Blog
本記事は、2023年夏季インターンシッププログラムで勤務された開田亮佑さんによる寄稿です。
はじめに
2023年度夏季インターンの開田亮佑です。この度インターンプロジェクトとして、PFVM向けのONNXエクスポータの開発に取り組みました。特に、エクスポートにおける深層学習モデルの計算グラフの取得に要する時間を短縮することと、エクスポータの拡張やデバッグを容易にすることを目的に開発を行いました。その取り組みを紹介いたします。
背景
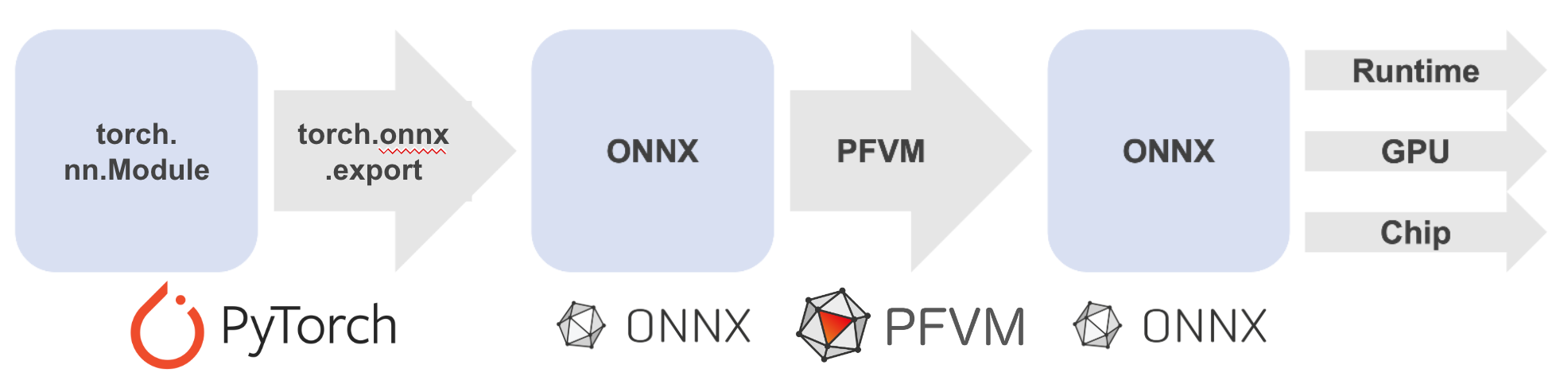
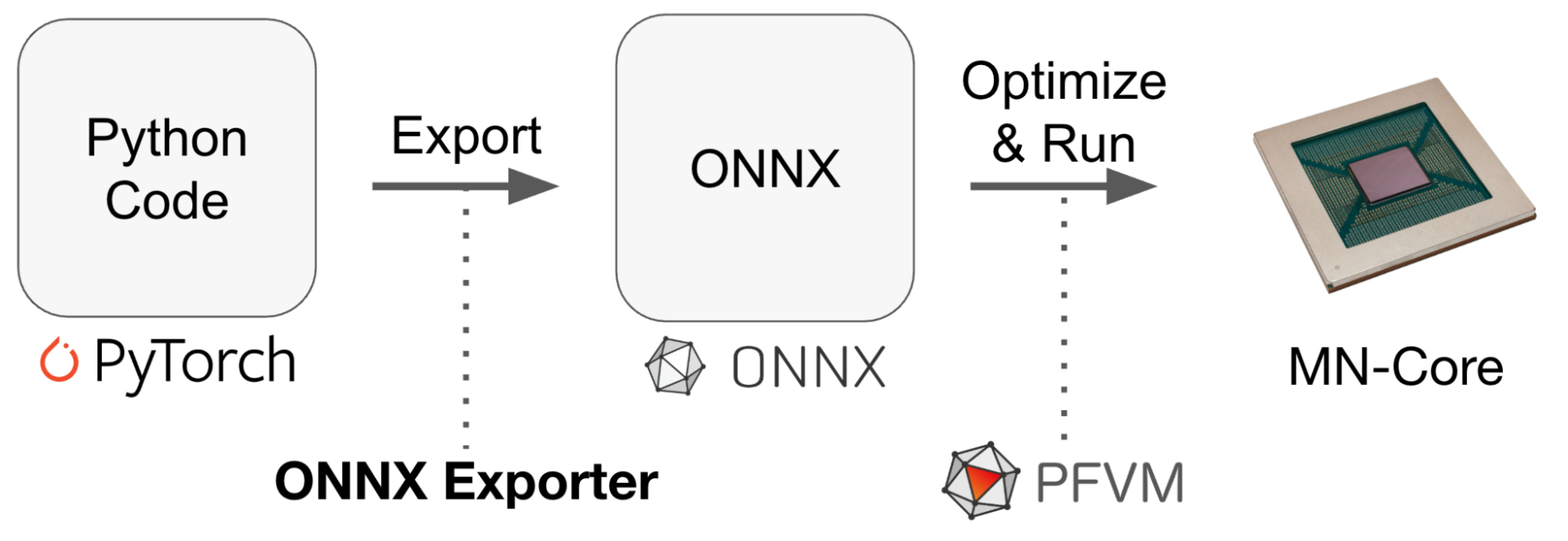
図1. 社内で典型的な深層学習の推論ワークロード
図1は、社内で典型的な深層学習の推論ワークロードの概要を模式的に表したものです。ワークロードでは、PyTorchなどのフレームワークで構築されたモデルをランタイムやチップ上で実行しますが、その前に、ONNXといった統一的なフォーマットに変換し、最適化する処理がよく行われます。
PFNではPFVMと呼ばれる深層学習の計算グラフ向けの最適化コンパイラ・ランタイムを内製しており、その入出力にはONNXと呼ばれるモデルフォーマットが用いられています。PFVMの詳細については、以下の記事も参考にしてください。
- PFVM – A Neural Network Compiler that uses ONNX as its intermediate representation (YouTube, スライドPDF)
- 複数のNNライブラリを活用したAndroidアプリ内での深層ポーズ推定モデルの実行
DL Ecosystemチームでは、こうした最適化フレームワークの開発と活用を手がけており、ONNXのエクスポートにかかるコストを削減するために、より柔軟なONNXのエクスポータが求められていました。
既存のエクスポータの問題点
既存のONNXエクスポータとして、PyTorchで開発されているtorch.onnx.exportが挙げられます。しかし、torch.onnx.exportには以下の問題点がありました。
- 深層学習モデルの計算グラフを取得するために、モデルを実際に実行する必要がある。多くの場合エクスポートはCPUで実行する必要があり、計算グラフの取得に時間がかかる
- エクスポータの開発にpybind11経由で使えるtorch.jitのC++ APIが多用されている。そのため、拡張やデバッグが容易ではない
これらの課題を解決するために、新しいエクスポータの開発では以下の工夫を行いました。
- PyTorchの新しいグラフ取得メソッド(torch.fx.symbolic_trace/torch.compile)を活用する
- Pythonで実装されたPyTorchやONNXのエコシステム(特にtorch.fx.GraphとONNX Script)を活用する
以下ではエクスポータの内部で行われる処理に沿って、これらの取り組みについて説明します。

図2. エクスポータの内部で行われる処理
