Blog
本記事は2025年度PFN夏季インターンシップで勤務された青木悠飛さん、大橋諭貴さん、芝太地さん、松浪大輔さんによる寄稿です。
はじめに
8/7~9/26の7週間にわたり、グループ開発インターンに取り組みました。本インターンでは、「LLMを用いたアプリケーション開発」のテーマでWeb上のデータを収集する 「Deep Crawler」というアプリケーションを開発しました。
メンバー紹介
チームメンバーの所属と主な担当部分を紹介します。
一橋大学大学院 修士2年の青木悠飛です。深層学習を利用した脳神経科学の研究をしています。Web Agent (Crawler)を主に担当しました。
東北大学大学院 修士1年の大橋諭貴です。自然言語処理や大規模言語モデルの研究をしています。Web backendを主に担当しました。
東京大学大学院 修士1年の芝太地です。大学では大規模言語モデルの研究をしています。フロントエンドを主に担当しました。
東京科学大学 3年の松浪大輔です。工学院経営工学系に所属しています。プランナーエージェントを主に担当しました。
背景
Web Agentとは?
Web AgentとはHTTPリクエストやブラウザ操作を通して、インターネット上の情報探索や操作を自動で実行するAIエージェントです。
Web Agent は主にPlanner、Tools、Memoryの3つの構成要素を持ちます。
- Planner: ユーザーのプロンプトを達成するために実行計画を立てます。
- Tools: クリックやスクロールなどのエージェントが実行できる操作の単位を表します。
- Memory: 過去の行動で得た情報を保持し、次の行動に活かします。
既存サービスの課題
既存のサービスは長大なリストや複数ページにわたるデータを過不足なく収集するのが苦手です。
