Blog
この記事は、パートタイムエンジニアの川上航さんとLLM応用に取り組んでいるリサーチャーの岩澤諄一郎とエンジニアの鈴木渓太による寄稿です。
概要
- 医師国家試験において外部知識として過去問を用いた場合のRAGと継続事前学習の性能の比較を行いました
- 上記の設定において継続事前学習がRAGを上回ることを示しました
- 更に継続事前学習とRAGを組み合わせることで大幅な性能向上が見込めることを示しました
- PFN ではLLMへの新たな知識の注入など、様々な分野でのLLMの活用を目指し引き続き研究開発を進めてまいります
RAGとFinetuning
近年大規模言語モデル(LLM)がその有用性から脚光を浴びており、様々な領域での活用が進められています。膨大なコーパスによって学習されたLLMは様々な知識を持っていますが、事前学習によって得られた知識だけでなくドメイン特化のLLMや社内情報を用いたLLMの活用など新しい知識をLLMに教えたい場合が実用上多々あります。LLMに新しい知識を教えるための有力な手法としてRAG [1]とFinetuningが知られています。RAGはRetrieval Augemented Generation (検索拡張生成)の頭文字をとったもので入力に関係した文章を検索してきてプロンプトに与え、LLMにIn-context learningで適応させることで外部の知識を活用する手法です。RAGは手軽に実現できる上に、強力な手法であるためLLMチャットボットをはじめとして幅広い領域で活用されています。一方でFinetuningはRAGのように都度必要な知識を与えるのではなく、学習を通して知識をまとめて教える手法です。LLMのFinetuningには継続事前学習 (Continual Pretraining) [2]や指示学習 (Instruction Tuning) [3]などがありますが、新しい知識の注入に特に有用なのは継続事前学習であり本実験でも継続事前学習を用いています。
新しい知識をLLMに教えるにあたって、どの様な場合にどちらの手法を選択すべきかというのはLLM界隈において大きな関心です。この課題について様々な検証が進められており、Ovadia et al. [4]の行った実験によれば様々なタスクにおいてRAGの方がFinetuneよりも性能がよく、さらにRAGとFinetuneを組み合わせるよりもRAG単体の方が高い性能がでるという結果が出ています。本稿ではRAGとFinetuneの振る舞いを理解するため日本医師国家試験とその過去問を用いて FinetuningとRAGの性能の比較し、更に組み合わせて適用した時の性能の検証を行います。
実験設定
RAGとFinetuningの性能を日本医師国家試験で評価するために IgakuQA [5] を使用しました。IgakuQA は Jungo Kasaiさんらによって開発された LLM 用のベンチマークであり、2018~2022年の日本医師国家試験の問題を LLM に解かせることができ、この5年分の医師国家試験の問題で性能の比較を行います。医師国家試験には知識を問う問題だけではなく知識を組み合わせて論理的推論を行う必要のある問題も多く含まれており、知識の有無だけでなく活用することができるのかという観点からも比較を行うことを狙いとしています。
また、RAGやFinetuningには2018~2022年を除く日本医師国家試験の過去問と解説文を使用します。比較に用いるベースのモデルにはSwallow-MX-8x7b [6]を選びました。東工大と産総研の合同グループによって開発されたSwallow-MX-8x7bは、 Mistral AI社のMixtral-8x7b[7]に対して継続事前学習を行って日本語能力を強化したモデルです。
RAGの詳細
今回RAGの実行に際して、全文検索手法であるBM25とベクトル検索の二つを用いてそれぞれ実験を行いました。ベクトル検索にはOpenAI社のtext-embedding-ada-002 [8]を用いています。具体的な方法としては解くべき問題の類題をBM25などで検索し、検索した類題の問題と答え、そして解説のセットを3-shotで与えています。この様な形式にした意図としては、元のIgakuQAが3-shotで解かせているのと、問題や解説をセットで与えないと例えば問題文だけが検索でヒットしてしまいLLMに有益な情報が提供されないなどの問題が発生するためです。プロンプトの例を以下に掲載します。一番下の問題が実際に解くべき問題で、事前に3-shotで問題と答え、解説を与えています。本来は3-shotですが紙面の関係で1-shotで掲載しています。