図2は、エクスポータの内部で行われる処理を模式的に表したものです。PyTorchで構築したtorch.nn.Moduleから計算グラフをtorch.fx.Graphとして取得します。その後ATenの関数(後述)をONNXのオペレータに変換する処理を経て、ONNXのモデルが構築されます。構築されたONNXのモデルは、PFVMといったフレームワークで最適化されたのち、ランタイムまたは実機上で実行されます。この手順のうち、(1)から(4)の点について詳細を説明します。
(1) グラフ取得メソッド
既存のエクスポータであるtorch.onnx.exportでは、torch.jit.traceと呼ばれるメソッドを用いて計算グラフが取得されています。しかし、torch.jit.traceは以下のような問題点があります。
- 計算グラフの取得にモデルの実行を要するため、グラフ取得に時間がかかる
- メソッドも得られるグラフもC++で実装されているため、活用やデバッグが容易でない
そこで、新しいエクスポータの実装では、torch.fx.symbolic_traceおよびtorch.compileと呼ばれるメソッドを活用しました。これらのメソッドは、以下の特徴によってtorch.jit.traceの問題点を克服することができます。
- 計算グラフの取得にモデルの実行を要しないため、グラフ取得が高速である
- torch.fx.symbolic_trace: モデルを仮想的な値を用いて実行し、グラフを取得する。Python-likeなoperatorが得られる
- torch.compile: PEP 523で可能となったPythonのフレーム評価フックを利用して、Pythonバイトコードからグラフを取得する。具体的なATenの関数が得られる
- メソッドも取得できるグラフもpure-Pythonで実装されており、エクスポータの実装への活用やデバッグが容易である
(2) torch.fx.Graph

図3. PyTorchで実装されたMNISTのCNNモデル(左)と、このモデルをtorch.fx.symbolic_traceに渡した結果得られるtorch.fx.Graph(右)
torch.fx.symbolic_traceおよびtorch.compileを用いることで、計算グラフはtorch.fx.Graph形式で得られます。torch.fx.Graphは、Pythonで実装されたPyTorchの計算グラフであり、ノードとノードの接続関係によって構成されています。1つのノードには1つのoperationが含まれており、このoperationは高々6命令の非常にシンプルな中間表現で構成されています。
- placeholder: 関数の引数
- get_attr: モジュールからinstance variable(モデルのパラメータ)を取得する
- call_function: 関数呼び出し
- call_module: モジュールのforward()メソッドを呼び出す
- call_method: テンソルのinstance methodを呼び出す
- output: return文
torch.fxで導入された機能の詳細については、以下の論文も参考にしてください。
- J. K. Reed et al., Torch.fx: Practical Program Capture and Transformation for Deep Learning in Python, arXiv:2112.08429 (2021).
