Blog
本記事は、2021年度PFN夏季インターンシップで勤務した平川雅人さんと畠山智之さんによる寄稿です。
はじめに
2021年度PFN夏季インターン生の平川雅人と畠山智之です。
今回のインターンでは、表形式データに対して様々な深層学習モデルを試すことができるライブラリを共同で開発しました。開発したライブラリは https://github.com/pfnet-research/deep-table で公開しています。
背景
近年、深層学習は画像や自然言語、音声の分野で目覚ましい成功を収めてきました。しかし表形式データに対しては、深層学習はそのような成功を遂げることは少なく、いまだにXGBoostやLightGBMのような決定木ベースのモデルが主流となっています。
深層学習の有望な手法として、決定木のアンサンブルを模倣して勾配ベースの学習を可能にしたNODE [1] や、スパースなattention機構により決定木のような特徴選択を行うTabNet [2] 等が提案されており、論文内での比較では決定木ベースのモデルを上回る性能と報告されています。しかし [3] ではそれらの深層学習モデルは、モデルを提案した論文内で使用されていないデータセットに対しては、決定木ベースのモデルの性能を上回れていないと報告しています。また [4] では表形式データに対する普遍的に優れたモデルはなく、データ依存による部分が大きいことを複数の性質のデータセットによる実験で明らかにしています。
以上のことから、現在は表形式データに対するデファクトスタンダードとなる深層学習モデルは存在せず、表形式のタスクを解く際には複数のモデルを試す必要があることがわかります。
既存ライブラリでの問題点
表形式データに対する深層学習モデルを扱っているライブラリとしては、次のようなものがあります。
このような既存ライブラリの問題点として、(i) 自己教師あり学習が実装されていない、(ii) 単一のモデルを扱うラッパーとして機能しており、複数のモデルのアーキテクチャを組み合わせて実行することができない、といったことがあげられます。
そこで今回は、複数のモデルアーキテクチャや自己教師あり学習の手法を柔軟に組み合わせて実験できるライブラリを開発しました。
表形式データに対する自己教師あり学習
自己教師あり学習とは、教師ラベルを必要としない表現学習の手法で、自然言語処理におけるMLM (Masked Language Model) [5] 等が知られています。
表形式データで学習を行う際に困難な点として、複数の論文で述べられていることを考慮すると、次の3つがあげられます。
- 特徴量同士の交互作用をどのように学習するか?
- 連続変数やカテゴリカル変数といった性質の異なる特徴量から、どのように表現を獲得するか?
- 画像や言語と比べて比較的小さいデータセットから、どのように効率的に学習するか?
このような問題をモデルのアーキテクチャ以外の観点からも解決する手段として、近年自己教師あり学習の枠組みが表形式データにも取り入れられています。
2017年にKaggleで開催されたPorto Seguro’s Safe Driver Predictionというコンペティションでは、表内のセルをランダムに入れ替えるswap noiseを与えたデータから、元のデータを復元するDenoising Auto Encoder (DAE) を採用した解法が1位を獲得しています。前述のTabNetでは、ランダムに入力の特徴量をマスクし、マスクされた部分を再構築する事前学習手法が提案されています。