医師国家試験を解きます。
問題: 40歳の男性。関節痛と皮疹とを主訴に来院した。以前から皮疹をよく認めていたが、約3か月前から背部の皮疹が拡大してきた。同時期から、手指の関節痛、腰痛および殿部痛を自覚するようになった。貼付剤で様子をみていたが、改善しないため受診した。意識は清明。体温36.5°C。心音と呼吸音とに異常を認めない。上腕部と背部とに皮疹を認める。両手の爪に点状陥凹を認める。両手の示指、中指、環指の遠位指節間関節〈DIP関節〉および近位指節間関節〈PIP関節〉に腫脹と圧痛とを認める。アキレス腱付着部に軽度の圧痛を認める。血液所見:赤血球452万、Hb 14.1g/dL、Ht 45%、白血球5,600、血小板16万。免疫血清学所見:CRP 0.3mg/dL、リウマトイド因子〈RF〉陰性、抗核抗体陰性。背部の写真を別に示す。この患者でみられる可能性が高いのはどれか。
a: 心嚢水貯留
b: 外陰部潰瘍
c: 仙腸関節炎
d: Gottron徴候
e: 多発単神経炎
必ずa,b,c,d,eの中からちょうど1個選んでください。
答え:c
考察:
(問題の解説)
(実際には上のような類題が後二つ続きます)
問題: 68歳の男性。上前胸部痛を主訴に来院した。2年前から両手掌に皮疹が繰り返し出現していた。1年前から上前胸部痛を自覚していたという。1か月前から上前胸部の疼痛が増悪したため受診した。両手掌に膿疱性皮疹を多数認める。両側の近位指節間関節の腫脹と圧痛を認める。両側胸鎖関節の骨性肥厚と熱感および圧痛を認める。この患者の胸部エックス線写真を別に示す。関節病変の原因として最も考えられるのはどれか。
a: 関節リウマチ
b: 強直性脊椎炎
c: 慢性疲労症候群
d: 掌蹠膿疱症性骨関節炎
e: リウマチ性多発筋痛症
必ずa,b,c,d,eの中からちょうど1個選んでください。
答え:
Finetuningの詳細
継続事前学習にはRAGで用いたものと同様に過去の医師国家試験の問題と解説を用いています。また限られた計算リソースで継続事前学習を実施するためにQLoRA [9]を用いました。QLoRA は量子化 (quantization) [10] と LoRA [11] を組み合わせた手法であり、大規模言語モデルのFinetuningを限られた計算リソースで実行するための手法です。通常 LLMを含む深層学習モデルでは、各パラメータは16ビットや 32ビットで表現されますが、量子化されたモデルでは各パラメータが4ビットなどの低いビット数で表現されるため、より小さいメモリで扱うことが可能になります。また、LoRA (Low-Rank Adaptation) とは大規模言語モデルの Finetuning における低次元性 [12] に着目した手法で、元のモデルのパラメータ自体を学習するのではなく、アダプターと呼ばれる低ランクの行列のみを学習し、得られた低ランク行列をモデルの重みに足し算するものです。これらの組み合わせによりQLoRA は少数の GPU で Finetuningを行うことが可能で、その手軽さから広く利用されています。実際、今回の QLoRA を用いた継続事前学習も社内の計算機クラスターの A100 GPU 2台のみで実現できています。
実験結果
2018~2022年の医師国家試験を継続事前学習とRAGを用いて解いた結果は表1の通りです。Swallow-MX-Cptが医師国家試験の過去問を用いてSwallow-MXを継続事前学習したモデル、Swallow-MX-RAG-EmbeddingとSwallow-MX-RAG-BM25がそれぞれベクトル検索とBM25を用いて行ったRAG、Swallow-MX-8x7b-NVE-v0.1が継続事前学習とRAGのベースモデルであるSwallow-MX-8x7Bの結果です。Swallow-Mx-CptとSwallow-MX-8x7b-NVE-v0.1には推論に際して出力の形式を安定させる目的でIgakuQAで用いられている 3-shot の問題と解答をIgakuQAのpromptと同様に与えていますがRAGの場合とは違って解説は与えていません。2018~2022年の全ての年において継続事前学習を行ったモデルが、RAGを行ったものを含め他のケースに大きく差をつけて勝っているのが見て取れます。
| 平均 | 2018 | 2019 | 2020 | 2021 | 2022 | |
| Swallow-MX-Cpt | 308.4 | 301 | 296 | 311 | 312 | 322 |
