Blog
本記事は、2024年夏季インターンシッププログラムに参加された九門涼真さんによる寄稿です。今回はPLaMoをベースにしたテキスト埋め込みモデルの開発に取り組んでいただきました。PFN/PFEではこのようなLLM性能改善のための研究開発を進めています。本取り組みで得られた知見・成果は今後PLaMoに取り入れていく予定です。
2024年度夏季インターンシップに参加した、東京大学大学院情報理工学系研究科修士一年の九門涼真と申します。現在は谷中研究室で自然言語処理に関する研究をしています。
今回のインターンでは、大規模言語モデル (LLM) を用いたテキスト埋め込みモデルについて研究と開発を行いました。LLMの持つ特徴を生かし、質の高いテキスト埋め込みを生成することを目指しました。
背景
テキスト埋め込みは、テキスト分類、文書検索など自然言語に関わる様々なタスクで用いられており、必要不可欠なものとなっています。特に近年ではLLMの登場により、検索拡張生成 (RAG) のような、テキスト埋め込みを活用する技術に注目が集まっています。そのため、汎用的で質の高いテキスト埋め込みモデルの開発が活発となっています。
テキスト埋め込みモデルには、主に双方向言語モデルが用いられてきました。特にBERT [1] やT5 [2] といった encoder / encoder-decoder の双方向の埋め込みを持つ事前学習済みモデルに様々なタスクのデータで教師あり対照学習を行うことで、テキスト埋め込みモデルの学習が行われています [3, 4]。
一方で、decoder-onlyのLLMをテキスト埋め込みモデルに用いる取り組みも複数存在します [5, 6, 7, 8]。decoder-onlyのLLMはcausal注意機構を持つため、素朴にはトークンiの埋め込みにはトークン0からトークンi-1までの情報のみが用いられます (図1)。
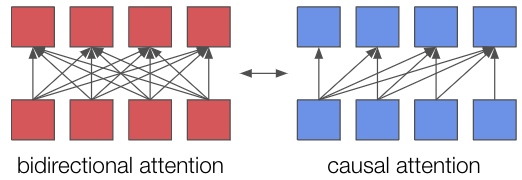
図1:双方向注意機構とcausal注意機構
すなわち、後に登場したトークン列はそれ以前のトークン列の埋め込みには影響しません。そのため、双方向注意機構と比較すると、causal注意機構を用いて生成された埋め込みは、文脈を反映する能力に制限がある可能性があります。既存の取り組みは、このようなdecoder-onlyのLLMの欠点を補い、LLMの強みである様々なタスクにおける汎用性を活用することを目指しています。実際、英語のテキスト埋め込みベンチマークである、MTEB [9] のリーダーボードの上位はdecoder-only LLMベースのモデルによりほとんど独占されています (図2)。
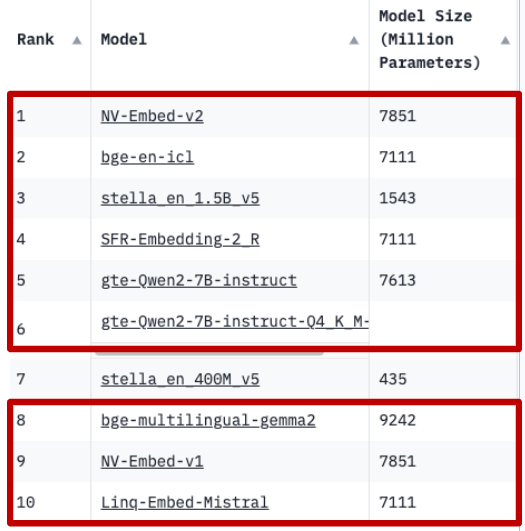
図2 MTEBリーダーボード (2024年9月25日時点)。赤枠で囲まれたモデルはdecoder-only LLMをベースとしたもの。
Decoder-only LLMベースのモデルの方が性能が高いことが示唆されているものの、このようなテキスト埋め込みモデルの開発やdecoder-onlyのLLMを活用する研究は主に英語で行われており、日本語における知見は十分に集まっていません。そこで、今回はPLaMoを用いた高性能な日本語テキスト埋め込みモデルの開発を行いました。
既存研究
Decoder-onlyのLLMをテキスト埋め込みモデルへと変換する代表的な手法として、LLM2Vec [5]とNV-Embed [6]があります。LLM2Vecは、三段階のステップから構成されています (図3)。
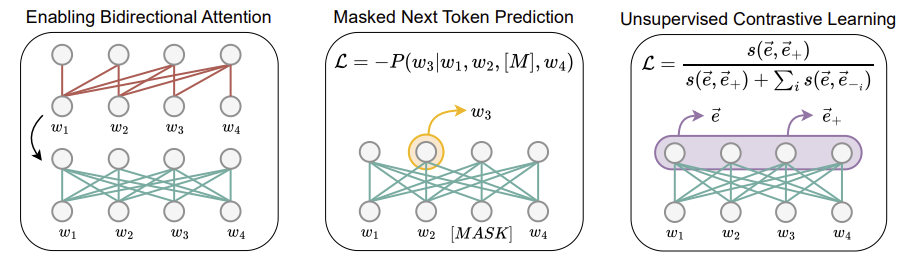
図3 LLM2Vecの学習フロー (BehnamGhader et.al., 2024 [5]より引用)
まずcausal注意機構のマスクを取り外し、双方向の注意機構に変換し、全てのトークンに注意が向くようにします。次に、decoder-onlyのモデルが新たに導入された双方向の注意機構を活用するように学習を行います。学習には、masked next token prediction (MNTP)という、next token predictionとmasked language modelingを組み合わせたタスクを用います。すなわち、前後のコンテキストをもとに得られたトークンi-1の埋め込みをもとにマスクされたトークンiを予測します。MNTPにより、モデルから双方向の注意機構を用いたワードレベルの表現が得られるようになります。最後に、SimCSE [10]による教師なし対照学習を行い、ワードレベルだけでなく、トークン列全体の文脈を反映した表現が得られるようにします。また、MNTPとSimCSEのいずれもLoRA [11]を用いて学習を行うため、計算コストを少なく抑えることができます。