(3) ATenからONNXへの変換
ATen(エーテンと読む)とは、PyTorchの内部で使用されるテンソル操作ライブラリのことです。torch.fx.symbolic_trace/torch.compileで得られたtorch.fx.Graphには、ATenの関数が含まれています。計算グラフの取得に続くエクスポータの処理では、これらのATenの関数をONNXモデルを表すグラフに変換する処理が行われます。この処理を容易かつ拡張可能な形で実装するために、(1)ONNXのエコシステムを活用し可能な限りオープンな実装を利用することで、実装コストを削減すること、(2)ONNXのOpSetやFunction libraryを拡張できること、が求められていました。そこで、新しいエクスポータの実装では、ONNX Scriptと呼ばれるPythonパッケージを活用することにしました。
ONNX Scriptとは、PythonでONNXのモデルや関数(ModelProto/FunctionProto)を簡単に構築するためのパッケージです(ONNX Scriptの概要についてはMicrosoftのブログ記事も参考にしてください)。新しいエクスポータでは、ONNX Scriptの以下の特徴を活用した実装を心がけました。
- DSLを用いてONNXの関数を簡単に実装することができる。例えば、複雑なアクティベーションであるHardmax関数は、図4のように実装することができます。図4では、ai.onnxをドメインとする特定のバージョンのOpSetを`op`として導入し、op以下のオペレータを使用してonnx_hardmax関数を実装しています。実装された関数は`@script()`デコレータを付与することでコンパイルされます
from onnxscript import opset15 as op from onnxscript import script @script() def onnx_hardmax(X, axis: int): argmax = op.ArgMax(X, axis=axis, keepdims=False) xshape = op.Shape(X, start=axis) zero = op.Constant(value_ints=[0]) depth = op.GatherElements(xshape, zero) empty_shape = op.Constant(value_ints=[0]) depth = op.Reshape(depth, empty_shape) values = op.Constant(value_ints=[0, 1]) cast_values = op.CastLike(values, X) return op.OneHot(argmax, depth, cast_values, axis=axis)図4. Hardmax関数の実装例。ONNX Script Exampleより引用、一部改変