| Swallow-MX-RAG-Embedding | 291.6 | 288 | 290 | 296 | 285 | 299 |
| Swallow-MX-RAG-BM25 | 286.2 | 273 | 280 | 309 | 280 | 289 |
| Swallow-MX-8x7b-NVE-v0.1 | 282.2 | 269 | 285 | 290 | 277 | 290 |
表1. 日本医師国家試験 (IgakuQA) における継続事前学習モデル、RAG、ベースモデルの成績。2018~2022年の各年度の成績とそれらの平均を記載しています。
結果の考察
今回の結果の要因として「知識の活用」という点でRAGよりも継続事前学習の方が得意であるということが挙げられます。継続事前学習については先行研究で同様の現象が観測されており、問題と解答のペアを作成してコーパスに加えることで性能の向上につながるといった研究が存在します。Cheng et al. [13]は医学分野や金融の分野で生のコーパスだけでなくそこから作成された問題と解答のペアをコーパスに加えることで生のコーパスだけの継続事前学習よりも性能が高くなったと主張しています。この現象は通常の事前学習でも観測され、特に後段の指示学習による恩恵がより大きくなるとのことです。あくまでも仮説ですが恐らく問題形式を学習することで知識の引き出し方を獲得していると考えられ、今回は解くべきタスクと同じ医師国家試験の問題で継続事前学習を行っているので尚更その効果が大きかったのだと思います。一方でRAGにおいては初見の知識に対応して、さらに知識を活用して高度な論理推論を行うという難題がLLMに要求されます。医師国家試験の問題は単に知識を問う問題だけではなく、患者の症例から診断を行う問題など高度な論理的思考を要する問題が存在します。検索によって提供された文章に適応して知識を獲得するだけでなく、応用させてこうした問題に取り掛かるのはLLM目線だと大きな負担になると考えられます。また、RAGではそもそも必要な知識を網羅できないということも考えられます。論理推論を要する問題は複数の知識が要求されることがあるため、必要な知識が検索してきたそれぞれの問題に散らばっていたり、あるいはそもそもその中になかったりということもあり、RAG目線では知識問題よりも難易度はかなり高くなると考えられます。
この考察を実証するために継続事前学習とRAGでベースモデルと比較したときの知識問題と論理的思考を要する問題の正答数の変化をそれぞれ集計して比較します。例えば知識を問う問題や論理的思考を要する問題というのはそれぞれ以下の様なものです。
やせをきたすのはどれか。3つ選べ。
a: Addison病
b: 褐色細胞腫
c: 甲状腺機能亢進症
d: 原発性アルドステロン症
e: 原発性副甲状腺機能亢進症
(第115回医師国家試験問題 [14] より引用)
5歳の女児。3日前からの高熱を主訴に母親とともに来院した。咽頭痛と食欲低下を認めるが、咳嗽や鼻汁は認めない。体温39.6℃。脈拍120/分、整。呼吸数28/分。SpO2 100%(room air)。活気良好。顔色良好。眼球結膜に軽度の発赤を認める。咽頭の発赤を認め、口蓋扁桃に白苔の付着を認める。両側の頸部に径1.5cmのリンパ節を4個ずつ触知する。心音と呼吸音とに異常を認めない。腹部は平坦、軟で、肝・脾を触知しない。可能性が最も低い疾患はどれか。
a: 川崎病
b: 溶連菌感染症
c: EBウイルス感染症
d: アデノウイルス感染症
e: パルボウイルスB19感染症
(第115回医師国家試験問題 [14] より引用)
二つ目の問題のように、医師国家試験の問題のうち、論理的な思考を問うものは問題文が長くなる傾向にあったことから集計に際して選択肢を除いた問題文が50文字以上の問題、知識を問う問題を50文字以下の問題で代用することにします。それぞれの問題における継続事前学習モデルとBM25とEmbeddingを用いたRAGのベースモデルからの正答数の変化を表2, 3に掲載しています。表1は医師国家試験のスコアですが表2, 3については正答数である点に注意してください。問題文が50文字以下の問題の正答数の変化にはほとんど差はありません(表2)が、一方で問題文が50文字以上の問題に関しては大きく差が開いており(表3)、継続事前学習では正答数を大きく伸ばしている一方でRAGでは正答数に多少の増減しかないことが見て取れます。
| 平均 | 2018 | 2019 | 2020 | 2021 | 2022 | |
| Swallow-MX-Cpt | +9.2 | +12 | +8 | +5 | +12 | +9 |