NV-Embedは、LLM2Vecと同様に双方向の注意機構への変換をした後に、MNTPのような双方向の注意機構に関する追加学習をせずに、二段階の教師あり対照学習を行います。一段階目は検索タスクのデータで、二段階目は検索タスクを含む様々なタスクのデータで対照学習を行います。学習の際には、LLM2Vecと同様にLoRAを用います。また、モデルの最終隠れ層から埋め込みを取得する際のpooling手法として、mean poolingや<EOS>トークンの埋め込みを用いる手法が一般的に用いられますが、NV-Embedはlatent注意層を導入し、既存の手法の弱点である重要なフレーズの情報の損失や最終トークンに近い埋め込みへの依存を改善することを目指しています。
手法
今回は、LLM2VecとNV-Embedおよび、既存の高精度なテキスト埋め込みモデルであるGTE [3], Ruri [4]の学習手法に基づき手法を検討しました。
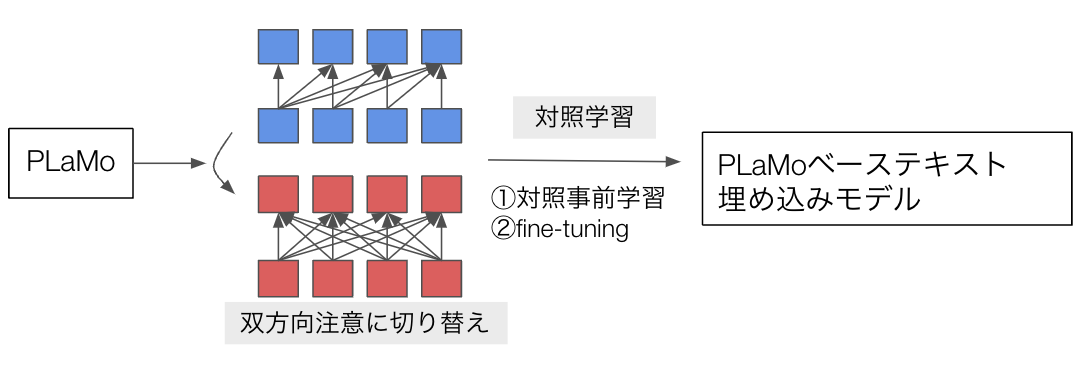
図4 今回のテキスト埋め込みの学習手法の流れ
学習手法の一連の流れは図4の通りです。まず、モデルのcausal注意機構のマスクを取り外し、双方向注意機構とします。次に、対照事前学習とfine-tuningの二段階の教師あり対照学習をLoRAを用いて行います。二段階の教師あり対照学習は、NV-Embedで用いられているだけでなく、近年高精度なテキスト埋め込みモデルの学習に一般的に用いられる手法である [3, 4] ため、今回は本手法を採用しました。
まず、対照事前学習では、弱教師付きの大規模データを用い、大規模に対照学習を行います。今回用いる大規模データは、日本語のテキスト埋め込みモデルであるRuriにおいて対照事前学習で用いられていた日本語データから一部のデータセット* を除き、サンプル数を削減したものです。今回はモデルサイズも大きいため、計算時間の都合上、こういったデータセットの削減が必要でした。削減をする際には、Ruriで用いられたデータセットの多様性を保ちつつ、NV-Embedの学習に用いられたデータセットに近い量まで減らしました。
また、NV-EmbedではLLMによる合成データは学習に用いられていませんでしたが、対照事前学習における合成データの効果が [4] により示されたため、今回は合成データも用いることにしました。実際に実験に用いたサンプル数はAppendixの表7の通りです。ここで用いるデータは必ずしもノイズのない整ったデータというわけではありませんが、双方向言語モデルに関しては、バッチサイズの値を大きく設定し、大規模な対照学習を行うことで埋め込みの精度が向上することが確認されています [3]。
対照学習に用いるhard negativeは、[4] で用いられているhttps://huggingface.co/datasets/hpprc/emb に用意されているBM25の類似度を元に抽出しました。表7のデータセットのうち、BM25の類似度が用意されていないものに関しては、ランダムなサンプルをhard negativeとしました。
次に、高品質で小規模なデータセットを用いたfine-tuningを行い、モデルの精度をさらに向上させます。fine-tuningに用いるデータに関しても、対照事前学習と同様にRuriで用いられたデータセットを使用しました。サンプル数に関してはdata augmentationは行なわなかったため、Ruriよりも少なくなっています。実験に用いたサンプル数はAppendixの表8の通りです。また、Ruriではretrievalの性能を上げるためにリランカーからの蒸留が組み込まれていましたが、今回は含めませんでした。
対照学習の損失関数は、[3, 4] で使われていた損失関数を選び、クエリとドキュメントの間だけではなく、クエリ同士やドキュメント同士の類似度も考慮に入れた対照学習を行いました。各バッチは同一のデータセットのサンプルのみから構成されます。学習設定の詳細はAppendixの表9に記載しました。
また、比較実験のために、LLM2Vecで用いられたMNTPやSimCSEも実装しました。MNTPの学習には、日本語のwikipedia dumpを、SimCSEの学習にはwiki40b-ja を用いました。LLM2Vecで用いられていたデータが英語のWikipediaベースのデータであったため、今回はいずれもWikipediaベースの日本語のデータを用いました。