これらの手法は、表形式データのカラム同士はそれぞれ相関し合っていて、表内のセルの値は周りの情報を参考にして推論することができるという仮説に基づいており、学習を通してモデルがカラム間の関係を学習することを期待しています。
設計 & 実装
全体の構造
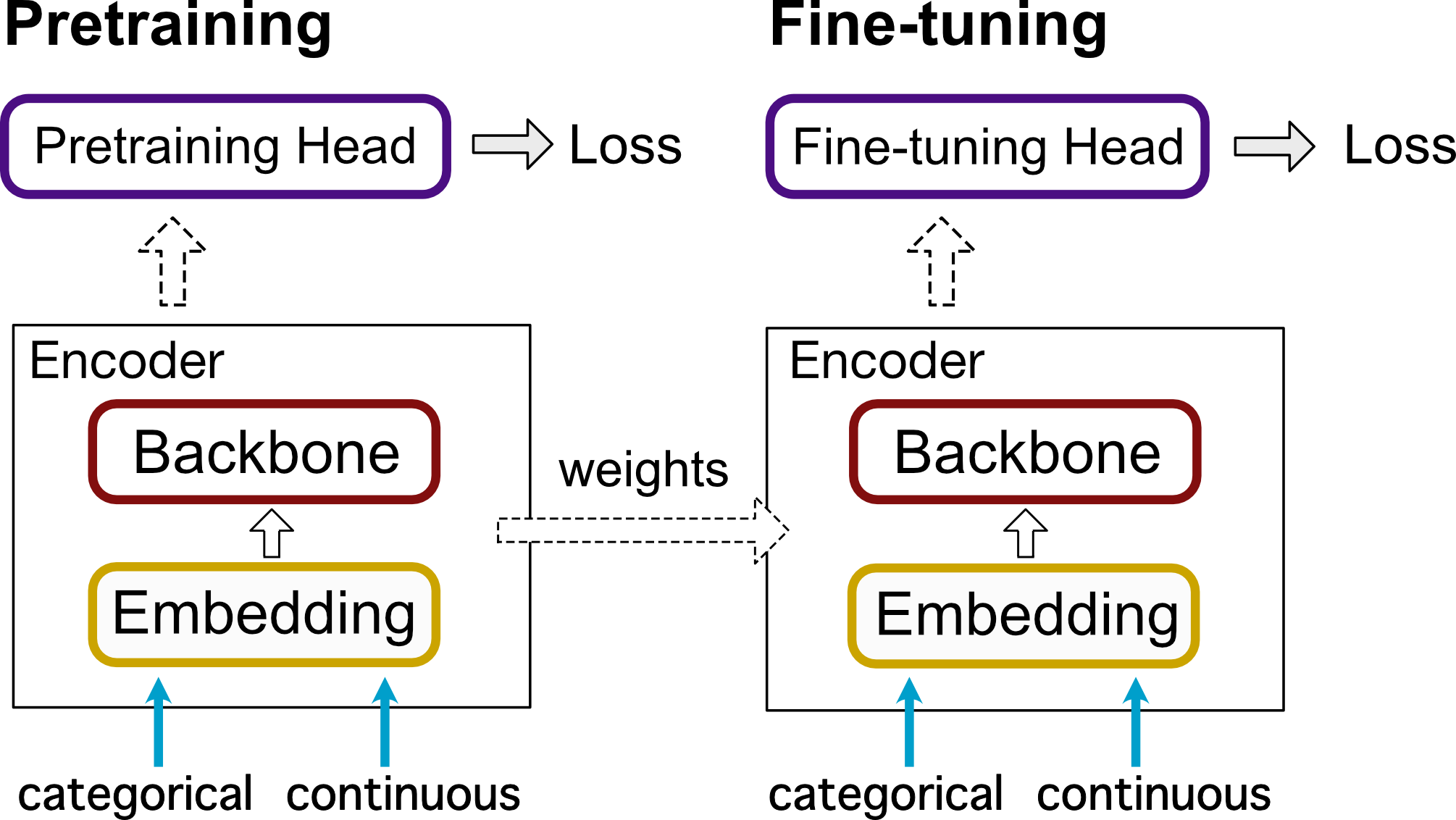
図1: 実験のフロー図。Pretraining、fine-tuning間でEncoderの重みを共有したうえでfine-tuningを実行できる。
図1に今回のライブラリの構造を示します。このライブラリで実装される手法は、3つのパーツに分解されるという前提で実装されます。
- Embedding: テーブルデータに含まれる連続値とカテゴリ値をembeddingするパーツです。
- Backbone: embeddingした後の表現が通るパーツです。Transformer-baseのモデルやMLPが実装されています。
- Pretraining: Encoderを自由に用いて最終的なLossを求める部分です。特徴量に対しnoiseをかけるDenoising Auto Encoderなどが実装されています。
EmbeddingとBackboneを合わせてEncoderと呼びます。また、事前学習が終わった後に、Pretrainの部分をMLP headに置き換えてfine-tuningを行うことができます。
API
このライブラリではシンプルなAPIを提供していて、scikit-learnのようにfit, predictを用いて学習・予測を行うことができます。また、fitするとき、from_pretrainedという引数にそのインスタンスを渡すことで、Encoderの重みを共有しfine-tuneを実行することができます。
pretrainer = Estimator( encoder_config, # Encoder architecture trainer_config, # training settings (epoch, gpu...) pretrainer_config, # Pretrain settings (learning rate, scheduler...) ) pretrainer.fit(datamodule) estimator = Estimator(encoder_config, trainer_config, estimator_config) estimator.fit(datamodule, from_pretrained=pretrainer) predict = estimator.predict(test_dataloader)
実装した機能
- Embedding(2種類):
- FeatureEmbedding [4], TabTransformerEmbedding [6]: FeatureEmbeddingは連続値/カテゴリ値どちらもembeddingするのに対し、TabTransformerEmbeddingはカテゴリ値のみembeddingを行うという違いがあります。
- Backbone(3種類):
- FT-Transformer [4], SAINT [7], MLP
- Pretrain(4種類):
- TabTransformer [6], SAINT [7], Denoising Auto Encoder [8], VIME [9]