| Swallow-MX-RAG-BM25 | +9.4 | +3 | +8 | +16 | +11 | +9 |
| Swallow-MX-RAG-Embedding | +8.2 | +8 | +3 | +11 | +14 | +5 |
表2. 日本医師国家試験 (IgakuQA) における継続事前学習モデルとRAGのベースモデルと比較した時の50文字以下の問題文を持つ問題の正答数の変化。2018~2022年の各年度の正答数の変化とそれらの平均を記載しています。
| 平均 | 2018 | 2019 | 2020 | 2021 | 2022 | |
| Swallow-MX-Cpt | +10.8 | +12 | +3 | +14 | +11 | +14 |
| Swallow-MX-RAG-BM25 | -3.2 | +1 | -5 | +3 | -8 | -7 |
| Swallow-MX-RAG-Embedding | +1.8 | +9 | +3 | -5 | 0 | +2 |
表3. 日本医師国家試験 (IgakuQA) における継続事前学習モデルとRAGのベースモデルと比較した時の50文字以上の問題文を持つ問題の正答数の変化。2018~2022年の各年度の正答数の変化とそれらの平均を記載しています。
この結果は先行研究であるOvadia et al.[4]の結果と異なるものになっていますが、この違いは恐らくタスクの種類に起因するものであると考えられます。彼らの実験ではMMLU [15]から極力論理的な推論が必要な問題を除去しており、純粋に知識の有無を問う問題に限定していてこれは医師国家試験とは大きく異なります。知識のみを問う問題は論理的推論が必要な問題に比べてRAG目線では解きやすい問題になっていると考えられ、検索の段階である程度正しい文章を引っ張ってくることができればあとは該当箇所を探すだけで回答することができます。また、この様な問題では複数の知識を組み合わせる必要がない場合が多いというのも考えられる要因として挙げられます。
今回は医師国家試験を解かせるにあたってRAGや継続事前学習で用いるデータとして過去問解説のみを用いましたが、今後の展望として医学分野の教科書など別の形式の外部知識を用いた時のそれぞれの振る舞いなどの検証も進めていきたいと考えています。
FinetuneとRAGの組み合わせ
継続事前学習モデルでRAGを行って医師国家試験を解かせる実験も行いました。継続事前学習モデルはSwallow-MX-Cptを用いており、RAGで与えるプロンプトも上述の実験と全く同じもので、検索にはBM25を用いています。また、RAGを行わない場合の対照実験では先の実験と同様にIgakuQA で用いられている 3-shot の問題と解答のみを与えています。表4に継続事前学習前後のモデルでBM25でRAGを行った場合と行わない場合の4通りの結果と、RAGを用いる前後でのスコアの変化を示します。Swallow-MX-Cpt-RAG-BM25が継続事前学習モデルにBM25でRAGを行った結果でその他は表1と同様です。表4から継続事前学習とRAGを組み合わせることで大幅にスコアを高めることができることが見て取れます。特筆すべきは継続事前学習とRAGで同じ文章を2回参照しているにも関わらず、継続事前学習後のモデルの方がスコアの増分がかなり大きくなっているの点です。これは解くべき問題の類題と答え、解説が与えられたことでAttention機構によるIn-context learningが働き、問題を解くのに必要な知識が想起されたからなのではないかと考えています。これはあくまでも仮説ですので今後も検証を続けていきたいと考えています。
| 平均 | 2018 | 2019 | 2020 | 2021 | 2022 | |
| Swallow-MX-Cpt-RAG-BM25 | 328.4 | 317 | 329 | 338 | 329 | 329 |
| Swallow-MX-Cpt | 308.4 | 301 | 296 | 311 | 312 | 322 |
| Swallow-MX-Cptのスコア変化 | +20 | +16 | +33 | +27 | +17 | +7 |
| Swallow-MX-RAG-BM25 | 286.2 | 273 | 280 | 309 | 280 | 289 |
| Swallow-MX-8x7b-NVE-v0.1 | 282.2 | 269 | 285 | 290 | 277 | 290 |
| Swallow-MXのスコア変化 | +4.0 | +4 | -5 | +10 | +3 | -1 |
