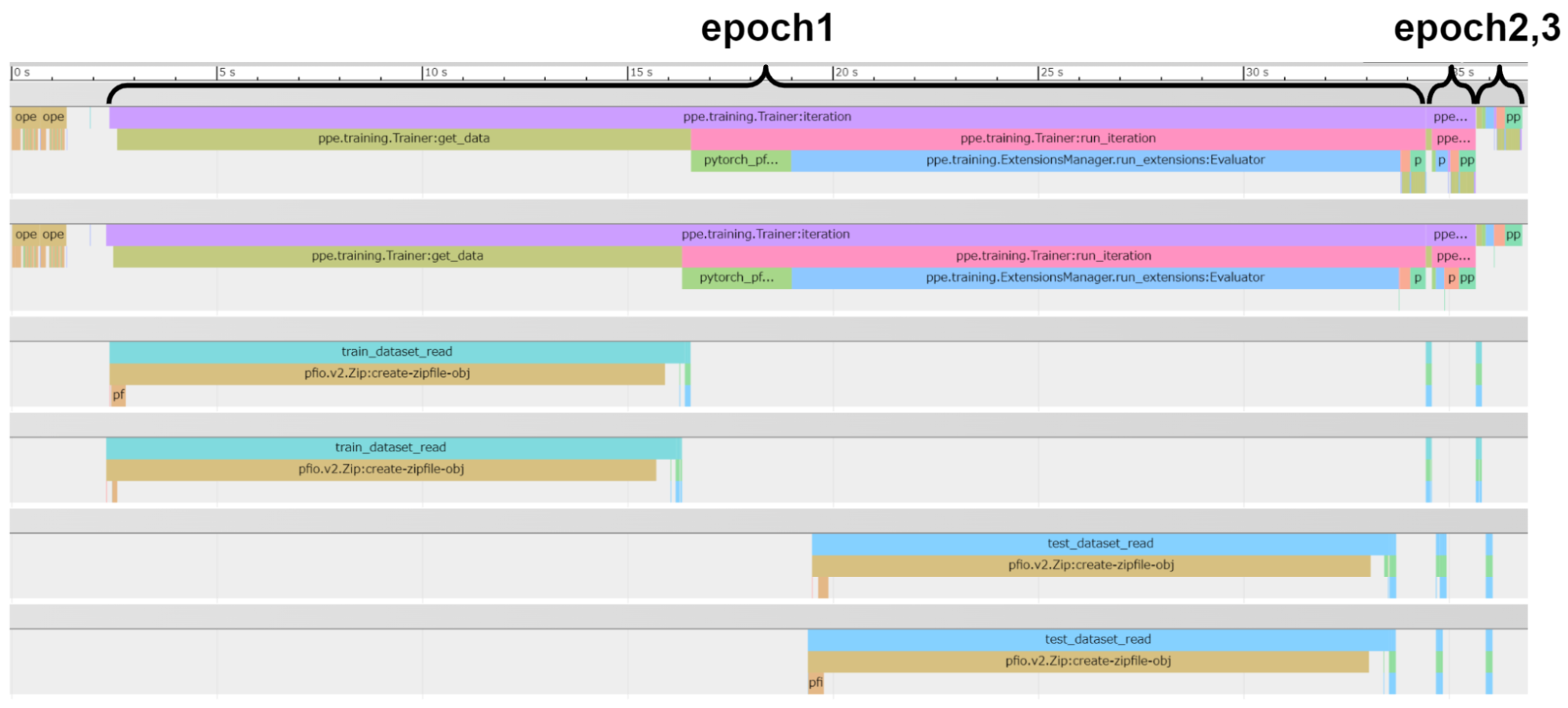
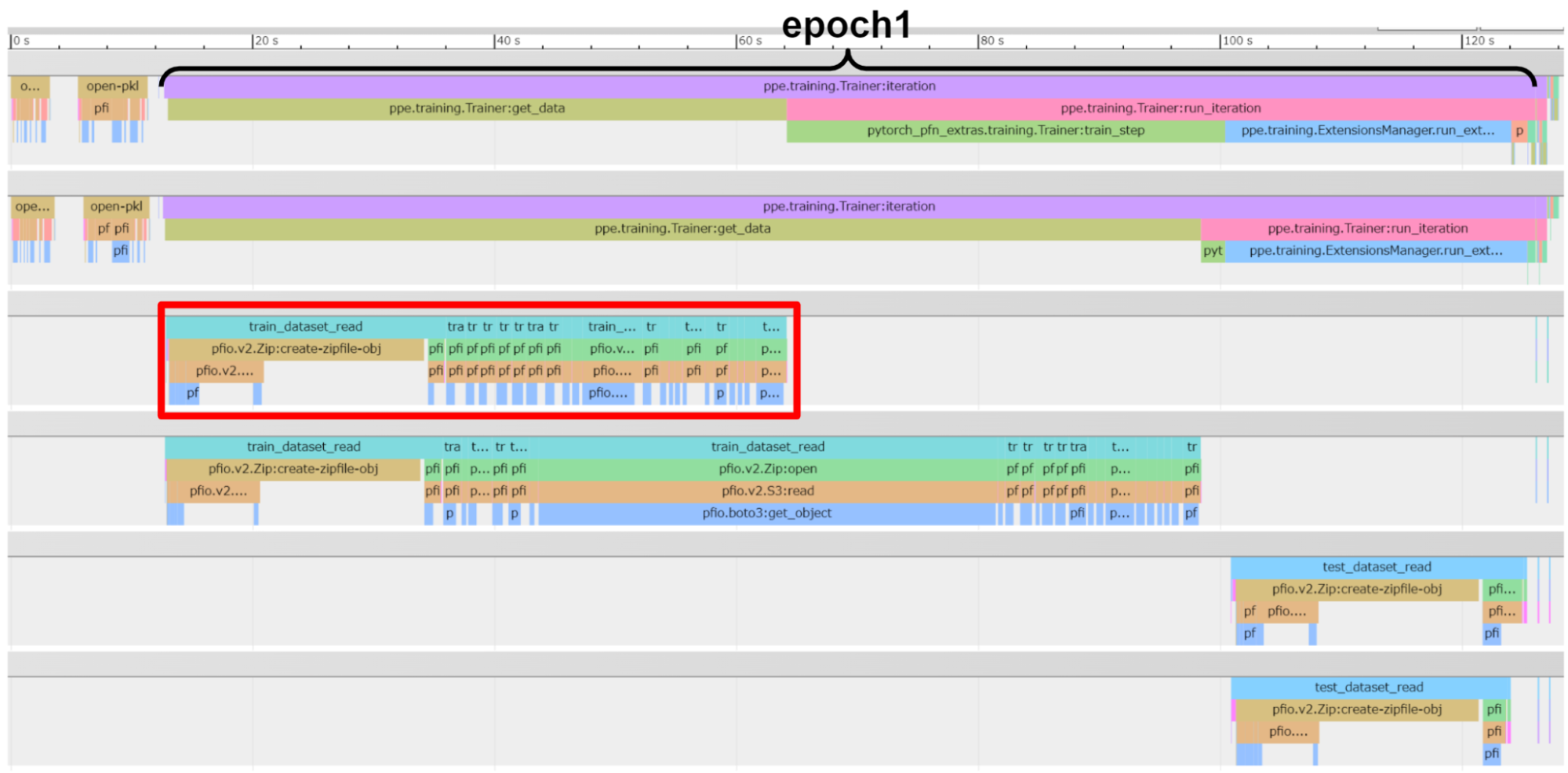
その結果、既存の学習プログラムのプロファイルと、PFIO部分のプロファイルを同じ画面に表示できています。1段目と2段目は学習処理のプロセス、3段目と4段目は学習データセットのDataLoader のプロセスのプロファイルです。そして、5段目と6段目はテストデータセットのDataLoader のプロセスのプロファイルです。
このサンプルコードの場合、最初のエポック (epoch1) のみ、データセットの読み込みに時間がかかることが確認されました。この時間の大半は、巨大なzipファイルをロードする処理に費やされていることが画像から読み取れます。
しかし、epoch2以降では、既にzipファイルの初期化が完了しているため、データ読み込みが格段に速くなります。これにより、初回のファイル読み込み以外のI/O負荷が大幅に軽減され、トレーニングの効率がとても高いことがわかります。
これらの情報を一つのプロファイルで一度に全部見れるため、学習が遅かったときに原因をすぐに推測できるようになりました。
5.3 ImageNet – NFSストレージ上のZipファイルを用い、MultiprocessFileCacheを有効にする場合
5.2節と同様の実験条件に加えてキャッシュを有効にした場合、特にepoch2以降でパフォーマンスの向上が顕著に見られます。キャッシュが効いてくるepoch2の様子を切り取った図 (下図) では、データの読み込みがキャッシュを有効にしていない場合と比べて訓練データの読み取り/テストデータの読み取り共に1.5〜2倍程度高速化しています。NFSストレージとFileCacheを使用した場合の速度差もこの範囲内に収まることが推察できます。