Embedding、 BackbonePretrainは自由に組み合わせられるため、ひとつのデータセットに対して、(Embedding手法)x(Backbone手法)x(Pretrain手法)のアーキテクチャが使用できます。「Pretrainしない」というパターンも含めて考えると、現時点では30 (=2×3×5) 種類のアーキテクチャを試すことができます。
実験
設定
表1に、使用した3つのデータセットの詳細を示します。今回は時間の関係上、それぞれのデータセットについて20種類のアーキテクチャで予測精度検証を行いました。optunaを用いてハイパーパラメータのチューニングを行い、validationデータに対してcross entropyが最も低くなるように調整しました。
表1. 使用したデータセットの詳細
| Adult [10] | Higgs [11] | Forest [12] | |
| train/valid/test | 26,000/6,500/16,300 | 150,000/37,500/62,500 | 12,100/3,000/565,900 |
| 特徴量(連続値/カテゴリ値) | 6/8 | 30/0 | 10/44 |
| タスク | binary classification | binary classification | multi-class classification |
結果
表2に今回の実験結果を示します。二値分類のタスク(Adult・Higgs)についてはAUC、マルチクラスの分類タスク(ForestCoverType)についてはaccuracyを示しています。
表2. 実験結果
| モデル | データ | ||||
| backbone | embedding | 事前学習 | Adult | Higgs | Forest |
| MLP | FeatureEmbedding | なし | 0.9119 | 0.9071 | 0.7420 |
| SAINT | 0.9111 | 0.9070 | 0.7570 | ||
| TabTransformer | 0.9096 | 0.9064 | 0.7439 | ||
| DAE | 0.9114 | 0.9074 | 0.7316 | ||
| VIME | 0.9070 | 0.9061 | 0.7575 | ||
| SAINT | FeatureEmbedding | なし | 0.9130 | 0.9062 | 0.6809 |
| SAINT | 0.9126 | 0.9057 | 0.7072 | ||
| TabTransformer | 0.9137 | 0.9062 | 0.7312 | ||
| DAE | 0.9127 | 0.9063 | 0.6037 | ||
| VIME | 0.9127 | 0.9067 | 0.7126 | ||
| FT-Transformer | FeatureEmbedding | なし | 0.9135 | 0.9080 | 0.7301 |
| SAINT | 0.9138 | 0.9082 | 0.7453 | ||
| TabTransformer | 0.9134 | 0.9087 | 0.7306 | ||
| DAE | 0.9150 | 0.9081 | 0.6923 | ||
| VIME | 0.9155 | 0.9066 | 0.7420 | ||
| TabTransformerEmbedding | なし | 0.9071 | 0.9004 | 0.6751 | |
