Blog
本記事は、2021年度PFN夏季インターンシップで勤務した秀島宇音さんによる寄稿です。
はじめに
深層学習を軸とする研究開発には計算資源を多く要します。特に、Trainingと呼ばれる深層学習モデルのパラメータを調節するフェーズでは多大な計算が必要です。そこでPFNはこの計算を得意とするアクセラレータMN-Core™を神戸大学と共同開発し、実際にスーパーコンピュータMN-3に搭載して運用しています。MN-3は極めて高い省電力性能を持ち、スーパーコンピュータの省電力性能ランキングGreen500で世界1位を3度獲得しています。Green500での成果については「PFNの深層学習用スーパーコンピュータMN-3、39.38GFlops/Wの電力効率を記録しGreen500ランキングで3度目の世界1位を獲得」をご覧ください。また、MN-Core上で動作する深層学習アプリケーションの開発状況については「MN-Coreコンパイラを用いた深層学習ワークロードの高速化」をご覧ください。
今回のインターンシップでは、MN-Core上のワークロードの最適化を支援するプロファイラを開発しました。本記事では、その特長と意義について説明します。
MN-Coreの概要とソフトウェアの責任
MN-Coreは深層学習ワークロードに特化したアクセラレータです。アーキテクチャとして以下の特徴を持っています。
- 単一の命令で複数の計算ユニットを動作させるSIMD(Single Instruction Multiple Data)モデルの、その中でも条件分岐が無く特に並列性を重視している完全SIMDモデルを採用していること。
- ハードウェア制約の許す限りで単一の命令内に複数種類の処理を表現でき、それらが同時に実行されるモデルを採用していること。
- 一般的なプロセッサではハードウェアが自動的におこなう、メモリ同士やメモリ・演算器の間でのデータ移動の制御をソフトウェアで陽に記述すること。
これらのアーキテクチャ上の特徴を活かすことで、MN-Coreは演算器の配置において極めて高い集積性を実現し、他のプロセッサを超えた計算性能・電力効率を実現しています。
一方で、ハードウェアの並列性を活かしつつ、制約を守りデータ移動を正しく制御する、大きな責務がソフトウェアのプログラマに課されます。ハードウェアの制御するところが極端に少ないこのハードウェアは、実行するソフトウェア(アセンブリ)だけで詳細な実行時の流れがほぼ決定されるほどで、良いソフトウェアを書けばその分高い効率が実現できる反面、そのためにプログラマが考えなければならない事柄が多いのです。
ここに、ハードウェアの活用状況や各処理の実行時間を提示する、洗練されたプロファイラを開発する大きな意義があります。そしてMN-Coreの独自性に対応するためにはプロファイラも新たに作成する必要がありました。このニーズに応え、すぐに実用できるプロファイラを用意したこと、それが私の6週間のインターンシップの成果です。
速く、シンプルで、それでいて網羅的
作成するプロファイラでは次のことを重視しました。
- MN-Coreの決定的な性質を活かし、高速に動作すること
一般的なプロセッサ上のプロファイリングでは、実際にプログラムを実行し、その最中にハードウェア資源を情報収集のために消費する必要があります。そこでは多くの情報を得ることと素早くプロファイリングを終えることが厳しいトレードオフの関係にあることが珍しくありません。
しかしMN-Coreの場合、先述の通りアセンブリから挙動がほぼ決定されます。これを活かし、実行する必要がなくかつ高速なプロファイリングを実現しました。
また後述するように実現の過程でコンパイラに機能追加を施しましたが、そこでもコンパイルに要する時間を極力増やさないよう配慮しました。
