Blog
本記事は、2024年夏季インターンシッププログラムで勤務された俵 遼太さんによる寄稿です。
こんにちは、京都大学 工学部 電気電子工学科3回生の 俵 遼太 (id:walnuts1018) です。
今回、PFN 2024 夏期国内インターンシップに参加し、社内機械学習基盤の開発・運用を行うCluster Servicesチームにて、「Podごとのインターネットトラフィック量を計測するツールの開発」というテーマに取り組みました。
この記事では、社内のKubernetesクラスタにおける課題と、Podごとのインターネットトラフィック量を計測するために作成したツールについて紹介します。
社内のKubernetesクラスタにおける課題
社内の Kubernetes クラスタでは、複数のユーザーが同じクラスタを利用して様々なワークロードを動かしています。このような構成をとることで、マシンリソースの利用効率を高めることができる一方、特定のテナントがクラスタ全体のリソースを占有してしまうという問題が発生することがあります。特に、今回はネットワーク帯域の占有に関する課題を考えてみます。
クラスタ内のノードは 100GbE のインターフェイスを複数持っているため、Pod 間の通信は非常に高速に行われます。一方、インターネットアクセスの帯域はそれに比べて小さいため、特定のユーザーの Pod がインターネットアクセス帯域を多く使用してしまうと他のユーザーの通信が低速になってしまいます。
このような帯域占有が起こった際に原因となったPodを特定するためには、Pod ごとのインターネットアクセストラフィック量を計測する必要があります。しかし、この値を計測することは意外と難しい課題です。
例えば、cAdvisor のメトリクスを利用する方法を検討してみます。cAdvisor は Pod やコンテナに関する様々なメトリクスを公開しており、その中には Pod のトラフィック量を表すメトリクスも存在します。しかし、このメトリクスの値は Pod 全体のトラフィックの合算値を計測したものであり、通信相手ごとに計測を行っているわけではないため、インターネットアクセスのトラフィック量を知ることはできません。
他の方法として、上流のルーターで計測を行う方法が考えられます。この方法ではインターネットアクセスのトラフィック量を計測することができます。しかし、Pod からの通信は Node で NAT されているため、どの Node からの通信なのかを調べることができますが、その Node 上のどの Pod が通信を行っているのかを調べることはできません。
Podのインターネットトラフィック量計測のアプローチ
以上の課題を解決するため、今回のインターンでは「Podのトラフィック量を通信相手ごとに計測・出力するツール」の作成に取り組みました。
今回の課題解決のためには、個別の通信相手ごとにトラフィック量を計測する必要はなく、適当な粒度で計測を行うことができればよいので、
- Podに対する通信