5.4 ImageNet – S3互換ストレージ上のZipファイルを用い、MultiprocessFileCacheを有効にする場合
NFSストレージの代わりにS3互換ストレージを使用してデータセットを取得する場合、NFSストレージと比較してZipファイルの初期化が占める時間の割合は相対的に小さくなっていることがわかります。これは、Zipファイルの初期化は、ストレージ間で大きな差が出る処理ではなく、その後のデータ読み込みに多くの時間がかかっているためです。S3互換ストレージからデータを取得する際は、boto3 API の呼び出しにかかる時間が非常に長いことが確認でき、これがS3のデータ転送時間の大きな要因となっています。
一方、キャッシュを使用することで、エポック2以降はローカルと同等の速度でデータを処理できるようになります。特にS3互換ストレージを使用する場合、FileCacheが効果的に機能し、データ読み込みのパフォーマンスを大幅に改善することが図より読み取れます。
6. まとめ
PFIOに既存のコードや機能に影響を与えない形でプロファイル機能を追加し、ストレージI/Oのパフォーマンスを容易に確認できるようにしました。
具体的なプロファイル内容は、S3互換ストレージのデータアクセス頻度やAWS API呼び出し時間の可視化、ローカルストレージにおけるファイル読み込み/書き込みのプロファイル化、Zipファイルの読み込み時間、キャッシュ利用時のロック取得時間などがあります。
これらの必要十分なプロファイル機能の追加により、ユーザがアプリケーションのボトルネックを迅速に特定し、最適化を進めるための具体的なデータを得ることが可能となりました。さらに、問題発生時の原因特定が効率化され、社内サポートの負担軽減にも繋がると考えられます。
7. 感想
今回のインターンシップでは、IO抽象化層にプロファイラを実装するという課題に取り組みました。