例えば、ChatGPTやGeminiのDeep Researchは複数の情報源からの情報をまとめてレポート化することを主眼としていますが、まだ数百件のページをクロールし、情報を漏れなく取得するような作業は不得意です。
例えば、PFNのブログページの場合、ページネーションが多数存在するページの情報を網羅的に取得するのは、現状のサービスではできません。
また、オープンソースのWeb AgentであるBrowser Useは簡単なタスクであれば高い精度で実行できますが、ステップ数の多い複雑なタスクでは誤操作や目的からの逸脱を生じる可能性があります。
目的
既存のサービスのという問題を解決するために、今回のアプリケーション「Deep Crawler」を開発しました。
アプリケーション紹介
Deep Crawler
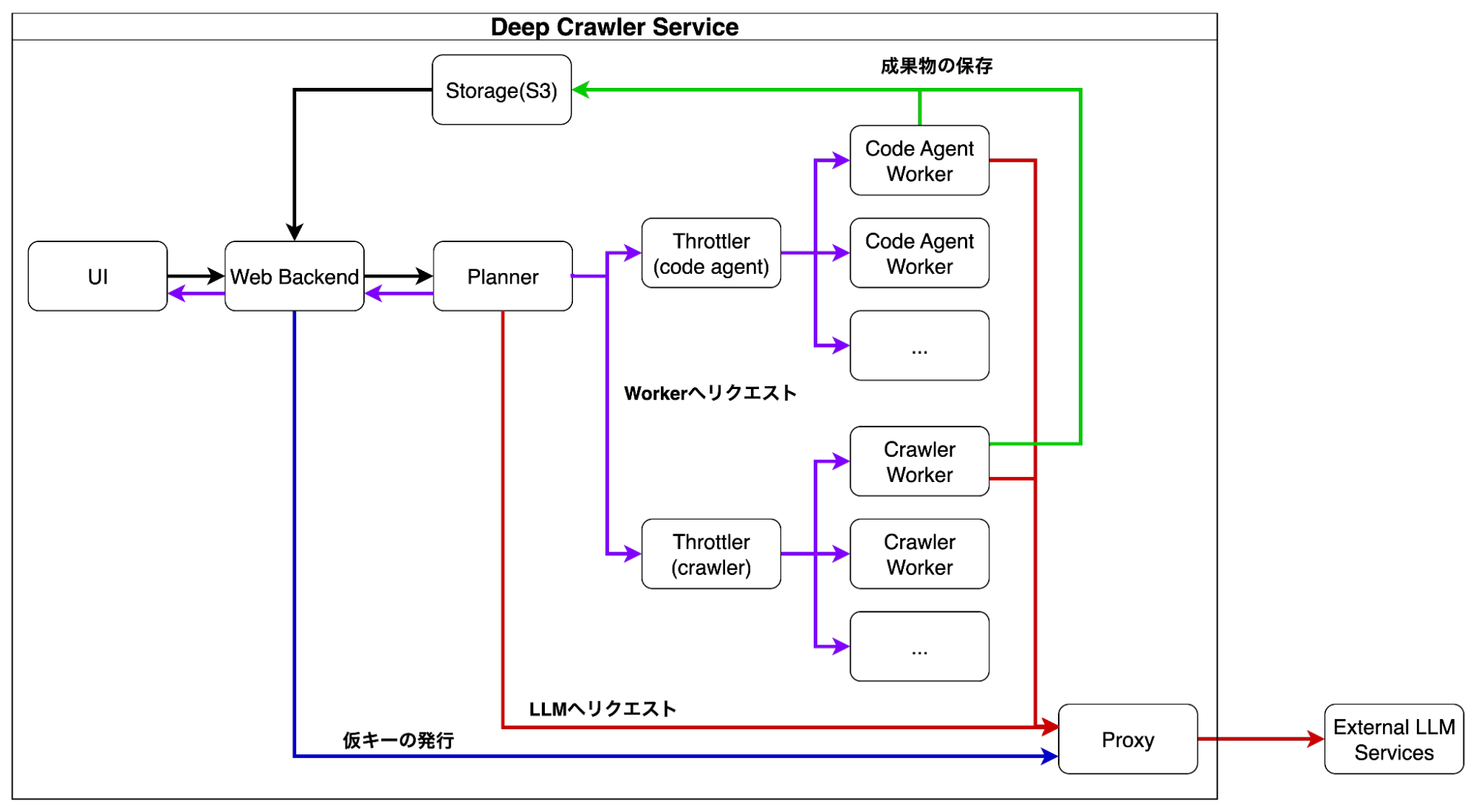
アプリケーション構成
今回のアプリケーションでは、UIとWeb Backendの間はREST APIとイベントストリームを、それ以外の通信ではgRPCを採用しました。これによってコンポーネントのモジュール性や再利用性が高くなり、ユーザーに質問をするWorkerの新規追加などの機能拡張をスムーズに進めることができました。
各コンポーネントの使用技術は以下のとおりです。
- UI
- React Router, TanStack Query, React Flow
- Web Backend
- Fastify, Postgres, Prisma
- Planner
- Nest-JS, Effect-TS
- Throttler
- Rust(tonic)
- Proxy
- express
- Worker
- Python, Browser Use, opencode
Throttlerはマルチスレッドプログラミングが主な責務だったためRustを、WorkerはWeb Agentとの接続のため、Pythonを使用しました。