- KubernetesのServiceに対する通信
- クラスタ外との通信
の3つにグループ化したうえで、それぞれのトラフィック量を計測することにしました。
特定のCNI Pluginの機能に依存せずに計測できるようにするため、以下のようにeBPFを活用したアプローチをとることにしました。
- Pod のネットワークインターフェイスにeBPFプログラムをアタッチする。
- eBPFプログラムが、Pod、Service、クラスタ外ネットワークの宛先ごとにIngress/Egress トラフィック量を計測し、eBPF Mapに保存する。
- ユーザー空間で動いているプログラムがeBPF Mapに保存された測定値を読み出し、メトリクスとして出力する。
前提知識
eBPF
eBPF (extended Berkeley Packet Filter) は、カーネルの動作を変更するプログラムを動的に読み込み、実行させるための機能です。eBPF プログラムは、カーネル内で起こる様々なイベントをトリガーとして実行されます。
eBPF プログラム実行のトリガーとなるイベントをフックポイントと呼び、特定のフックポイントで eBPF プログラムが実行されるように設定することをアタッチと呼びます。
フックポイントは、「パケットを受け取った時」や「システムコールが呼ばれた時」など、様々な種類が用意されています。
また、eBPF プログラムとユーザー空間との間でデータをやりとりする時は、eBPF Map を使います。eBPF Map は、eBPF プログラムとユーザ空間のプログラムの両方から読み書きできる特別なデータ構造で、ハッシュマップや配列など様々なタイプがあります。
XDPとTraffic Control
eBPF のネットワーク関連のフックポイントとして、XDP (eXpress Data Path) と Traffic Control (TC) があり、これらの機構を利用してネットワークパケットの操作を行うことができます。
XDP は、Linux カーネルにおいてネットワークパケットを処理するための機構です。XDP フックにアタッチされたプログラムは、ネットワークパケットが NIC に届いたときに実行されます。
Traffic Control (TC) は、Linux においてトラフィックの分類や制限を行うための機構です。TC にアタッチされたプログラムは、Linux カーネルにパケットがロードされた後に実行されます。
CNI Plugin
CNI Pluginは、コンテナのネットワークに関する設定を行うためのプログラムです。Pod作成時や削除時にコンテナランタイムから呼び出され、インターフェイスの作成や削除、IPアドレスの割り当てなどを行います。
CNI Pluginには、Interface CNI PluginとChained CNI Pluginの2種類があり、複数のPluginを組み合わせて使うことができます。