- ONNXの計算グラフを取得する方法として、(1)Python ASTを静的にコンパイルする方法、(2)Pythonコードを仮想的な値で実行する方法、の2種類を使用できる
- カスタムOpSetを定義できる
ONNX Scriptを用いてATenの関数を実装する具定例として、(1)aten::addの実装、(2)aten::getitemの実装を紹介します。
aten::addの実装
aten::addは、テンソルA, Bとスカラαに対し、A+αBを計算する関数です。aten::addは、ONNXの標準のオペレータを用いて、図5のように実装することができます。
@torch_op("aten::add")
def aten_add(A: TReal, B: TReal, alpha: float = 1.0) -> TReal:
alpha = op.CastLike(alpha, B)
B = op.Mul(alpha, B)
return op.Add(A, B)
図5. aten::addの実装
ここでは@script()の代わりにONNX Scriptのtorch_libで定義されている`@torch_op()`が使用されています。@torch_op()の内部では、@script()を用いて関数をコンパイルしたのち、ONNX Scriptのデフォルトレジストリに関数を登録する処理が行われています。
ONNXにおいて、モデルの実行時ではなくモデルの構築時に決定される値は属性(attribute)と呼ばれており、aten::addはalphaという属性を持ちます。図4のように、ONNX Scriptを用いることで属性をもつ関数を簡単に記述することができます。また、aten::addはConvやPadオペレータのような複雑なattribute処理を必要としないため、Python ASTを静的にコンパイルしてONNXの計算グラフを構築することができます。
このように、エクスポータの実装の大部分はONNXのオペレータを用いてATenの関数を実装する作業となりますが、ONNX Scriptのtorch_lib.opsで実装されている関数ライブラリを利用することで、実装コストを大幅に削減することができます。また、実装されていないATenの関数は、PyTorchのnative_functions.yamlに記載されているtype signature等を頼りに実装することになります。
aten::getitemの実装
aten::getitemは、PyTorchのテンソルであるtorch.Tensorに対する添字アクセスを表す関数です。torch.Tensorでは整数だけでなく、slice(0, n, 1)といったスライスや、Noneを添字として使用することができます。この添字アクセスの大まかな仕様は、Tensor Indexing APIにまとめられています。