| SAINT | 0.9063 | N/A | 0.6797 | ||
| TabTransformer | 0.9064 | N/A | 0.6882 | ||
| DAE | 0.9068 | N/A | 0.6836 | ||
| VIME | 0.9079 | N/A | 0.6691 | ||
| XGBoost | 0.9247 | 0.9075 | 0.7298 | ||
ここで、Higgsは連続値のみで構成されているデータセットであり、カテゴリ値のみをembeddingするTabTransformerEmbeddingで事前学習を行うことができないため、実験できないアーキテクチャが複数存在します。
実験結果から次の傾向を読み取ることができます
- MLP Backboneはシンプルであるが非常に良い結果を出す
- 連続値のembeddingの重要性
FT-Transformer Backboneの結果を見ると、連続値/カテゴリ値をembeddingしたときより、カテゴリ値のみembeddingしたときのほうが評価値が下がっています。このことから、カテゴリ値だけでなく連続値もembeddingするほうが良いということがわかります。
- 事前学習は常に効果的とは限らない
- 多くのコラム数をもつデータ(Higgs, Forest)については事前学習が良い効果をもつ
Ensemble
実験結果より、ForestCoverTypeについてはDNNがXGBoostより良い結果が出せることが分かりました。ここで、実際のデータ解析時に用いられる、予測精度の向上のため複数のモデルの結果を集約するensembleという手法についても実験を行いました。
DNNとXGBoostの予測結果を集約し、予測を行います。validation dataに対してcross entropyを最小化するような割合を求め、その割合をそのまま用いてtest dataに対する予測を行いました。ForestCoverTypeデータセットについて、一部のモデルに対してensembleを実行したときの結果を示します(表3)。結果より、ForestCoverTypeについては、ensembleを行うことでほとんどのモデルで精度が大きく向上していることがわかります。しかし、AdultやHiggsについて行ったensembleの実験では、精度の大きな向上は見られませんでした。これは、それらのデータセットに対してDNNの予測がXGBoostのものよりも精度が低いためと考えられます。
表3: ForestCoverTypeデータセットに対してensembleを行ったときの結果
| Backbone | Embedding | Pretrain | Accuracy | Ensemble Accuracy |
| MLP | FeatureEmbedding | NoPretrain | 0.7420 | 0.7489 |
| SAINT | 0.7570 | 0.7488 | ||
| TabTransformer | 0.7439 | 0.7588 | ||
| Denoising | 0.7316 | 0.7534 | ||
| VIME | 0.7575 | 0.7559 | ||
| FT-Transformer | FeatureEmbedding | NoPretrain | 0.7301 | 0.7478 |
| SAINT | 0.7453 | 0.7470 | ||
| TabTransformer | 0.7306 | 0.7458 | ||
