Blog
本記事は、2021年インターンシッププログラムで勤務された熊野創一郞さんによる寄稿です。
はじめに
PFN2021夏期インターンに参加させて頂いた熊野創一郞と申します. 普段は東京大学大学院情報理工学系研究科で computer vision の研究をしています.
今回のインターンでは 現実の画像に似せたComputer Graphics (CG) 画像と現実の画像の間に存在する gap を 人間が解釈できる形で埋め, CG データセットでの深層学習や CG クリエイターの リアルなCG生成・tuning を手助けする手法について研究しました.
背景
データセットとコスト
近年, Deep Neural Networks (DNN) による機械学習は大きな発展を遂げ, 非常に注目されています. しかし DNN による学習は大きな問題を抱えています. 学習に必要なデータセットを作成するのに非常に多くのコストが必要となるのです. 例えば semantic segmentation というタスクでは一つのトレーニングデータを作成するために, 一枚の画像とその画像の各ピクセルがどのクラスに属するのかを表した教師データが必要です. このようなデータを10K以上作成しようとすると多くの時間とお金が必要となってしまいます.
CG データセットでの学習
この問題を解決するために提案されたのが CG 画像での学習です. CG 画像は画像内の object に関する情報を全て保持しているので, 教師データが簡単に生成できるのです. 先程の semantic segmentation の例を考えます. これまでは一つ一つのピクセルがどのクラスに属しているのかを人間が手動で割り当てる必要がありましたが, CG 画像を生成する blender などのソフトはどのピクセルにどのオブジェクトが映っているのかを完璧に知っているので, 一瞬で教師データを作成することが出来るのです. このような CG 技術を利用したデータ作成は短い時間かつ少ない費用で大規模なトレーニングデータセットを作成できるので高い関心が集められています [1, 2, 3, 4, 5].
CG データセットの抱える問題
CG 画像で学習した DNN は現実世界の画像に対して上手く汎化できない問題があります. CGと実写には乖離があり、学習に悪影響を与える可能性は過去に指摘されました [6, 7, 8]. CGのレンダリング技術の向上に伴いCG学習に使われる画像のクオリティも上がり,CGと実写の乖離も埋められるようになってきました. しかし、 CG クリエイターは現実世界のデータに CG を寄せるには大きな労力が必要とされるため、この作業の自動化が望まれています.
CG画像で学習精度を高める関連研究
CG 画像での学習に関する問題を解決する手法として以下の二つの研究を紹介させて頂きます. この他にも ImageNet で事前学習されたモデルの知識を利用する手法などがありますが, ここでは CG 画像に変更を加えるもののみに絞らさせて頂きます.
Augmentation
CG 画像を現実の画像に近づけるようにある程度確率的に変換をかけ, CG 画像に多様性を持たせ, DNN の汎化能力を上げようとする手法です [9]. 変換は例えば輝度・コントラストの調整, ノイズの付加, フィルタの適用, 露出補正などがあります. この手法は仕組みが理解しやすく, 実装もとても簡単です. また現実の画像が一枚も要らないという点も嬉しいです. しかしながらどの程度の変換をかけるのかはドメインにセンシティブな問題を持っています.
Style transformation
Generative Adversarial Networks (GAN) を用いて CG 画像を現実の画像に変換する手法です. 最も有名な例としては Cycle GAN が挙げられますが, 他にも様々な GAN を用いた style transformation 手法が提案されています [10, 11]. この手法は augmentation で挙げられたようなシンプルな変換手法に比べてより強力な変換が期待でき, また変換時に人間がレンジを設定する必要がない (トレーニング時に正則化項などを調整する必要はあります) という点が嬉しいです. しかし GAN を用いた style transformation は時として画像に含まれるオブジェクト自体を壊してしまい, 画像の意味を変えてしまいます. 例えばペットボトルを style transformation するとラベルが完全に消えてしまうことがあります.
提案法
私達は CG 画像と現実の画像の間に存在する gap を人間が理解できるような形で埋める方法を提案します.これにより, CG 画像での学習効果を高めることを期待します. この手法は以下の点で関連研究に比べて優れています.
- スタイル (テクスチャや色味など) とコンテンツ (オブジェクトの形状やオブジェクトの並び方) を完全に分離して操作することができる.
- 人間の調整を必要としない.
- 画像に含まれるオブジェクトが壊れることがない.
- CG クリエイターに gap を semantic に伝えることができる.