* Wiki Atomic Edits, CC News (short)を除きました。Wiki Atomic EditsはHuggingfaceにデータが整備されていなかったため、CC News (short)は今回は不要と判断したためです。
実験と結果
以上に述べた手法を用い、PLaMoをテキスト埋め込みモデルへと変換するための学習を行い、評価を行いました。学習したモデルの評価には、日本語テキスト埋め込みベンチマークであるJMTEB [12] を用いました。JMTEBは6カテゴリ16タスクからなるベンチマークで、テキスト埋め込みモデルの包括的な評価を行います。評価結果の表には、比較対象のモデルとして、公開されているモデルの中でJMTEBでのスコアが最も高い3つのモデルを載せています。ただし、Mr.TyDiは評価に非常に時間がかかるため、インターン期間中に評価が間に合わず、今回の評価からは除きました。
まず、追加学習を全く行わずに、causalマスクを取り除き、双方向注意に切り替えたのみのモデルの評価結果を以下の表1に示します。評価を行ったモデルはPLaMo-1B-pretrain、PLaMo-1B-sft、PLaMo-1B-dpoの三種類です*。PLaMo-1B-pretrainは事前学習のみを行ったモデル、PLaMo-1B-sftは指示学習を行ったモデル、PLaMo-1B-dpoは指示学習に加えDPOを行ったモデルです。また、モデルサイズはいずれのモデルも約1Bです。なお、以降PLaMo-1Bと表記するものは表6を除きすべて、causalマスクを取り除き双方向注意に切り替えたモデルを指します。
| モデル | Overall* | Retrieval* | STS | Classification | Reranking | Clustering | PairClassification |
| OpenAI/text-embedding-3-large | 76.66 | 82.39 | 82.52 | 77.58 | 93.58 | 53.32 | 62.35 |
| intfloat/multilingual-e5-large | 71.71 | 73.42 | 79.70 | 72.89 | 92.96 | 51.24 | 62.15 |
| Ruri_large | 75.35 | 80.02 | 83.13 | 77.43 | 92.99 | 51.82 | 62.29 |
| PLaMo-1B-pretrain | 48.32 | 14.93 | 72.75 | 62.77 | 87.68 | 51.78 | 62.38 |
| PLaMo-1B-sft | 50.54 | 16.13 | 74.73 | 68.73 | 89.67 | 50.53 | 62.38 |
| PLaMo-1B-dpo | 51.35 | 24.18 | 72.16 | 63.86 | 87.48 | 50.31 | 61.54 |
表1 追加学習なしの評価結果
(Overall*、Retrieval*はMr.Tydiを除いたスコアの平均)
JMTEB全体での精度としては、PLaMoシリーズのモデルの中では、PLaMo-1B-dpoが最も優れた結果となりました。カテゴリ別に見ると、retrievalにおいてPLaMo-1B-dpoは他のPLaMoのモデルよりも高い精度を出していることがわかります。一方で、既存の埋め込みモデルと比較すると、PLaMoシリーズのモデルのretrievalの精度は非常に低いです。retrieval以外のタスクに関しては、既存の埋め込みモデルに劣りはするものの、その差は比較的小さいです。そのため、追加学習では特にretrievalの精度を向上することを目標としました。
以上の結果を踏まえ、ベースモデルはPLaMo-1B-dpoとして、様々な実験を行いました。PLaMo-1B-dpoはLLMとしては比較的小規模なモデルで、より大きなサイズのモデルを用いることで更なる高性能が期待できますが、推論速度や計算リソースに負担がかかるため、今回はPLaMo-1B-dpoを選択しました。PLaMo-1B-dpoに追加学習を行ったモデルの結果を以下に示します。表2にJMTEBの全カテゴリでの評価結果を、表3にretrievalでの評価結果を載せています。
| モデル | Overall* | Retrieval* | STS | Classification | Reranking | Clustering | PairClassification |