UI
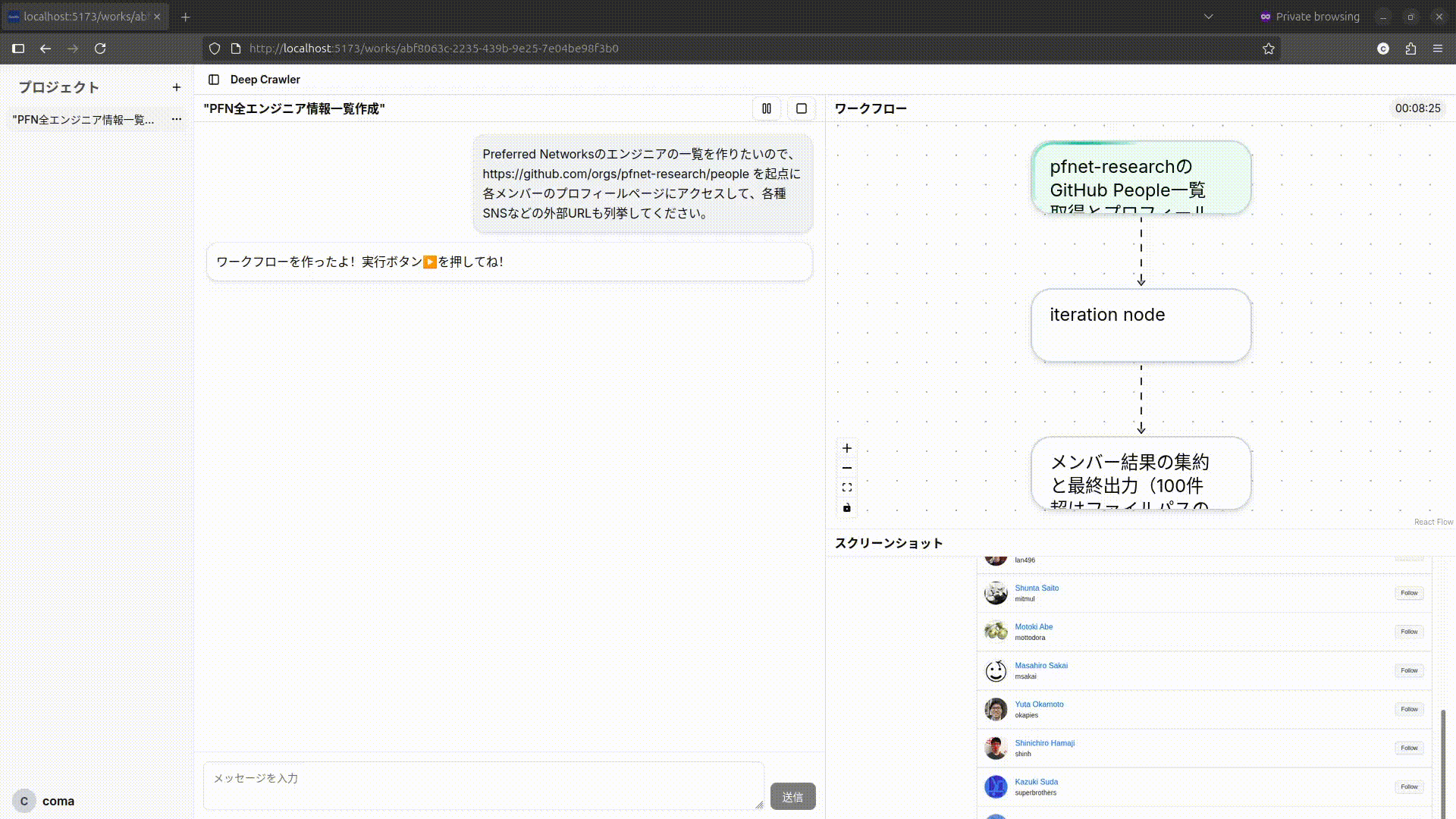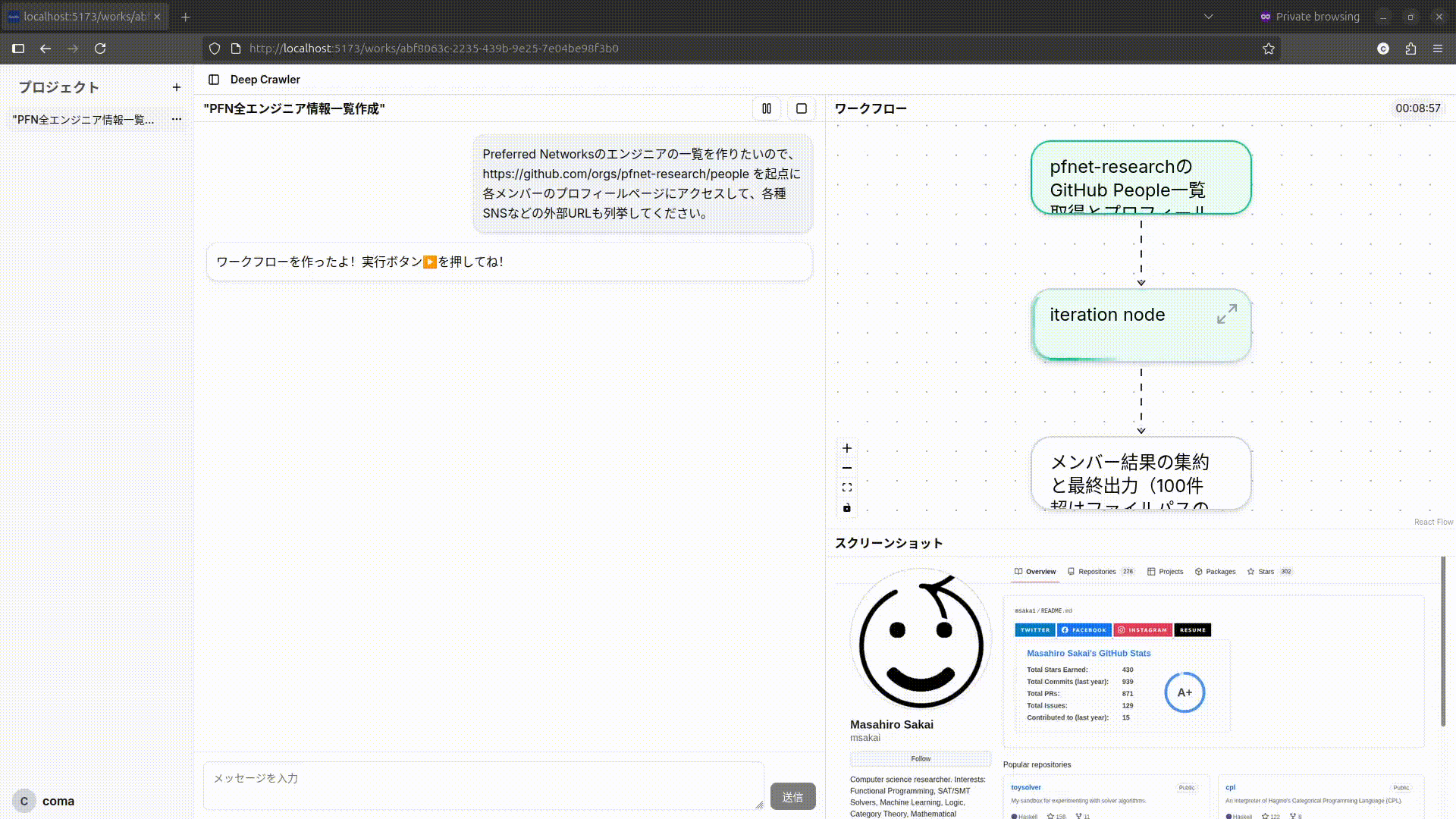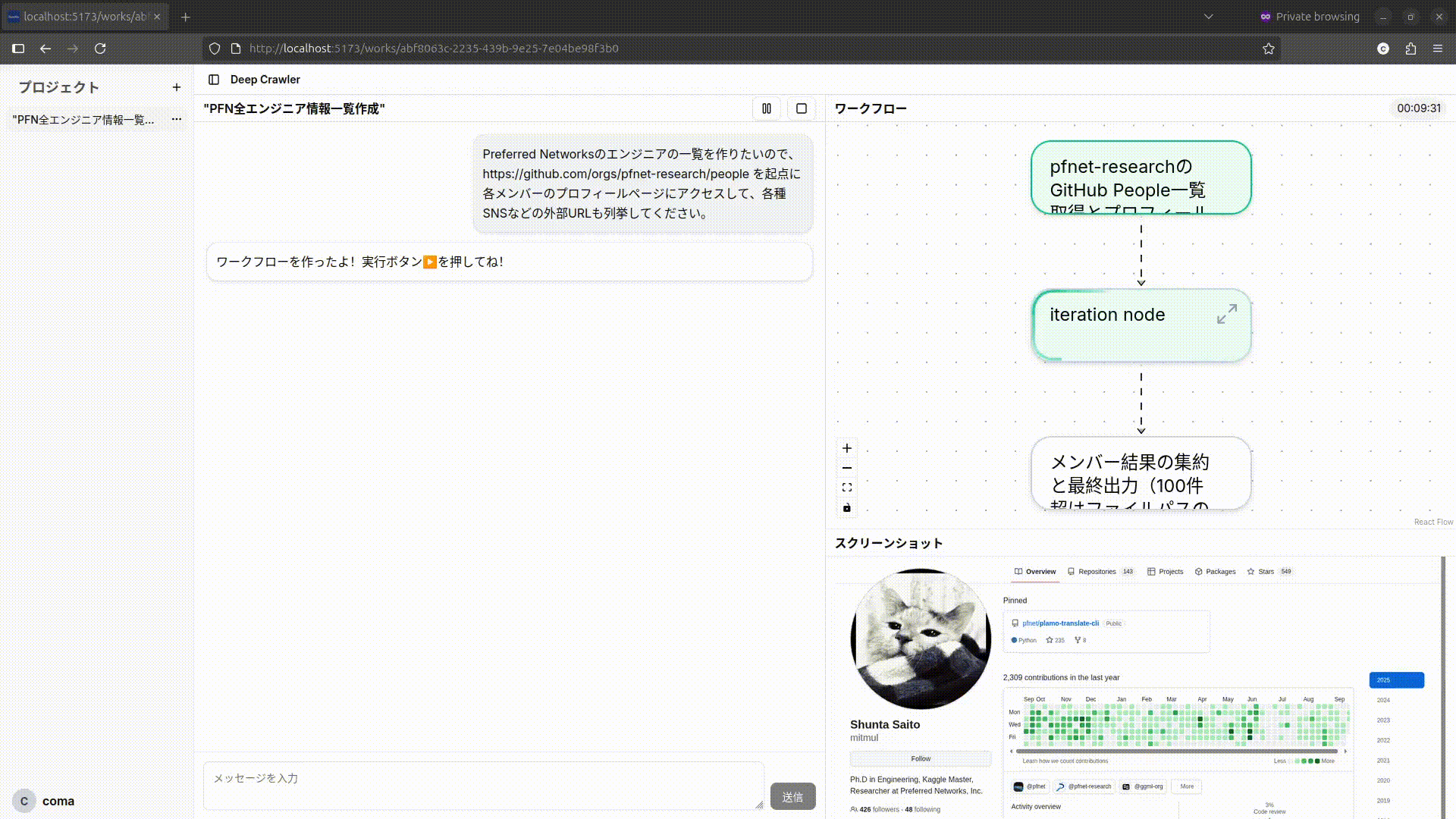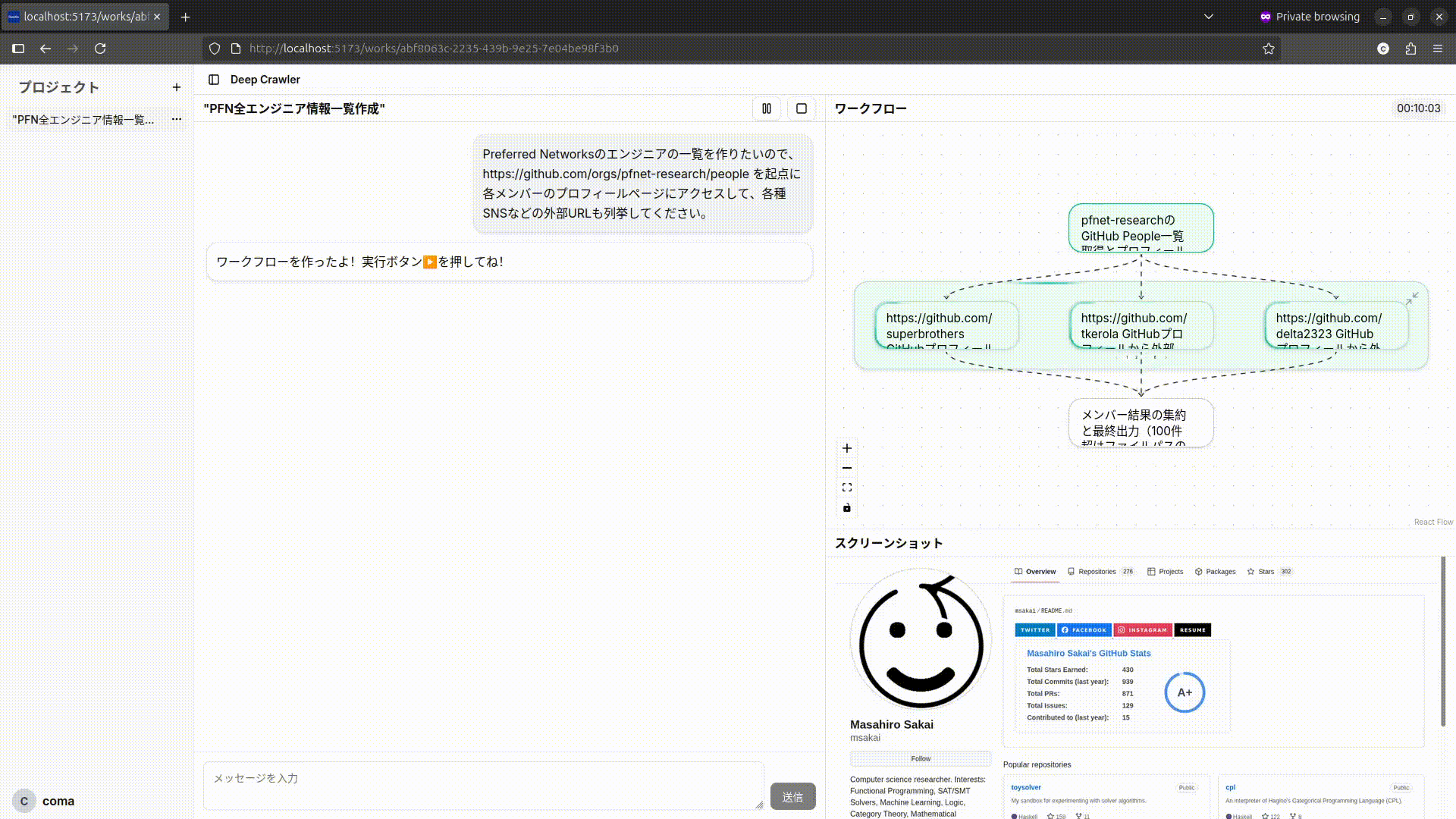
本アプリケーションの機能を紹介します。
- チャットの送信によるプロンプトの実行
- ワークフローの実行状態の表示
- 閲覧中のウェブページのスクリーンショットの表示
- 実行中のワークフローの停止、再開
- 実行時間とAPI使用コストの表示
- 参考にしたURLの一覧表示
- 与えられた情報が不十分な場合やWeb Agentの挙動がループしている場合のユーザーへの問い合わせ
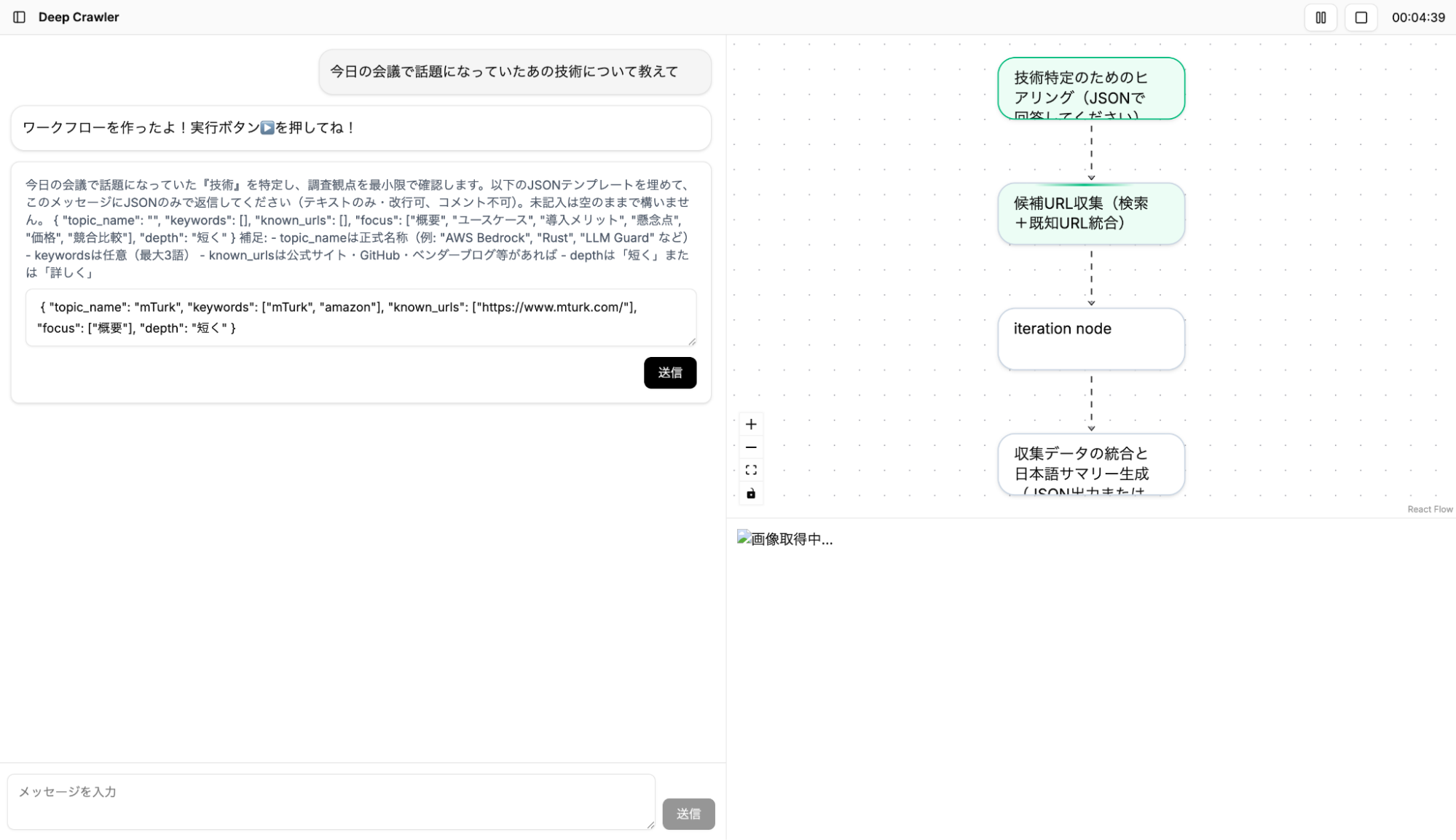
ワークフローではPlannerが実行時に得た情報に基づいて並列処理に分岐させたり、再帰的にさらにワークフローを作成するため、各ノード(実行単位)が再帰的に複数のWorkflowを内包します。それに応じて、UIでも各ノードをクリックすることで再帰的にノードに内包されたワークフローを展開して表示されます。また、分岐が多い場合はノード内でページネーションで表示し、それぞれの実行が終了しているかどうかを確認できます。
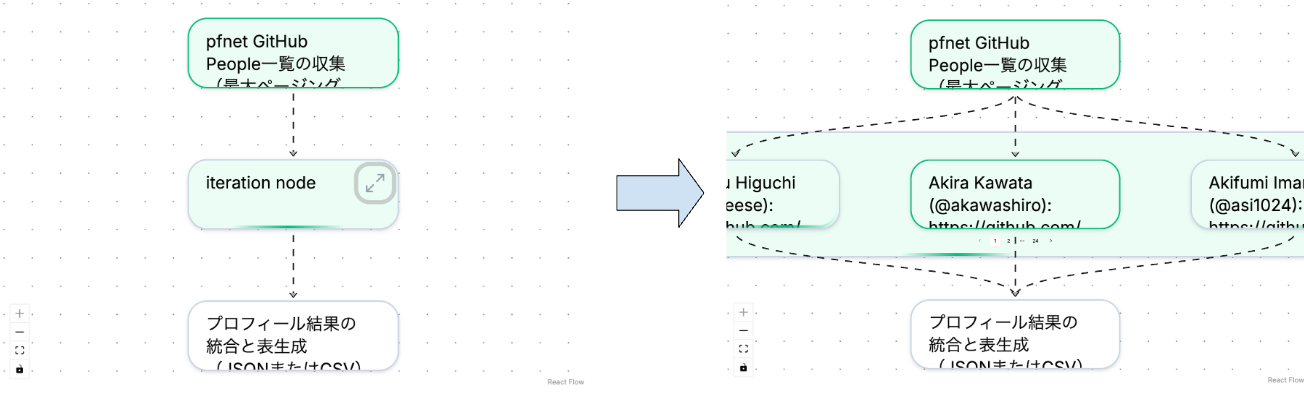
ワークフローが展開される様子
チャット、ワークフロー、スクリーンショットなどの各要素はリアルタイムでバックエンドと状態を同期する必要があります。これらすべてをポーリングで同期させるとリクエスト数が多くなってしまうので、バックエンドからストリームでイベントを通知することでリクエスト数を減らしながらリアルタイム性を実現しています。
