Blog
本記事は、2019年夏のインターンシップに参加された柴田佳祐さんによる寄稿です。
はじめに
PFN2019年夏季インターンに参加した柴田佳祐です.普段は京都大学情報学研究科でコンピュータビジョンの研究をしています.今回のインターンでは音声信号処理をやってみたいと思い,インターンではSpeech Separation(音声分離)のタスクに取り組みました.
背景
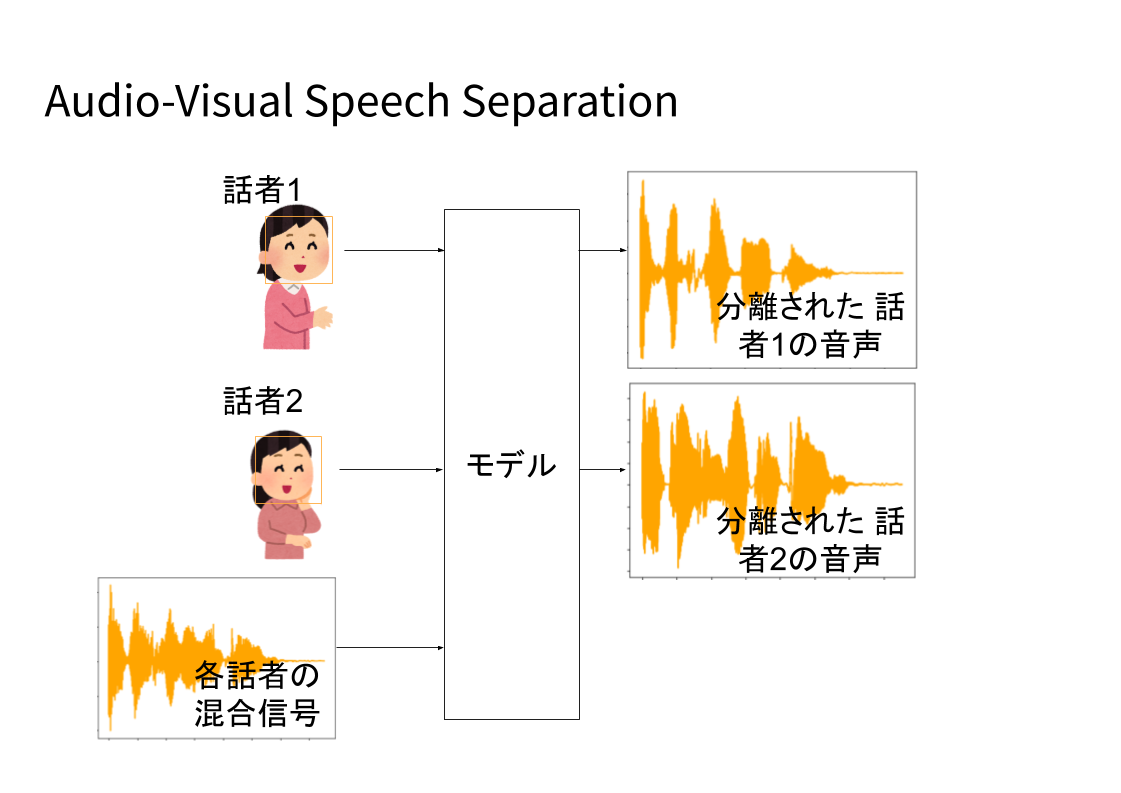
まず,Speech Separationとは,複数人の音声が混ざった混合信号から各人の音声を取り出すタスクです.人間の場合は,カクテルパーティー効果として知られているように関心のある話者の音声に注意を向けることができます.しかし,複数人の音声が混ざるような環境で音声を聞き取って利用するロボットの場合,そのままではカクテルパーティー効果は働きません.
今回取り組んだAudio-Visual Speech Separationは,Speech Separationに聴覚情報だけではなく,視覚情報を利用するという研究です.視覚情報を利用すると性能の向上が見込まれるだけではなく,映像中で話している人と,分離された音声の対応づけを行うことができます.
先行研究
Audio-Visual Speech Separationの先行研究については,以下の2つの論文を主に参考にしました.
[Ephrat+2018]
https://looking-to-listen.github.io/
視覚情報を利用するためにFaceNetのような顔認識ネットワークを利用しており,全体のモデルサイズが非常に大きくなっています.また,分離を行う対象が対象の人数,例えば2人の場合と3人の場合でモデルの構造が異なっており,話者の数や検出できる顔の数が異なる場合に単一のモデルで適用できないという問題がありました.