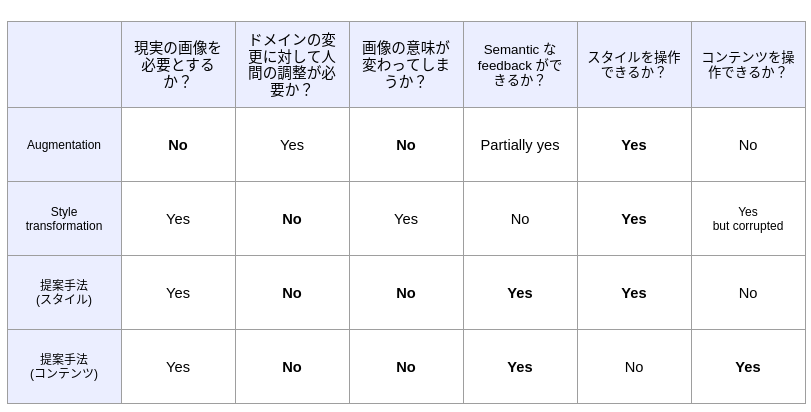
太字は positive な性質
スタイル操作
ここからは本手法のスタイル操作に関して詳しい手順と結果について紹介させて頂きます. また簡単のため以下、現実の画像をリアル画像と呼びます。
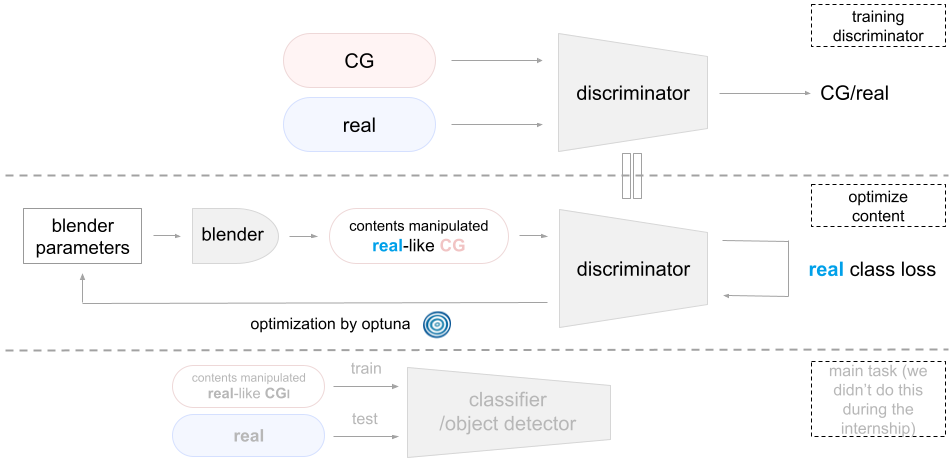
手順 (CG-to-real)
本手法では以下の手順を踏むことで CG 画像をリアル画像に近づけます. 下の画像も参照して頂けると幸いです.
- CG 画像とリアル画像を見分ける discriminator を学習する.
- Manipulation parameters を初期化する.
- 以下の操作を決められた回数だけ繰り返す.
- Manipulation parameters を用いて CG 画像を manipulation する.
- Manipulation された CG 画像を discriminator に入力し, リアル画像らしさを表す loss を取得する. ここでは単に現実クラスに対する cross entropy loss を用いている.
- bで得られた loss を下げるように backpropagation することで manipulation parameters を最適化していく.
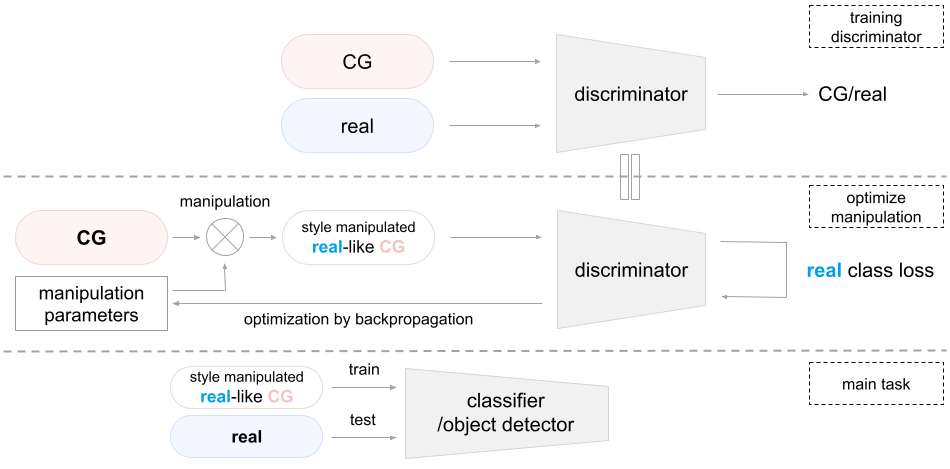
上記の手順で得られる最適化された manipulation parameters は CG 画像をどのように操作すればリアル画像とCG画像を識別するDiscriminatorを出せるようになるるのかという情報そのものです. Manipulation parameters は CG 画像とリアル画像の間の gap を CG クリエイターに明示的に伝えることができます. また操作後の画像を用いて DNN を訓練すれば操作前の画像を用いて学習するよりリアル画像に汎化しやすくなると考えられます.