Web Backend
Web BackendはUIからのリクエストに応答し、アプリ全体を繋ぐ基盤として動作しています。今回の開発では、UIとバックエンドの開発を同時に進めたかったため、デザインファーストで開発を行いました。まずOpenAPI.yamlでAPI仕様を定義し、そこから型を生成、その型をもとにUIとバックエンドのコードを書くことで、仕様のズレを防ぎつつ効率的に開発を進めることができました。
バックエンドの主な役割は以下のようになっています:
1. リクエストの処理と状態管理
- UIからのリクエストに対する適切な処理結果の返答
- アプリ全体の状態を管理、各コンポーネント間の連携力向上
2. データベース・S3とのやりとり
- スクリーンショットや収集データなどの大容量ファイルはS3に格納
3. Planner・Proxyとの連携
- gRPCのストリームを通じてPlannerやProxyと通信しワークフローの実行状況やコスト計測イベントを購読
ユーザーへの問い合わせ
Web Backendではユーザーに質問をするためのgRPCサーバーも用意されています。通常はWeb Agentが情報収集を行いますが、ページの構造が特殊でうまく処理できない場合や、Web Agentがループに入ってしまった場合には、ユーザーに直接問い合わせる仕組みを備えています。この設計により、完全自動化と人間による補完を両立し、実運用での信頼性を高めています。
Planner
Plannerでは、まずユーザーから入力された指示文をLLMを用いて構文木の形のJSONに変換し、それに基づいてWorkerにジョブをディスパッチしています。ジョブはWorker呼び出し、直列実行、並列実行、プランナーの再帰呼び出しの4種類あり、直列実行の各ステップと並列実行の並列処理部分はそれぞれ再帰的にジョブとして表現しています。各ジョブはバックエンドから一時停止と再開をすることができ、一時停止時に終了済みのジョブはキャッシュされて再開時に前回の進捗を引き継ぐことができます。