| Denoising | 0.6923 | 0.7307 | ||
| VIME | 0.7420 | 0.7491 |
ラベルありデータが限られる状況での実験
自己教師あり学習は教師ラベルを必要としないため、ラベルありデータは少ないがラベルなしデータが大量に存在しているような状況で有効に働くことが考えられます。そこで今回は検証として、ラベルありデータの一部をラベルなしデータとみなし、擬似的にラベルありデータが限られている状況を再現して実験を行いました。同じモデル、パラメータで事前学習をした場合としていない場合の比較を行っています。
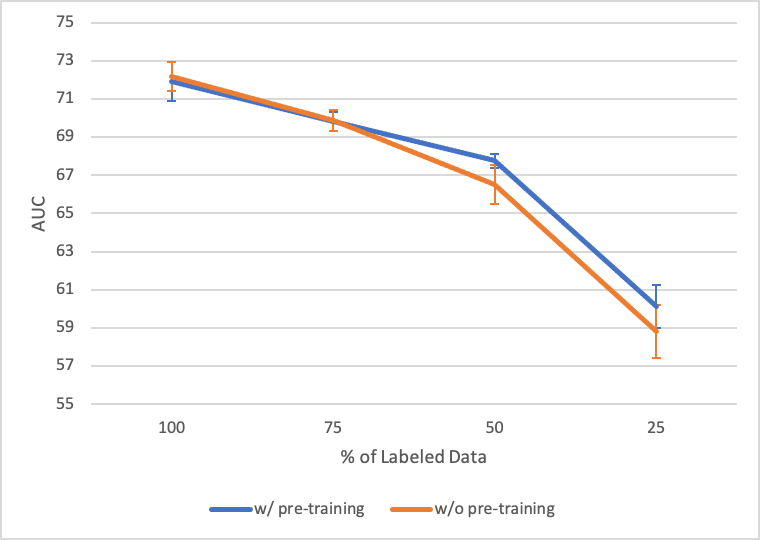
図2. 教師あり学習に使用したラベルありデータの割合とAUCの推移 (Adultデータセット)
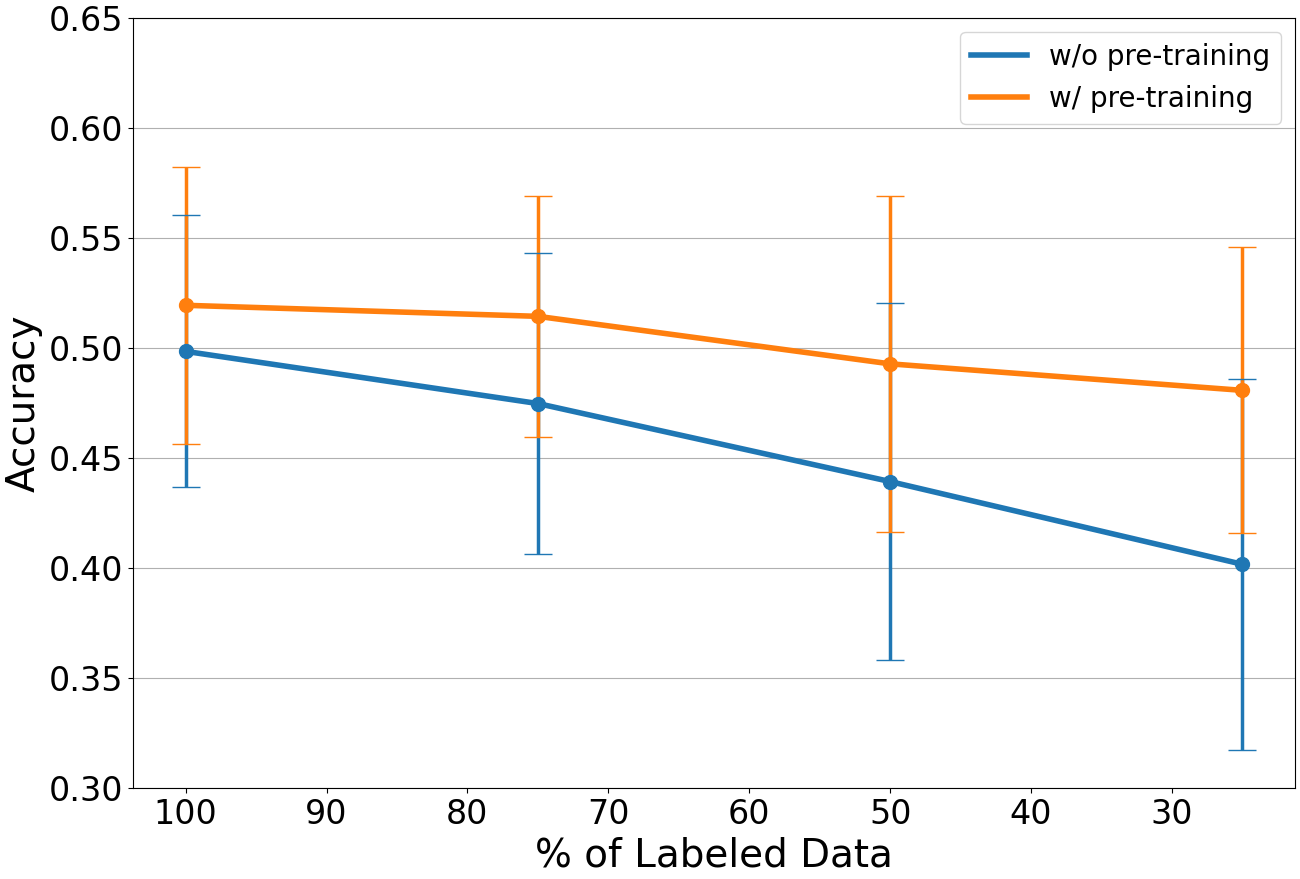
図3. 教師あり学習に使用したラベルありデータの割合とAccuracyの推移 (ForestCoverTypeデータセット)
図2にAdultデータセットでシードを変えて5回実験したときの結果、図3にForestCoverTypeデータセットでシードを変えて100回実験したときの結果を示します。結果として、事前学習時に全データを活用することができるため、事前学習ありの方がラベルありデータが少なくなった場合も性能が落ちにくくなっています。しかし差分としては小さく、大きな改善とは言えません。これはVIME [9] での実験でも同じ結果になっており、論文内では半教師あり学習も同時に行うことで大きく性能を改善しています。
したがって、ラベルありデータが限られる場合に自己教師あり学習は有効ではあるものの、大きく性能を改善するには、半教師あり学習も行う必要があることがわかりました。
終わりに
本インターンシップでは、インターン生の平川さんとともに、テーブルデータに対する深層学習ライブラリを新しく開発し、そのライブラリを用いて網羅的に実験を行いました。約一ヶ月半という短い期間でのインターンシップでしたが、社員の方々のサポートのおかげで充実したインターンシップ生活を送ることができました。特に、メンターの鈴木さん、副メンターの大野さん、Gaoさん、そして、平川さんには期間中大変お世話になりました。ありがとうございました。
畠山
今年もリモートでの開催で、例年よりも短い期間であったものの、非常に充実したインターン期間を過ごすことができたのは多くの社員の方々のご協力のおかげです。特にメンターの大野さん、Gaoさん、鈴木さんには毎日のデイリーMTGで的確なフィードバックをいただき、スムーズに開発を進めることができました。そして共同で開発を行った畠山さんとは設計の段階から綿密に議論をし、実験も分担して行うことで膨大な量の設定を検証することができました。誠にありがとうございました。インターン期間中お世話になった全ての方に心より感謝を申し上げます。
平川
参考文献
[1] S. Popov, S. Morozov and A. Babenko, “Neural Oblivious Decision Ensembles for Deep Learning on Tabular Data,” International Conference on Learning Representations (ICLR), 2020.