手順 (real-to-CG)
上記手法は全く同じようにしてリアル画像を CG 画像風に変換することができます.
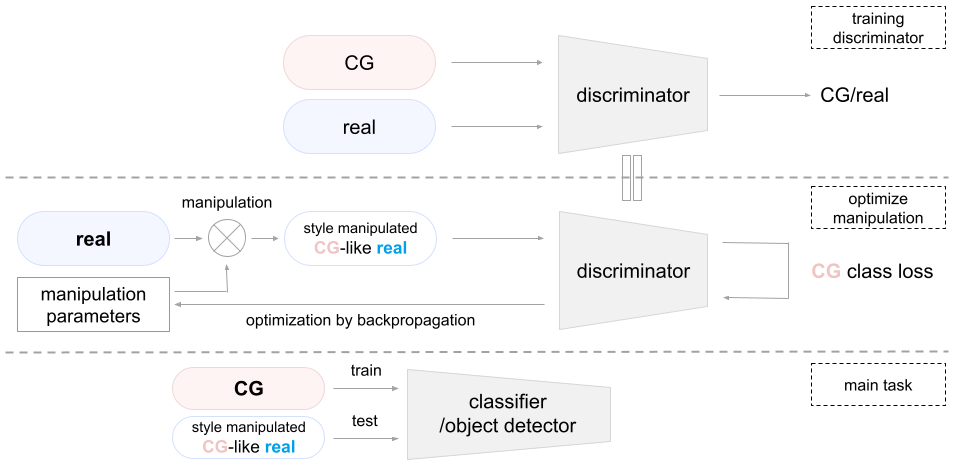
操作手法
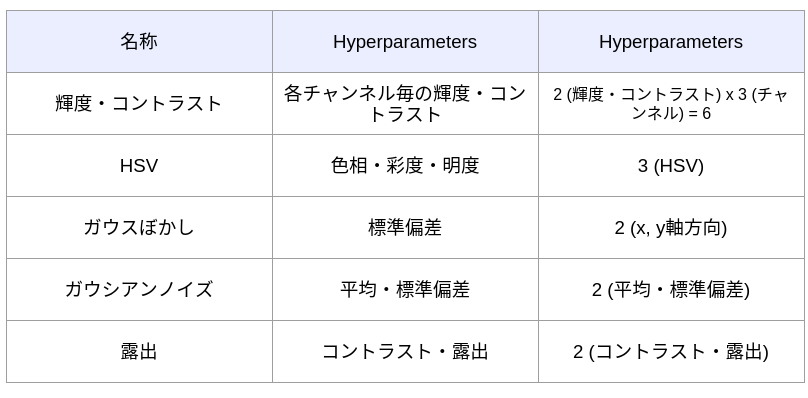
今回は以下のような manipulation について実験を行いました.
実験結果
Discriminator の訓練・評価
まず CG 画像とリアル画像を見分ける discriminator を訓練・評価します. 各設定は以下のようになっています.
- トレーニングデータセット
- CG: 20K
- リアル画像: 20K
- テストデータセット
- CG: 5K
- real: 5K
- 2 epoch
この結果, テストデータセットに対して99.7%の分類精度を出す discriminator が得られました.
操作結果
各操作の結果で得られた画像を紹介していきます. 画像の上部に書かれた succeed, failed は discriminator を騙すことが出来たかどうかを表しています. つまり操作後の CG 画像が discriminator にリアル画像と判断されたら succeed, CGと判断されたら failed となります. 今回は諸事情により CG 画像からリアル画像への変換結果しか載せていません.
輝度・コントラスト
以下のような操作を行いました. パラメーターは太字で表現されています.
manipulated image = image (R) x contrast (R) + brightness (R) + image (G) x contrast (G) + brightness (G) + image (B) x contrast (B) + brightness (B)
操作前の画像と操作後の画像は以下のようになりました.

操作された画像の多くは discriminator を騙すことに成功しましたが, 一部画像はあまりリアル画像風ではなくなってしまいました. これは discriminator を騙せた後も optimization を止めなかったため, 過度に discriminator のロスを下げようとしてしまったからだと考えられます.