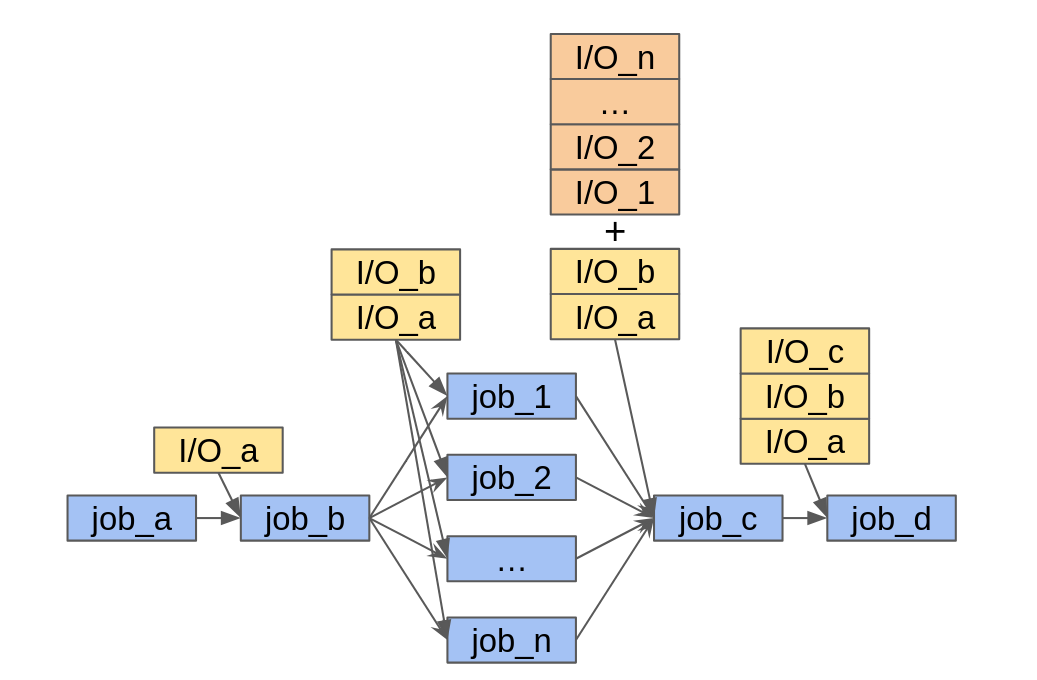
直列ノードと並列ノードで表現できるワークフローの例また、Plannerの再帰呼び出しノードによって、状態の更新とサンプリングを繰り返すエージェントと同じ挙動を表現することができます。
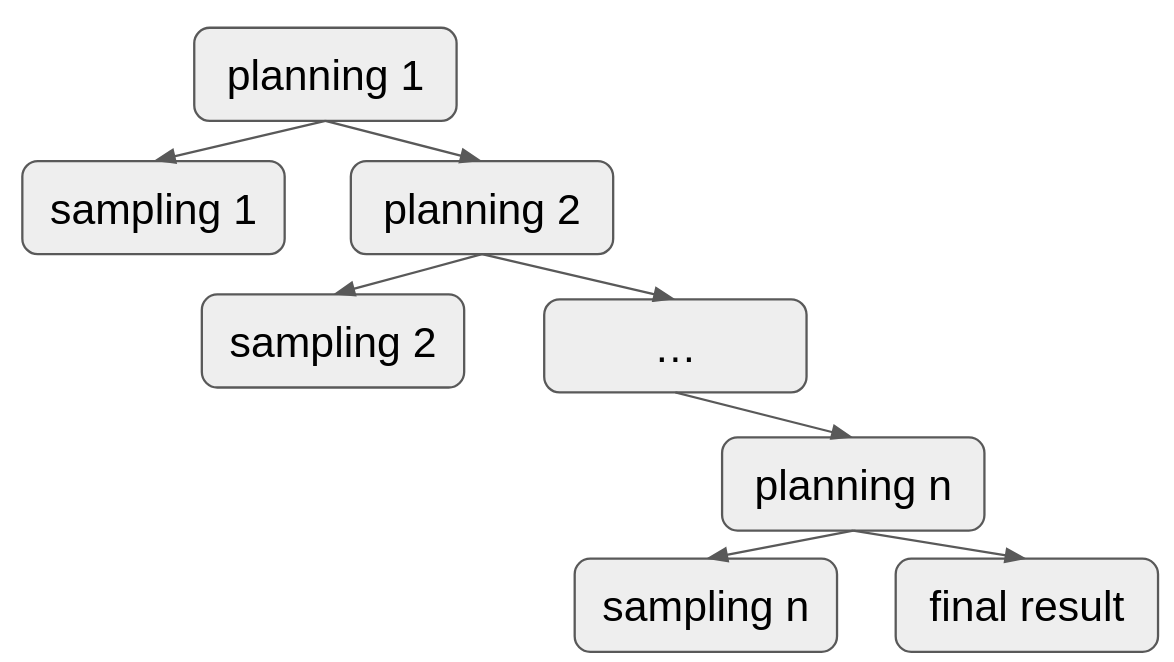
再帰的なPlannerノードの呼び出しによってループを表現する構文木の例
Throttler
Throttlerは、Plannerが送信したジョブを一度受信してキューに積み、利用可能なWorkerにキューに積まれたジョブを送信しています。
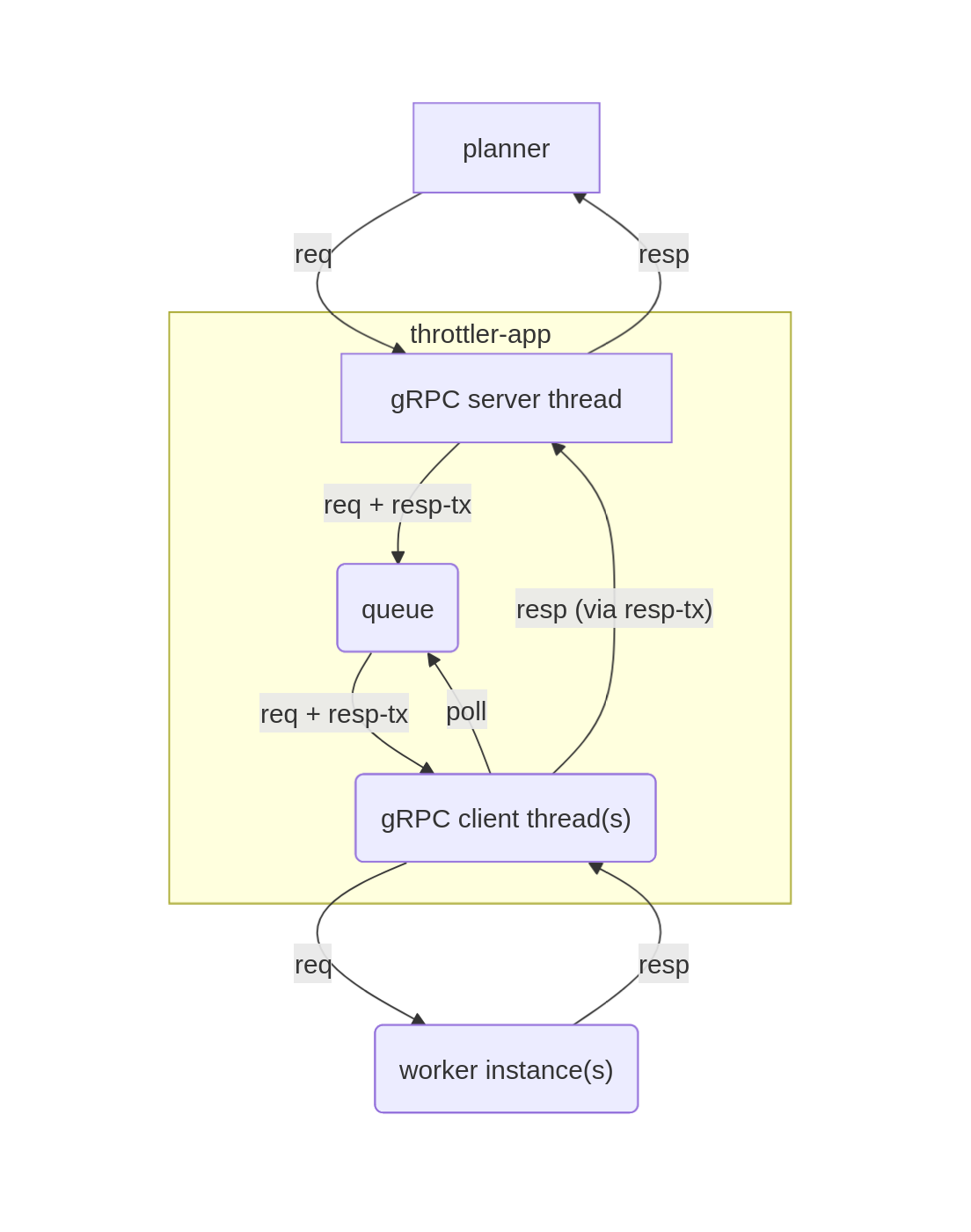
Worker
Workerでは、Plannnerが分割したジョブの指示に従って、Web AgentがBrowserで情報収集を行います。
Web Agentでは下記のような流れで、情報収集を行っています。
BrowserからPageを開き、Webサイトにアクセスを行い、各アクションをLLMが指示することで、ブラウザを操作します。この操作の中で、適切なタイミングで構造化データを抽出し、Web上のデータを収集します。
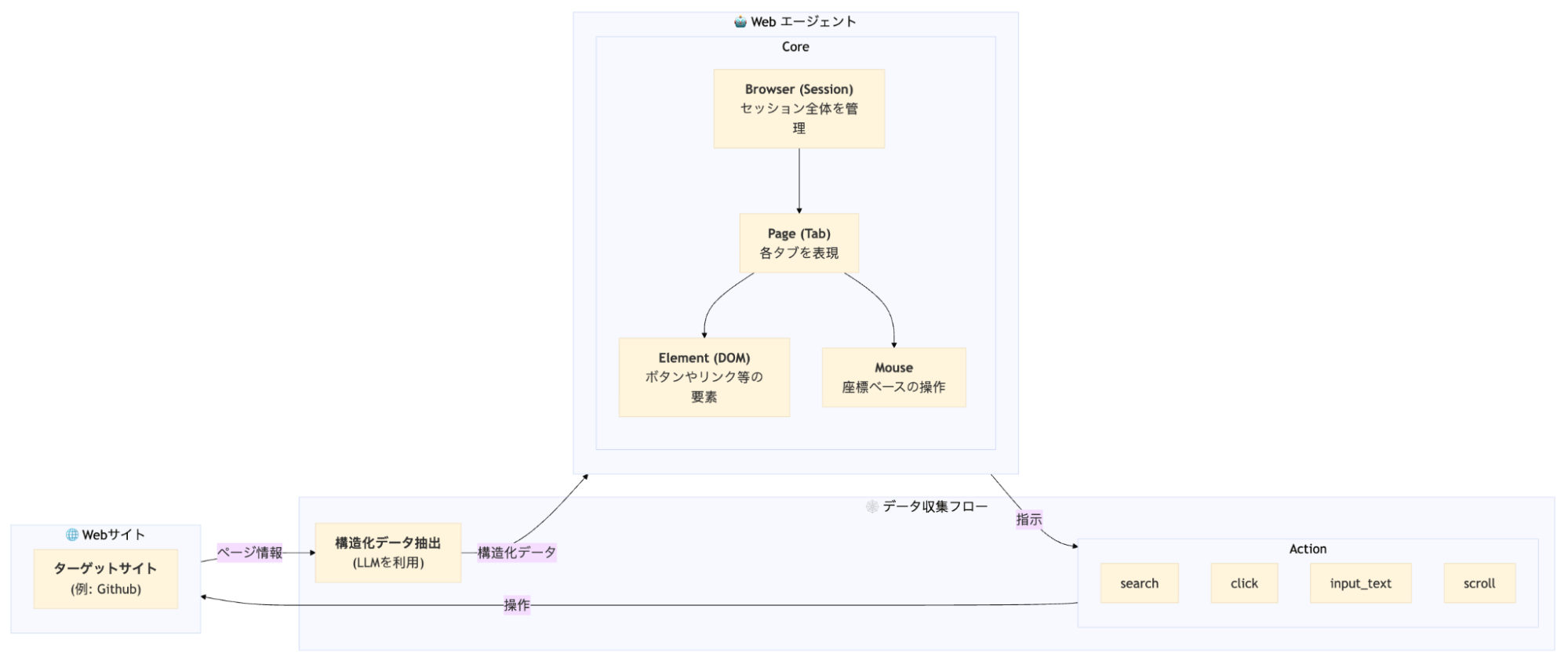
また、今回は各Workerで集めた結果を統合するために、Code Agentを実行するCode Agent Workerを作成し、Workerで並列にJobを実行した結果を統合することができます。
Proxy