Interface CNI Pluginは、ネットワークインターフェイスを作成し、接続性に責任を持ちます。一方、Chained CNI Pluginは、Interface CNI Pluginがネットワークインターフェイスを作成した後に実行され、様々な処理を行います。[1]
コンテナランタイムによってCNI Pluginが呼び出される際には、コンテナのネットワークインターフェイス名、ネットワークネームスペース、Podの名前やNamespaceに関する情報が渡されます。
設計
前章で説明したアプローチをもとに詳細な実装方法について考えてみます。
特に考慮しなければならないのは以下の4点です。
- Podの作成をどうやって検出するか
- eBPFのフックポイントをどこにするのか
- どのeBPF Mapタイプを利用し、どのようにトラフィック量の情報を書き出すか
- CIDRの情報をどうやってeBPFプログラムに渡すか
それぞれの項目について、今回採用した実装方法について説明します。
Pod作成の検出方法
Pod のネットワークインターフェイスに eBPF プログラムをアタッチするためには、Pod の新規作成を検出し、その Pod のネットワークネームスペースやインターフェイス名を取得する必要があります。
この処理を簡単に行うために、今回は eBPF プログラムをアタッチする部分を Chained CNI Plugin として実装することにしました。前提知識の章で説明した通り、CNI Plugin は Pod 作成時に確実に呼び出されるかつ eBPF プログラムをアタッチするために必要な情報を全て受け取ることができるため、この方法を採用しました。
CNI Plugin は Pod 作成時などに都度呼び出され、処理が完了すると直ちに終了するプログラムであるため、eBPF Map から値を読み取って定期的にメトリクスを出力するためには、CNI Plugin が終了した後も動作し続けるプログラムが必要です。よって、メトリクスの出力部分は CNI Plugin とは別のプログラムとして実装することにしました。
eBPFのフックポイント
ネットワークに関する eBPF プログラムを実行する際には、XDP と TC の二つが選択肢となりますが、今回は TC を利用することにしました。
その理由は、パケット送信時のイベント発生の有無にあります。XDP は、ネットワークパケットの受信時(Ingress)にしかイベントが発生しないため、送信時(Egress)のトラフィック量を計測することができません。一方、TC は受信時も送信時もイベントが発生するため、Ingress と Egress の両方のトラフィック量を計測することができます。そのため、TC を利用することにしました。
eBPF Mapのタイプと構成
トラフィック量を保存するeBPF Mapにどのようなタイプを用いるか、そしてどの単位でeBPF Mapを分けるかを考える必要があります。
今回は、以下のようなeBPF Map構成をとることにしました。
- eBPF Mapタイプには、