ONNX Scriptでも、テンソルの添字アクセスはonnxscript.Tensorのメソッドとして実装されています。しかし、ONNXのUnsqueezeオペレータに相当するNone indexingが実装されていませんでした。そこで、ONNX Scriptを用いてPyTorchの添字アクセスを実装する必要がありました。
@torch_op("aten::getitem", trace_only=True)
def aten_getitem(self, index):
if isinstance(index, int):
return op.Slice(self, [index], [index+1], [0], [1])
elif isinstance(index, slice):
start = index.start if index.start else 0
end = index.stop # TODO: Support the case where index.stop is None
step = index.step if index.step else 1
return op.Slice(self, [start], [end], [0], [step])
elif isinstance(index, tuple) and None in index:
assert all(axis == slice(None) or axis is None for axis in index), "Not implemented"
index_to_unsqueeze = [i for i, axis in enumerate(index) if axis is None]
return op.Unsqueeze(self, index_to_unsqueeze)
else:
return self[index]
図6. aten::getitemの実装
aten::getitemの実装を図6に示します。この実装は、PyTorchの添字アクセスの仕様を完全に満たしたものではなく、現時点で必要となった部分のみ実装したものです。このように、必要な部分のみ実装し、その他の部分を既存の実装に委譲するといったことが、ONNX Scriptを用いて容易に実現することができます。
この実装では、@torch_op()のキーワード引数にtrace_only=Trueが指定されています。これは、Pythonコードを仮想的な値で実行(トレース)し、ONNXの計算グラフを取得することを指定する引数です。トレースはTorchScriptTracingEvaluatorを用いて実行され、その結果はTorchScriptGraphに追加されます。このように、trace_onlyモードを用いることで、モデルの構築時に決定可能な値に基づくPythonの制御文を記述できることも、ONNX Scriptを活用する利点の1つとなります。
Operationが2つ以上含まれるようなtorch.fx.Graphでは、ノードを順にたどり、各ノードをONNXのノードに変換する処理が行われます。このとき、torch.fx.Graphの命令は以下のようなONNXのノードに変換されます。