実際に最適化されたパラメータがどのような分布をとるのか見ていきます. 以下のヒストグラムは1300枚程度の CG 画像を操作・最適化し, 得られたパラメータをヒストグラムにしたものです. 赤と青の成分は正負にほぼ均一なのに対して, 緑の成分は有意に負に寄っていることがわかります. これは CG 画像はリアル画像に比べて緑の成分が大きいことを示唆していると考えられます. 興味深いことに画像に対して単純に色ヒストグラムをとってもこのような結果は得られませんでした.
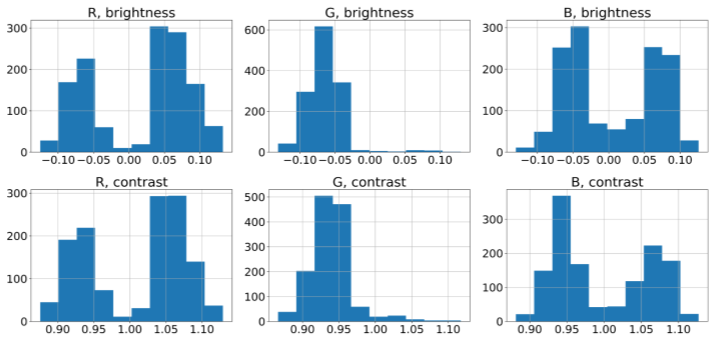
輝度・コントラスト (patch 毎)
画像を64分割し, 各 patch 毎に輝度・コントラストの変化を行いました. 操作前の画像と操作後の画像は以下のようになりました. 
操作された画像の多くは discriminator を騙すことに成功しました. また映っている商品や背景によってパッチの色が異なることがわかりました.
HSV
以下のような操作を行いました. パラメーターは太字で表現されています.
manipulated image = image (H) + ΔH +image (S) + ΔS + image (V) + ΔV
操作前の画像と操作後の画像は以下のようになりました. 
操作された画像の多くは discriminator を騙すことが出来ませんでした. 輝度・コントラストの変換で判明したように今回の CG 画像をリアル画像に変換するためには色味の変換がとても重要なものとなっています. これを色相の操作で実現しようとすると初期解から離れた色に移動する前に局所解に落ちてしまい, 中々最適な色とならないことが低い成功率に繋がったのだと考えられます.
ガウスぼかし
ガウシアンフィルターの標準偏差をハイパーパラメータとして持ちます. 操作前の画像と操作後の画像は以下のようになりました.

操作された画像の多くは discriminator を騙すことに成功しました. 一部の CG 画像にはレンダリングの過程でノイズが加わることがあり, そのようなノイズを取り除けたことでリアル画像に近付けたのではないかと考えられています.
ガウスぼかし (チャンネル毎)
各チャンネル毎に異なる標準偏差を持つようにします. 操作前の画像と操作後の画像は以下のようになりました. 
操作された画像の多くは discriminator を騙すことに成功しました. リアル画像に含まれる色収差を再現できるのではないかという意図でチャンネル毎の操作を行いましたが, 画像の細部を観察しても色収差は見られませんでした.
ガウシアンノイズ
平均値と標準偏差をパラメーターとして持ちます. 各ピクセル毎にノイズが計算され付与されます. 操作前の画像と操作後の画像は以下のようになりました. 
操作された画像の多くは discriminator を騙すことが出来ませんでした. ガウスぼかしのようなデノイズの作業が CG 画像からリアル画像への変換に必要なので, ガウシアンノイズを加える操作が上手くいかないことは納得のゆく結果だと考えられます.
露出
以下のような操作を行いました. パラメーターは太字で表現されています.
結果はf(S’)
![]()
![]()
操作前の画像と操作後の画像は以下のようになりました. 
操作された画像の多くは discriminator を騙すことが出来ませんでした. ほとんどの画像であまり変化が見られなかったので, iteration回数や最適化における学習率のスケールを大きくするなどの変更で成功率の改善が見られるかもしれません.
まとめ
各操作がどれだけ discriminator を騙せやすいかをまとめた表が以下になります. 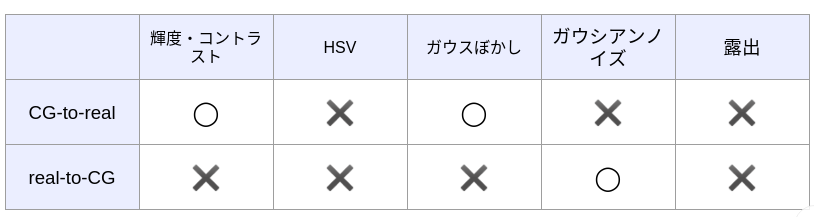
また次のような興味深い結果も得られました.