[Morrone+2019]
https://arxiv.org/abs/1811.02480
こちらは,顔から特徴を抽出するネットワークを使わずに既存の顔ランドマーク検出器を視覚情報として利用するという論文です.顔ランドマークとは,目,眉,唇の輪郭などの識別可能な顔のパーツ上の点のことを言います.そのため,サイズが小さく利用しやすいモデルになっています.このモデルは,一度に全話者の音声の分離を行うのではなく,混合信号と一人分の話者の視覚情報を入力することで当該話者の音声信号の分離抽出を行います.これにより,話者の数に依存しないモデルになっています.
https://www.youtube.com/watch?v=YQ0q-OFphKM
問題設定
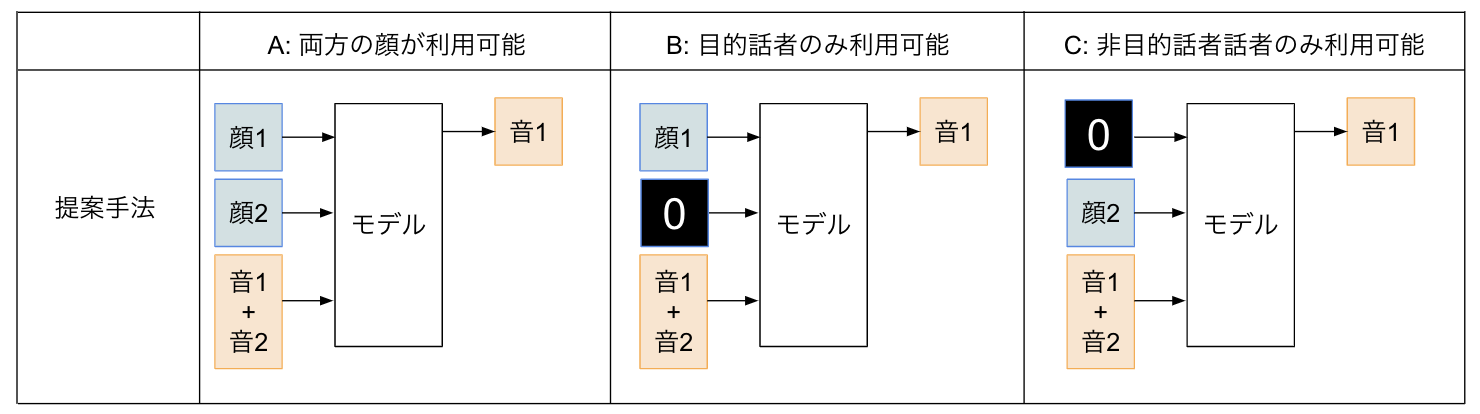
どちらの先行研究も音声分離のために顔情報を利用していますが,現実的には常に顔検出器によって顔を検出できるとは限りません.後ろを向いている話者やカメラから映らない範囲にいる話者など,顔検出が失敗する場合が考えられます.例えば,2話者の混合音声から1話者の音声を取り出す場合を考えると以下のような顔情報の入手パターンが考えられます.
- A: 2人とも手に入る場合
- B: 目的話者(取り出したい話者)のみ手に入る場合
- C: 非目的話者(取り出さない話者)のみ手に入る場合
Ephrat+2018のモデルでは,顔1と顔2を両方同時に利用して,顔1の人に対応する音1,顔2の人に対応する音2をそれぞれ取り出します.この場合は,どちらか片方の顔が手に入らない場合に対応することができません.
Morrone+2019のモデルでは,Aの設定の場合,目的話者(話者1)の顔を利用して目的話者の音声を取り出します.次に,両方の人の音声を取り出すために話者1と話者2を入れ替えて同様に音声を取り出します.この場合,2人分の顔が手に入る場合にも1人分の顔のみを利用して音声分離を行いますが,2人の顔が手に入る場合は2人の顔を使う方が性能が向上すると考えられます.今回は,手に入った分の顔を使えるだけ使って音声分離を行うような手法を考えて実装しました.
| A: 両方 (目的話者, 非目的話者)の顔 が利用可能 |
B: 目的話者 のみ利用可能 |
C: 非目的話者 のみ利用可能 |
|
| Ephrat+2018 | ○ | ☓ | ☓ |
| Morrone+2019 | ○ | ○ | ☓ |
| Ours | ○ | ○ | ○ |
提案手法
顔が見えない場合に対応するため,最大の人数(今回は2人)に対応するモデルを作り,顔が手に入らない部分にはダミーの顔情報(今回は要素が0のベクトル)を入れて学習しました.
実験
今回考案した手法では,A,B,Cそれぞれの設定で訓練を行なった場合と,それぞれの設定を混ぜたデータで訓練を行なった場合について実験を行いました.データセットはThe GRID audiovisual sentence corpusを利用しました.データセットの33話者のうち,訓練データは25話者,バリデーションは4話者,テストには4話者を用い,話者に依存しないモデルとしてのテストができるように分割しました.
結果
SDR(音声対全歪比)を用いて評価しました.テストデータの混合信号のSDRは,0.292でした.SDRは,高ければ高いほど分離結果が良いことを表しています.ベースラインは,Morrone+2019の手法を参考にして実装したものを用いています.