| OpenAI/text-embedding-3-large | 76.66 | 82.39 | 82.52 | 77.58 | 93.58 | 53.32 | 62.35 |
| intfloat/multilingual-e5-large | 71.71 | 73.42 | 79.70 | 72.89 | 92.96 | 51.24 | 62.15 |
| Ruri_large | 75.35 | 80.02 | 83.13 | 77.43 | 92.99 | 51.82 | 62.29 |
| PLaMo-1B-dpo (追加学習なし) | 51.35 | 24.18 | 72.16 | 63.86 | 87.48 | 50.31 | 61.54 |
| PLaMo-1B-dpo + 対照事前学習 | 75.10 | 78.40 | 82.12 | 76.73 | 93.37 | 53.80 | 62.46 |
| PLaMo-1B-dpo + 対照事前学習 + fine-tuning | 76.45 | 81.49 | 83.24 | 76.83 | 93.25 | 54.89 | 62.46 |
表2 JMTEBでの全カテゴリの評価結果
| モデル | Retrieval Avg* | JaGovFAQs | JAQKET | nlp_journal_abs_intro | nlp_journal_title_abs | nlp_journal_title_intro |
| OpenAI/text-embedding-3-large | 82.39 | 72.41 | 48.21 | 99.33 | 96.55 | 95.47 |
| intfloat/multilingual-e5-large | 73.42 | 70.3 | 43.63 | 86.00 | 94.70 | 72.48 |
| Ruri_large | 80.02 | 76.68 | 61.74 | 87.12 | 96.58 | 77.97 |
| PLaMo-1B-dpo(追加学習なし) | 24.18 | 29.13 | 11.86 | 41.23 | 25.86 | 12.81 |
| PLaMo-1B-dpo + 対照事前学習 | 78.40 | 71.73 | 58.89 | 88.03 | 96.28 | 77.05 |
| PLaMo-1B-dpo + 対照事前学習 + fine-tuning | 81.49 | 73.28 | 70.05 | 89.72 | 96.65 | 77.74 |
表3 JMTEBでのRetrievalの評価結果(Retrieval Avg*はMr.Tydiを除いたスコアの平均)
PLaMo-1B-dpoに追加学習を行ったモデルはretrieval以外のカテゴリの精度が向上しただけでなく、retrievalの精度が大幅に改善し、公開されている日本語テキスト埋め込みモデルの中で最もretrievalのスコアが高いRuri_largeを上回る精度となっています。JMTEBの全タスクの平均では、Ruri_largeやintfloat/multilingual-e5-largeを上回り、OpenAI/text-embedding-3-largeをわずかに下回る精度となりました。この結果から、decoder-onlyのLLMを追加学習することにより、非常に優れたテキスト埋め込みモデルを作ることができることがわかりました。
また、今回の追加学習はGTEやRuriと比較すると、30分の1程度のデータ量で対照事前学習を行ったにも関わらず、最終的な精度は非常に優れた結果となり、テキスト埋め込みのためのLLMの追加学習には大量のデータを必要としない可能性が示唆されました。日本語のテキスト埋め込みを学習するためのデータが不足している現状を考慮すると、興味深い結果と言えます。
* 今回の実験で使用したPLaMo-1Bは、PLaMo Liteとは異なる社内開発用のモデルです。
比較実験と考察
以下ではテキスト埋め込みの学習手法の様々な要素がモデルの精度にどのような影響を与えているかを、比較実験を通して分析します。なお、比較実験はいずれも予備実験として実施したため、本実験よりも小規模に行い、学習に用いたデータセットや学習ステップ数などが本実験とは異なっています。
MNTPの有無
次に、LLM2Vecで用いられたMNTPを用いて追加学習を行ったモデルとの比較を行います。MNTPはcausalマスクを取り除き、双方向注意に切り替えた直後に行い、MNTPの学習をしたモデルに対照学習を行います。理論上は、MNTPにより双方向注意機構をより効果的に使えるようになることが期待されます。そこで、この比較実験を通してMNTPがテキスト埋め込みの精度向上にどの程度寄与しているかを調べます。