- CG-to-real ではデノイズの作業, rea-to-CG ではノイズを加える作業という対称性が見られた. これは CG に何らかのノイズに相当する成分が含まれていることを示唆している.
- 映っている商品や背景毎に色味の変換が異なる.
- CG とリアルの画像は異なる色分布を持っていると discriminator は認識している. しかしパラメーターのヒストグラムは画像自体の色ヒストグラムの傾向に一致しない.
Instance Segmentation への適用
ではこのようにしてリアル画像風に操作された CG 画像を使って DNN の汎化能力を改善できるのでしょうか. これを確かめるために私達は instance segmentation タスクを以下の三種類のデータセットに対して適用しました.
- ベースライン: 元の CG データセットを用いて DNN を学習させたもの
- Proposal 1: 提案手法を用いて元の CG データセットに輝度・コントラスト操作を行い, 新たに作られたデータセットを用いて DNN を学習させたもの
- Proposal 2: 提案手法を用いて元の CG データセットにガウスぼかし操作を行い, 新たに作られたデータセットを用いて DNN を学習させたもの
Instance segmentation の訓練・評価は以下の設定で行います.
- トレーニングデータセット (CG) : 31K
- テストデータセット (リアル) : 180
- クラス数: 1 (background / product)
また画像操作も少しだけ手法を変えました. 変更前はmanipulation parametersの勾配法による最適化を決められた反復回数だけ繰り返していました (手順3参照) が, これでは過剰な最適化が起こってしまうことが輝度・コントラスト操作の実験で判明したので, 変更後はリアルクラスの確信度が50%以上になるとその時点で最適化を停止するようにしました.
Instance segmentation の Average Precision (AP) は以下のようになりました.

残念ながら大きな精度向上は見られませんでした. なぜ精度が向上しなかったのでしょうか. これは discriminator に原因があると考えられます. Discriminator は CG 画像とリアル画像を見分けるように訓練されます. このときある一つの違いだけで両者を分類することができてしまうと, その違いだけを見るようになり, 他の違いを見なくなります. そうすると discriminator は画像操作時にその特徴だけを変えようとして, 他の特徴を操作することを放棄してしまいます. これによって一部の違いだけしか改善できず, 他の違いの多くはそのまま残ってしまい, リアル画像にあまり近付かなくなってしまったと考えることができます.
今後の課題
今回は主に PFN が用意して下さったデータセットで実験を行ったのですが, これはスタイル以外にも様々なコンテンツの違いが存在していました (これらの影響でベースラインの AP も低めの値となっています). これにより考えなければいけない要素がスタイル以外にも多く存在してしまい, 何がどのように影響しているのか中々把握し辛いという問題がありました. 今後はより統制の取れたデータセットを使うことで, 原因の把握や改善がよりスムーズに進むと考えられます.
また本手法は最適な manipulation parameters を一つのベクトルとして出力していましたが, これを確率的な幅を持たせるように出力することで一つの CG 画像に多様性を持たせて操作することができるようになり, より DNN の精度改善につながるのではないかと考えています.
さらに discriminator が一つの特徴を注視しないように, 操作された画像を新たにデータセットに加え, そのデータセットで学習した discriminator を用いて新たに操作された画像を生成し, それをまたデータセットに加えGAN のような構造を導入することでより多様な特徴を学習することができるかもしれません.
コンテンツ操作
これまではスタイル操作に関する手順や実験結果について見てきましたが, 次はコンテンツ操作について見ていきます.
手順 (CG-to-real)
コンテンツ操作の手順は基本的にスタイルのものと同じです. 大きな違いは blender (CGを扱うソフトウェア) を用いるので, そこで勾配の情報が落ちてしまい, backpropagation ができない点です. そこで我々は blackbox 最適化ライブラリである optuna を用いています.
統制の取れたデータセット
本手法の目的は元々, CG 画像をリアル画像に似せるためにコンテンツを操作するというものです. しかし実際の CG 画像とリアル画像はコンテンツではないスタイルの部分に様々な違いを持っています. これはコンテンツの違いだけを discriminator に見てもらいたい今回の実験においては望ましくありません. そこで私達は完全に同じスタイルを持つように二つの CG データセットを用いることにしました. 一つは CG データセットであることを模した CG データセット, もう一つは リアルデータセットであることを模した CGデータセットです. 例えば後述する実験1ではペットボトルが横に置かれているデータセットと縦に置かれているデータセットの二つを用意しています. このうち前者が CG データセットであることを想定したもので, 後者がリアルデータセットであることを想定したものです. このように完全にスタイルは一致しており, コンテンツだけが違うデータセットを CG によって作ることで, より問題の切り分けがしやすい環境を作成しました.