| torch.fx.Graphの命令 | ONNXのノード |
| placeholder | input |
| get_attr | initializer |
| call_function, call_method, call_module | NodeProto & FunctionProto |
| output | output |
表1. torch.fx.Graphの命令とONNXのノードとの対応関係
(4) PFVMコンパイラの修正
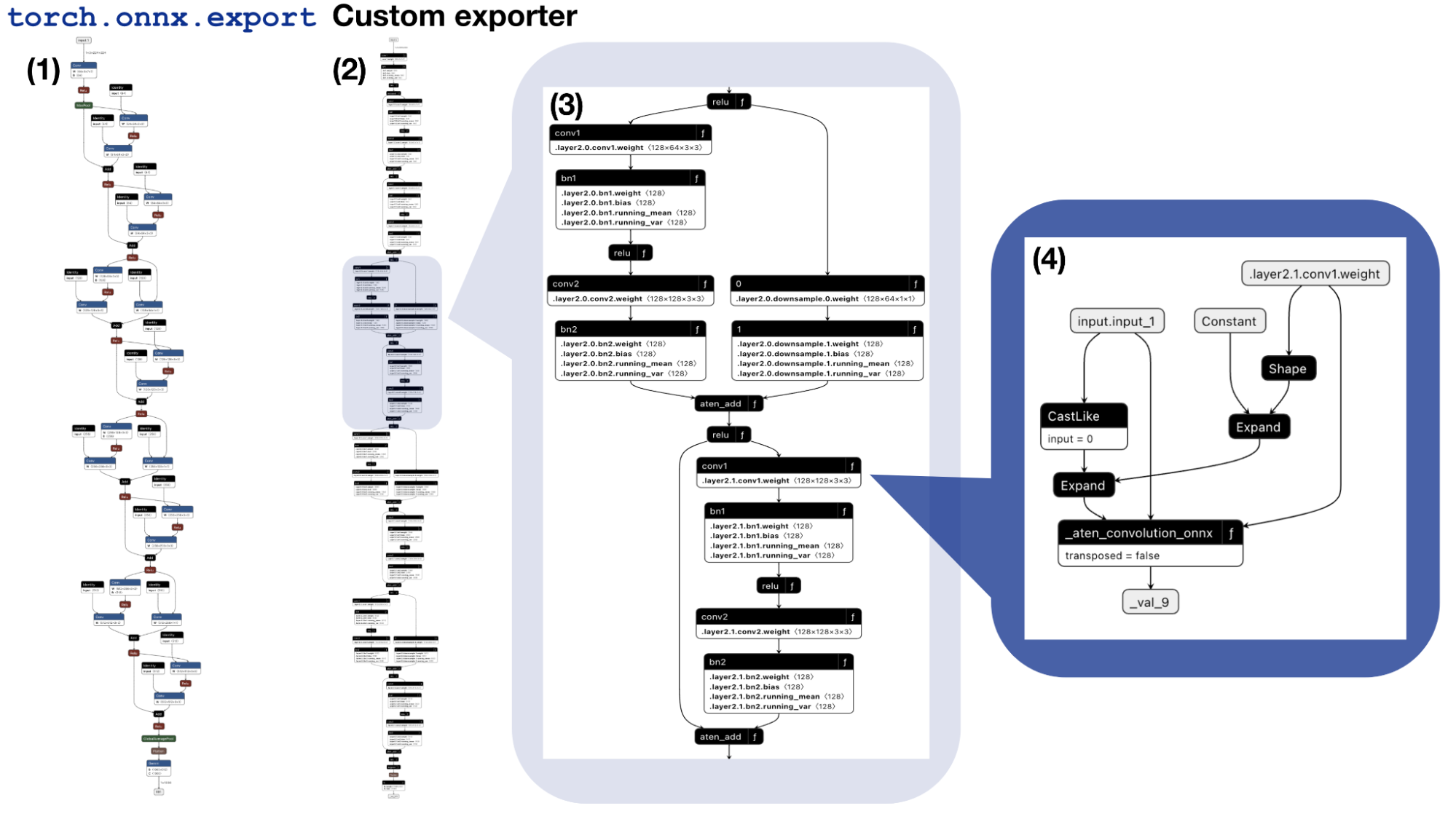
図7. エクスポータで出力されたONNXモデルを、Netronと呼ばれるビジュアライザで可視化した結果。(1)既存のエクスポータであるtorch.onnx.exportで出力した結果。(2)新たに開発したエクスポータで出力した結果。(3)(2)の出力結果の2層目を拡大した様子。「f」のマークを含むlocal functionを活用してモデルが出力されていることがわかる。(4)Convolutionを表すlocal functionに含まれるサブグラフ
図7は、以上の過程を経て出力されたONNXモデルをNetronで可視化したものです。新たに開発したエクスポータで出力したモデルは、既存のエクスポータで出力したモデルに比べて色彩に乏しく、代わりに、右上に「f」と書かれたノードが多く含まれています。これは、新たに開発したエクスポータでは、計算グラフのサブグラフ(ONNXではlocal funtionと呼ばれる)を大幅に活用して、モデルを出力していることに起因します。
Local functionとは、ONNXモデルに含まれているFunctionProtoの呼び出しを実行するノードです。FunctionProtoは子の計算グラフを保持しているため、local functionを用いることでネストした計算グラフを表現することができます。ONNX Scriptで実装された関数はすべてFunctionProtoに変換されるため、新たに開発したエクスポータで出力したモデルにはlocal functionが多数含まれることになります。Local functionを活用してモデルを出力する利点として、
- torch.fx.GraphのノードをONNX Scriptを用いたATenの関数の実装に割り当てることが容易となる
- ONNXのオペレータが関数の単位で保持されているため、特定の関数(Batch Normalization等)に起因する最適化を実行しやすい
といったことが挙げられます。