BPF_MAP_TYPE_PERCPU_ARRAYを利用する- このタイプは、各 CPU ごとに値を持つ固定長の配列であり、複数の CPU が同時にアクセスしても競合が発生しない [2]
- Keyは、送信元 (Ingress) / 宛先 (Egress) のCIDRを表す数字 (0: Pod / 1: Service / 2: Other)とし、Value はその累積のトラフィック量 (byte) とする
- PodごとにIngress用、Egress用の二つのBPF Mapを用意する
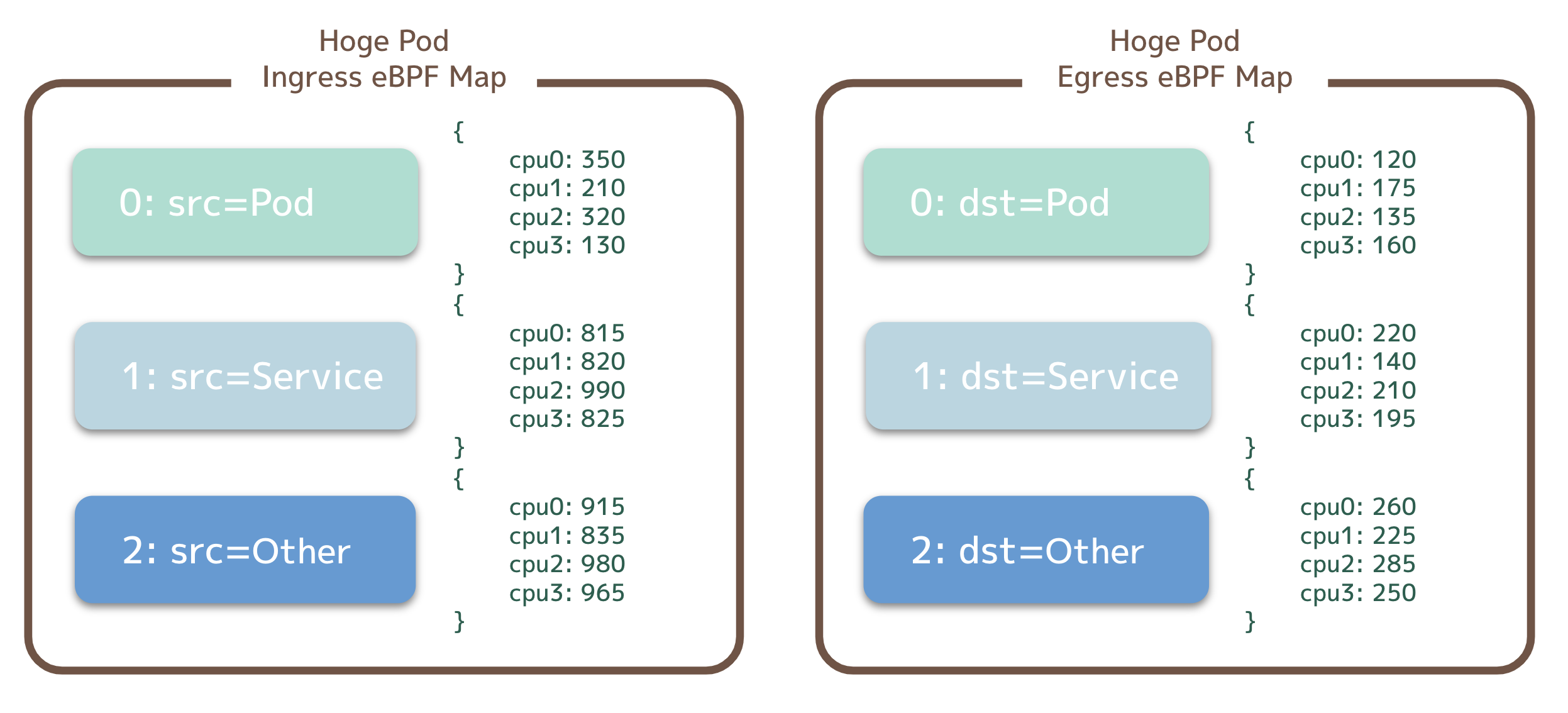
図1: eBPF Mapの構成
CIDRの情報をどうやってeBPFプログラムに渡すか
Pod や Service に割り当てられるアドレスの CIDR は環境によって異なるため、eBPF のプログラム中にその値をハードコードすることはできません。また、eBPF プログラムはカーネル空間で動作するため、環境変数などから動的に値を読み取ることもできません。
そこで、今回の実装では、あらかじめユーザー空間のプログラムが CIDR の情報を eBPF Map に書き込んでおき、eBPF プログラムはその値を読み取って利用することにしました。この構成であれば、環境変数などの値をユーザー空間のプログラムを介して eBPF プログラムに渡すことができます。
eBPF Map はカーネルにロードした時点で値を書き込むことができるようになるため、先に eBPF Map だけをロードし、CIDR 情報の書き込みが完了した後に eBPF プログラムをアタッチすることで、確実にeBPF Mapの値を初期化することができます。
プログラムの構成
これらの考慮事項と方針を踏まえて全体のアーキテクチャとして以下のような構成を取りました。
- Pod作成時に、CNI PluginがPod のネットワークインターフェイスの TC (Traffic Control) にeBPFプログラムをアタッチする。
- eBPFプログラムは、パケットごとに、送信元 (Ingress) / 宛先 (Egress) のIPアドレスから、Pod / Service / OtherのCIDRを判断し、対応するeBPF Mapのエントリの値をパケットサイズ分増やす。
- ユーザー空間のプログラム (Traffic-Exporter Daemon Pod) は定期的にeBPF Mapの値を読み取り、OpenTelemetry/Prometheus 形式のメトリクスとして出力する。
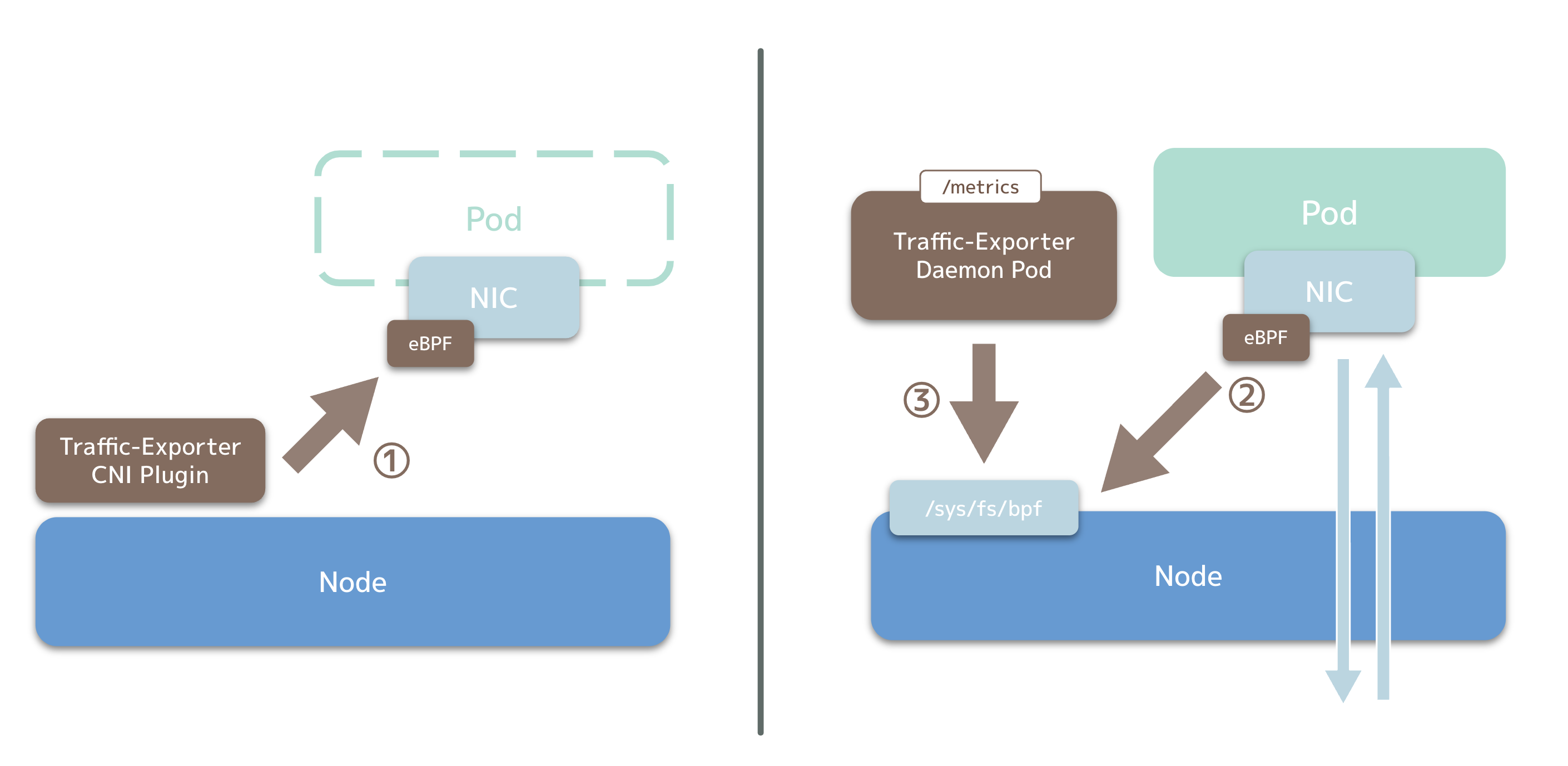
図2: アーキテクチャ
次の章では、この設計を基に実装方法を説明します。
実装
eBPFプログラム
まずは、このツールの肝となる eBPF プログラムの実装について説明します。