実験1
まず私達は最も簡単な問題設定として縦向きのペットボトルで構成されるデータセットと横向きのペットボトルで構成されるデータセットを用意しました. ここでは横向きのペットボトルを CG, 縦向きのペットボトルをリアルと仮定しています.

まずはこの二つのデータをちゃんと分類できるような discriminator を学習させます. 訓練・評価時の設定は以下の通りです.
- トレーニングデータセット
- 横向き: 10K
- 縦向き: 10K
- テストデータセット
- 横向き: 1K
- 縦向き: 1K
- 5 epoch
この結果, テストデータセットに対して100%の分類精度を出す discriminator が得られました.
この discriminator を用いて縦のペットボトルの画像を生成します. 最適化するパラメータはオブジェクトの位置と回転角の計6個です. 最適化の結果, 以下のような画像が得られました.

これらの画像に対して, discriminator はリアルクラスの loss は0, つまり確信度100%で縦向きの画像と判定します. 若干斜めに傾いたものもありますが, 大まかに良さそうな結果となっています. 一方で最適化の結果, 以下のような画像も生成されました.

この画像ではオブジェクトが完全に横向きに配置されているのにも関わらず, discriminator は100%の確信度で縦向きの画像と判定します. 先程の斜めの画像もそうですが, 何故このような縦向きから外れたようなオブジェクトの配置がなされてしまうのでしょうか. 私達はこの現象が discriminator の Out-Of-Distribution (OOD) に対する学習不足に起因しているのではないかと考えています. つまり discriminator は完全に縦または横にオブジェクトが向いている画像しか見ていないので, 学習データに含まれていない斜め向きのオブジェクトや先端 (飲み口) が右向きに向いているオブジェクトには知識が無く, このような画像に対して上手く予測することができないのではないかと考えられます. このようなOODな画像に対して誤って高い確信度を出してしまうことがあることは数学的にも証明されています [12].
また最適化の推移は以下のようになっています. かなり早い段階で最適解が見つかっていることがわかります.

実験2
次により難しく, 現実的な問題設定としてコンビニやスーパーの棚を模したデータを扱います. ペットボトルや缶の棚への置かれ方はランダムではなく, ある規則性を持っています. ここでは以下のようなルールを持つ棚を考えます.
- 棚の上段には1L未満の小さなオブジェクトが縦向きに置かれる.
- 棚の下段には1L以上の大きなオブジェクトがこちらに向かって横向きに置かれる.
もう一方のCGデータセットはほぼランダムに配置します. 実際に作成されたデータセットは以下のようになっています.

両データセットに共通する性質は以下の通りです.
- ペットボトルの底面の座標 (回転の中心角)
- オブジェクト数
- オブジェクトが選択されるオブジェクト集合
この二種類の画像を識別するために以下の設定で discriminator を訓練・評価しました.
- トレーニングデータセット
- ランダム: 10K
- 棚: 10K
- テストデータセット
- ランダム: 1K
- 縦: 1K
- 5 epoch
その結果, テストデータセットに対して100%の分類精度を出す discriminator が得られました.
この discriminator を用いて棚の画像を生成します. 最適化するパラメータはオブジェクトの種類 (6種類) とそれぞれの回転角 (3個) の計18個です. 最適化の結果, 以下のような画像が得られました.

これらはどれも discriminator によって100%の確信度で棚だと判定される画像です. 上段の縦向きのペットボトルは比較的上手くいっているのに対して, 下段のペットボトルはほとんど上手くいっていません. これはデータセットの構築に, ひいては discriminator の識別に問題があります. 今回の discriminator のタスクはランダムにオブジェクトが配置された画像と棚のように配置された画像を見分けることですが, これは単に画像の上部を見るだけで上手くいってしまいます. これにより discriminator は画像上段しか見ないようになってしまい, 下段を完全に無視し, optimization 時には画像の上部だけを揃えるようになってしまいました. 下の画像は最適化の過程で生まれた画像で, 画像上部の数字は cross entropy loss です. loss が上昇するほど上段の配置がおかしくなっていくことがわかります. 