Proxyでは、Worker側に秘匿情報を隠蔽して、LLMへAPIリクエストを送るために、仮のAPIキーを発行し、仮のAPIキーのリクエストがきた場合、本物のAPIキーに書き換えるというリバースプロキシになります。さらに、LLMのコストをワークフロー単位で計測し、gRPCストリームでバックエンドに送信します。
検証結果
「Deep Crawler」で「PFN社員のgithubの情報」が収集できるか検証しました。これらの収集は調査日時点ではChatGPTやGeminiのDeep Researchを使っても過不足なく収集できない情報でした。
PFN社員のGitHubの情報
71人のメンバーが公開されているGitHubのpfnetオーガニゼーションについて、「Preferred Networksのエンジニア一覧を作りたい。https://github.com/orgs/pfnet/people を起点に個別ページにもアクセスし、XやLinkedInなどの外部URLも列挙して表を作ってください。」というプロンプトで、公開されているメンバー71人分の情報を取得することができました。
同じタスクをChatGPT Deep Researchで実施したところ69人を取得(何人かの欠落が発生)、Gemini Deep Researchでは30人を取得(ページネーションを処理せず)できるのと比較すれば、確実に取得できることがわかりました。
また、人間と比べてコストとしてはどうか?の比較も実施してみました。16人のメンバーが公開されているpfnet-researchについて人間による作業とのコスト比較を行った結果、Deep CrawlerのAPI使用料が4.29ドル(150円/ドル換算で643円)、人間のコピペによる手作業の場合の作業時間は6分44秒(時給1200円換算で135円)となり、人間に対してコスト面での優位性は現状ではありませんでした。