今回の eBPF プログラムは TC にアタッチするので、関数の引数は__sk_buffという構造体になります。 この中には実際のパケットデータが格納された領域へのポインタが入っているため、パケットデータからIPヘッダーの部分をパースし、送信元/宛先の IP アドレス、パケットサイズを取得できます。
今回は、以下のようにして送信元/宛先の IP アドレスとパケットサイズの取得の実装を行いました。
void *data = (void *)(long)skbuff->data;
void *data_end = (void *)(long)skbuff->data_end;
struct ethhdr *eth = data;
int ethsize = sizeof(*eth);
if (data + ethsize > data_end) {
return -1;
}
if (bpf_ntohs(eth->h_proto) != ETH_P_IP) {
return -1;
}
struct iphdr *iph = data + ethsize;
if (data + ethsize + sizeof(*iph) > data_end) {
return -1;
}
if (iph->version == 0x04) {
*size = bpf_ntohs(iph->tot_len);
*src_addr = bpf_ntohl(iph->saddr);
*dst_addr = bpf_ntohl(iph->daddr);
return 0;
}
ここで、sizeがパケットサイズ、src_addrとdst_addrが送信元/宛先の IP アドレスです。
次は、取得したIPv4アドレスが Pod / Service / その他 のうち、どれに該当するかを判定する必要があります。 今回は、CIDR のネットワークアドレスとサブネットマスクをビット演算で比較する実装を採用しました。
最後に、eBPF Map に保存されている値のうち、CIDRに対応する値をパケットサイズ分増やす処理を行います。bpf_map_lookup_elem関数を使うことで、第1引数の eBPF Map から第2引数のKeyに対応する値のポインタを取得できるため、このポインタの参照先の値にパケットサイズを加算します。
__u64 *p = bpf_map_lookup_elem(&ingress_traffic_count_v4, &cidr_id);
if (p) {
(*p) += size;
}
設計の章でも説明したように、今回はBPF_MAP_TYPE_PERCPU_ARRAYという種類のeBPF Mapを使用しているので、このように直接加算を行うことができます。
次の章では、このプログラムをロードし、TC にアタッチする方法について説明します。
eBPF オブジェクト の 永続化
通常、eBPF オブジェクトはプロセスによる参照がすべてなくなった時点でカーネルによってアンロードされます。そのため、アタッチを行ったプロセスが終了すると、アタッチされたプログラムや、eBPF Map などが消えてしまいます。