最適化の推移は以下のようになっています. 先程の実験1に比べると loss の下降が遅いもののそれでもパラメータ数に対して比較的早く収束しているように思われます. これは上段のオブジェクトだけを最適化すればいいということに起因しています. 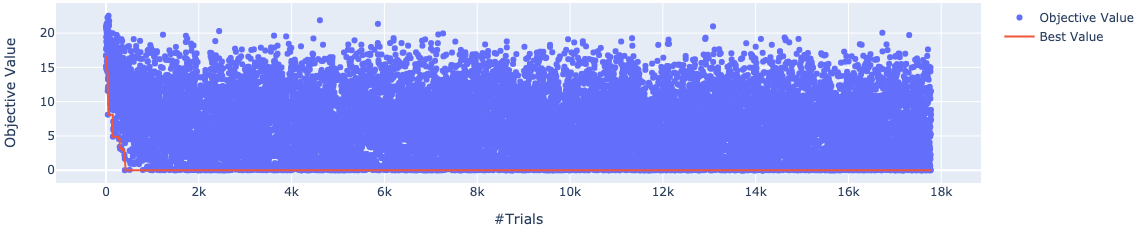
実験2.1
実験2では discriminator が棚の上段だけに注目してしまい, 最適化があまり上手くいきませんでした. では事前知識無しでこの現象を改善していくにはどうすればいいでしょうか. 今回のようなデータセット構成では discriminator が学習する前の段階で気付けそうなものですが, 実際は人間が気付けないような違いを自動で修正していきたいので, 適切なデータセットは人間の知識は使わず構成されるべきです. そこで私達は実験2で生成された画像をランダムデータセットに混ぜて新たなデータセットを構築することを考えました. すなわち今回の実験2.1で使われるデータセットは以下の二つです.
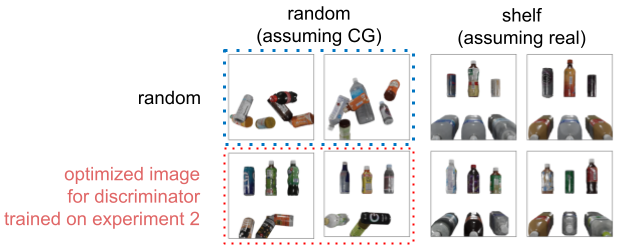
この二種類の画像を識別するために以下の設定で discriminator を訓練・評価しました.
- トレーニングデータセット
- ランダム: ランダム5K + 実験2で生成された画像5K
- 棚: 10K
- テストデータセット
- ランダム: ランダム500 + 実験2で生成された画像500
- 棚: 1K
- 5 epoch
その結果, テストデータセットに対して100%の分類精度を出す discriminator が得られました.
この discriminator を用いて棚の画像を生成します. 最適化するパラメータは実験2に同じです. 最適化の結果, 以下のような画像が得られました.

画像上部の数字は cross entropy loss です. Cross entropy loss はニクラス分類でお互いの確率が50%のとき, およそ0.69なのでどの画像も discriminator によって棚と判断されていません. 下の画像は最適化の推移を表したものです. これまでは loss が低い位置からも多くの点がサンプリングされていたのに対して, 今回の結果はサンプリングされた点がほとんど高い loss となっています.
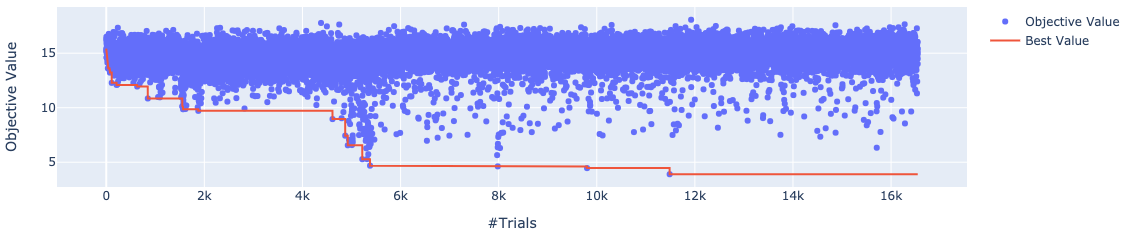
何故このような現象が起こっているのでしょうか. 下の画像は人間の手によって生成された画像を discriminator に入力し, cross entropy loss を計測したものです. 左から一枚目と三枚目の画像は実験2.1の discriminator が下段の変化にとても sensitive なことを示しています. これにより optuna は loss が低くなるパラメータを中々取得できず, 最適化の手掛かりがほとんど得られなかったのだと考えられます. また左から一枚目と二枚目の画像を比べると今度は上段のオブジェクトを無視していることがわかります.