Local functionを活用したモデル出力を実現する一方、PFVMランタイムはlocal functionを含むONNXモデルを直接実行できず、PFVMコンパイラにおいてサブグラフをインライン展開したのち実行されます。しかし、PFVMコンパイラで実装されているインライン展開には、local functionの属性参照(図8に示す概念図のように、FunctionProtoに含まれるNodeProtoの属性が、呼び出し元の属性を参照する機能)を正しく解決できないという問題がありました。そこで、属性参照を正しく解決するパッチをPFVMに加えました。この他にも、インライン展開に起因する問題には、エクスポータを開発する過程で複数遭遇しましたが、チームの皆さまの素早い修正のおかげで、滞りなく開発を進めることができました。

図8. 属性参照の概念図
開発したエクスポータの評価
1. エクスポート可能なモデル
新たに開発したエクスポータを用いることで、MNISTやtorchvisionのResNetの推論用および学習用のONNXモデルを出力することができました。また、比較的実践的なモデルとして、Googleが開発した言語モデルであるT5の出力(推論のみ)も行うことができました。ただし、T5の出力はHugging Faceがサポートするカスタムfx.Tracerを用いて初めて達成することができました。symbolic_traceを用いてより広範囲のモデルを出力可能とするには、ONNXのエクスポータだけではなく、計算グラフの取得にも修正を加える必要があると考えられます。
2. エクスポートに要する時間
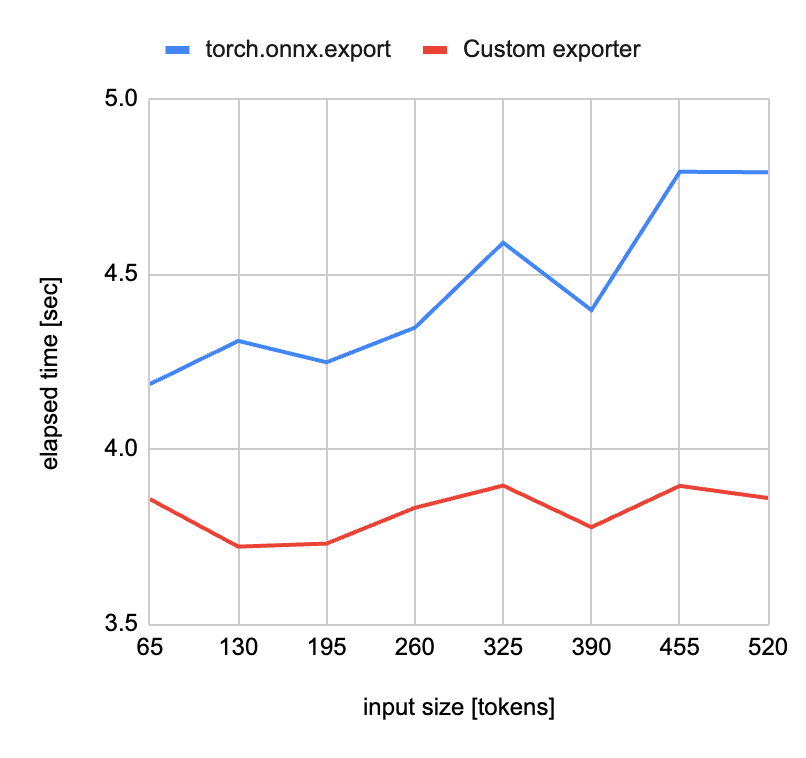
図9. モデルの出力にかかる時間のサンプル入力サイズ依存性。(青色)既存のONNXエクスポータであるtorch.onnx.exportの場合。(赤色)新たに開発したエクスポータの場合。このプロファイルはGoogleが開発した言語モデルであるT5のHugging faceのtransformers実装を対象に取得されたものである。サンプル入力はエクスポータに渡す入力例を表し、入力サイズはトークナイズされたテキストのトークン数を表す
図9は、言語モデルT5を用いて、サンプル入力サイズに対しモデルの出力にかかる時間をプロットしたグラフです。既存のONNXエクスポータであるtorch.onnx.exportでは、計算グラフの取得にモデルの実行を要するため、エクスポートにかかる時間が入力サイズに応じて増大しています。一方、新たに開発したエクスポータでは、モデルを直接実行しないため、入力サイズに依存しない時間でモデルを出力でき、エクスポートにかかる時間も、既存の実装に比べ1割強程度短縮されていることがわかります。
3. エクスポートに要する時間における、各メソッドが占める割合
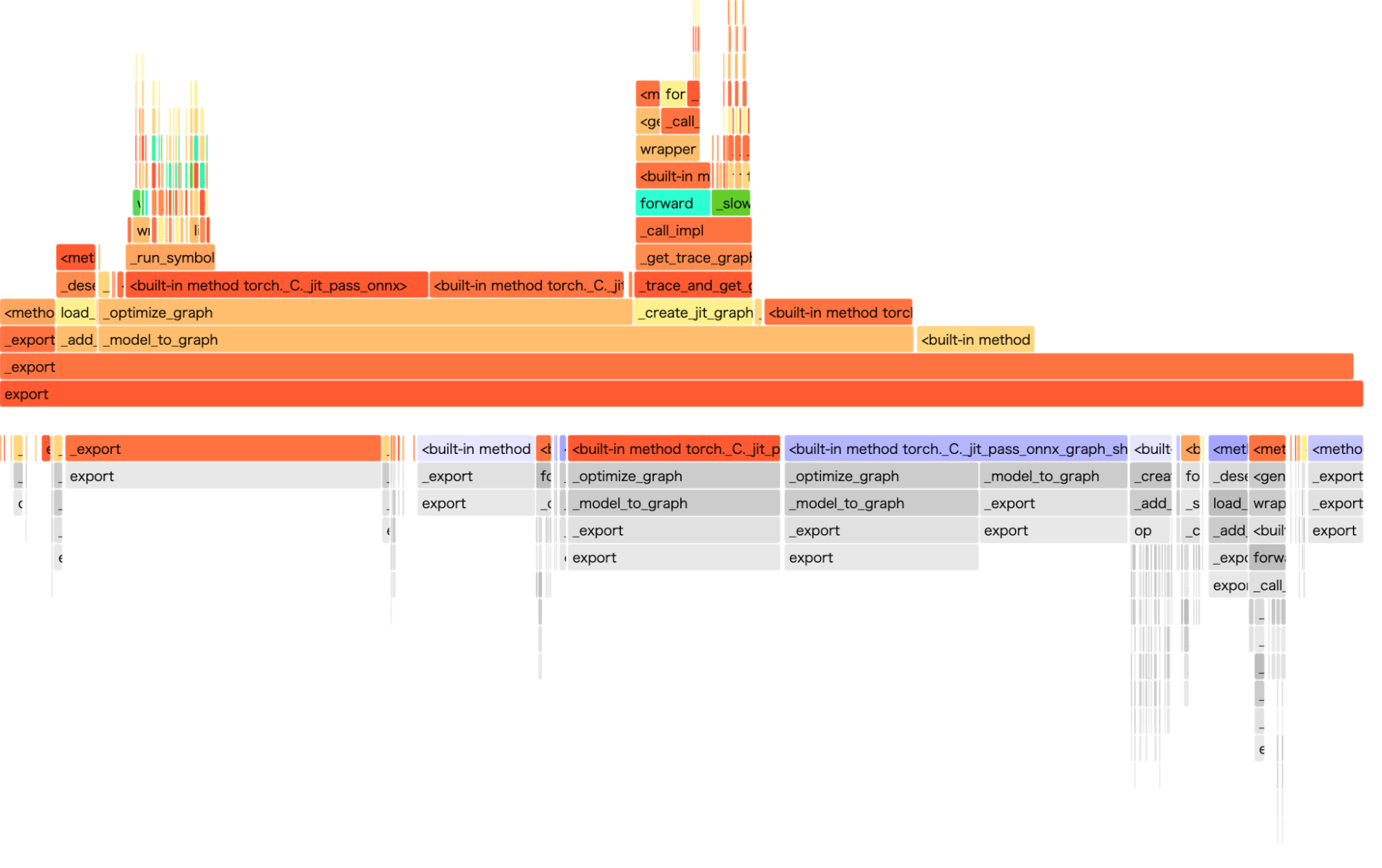
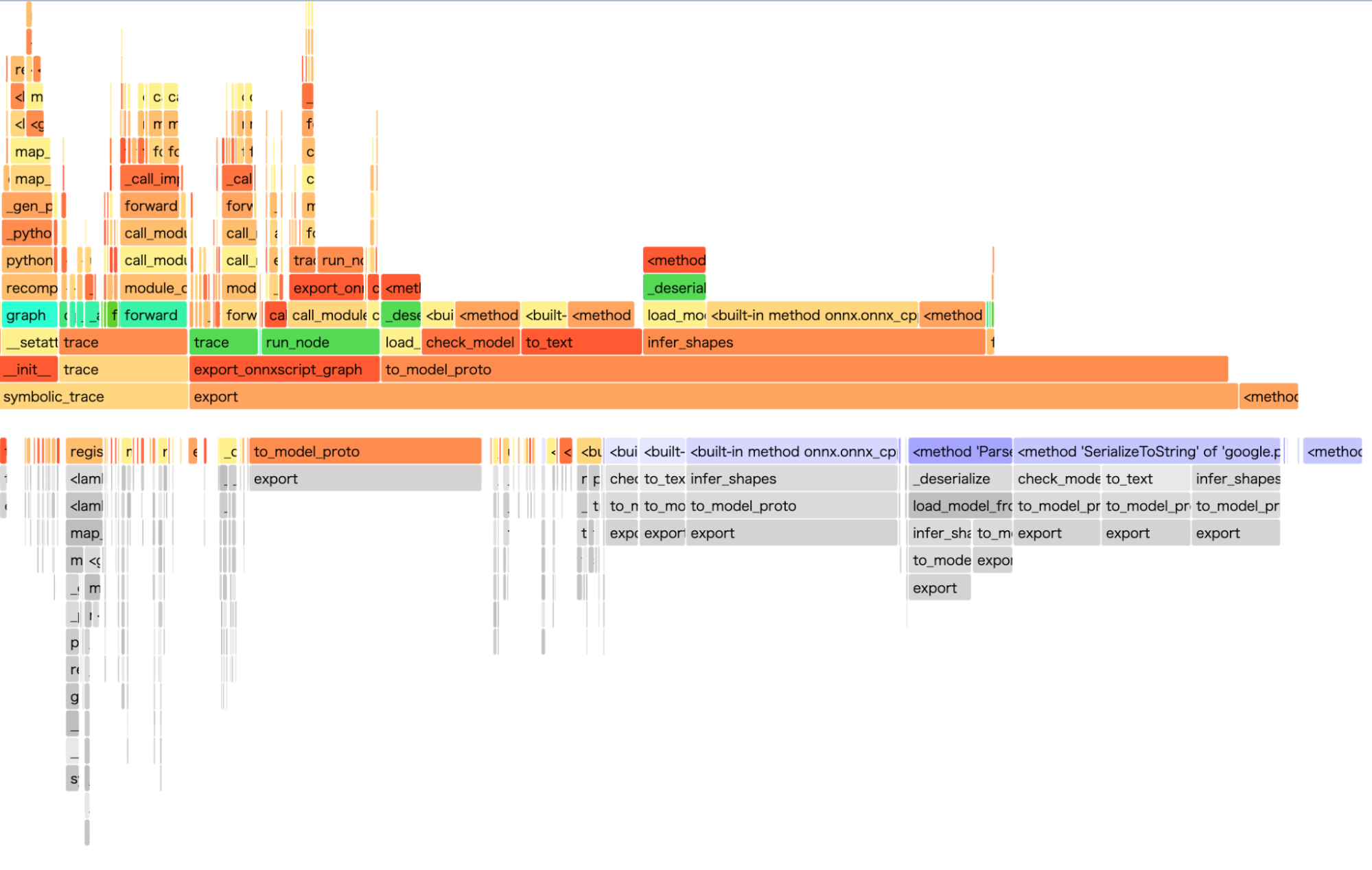
図10. エクスポートに要する時間における、各メソッドが占める割合。(上)既存のONNXエクスポータであるtorch.onnx.exportの場合。(下)新たに開発したエクスポータの場合。