表4. 日本医師国家試験 (IgakuQA) における継続事前学習前後のモデルでRAGを行った場合と行わない場合の成績とRAG前後のスコアの変化。2018~2022年の各年度の成績とそれらの平均を記載しています。
今までの実験を総合してRAGと継続事前学習、そして両者を組み合わせた手法のそれぞれの性能のイメージを図1に掲載します。論理推論が必要な問題では継続事前学習の方がRAGよりも得意であること、そして両者を組み合わせることで知識量の面でも知識の活用の面でも大きく改善することが今回の検証において示唆されました。
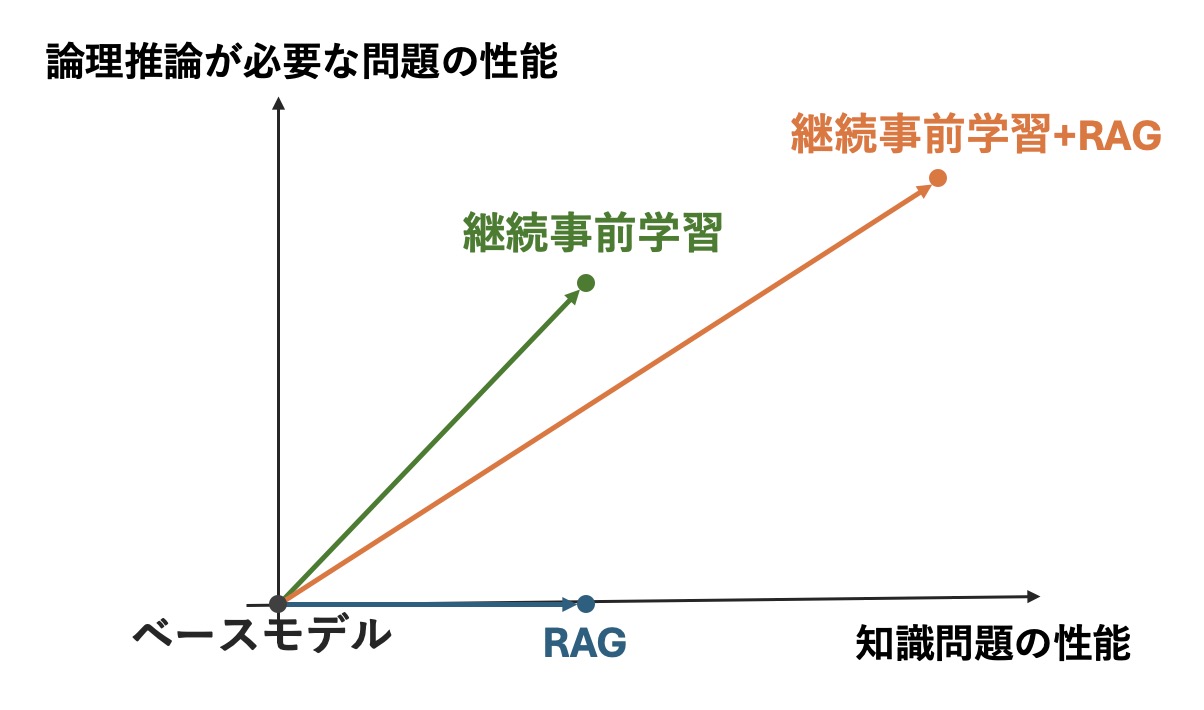 図1. 医師国家試験における継続事前学習、RAG、継続事前学習+RAGの性能のイメージ
図1. 医師国家試験における継続事前学習、RAG、継続事前学習+RAGの性能のイメージ
Llama3-Preferred-MedSwallow-70BにRAGを適用
最後にPFNが開発したLlama3-Preferred-MedSwallow-70B[16]にRAGを適用して医師国家試験を解かせてみます。Llama3-Preferred-MedSwallow-70BはPFNが既存の LLM を医療向けに改良したモデルでHugging Face 上で公開されているモデルとして初めて日本医師国家試験で GPT-4 [17]を超え、重みが公開されている LLM の中で唯一合格点を達成したモデルです。
今回の実験ではLlama3-Preferred-MedSwallow-70BにBM25を用いたRAGを行う設定と行わない設定で2018~2022年の医師国家試験を解かせました。表5に結果と比較用のGPT-4のスコアを示します。Llama3-Preferred-MedSwallow-70B-RAG-BM25というのがLlama3-Preferred-MedSwallow-70BでRAGを行った時の結果です。こちらのモデルでも継続事前学習とRAGを組み合わせることで大幅な点数の伸びが見られ、医師国家試験の合格点を出すことのできるGPT-4を大きく引き離しています。
| 平均 | 2018 | 2019 | 2020 | 2021 | 2022 | |
| Llama3-Preferred-MedSwallow-70B-RAG-BM25 | 411.8 | 414 | 413 | 414 | 411 | 407 |
| Llama3-Preferred-MedSwallow-70B | 395.2 | 407 | 390 | 391 | 393 | 395 |
| GPT4 | 388.8 | 382 | 385 | 387 | 398 | 392 |
表5. 日本医師国家試験 (IgakuQA) におけるLlama3-Preferred-MedSwallow-70BでRAGを行った場合と行わない場合の成績とGPT-4の成績。2018~2022年の各年度の成績とそれらの平均を記載しています。GPT-4の成績は [5] より引用し、Llama3-Preferred-MedSwallow70Bの成績は社内での測定結果を用いています。
最後に
今回、医師国家試験を題材にして外部知識をLLMに注入するための手法として継続事前学習とRAGの性能の比較や両者を組み合わせた時の性能を検証しました。医師国家試験の過去問のような問題形式では継続事前学習に分があることや両者を組み合わせることで更なる性能の向上が見込めることが明らかになりました。今回得られた知見は、今後の社内における研究開発やソリューション開発にも活用していく予定です。
なお、これらの結果はRAGや継続事前学習の手法の違いや用いるモデル、データセットの違いによって異なる結果が得られる可能性があります。PFNでは今後もLLMの外部知識の活用に関して研究開発や検証を進めてまいります。
PFNでは様々なドメインにおける LLM の活用を目指し、独自のベンチマークやデータセットの整備を進めています。今回の取り組みに興味を持っていただいた企業の方はぜひお問い合わせフォームよりご連絡ください。
最後に、Preferred Networks では採用を行っております。今回の記事で興味を持っていただけた方はぜひご応募ください。
- Machine Learning・Optimization・Data Science Engineer/機械学習・最適化・データサイエンスエンジニア / 株式会社Preferred Networks
- 基盤モデルサービス開発エンジニア(大規模言語モデル / 画像基盤モデル) / 株式会社Preferred Networks