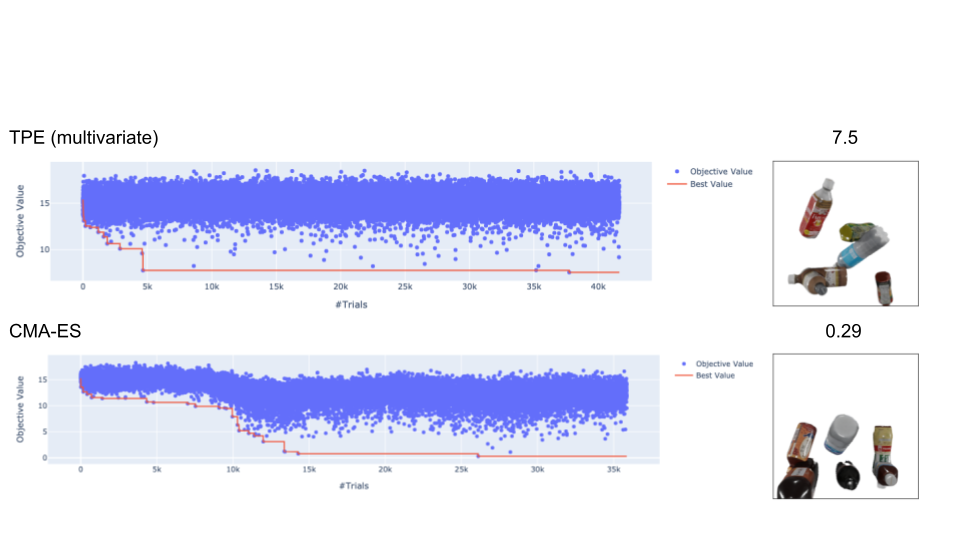
ちなみにこれまでは optuna のデフォルトの Tree-structured Parzen Estimator (TPE) sampler を使っていたのですが, optuna の sampler を変えて, 最適化を行うと以下のようになります. 右の画像は最も loss が小さくなった画像です. 結果, CMA-ES sampler で最も良い最適化を行うことができました. これは最適化のパラメータがほとんど連続値だったからだと考えられます.
今後の課題
今回は実験2.1まででインターン期間が終了してしまいましたが, 実験2.1で生成された画像を新たにランダムデータセットに混ぜることで完璧な棚画像を生成できるかもしれません. またリアルを模した CG データセットを扱うことで実験を行いましたが, より複雑な現実のデータに対してもこのような最適化が上手くいくのか検証したいと思います. さらにこのようなコンテンツの最適化が実際に classification や instance segmentation などの精度を向上できるのかを実験していきたいと考えています.
まとめ
私達は CG 画像とリアル画像の間に存在する gap を semantic に埋め, CG データセットでの深層学習や CG クリエイターの CG 生成を手助けする手法について研究しました. スタイル操作では残念ながら instance segmentation の精度向上にまでは繋がりませんでしたが, CG 画像とリアル画像の間の gap を人間にも分かる形で分析することができました. コンテンツ操作では二つの CG データセットと提案手法を用いて自動的にコンテンツ要素を最適化できることを示しました.
参考文献
[1] Learning deep object detectors from 3d models [Peng+, ICCV15]
[2] Play and Learn: Using Video Games to Train Computer Vision Models [Shafaei+, BMVC16]
[3] Virtual Worlds as Proxy for Multi-Object Tracking Analysis [Gaidon+, CVPR16]
[4] VisDA: The Visual Domain Adaptation Challenge [Peng+, arXiv17]
[5] Habitat: A Platform for Embodied AI Research [Savva+, ICCV19]
[6] Learning Classifiers from Synthetic Data Using a Multichannel Autoencoder [Zhang+, arXiv15]
[7] Learning from Simulated and Unsupervised Images through Adversarial Training [Shrivastava+, CVPR17]
[8] CONTRASTIVE SYN-TO-REAL GENERALIZATION [Chen+, ICLR21]
[9] Domain Stylization: A Strong, Simple Baseline for Synthetic to Real Image Domain Adaptation [Dundar+, arXiv18]
[10] Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks [Zhu+, ICCV17]
[11] On the Role of Receptive Field in Unsupervised Sim-to-Real Image Translation [Jaipuria+, NeurIPS19]
[12] Why ReLU networks yield high-confidence predictions far away from the training data and how to mitigate the problem [Hein+, CVPR19]
感想
PFNでのインターンはおよそ一ヶ月程でしたが, 一ヶ月とは思えないような濃い時間を過ごさせて頂きました. 中間発表と最終発表では多くの社員の方と議論を交わし, また沢山のアドバイスを頂くことができました. PFNがこのような環境を整えて下さったお陰で, ずっと楽しく, 充実した研究をすることが出来ました. 今回のインターンで培われた知識や考え方をこの先の人生でも大いに役立て, 励んでいきたいと思います.
最後になりますが, メンターの二井谷さんと小川さん, サポートの菊池さんにはこの一ヶ月の間, 毎日長時間議論を交わさせて頂き, 本当に感謝の気持ちで一杯です. この場を借りてお礼申し上げます. 本当にありがとうございました.