自社で複数のストレージを運営しているPFNならではの問題や課題に直面し、それらを解決する過程で多くの学びを得ることができました。
最後に、インターン期間中にサポートしていただいたメンターの杉原さんをはじめとするStorageチームの上西さん、水丸さん、そしてClusterチームの皆様には大変お世話になりました。
2週間という非常に短い期間でしたが、成長を実感できる貴重な時間でした。本当にありがとうございました!
参考文献
[1] PFIO, https://github.com/pfnet/pfio
[2] pytorch_pfn_extras, https://github.com/pfnet/pytorch-pfn-extras
[3] Trace Event Format, October 2016, https://docs.google.com/document/d/1CvAClvFfyA5R-PhYUmn5OOQtYMH4h6I0nSsKchNAySU/preview?tab=t.0
[4] The Trace Event Profiling Tool (about:tracing), The Chromium Projects, https://www.chromium.org/developers/how-tos/trace-event-profiling-tool/
[5] AWS SDK for Python (Boto3), https://aws.amazon.com/jp/sdk-for-python/
[6] Apache Ozoneをやっていた一年, PFN Tech Blog, https://tech.preferred.jp/ja/blog/apache-ozone-year/
[7] https://github.com/pfnet/pytorch-pfn-extras/blob/master/example/mnist_trainer.py
Area
Tag