- Software Engineer – LLM Platform (Application, Infrastructure) / 大規模言語モデルプラットフォーム開発エンジニア (アプリケーション・インフラ)
Reference
[1] Lewis, Perez, et al. “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” arXiv preprint arXiv:2005.11401 (2020).
[2] Chen, Zeming, et al. “Meditron-70b: Scaling Medical Pretraining for Large Language Models.” arXiv preprint arXiv:2311.16079 (2023).
[3] Ouyang, Long, et al. “Training language models to follow instructions with human feedback.” Advances in neural information processing systems 35 (2022): 27730-27744.
[4] Ovadia, Brief et al. “Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs” arXiv preprint arXiv:2312.05934 (2023).
[5] Kasai, Jungo, et al. “Evaluating GPT-4 and ChatGPT on Japanese Medical Licensing Examinations.” arXiv preprint arXiv:2303.18027 (2023).
[6] https://tokyotech-llm.github.io/swallow-mistral
[7] https://mistral.ai/news/mixtral-of-experts/
[8] https://platform.openai.com/docs/guides/embeddings
[9] Dettmers, Tim, et al. “QLoRA: Efficient Finetuning of Quantized LLMs.” Advances in Neural Information Processing Systems 36 (2024).
[10] Dettmers, Tim, and Luke Zettlemoyer. “The case for 4-bit precision: k-bit inference scaling laws.” International Conference on Machine Learning. PMLR, 2023.
[11] Hu, Edward J., et al. “LoRA: Low-Rank Adaptation of Large Language Models.” arXiv preprint arXiv:2106.09685 (2021).
[12] Aghajanyan, Armen, Luke Zettlemoyer, and Sonal Gupta. “Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning.” arXiv preprint arXiv:2012.13255 (2020).
[13] Cheng, Gu, et al. “Instruction Pre-Training: Language Models are Supervised Multitask Learners” arXiv preprint arXiv:2406.14491 (2024).
[14] https://www.mhlw.go.jp/seisakunitsuite/bunya/kenkou_iryou/iryou/topics/tp210416-01.html
[15] https://paperswithcode.com/sota/multi-task-language-understanding-on-mmlu
[16] https://tech.preferred.jp/ja/blog/llama3-preferred-medswallow-70b/
[17] https://openai.com/index/gpt-4/
Tag