コスト面についてはさらなる改善が求められる一方で、これには「タスクをどのように実施するか?」のプランニングの部分などは含まれていません。アウトプットのクオリティは高く、人間がタスクを行う場合はコンテキストスイッチの負荷などもあるので、人間に比べて約4〜5倍程度のコストで実施できるということには相応のメリットもあるのではないかと考えられます。

今後の課題
今回のアプリケーションでは、既存の課題を一部解決することができましたが、本当に実現したいことには届きませんでした。特に、
- 実行時間
内部のモデルはGPT-5を使用しましたが、一回あたりのリクエストが長く、データ収集に本来の想定よりも数倍時間がかかってしまうケースが多々ありました。
- 情報収集の精度
Web Agentの精度とLLMのランダム性により、なかなか取れないデータや、一度取れたデータを取得する再現性が低いという問題が残りました。
- 保存形式の指定
今回はアプリケーション内でJSONを共通フォーマットにしており、対応する出力はJSONのみでした。実際の応用では、CSVやエクセル形式などで出力するユースケースも考えられるため、拡張できると使用範囲が広がります。
- コスト面の改善
Browser Useは指示の他画面スクリーンショットをLLMに入力するため、多くのトークンコストが掛かることが知られています。そのため、実際に収集するデータに基づいてプロンプトを最適化する余地が大きいと考えられます。
感想
青木
テーマを聞いた時、短期間で実装するのは大変なアプリケーションだと思いましたが、なんとか動かせるものを作ることができました。個人的には納得できるアプリケーションはできず悔しいですが、Web Agentの課題とアプローチについて深く知ることができたので、良いインターンとなりました。
大橋
今回のインターンでは、Backend APIをゼロから設計・実装するという初めての体験を通じて、多くのことを学べました。扱う技術領域が広かった分、キャッチアップの大変さと面白さを同時に感じました。また、プロダクトとして動かすまでのハードルや、実運用に耐えうるためのプロセスの考え方に触れられたのも大きな経験でした。