なお、以下の比較実験で事前対照学習に用いたデータは、Appendixの表7に示したデータセットの一部です。また、ベースのモデルはPLaMo-1B-sftです。
比較実験の結果は表4の通りです。
| モデル | Overall* | Retrieval* | STS | Classification | Reranking | Clustering | PairClassification |
| PLaMo-1B-sft + MNTP + 対照学習 | 71.68 | 67.90 | 83.25 | 77.08 | 91.84 | 53.32 | 62.44 |
| PLaMo-1B-sft + 対照学習 | 72.41 | 70.69 | 83.37 | 76.35 | 92.04 | 53.04 | 62.43 |
表4 MNTPの有無での比較実験結果
表4から、MNTPを経て対照学習をしたモデルは、MNTPを行わずに対照学習をしたモデルを精度で上回らないことがわかります。全カテゴリの平均やretrievalではMNTPなしのモデルの方が良いパフォーマンスで、他のカテゴリではほぼ同等の結果となっています。この結果から、教師ありの対照学習を後に行う場合には、MNTPはテキスト埋め込みの精度の向上には寄与しないことが示唆されます。考えられる理由としては、対照学習の段階で双方向注意機構を適切に扱えるように学習されるため、MNTPのような双方向注意機構を学習するためにのみ用意されたタスクは不要であることが挙げられます。
対照学習の教師あり・なし
二つ目の比較実験として、教師ありの対照学習の代わりに教師なしの対照学習をSimCSEで行ったモデルとの比較を行います。LLM2Vecでは、SimCSEによる学習で得られたモデルは教師ありの対照学習を行ったモデルには劣りますが、精度の高いテキスト埋め込みモデルであることが示されました。そこで、PLaMoをベースに日本語データで教師なし対照学習を行った場合でも同様の結果が得られるかを調べます。MNTPの有無の比較実験と同様に、学習に用いたデータはAppendixの表7の一部で、ベースモデルはPLaMo-1B-sftです。結果は表5の通りです。
| モデル | Overall* | Retrieval* | STS | Classification | Reranking | Clustering | PairClassification |
| PLaMo-1B-sft + MNTP + 教師なし対照学習 | 62.31 | 45.53 | 75.76 | 76.50 | 90.90 | 48.08 | 62.38 |
| PLaMo-1B-sft + MNTP + 教師あり対照学習 | 72.41 | 70.69 | 83.37 | 76.35 | 92.04 | 53.04 | 62.43 |
表5 対照学習の教師あり/なしでの比較実験結果
結果としては、教師あり対照学習をしたモデルの方が教師なし対照学習をしたモデルよりも高い精度となりました。特にretrievalでは教師なし対照学習のモデルは大きく劣っています。この結果は、現在は教師あり対照学習が一般的に用いられていることにも沿ったものとなっています。
双方向注意とcausal注意
最後に、causalマスクを除く処理を行わず、PLaMoに直接対照学習を行った場合の結果との比較を行います。テキスト埋め込みの生成においては双方向注意の方がcausal注意よりも優れているという仮説が正しいかを検証します。なお、ここではfine-tuningは行わず、対照事前学習を2000ステップのみ行ったモデル同士の比較を行います。学習に用いたデータはAppendixの表7と同一です。
| モデル | Overall* | Retrieval* | STS | Classification | Reranking | Clustering | PairClassification |
| PLaMo-1B-dpo (causal) + 対照事前学習 | 72.75 | 73.96 | 82.55 | 75.29 | 93.06 | 49.85 | 62.35 |
| PLaMo-1B-dpo + 対照事前学習 | 74.74 | 77.62 | 83.52 | 76.78 | 93.20 | 51.77 | 62.12 |
表6 双方向注意とcausal注意の比較実験結果