- ソフトウェア全体の特徴を楽に俯瞰できること
高速化においては、まずプロファイリングを通じて時間のかかっている箇所を特定し、そこから高速化を検討せよ、という戦略がよく知られています。MN-Coreプログラミングでもこれを実現できるよう、ソフトウェア全体を見渡して、ボトルネックはどこか、そこに高速化の余地はありそうかが分かりやすい可視化を目指しました。結果は次の章でご覧頂きます。
- 細かな部分の挙動を知れること
MN-Coreの、データ移動をソフトウェアで陽に制御するとか、単一の命令内に複数種類の処理を表現できるといった特徴のため、命令1つ1つの粒度でハードウェアの挙動を把握することが高速化に繋がることが少なくありません。全体の俯瞰から詳細の拡大までをシームレスに行えることを目指しました。こちらも結果は次の章でご覧頂きます。
可視化結果
次は実際に可視化した結果の例です。
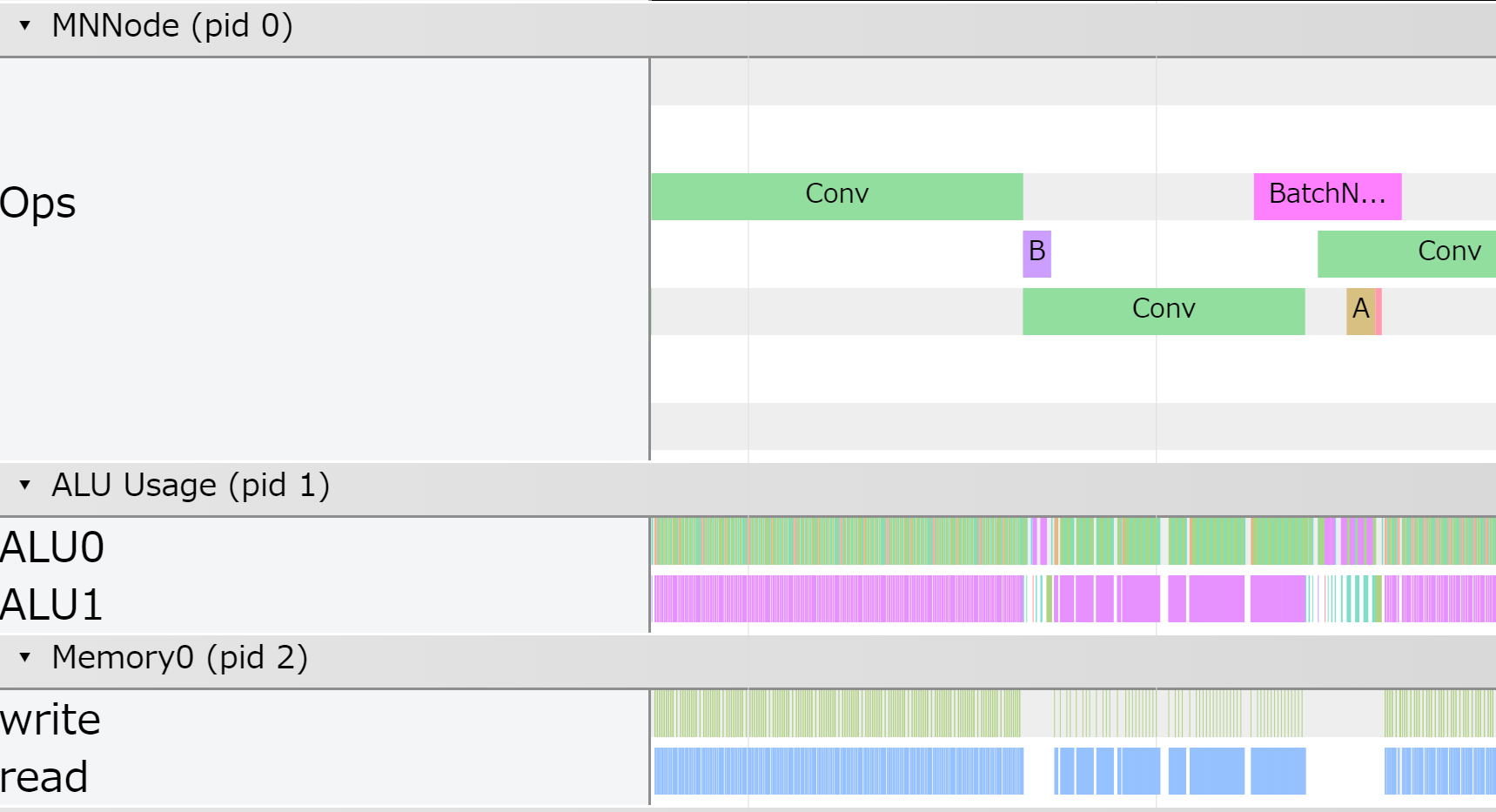
まず、ソフトウェア全体の特徴をマクロに俯瞰でき、高速化すべき箇所を発見できます。「MNNode」と名付けられた部分は主にそのためのレーンです。ここでは深層学習モデルのレイヤや、プログラマが独自に指定した処理のかたまりといった大きな粒度で、各々がいつどれぐらい時間をかけて実行されているかが表示されています。そして、他のレーンをマクロに見ると演算器やメモリがあまり使われていない時間帯が見て取れます。組み合わせると、時間がかかっていて高速化の余地があるという、まさに高速化すべき部分にたどり着けるのです。
実際に高速化を試行錯誤する際には、よりミクロな見方でハードウェアの挙動の詳細を把握することが役に立ちます。そのために「ALU Usage」以下のレーンで演算器やメモリをいつ何に使っているかがサイクル単位で可視化されています。
また、可視化結果を自分で最適化に応用し、Gatherレイヤのbackpropなどに用いられるindex_addという演算について、あるパラメータにおいて所要時間を2/3にすることに成功し、可視化プロファイラの有用性を確認できました。
実装上の工夫点
Chrome Trace Eventの活用
プロファイル結果には既存の洗練されたビューアを活用できるChrome Trace Event形式を採用しました。本来はスタックトレースを扱うことが想定されている形式ですが、マルチプロセス・マルチスレッドに対応するための機能を使うと行ラベル名なども含め自由なタイムラインを表示できます。
コンパイラとの協調
MN-CoreコンパイラはONNXを入力とし、MN-Coreアセンブリを出力します。ONNXの各層とアセンブリの区間の対応関係は全体像の把握に有用ですが、最適化の結果、区間は重複したり包含関係にあることがあり、対応関係を著しく難読化させていました。
今回のプロファイラ開発では、コンパイラと協調し、対応関係も可視化することに成功しました。アセンブリの区間と対応を取りたい範囲はコンパイラ開発者が独自に指定することもできるようになっています。
実装にあたっては、スケジューラの実装者と密にコミュニケーションし、スケジューリング越しの情報伝達を低オーバーヘッドで実施する方法を考案しました。
今後の展開
今回、インターン期間内で可視化プロファイラを実装し、実際に最適化の補助になると実証できました。今後もPFN内で使用され、より一層の高速化とその先の応用に繋がると期待しています。
また、コンパイラとの協調に用いた仕組みは一般的なもので、同じ仕組みでより豊富な情報を可視化できます。これにより今回の成果が間接的にも高速化に寄与することを期待しています。