開発以外でも、PFN Dayなどの交流イベントを通じて、社内の雰囲気や、PFNが扱う技術領域の広さ・深さを知り、また同期インターン生からも多くの刺激を受けました。新しいことの出会いと学びしかないインターンだったと思います。
芝
設計から実装までゼロから大きなアプリケーションを作るのは初めての経験でした。また、ここ数年でLLMは急速に進化していますが、それをエージェントとして思い通りに動かす難しさを実感しました。チームで開発を進める中で新しい技術や考えに触れる機会が多くあり、学びの多い時間となりました。
松浪
最初は挙動のイメージがつかなかったものの、チームで話をしながらなんとか動かすところまでこぎつけることができました。処理が分岐するエージェントという面白い部分を担当させていただいたほか、これまで馴染みのなかったQAやデモの考え方に触れることができ、いい経験になったと思います。
メンターからのコメント
メンターを務めた秋田です。
今回のグループ開発では、LLMによるスクレイピングをテーマに置きました。メンターからはどのようなプロンプトが通ると良いかというゴールを示すのに留め、実現の手法、実装の方針など具体的な部分がタスクとなりました。
本記事にもあるように、アプリケーション全体の開発に取り組んでいただき、七週間という限られたスケジュールで実際にデータ収集が可能なサービスが開発できたことは良かったと感じています。グループ開発特有の難しさがあったと思いますが、この経験が今後の成長やキャリアに役立つ学びとなれば幸いです。
また、インターンの取り組みという形ではありましたが、本プログラムが社内の雰囲気を掴んでいただく一助にもなっていたかと思います。
PFNではアプリケーションの開発者の採用も行っております。