表6の結果から、causalマスクを残したモデルは精度が低下することが確認できました。特にretrievalにおいてcausalマスクの有無が精度に与える影響が強いことがわかりました。
やり残したこと
より大きいバッチサイズを用いた対照事前学習
対照事前学習において、大きなバッチサイズを用いることで埋め込みの精度が向上することが知られています [3]。[3]において、バッチサイズを8192や16384まで増やしても精度が単調に増加し続けることが示されました。今回は最大系列長を512にとっていたことや、計算リソースの都合でバッチサイズは512と比較的小さい値にとどまってしまいましたが、今後この値を大きくすることで、精度の向上が期待できます。
Latent注意層の導入
NV-Embedでは、latent注意層を導入することによりmean poolingよりも高い精度が得られることが示されました。今回は全ての実験でmean poolingを用いましたが、latent注意層に置き換えることでさらなる精度向上が期待できます。latent注意層の実装は完了しましたが、実験はインターン期間中には間に合いませんでした。
Hard negativeの質の改善
対照学習で用いるhard negativeの質を上げることで、テキスト埋め込みの精度が向上することが知られています [13]。hard negativeはpositiveとの区別が難しいサンプルであると同時にfalse negativeではないサンプルである必要があります。今回は、[13]が提案したpositiveのサンプルとの類似度を参照したhard negativeの収集手法を実装しましたが、データセットへの適用は間に合いませんでした。
まとめ
今回のインターンでは、PLaMoをベースに高性能な日本語テキスト埋め込みモデルを開発しました。causalマスクの除去や対照学習をPLaMoに施すことで、decoder-onlyのLLMであるPLaMoを日本語テキスト埋め込みモデルとして使えるようになることがわかりました。また、既存のテキスト埋め込みモデルと比較すると、PLaMoでは小規模な追加学習でも高い精度が出ることが示されました。
メンターより
本インターンでは、九門さんに頑張っていただいたおかげで、decoder only LLMをベースにして高性能な日本語テキスト埋め込みモデルを作成できました。限られた計算資源、時間、データ量であっても、decoder only LLMをベースにすると、他で公開されている埋め込みモデルと比べても遜色ない性能を達成できたことは興味深い知見です。
PFN/PFEではこのようなLLM性能改善のための研究開発を進めています。本取り組みで得られた知見・成果は今後PLaMoに取り入れていく予定です。
Appendix
| ソース | サンプル数 |
| Wikipedia (1) | 264,669 |
| Wikipedia (long) | 697,405 |
| Wiktionary | 357,463 |
| WikiBooks | 13,291 |
| MQA | 796,213 |
| CC News (long) | 829,972 |
| AutoWikiQA (MX) | 594,330 |
| AutoWikiQA (Nemo) | 156,072 |
| JRC | 16,893 |
| JSQUAD | 62,820 |
| AutoWikiNLI | 198,895 |
| JSNLI | 144,190 |
| Total | 4,128,256 |
表7 対照事前学習に用いたデータセットとサンプル数
| ソース | サンプル数 |
| Quiz No Mori | 21,091 |
| Quiz Works | 16,835 |
| JQaRA | 2,235 |
| MIRACL | 3,477 |
| Mr. TyDi | 3,697 |
| NU-SNLI | 109,154 |
| NU-MNLI | 77,785 |
| JaNLI | 6,775 |
| Total | 240,384 |
表8 fine-tuningに用いたデータセットとサンプル数
| 対照事前学習 | fine-tuning | |
| 学習率 | 5e-5 | 5e-6 |
| LoRA r | 64 | 16 |
| バッチサイズ | 512 | 128 |
| ステップ数 | 5000 | 800 |
| 最大系列長 | 512 | 512 |
| hard negatives | 1 | 15 |
表9 学習設定の詳細
参考文献