そこで、この問題を解決するためにPinning という機能を利用します。Pinning を行うことで、eBPF オブジェクトが/sys/fs/bpf 上の疑似ファイルとして永続化されます。これでアタッチを行ったプロセスが終了したとしてもアタッチされたプログラムや eBPF Map が消える心配はありません。また、アタッチを行ったプログラムとは別のプログラムからもeBPF Mapの値を読み取ることができるようになります。
eBPF Mapの読み出し
ここまで、CNI PluginとしてeBPFプログラムをアタッチする部分に焦点を当ててきました。ここからは読み出し側の実装を説明します。
読み出しとメトリクスの出力を行うプログラムは、常時起動しているデーモンとして実装します。Kubernetes上にDaemonsetとしてデプロイすることを想定しています。
CNI PluginによってPinningされたeBPF Mapは、cilium/ebpfのLoadPinnedMap 関数を使ってロードした後、Lookup メソッドを使って値を読み出すことができます。
m, _ := ebpf.LoadPinnedMap("/sys/fs/bpf/test", nil)
defer m.Close()
var v uint32
m.Lookup(uint32(0), &v)
このとき、Nodeの/sys/fs/bpfをDaemonsetのPodにHostPathでマウントする必要があります。
今回は、eBPF Mapの疑似ファイル名にPodの名前とNamespace名を使用しているので、KubernetesのAPIを利用せずともPodを特定することができます。
メトリクスのエクスポート
今回、メトリクスの収集とエクスポートには go.opentelemetry.io/otel ライブラリを利用しました。このライブラリを用いることで、簡単にOpenTelemetry形式、もしくはPrometheus形式でメトリクスを出力することができます。
検証
実装完了後、実際に検証用のPodを作成し、トラフィックを正しく計測できているかどうか、検証を行いました。検証環境は図3の通りです。
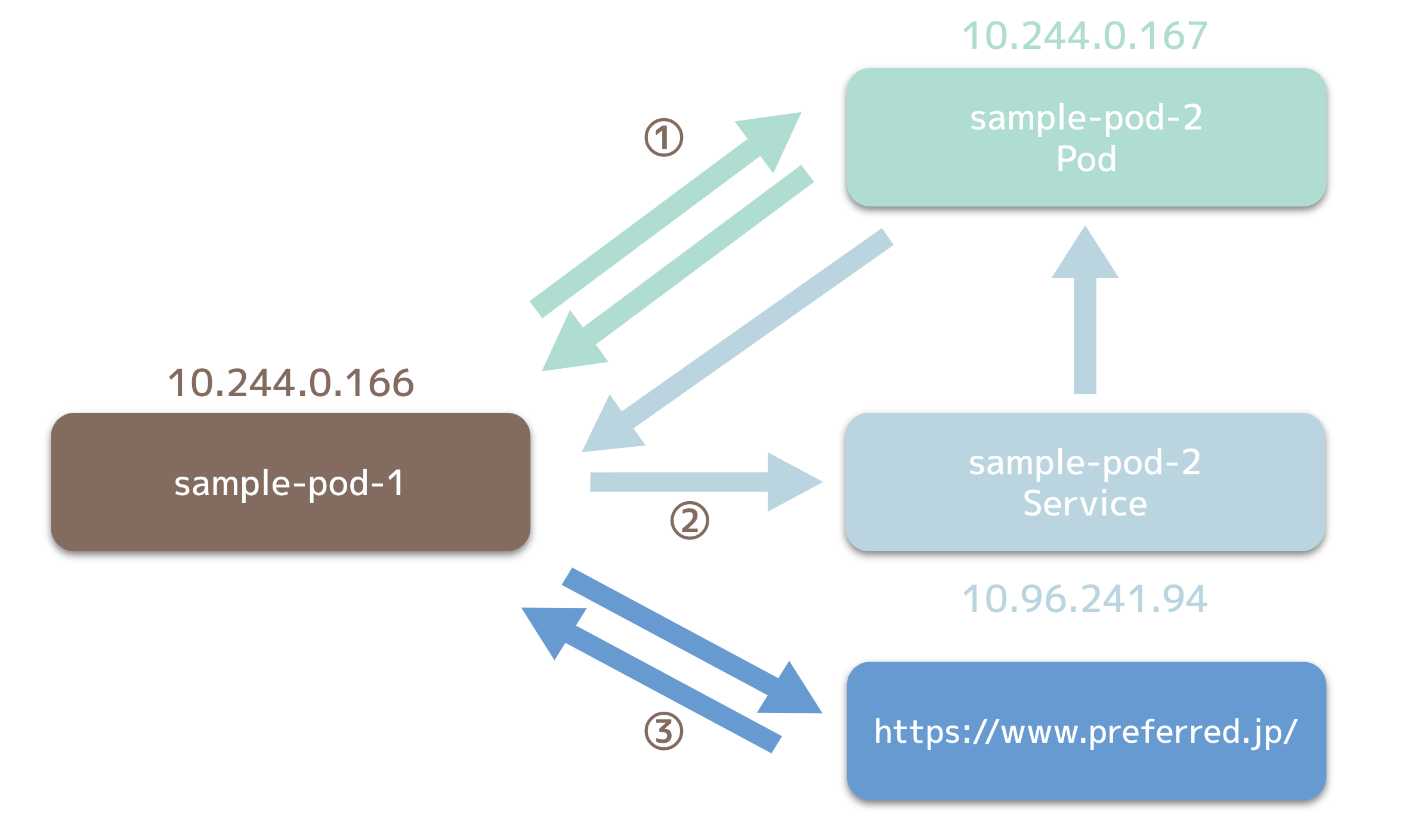
図3: 検証環境の構成
sample-pod-1から、sample-pod-2内の約100KiBのファイルをPod IP・Service IP経由でそれぞれ取得した後、 https://www.preferred.jp/ (約45KiB) にリクエストを投げました。
テスト実行後のメトリクスを図4、 図5に示します。
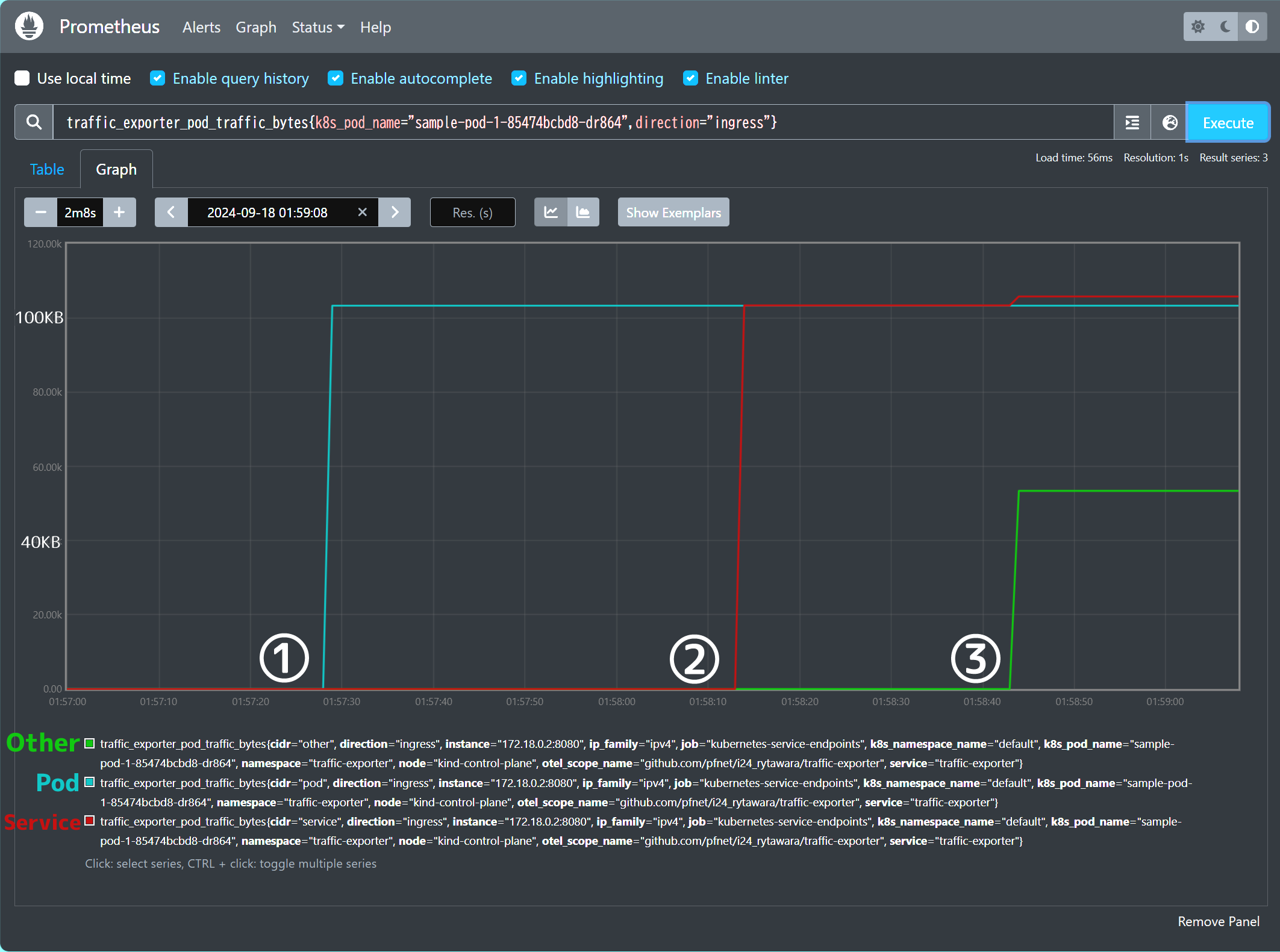
図4: sample-pod-1のIngress (受信) トラフィック量
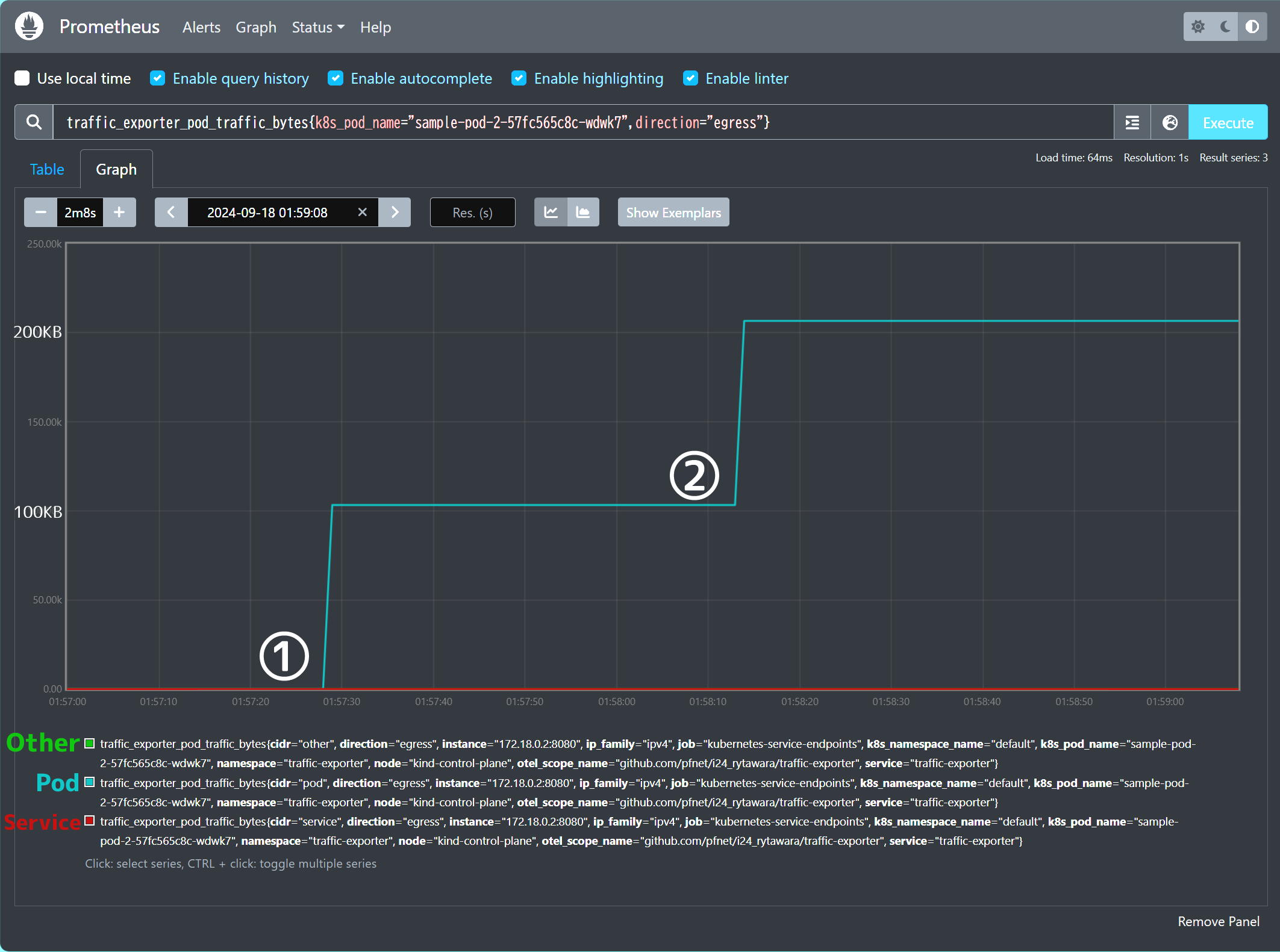
図5: sample-pod-2のEgress (送信) トラフィック量