[2] S. O. Arik and T. Pfister, “TabNet: Attentive Interpretable Tabular Learning,” AAAI, vol. 35, no. 8, pp. 6679-6687, 2021.
[3] R. Shwartz-Ziv and A. Armon, “Tabular Data: Deep Learning is Not All You Need,” ArXiv: 2106.03253 [cs.LG], 2021.
[4] Y. Gorishniy, I. Rubachev, V. Khrulkov and Artem Babenko, “Revisiting Deep Learning Models for Tabular Data,” ArXiv: 2106.11959 [cs.LG], 2021
[5] J. Devlin, M. Chang, K. Lee and K. Toutanova, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” Association for Computational Linguistics (ACL), 2019.
[6] X. Huang and A. Khetan, M. Cvitkovic and Z. Karnin, “TabTransformer: Tabular Data Modeling Using Contextual Embeddings,” ArXiv: 2012.06678 [cs.LG], 2020.
[7] G. Somepalli, M. Goldblum, A. Schwarzschild, C. B. Bruss and T. Goldstein, “SAINT: Improved Neural Networks for Tabular Data via Row Attention and Contrastive Pre-Training,” ArXiv:2106.01342 [cs.LG], 2021.
[8] 1st place – turn your data into DAEta | Kaggle, https://www.kaggle.com/springmanndaniel/1st-place-turn-your-data-into-daeta
[9] R. Houthooft, X. Chen, Y. Duan, J. Schulman, F. De Turck and P. Abbeel, ”VIME: Variational Information Maximizing Exploration,” Advances in Neural Information Processing Systems 29 (NeurIPS 2016), vol. 29, pp. 1109-1117, 2016.
[10] UCI Machine Learning Repository: Adult Data Set, https://archive.ics.uci.edu/ml/datasets/adult
[11] Higgs Boson Machine Learning Challenge | Kaggle, https://www.kaggle.com/c/higgs-boson
[12] Forest Cover Type Prediction | Kaggle, https://www.kaggle.com/c/forest-cover-type-prediction