図10は、再びT5を用いて、ONNXのエクスポートにおけるフレームグラフを取得したものです。既存のエクスポータであるtorch.onnx.export、および新たに開発したエクスポータの両方で、計算グラフの取得に要する時間は全体の時間の2割程度に留まっています。これは、計算グラフの取得だけでなく、テンソルの形状推論といった、モデルのノード数に比例する処理も律速するためだと考えられます(ただし、より大きなモデルでは事情は変わるかもしれません)。したがって、エクスポート全体を高速化するには、計算グラフの取得だけでなく、これらの処理も高速化する必要があると結論できます。
Future Work
計算グラフ取得以外のメソッドの高速化
今回は、モデル実行を要する計算グラフの取得方法が原因で、エクスポートが低速であることに着目し、計算グラフの取得方法を変更することで、エクスポートの高速化を目指しました。しかし、期待したほどのエクスポートの高速化は成し遂げられませんでした。これは、図11に示したエクスポートのフレームグラフからわかるように、エクスポートにおいて律速するメソッドが、計算グラフの取得以外にも存在するためです。特に、ONNX ScriptからModelProtoへの変換(to_model_proto)に時間を要していることがわかります。
ONNX Scriptのto_model_protoはtorch.jitのC++ APIに依存しているため、今後の取り組みとして、この依存性を取り除くために、ModelProtoへの変換を内製することが考えられます。ただし、ONNXパッケージにおいて提供されているonnx.helper.make_nodeといったメソッドは、メモリのコピーを要するため、高速な実装が困難です。そこで、メモリ効率性を意識したto_model_protoの実装を工夫する必要があります。また、ONNXにおけるテンソルの次元の保持は、Array of Structsで実現されており、非効率な方法となっています。そこでONNXのメッセージ構造にも工夫が必要であると考えられます。
謝辞
この度は、6週間にわたりプロジェクトに携わせていただき、ありがとうございました。インターンシップ期間中にお世話になりましたDL Ecosystemチームの皆さまをはじめ、お力添えいただいたすべての皆さまに、心より感謝申し上げます。
メンターからのコメント
今回のタスクはPyTorch 2.0以降ゆるやかに廃止されていくであろうtorch.jitを移行していくにあたって社内でONNXをtorchからエクスポートしているプロジェクトの技術移行の検討タスクとして設定させてもらいました。
限られた時間の中で現状満足にドキュメントや知見のなかったtorch.fx関係とONNX Script関係の2つについて同時に調査や実験をしてくださりとても助かりました。今後、それらの知見や実装はpytorch-pfn-extrasやONNX ScriptへフィードバックしていくことでONNXのエコシステムにもフィードバックさせてもらいます。
PFNでは今後もPyTorchやONNXエコシステムを活用しながらDLモデルのデプロイや学習を効率化していきます。