図4・図5を見ると、各リクエスト送信後にそれぞれのメトリクスの値がファイルサイズ分増加しており、正しく動作していることがわかります。
苦労点
この章では実装時に苦労した点について紹介します。
IPヘッダをパースして得られたIPアドレスが正しくない
eBPFプログラムの実装中、IPヘッダから取り出されたIPアドレスが想定とは異なる値になるという問題が発生しました。
IPヘッダの送信元アドレスと宛先アドレスは、32ビット符号なし整数として表現されます。例えば、10.146.0.7は0x0a920007として格納されます。 しかし、IPヘッダのパースを実装し、IPアドレスを取り出した結果、下位2バイトが0になってしまい、0x0a920000のような値となってしまっていました。
この問題の原因はByte Orderの変換にありました。 IPヘッダの中の数値は、Network Byte Orderで格納されています。よって、Host Byte Orderを基準にすると、0x0700920aという形で格納されていることになります。 この値をHost Byte Orderに変換するためのマクロとして、bpf_ntohs(unsigned short用)とbpf_ntohl(unsigned integer用)が定義されています。
IPv4アドレスは32ビットなので、bpf_ntohlを使うべきですが、最初の実装では誤ってbpf_ntohsを使用していました。bpf_ntohsは渡された値を unsigned shortとして解釈するので、下位2バイトのみが取り出され、0x0a920000となってしまっていました。 bpf_ntohlを使う実装に変更したところ、正しくIPアドレスを取得できるようになりました。
eBPF MapのPinning時にOperation not permittedエラーが発生する
CNI Pluginの実装が完了し、実際に動作させたところ、eBPF MapのPinningを行う処理がOperation not permittedというエラーで失敗してしまいました。
この問題の原因として、CNI Pluginがコンテナランタイムによって実行される際のCapabilityや、ネットワークネームスペース内で実行していることなどが影響しているのではないかと推測し、さまざまな対照実験を繰り返しましたが、解決には至りませんでした。
その後も実験を繰り返した結果、Pinningを行うときのファイル名に「.」が含まれているとエラーが発生する、ということが判明しました。 事前のテスト実装では、testというファイル名を用いていましたが、実際の実装では Pod の IPv4 アドレスをそのままファイル名としていたため、エラーが発生していました。
PodのNamespaceと名前を使ってファイル名を生成する実装に変更することで、エラーなくPinningを行うことができるようになりました。
その後メンターの石澤さんが以下の実装を見つけてくださいました。