[1] Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova, 2018, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, NAACL2019.
[2] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu, 2019, Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer, JMLR2020.
[3] Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, Meishan Zhang, 2023, Towards General Text Embeddings with Multi-stage Contrastive Learning.
[4] Hayato Tsukagoshi, Ryohei Sasano, 2024, Ruri: Japanese General Text Embeddings.
[5] Parishad BehnamGhader, Vaibhav Adlakha, Marius Mosbach, Dzmitry Bahdanau, Nicolas Chapados, Siva Reddy, 2024, LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders, COLM2024.
[6] Chankyu Lee, Rajarshi Roy, Mengyao Xu, Jonathan Raiman, Mohammad Shoeybi, Bryan Catanzaro, Wei Ping, 2024, NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models.
[7] Niklas Muennighoff, Hongjin Su, Liang Wang, Nan Yang, Furu Wei, Tao Yu, Amanpreet Singh, Douwe Kiela, 2024, Generative Representational Instruction Tuning.
[8] Jinhyuk Lee, Zhuyun Dai, Xiaoqi Ren, Blair Chen, Daniel Cer, Jeremy R. Cole, Kai Hui, Michael Boratko, Rajvi Kapadia, Wen Ding, Yi Luan, Sai Meher Karthik Duddu, Gustavo Hernandez Abrego, Weiqiang Shi, Nithi Gupta, Aditya Kusupati, Prateek Jain, Siddhartha Reddy Jonnalagadda, Ming-Wei Chang, Iftekhar Naim, 2024, Gecko: Versatile Text Embeddings Distilled from Large Language Models.
[9] Niklas Muennighoff, Nouamane Tazi, Loïc Magne, Nils Reimers, 2022, MTEB: Massive Text Embedding Benchmark, EACL2023.
[10] Tianyu Gao, Xingcheng Yao, Danqi Chen, 2021, SimCSE: Simple Contrastive Learning of Sentence Embeddings, EMNLP2021.
[11] Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, 2021, LoRA: Low-Rank Adaptation of Large Language Models, ICLR2022.
[12] SB Intuitions, 日本語テキスト埋め込みベンチマークJMTEBの構築.
[13] Gabriel de Souza P. Moreira, Radek Osmulski, Mengyao Xu, Ronay Ak, Benedikt Schifferer, Even Oldridge, 2024, NV-Retriever: Improving text embedding models with effective hard-negative mining.