Aの実験:2人の顔が利用可能
| 手法 | 訓練時 | テスト時 | SDR |
| ベースライン ([Morrone+2019] を参考とした実装) |
両方 | 両方 | 4.50 |
| 提案手法 | 両方 | 両方 | 5.09 |
A(2人の顔が利用可能)の設定では,ベースラインの手法では1つしか顔を利用できないため,目的話者の顔のみを利用して訓練とテストを行いました.Aの設定でもベースラインが実質的に利用できる顔情報はBの設定の場合と同じです.一方,提案手法は顔を複数受け付けることができるモデルであり,2人の顔を利用して訓練し2人の顔を使ってテストしました.
訓練とテストで2人の顔を使うことでSDRが上がり,性能が向上しました.
Bの実験 : 目的話者のみ利用可能
| 手法 | 訓練時 | テスト時 | SDR |
| ベースライン ([Morrone+2019] を参考とした実装) |
目的話者のみ | 目的話者のみ | 4.50 |
| 提案手法 (Bのみで訓練) | 目的話者のみ | 目的話者のみ | 4.50 |
| 提案手法 (A, Bを混ぜて訓練) | 両方 | 目的話者のみ | 4.65 |
B(取り出したい話者のみ利用可能)の設定では,ベースラインの手法と提案手法ともにテスト時には目的話者の顔のみを利用しました.提案手法の訓練時は,目的話者の顔とダミーの顔のデータ(Bの設定)のみで訓練する場合と,両方の話者の顔のデータ(Aの設定)とBの設定のデータで訓練する場合をテストしました.
AとBを混ぜて訓練する場合では,ベースラインと比較してSDRは低下しませんでした.
Cの実験 : 非目的話者のみ利用可能
| 手法 | 訓練時 | テスト時 | SDR |
| ベースライン ([Morrone+2019] を参考とした実装) | N/A | N/A | N/A |
| 提案手法 (A, B, Cを混ぜて訓練) | 両方 | 非目的話者のみ | 4.15 |
C(取り出さない話者のみ利用可能)の設定では,ベースラインの手法は利用できる顔が無いためテストすることができません(今回のような2話者のケースであれば,顔2を入力することで顔2音声を取り出し,入力信号から減算することもできますが).提案手法では,A, B, Cの設定の全てのデータを混合して訓練し,テスト時に非目的話者のみを用いた場合,SDRは他の設定でテストする場合と比較して少しの低下となる結果が得られました.
まとめ・感想・謝辞
今回の手法は,2話者で顔情報が得られない場合について実験を行いました.3,4話者の場合や不特定多数の話者の場合,雑音が混ざる場合についてはまだ実験を行なっておらず,今後の課題だと考えています.
このインターンでは,GPUクラスタを利用して学習を行いました.ChainerMNを用いると,16GPUなど,多数のGPUを使いたい場合も簡単に学習を行うことができました.また,並列でジョブを実行させることができ複数の条件で比較を行いたい時にすぐに結果が得られたため,多くの試行錯誤を行うことができました.環境設定にはDockerfileを利用でき,さらにcuDNNのdeterministicモードと乱数シード値の固定を行うことで,同じ設定なら同じ結果が再現する環境だったのも非常に良かったです.
1ヶ月半という通常であれば研究をするには短い期間でしたが,データセットの準備をしていただけたことやすぐに整う再現性のある環境,同じチームの方や社員の方のアドバイスのおかげで期間内に新しいアイディアを定量的に評価することができました.特に,メンターの佐藤さん,谷口さんには非常にお世話になりました.音声のタスクに取り組むのは初めてでしたが,学習を行う際のテクニックや音声信号処理の議論など非常に勉強になりました.ありがとうございました.
メンターからのコメント
メンターを担当したPFNの佐藤と谷口です.
今回柴田さんに取り組んでいただいた音声分離はロボット向けの音声ユーザインタフェース(VUI)における音声処理において重要な技術です.1990年代から複数マイク(マイクアレイ)を用いた方式は盛んに研究されてきましたが,ここ最近,deep clusteringやpermutation invariant trainingなど,深層学習を活用して1マイクでも高精度に音声分離が可能な技術が発表されており,大きな期待を集めています.しかし,遠距離からの音声の分離,耐雑音性能,話者のトラッキングなど,ロボットVUIへの実応用には多くの課題が残っています.
今回, 柴田さんに取り組んで頂いた,映像など他のモーダルの活用はその課題へのアプローチの一つだと考えられます.
マルチモーダルな機械学習のため,通常より大きいデータセットのサイズに起因する問題や,実装そのものが難しい部分が多くありましたが,柴田さんにはコンピュータービジョンの分野の知識を活かしつつ,研究開発をしていただきました.音声分野は本人の分野外でしたが,意欲的に勉強して取り組んで頂き,インターンの限られた時間の中で性能評価まで行うことができました.
Tag