/* Dots in names (e.g. "/sys/fs/bpf/foo.bar") are reserved for future * extensions. That allows popoulate_bpffs() create special files. */ if ((dir->i_mode & S_IALLUGO) && strchr(dentry->d_name.name, '.')) return ERR_PTR(-EPERM);
この実装を見る限り、ファイル名に.が含まれている場合には EPERM のエラーコードを返すようです。
この仕様は eBPF Docs などにも明記されておらず、気づくまでに多くの時間を費やしてしまいました。
感想
今回のインターンでは以上のようなテーマに取り組み、無事 Pod ごとのトラフィックを計測できるようになりました。
実装前は、eBPFはとても複雑で難しい物だと捉えていましたが、簡単なプログラムであれば思ったよりも簡単に扱えることが分かりました。しかし、ドキュメントが完璧に整備されているとは言えないので、トラブルシューティングなどは少し難しかったです。
実装にあたっては「入門eBPF」という書籍や、以下の記事が大変役立ちました。
この場を借りてお礼申し上げます。
また、メンターの清水さん、石澤さんのお二人には実装の相談やバグ原因調査で何度もお世話になりました。特に IPアドレスのパースに関するバグや、eBPF MapのPinning時のエラーは、絶対に一人では解決できなかったと思います。本当にありがとうございました。
そして、他のインターンの方々やCluster Serviceチームのみなさんと交流する中でたくさんの新しい知識や発見を得ることができました。本当に皆さんの知識量が凄く、色々と調べながら学ぶ日々でした。
2週間という短い期間でしたが、とても充実した時間を過ごすことができました。今回の経験を生かし、大好きなKubernetes関連の開発を今後も続けていきたいと思います!
メンターからのコメント
Cluster Services チームの昨年までの7週間の期間から今年は2週間へ期間を短縮して実施しました。この2週間の中で、オリエンテーション、クラスタを設置しているデータセンターへの見学、最終発表などがあり、テーマに取り組むことができる実質的な時間が短くなってしまう中で俵さんにはインターンのテーマに取り組んでいただきました。
2週間という短い期間を考えるとやりきることが比較的難しいテーマであると考えていたこと、また、俵さんはこのインターン以前には eBPF の経験がないとのことだったため、やりきれなくて終わってしまう可能性も十分あり得ると思っていたのですが、やりきって形にまとめてくれました。これまで、チームでは実際に eBPF を使ったツールの開発経験がなかったのですが、今回のインターンでのテーマを通してチームにおいても eBPF を利用するための知見が得られました。ありがとうございます。
Area
